【9.0】对于java集合的迭代器的底层分析
前言:如果对java的集合的遍历(主要是HashMap中的keySet() 和 entrySet()是如何取值并且可以实现遍历的)不是很明白的话,有兴趣深入了解的小伙伴,本文可以作为一个参考,由于时间的原因,就着重讲其遍历的核心代码,底层迭代器的分析。如果对集合的遍历已经迭代器没有基本的理解的话,建议先看看相关的文章;不然基本看不懂本文。推荐几篇相关博文:
由于ArrayList的迭代器实现比较简单,这里不赘述,主要讲讲HashMap的迭代器,以HashMap的entrySet()方法为例:
1.先看一下代码及其运行结果:
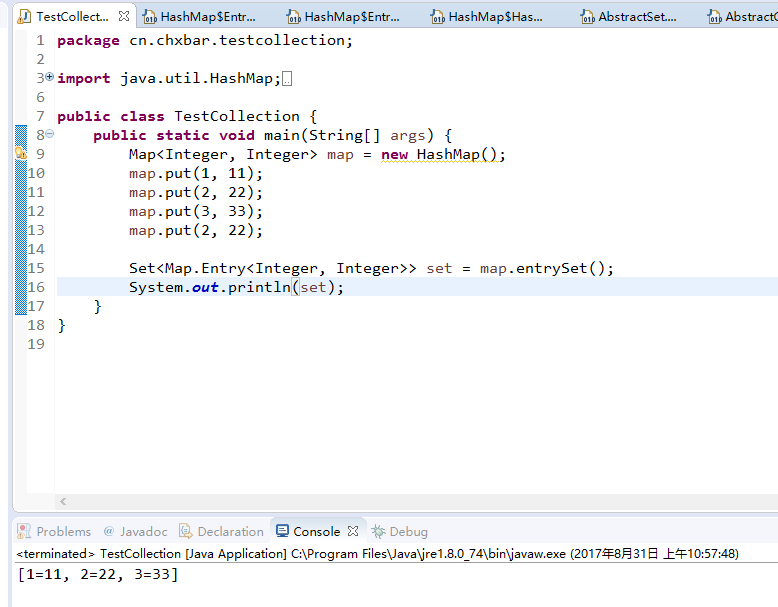
如果你点开entrySet()的代码一看,你就会觉得很神奇,如果你现在无感,那么你还是先看看这篇博文吧【1.实在没想到系列——HashMap实现底层细节之keySet,values,entrySet的一个底层实现细节 (为了方便描述,将该博文称为博文1,其他类推)】。那么现在分析一下,为什么entrySet()可以实现将map中值取出来呢,现在按步骤分析如下(以源码的查看为线索):
1.1 查看HashMap源码,定位到entrySet()方法:
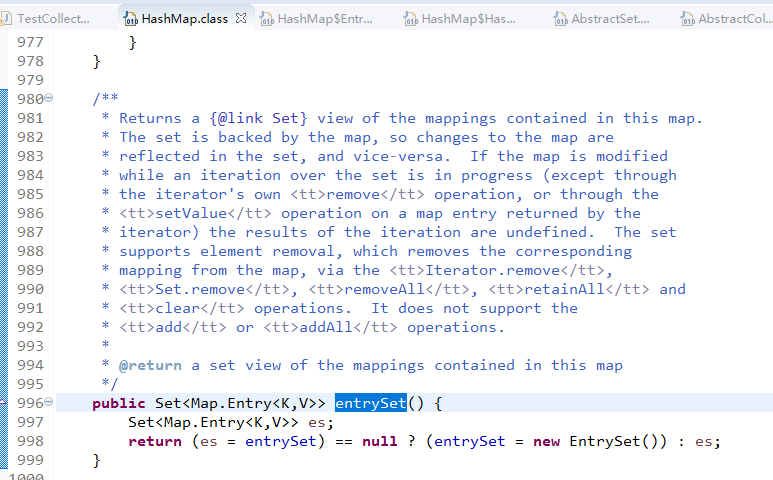
1.2 注意到此处返回的是一个EntrySet对象,那么定位到EntrySet对象:
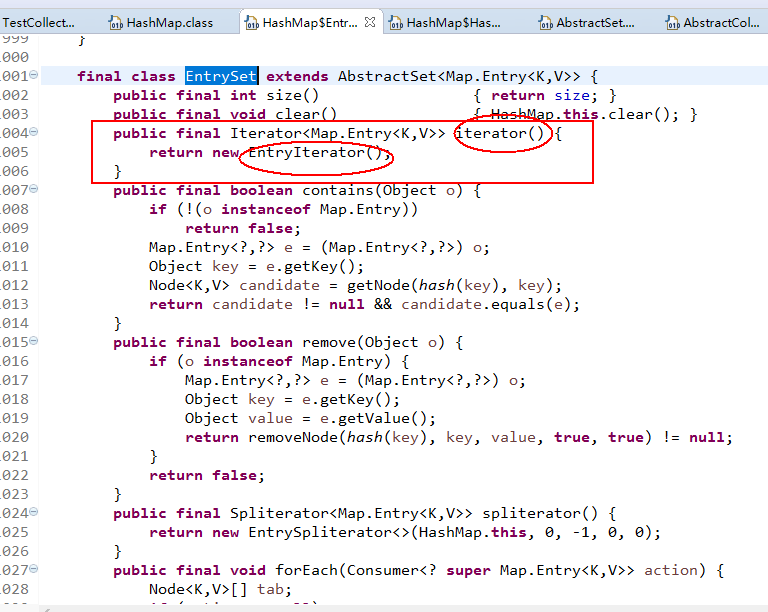
1.3 这时候你再怎么深入去定位你都会发现压根找不到有明显返回map中的值的地方,具体参考博文1,里面讲得很清楚;然后请注意截图中红色圈出的地方,注意到有一个iterator()方法,这就是关键所在,这时候请先参考博文2和博文3,以便理解后面的分析。到这里我们很清楚肯定是map调用了迭代器才使得可以取出map中相关的值(比如Set<Map.Entry<Integer, Integer>> set = map.entrySet();取出值:[1=11, 2=22, 3=33]),但注意set本身并没有什么变量或者字段保存了map中的值,而是在System.out.println(set);的时候,set调用了toString()方法(估计foreach获取map中的值也是有调用toString或者toArray()方法的),而toString()方法中调用(循环调用)了iterator()方法,从而遍历获取了map中的底层数组table(不懂的自己先查阅资料)中的值,这句话不是很理解没关系,我们先分析一下EntrySet对象(即对象set)的继承关系:
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {。。。}
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {。。。}
public abstract class AbstractCollection<E> implements Collection<E> {
。。。
public String toString() {
Iterator<E> it = iterator();
if (! it.hasNext())
return "[]";StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
if (! it.hasNext())
return sb.append(']').toString();
sb.append(',').append(' ');
}
}。。。
}
1.4 那么从EntrySet对象的继承关系来看,代码:Set<Map.Entry<Integer, Integer>> set = map.entrySet(); System.out.println(set); 其最终调用的是EntrySet对象的toString()方法,然后完成了对map中的值的遍历。那么现在分析一下toString()如何遍历获取map中的值
1.5 很明显 toString()中调用了iterator()方法,那么看看iterator()方法是如何实现的:



1.6 其实从以上源码不难知道iterator()方法的调用会返回一个迭代器EntryIterator, 该迭代器实现了对map底层数组table的非空值的获取,那么分析如何实现的。EntryIterator继承了HashIterator,核心便在此处,对HashIterator的源码一一分析如下:
首先,我们分析一下map的底层数组table,从中明显看出由于是哈希存储,数组上的值的分布不是有序的,比较散:

然后我们在看回HashIterator的源码,它实现了从map的底层数组table中获取非空值(即数组table [null, 1=11, 2=22, 3=33, null, null, null, null, null, null, null, null, null, null, null, null]中的非空值):
abstract class HashIterator { Node<K,V> next; // 保存table中的非空值 比如table数组的第二个元素【1=11】(该元素是一个Node对象,继承自Entry) Node<K,V> current; // current entry int expectedModCount; // for fast-fail int index; // table数组下标 //构造器 主要工作是获取table中的第一个非空值,并赋值给next HashIterator() { expectedModCount = modCount; Node<K,V>[] t = table; current = next = null; index = 0; if (t != null && size > 0) { // advance to first entry //获取table中的第一个非空值,并赋值给next do {} while (index < t.length && (next = t[index++]) == null); } } //判断当前元素是否为空 public final boolean hasNext() { //如果next不为空,说明从table中找到了非空值赋值给next【在构造器中赋值或者在nextNode()方法调用时赋值】 return next != null; } //获取当前元素 final Node<K,V> nextNode() { Node<K,V>[] t; Node<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); //【(next = (current = e).next) == null】判断当前的next(next是一个单链表)是否还有子结点,如果没有,查找table的下一个元素【(next = t[index++]) == null】; //如果有,则先把next单链表中的所有结点先遍历出来 if ((next = (current = e).next) == null && (t = table) != null) { do {} while (index < t.length && (next = t[index++]) == null); } return e; } }
最后,看回toString()方法对iterator()的调用,该方法实现了对迭代器EntryIterator的获取和使用,通过该迭代器遍历获取了map中的底层数组table中的所有非空值(即:[1=11, 2=22, 3=33])
public String toString() {
//获取迭代器EntryIterator
Iterator<E> it = iterator();
//判断EntryIterator中赋值的当前元素(EntryIterator中的next)是否为空
if (! it.hasNext())
return "[]";
StringBuilder sb = new StringBuilder();
sb.append('[');
//通过迭代器EntryIterator遍历map的底层数组table中的非空值
for (;;) {
//获取迭代器中赋值的当前元素next
E e = it.next();
sb.append(e == this ? "(this Collection)" : e);
//如果当前元素next为空,则结束遍历
if (! it.hasNext())
return sb.append(']').toString();
//否则拼接,后继续遍历
sb.append(',').append(' ');
}
}
总结,由于第一次做这么多源码分析,表达得也不好,望读者谅解,分析不对之处还望斧正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号