吴恩达Coursera, 机器学习专项课程, Machine Learning:Unsupervised Learning, Recommenders, Reinforcement Learning第三周测验
Practice quiz: Reinforcement learning introduction
第 1 个问题:You are using reinforcement learning to control a four legged robot. The position of the robot would be its _____.
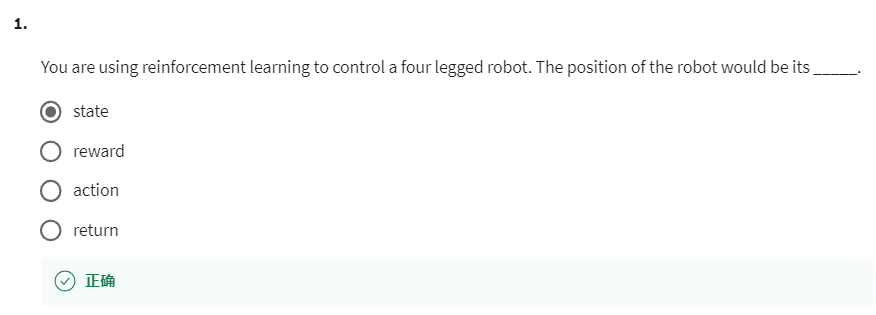
【正确】state
第 2 个问题:You are controlling a Mars rover. You will be very very happy if it gets to state 1 (significant scientific discovery), slightly happy if it gets to state 2 (small scientific discovery), and unhappy if it gets to state 3 (rover is permanently damaged). To reflect this, choose a reward function so that:

【正确】R(1) > R(2) > R(3), where R(1) and R(2) are positive and R(3) is negative.
【解释】Good job!
第 3 个问题:You are using reinforcement learning to fly a helicopter. Using a discount factor of 0.75, your helicopter starts in some state and receives rewards -100 on the first step, -100 on the second step, and 1000 on the third and final step (where it has reached a terminal state). What is the return?
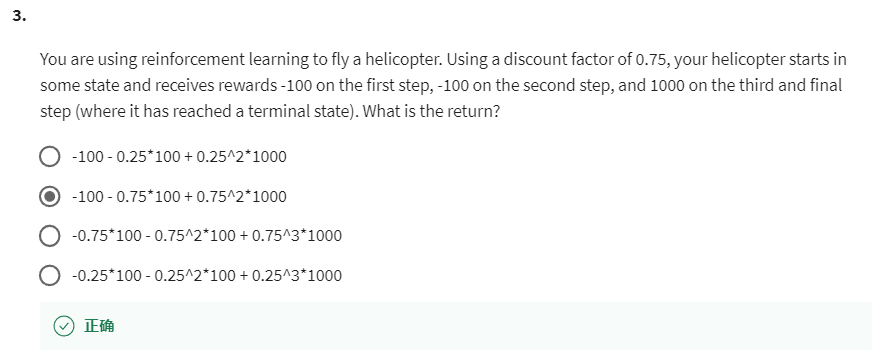
【正确】-100 - 0.75100 + 0.75^21000
第 4 个问题:Given the rewards and actions below, compute the return from state 3 with a discount factor of \gamma = 0.25.

【正确】6.25 Correct
【解释】If starting from state 3, the rewards are in states 3, 2, and 1. The return is 0+(0.25)×0+(0.25) ^2×100=6.25.
Practice quiz: State-action value function
第 1 个问题:Which of the following accurately describes the state-action value function Q(s,a)?

【正确】It is the return if you start from state s, take action a (once), then behave optimally after that.
第 2 个问题:You are controlling a robot that has 3 actions: ← (left), → (right) and STOP. From a given state s, you have computed Q(s, ←) = -10, Q(s, →) = -20, Q(s, STOP) = 0.What is the optimal action to take in state s?

【正确】STOP
第 3 个问题:For this problem, \gamma = 0.25. The diagram below shows the return and the optimal action from each state. Please compute Q(5, ←).
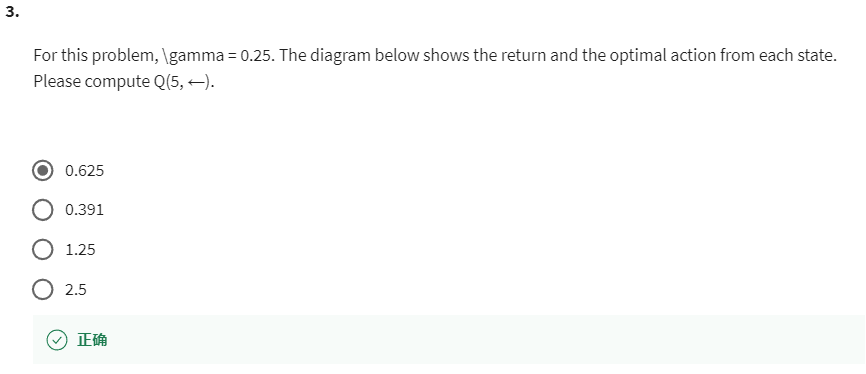
【正确】0.625
Practice quiz: Continuous state spaces
第 1 个问题:The Lunar Lander is a continuous state MDP because:

【正确】The state contains numbers such as position and velocity that are continuous valued
第 2 个问题:In the learning algorithm described in the videos, we repeatedly create an artificial training set to which we apply supervised learning where the input x = (s,a) and the target, constructed using Bellman’s equations, is y = _____?
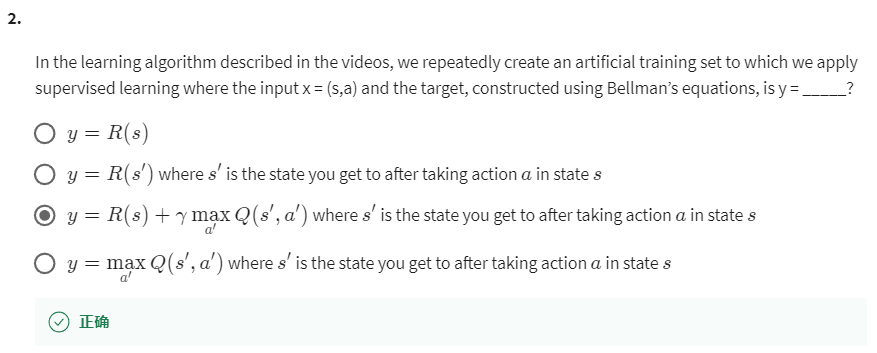
【正确】见上图
第 3 个问题:You have reached the final practice quiz of this class! What does that mean? (Please check all the answers, because all of them are correct!)
【正确】The DeepLearning.AI and Stanford Online teams would like to give you a round of applause!
【正确】You deserve to celebrate!
【正确】Andrew sends his heartfelt congratulations to you!
【正确】What an accomplishment -- you made it!
作者:楚千羽
出处:https://www.cnblogs.com/chuqianyu/
本文来自博客园,本文作者:楚千羽,转载请注明原文链接:https://www.cnblogs.com/chuqianyu/p/16947468.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利!















【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~