YOLOv9:在自定义数据上进行图像分割训练
YOLOv9:在自定义数据上进行图像分割训练
介绍
在快速发展的计算机视觉领域,物体分割在从图像中提取有意义信息方面发挥着重要作用。在各种分割算法中,YOLOv9 已经成为一个强大而灵活的解决方案,提供了高效的分割能力和出色的准确性。
在这个全面的指南中,我们将深入探讨如何在自定义数据集上训练 YOLOv9 进行物体分割,并对测试数据进行推断。通过本教程,您将深入了解 YOLOv9 的分割机制,并学会如何使用自定义数据集和 ultralytics 应用它到您的项目中。
目录
-
步骤 1:下载数据集
-
步骤 2:安装 Ultralytics
-
步骤 3:加载 YOLOv9-seg 预训练模型和推断
-
步骤 4:在自定义数据集上微调 YOLOv9-seg
-
步骤 5:加载自定义模型
-
步骤 6:对测试图像进行推断
步骤 1:下载数据集
我们将使用 Furniture BBox To Segmentation (SAM) 数据集进行本教程。您可以从 Kaggle 获取 Furniture BBox To Segmentation (SAM) 数据集,Kaggle 是一个流行的数据科学竞赛、数据集和机器学习资源平台。下载数据集后,如果数据集被压缩(例如 ZIP 或 TAR 文件),您可能需要解压缩文件。
数据集链接:
http://kaggle.com/datasets/nicolaasregnier/furniture
步骤 2:安装 Ultralytics
!pip install ultralytics -q
导入包
from ultralytics import YOLO
import matplotlib.pyplot as plt
import cv2
import pandas as pd
import seaborn as sns
步骤 3:使用预训练的 YoloV9 权重进行推断
model = YOLO('yolov9c-seg.pt')
model.predict("image.jpg", save=True)
1. model = YOLO('yolov9c-seg.pt'):
-
这一行初始化了一个 YOLOv9(You Only Look Once)模型,用于物体分割。
-
该模型从名为 'yolov9c-seg.pt' 的文件中加载,其中包含了专门设计用于分割任务的 YOLOv9 架构的预训练权重和配置。
2. model.predict("image.jpg", save=True):
-
这一行使用初始化的 YOLOv9 模型对名为 "image.jpg" 的输入图像执行预测。
-
predict 函数接受输入图像并进行分割,识别并勾画图像中的物体。
-
save=True 参数表示分割结果将被保存。
步骤 4:在自定义数据集上微调 YOLOv9-seg
yolov9 的配置:
dataDir = '/content/Furniture/sam_preds_training_set/'
workingDir = '/content/'
变量 dataDir 表示对象分割模型的训练数据所在的目录路径。训练数据存储在一个名为 "sam_preds_training_set" 的目录下,该目录位于 "/content" 目录下的 "Furniture" 目录中。类似地,变量 workingDir 表示存储主要工作文件的目录路径。
num_classes = 2
classes = ['Chair', 'Sofa']
-
num_classes = 2:这个变量指定了模型将被训练以分割的类别或分类的总数。在本例中,num_classes 设置为 2,表示模型将学习识别两个不同的物体类别。
-
classes = ['Chair', 'Sofa']:这个列表包含了模型将被训练以识别的类别或对象的名称。列表中的每个元素对应一个特定的类标签。这些类别被定义为 'Chair' 和 'Sofa',模型将被训练以分割属于这些类别的物体。
import yaml
import os
file_dict = {
'train': os.path.join(dataDir, 'train'),
'val': os.path.join(dataDir, 'val'),
'test': os.path.join(dataDir, 'test'),
'nc': num_classes,
'names': classes
}
with open(os.path.join(workingDir, 'data.yaml'), 'w+') as f:
yaml.dump(file_dict, f)
- file_dict:创建一个包含数据集信息的字典:
-
'train'、'val' 和 'test':训练、验证和测试数据目录的路径,分别。这些路径通过将 dataDir(包含数据集的目录)与相应的目录名称连接而获得。
-
'nc':数据集中类别的数量,由变量 num_classes 表示。
-
'names':一个类名列表,由变量 classes 表示。
-
with open(...) as f:以写入模式('w+')打开名为 'data.yaml' 的文件。如果文件不存在,将被创建。with 语句确保在写入后正确关闭文件。
-
yaml.dump(file_dict, f):将 file_dict 字典的内容写入到 YAML 文件 f 中。yaml.dump() 函数将 Python 对象序列化为 YAML 格式并写入到指定的文件对象中。
model = YOLO('yolov9c-seg.pt')
model.train(data='/content/data.yaml' , epochs=30 , imgsz=640)
初始化一个 YOLOv9 模型,用于对象分割,使用指定的预训练权重文件 'yolov9c-seg.pt'。然后将模型训练在由 data 参数指定的自定义数据集上,data 参数指向包含数据集配置细节(如训练和验证图像的路径、类别数量和类别名称)的 YAML 文件 'data.yaml'。
步骤 5:加载自定义模型
best_model_path = '/content/runs/segment/train/weights/best.pt'
best_model = YOLO(best_model_path)
我们正在定义训练期间获得的最佳性能模型的路径。best_model_path 变量保存了存储最佳模型权重的文件路径。这些权重表示在训练数据上表现最佳的 YOLOv9 模型的学习参数。
接下来,我们使用 best_model_path 实例化 YOLO 对象。这将使用训练期间获得的最佳模型的权重初始化 YOLO 模型的一个实例。这个被实例化的 YOLO 模型,称为 best_model,现在已经准备好用于对新数据进行预测。
步骤 6:对测试图像进行推断
# Define the path to the validation images
valid_images_path = os.path.join(dataDir, 'test', 'images')
# List all jpg images in the directory
image_files = [file for file in os.listdir(valid_images_path) if file.endswith('.jpg')]
# Select images at equal intervals
num_images = len(image_files)
selected_images = [image_files[i] for i in range(0, num_images, num_images // 4)]
# Initialize the subplot
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
fig.suptitle('Test Set Inferences', fontsize=24)
# Perform inference on each selected image and display it
for i, ax in enumerate(axes.flatten()):
image_path = os.path.join(valid_images_path, selected_images[i])
results = best_model.predict(source=image_path, imgsz=640)
annotated_image = results[0].plot()
annotated_image_rgb = cv2.cvtColor(annotated_image, cv2.COLOR_BGR2RGB)
ax.imshow(annotated_image_rgb)
ax.axis('off')
plt.tight_layout()
plt.show()
- 定义验证图像的路径:这一行构建了在 dataDir 目录中包含测试图像的目录路径。
- 列出目录中的所有 jpg 图像:它创建了一个包含指定目录中所有 JPEG 图像文件的列表。
- 以相等间隔选择图像:它从列表中选择子集图像以进行可视化。在本例中,它选择了总图像数量的四分之一。
- 初始化子图:这一行创建一个 2x2 的子图网格,用于显示所选图像及其对应的预测。
- 对每个选择的图像进行推断并显示:它遍历每个子图,对相应的选择图像使用 best_model.predict() 函数进行推断,并显示带有边界框或分割掩码的标注图像。
- 最后,使用 plt.tight_layout() 整理子图并使用 plt.show() 显示它们。
【手把手教学】如何在YOLOv9上训练自己的目标检测数据集
文章源于网络,如若侵权,请联系删除!
前言
文章演示了如何在自定义数据集上运行推理和训练YOLOv9模型。作者克隆了YOLOv9项目代码,下载了模型权重,然后使用默认的COCO权重进行推理。然后,使用足球运动员检测数据集训练了一个微调的模型。作者回顾了训练图和混淆矩阵,然后在来自验证集的图像上测试了模型。
0. 写在前面
今天笔者为大家分享国外的James Gallagher和Piotr Skalski编写的YOLOv9使用教程!原博客链接为https://blog.roboflow.com/train-yolov9-model。
YOLOv9开源了一种新的CV模型架构,比现有流行的YOLO模型(YOLOv8、YOLOv7和YOLOv5)在MS COCO数据集上取得了更高的mAP。
本指南展示了如何在自定义数据集上训练YOLOv9模型,将通过一个训练视觉模型的例子来识别一个球场上的足球运动员。有了这一点,可以用这个指南使用你想要的任何数据集。
话不多说,让我们开始!
1. 什么是YOLOv9?
YOLOv9是由Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao开发的计算机视觉模型。Hong-Yuan Mark Liao和Chien-Yao Wang还对YOLOv4、YOLOR和YOLOv7等流行的模型架构进行了研究。YOLOv9引入了两种新的架构:YOLOv9和GELAN,这两种架构都可以从论文发布的YOLOv9 Python库中使用。
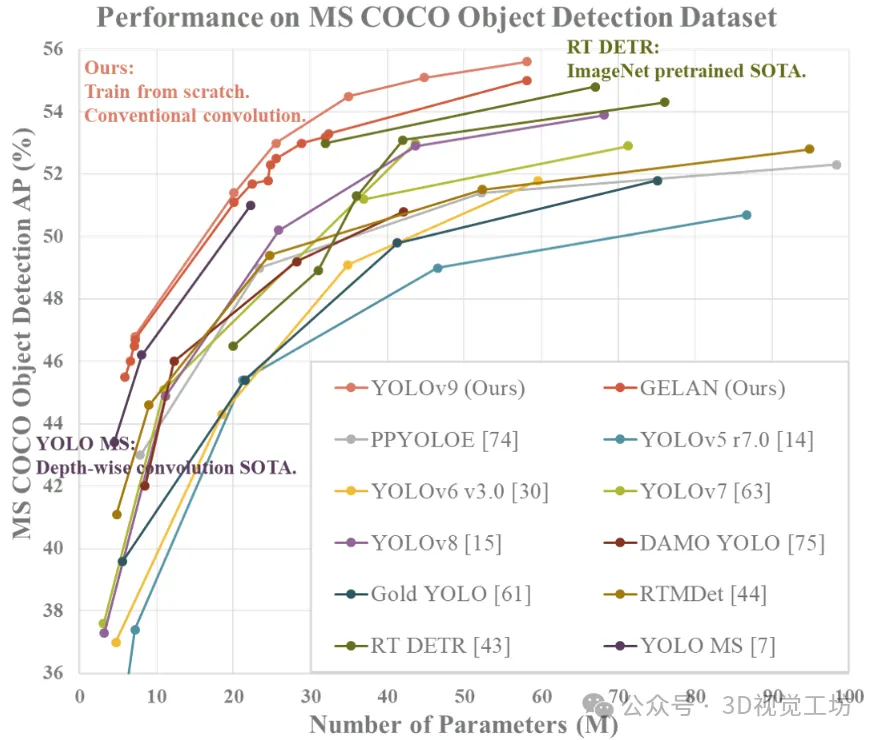
使用YOLOv9模型,可以训练出一个目标检测模型。此时不支持分割、分类等任务类型。YOLOv9有四种模型,按参数个数排序是:v9-S、v9-M、v9-C、v9-E。目前v9 - S和v9 - M的权重暂不可用。其中最小的模型在MS COCO数据集的验证集上达到了46.8 %的AP,而最大的模型达到了55.6 %。这为目标检测性能提供了一个新的先进水平。下面的图表展示了来自YOLOv9研究团队的研究结果。
YOLOv9在撰写本指南时没有官方许可证。截至2023年2月22日,一位主要研究人员指出:"我认为应该是GPL3,我会检查并更新许可文件。"。这表明许可证将很快确定。
2. 如何安装YOLOv9
YOLOv9被打包为一系列脚本,您可以使用这些脚本进行工作。在撰写本指南时,没有官方的Python包或包装器可供您与模型进行交互。
要使用YOLOv9,您需要下载项目存储库。然后,您可以运行训练作业或从现有的COCO检查点进行推理。
本教程假定您正在使用Google Colab。如果您在笔记本环境之外的本地机器上工作,请根据需要调整命令。
YOLOv9中存在一个错误,阻止您对图像进行推理,但Roboflow团队正在维护一个非官方的分支,其中包含一个补丁,直到修复发布。要从我们的补丁分支安装YOLOv9,请运行以下命令:
git clone https://github.com/SkalskiP/yolov9.git
cd yolov9
pip3 install -r requirements.txt -q
让我们设置一个HOME目录来工作:
import os
HOME = os.getcwd()
print(HOME)
接下来,需要下载模型权重。目前只有v9 - C和v9 - E权重可用。可以使用以下命令进行下载:
!mkdir -p {HOME}/weights
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
!wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt
现在可以使用项目库中的脚本在YOLOv9模型上运行推理和训练。
3.在YOLOv9模型上推理
在示例图像上使用v9 - C COCO检查点进行推理。创建一个新的数据目录,并将示例图像下载到您的笔记本中。你可以用我们的狗图片作为例子,也可以用你想要的任何其他图片。
!mkdir -p {HOME}/data
!wget -P {HOME}/data -q https://media.roboflow.com/notebooks/examples/dog.jpeg
SOURCE_IMAGE_PATH = f"{HOME}/dog.jpeg"
我们现在可以在我们的图像上进行推理:
!python detect.py --weights {HOME}/weights/gelan-c.pt --conf 0.1 --source {HOME}/data/dog.jpeg --device 0
Image(filename=f"{HOME}/yolov9/runs/detect/exp/dog.jpeg", width=600)

我们的模型能够成功地识别出图像中的人、狗和汽车。有鉴于此,该模型错误地将背带识别为手提包,并且未能检测到背包。
让我们试试参数最多的v9 - E模型:
!python detect.py --weights {HOME}/weights/yolov9-e.pt --conf 0.1 --source {HOME}/data/dog.jpeg --device 0
Image(filename=f"{HOME}/yolov9/runs/detect/exp2/dog.jpeg", width=600)

该模型能够成功识别人、狗、汽车和背包。
4. 如何训练YOLOv9模型
您可以使用YOLOv9项目目录中的train.py文件来训练YOLOv9模型。
第1步:下载数据集
要开始训练模型,您将需要一个数据集。对于本指南,我们将使用一个关于足球运动员的数据集。生成的模型将能够在场地上识别足球运动员。
如果您没有数据集,请查看Roboflow Universe,这是一个共享了超过200,000个计算机视觉数据集的社区。您可以找到涵盖从书脊到足球运动员再到太阳能电池板的数据集。
运行以下代码来下载我们在本指南中使用的数据集:
%cd {HOME}/yolov9
roboflow.login()
rf = roboflow.Roboflow()
project = rf.workspace("roboflow-jvuqo").project("football-players-detection-3zvbc")
dataset = project.version(1).download("yolov7")
当您运行此代码时,将会要求您通过Roboflow进行身份验证。请跟随在您的终端中出现的链接进行验证。如果您没有账户,将被带到一个页面,您可以在该页面创建一个账户。然后,再次点击链接以使用Python包进行身份验证。
此代码以YOLOv7格式下载数据集,该格式与YOLOv9模型兼容。
您可以使用任何按照YOLOv7格式格式化的数据集来进行此操作。
第2步:使用YOLOv9 Python脚本训练模型
让我们为我们的数据集训练一个模型,训练20个epochs。我们将使用GELAN-C架构进行此操作,该架构是YOLOv9 GitHub仓库发布的两种架构之一。GELAN-C的训练速度快。GELAN-C的推理时间也很快。
您可以使用以下代码进行此操作:
%cd {HOME}/yolov9
!python train.py \
--batch 16 --epochs 20 --img 640 --device 0 --min-items 0 --close-mosaic 15 \
--data {dataset.location}/data.yaml \
--weights {HOME}/weights/gelan-c.pt \
--cfg models/detect/gelan-c.yaml \
--hyp hyp.scratch-high.yaml
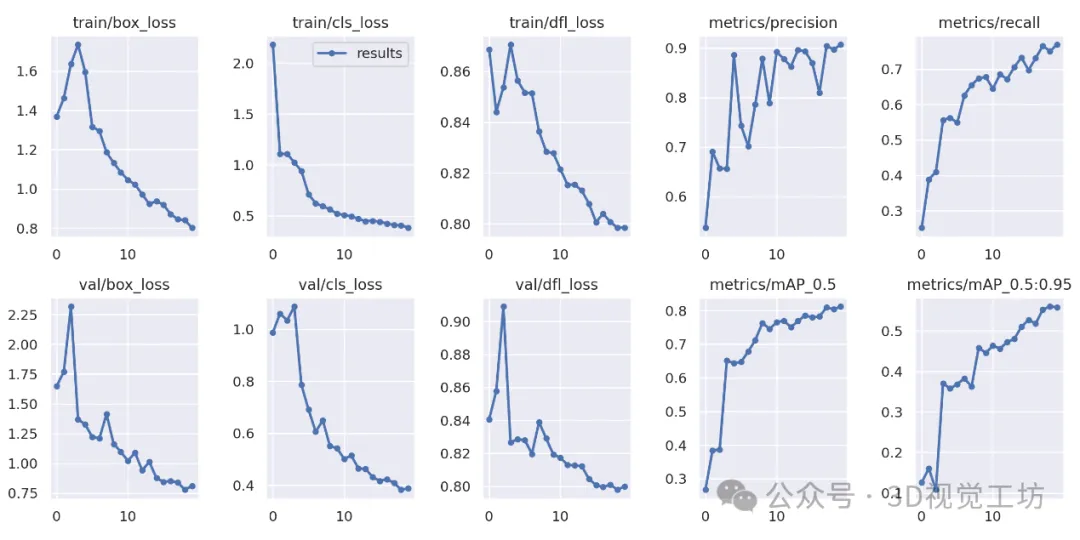
你的模型将开始训练。模型训练时,将看到每个epoch的训练指标。一旦模型完成训练,就可以使用YOLOv9生成的图来评估训练结果。
运行下面的代码来查看你的训练图:
Image(filename=f"{HOME}/yolov9/runs/train/exp/results.png", width=1000)
运行以下代码,查看您的模型在验证集中的一批图像上的结果:
Image(filename=f"{HOME}/yolov9/runs/train/exp/val_batch0_pred.jpg", width=1000)

第3步:在自定义模型上运行推理
既然我们有了一个训练好的模型,我们就可以进行推理。为此,我们可以使用YOLOv9库中的detection . py文件。
运行以下代码对验证集中的所有图像进行推理:
!python detect.py \
--img 1280 --conf 0.1 --device 0 \
--weights {HOME}/yolov9/runs/train/exp/weights/best.pt \
--source {dataset.location}/valid/images
import glob
from IPython.display import Image, display
for image_path in glob.glob(f'{HOME}/yolov9/runs/detect/exp4/*.jpg')[:3]:
display(Image(filename=image_path, width=600))
print("\n")
我们在大小为640的图像上训练了我们的模型,这使得我们可以用较少的计算资源来训练模型。在推理过程中,我们将图像尺寸增加到1280,使得我们可以从我们的模型中得到更准确的结果。
下面是我们模型结果的三个例子:
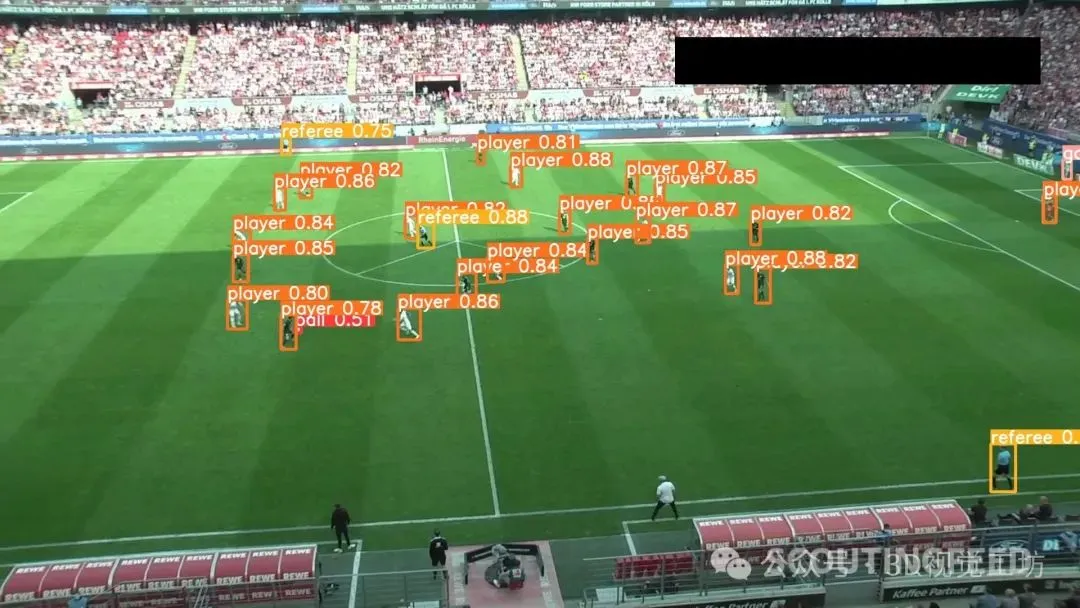
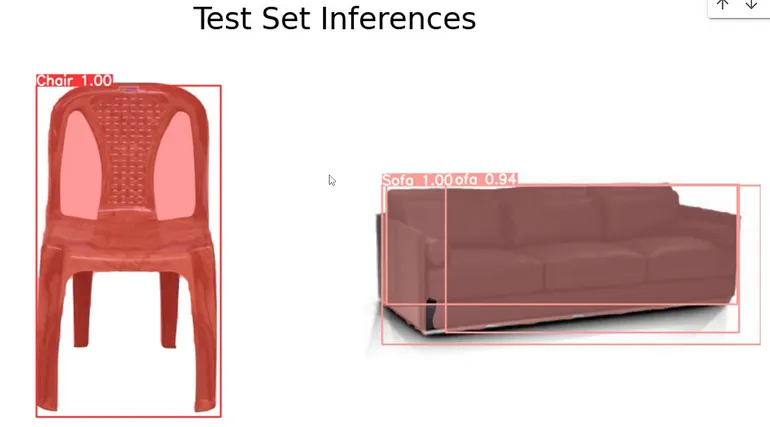
我们的模型成功地识别了球员、裁判员和守门员。
5. 结论
YOLOv9是由Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao发布的一种新的计算机视觉模型架构。可以使用YOLOv9架构训练目标检测模型。
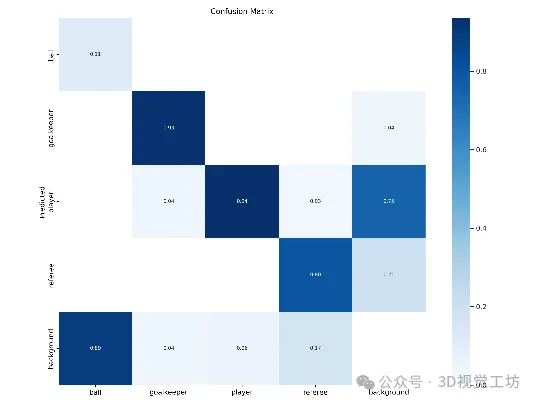
在本指南中,我们演示了如何在自定义数据集上运行推理和训练YOLOv9模型。我们克隆了YOLOv9项目代码,下载了模型权重,然后使用默认的COCO权重进行推理。然后,我们使用足球运动员检测数据集训练了一个微调的模型。我们回顾了训练图和混淆矩阵,然后在来自验证集的图像上测试了模型。
Ref
[1] YOLOv9:在自定义数据上进行图像分割训练:https://mp.weixin.qq.com/s/U1VLKWREGCtwDjD7gmTlxA
[2] 【手把手教学】如何在YOLOv9上训练自己的目标检测数据集: https://mp.weixin.qq.com/s/Fg66Keg1ttHCNl_pLKp5Fw
[3] 【YOLO系列】YOLOv9论文超详细解读(翻译 +学习笔记):https://blog.csdn.net/weixin_43334693/article/details/136383022
[4] YOLOv9论文:《YOLOv9: 利用可编程梯度信息学习你想学习的内容》
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information 论文链接:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
[5] YOLOV9开源项目:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
[6] 一文搞懂YOLOv9训练推理全流程|YOLOv9你绝对不知道的细节!: https://zhuanlan.zhihu.com/p/690115605
作者:楚千羽
出处:https://www.cnblogs.com/chuqianyu/
本文来自博客园,本文作者:楚千羽,转载请注明原文链接:https://www.cnblogs.com/chuqianyu/p/18149845
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利!
