记录一次生产环境服务无响应问题
问题描述
最近公司某app后台服务器经常请求无响应三番五次需要重启,时间间隔没规律白天晚上均有可能。由于日志信息并没有异常信息,且没有足够时间排查,故一直都是临时重启处理。
排查经过
这个问题终于到了不得不解决的时候,于是花了很长时间去排查。
-
先前已经排查过log日志并没有提供有用的异常信息。
-
通过修改nginx负载均衡配置临时隔离出一台服务器以便排查使用,另一台重启以便业务正常使用。
-
来到隔离的服务器,先是用top指令观察了下,cpu及内存非常正常且十分充裕。
-
通过jcmd查看,应用正常运行。
-
这时只能通过 jstack -l pid >> pid.log 导出线程信息看看服务到底在搞什么鬼。
-
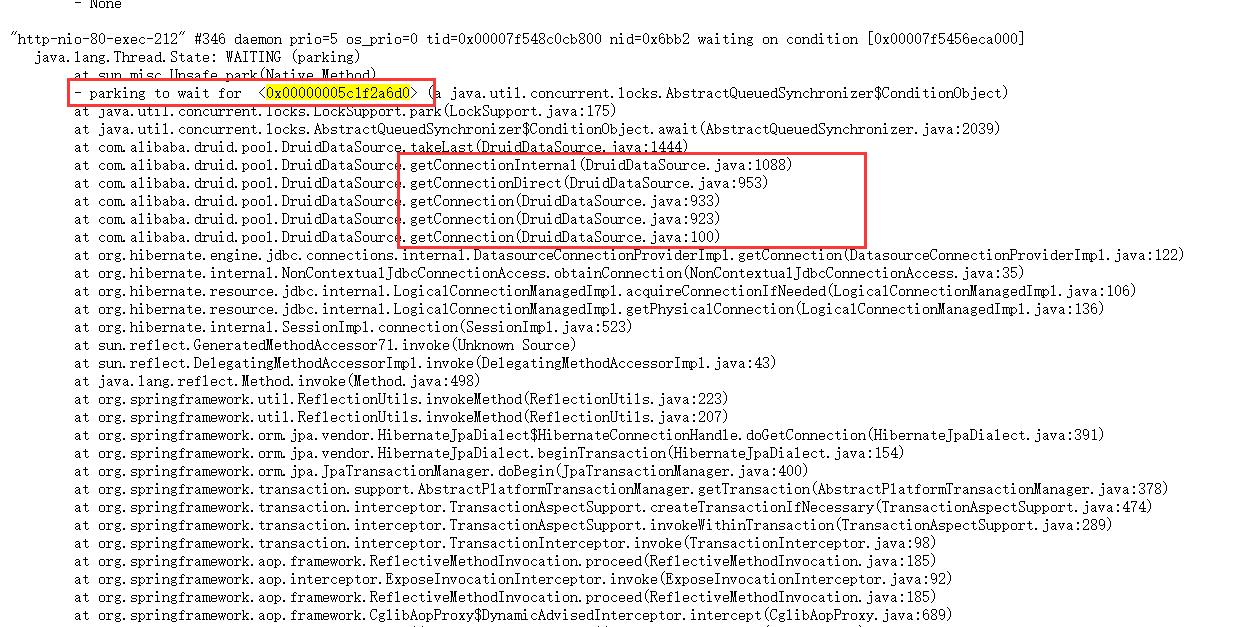
导出来的线程信息文件内容比较多,耐心看发现所有"http-nio-80-exec-***"线程都在parking to wait for某一个锁,搜索了下共193处。这也是服务没有响应的原因,因为所有链接都处于wait状态,从线程信息中可以看出是停在了获取数据库链接的地方。
![]()
-
再查看了RUNNABLE状态的线程信息发现共有8处都停留再了执行sql语句的地方,查看了项目配置发现并没有配置数据库连接池大小所以根据源码默认的大小为8。刚好对应上面8处RUNNABLE状态线程。也就是说这8处占用了所有的数据库连接并没有归还导致其它请求获取不到数据库连接一直处于等待状态,从而导致请求超时。
![]()
-
服务无响应的诱因已经找到,根据RUNNABLE状态线程的栈信息可以找到具体的业务DAO接口,这里不方便截图。
-
单从语句来看这条sql语句并没有独特的地方仅仅为普普通通的update语句。
-
于是从数据库层面入手查看正在执行的语句及事务。

SELECT
b.sid oracleID,
b.username Oracle用户,
b.serial #,
spid 操作系统ID,
paddr,
sql_text 正在执行的SQL,
b.machine 计算机名
FROM
v$process a,
v$session b,
v$sqlarea c
WHERE
a.addr = b.paddr
AND b.sql_hash_value = c.hash_value
AND b.username = 'userName';
SELECT
s.sid,
s.serial #,
s. EVENT,
a.sql_text,
a.sql_fulltext,
s.username,
s. STATUS,
s.machine,
s.terminal,
s.program,
a.executions,
s.sql_id,
p.spid,
a.direct_writes
FROM
(
SELECT
*
FROM
v$session
WHERE
STATUS = 'ACTIVE'
) s
LEFT JOIN v$sqlarea a ON s.sql_id = a.sql_id
INNER JOIN v$process p ON s.paddr = p.addr
WHERE
s.USERNAME = 'userName'
- 执行查看执行结果,发现存在delete语句,该语句没有提交事务导致业务中的update语句无法提交。
- 杀掉正在执行的语句试试(ps:这里自己要判断下能不能杀,不要乱杀)
alter system kill session 'sid,serial#';
- 过一会儿发现又出现了。与同事沟通得知存在定时同步数据的任务在执行,由于环境变迁导致这个任务执行不下去。于是涉及这块数据的业务语句就执行不下去了。刚好前段时间发布一版app引导用户修改与这相关的业务。
- 到这前因后果都清楚了。
结语:排查问题的经过挺有意思,一步一步抽丝剥茧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号