消息队列
创建
'''
Queue是模块multiprocessing中的一个类我们也可以这样导入from multiprocessing import Queue,创
建时queue = Queue(队列长度)
'''
import multiprocessing
queue = multiprocessing.Queue(队列长度)
方法
方法
描述
put
变量名.put(数据),放入数据(如队列已满,则程序进入阻塞状态,等待队列取出后再放入)
put_nowait
变量名.put_nowati(数据),放入数据(如队列已满,则不等待队列信息取出后再放入,直接报错)
get
变量名.get(数据),取出数据(如队列为空,则程序进入阻塞状态,等待队列加入数据后再取出)
get_nowait
变量名.get_nowait(数据),取出数据(如队列为空,则不等待队列放入信息后取出数据,直接报错),放入数据后立马判断是否为空有时为True,原因是放入值和判断同时进行
qsize
变量名.qsize(),消息数量
empty
变量名.empty()(返回值为True或False),判断是否为空
full
变量名.full()(返回值为True或False),判断是否为满
进程通信
因为进程间不共享全局变量,所以使用Queue进行数据通信,可以在父进程中创建两个字进程,一个往
Queue里写数据,一个从Queue里取出数据。
import multiprocessing
import time
def write_queue (queue ):
for i in range (10 ):
if queue.full():
print ("队列已满!" )
break
queue.put(i)
print (i)
time.sleep(0.5 )
def read_queue (queue ):
while True :
if queue.empty():
print ("---队列已空---" )
break
result = queue.get()
print (result)
if __name__ == '__main__' :
queue = multiprocessing.Queue(3 )
p1 = multiprocessing.Process(target=write_queue, args=(queue,))
p1.start()
p1.join()
p2 = multiprocessing.Process(target=read_queue, args=(queue,))
p2.start()
执行结果
0
1
2
队列已满!
0
1
2
---队列已空 - --
IPC机制
from multiprocessing import Queue, Process
"""
一.主进程跟子进程借助于队列通信
二.子进程跟子进程借助于队列通信
"""
def producer (A ):
A.put('准备服务' )
def consumer (A ):
print (A.get())
if __name__ == '__main__' :
A = Queue()
B = Process(target=producer,args=(A,))
B1 = Process(target=consumer,args=(A,))
B.start()
B1.start()
生产者消费者模型
为什么要使用生产者消费者模型?
生产者消费者模型当中有两大类重要的角色,一个是生产者(负责造数据的任务),另一个是消费者
(接收造出来的数据进行进一步的操作)。
在并发编程中,如果生产者处理速度很快,而消费者处理速度比较慢,那么生产者就必须等待消费者处理
完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为
了解决这个等待的问题,就引入了生产者与消费者模型。让它们之间可以不停的生产和消费。
实现生产者消费者模型三要素:
1 、生产者
2 、消费者
3 、队列(或其他的容哭器,但队列不用考虑锁的问题)
什么时候用这个模型?
程序中出现明显的两类任务,一类任务是负责生产,另外一类任务是负责处理生产的数据的(如爬虫)
用该模型的好处?
1 、实现了生产者与消费者的解耦和
2 、平衡了生产力与消费力,就是生产者一直不停的生产,消费者可以不停的消费,因为二者不再是直接
沟通的,而是跟队列沟通的。
实现
模型:生产者+媒介(队列)+消费者(用到的就是IPC机制)
这里队列用JoinableQueue这个模块,该模块有以下几个方法:
JoinableQueue()内有自带计数器,每当队列放一个数据的时候,会自动+1
task_done()方法,每从队列取出一个数据的时候,会自动减1
q.join(),当计数器为0 时候才会执行
同时:将消费者进程设置成守护进程,这样q.join()执行完毕的时候,消费者子进程也会跟着结束
c1.daemon=True
from multiprocessing import Process, Queue, JoinableQueue
import time
import random
def productor (name, food, q ):
for i in range (1 ,4 ):
data="%s做好了%s%s" %(name,food,i)
time.sleep(random.randint(1 ,3 ))
q.put(data)
print (data)
def customer (name, q ):
while True :
food=q.get()
time.sleep(random.randint(1 ,3 ))
print ("%s吃了%s" %(name,food))
q.task_done()
if __name__ == '__main__' :
q = JoinableQueue()
p1 = Process(target=productor, args=('alex' , '包子' , q,))
p2 = Process(target=productor, args=('egon' , '肠粉' , q,))
c1=Process(target=customer,args=('李浩' , q,))
c2 = Process(target=customer, args=('猪哥' , q,))
c1.daemon=True
c2.daemon=True
p1.start()
p2.start()
c1.start()
c2.start()
p1.join()
p2.join()
q.join()
"""执行完上述的join方法表示消费者也已经消费完数据了"""
执行结果:
egon做好了肠粉1
alex做好了包子1
李浩吃了egon做好了肠粉1
猪哥吃了alex做好了包子1
egon做好了肠粉2
李浩吃了egon做好了肠粉2
alex做好了包子2
egon做好了肠粉3
猪哥吃了alex做好了包子2
alex做好了包子3
李浩吃了egon做好了肠粉3
猪哥吃了alex做好了包子3
线程
有了进程为什么要有线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计
算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程
还是有很多缺陷的,主要体现在两点上:
进程只能在一个时间干—件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了︰如果把我们上课的过程看成一个进
程的话,那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课
的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候
就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然
有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,即使你想趁此时思考一下刚才
没听懂的一个问题都不行,这是其二,
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并
行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制―一线程。
'''
开设线程的消耗远远小于进程
开进程
1.申请内存空间
2.拷贝代码
开线程
一个进程内可以开设多个线程 无需申请内存空间、拷贝代码
一个进程内的多个线程数据是共享的
'''
线程和进程的区别
线程与进程的区别可以归纳为以下4 点:
1 )地址空间和其它资源(如打开文件)∶进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
2 )通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信――需要进程同步和互斥手段的辅助,以保证数据的—致性。
3 )调度和切换:线程上下文切换比进程上下文切换要快得多。
4 )在多线程操作系统中,进程不是—个可执行的实体。
创建线程的两种方法
第一种
from threading import Thread
def test (name ):
print (f'{name} ' )
name = '春游去动物园'
t = Thread(target=test, args=(name,))
t.start()
第二种
from threading import Thread
class Mythread (Thread ):
def __init__ (self, username ):
super ().__init__()
self.username = username
def run (self ):
print (f'{self.username} ' )
t = Mythread('春游去动物园' )
t.start()
join
这里的join方法和进程中的用法一致。
join方法会让主线程等待子线程执行完后再去继续执行主线程后的代码。
from threading import Thread
import time
def test (name ):
time.sleep(3 )
print (f'{name} ' )
name = '春游去动物园'
t = Thread(target=test, args=(name,))
t.start()
t.join()
print ('主线程结束' )
"""
主线程为什么要等着子线程结束才会结束整个进程
因为主线程结束也就标志着整个进程的结束 要确保子线程运行过程中所需的各项资源
"""
同一个进程内的多个线程数据共享
from threading import Thread
import time
name = '春游去动物园'
def test ():
time.sleep(3 )
global name
name = '金'
print (f'{name} ' )
t = Thread(target=test)
t.start()
t.join()
print (name)
线程属性和方法
threading.currentThread(): 返回当前的线程变量。
threading.enumerate (): 返回一个包含正在运行的线程的list 。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.active_count: 返回正在运行的线程数量,与len (threading.enumerate ())有相同的结果。
threading.current_thread().name:获取当前线程的名字。
守护线程
Thread类有一个名为deamon的属性,标志该线程是否为守护线程,默认值为False ,当为设为True 是表
示设置为守护线程。是否是守护线程有什么区别呢?
当deamon值为True ,即设为守护线程后,只要主线程结束了,无论子线程代码是否结束,都得跟着结
束,这就是守护线程的特征。另外,修改deamon的值必须在线程start()方法调用之前,否则会报错。
from threading import Thread, current_thread, active_count, currentThread, enumerate
import time
def test ():
time.sleep(3 )
name = '金'
print (f'{name} ' )
t = Thread(target=test, daemon=True )
t.start()
t.join()
print (active_count())
print (current_thread().name)
GIL全局解释器锁
"""纯理论 不影响编程 只不过面试的时候可能会被问到"""
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
"""
1.回顾
python解释器的类别有很多
Cpython Jpython Ppython
垃圾回收机制
应用计数、标记清除、分代回收
GIL只存在于CPython解释器中,不是python的特征
GIL是一把互斥锁用于阻止同一个进程下的多个线程同时执行
原因是因为CPython解释器中的垃圾回收机制不是线程安全的
反向验证GIL的存在 如果不存在会产生垃圾回收机制与正常线程之间数据错乱
GIL是加在CPython解释器上面的互斥锁
同一个进程下的多个线程要想执行必须先抢GIL锁 所以同一个进程下多个线程肯定不能同时运行 即无法利用多核优势
强调:同一个进程下的多个线程不能同时执行即不能利用多核优势
很多不懂python的程序员会喷python是垃圾 速度太慢 有多核都不能用
反怼:虽然用一个进程下的多个线程不能利用多核优势 但是还可以开设多进程!!!
再次强调:python的多线程就是垃圾!!!
反怼:要结合实际情况
如果多个任务都是IO密集型的 那么多线程更有优势(消耗的资源更少)
多道技术:切换+保存状态
如果多个任务都是计算密集型 那么多线程确实没有优势 但是可以用多进程
CPU越多越好
以后用python就可以多进程下面开设多线程从而达到效率最大化
"""
1. 所有的解释型语言都无法做到同一个进程下多个线程利用多核优势
2. GIL在实际编程中其实不用考虑
为什么有 GIL?
GIL,是最流行的 Python 解释器 CPython 中的一个技术术语。它的意思是全局解释器锁,本质上是类
似操作系统的 Mutex。每一个 Python 线程,在 CPython 解释器中执行时,都会先锁住自己的线程,阻
止别的线程执行。
当然,CPython 会做一些小把戏,轮流执行 Python 线程。这样一来,用户看到的就是“伪并行”——
Python 线程在交错执行,来模拟真正并行的线程。
CPython 引进 GIL 其实主要就是这么两个原因:
一是设计者为了规避类似于内存管理这样的复杂的竞争风险问题(race condition);
二是因为 CPython 大量使用 C 语言库,但大部分 C 语言库都不是原生线程安全的(线程安全会降低性能和增加复杂度)。
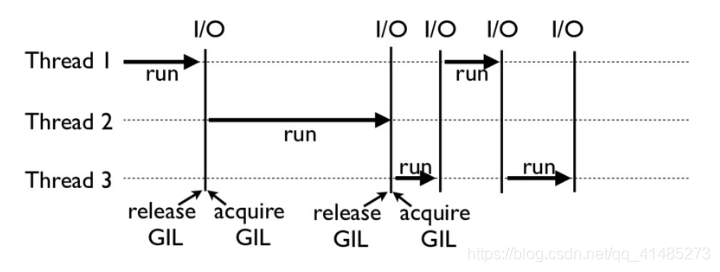
GIL 是如何工作的?
下面这张图,就是一个 GIL 在 Python 程序的工作示例。其中,Thread 1 、2 、3 轮流执行,每一个线
程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL
,以允许别的线程开始利用资源。
细心的你可能会发现一个问题:为什么 Python 线程会去主动释放 GIL 呢?毕竟,如果仅仅是要求
Python 线程在开始执行时锁住 GIL,而永远不去释放 GIL,那别的线程就都没有了运行的机会。
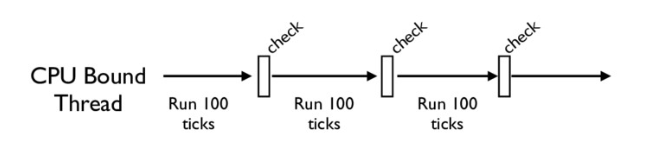
没错,CPython 中还有另一个机制,叫做 check_interval,意思是 CPython 解释器会去轮询
检查线程 GIL 的锁住情况。每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才
能有执行的机会。
不同版本的 Python 中,check interval 的实现方式并不一样。早期的 Python 是 100 个 ticks,
大致对应了 1000 个 bytecodes;而 Python 3 以后,interval 是 15 毫秒。当然,我们不必细究具体
多久会强制释放 GIL,这不应该成为我们程序设计的依赖条件,我们只需明白,CPython 解释器会在一个“合
理”的时间范围内释放 GIL 就可以了。
如何绕过GLIL
学到这里,估计有的 Python 使用者感觉自己像被废了武功一样,觉得降龙十八掌只剩下了一掌。其实
大可不必,你并不需要太沮丧。Python 的 GIL,是通过 CPython 的解释器加的限制。如果你的代码并不需
要 CPython 解释器来执行,就不再受 GIL 的限制。
事实上,很多高性能应用场景都已经有大量的 C 实现的 Python 库,例如 NumPy 的矩阵运算,就都是
通过 C 来实现的,并不受 GIL 影响。
所以,大部分应用情况下,你并不需要过多考虑 GIL。因为如果多线程计算成为性能瓶颈,往往已经有
Python 库来解决这个问题了。
换句话说,如果你的应用真的对性能有超级严格的要求,比如 100us 就对你的应用有很大影响,那我必
须要说,Python 可能不是你的最优选择。
当然,可以理解的是,我们难以避免的有时候就是想临时给自己松松绑,摆脱 GIL,比如在深度学习应用
里,大部分代码就都是 Python 的。在实际工作中,如果我们想实现一个自定义的微分算子,或者是一个特定
硬件的加速器,那我们就不得不把这些关键性能(performance-critical)代码在 C++ 中实现(不
再受 GIL 所限),然后再提供 Python 的调用接口。
总的来说,你只需要重点记住,绕过 GIL 的大致思路有这么两种就够了:
绕过 CPython,使用 JPython(Java 实现的 Python 解释器)等别的实现;
把关键性能代码,放到别的语言(一般是 C++)中实现。
例子
import threading
global_num = 0
def test1 ():
global global_num
for i in range (1000000 ):
global_num += 1
print ("test1" , global_num)
def test2 ():
global global_num
for i in range (1000000 ):
global_num += 1
print ("test2" , global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
执行结果:
test1 1106100
test2 1285549
在上面的例子里,我们创建了两个线程来争夺对global_num的加一操作,但是结果并非我们想要的,所以我们在这里加入了互斥锁
import time
global_num = 0
lock = threading.Lock()
def test1 ():
global global_num
lock.acquire()
for i in range (1000000 ):
global_num += 1
lock.release()
print ("test1" , global_num)
def test2 ():
global global_num
lock.acquire()
for i in range (1000000 ):
global_num += 1
lock.release()
print ("test2" , global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
start_time = time.time()
t1.start()
t2.start()
执行结果
test1 1000000
test2 2000000
这回能得到我们想要的结果
而在Cpython解释器中,当我们的python代码有一个线程开始访问解释器的时候,GIL会把这个大锁给锁
上,此时此刻其他的线程只能干等着,无法对解释器的资源进行访问,这一点就跟我们的互斥锁相似。而只是
这个过程发生在我们的Cpython中,同时也需要等这个线程分配的时间到了,这个线程把gil释放掉,类似我
们互斥锁的lock.release()一样,另外的线程才开始跑起来,说白了,这无疑也是一个单线程。
执行过程: 1. thread1拿到全局变量count
2. thread1申请到python解释器的gil
3. 解释器调用系统原生线程
4. 在cpu1上执行规定的时间
5. 执行时间到了,要求释放gil@等下一次得到gil的时候,程序从这里接着这一次开始执行
6. thread2拿到了全局变量,此时thread1对全局count的操作并未完成,所以thread2拿到的和thread1拿到的count其实是相同的,这样也很好解释为什么结果不是200 万 而是少于200 万
7. thread2申请到了gil锁
8. 调用原生的线程
9. 如果是单核cpu则会在cup1上执行,(不是重点)
10. 执行规定的时间,此时完成了对count的加一操作
11. 执行时间还未到,线程2 执行完对count操作,并给count加一,并且释放了gil锁
12. 线程1 又申请到了gil锁,重复之前的操作。
13. 线程1 执行对count的操作,执行时间到,释放gil锁
综合上面的步骤就能很好的理解gil锁



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现