调用百度OCR模块进行文字识别
转自:https://www.cnblogs.com/students/p/10826822.html(代码可实现,但是识别效率有点低)
和https://mp.weixin.qq.com/s/RSSOJBm4KsU4EwX6J6Nt7w(这是参考的代码2,代码有问题)
1.登录百度云平台,创建应用

2.编写代码
1 from aip import AipOcr#要安装baidu-aip包,不是aip包 2 import codecs 3 import os 4 #读取图片函数 5 def ocr(path): 6 with open(path,'rb') as f: 7 return f.read() 8 def main(): 9 filename = "c.jpg" 10 print("已经收到,正在处理,请稍后....") 11 app_id = '16193547' 12 api_key = 'B0R5gbezdGSzCY4oIlOpuLy8' 13 secret_key = 'CyevG1PTfpPvkw9vwItPdya09GrzZ462' 14 client = AipOcr(app_id,api_key,secret_key) 15 #读取图片 16 image = ocr(filename) 17 #进程OCR识别 18 dict1 = client.general(image) 19 # print(dict1) 20 with codecs.open(filename + ".txt","w","utf-8") as f: 21 for i in dict1["words_result"]: 22 f.write(str(i["words"] + "\r\n")) 23 print ("处理完成") 24 if __name__ == '__main__': 25 main()
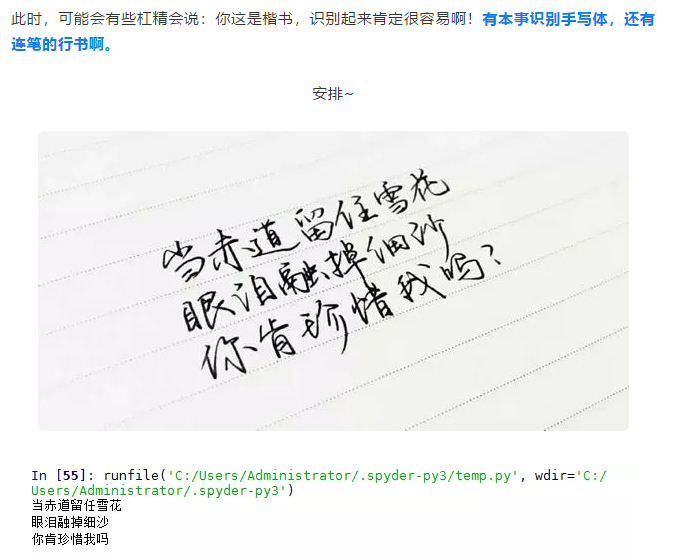
效果图:

3代码2
首先,说个大前提,我这种方法是用来识别图片上的文字的。也就是说,你想把图片上的文字扒下来,用我的方法肯定没错!
1 # 第一步:导包 2 from aip import Aipocr as ocr 3 # 第二步:读取 4 with open(path,'rb') as f: 5 img = f.read() 6 # 第三步:调用 7 cli = ocr(appId, apiKey, secretKey) 8 # 第四步:识别 9 rlt = cli.general(img) 10 # 第五步:输出 11 for line in rlt['words_result']: 12 print(line.get('words'))



作者:楚千羽
出处:https://www.cnblogs.com/chuqianyu/
本文来自博客园,本文作者:楚千羽,转载请注明原文链接:https://www.cnblogs.com/chuqianyu/p/14060650.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面给出原文连接,否则保留追究法律责任的权利!

