spark[源码]-DAG调度器源码分析[二]
前言
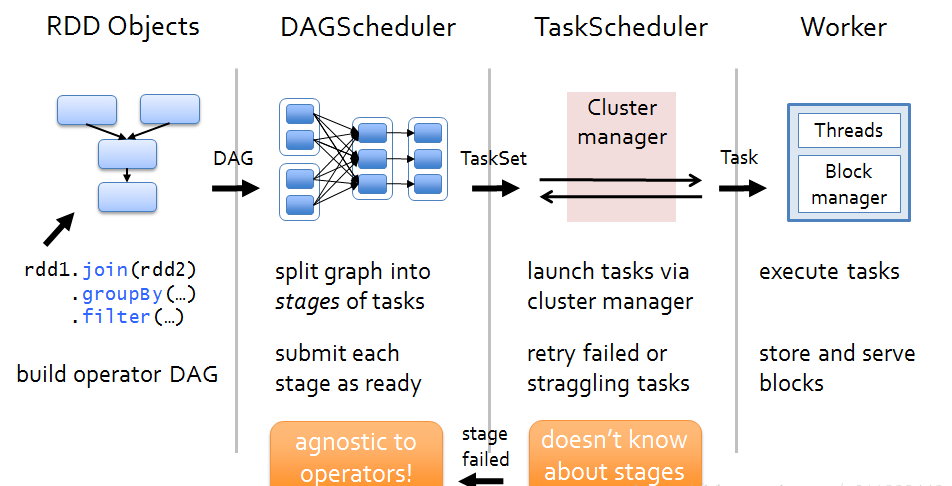
根据图片上的结构划分我们不难发现当rdd触发action操作之后,会调用SparkContext的runJob方法,最后调用的DAGScheduler.handleJobSubmitted方法完成整个job的提交。然后DAGScheduler根据RDD的lineage进行Stage划分,再生成TaskSet,由TaskScheduler向集群申请资源,最终在Woker节点的Executor进程中执行Task。
这个地方再次强调一下宽依赖和窄依赖的概念,因为这个是决定stage划分的关键所在。
窄依赖指的是:每个parent RDD 的 partition 最多被 child RDD的一个partition使用 宽依赖指的是:每个parent RDD 的 partition 被多个 child RDD的partition使用 窄依赖每个child RDD 的partition的生成操作都是可以并行的,而宽依赖则需要所有的parent partition shuffle结果得到后再进行。
接下来,Spark就可以提交这些任务了。但是,如何对这些任务进行调度和资源分配呢?如何通知worker去执行这些任务呢?接下来,我们会一一讲解。
回忆sparkcontext
是否还记得在sparkcontext初始化的时候做的操作?
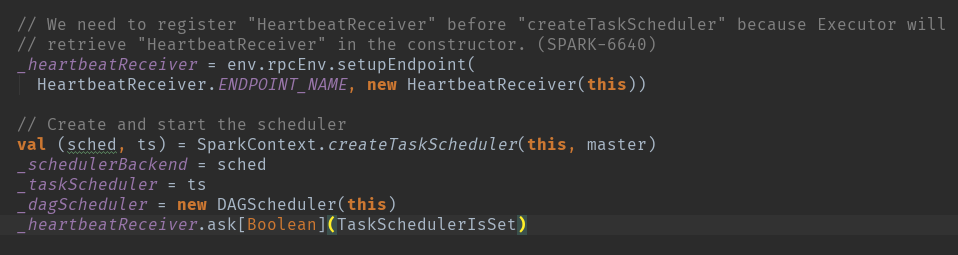
这个地方初始化了TaskScheduler,schedulerBackend,和DAGScheduler,请记住这三大关键点,还有就是为什么要先创建TaskScheduler呢?因为DAGScheduler接受的参数之一就是TaskScheduler啊,回答的没错的,是这么回事,但是具体的呢?我这里只先截图遗留一下吧。

根据源码可以看到了吧,原来在DAG一系列的操作中,最后需要调用taskScheduler的submitTasks 来提交taskSet任务集的。
rdd触发action操作
请时刻记住spark是很懒的,如果一个rdd里面没有action操作,你即使做在做的操作,但是没有action操作,对不起哥们就是不干活。lazy加载用的出神入化。
调用栈如下:
- rdd.count
- SparkContext.runJob
- DAGScheduler.runJob
- DAGScheduler.submitJob
- DAGSchedulerEventProcessLoop.doOnReceive
- DAGScheduler.handleJobSubmitted
- DAGSchedulerEventProcessLoop.doOnReceive
- DAGScheduler.submitJob
- DAGScheduler.runJob
- SparkContext.runJob
RDD的一些action操作都会触发SparkContext的runJob函数,如count()
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
通过count()这个函数我们可以发现,其调用了sparkContext中的runJob函数。
new DAGScheduler()
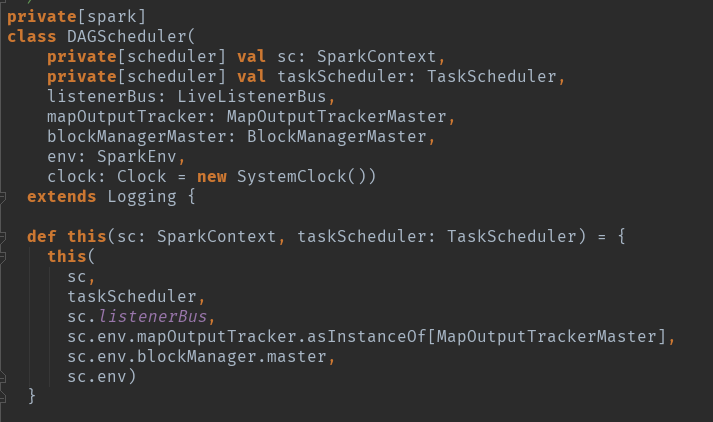
这个地方做的是DAG的初始化,这里面有个比较重要的初始化参数。
在sparkContext创建DAG的时候。DAG初始化eventProcessLoop变量:
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
在1585行有个后台进程启动,eventProcessLoop.start(),这个地方注意一下,等遇到了我们在详细说。
sparkContext.runJob函数
当你去看SparkContext中的runJob函数的时候,你会发现很多个,让我们根据调用的方法一层一层来解析。
/** * Run a job on all partitions in an RDD and return the results in an array. */ def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = { runJob(rdd, func, 0 until rdd.partitions.length) }
这个调用是添加了rdd.partitions.length长度
/** * Run a job on a given set of partitions of an RDD, but take a function of type * `Iterator[T] => U` instead of `(TaskContext, Iterator[T]) => U`. */ def runJob[T, U: ClassTag]( rdd: RDD[T], func: Iterator[T] => U, partitions: Seq[Int]): Array[U] = { val cleanedFunc = clean(func) runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions) }
这个地方又填加了一个操作,就是清除闭包用的,这样可以也可做序列化了。
/** * Run a function on a given set of partitions in an RDD and return the results as an array. */ def runJob[T, U: ClassTag]( rdd: RDD[T], func: (TaskContext, Iterator[T]) => U, partitions: Seq[Int]): Array[U] = { val results = new Array[U](partitions.size) runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res) results }
这个地方又添加了一个result变量,用于存在将来task执行后的返回结果。
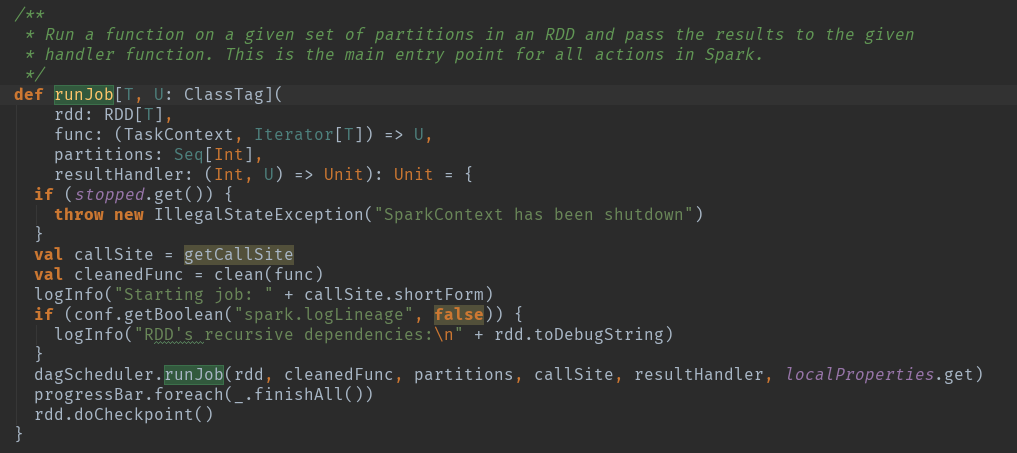
到了这个地方,runJob基本上就处理完了,开始了真正的DAG划分操作了。值得注意的是,可以重点关注一下rdd.doCheckpoint()这个方法,这个方法在优化的时候比较有用,可以将rdd缓存后,清除其缓存或者存储节点前的血统关系。
private[spark] def doCheckpoint(): Unit = {
RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {
if (!doCheckpointCalled) {
doCheckpointCalled = true
if (checkpointData.isDefined) {
checkpointData.get.checkpoint()
} else {
dependencies.foreach(_.rdd.doCheckpoint())
}
}
}
}
时刻注意:如果RDD做了checkpoint了,那么它就将lineage中它的parents给切除了。所以你要做checkpoint的时候想好如何做,是否也要做起partent的checkpoint
dagScheduler.runJob
def runJob[T, U]( rdd: RDD[T], func: (TaskContext, Iterator[T]) => U, partitions: Seq[Int], callSite: CallSite, resultHandler: (Int, U) => Unit, properties: Properties): Unit = { val start = System.nanoTime val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties) waiter.awaitResult() match { case JobSucceeded => logInfo("Job %d finished: %s, took %f s".format (waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9)) case JobFailed(exception: Exception) => logInfo("Job %d failed: %s, took %f s".format (waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9)) // SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler. val callerStackTrace = Thread.currentThread().getStackTrace.tail exception.setStackTrace(exception.getStackTrace ++ callerStackTrace) throw exception } }
这个函数主要是调用了submitJob函数
DAGScheduler.submitJob
def submitJob[T, U]( rdd: RDD[T], func: (TaskContext, Iterator[T]) => U, partitions: Seq[Int], callSite: CallSite, resultHandler: (Int, U) => Unit, properties: Properties): JobWaiter[U] = { // Check to make sure we are not launching a task on a partition that does not exist.
//这个地方是检查一下需要运行partition的数量,因为不是每个rdd的partition都需要运行,比如frist()就只需要一个partition就可以了。 val maxPartitions = rdd.partitions.length partitions.find(p => p >= maxPartitions || p < 0).foreach { p => throw new IllegalArgumentException( "Attempting to access a non-existent partition: " + p + ". " + "Total number of partitions: " + maxPartitions) } val jobId = nextJobId.getAndIncrement() if (partitions.size == 0) { // Return immediately if the job is running 0 tasks return new JobWaiter[U](this, jobId, 0, resultHandler) } assert(partitions.size > 0) val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _] val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler) eventProcessLoop.post(JobSubmitted( jobId, rdd, func2, partitions.toArray, callSite, waiter, SerializationUtils.clone(properties))) waiter }
1.检查出需要运行的partitions。
2.生成了一个新的jobId 比如是0。
3.主要的是生成一个JobWaiter()对象。
4.eventProcessLoop.post(JobSubmitted()提交作业了,看到了么?这个地方就是上面我们说的需要注意的点,new DAGSchedulerEventProcessLoop(this)上面是不是new了一个呢?
这个地方是eventProcessLoop 调用post方法,将JobSubmitted放入排队的带处理队列中,他是一个一直循环的处理的进程,当有JobSubmitted放入队列的时候就开始处理,里面有个onReceive()方法,这个方法被DAGSchedulerEventProcessLoop里面的onReceive方法所重写。
让我们看一下

在看一下doOnReceive(event)

其实调用的是handleJobSubmitted()方法,在看这个方法的时候我们还是先看看EventLoop这个抽象类吧。看看具体是啥。
EventLoop()
/** * An event loop to receive events from the caller and process all events in the event thread. It * will start an exclusive event thread to process all events. * * Note: The event queue will grow indefinitely. So subclasses should make sure `onReceive` can * handle events in time to avoid the potential OOM. */ private[spark] abstract class EventLoop[E](name: String) extends Logging { private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() private val stopped = new AtomicBoolean(false) private val eventThread = new Thread(name) { setDaemon(true) override def run(): Unit = { try { while (!stopped.get) { val event = eventQueue.take() try { onReceive(event) } catch { case NonFatal(e) => { try { onError(e) } catch { case NonFatal(e) => logError("Unexpected error in " + name, e) } } } } } catch { case ie: InterruptedException => // exit even if eventQueue is not empty case NonFatal(e) => logError("Unexpected error in " + name, e) } } } }
注释翻译:
事件循环从调用者接收事件并处理事件线程中的所有事件。它将启动一个单独的事件线程来处理所有事件。
注意:事件队列将无限增长。因此子类应该确保“onReceive”能够及时处理事件,以避免潜在的OOM。
1.定义了一个事件队列 eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]()
2.定义了一个事件线程,private val eventThread = new Thread(name) {}
3.当调用EventLoop的start()方法的时候,其实调用的是eventThread()的start()方法,这个地方还记得上面写到的1585行的start()调用么?

这个地方onstart()啥都没干,掉用了eventThread的start()方法,这个方法里面调用了onReceive(event)方法,这个方法在DAGScheduler中又被重写了。好了到此你知道了整体关系了。

dagScheduler.handleJobSubmitted
private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], callSite: CallSite, listener: JobListener, properties: Properties) { var finalStage: ResultStage = null try { // New stage creation may throw an exception if, for example, jobs are run on a // HadoopRDD whose underlying HDFS files have been deleted. finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite) } catch { case e: Exception => logWarning("Creating new stage failed due to exception - job: " + jobId, e) listener.jobFailed(e) return } val job = new ActiveJob(jobId, finalStage, callSite, listener, properties) clearCacheLocs() logInfo("Got job %s (%s) with %d output partitions".format( job.jobId, callSite.shortForm, partitions.length)) logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")") logInfo("Parents of final stage: " + finalStage.parents) logInfo("Missing parents: " + getMissingParentStages(finalStage)) val jobSubmissionTime = clock.getTimeMillis() jobIdToActiveJob(jobId) = job activeJobs += job finalStage.setActiveJob(job) val stageIds = jobIdToStageIds(jobId).toArray val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo)) listenerBus.post( SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties)) submitStage(finalStage) submitWaitingStages() }
1.DAGScheduler将Job分解成具有前后依赖关系的多个stage.
2.DAGScheduler是根据ShuffleDependency划分stage的.
3.stage分为ShuffleMapStage和ResultStage;一个Job中包含一个ResultStage及多个ShuffleMapStage.
4.一个stage包含多个tasks,task的个数即该stage的finalRDD的partition数.
5.一个stage中的task完全相同,ShuffleMapStage包含的都是ShuffleMapTask;ResultStage包含的都是ResultTask.
注意上面总结的这几点,我们开始一一的坐解析。先从newResultStage()开始
Stage划分
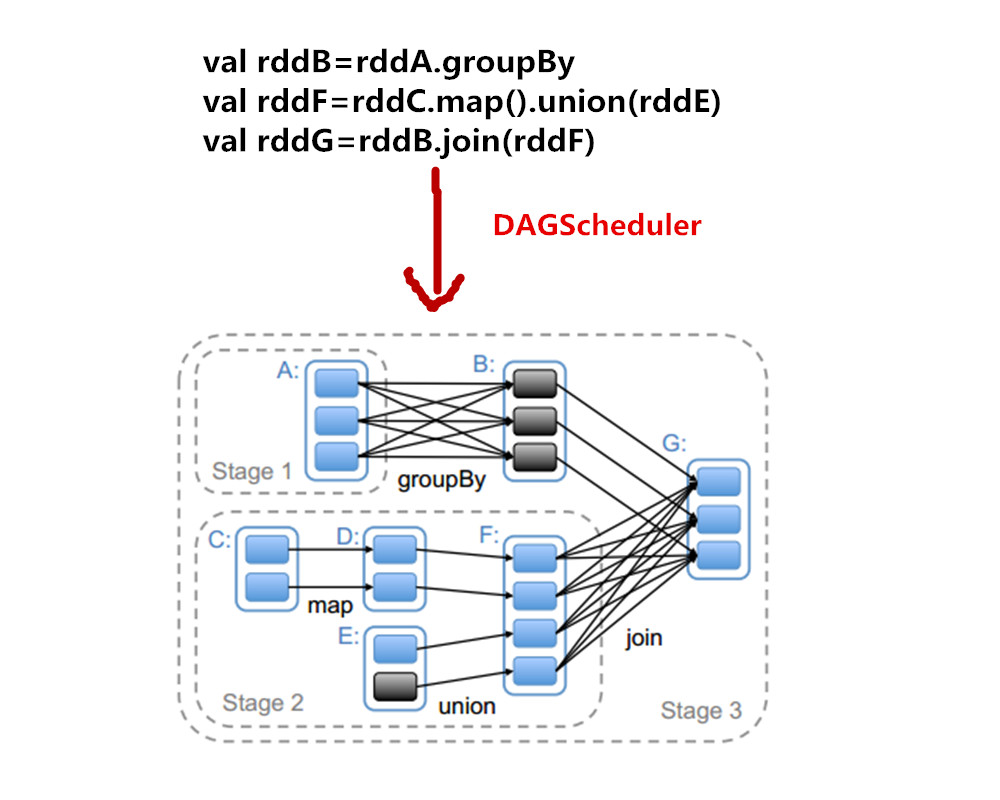
还是先盗个图,这样看着更好。
栈调用:
DAGScheduler.newResultStage
- DAGScheduler.getParentStagesAndId
- DAGScheduler.getParentStages
- DAGScheduler.getShuffleMapStage
- DAGScheduler.getAncestorShuffleDependencies
- DAGScheduler.newOrUsedShuffleStage
- DAGScheduler.newShuffleMapStage
- DAGScheduler.getShuffleMapStage
- DAGScheduler.getParentStages
这里面把最后一个触发action动作的rdd叫做finalRDD,所有的划分都是从这个rdd开始往前推的,是一个从右往左的过程,因为是递归调用,因此越靠左边的stageid越小,也越先调用。
newResultStage
调用是从最后一个RDD所在的Stage,ResultStage开始划分的,这里即为G所在的Stage。但是在生成这个Stage之前会生成它的parent Stage,就这样递归的把parent Stage都先生成了。

getParentStagesAndId

该函数调用getParentStages获得parentStages,之后获取一个递增的id,连同刚获得的parentStages一同返回,并在newResultStage中,将id作为ResultStage的id。
getParentStages()
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = { //存储parents的stage val parents = new HashSet[Stage] //存储已经遍历过的rdd val visited = new HashSet[RDD[_]] // We are manually maintaining a stack here to prevent StackOverflowError // caused by recursively visiting //需要遍历的rdd val waitingForVisit = new Stack[RDD[_]] def visit(r: RDD[_]) { if (!visited(r)) { visited += r // Kind of ugly: need to register RDDs with the cache here since // we can't do it in its constructor because # of partitions is unknown for (dep <- r.dependencies) { dep match { //若是宽依赖则生成新的Stage case shufDep: ShuffleDependency[_, _, _] => parents += getShuffleMapStage(shufDep, firstJobId) //若是窄依赖则加入Stack,等待处理 case _ => waitingForVisit.push(dep.rdd) } } } } //在Stack中加入最后一个RDD waitingForVisit.push(rdd) //广度优先遍历 while (waitingForVisit.nonEmpty) { visit(waitingForVisit.pop()) } //返回ParentStages List parents.toList }
函数getParentStages中,遍历整个RDD依赖图的finalRDD的List[dependency],若遇到ShuffleDependency,这是相当于是一个另一个stage了,此时我们就得获取这个stage了呀,则调用getShuffleMapStage(shufDep,jobId)返回一个ShuffleMapStage类型对象,添加到父stage列表中,若为NarrowDependency,则将NarrowDependency包含的RDD加入到待visit队列中,之后继续遍历待visit队列中的RDD,直到遇到ShuffleDependency或无依赖的RDD。
函数getParentStages的职责说白了就是:以参数rdd为起点,一级一级遍历依赖,碰到窄依赖就继续往前遍历,碰到宽依赖就调用getShuffleMapStage(shufDep, jobId)。这里需要特别注意的是,getParentStages以rdd为起点遍历RDD依赖并不会遍历整个RDD依赖图,而是一级一级遍历直到所有“遍历路线”都碰到了宽依赖就停止。剩下的事,在遍历的过程中交给getShuffleMapStage。
getshuffleMapStage
private def getShuffleMapStage( shuffleDep: ShuffleDependency[_, _, _], firstJobId: Int): ShuffleMapStage = { shuffleToMapStage.get(shuffleDep.shuffleId) match { //若找到则直接返回 case Some(stage) => stage case None => // 检查这个Stage的Parent Stage是否生成 // 若没有,则生成它们 // We are going to register ancestor shuffle dependencies getAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep => shuffleToMapStage(dep.shuffleId) = newOrUsedShuffleStage(dep, firstJobId) } // Then register current shuffleDep // 生成新的Stage val stage = newOrUsedShuffleStage(shuffleDep, firstJobId) //将新的Stage 加入到 HashMap shuffleToMapStage(shuffleDep.shuffleId) = stage //返回新的Stage stage } }
上面说了遇到ShuffleDependency 的依赖就是一个新的stage的开始,因此我们需要得到这个stage,前面我们还说到了,stage只有两种,一种叫ShuffleMapStage,一种叫resultStage而且只能有一个,因此除了最开始的那个stage,其他的都是shuffleMapStage,因此遇到的时候我们就得获取他。
这个地方有两种情况,就是之前已经创建好了,当你有多个action动作的时候,可能存在多个依赖关系,此次划分的stage可能之前你已经划分好了,因此做一次检查这个很重要的。
getAncestorShuffleDependencies
private def getAncestorShuffleDependencies(rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = { val parents = new Stack[ShuffleDependency[_, _, _]] val visited = new HashSet[RDD[_]] // We are manually maintaining a stack here to prevent StackOverflowError // caused by recursively visiting val waitingForVisit = new Stack[RDD[_]] def visit(r: RDD[_]) { if (!visited(r)) { visited += r for (dep <- r.dependencies) { dep match { case shufDep: ShuffleDependency[_, _, _] => if (!shuffleToMapStage.contains(shufDep.shuffleId)) { parents.push(shufDep) } case _ => } waitingForVisit.push(dep.rdd) } } } waitingForVisit.push(rdd) while (waitingForVisit.nonEmpty) { visit(waitingForVisit.pop()) } parents }
可以看到的是和newResultStage中的getParentStages会非常类似,不同的是这里会先判断shuffleToMapStage是否存在这个Stage,不存在的话会将这个shuffledepen push到parents这个Stack,最会返回给上述的getShuffleMapStage,调用newOrUsedShuffleStage生成新的Stage
newOrUsedShuffleStage
这个地方出现了上面提到了每个Stage中的task数量是最后一个rdd的partitions决定的,因为在创建newShuffleMapStage()的时候将这个当参数传入了。
还有一点:判断stage是否已经被计算过了,如果计算过了,则将结果赋值到这个stage中,如果没计算则注册到mapOutputTracker中为存储元数据占位。
val numTasks = rdd.partitions.length
private def newOrUsedShuffleStage( shuffleDep: ShuffleDependency[_, _, _], firstJobId: Int): ShuffleMapStage = { val rdd = shuffleDep.rdd val numTasks = rdd.partitions.length //生成新的Stage val stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite) //判断Stage是否已经被计算过 //若计算过,则把结果复制到新的stage if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) { val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId) val locs = MapOutputTracker.deserializeMapStatuses(serLocs) (0 until locs.length).foreach { i => if (locs(i) ne null) { // locs(i) will be null if missing stage.addOutputLoc(i, locs(i)) } } } else { //如果没计算过,就在注册mapOutputTracker Stage //为存储元数据占位 // Kind of ugly: need to register RDDs with the cache and map output tracker here // since we can't do it in the RDD constructor because # of partitions is unknown logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")") mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length) } stage }
newShuffleMapStage
private def newShuffleMapStage( rdd: RDD[_], numTasks: Int, shuffleDep: ShuffleDependency[_, _, _], firstJobId: Int, callSite: CallSite): ShuffleMapStage = { val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, firstJobId) val stage: ShuffleMapStage = new ShuffleMapStage(id, rdd, numTasks, parentStages, firstJobId, callSite, shuffleDep) stageIdToStage(id) = stage updateJobIdStageIdMaps(firstJobId, stage) stage }
通过代码发现newShuffleMapStage 和newResultStage 基本一样,那流程也基本一样了,也是上面整个过程的再次循环。
通过stage的划分,我们就这样一层层的划分完成了,每个stage都知道其依赖rdd的stage情况。下面让我们看看job的创建,以及taskSet的创建。
任务创建

finalStage创建完成后,我们要创建ActiveJob了,同时为每个stage创建stageInfos。
提交finalStage
submitStage
private def submitStage(stage: Stage) { val jobId = activeJobForStage(stage) if (jobId.isDefined) { logDebug("submitStage(" + stage + ")") //得到缺失的Parent Stage if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) { val missing = getMissingParentStages(stage).sortBy(_.id) logDebug("missing: " + missing) if (missing.isEmpty) { logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents") //如果没有缺失的Parent Stage, //那么代表着该Stage可以运行了 //submitMissingTasks会完成DAGScheduler最后的工作, //向TaskScheduler 提交 Task submitMissingTasks(stage, jobId.get) } else { //深度优先遍历 for (parent <- missing) { submitStage(parent) } waitingStages += stage } } } else { abortStage(stage, "No active job for stage " + stage.id, None) } }
就是在正式跑这个job的时候,先检查一下其parents的情况,这个也是一个深度遍历的过程,如果存在丢失,则递归调用继续检查丢失的。最终到没有丢失的情况时,提交stage。
getMissingParentStages()


private def getMissingParentStages(stage: Stage): List[Stage] = { val missing = new HashSet[Stage] val visited = new HashSet[RDD[_]] // We are manually maintaining a stack here to prevent StackOverflowError // caused by recursively visiting val waitingForVisit = new Stack[RDD[_]] def visit(rdd: RDD[_]) { if (!visited(rdd)) { visited += rdd val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil) if (rddHasUncachedPartitions) { for (dep <- rdd.dependencies) { dep match { case shufDep: ShuffleDependency[_, _, _] => val mapStage = getShuffleMapStage(shufDep, stage.firstJobId) if (!mapStage.isAvailable) { missing += mapStage } case narrowDep: NarrowDependency[_] => waitingForVisit.push(narrowDep.rdd) } } } } } waitingForVisit.push(stage.rdd) while (waitingForVisit.nonEmpty) { visit(waitingForVisit.pop()) } missing.toList }
就是检查是否有丢失的情况,如果有丢失的加入到missing里面返回,让submitStage将丢失的stage陆续提交,得到计算结果。
submitMissingTasks
private def submitMissingTasks(stage: Stage, jobId: Int) { logDebug("submitMissingTasks(" + stage + ")") // Get our pending tasks and remember them in our pendingTasks entry stage.pendingPartitions.clear() // First figure out the indexes of partition ids to compute. val partitionsToCompute: Seq[Int] = stage.findMissingPartitions() // Create internal accumulators if the stage has no accumulators initialized. // Reset internal accumulators only if this stage is not partially submitted // Otherwise, we may override existing accumulator values from some tasks if (stage.internalAccumulators.isEmpty || stage.numPartitions == partitionsToCompute.size) { stage.resetInternalAccumulators() } // Use the scheduling pool, job group, description, etc. from an ActiveJob associated // with this Stage val properties = jobIdToActiveJob(jobId).properties runningStages += stage // SparkListenerStageSubmitted should be posted before testing whether tasks are // serializable. If tasks are not serializable, a SparkListenerStageCompleted event // will be posted, which should always come after a corresponding SparkListenerStageSubmitted // event. stage match { case s: ShuffleMapStage => outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1) case s: ResultStage => outputCommitCoordinator.stageStart( stage = s.id, maxPartitionId = s.rdd.partitions.length - 1) } val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try { stage match { case s: ShuffleMapStage => partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap case s: ResultStage => val job = s.activeJob.get partitionsToCompute.map { id => val p = s.partitions(id) (id, getPreferredLocs(stage.rdd, p)) }.toMap } } catch { case NonFatal(e) => stage.makeNewStageAttempt(partitionsToCompute.size) listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties)) abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq) listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties)) // TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times. // Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast // the serialized copy of the RDD and for each task we will deserialize it, which means each // task gets a different copy of the RDD. This provides stronger isolation between tasks that // might modify state of objects referenced in their closures. This is necessary in Hadoop // where the JobConf/Configuration object is not thread-safe. var taskBinary: Broadcast[Array[Byte]] = null try { // For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep). // For ResultTask, serialize and broadcast (rdd, func). val taskBinaryBytes: Array[Byte] = stage match { case stage: ShuffleMapStage => closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array() case stage: ResultStage => closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array() } taskBinary = sc.broadcast(taskBinaryBytes) } catch { // In the case of a failure during serialization, abort the stage. case e: NotSerializableException => abortStage(stage, "Task not serializable: " + e.toString, Some(e)) runningStages -= stage // Abort execution return case NonFatal(e) => abortStage(stage, s"Task serialization failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } val tasks: Seq[Task[_]] = try { stage match { case stage: ShuffleMapStage => partitionsToCompute.map { id => val locs = taskIdToLocations(id) val part = stage.rdd.partitions(id) new ShuffleMapTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, stage.internalAccumulators) } case stage: ResultStage => val job = stage.activeJob.get partitionsToCompute.map { id => val p: Int = stage.partitions(id) val part = stage.rdd.partitions(p) val locs = taskIdToLocations(id) new ResultTask(stage.id, stage.latestInfo.attemptId, taskBinary, part, locs, id, stage.internalAccumulators) } } } catch { case NonFatal(e) => abortStage(stage, s"Task creation failed: $e\n${e.getStackTraceString}", Some(e)) runningStages -= stage return } if (tasks.size > 0) { logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")") stage.pendingPartitions ++= tasks.map(_.partitionId) logDebug("New pending partitions: " + stage.pendingPartitions) taskScheduler.submitTasks(new TaskSet( tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties)) stage.latestInfo.submissionTime = Some(clock.getTimeMillis()) } else { // Because we posted SparkListenerStageSubmitted earlier, we should mark // the stage as completed here in case there are no tasks to run markStageAsFinished(stage, None) val debugString = stage match { case stage: ShuffleMapStage => s"Stage ${stage} is actually done; " + s"(available: ${stage.isAvailable}," + s"available outputs: ${stage.numAvailableOutputs}," + s"partitions: ${stage.numPartitions})" case stage : ResultStage => s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})" } logDebug(debugString) } }
TaskSet保存了Stage包含的一组完全相同的Task,每个Task的处理逻辑完全相同,不同的是处理的数据,每个Task负责一个Partition。

最后就是将一个TaskSet提交出去了,至此DAG阶段的处理就全部完成了。

