HAVING
“where”是一个约束声明,在查询数据库的结果返回之前对数据库中的查询条件进行约束,即在结果返回之
前起作用,且“where”后面不能写“聚合函数”。
“having”是一个过滤声明,是在查询数据库结果返回之后进行过滤,即在结果返回值后起作用,并且
“having”后面可以写“聚合函数”。
where、聚合函数、having在from后面的执行顺序:
where>聚合函数(sum,min,max,avg,count)>having
注意事项 :
1、where 后不能跟聚合函数,因为where执行顺序大于聚合函数。
2、where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数
据,条件中不能包含聚合函数,使用where条件显示特定的行。
3、having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚合函数,使用
having 条件显示特定的组,也可以使用多个分组标准进行分组。
(1) where和having均可使用:
select score name from student where score>60;
select score name from student having score>60;
可用having的原因是已经筛选出score字段,在这种情况下是和where等效的。
(2) 只能用where、不能用having
select score name from student where sex="man"; 正确的
select score name from student having sex="man"; 错误的,因为前面没有筛选sex。
(3) 只能用having、不能用where
select goods_category_id,avg(goods_price) as ag from goods_table group by goods_category having ag>100; 正确的
select goods_category_id,avg(goods_price) as ag from goods_table where ag>100 group by goods_category; 错误的
注意:where 后面要跟的是数据表里的字段,如果我把ag换成avg(goods_price)也是错误的!因为表里没有该字段。而having只是根据前面查询出来的是什么就可以后面接什么。
DISTINCT去重
采用DISTINCT关键字去除返回结果中的重复项,NULL也是一类数据,返回结果中如果有多个null,使用distinct将多个null合并为一条。
select shop_car from shop;
返回的值为:
'''
衣服
办公用品
衣服
厨房用具
厨房用具
厨房用具
厨房用具
'''
select DISTINCT shop_car from shop;
返回值为:
'''
衣服
办公用品
厨房用具
'''
多列使用
多列数据都相同的情况下会被合并,(distinct只能放在第一个字段名之前)
select DISTINCT shop_car,data from shop;
ORDER BY 排序
select * from student order by age;#按照age升序排列
select * from student order by age asc;#按照age升序排列
select * from student order by age desc;#按照age降序排列
select * from student order by age,mobile asc #第一个优先级最高,升序排列,遇到相同时,再按mobile的数据升序排。
limit分页
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是
一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行
的最大数目。初始记录行的偏移量是 0(而不是 1)
举例说明:
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
//为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
//如果只给定一个参数,它表示返回最大的记录行数目:
mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行
REGEXP正则
模式 模式匹配什么
^ 匹配字符串开头
$ 匹配字符串结尾
. 匹配任意单个字符
[...] 匹配方括号间列出的任意字符
[^...] 匹配方括号间未列出的任意字符
p1|p2|p3 交替匹配任意 p1 或 p2 或 p3
* 匹配前面的元素的零次或多次
+ 匹配前面的元素的一次或多次
{n} 匹配前面的元素 n 次
{m,n} 匹配前面的元素 m 至 n 次
查询以小开头红结尾的名字的全部信息
select * from student where name regexp '^小.*红$'
多表连接查询思路
# 多表查询的思路总共就两种
1.子查询
就相当于是我们日常生活中解决问题的方式(一步步解决)
将一条SQL语句的查询结果加括号当做另外一条SQL语句的查询条件
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
子查询的步骤
1.先查jason所在的部门编号
2.根据部门编号去部门表中查找部门名称
2.连表操作
先将多张表拼接到一起 形成一张大表 然后基于单表查询获取数据
eg:以昨天的员工表和部门表为例 查询jason所在的部门名称
连表操作
1.先将员工表和部门表按照某个字段拼接到一起
2.基于单表查询
join
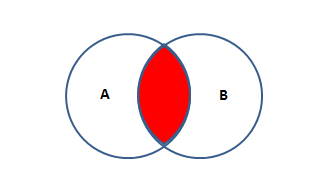
这就是两张表共有的部分(内连接),取交集。
SQL语句:
SELECT * FROM TABLEA A INNER JOIN TABLEB B ON A.KEY=B.KEY;
'''只连接两张表中有对应关系的数据'''
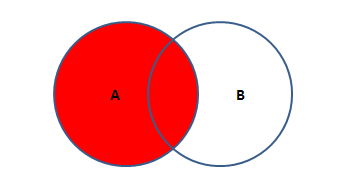
A独有的部分加上和A和B公共 的部分。也叫左外连接。
SQL语句:
SELECT * FROM TABLEA A LEFT JOIN TABLEB B
ON A.KEY = B.KEY;
'''以左表为基准 展示所有的数据 没有对应项则用NULL填充'''
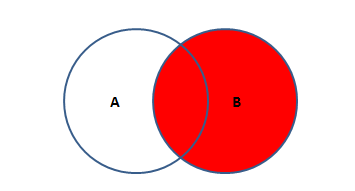
这张图恰好跟左外连接相反(右外连接)。
SQL语句如下:
SELECT * FROM TABLEA A RIGHT JOIN TABLEB B
ON A.KEY = B.KEY;
'''以右表为基准 展示所有的数据 没有对应项则用NULL填充'''
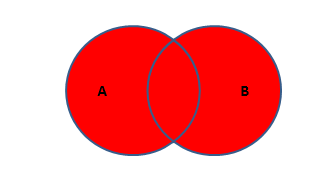
MySQL实现全连接的SQL语句:
SELECT * FROM TABLEA A LEFT JOIN TABLEB B
ON A.KEY = B.KEY
UNION
SELECT * FROM TABLEA A RIGHT JOIN TABLEB B
ON A.KEY = B.KEY;
'''左右两表数据全部展示 没有对应项则用NULL填充'''
可视化软件之Navicat
Navicat可以充当很多数据库软件的客户端 提供了图形化界面能够让我们更加快速的操作数据库
# 下载
navicat有很多版本 并且默认都是收费使用
正版可以免费体验14天
针对这种图形化软件 版本越新越好(不同版本图标颜色不一样 但是主题功能是一样的)
# 使用
内部封装了SQL语句 用户只需要鼠标点点点就可以快速操作
连接数据库 创建库和表 录入数据 操作数据
外键 SQL文件 逆向数据库到模型 查询(自己写SQL语句)
# 使用navicat编写SQL 如果自动补全语句 那么关键字都会变大写
SQL语句注释语法(快捷键与pycharm中的一致 ctrl+?)
多表查询练习
数据准备
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
SET FOREIGN_KEY_CHECKS = 1;
题目
1、查询所有的课程的名称以及对应的任课老师姓名
4、查询平均成绩大于八十分的同学的姓名和平均成绩
7、查询没有报李平老师课的学生姓名
8、查询没有同时选修物理课程和体育课程的学生姓名
9、查询挂科超过两门(包括两门)的学生姓名和班级
-- 1、查询所有的课程的名称以及对应的任课老师姓名
# 1.先明确需要几张表 course表 teacher表
# 2.大致查找一些表中的数据情况
# 3.既然是多表查询 那么查询思路 子查询 连表操作(复杂的SQL需要两者配合使用)
# 4.编写完成后 使用美化功能 将SQL语句规范化
-- SELECT
-- course.cname,
-- teacher.tname
-- FROM
-- course
-- INNER JOIN teacher ON course.teacher_id = teacher.tid;
-- 4、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先明确需要用到几张表 student score
# 2.大致查看一下两张表里面的数据
# 3.先获取平均成绩大于80分的学生信息(按照student_id分组)
-- select score.student_id,avg(num) as avg_num from score group by score.student_id having avg_num>80;
# 4.结果需要从两个表里面的获取 student SQL语句执行之后的虚拟表
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN ( SELECT student_id, avg( num ) AS avg_num FROM score GROUP BY score.student_id HAVING avg_num > 80 ) AS t1 ON student.sid = t1.student_id;
-- 7、查询没有报李平老师课的学生姓名
# 此题有两种思路 第一种是正向查询 第二种是反向查询(先查所有报了李平老师课程的学生id 之后取反即可)
# 1.先明确需要用到几张表 四张表
# 2.先查询李平老师的编号
-- select tid from teacher where tname='李平老师'
# 3.再查李平老师教授的课程编号
-- select cid from course where teacher_id=(select tid from teacher where tname='李平老师')
# 4.根据课程编号 去score表中筛选出所有选了课程的学生编号
-- select distinct student_id from score where course_id in (select cid from course where teacher_id=(select tid from teacher where tname='李平老师'));
# 5.根据学生编号去学生表中反向筛选出没有报李平老师课程的学生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid NOT IN ( SELECT DISTINCT student_id FROM score WHERE course_id IN ( SELECT cid FROM course WHERE teacher_id = ( SELECT tid FROM teacher WHERE tname = '李平老师' ) ) )
-- 8、查询没有同时选修物理课程和体育课程的学生姓名(两门都选了和一门都没选的 都不要 只要选了一门)
# 1.先明确需要用到几张表 三张
# 2.先获取物理课程和体育课程的编号
-- select cid from course where cname in ('物理','体育');
# 3.再去分数表中筛选出选了物理和体育的数据(包含了选了一门和两门 没有选的就已经被排除了)
-- select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 4.如何剔除选了两门的数据(按照学生id分组 然后对课程计数即可)
-- select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
-- group by student_id HAVING count(course_id) = 1;
# 5.根据上述学生id号筛选出学生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid IN (
-- SELECT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN ( SELECT cid FROM course WHERE cname IN ( '物理', '体育' ) )
-- GROUP BY
-- student_id
-- HAVING
-- count( course_id ) = 1
-- )
-- 9、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先明确需要几张表 三张表
# 2.先去score表中筛选出所有不及格的数据
-- select * from score where num < 60;
# 3.如何筛选每个学生挂科的门数(按照学生id分组 对学科计数即可)
-- select student_id from score where num < 60 group by student_id
-- HAVING count(course_id) >= 2;
# 4.由于最终的结果需要取自两张表 所以应该拼接
-- select student.sname,class.caption from class inner join student on class.cid=student.class_id;
# 5.使用步骤3获取到的学生编号 对步骤4的表结果筛选数据
--SELECT
-- student.sname,
-- class.caption
--FROM
-- class
--- INNER JOIN student ON class.cid = student.class_id
--WHERE
-- student.sid IN ( SELECT student_id FROM score WHERE num < 60 GROUP BY student_id HAVING count( course_id ) >= 2 );


 浙公网安备 33010602011771号
浙公网安备 33010602011771号