

一、基本概念
1.数据库系统DBS:是一个采用了数据库技术,有组织地、动态地存储大量相关数据,方便多用户访问的计算机系统,组成部分:数据库、硬件、软件、人员
2.数据库管理系统DBMS的功能:实现对共享数据有效的组织、管理和存取;包括数据定义、数据库操作、数据库运行管理、数据库的建立和维护等
二、三级模式-两级映像
1.内模式:管理如何存储物理的数据,对应具体物理存储文件
2.模式:又称为概念模式,根据应用、需求将物理数据划分成一张张表
3.外模式:对应数据库中的视图这个级别,将表进行一定的处理后,再提供给用户使用
4.外模式-模式映像:是表和视图之间的映射,存在于概念级和外部级之间,若表中数据发生了修改,只需要修改此映射,而无需修改应用程序
5.模式-内模式映像:是表和数据的物理存储之间的映射,存在于概念和内部级之间,若修改了数据存储方式,只需要修改此映射,而不需要去修改应用程序
三、数据库设计
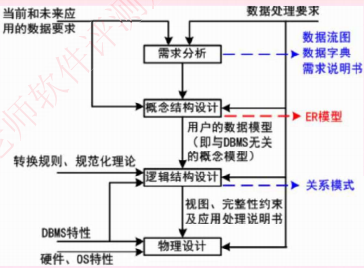
1.需求分析:分析数据存储的要求,产出物有数据流图,数据字典、需求说明书
2.概念结构设计:就是设计E-R图,实体-属性图,与物理实现无关,说明有哪些实体,实体有哪些属性
3.逻辑结构设计:将ER图,转换成关系模式,也即转换成实际的表和表中的列属性,这里要考虑很多规范化的东西
4.物理设计:根据生成的表等概念,生成物理数据库
四、E-R模型
1.数据模型三要素:数据结构、数据操作、数据的约束条件
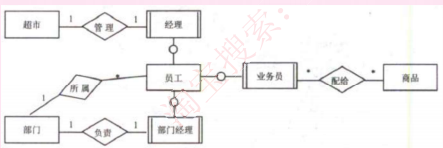
2.E-R模型:即实体-联系模型,使用椭圆表示属性,长方形表示实体,菱形表示联系、联系两端要标志联系类型
3.联系类型:一对一1:1、一对多1:n、多对多m:n
4.属性分类:简单属性和复合属性、单值属性和多值属性,Null属性、派生属性
五.模型转换
1.E-R转换为关系模型,每个实体都对应一个关系模式,联系分为三种
2.1:1联系中,可以放到任意的两端实体,作为一个属性
3.1:n中,必须作为一个单独的关系模式,其主键就是M和N端的联合主键
4.M:N中,必须作为一个单独的关系模式,其主键是M和N段的联合主键
六.关系代数运算
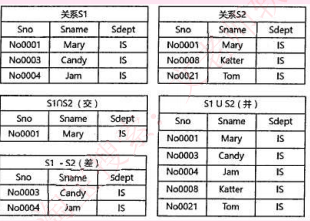
1.并:结果是两张表中所有记录数合并,相同记录只显示一次
2.交:结果是两张表中相同的记录
3.差s1-s2,结果是s1表中有而S2表中没有的那些记录
七、关系代数运算
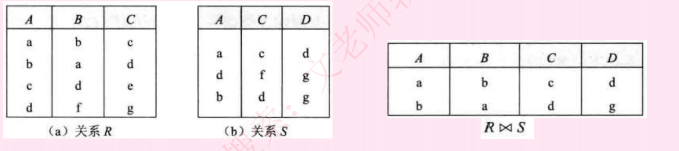
1.笛卡尔积:S1*S2,产生的结果包括S1和S2的所有属性列,并且S1中每条记录依次和S2所有记录组合成一条记录,最终属性列为S1+S2属性列,记录数为S1*S2记录数
2.投影:实际是按条件选择某关系模式中的某列,列也可以用数字表示
3.选择:实际是按条件选择某关系模式中的某条件记录

4.自然连接的结果显示全部的属性,但是属性列只显示一次,显示两个关系模式中属性相同且值相同的记录
5.设有关系R、S如下左图所示,自然连接结果如右下图所示

八、函数依赖
1.给定一个X,能唯一确定一个Y,就称X确定Y,或者说Y依赖于X,列如Y=X*X函数
2.函数依赖可扩展一下两种规则:
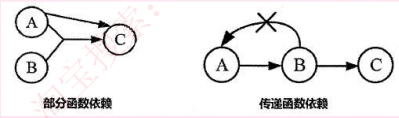
部分函数依赖:A可确定C,A、B也可确定C,A、B中的一部分即A可以确定C,称为部分函数依赖
传递函数依赖:当A和B不等价时,A可确定B,B可确定C,则A可确定C,是传递函数依赖,若A和B等价,则不存在传递,直接就可确定C
九、键与约束
1.超键:能唯一标识此表的属性和组合
2.候选键:超键中去掉冗余的属性,剩余的属性就是候选键
3.主键:任选一个候选键,即可作为主键
4.外键:其他表中的主键
5.主属性:候选键内的属性为主属性,其他属性为非主属性
6.实体完整性约束:即主键约束,主键值不能为空,也不能重复
7.参照完整性约束:即外键约束,外键必须是其他表中已经存在的主键的值,或者为空
8.用户自定义完整性约束:自定义表达式约束,如设定年龄属性值必须是0-150
十、第一范式
1.第一范式,关系总的每一个分量必须是一个不可分的数据项,通俗地说,第一范式就是表中不允许有小表的存在
十一、第二范式
1.如果关系R属于1NF,且每一个非主属性完全函数依赖任何一个候选码,则R属于2NF
2.通俗地说,2NF就是在1NF的基础上,表中的每一个非主属性不会依赖复合主键中的某一个列
十二、第三范式
1.在满足2NF的基础上,表中不存在非主属性对码的传递依赖
十三、BC范式
1.BC范式,是指在第一范式的基础上进一步消除主属性对码的部分函数依赖和传递依赖,通俗的来说,就是在每一种情况下 ,每一个依赖的左边决定因素都必然包含候选键
十四、模式分解
1.范式之间的转换一般都是通过拆分属性,即模式分解,将具有部分函数依赖和传递依赖的属性分离出来,达到一步步优化,一般分为以下两种:
保持函数依赖
对于关系模式R,偶依赖集F,若对R进行分解,分解出来的多个关系模式,保持原来的依赖集不变,则为保持函数依赖的分解,另外,注意要消除冗余依赖(传递依赖)
2.无损分解:分解后的关系模式能够还原出原关系模式,就是无损分解,不能还原就是有损
3.当分解为两个关系模式,除了表格法外,还可以通过定理判断
定理:如果R的分解为p={R1,R2},F为R所满足的函数依赖集合,分解P具有无损连接性的充分必要条件R1^让->(R1-R2)或者R1^R2->(R2-R1)
十五、事务管理
1.事务提交commit,事务回滚rollback
2.事务:由一系列操作组成,这些操作要么全做,要么全不做,拥有四种特性
原子性:要么全做,要么全不做
一致性:事务发生后数据是一致的,如银行转账,不会存在A账户转出,B账户没有收到钱
隔离性:任何事务的更新操作直接到其成功提交的整个过程对其事务都是不可见的,不同事务之间是隔离的,互不干涉
持续性:事务操作的结果是持续性的
十六、并发控制
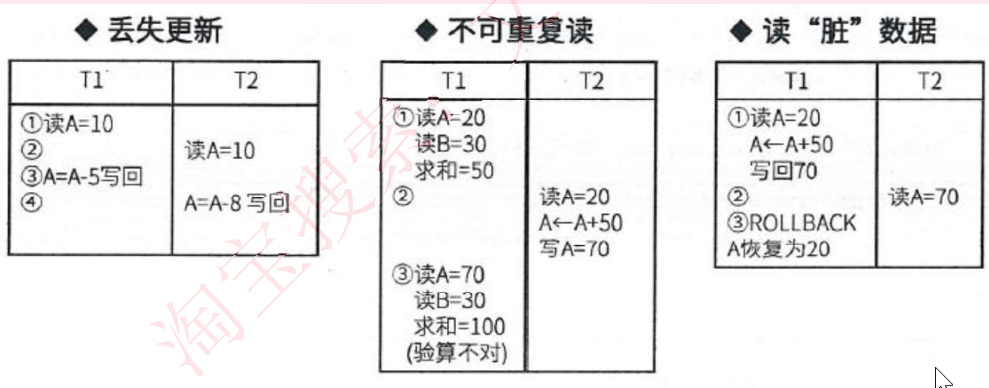
1.事务是并发控制的前提条件,并发控制就是控制不同的事务并发执行,提高系统效率,但是并发控制存在下面三个问题:丢失更新、不可重复读、读脏数据
十七、封锁协议
1.S锁是共享锁(读锁),若事务T对数据对象A加上S锁,则只允许T读取A,但不能修改A,其他事务只能对A加S锁(不能读也不能修改),知道T释放A上的S锁
2.一级封锁协议:事务在修改数据R之前必须对其加X锁,直到事务结束才释放,可解决丢失更新问题
3.二级封锁协议:一级封锁协议的基础上加事务T在读数据R之前必须先对其加S锁,读完后即可释放S锁,可解决丢失更新、读脏数据问题
4.三级封锁协议:一级封锁协议加事务T在读取数据R之前先对其加S锁,知道事务结束才释放。可解决丢失、更新、读脏数据、数据重复问题
十八、数据库安全
1.安全措施和级别

十九、数据库安全
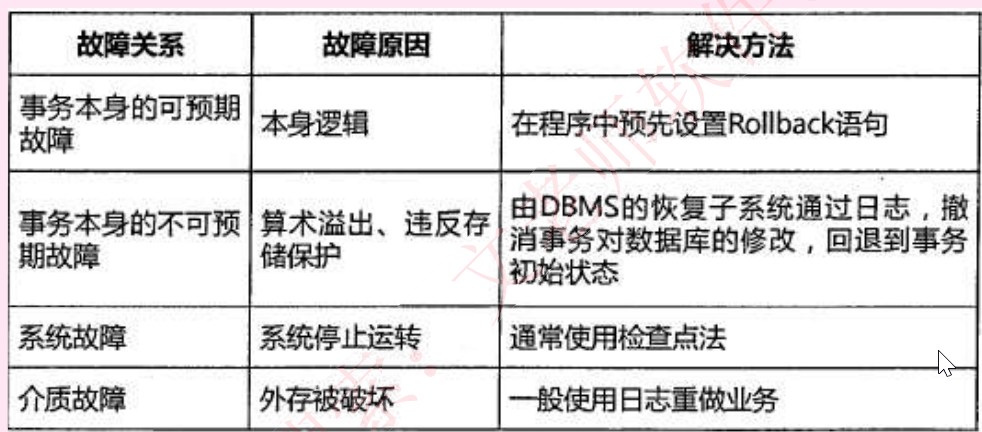
1.数据故障
二十、数据库备份
1.静态转储:即冷备份,指在转储期间不允许对数据库进行任何存取,修改操作
2.优点是非常快速的备份方法,容易归档
3.缺点是只能提供到某一时间点上的恢复,不能做其他工作,不能按表或按用户恢复
4.动态转储:即热备份,在转储期间允许对数据库进行存取,修改操作,因此,转储和用户事务科并发执行
5.优点是可在表空间或数据库文件级备份,数据库仍可用,可达到秒级恢复
6.缺点是不能出错,否则后果严重,若热备份不成功,所得结果几乎全部无效
7.完全备份:备份所有数据
8.差量备份:仅备份上一次完全备份之后变化的数据
9.增量备份:备份上一次备份之后变化的数据
10.日志文件:在事务处理过程中,DBMS把事务开始、事务结束以及对数据库的插入、删除和维修的每一次操作写入日志文件,一旦发生故障,DBMS的恢复子系统利用日志文件撤销事务对数据库的改变,回退到事务的初始状态
二十一、分布式数据库
1.分布式数据库:局部数据库位于不同的物理位置,使用一个全局DBMS将所有局部数据库联网管理

2.分片模式:
水平分片:将表中水平的记录分别存在不同的地方
垂直分片:将表中的垂直列值分别存放在不同的地方
3.分布透明性
分片透明性:用户或应用程序不需要知道逻辑上访问的表具体是如何分块存储的
位置透明:应用程序不关系数据存储物理位置的改变
逻辑透明:用户或应用程序无需知道局部使用的是哪种数据模型
复制透明性:用户或应用程序不关心复制的数据从何而来
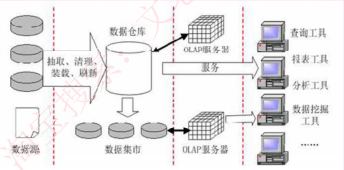
二十二、数据仓库
1.数据仓库是一种特殊的数据库,也是按数据库形式存储数据的,数据仓库的目的不是为了应用,是面向主题的,用来做数据分析,是相对稳定的,一般不会做修改,同时会在特定的时间点做大量的插入,反映历史的变化
二十三、数据挖掘
1.关联分析:用于发现不用事件之间的关联性,即一个事件发生的同时,另一个事件也经常发生
2.序列分析:序列分析主要用于发现一定时间间隔内接连发生的事件,这些事件构成一个序列,发现的徐磊应该㕛普遍意义
3.分类分析:分类分析通过分析具有类别的样本特点,得到决定样本属于各种类型的规则或方法,分类分析时首先为每一个记录赋予一个标记,即按标记分类记录,然后检查这些标定的记录,描述出这些记录的特点
4.聚类分析:聚类分析时根据“物以类聚”的原理,将本身没有类别
二十四、商业智能
1.BI系统主要是包括数据预处理、建立数据仓库、数据分析和数据展现四个阶段
2.数据预处理是整合企业原始数据的第一步,包括数据的抽取、转换和加载
3.家里数据仓库则是处理海量数据的基础
4.数据分析是体现系统智能的关键,一般采用联机分析处理(OLAP)和数据挖掘两大技术,联机分析处理不仅进行数据汇总/聚集,同时还提供切片、切块、下钻、上卷的旋转等数据分析功能,用户可以方便的对海量数据进行多维分析,数据挖掘的目标是挖掘数据背后隐藏的知识,通过关联分析、聚类和分类等方法建立分析模式,预测企业未来发展趋势和将要面临的问题
5.海量数据和分析手段增多的情况下,数据展现则主要是保障系统分析结果的可视化
二十五、反规范化技术
1.技术手段:增加派生性冗余列、增加冗余列,重新组表、分割表
2.主要就是增加冗余、提高查询效率,为规范化操作的逆操作
二十六、大数据
1.特点:大量化、多样化、价值密度低、快速化
2.大数据和传统数据的比较

3.集成平台 大数据处理系统特征:高度可扩展性、高性能、高度 容错、支持异构环境、较短的分析延迟,易用且开放的接口、较低成本、向下兼容
二十七、SQL语言




