算法工程师面试常考手撕题(二)—— AI深度学习算法
手撕 IOU
IoU(Intersection over Union),又称重叠度/交并比。
1 NMS:当在图像中预测多个proposals、pred bboxes时,由于预测的结果间可能存在高冗余(即同一个目标可能被预测多个矩形框),因此可以过滤掉一些彼此间高重合度的结果;具体操作就是根据各个bbox的score降序排序,剔除与高score bbox有较高重合度的低score bbox,那么重合度的度量指标就是IoU;
2 mAP:得到检测算法的预测结果后,需要对pred bbox与gt bbox一起评估检测算法的性能,涉及到的评估指标为mAP,那么当一个pred bbox与gt bbox的重合度较高(如IoU score > 0.5),且分类结果也正确时,就可以认为是该pred bbox预测正确,这里也同样涉及到IoU的概念;
提到IoU,大家都知道怎么回事,讲起来也都头头是道,我拿两个图示意下(以下两张图都不是本人绘制):

绿框:gt bbox;红框:pred bbox;那么IoU的计算如下:
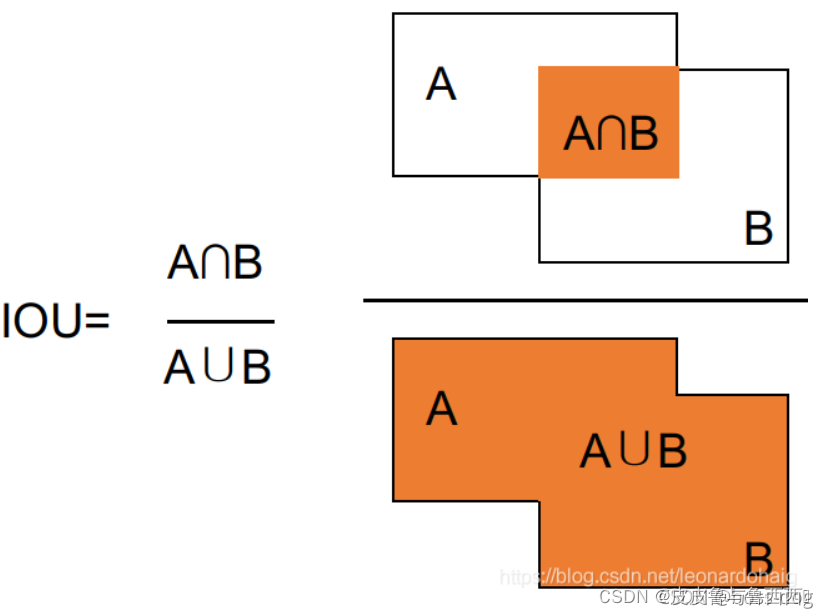
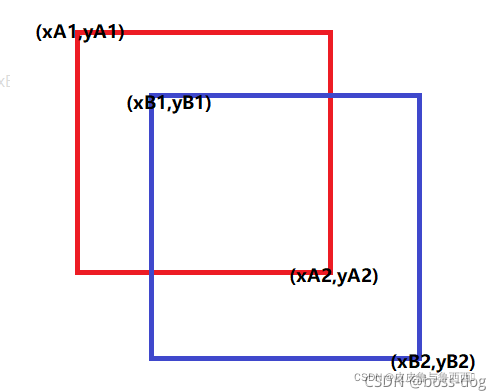
简单点说,就是gt bbox、pred bbox交集的面积 / 二者并集的面积;好了,现在理解IoU的原理和计算方法了,就应该思考如何函数实现了。注意:求交区域的时候,一定要和0比较大小,如果是负数就说明压根不相交
import numpy as np
def ComputeIOU(boxA, boxB):
## 计算相交框的坐标
x1 = np.max([boxA[0], boxB[0]])
x2 = np.min([boxA[2], boxB[2]])
y1 = np.max([boxA[1], boxB[1]])
y2 = np.min([boxA[3], boxB[3]])
## 计算交区域,并区域,及IOU
interArea = np.max([x2-x1+1, 0])*np.max([y2-y1+1,0]) ##一定要和0比较大小,如果是负数就说明压根不相交
unionArea = (boxA[2]-boxA[0]+1)*(boxA[3]-boxA[1]+1) + (boxB[2]-boxB[0]+1)*(boxB[3]-boxB[1]+1)-interArea
iou = interArea/unionArea
return iou
boxA = [1,1,3,3]
boxB = [2,2,4,4]
IOU = ComputeIOU(boxA, boxB)
手撕NMS
本笔记介绍目标检测的另一个基本概念:NMS(non-maximum suppression),做目标检测的同学想必对这个词语耳熟能详了;
在检测图像中的目标时,不可避免地会检出很多bboxes + cls scores,这些bbox之间有很多是冗余的,一个目标可能会被多个bboxes检出,如果所有bboxes都输出,就很影响体验和美观了(同一个目标输出100个bboxes,想想都后怕~),一种方案就是提升cls scores的阈值,减少bbox数量的输出;另一种方案就是使用NMS,将同一目标内的bboxes按照cls score + IoU阈值做筛选,剔除冗余地、低置信度的bbox;
可能又会问了:为什么目标检测时,会有这么多无效、冗余检测框呢?这个。。。我的理解,是因为图像中没有目标尺度、位置的先验知识,为保证对目标的高召回,就必须使用滑窗、anchor / default bbox密集采样的方式,尽管检测模型能对每个anchor / default bbox做出 cls + reg,可以一定程度上剔除误检,但没有结合检出bbox的cls score + IoU阈值做筛选,而NMS就可以做到这一点;
NMS操作流程
NMS用于剔除图像中检出的冗余bbox,标准NMS的具体做法为:
step-1:将所有检出的output_bbox按cls score划分(如pascal voc分20个类,也即将output_bbox按照其对应的cls score划分为21个集合,1个bg类,只不过bg类就没必要做NMS而已);
step-2:在每个集合内根据各个bbox的cls score做降序排列,得到一个降序的list_k;
step-3:从list_k中top1 cls score开始,计算该bbox_x与list中其他bbox_y的IoU,若IoU大于阈值T,则剔除该bbox_y,最终保留bbox_x,从list_k中取出;
step-4:选择list_k中top2 cls score(步骤3取出top 1 bbox_x后,原list_k中的top 2就相当于现list_k中的top 1了,但如果step-3中剔除的bbox_y刚好是原list_k中的top 2,就依次找top 3即可,理解这么个意思就行),重复step-3中的迭代操作,直至list_k中所有bbox都完成筛选;
step-5:对每个集合的list_k,重复step-3、4中的迭代操作,直至所有list_k都完成筛选;
以上操作写的有点绕,不过如果理解NMS操作流程的话,再结合下图,应该还是非常好理解的;

# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0] # pred bbox top_x
y1 = dets[:, 1] # pred bbox top_y
x2 = dets[:, 2] # pred bbox bottom_x
y2 = dets[:, 3] # pred bbox bottom_y
scores = dets[:, 4] # pred bbox cls score
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # pred bbox areas
order = scores.argsort()[::-1] # 对pred bbox按score做降序排序,对应step-2
keep = [] # NMS后,保留的pred bbox
while order.size > 0:
i = order[0] # top-1 score bbox
keep.append(i) # top-1 score的话,自然就保留了
xx1 = np.maximum(x1[i], x1[order[1:]]) # top-1 bbox(score最大)与order中剩余bbox计算NMS
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter) # 无处不在的IoU计算~~~
inds = np.where(ovr <= thresh)[0] # 这个操作可以对代码断点调试理解下,结合step-3,我们希望剔除所有与当前top-1 bbox IoU > thresh的冗余bbox,那么保留下来的bbox,自然就是ovr <= thresh的非冗余bbox,其inds保留下来,作进一步筛选
order = order[inds + 1] # 保留有效bbox,就是这轮NMS未被抑制掉的幸运儿,为什么 + 1?因为ind = 0就是这轮NMS的top-1,剩余有效bbox在IoU计算中与top-1做的计算,inds对应回原数组,自然要做 +1 的映射,接下来就是step-4的循环
return keep # 最终NMS结果返回
if __name__ == '__main__':
dets = np.array([[100,120,170,200,0.98],
[20,40,80,90,0.99],
[20,38,82,88,0.96],
[200,380,282,488,0.9],
[19,38,75,91, 0.8]])
py_cpu_nms(dets, 0.5)
另一个版本的NMS:
对整个bboxes排序的写法
import numpy as np
def nms(dets, iou_thred, cfd_thred):
if len(dets)==0: return []
bboxes = np.array(dets)
## 对整个bboxes排序
bboxes = bboxes[np.argsort(bboxes[:,4])]
pick_bboxes = []
# print(bboxes)
while bboxes.shape[0] and bboxes[-1,-1] >= cfd_thred:
bbox = bboxes[-1]
x1 = np.maximum(bbox[0], bboxes[:-1,0])
y1 = np.maximum(bbox[1], bboxes[:-1,1])
x2 = np.minimum(bbox[2], bboxes[:-1,2])
y2 = np.minimum(bbox[3], bboxes[:-1,3])
inters = np.maximum(x2-x1+1, 0) * np.maximum(y2-y1+1, 0)
unions = (bbox[2]-bbox[0]+1)*(bbox[3]-bbox[1]+1) + (bboxes[:-1,2]-bboxes[:-1,0]+1)*(bboxes[:-1,3]-bboxes[:-1,1]+1) - inters
ious = inters/unions
keep_indices = np.where(ious<iou_thred)
bboxes = bboxes[keep_indices] ## indices一定不包括自己
pick_bboxes.append(bbox)
return np.asarray(pick_bboxes)
### 肌肉记忆了
import numpy as np
def nms(preds, iou_thred=0.5, score_thred=0.5):
## preds: N * 5, [x1, y1, x2, y2, score]
orders = np.argsort(preds[:,4])
det = []
arears = (preds[:, 2] - preds[:, 0]) * (preds[:, 3] - preds[:, 1])
while orders.shape[0] and preds[orders[-1], 4] >= score_thred:
pick = preds[orders[-1]]
xx1 = np.maximum(pick[0], preds[orders[:-1], 0])
yy1 = np.maximum(pick[1], preds[orders[:-1], 1])
xx2 = np.minimum(pick[2], preds[orders[:-1], 2])
yy2 = np.minimum(pick[3], preds[orders[:-1], 3])
inters = np.maximum((xx2-xx1), 0) * np.maximum((yy2-yy1), 0)
unions = arears[orders[-1]] + arears[orders[:-1]] - inters
iou = inters / unions
keep = iou < iou_thred
orders = orders[:-1][keep]
det.append(pick)
return np.asarray(det)
dets = np.asarray([[187, 82, 337, 317, 0.9], [150, 67, 305, 282, 0.75], [246, 121, 368, 304, 0.8]])
nms(dets)
dets = [[187, 82, 337
, 317, 0.9], [150, 67, 305, 282, 0.75], [246, 121, 368, 304, 0.8]]
dets_nms = nms(dets, 0.5, 0.3)
print(dets_nms)
不改变bboxes,维护orders的写法:
始终维护orders,代表到原bboxes的映射(map)
优化1:仅维护orders,不改变原bboxes
优化2:提前计算好bboxes的面积,以免在循环中多次重复计算
import numpy as np
def nms(dets, iou_thred, cfd_thred):
if len(dets)==0: return []
bboxes = np.array(dets)
## 维护orders
orders = np.argsort(bboxes[:,4])
pick_bboxes = []
x1 = bboxes[:,0]
y1 = bboxes[:,1]
x2 = bboxes[:,2]
y2 = bboxes[:,3]
areas = (x2-x1+1)*(y2-y1+1) ## 提前计算好bboxes面积,防止在循环中重复计算
while orders.shape[0] and bboxes[orders[-1],-1] >= cfd_thred:
bbox = bboxes[orders[-1]]
xx1 = np.maximum(bbox[0], x1[orders[:-1]])
yy1 = np.maximum(bbox[1], y1[orders[:-1]])
xx2 = np.minimum(bbox[2], x2[orders[:-1]])
yy2 = np.minimum(bbox[3], y2[orders[:-1]])
inters = np.maximum(xx2-xx1+1, 0) * np.maximum(yy2-yy1+1, 0)
unions = areas[orders[-1]] + areas[orders[:-1]] - inters
ious = inters/unions
keep_indices = np.where(ious<iou_thred)
pick_bboxes.append(bbox)
orders = orders[keep_indices]
return np.asarray(pick_bboxes)
dets = [[187, 82, 337, 317, 0.9], [150, 67, 305, 282, 0.75], [246, 121, 368, 304, 0.8]]
dets_nms = nms(dets, 0.5, 0.3)
print(dets_nms)
手撕 正向卷积
torch官方的Conv2d需要传入的参数:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
输入和输出的特征图尺寸大小关系:
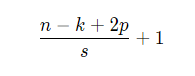
1.对于padding的处理是重开一个输出特征图尺寸的矩阵,然后给非padding区域赋值。或者直接用np.pad函数
2.卷积通过逐元素相乘并求和实现。使用numpy的np.multiply和np.sum函数。在inputs上逐行和逐列操作并赋值到outputs中。np.multiply可以广播,所以可以同时对多个卷积核操作,例如卷积核251633与特征图区域1633经过multiply和sum后得到251,就是输出特征图该像素点上的多通道特征。这样可以省去对各卷积核的一层循环。
3.直接利用range中的间隔模拟stride,由于总共有n-k+2p-1个有效位置,因此range的边界是n-k+2p-1。
import numpy as np
def conv2d(inputs, kernels, padding, bias, stride):
c, w, h = inputs.shape
# inputs_pad = np.zeros((c,w+2*padding,h+2*padding))
# inputs_pad[:, padding:w+padding, padding:h+padding] = inputs
# print(inputs_pad.shape, '\n', inputs_pad)
# inputs = inputs_pad
inputs = np.pad(inputs, ((0,0),(1,1),(1,1))) ## 可以直接用np.pad函数实现pad
kernels_num, kernel_size = kernels.shape[0], kernels.shape[2]
outputs = np.ones((kernels_num, (w-kernel_size+2*padding)//stride+1, (h-kernel_size+2*padding)//stride+1))
for i in range(0, w-kernel_size+2*padding+1, stride):
for j in range(0, h-kernel_size+2*padding+1, stride):
outputs[:, i//stride, j//stride] = np.sum(np.multiply(kernels, inputs[:, i:i+kernel_size, j:j+kernel_size]), axis=(1,2,3))+bias
return outputs
inputs = np.ones((16,9,9))
kernels = np.ones((25,16,3,3))
bias = np.arange(1,kernels.shape[0]+1)
stride = 2
padding = 1
outputs = conv2d(inputs, kernels, padding, bias, stride)
print("input{}".format(inputs.shape))
print("kenerls{}, stride{}".format(kernels.shape, stride))
print("output{}".format(outputs.shape))
print(outputs)
手撕 池化
torch官方的Pool2d需要传入的参数
nn.MaxPool2d(kernel_size=2, stride=(2, 1), padding=(0, 1))
没写padding了,stride在w和h方向也没区分。。。
## 池化操作
def pooling(inputs, pool_size, stride, mode='max'):
c, w, h = inputs.shape
k = pool_size
outputs = np.zeros((c,(w-k)//stride+1, (h-k)//stride+1))
if mode == 'max':
for i in range(0, w-k+1, stride):
for j in range(0, h-k+1, stride):
outputs[:, i//stride, j//stride] = np.max(inputs[:,i:i+k,j:j+k], axis=(1,2))
return outputs
elif mode == 'avg':
for i in range(0, w-k+1, stride):
for j in range(0, h-k+1, stride):
outputs[:, i//stride, j//stride] = np.mean(inputs[:,i:i+k,j:j+k], axis=(1,2))
return outputs
else:
raise ValueError('not support this mode, choose "max" or "avg" ')
pool_size = 2
stride = 2
mode = 'max'
inputs = np.arange(1,76).reshape((3,5,5))
print("inputs:{}".format(inputs.shape), '\n',inputs)
outputs = pooling(inputs, pool_size, stride, mode)
print("outputs:{}".format(outputs.shape), '\n',outputs)
手撕BN
正向传播

反向传播(求导)
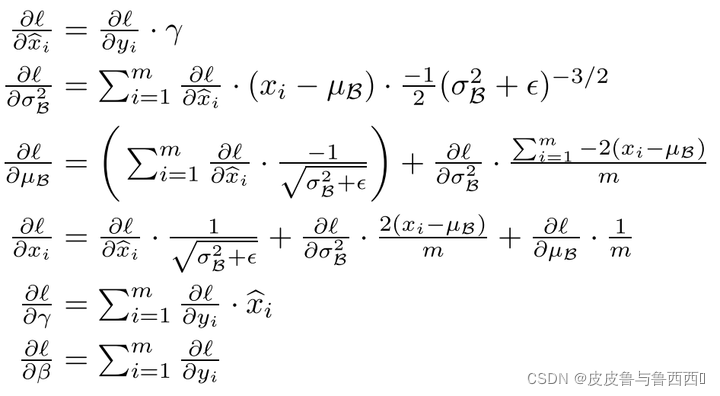
#### 手撕 BN
import torch
from torch import nn
def batch_norm(X, parameters, moving_mean, moving_var, eps, momentum):
#### 预测模式下
if not torch.is_grad_enable():
X_hat = (X-moving_mean) / torch.sqrt(moving_var + eps)
return x_hat
### 训练模式下
else:
assert len(X.shape) in (2, 4)
#### 全连接层
if len(X.shape) == 2:
mean = X.mean(dim=0)
var = ((X-mean)**2).mean(dim=0)
### 卷积层
elif len(X.shape) == 4:
mean = X.mean(dim=(0,2,3))
var = ((X-mean)**2).mean(dim=(0,2,3))
X_hat = (X-mean) / torch.sqrt(var + eps)
moving_mean = momentum*moving_mean + (1-momentum)*mean
moving_var = momentum*moving_var + (1-momentum)*moving_var
Y = parameters['gamma'] * X_hat + parameters['beta']
return Y, moving_mean, moving_var
class BatchNorm(nn.Module):
def __ init__(self, num_features, num_dims):
super.__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
self.parameters = {}
self.parameters['gamma'] = nn.parameters(torch.ones(shape))
self.parameters['beta'] = nn.parametersa(torch.zeros(shape))
self.moving_mean, self.moving_var = torch.ones(shape), torch.zeros(shape)
def forward(self, X):
Y, self.moving_mean, self.moving_var = batch_norm(X, self.parameters, self.moving_mean, self.moving_var, eps=1e-5, momentum=0.9)
return Y
手撕resnet
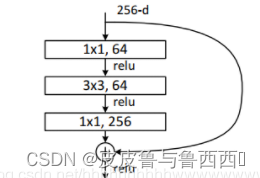
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResNetBlock(nn.Module):
def __init__(self):
super(ResNetBlock, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(256, 64, 1, padding='same'),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding='same'),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 256, 1, padding='same')
)
def forward(self, x):
residual = self.bottleneck(x)
outputs = x + residual
return outputs
resnet = ResNetBlock()
inputs = torch.rand(4, 256, 16, 16)
outputs = resnet(inputs)
print(outputs.shape, outputs)
手撕 pytorch搭建简单的全连接神经网络(MLP)训练
#### 手撕 torch神经网络
import torch
from torch import nn
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
### 定义模型
### N,1 -> N,10 -> N,10 -> N,1
class Net(nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net, self).__init__()
self.dense1 = nn.Linear(n_input, n_hidden)
self.dense2 = nn.Linear(n_hidden, n_hidden)
self.out = nn.Linear(n_hidden, n_output)
def forward(self, x):
x = self.dense1(x)
x = F.relu(x)
x = self.dense2(x)
x = F.relu(x)
x = self.out(x)
return x
model = Net(1, 20, 1)
print(model)
### 准备数据
x = torch.unsqueeze(torch.linspace(-1,1,100),dim=1)
y = x.pow(3)+0.1*torch.randn(x.size())
x , y =(Variable(x),Variable(y))
plt.scatter(x.data,y.data)
# 或者采用如下的方式也可以输出x,y
# plt.scatter(x.data.numpy(),y.data.numpy())
plt.show()
#### pipeline
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
loss_func = torch.nn.MSELoss()
for t in range(500):
predict = model(x)
loss = loss_func(predict, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t%5 ==0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), predict.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss = %.4f' % loss.data, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.05)
上面定义模型使用nn.sequential()这种更简单的方式
class Net(torch.nn.Module):
def __init__(self, n_input, n_hidden, n_output):
super(Net4, self).__init__()
self.dense1 = torch.nn.Sequential(
OrderedDict(
[
("dense1", torch.nn.Linear(n_input, n_hidden),
("relu1", torch.nn.ReLU()),
]
))
self.dense2 = torch.nn.Sequential(
OrderedDict([
("dense1", torch.nn.Linear(n_hidden, n_hidden),
("relu2", torch.nn.ReLU()),
])
)
self.out = nn.Linear(n_hidden, n_output)
def forward(self, x):
x= self.dense1(x)
x= self.dense2(x)
x= self.out(x)
return x
结果如下:
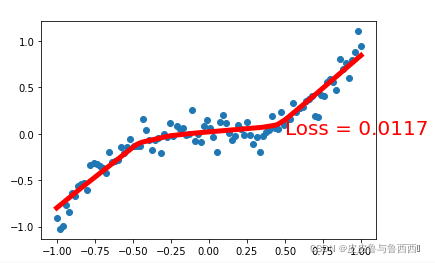
-------------THE END-------------
休息一下~

文章来源于微信公众号
文章链接:
https://zhuanlan.zhihu.com/p/273485367
https://blog.csdn.net/weixin_44398263/article/details/123407466
本文仅用于学术分享,如有侵权,请联系后台作删文处理
作者:楚千羽
出处:https://www.cnblogs.com/chuqianyu/
本文来自博客园,本文作者:楚千羽,转载请注明原文链接:https://www.cnblogs.com/chuqianyu/p/18062881
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利!

