
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践/S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 学会使用git和GitHub 重新复习好Java语言基础知识,完成WordCount编程 学会对自己的代码进行单元测试以及性能分析 |
| 其他参考文献 | [第二届构建之法论坛] 预培训文档(Java版) 0基础的git教程 Mac Intellj idea 修改jvm参数 廖雪峰的git教程 正则表达式 ... |
任务一:阅读《构建之法》并提问
一、提出问题(讲义)
问题 1
- 在第五章团队中的角色和合作中提到“开发项目的时候才觉得实际情况和书上讲的都有一些出入,偏偏一些重要的出入书上没有提。我们很多人是边看asp.net的书, 边开发asp.net的项目,这相当于一边看医学书一边动手术。”
- 在我看来这个是初期项目开发者都会遇到的问题,其实在一定程度上确实影响了自身的开发效率,那面对这样的情况应该要怎么处理呢?同时技术是不断的革新的,所以就算技术有一定的长进在日后的开发过程中这样的情况应该也是没法避免的。
- 我的观点是:其实在我看来,就目前的我们来说基本上都是处于边学边开发的情况,前期效率低一点应该是无伤大雅的,在不断的学习过程中增长自己技术,从而也会在学习的过程中不断的提高自己学习新知识的能力,这样学习效率就会提高,从而开发效率也会进一步的提高。
问题 2
- 在第五章的团队不同的投入中作者提到团队中有一类人为
鹦鹉:“他们有漂亮的羽毛,,能说会道,联系广泛,能提出很多建议,很多点子但是他们不执行,除了一些人云亦云的观点和一些关于架构的空谈之外,他们没有其他投入,一旦项目失败, 他们就会飞到另一个项目中去。” - 这种类型在团队其实是很影响队员效率的,那应不应该适当的提醒她呢?或者应该怎么处理这样的情况呢?
- 我的观点是:假设他完全不了解项目,对于不认可的观点不予理会就好,不要被他左右,这样也不会影响自己的项目进度;如果她有一定了解的话,又或许在旁观者的角度可以提出我们核心人员不一样的观点。在我自己的项目经历中,我们的产品是在每次迭代更新的时候都需要有一些新的点子,对于已经特别熟悉项目的开发人员来说就已经想不出什么好的点子了,所以这个时候我就会去询问身边人的意见,在第一次看我们的产品时有什么建议,我想这个也是“鹦鹉”这个角色的存在意义吧。
问题 3
- 在第九章创新方面作者提到了两种如何在一个创新性的市场上后来居上的观点,分别是“改变游戏规则”和“转换目标用户”。
- 其实我认为“居上”最多也就是几乎齐头并进,但是还是无法超越之前的产品,这样的想法是否正确呢?
- 对于这个观点,我觉得最好的例子就是拼多多的崛起,在淘宝已经占据了绝大部分市场份额的时候,拼多多以一个“砍一刀”的规则重新进入了大众的视野,同时商品定位比较亲民,他利用了大众心理制定的政策,果不其然,确实很成功。同时,在后续的使用过程中我们也先后发现了其他app也出现过类似的板块。这其实就正好契合作者所提到的这两个创新的办法,但是在市场上看淘宝还是大部分用户的第一选择,因为前者可以向新的创意学习,可能两者的起点就是不同,但是不可否定的是拼多多的创新确实做的很成功。
问题 4
- 在第七章设计阶段分析中作者提到对于需求分析不应该条条框框的完成需求内的要求,但是也不可以一味追求“最大的扩展性”。
- 所以在需求分析和设计的时候我们应该保留什么样的弹性呢?
- 我思考了一下之前的项目开发经历好像基本上主要还是条条框框的按照功能需求去完成了,没有过多的去考虑比如性能方面的问题,感觉在接下来的实践中应该更加注重一点拓展性的考虑。
问题 5
- 在七章开发阶段的日常管理中作者提到“要尽量减少非开发时间,不要动不动就开“全体会议”。团队成员们自我时间管理也很重要。”
- 这个全体会议其实是很经典的问题,感觉其实当团队积极参与度不高的时候,全体会议就显得很没有效率,但是有时候又是必要的需要告知大家,或者希望大家参与讨论,应该怎么处理呢?
- 我的观点是在一些重要的开发节点可以和队友集中讨论,有的仅需要部分队员悉知的只要小范围讨论这样效率更高,一些简短的公告可能以文字的形式提醒会更有效率。
二、附加题:冷知识
在程序中bug一词用于技术错误。这一术语最初由爱迪生在1878年提出的,但当时并没有流行起来。在这的几年之后,美国上将Grace Hopper在她的日志本中,写下了她在Mark II电脑上发现的一项bug。不过实际上,她说的真的是“虫子”问题,因为一只蛾子被困在电脑的继电器中,导致电脑的操作无法正常运行。她写道“这是我在电脑上发现的第一个bug”。
在现在看来,在开发的过程中这个“虫子”倒也是最令人头疼的问题...感觉这个文章的冷知识都写的挺有趣!
参考文献:作为程序猿必须知道的十条冷知识
任务二:WordCount编程
一、项目Github地址
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 20 | 35 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 240 |
| • Design Spec | • 生成设计文档 | 30 | 45 |
| • Design Review | • 设计复审 | 15 | 10 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 35 | 40 |
| • Coding | • 具体编码 | 300 | 370 |
| • Code Review | • 代码复审 | 30 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 100 | 170 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 90 | 120 |
| • Size Measurement | • 计算工作量 | 10 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 40 | 45 |
| 合计 | 850 | 1150 |
三、解题思路描述
1、git初使用
阅读了一边作业需求后,首先要做的就是对git的使用和学习,首先由于原先没有具体使用过GitHub,刚刚开始入手学习的时候还是有一点吃力,主要是详细阅读了廖雪峰的git教程以及查阅各种资料熟悉git的使用方法,然后根据作业的步骤一步一步了解相关指令完成基础的git使用的学习,这样项目才开始步入正轨,最后在使用中感觉教程中所推荐的SourceTree软件来进行文件的管理和提交很便捷,使用的时候不用通过再命令行指令操作,更加方便。
2、WordCount编码思路
- 在阅读了项目需求后首先先确定了一下自己所要使用的语言,感觉Java语言对字符串的处理更加灵活,所以最后使用了Java语言来编写。
- 接下来总结该项目主要需要实现一下功能:
- 要实现文件的读写功能;
- 统计文件字符数;
- 统计文件的单词总数;
- 统计文件的有效行数;
- 统计文件中各单词的出现次数。
- 同时,在作业中提示到一个好的项目应该实现接口的封装,所以我就思考可以根据功能对功能进行划分,封装成IO工具类以及统计工具类,主程序单独用一个类进行测试,来编写程序。
- 接下来就是根据划分好的模块,开始逐步编写上述的功能。
四、代码规范制定链接
五、设计与实现过程
1、类的设计
- 首先,设计了对IO读写进行了封装,实现两大功能:
- 实现从文件中读取字符流并转化为字符串存储,这样更加方便后续对文件中的数据进行统计,以字符流进行读取则保证了计数的正确性;
- 实现将结果输出到文件的功能,参数中的数据主要通过计数工具类中的计数方法获取得到。
/* IO工具 */
public class IOTool {
/* 从文件读取字符流 */
public StringBuilder fileInputToString(String filePath) throws IOException {}
/* 将结果输出到文件中 */
public void OutputToFile (String filePath, int sumCharacter, int wordsNum, int lines, List<Map.Entry<String,Integer>> list) throws IOException {}
}
- 接下来对计数的功能封装成
CountTool类,来实现对文件中的数据的统计。
其中在编写代码的过程中,统计单词数和统计频次部分都需要对字符串进行相同的处理(筛选出有效的单词,加入字符数组),所以为了提高代码的重用性将该功能单独写成一个方法。
/* 用于字符统计工具 */
public class CountTool {
/* 统计总字符数 */
public int characterCount(StringBuilder str) {}
/* 统计单词数 */
public int wordsCount(StringBuilder str) {}
/* 转化成小写且用空格分割字符串,返回字符串数组 */
public String[] changeStr(StringBuilder str) {}
/* 统计有效行 */
public int invaluableLines(String filePath) throws IOException {}
/* 统计单词频次 */
public HashMap<String, Integer> wordsSortCount(StringBuilder str) {}
/* 对哈希表进行排序 */
public List<Map.Entry<String,Integer>> sortMap(HashMap<String,Integer> map) {}
}
- 两个类之间函数的关系如下:
- 首先,通过IO类中的
fileInputToString方法从文件中读取字符流转化为StringBuilder类型的字符串; - 然后将字符串传入计数工具类中的各个方法进行统计,并返回结果;
- 最后将统计结果通过参数传入
OutputToFile方法,输出到文件。
- 首先,通过IO类中的
2、关键性函数的具体实现思路
- IO方面
(1)为了统一文件的编码为UTF-8,在编写文件字符流的读写的时候,注意设置了编码格式。
//UTF-8编码进行读取
FileInputStream file = new FileInputStream(filePath);
InputStreamReader reader = new InputStreamReader(file,"UTF-8");
(2)同时,在输出的时候将String类型转码成UTF-8格式进行输出
//转码成UTF-8
String context = "..."
...
byte[] bytes = context.getBytes("UTF-8");
file.write(bytes);
- 统计方法实现
(1)统计文件的字符数
根据题目要求“只需要统计Ascii码,汉字不需考虑”,刚刚开始编写的时候想的还复杂了,还将字符串转化为字符数组,然后遍历累加计算字符数,在调试的时候发现,上述的代码是多余的,其实总数就是按字符流读取后返回字符流的长度。所以仅需要以下语句即可以实现计数功能:
/* 统计总字符数 */
public int characterCount(StringBuilder str) {
//返回字符流的个数
return str.length();
}
(2)统计文件的单词总数
该功能最关键的就是在于如何从字符串当中提取有效的单词,并将它进行分割计数,刚刚开始对于有效单词的筛选感觉实现起来有点复杂,在构思的时候感觉有好几个if语句在脑海里闪过,感觉很容易判断出错。
后来,在同学的提点下知道可以使用正则表达式去筛选满足要求的字符串,由于之前对该知识还没有使用过,于是就查阅了正则表达式的资料,得出正确的单词形式应该满足正则表达式为[a-z]{4}[a-z0-9]*。
最后功能的实现思路如下:
由于最后输出的形式为小写,所以第一步先把字符串全部转化为小写;
接下来用正则表达式[^a-z0-9]将不是字母和数字的符号都换成空格;
然后利用split方法,以空格为分割符号把字符串进行分割;
最后就用有效单词的正则表达式对进行筛选和统计即可。
(展示对字符串进行处理的方法,该方法词频统计也需要使用到)
/* 转化成小写且用空格分割字符串,返回字符串数组 */
public String[] changeStr(StringBuilder str) {
//转化为小写
String result = str.toString().toLowerCase();
//利用正则表达式筛选出不是数字和字母的符号,转化为'.'
String regex = "[^a-z0-9]";
result = result.replaceAll(regex, " ");
//用空格来分割单词
String[] resultArray = result.split(" ");
return resultArray;
}
(3)统计文件中各单词的出现次数
单词的词频统计关键也是在于分割单词并存储,所以和上述统计单词数的方法一样也是先调用changeStr方法来分割单词,由于是键值对的形式所以使用HashMap来存,然后就是理清修改HashMap的值和加入新的键值对的逻辑。
在调试的时候发现在这里两次出现了逻辑错误,主要就是对是否加入哈希表判断位置出错。
(4)有效行的统计
由于要对行进行统计,所以读取字符流就判断起来就有点繁琐,所以在该方法又重新按行从文件中读取数据,再次利用正则表达式\\s*判断该行是不是空白行,再进行记录。
//记录有效行数(任何包含非空白字符的行,都需要统计)
//利用正则表达式指代空白字符
String regex = "\\s*";
//统计行数
while ((line = br.readLine()) != null) {
sumLines++;
//判断是不是空白字符行
if (line.matches(regex)) {
sumLines--;
}
}
六、性能改进
1、拼接字符串性能提升
因为程序需要对字符串进行拼接,在测试中发现利用StringBuilder进行字符串的拼接会对程序的性能有一定程度的提升,同时主要是当时测试的时候跑10000字符的数据,出现了内存溢出的现象,所以对数据类型把数据类型从StringBuffer改成了StringBuilder,同时也测试了直接用String的方法,同样的数据已经跑不动了,电脑的风扇不停转,显然性能太差。
最后用测试跑10w字符的项目时间大约在500ms左右。
2、IO操作
如果多次对文件进行读取会影响程序的性能,所以程序对IO工具进行了封装,读取一次文件转化成字符串,其他函数直接对字符串处理会大大提高程序的效率,但是由于编写的读文件的功能是按字符流读取,所以在计算有效行的方法上就不太方便,所以在计算有效行的时候,我又按行读取了一次文件。感觉对性能会有影响,但是目前还没想到怎么直接用字符串判断有效行的方法。
/* 统计有效行 */
public int invaluableLines(String filePath) throws IOException {
//UTF-8编码进行读取
FileInputStream file = new FileInputStream(filePath);
InputStreamReader reader = new InputStreamReader(file, "UTF-8");
BufferedReader br = new BufferedReader(reader);
...(具体实现)
}
七、单元测试
1、字符统计测试
主要是为了测试在大数据情况下程序性能和正确性,同时在测试的字符串中加了很多符号来判断代码的正确性。
@org.junit.Test
public void characterCount() {
String str = "shjdu\t\r\nhsj[]ks";
StringBuilder strTest = new StringBuilder();
for (int i = 0; i < 10000000; i++) {
strTest.append(str);
}
CountTool count = new CountTool();
int result = count.characterCount(strTest);
Assert.assertEquals(result,str.length()*10000000);
}
2、单词数统计测试
@org.junit.Test
public void wordsCount() {
//有5个合法的单词
String str = "aaa=-aAaa123 kkkk12??\n\taaaa12?\rfile?123file\naaAaa123";
StringBuilder strTest = new StringBuilder();
for (int i = 0; i < 10000; i++) {
strTest.append(str);
}
CountTool count = new CountTool();
int result = count.wordsCount(strTest);
Assert.assertEquals(result,50000);
}
测试结果
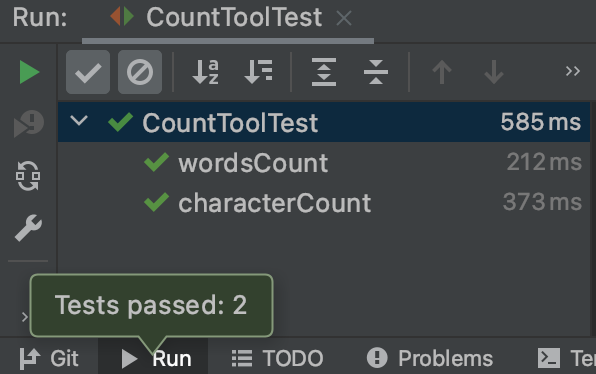
3、行数和词频测试
因为行数需要传入文件,以及词频是显示输出,所以直接进行统一的测试的展示,可以看到对空行进行了忽略,同时只会展示前10的单词。
写的测试例子如下:
windows95 windows98 windows200
123file flie123
windows95 windows98][]???aaa123 file123 bbbb cccc
Dddd fffff ggggg vvvvvv fffff jjjjjj kkkkk
4、覆盖率截图
- 当测试的有效单词数未超过10个且没有空白行的时候,测试的覆盖率为98%;
- 主要是由于要求仅输出10个单词,所以加了判断语句,则未到10个的时候,则不会执行。
//判断单词数是否等于10了
if (num == 10)
break;
- 对空白行进行判断,则没有空白行的时候不会进行下述第二个语句
//判断是不是空白字符行
if (line.matches(regex)) {
sumLines--;
}
- 有效单词数超过10个的时候,且有空白行,测试覆盖率100%。
八、异常处理说明
主要的异常处理是针对文件的IO方面,系统自动抛出异常,其余就没有过多的判断。
九、心路历程与收获
首先,在看到本次作业的时候,就感觉有一点一头雾水,不知道该如何下手,在反复阅读了几遍作业要求之后,根据作业的步骤才慢慢有了思路。最难开头的还是学会对于git和GitHub的使用,因为之前都没接触过git,各种指令和安装操作有点繁琐,在操作的过程中还出现了一些问题,经过各种查资料以后才终于弄懂了git,最后在摸索中感觉SouceTree软件来管理确实很方便。同时在使用的时候也感觉到git在后续的团队项目环节也起到了很重要的作用,之前写在团队写一些小项目的时候,我和我队友也感觉人工合成项目代码实在是太繁琐并且不可取的工作了,所以对于git的学习还是受益匪浅的。
接下来就是对于项目的编写,太久没有用java了,对于有点知识点还有一点遗忘了,所以正好通过这次的项目重新复习了一遍java,也为当时对字符串这一块的学习查缺补漏了一下。
同时第一次学习对项目进行了单元测试和性能测试,在这个过程中也更加直观的感受到不同数据类型的优缺点。
这次作业虽然过程中有很多困难,但是总体来说还是收获颇丰,对项目开发有了更完善更全面的认识,也为后续的工作打好了基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号