《kafka权威指南》阅读笔记——第1章 初识kafka
Kafka一般被称为“分布式提交日志”或者“分布式流平台”。文件系统或数据库提交日志用来提供所有事务的持久记录,通过重放这些日志可以重建系统的状态。同样地,Kafka的数据是按照一定顺序持久化保存的,可以按需读取。此外,Kafka的数据分布在整个系统里,具备数据故障保护和性能伸缩能力。
1.2.1 消息和批次
Kafka的数据单元被称为消息。为了提高效率,消息被分批次写入Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果每一个消息都单独穿行于网络,会导致大量的网络开销,把消息分成批次传输可以减少网络开销。不过,这要在时间延迟和吞吐量之间做出权衡:批次越大,单位时间内处理的消息就越多,单个消息的传输时间就越长。
1.2.2 模式
消息模式有许多可用的选项,像JSON和XML,易用可读性好,但缺乏强类型处理能力,版本间兼容性也不是很好。
数据格式的一致性对于Kafka来说很重要,它消除了消息读写操作之间的耦合性。如果读写操作紧密的耦合在一起,消息订阅者需要升级应用程序才能同时处理新旧两种数据格式。在消息订阅者升级了之后,消息发布者才能跟着升级,以便使用新的数据格式。
1.2.3 主题和分区
Kafka的消息通过主题进行分类。主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
Kafka通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。

流是一组从生产者移动到消费者的数据。
1.2.4 生产者和消费者
Kafka的客户端被分为两种基本类型:生产者和消费者。此外还有高级客户端API,用于数据集成的Kafka Connect API和用于流式处理的Kafka Streams。
偏移量是一种元数据,它是一个递增的整数值,保存在Zookeeper或Kafka上,消费者关闭或者重启,读取状态不会丢失。
消费者是消费者群组的一部分,也就是说,会有一个或者多个消费者共同读取一个主题。群组保证每个分区只能被一个消费者使用,消费者与分区之间的映射通常被称为消费者对分区的所有权关系。通过这种方式,消费者可以消费包含大量消息的主题。而且,如果一个消费者失效,群组里的其他消费者可以接管失效消费者的工作。

1.2.5 broker和集群
一个独立的Kafka服务器被称为broker。根据特定的硬件及其性能特征,单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker是集群的组成部分。每个集群都有一个broker同时充当了集群控制器的角色。控制器负责管理工作,包括将分区分配给broker和监控broker。在集群中,一个分区从属于一个broker,该broker被称为分区的首领。一个分区可以分配给多个broker,这个时候会发生分区复制。这种复制机制为分区提供了消息冗余,如果一个broker失效,其他broker可以接管领导权。不过,相关的消费者和生产者都需要重新连接到新的首领。
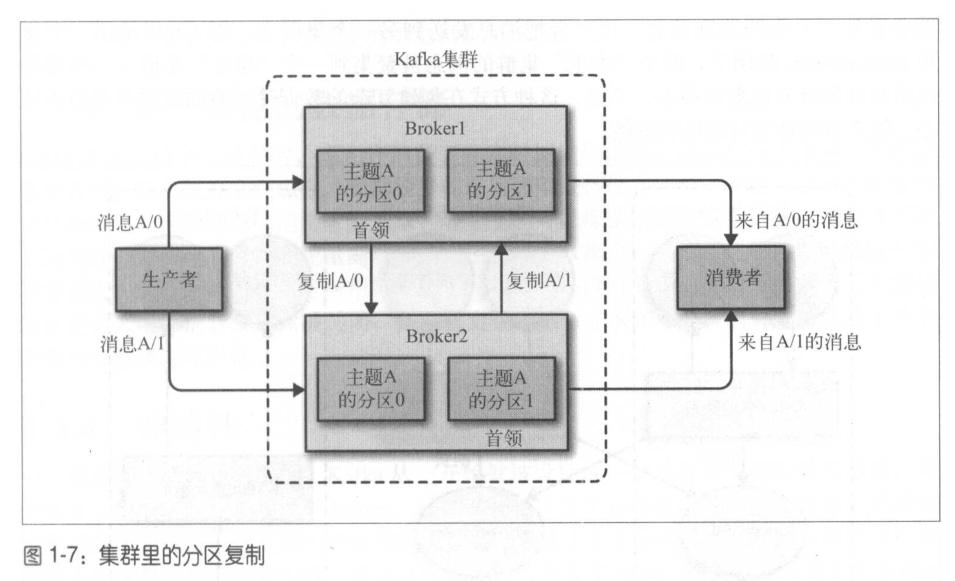
保留消息(在一定期限内)是Kafka的一个重要特性。Kafka broker默认的消息保留策略:要么保留一段时间(比如7天),要么保留到消息达到一定大小的字节数(比如1GB)。当消息数量达到这些上限时,旧消息就会过期并删除。主题可以配置自己的保留策略,可以将消息保留到不再使用它们为止。
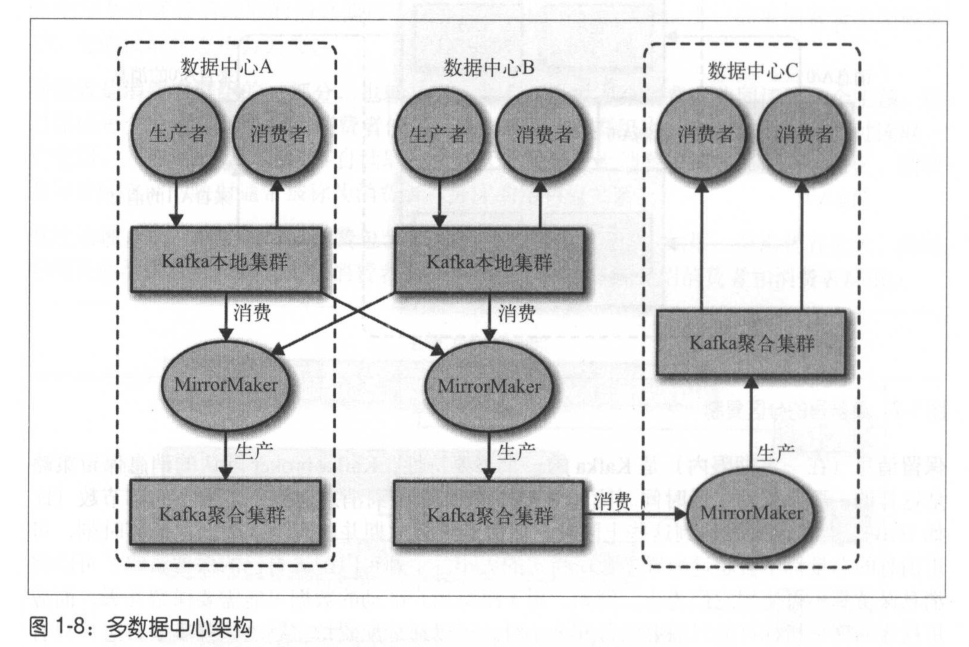
1.2.6 多集群
基于以下原因,最好使用多个集群。
- 数据类型分离
- 安全需求隔离
- 多数据中心(灾难恢复)
Kafka的消息复制机制只能在单个集群里进行。Kafka提供了一个MirrorMaker的工具,可以用来实现集群间的消息复制。MirrorMaker的核心组件包含了一个生产者和一个消费者,两者通过一个队列相连。
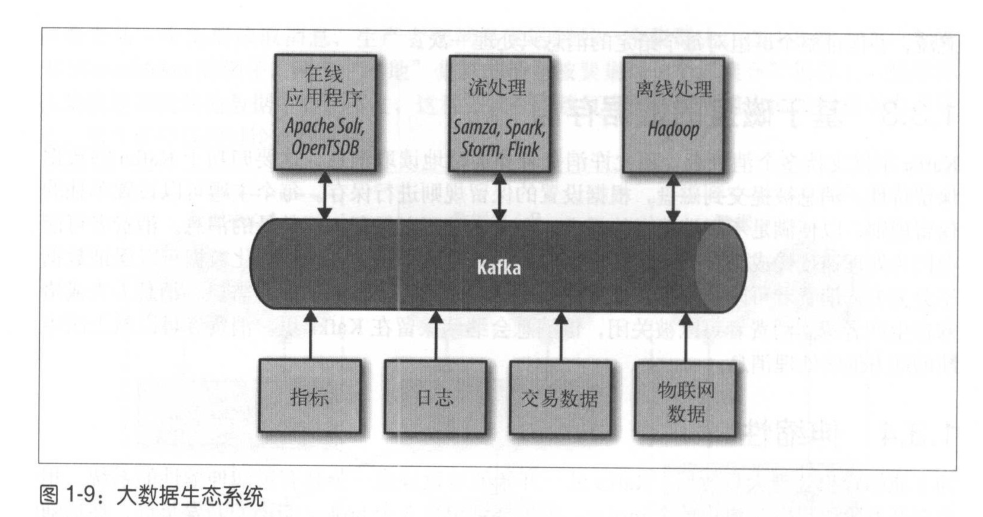
使用场景:1,活动跟踪;2,传递消息;3,度量指标和日志记录;4,提交日志;5,流处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号