spark[源码]-sparkContext概述
SparkContext概述
sparkContext是所有的spark应用程序的发动机引擎,就是说你想要运行spark程序就必须创建一个,不然就没的玩了。sparkContext负责初始化很多东西,当其初始化完毕以后,才能像spark集群提交任务,这个地方还有另一个管理配置的类sparkConf,它主要负责配置,检查,修改等工作,这会在后期源码阅读的时候你会经常看到的一个参数conf,说的就是它。
1.代码小实例
object sparktest_hivesql { def main(args: Array[String]): Unit = { val sc = new SparkContext(new SparkConf().setAppName("sparktest_sql")) val hiveContext = new HiveContext(sc) import hiveContext.implicits._ hiveContext.sql("use data_sence") val testData = hiveContext.sql("select * from ods_position_day limit 10") testData.collect().foreach(x=>println("****:"+x)) sc.stop() } }
功能很多简单,即使通过spark和hive 的配置连接,让spark可以读hive 库里面的数据,这个地方就读取一个表里面的数据,打印出来。主要是为了做一个sparkconf和sparkContext的引子。
2.sparkConf
1.参数配置处理
就是一些spark配置信息的处理,主要是一个:private val settings = new ConcurrentHashMap[String, String]()
sparkconf() 只接受一个boolean的参数:
当为true时,系统将加载外部设置。

当为false时,跳过加载外部设置,无论系统属性是什么,都要得到相同的配置.
对一些参数做出map处理,将用户自己添加和系统提供的进行整合,全是围绕这个方法进行处理的。

这个地方用到了一个scala的单例模式,返回的是this,这样你就用在生成sparkConf().setMaster().setAppName()的情况了。
2.对一些过时的参数进行验证。
3.sparkContext描述
先来个简单的关系图了解一下基本关系:
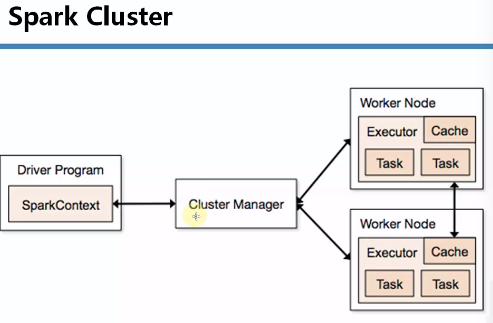
1.spark程序在运行的时候分为Driver(任务解析,分配)和Executor(job具体执行者)两部分。
2.spark编程是基于SparkContext的,具体说来包含两部分。
1.spark编程的核心基础RDD,是由SparkContext来创建的。
2.spark程序的调度优化也是基于SparkContext。
3.spark程序的注册是通过SparkContext实例化时候生产的对象来完成的。其实是通过SchedulerBankend来注册程序。
4.spark程序运行时通过Master获取具体的计算资源,计算资源获取也是通过SparkContext产生的对象来申请。实际是SchedulerBackend来获取计算资源的。
5.SparkContext结束的时候spark也结束了。
4.spark初始化步骤
SparkContext的主构造器参数为SparkConf:这个地方简单的说一下,一直强调sparkContext只能有一个,但是其实是可以多个的。

allowMultipleContexts :多个contexts的标签,当为true的时候 有多个sparkcontext的时候 会抛出异常。
SparkContext.markPartiallyConstructed(this, allowMultipleContexts) 为了多个sparkContexts。
SparkContext的初始化步骤如下:
1) 创建Spark执行环境SparkEnv;
2) 创建RDD清理器metadataCleaner;
3) 创建并初始化Spark UI;
4) Hadoop相关配置及Executor环境变量的设置;
5) 创建任务调度TaskScheduler;
6) 创建和启动DAGScheduler;
7) TaskScheduler的启动;
8) 初始化块管理器BlockManager;
9) 启动测量系统MetricsSystem;
10) 创建和启动Executor分配管理器ExecutorAllocationManager;
11) ContextCleaner的创建和启动;
12) Spark环境更新;
13) 创建DAGSchedulerSource和BlockManagerSource;
14) 将SparkContext标记为激活。

