浅谈 Attention 机制
01 引言
Attention 机制并不是一个新概念,在 90 年代就有学者提出,其最早产生并且应用在计算机视觉(CV)领域,之后在自然语言处理(NLP)领域快速发展。
02 Attention的本质
Attention 机制来源于人类的视觉注意力机制,可以算是仿生学的一个应用。
人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,即常说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息,这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
03 Attention的结构
从本质上理解,Attention 需要聚焦到重要信息上,那么怎么实现呢?可以通过权重来进行控制,权重越大越聚焦于对应的 value 值,权重代表了信息的重要性,value 就是对应的信息。那么权重系数又是怎么计算得到呢?通过 query 和 key 可以计算两者的相似性或相关性,再进行 softmax 类归一化处理,就能得到 query 在每个 key 上的权重。
抽象来说,注意力函数可以描述为将查询向量 Querys 和一组键值对向量 (Keys, Values) 映射到输出向量 Output,其中 Output 计算为值 Values 的加权和,其中分配给每个值的权重由查询向量 Querys 与相应键向量 Keys 进行计算得到,常见的方法有向量点积、Cosine 相似性、MLP 网络。由于权重根据具体产生的方法不同其数值取值范围也不相同,需要引入 softmax 的计算方式进行数值转换,一方面可以进行归一化,将权重分值调整为所有元素权重之和为1的概率分布,另一方面可以通过 softmax 的内在机制更加突出重要元素的权重。
整体架构如下图所示:
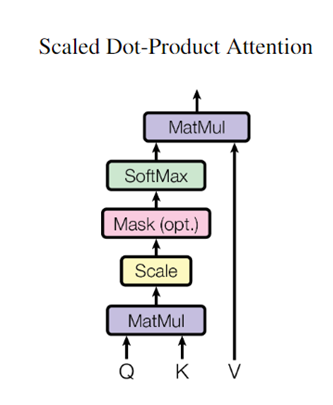
图源:论文《Attention is all you need》
Google 给出的 Attention 具体公式定义为:
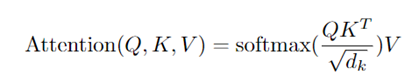
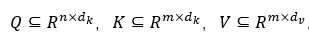
Q 是词的查询向量,K 是“被查”向量,V 是内容向量。K 和 V 一一对应,代表着key-value 的映射关系。其中参数 dk 起到调节内积大小的作用(太大的话 softmax 后会存在梯度消失问题)。
从几何角度看,点积是两个向量的长度与它们夹角余弦的积。如果两向量夹角为 90 度,那么结果为 0,代表两个向量线性无关。如果两个向量夹角越小,两向量在方向上相关性也越强,结果也越大。点积反映了两个向量在方向上的相似度,结果越大越相似。
如果忽略 softmax 的话,那么事实上它就是三个n×dk,dk×m,m×dv 的矩阵相乘,最后的结果就是一个矩阵。所以一个 Attention 层也可以理解为,将序列 Q 的编码形成一个新的序列。
04 Attention的代码实现
注意力机制的计算可以分为两步:
-
- 在所有输入信息上计算注意力分布
-
- 根据注意力分布来计算输入信息的加权平均
下面是基于 torch 框架构建的一个简单 Attention 模块,包含一个线性层(用于计算 attention 分数)以及一个可训练的参数v。
代码仅为示例,实际的 Attention 模型可能需要根据具体情况进行更复杂的设计。
import torch
import torch.nn as nn
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size))
self.v.requires_grad = True
# forward 方法中,通过输入隐藏状态和编码器输出,计算得到attention分数
def forward(self, hidden, encoder_outputs):
seq_len = encoder_outputs.size(0)
hidden = hidden.repeat(seq_len, 1, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
energy = torch.tanh(self.attn(torch.cat([hidden, encoder_outputs], dim=2)))
energy = energy.permute(0, 2, 1)
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)
attention_scores = torch.bmm(v, energy).squeeze(1)
# 使用softmax将 attention 分数转化为注意力权重
return nn.functional.softmax(attention_scores, dim=1)
05 Attention机制的优点
-
- 参数少:
模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少,所以对算力要求也就更小。
- 参数少:
-
- 速度快:
Attention 解决 RNN 不能并行计算的问题,每一步计算不依赖于上一步的计算结果,因此可和CNN一样并行处理。
- 速度快:
-
- 效果好:
在 Attention 机制引入之前,长距离的信息会被弱化,而 Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。
- 效果好:
06 结语
Attention 目前发展非常迅速,从自注意力机制到多头注意力机制到多查询注意力机制、分组注意力机制等,同时也衍生出了许多变体,广泛应用到计算机视觉、自然语言处理、小样本学习、推荐系统等多种任务上。
参考资料
1.《Attention is all you need》原论文:https://arxiv.org/abs/1706.03762
2. 深度学习中的注意力模型:https://zhuanlan.zhihu.com/p/37601161
3. attention机制原理及简单实现:https://www.jianshu.com/p/1d67638139da
4.【NLP相关】深入理解attention机制:https://blog.csdn.net/qq_41667743/article/details/108936166
作者:楚千羽
出处:https://www.cnblogs.com/chuqianyu/
本文来自博客园,本文作者:楚千羽,转载请注明原文链接:https://www.cnblogs.com/chuqianyu/p/18134796
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利!

