spark[源码]-Pool分析
概述
这篇文章主要是分析一下Pool这个任务调度的队列。整体代码量也不是很大,正好可以详细的分析一下,前面在TaskSchedulerImpl提到大体的功能,这个点在丰富一下吧。
DAGScheduler负责构建具有依赖关系的任务集,TaskSetManger负责在具体的任务集内部调度任务,而TaskScheduler负责将资源提供给TaskSetManger供其作为调度任务的依据,但是每个sparkContext可能同时存在多个可运行的任务集,因此需要调度池pool来进行协调管理。
初始化源码解析
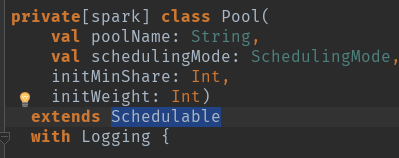
poolname:名字
schedulingMode:调度模式,FAIR(公平调度),FIFO,默认是FIFO的方式。
initWeight:调度池权重
initMinShare:计算资源中的cpu核数
先看一下扩展类Schedulable,Scheduler是一个特征类,pool是其具体的实现.
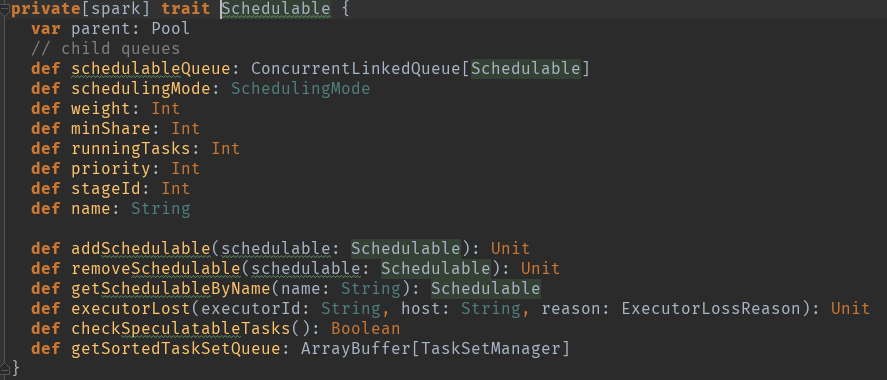
val schedulableQueue = new ConcurrentLinkedQueue[Schedulable] 调度队列
val schedulableNameToSchedulable = new ConcurrentHashMap[String, Schedulable] 调度对应关系
var weight = initWeight 调度池权重
var minShare = initMinShare 计算资源中的cpu核数
var runningTasks = 0 正在运行的task数量
var priority = 0 优先级
var stageId = -1 池的阶段id用于在调度中中断绑定
var name = poolName 调度池名字
var parent: Pool = null
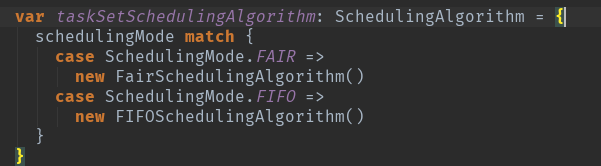
调度算法,根据调度模式初始化算法。org.apache.spark.scheduler.SchedulingAlgorithm。
调度池则用于调度每个sparkContext运行时并存的多个互相独立无依赖关系的任务集。
调度池负责管理下一级的调度池和TaskSetManager对象。
用户可以通过配置文件定义调度池和TaskSetManager对象。
1.调度的模式Scheduling mode:用户可以设置FIFO或者FAIR调度方式。
2.weight,调度的权重,在获取集群资源上权重高的可以获取多个资源。
3.miniShare:代表计算资源中的cpu核数。
配置conf/faurscheduler.xml配置调度池的属性,同时要在sparkConf对象中配置属性。
方法解析
TaskSchedulerImpl在初始化过程中会根据用户设定的SchedulingMode(默认是FIFO)创建一个rootPool根调度池,之后根据具体的调度模式再进一步创建ScheduleBuilder对象,具体的ScheduleBuilder对象的BuildPools方法将在rootPool的基础上完成整个Pool的构建工作,之后就有通过addSchedulable将taskSetManger和pool关联起来了。
Schedulable有两个类,一个是pool,一个是TaskSetManager。
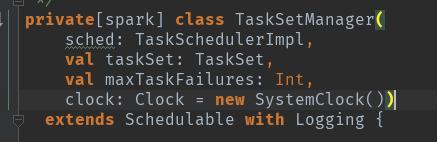
Pool直接管理的是TaskSetManager,每个TaskSetManager创建时都存储了其对应的StageID.
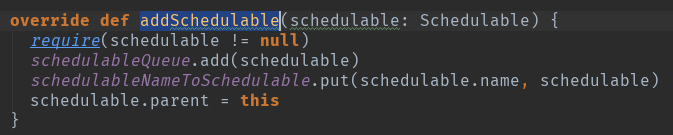
具体的调度算法,等以后的文章在做详细分析吧。

