设计模式---单例模式
简介
单例模式(Singleton Pattern) 是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实
例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
单例模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建
'''
1、单例类只能有一个实例。
2、单例类必须自己创建自己的唯一实例。
3、单例类必须给所有其他对象提供这一实例。
'''
关键实现思想:
第一次创建类的对象的时候判断系统是否已经有这个单例,如果有则返回,如果没有则创建。那么后续再次
创建该类的实例的时候,因为已经创建过一次了,就不能再创建新的实例了,否则就不是单例啦,直接返回前
面返回的实例即可。
单例模式的python实现
使用“装饰器”来实现单例模式
def Singleton(cls): # 这是一个函数,目的是要实现一个“装饰器”,而且是对类型的装饰器
'''
cls:表示一个类名,即所要设计的单例类名称,
因为python一切皆对象,故而类名同样可以作为参数传递
'''
instance = {}
def singleton(*args, **kargs):
if cls not in instance:
instance[cls] = cls(*args, **kargs) # 如果没有cls这个类,则创建,并且将这个cls所创建的实例,保存在一个字典中
return instance[cls]
return singleton
@Singleton
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
s1 = Student('张三', 23)
s2 = Student('李四', 24)
print((s1 == s2))
print(s1 is s2)
print(id(s1), id(s2), sep=' ')
运行结果:
True
True
24171496 24171496
通过__new__函数去实现
若要得到当前类的实例,应在当前类__new__()中调用其父类的__new__()来返回,python2和python3调
用父类的__new__()方法不同:
python2: object.__new__(cls)
python3: super().__new__(cls) #super()中类可加可不加
'''基于python3代码:'''
class Student(object):
instance = None
def __new__(cls, name, age):
if not cls.instance:
cls.instance = super(Student, cls).__new__(cls)
return cls.instance
def __init__(self, name, age):
self.name = name
self.age = age
s1 = Student('张三', 23)
s2 = Student('李四', 24)
print((s1 == s2))
print(s1 is s2)
print(id(s1), id(s2), sep=' ')
运行结果:
True
True
27579152 27579152
'''基于python2代码实现:'''
if not cls.instance:
cls.instance = object.__new__(cls)
return cls.instance
使用一个单独的模块作为单例模式
因为,Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入
时,就会直接加载 .pyc 文件,而不会再次执行模块代码。
因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。如果我们真的想要一个单例类,可以考虑这样做:
在一个模块中定义一个普通的类,如在demo.py模块中定义如下代码
#demo.py
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
student=Student('张三',23)
这里的student就是一个单例。 当我们在另外一个模块中导入student这个对象时,因为它只被导入了一
次,所以总是同一个实例。
#test.py
from demo import student
#此时,无论该test脚本怎么运行,import进来的student实例是唯一的
pickle模块
pickle模块的介绍
(1)pickle模块:
pickle模块是python语言的一个系统内置模块,安装python后已包含pickle库,不需要单独再安装。
(2)pickle模块的特点:
1、只能在python中使用,只支持python的基本数据类型,是python独有的模块。
2、序列化的时候,只是序列化了整个序列对象,而不是内存地址。
3、pickle有两类主要的接口,即序列化和反序列化;
通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;
通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
(3)为什么需要序列化和反序列化操作呢?
1、便于存储
序列化过程是将Python程序运行中得到了一些字符串、列表、字典等数据信息转变为二进制数据流。这样信息
就容易存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据,然后再将其反序列化便可以得到原始的数据。
2、便于传输
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的
形式在网络上传送。发送方需要把对象转换为字节序列,在网络上传输;接收方则需要把字节序列在恢复为
对象,得到原始的数据。
pickle模块的使用
序列化操作
序列化方法1:pickle.dump()
格式为:pickle.dump(obj,file)
该方法是将序列化后的对象obj以二进制形式写入文件file中,进行保存,不能直接预览。 关于文件file,
必须是以二进制的形式进行操作(写入)。
示例如下:将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中
import random
import pickle
# 初始化成绩表为空
cjb = []
# 写入5个学生的数据到成绩表中
for i in range(5):
name = input("name:") # 姓名
cj = random.randint(50, 100) # 随机生成50——100之间的整数作为成绩
cjb.append([name, cj])
print(cjb)
# 将成绩表中的数据保存到cjb.txt文件中
with open('cjb.txt', 'wb') as f:
pickle.dump(cjb, f)
print("结果已保存")
序列化方法2:pickle.dumps()
格式为:pickle.dumps(obj)
pickle.dumps()方法跟pickle.dump()方法不同:pickle.dumps()方法不需要写入文件中,而是
直接返回一个序列化的bytes对象。
示例如下:与上面的例子一样,只是方法不同,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中
import random
import pickle
#初始化成绩表为空
cjb=[]
#写入5个学生的数据到成绩表中
for i in range(5):
name=input("name:") #姓名
cj=random.randint(50,100) #成绩
cjb.append([name,cj])
print(cjb)
print(pickle.dumps(cjb)) #序列化的bytes对象
print(type(pickle.dumps(cjb))) #class 'bytes'
#将成绩表中的数据保存到cjb.txt文件中
with open('cjb.txt','wb')as f:
f.write(pickle.dumps(cjb))
print("结果已保存")
运行结果为:
[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63]]
b'\x80\x04\x957\x00\x00\x00\x00\x00\x00\x00]\x94(]\x94(\x8c\x011\x94KBe]\x94(\x8c\x012\x94KFe]\x94(\x8c\x013\x94K:e]\x94(\x8c\x014\x94K`e]\x94(\x8c\x015\x94K?ee.'
<class 'bytes'>
结果已保存
反序列化操作
反序列化方法1:pickle.load()
该方法是将序列化的对象从文件file中读取出来。关于文件file,必须是以二进制的形式进行操作(读取)。
示例如下:与上面的例子一样,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中;再次运行程序
时,读取cjb.txt中的学生信息,进行加载,再次写入数据时,以追加的方式写入。
import random
import pickle
#如果没有cjb,就让cjb=[],如果存在,就将内容读取出来
try:
with open('cjb.txt','rb')as f:
cjb=pickle.load(f)
print(cjb)
print("结果已加载")
except:
cjb=[]
#写入5个学生的数据到成绩表中
for i in range(5):
name=input("name:") #姓名
cj=random.randint(50,100) #成绩
cjb.append([name,cj])
print(cjb)
#将成绩表中的数据保存到cjb.txt文件中
with open('cjb.txt','wb')as f:
pickle.dump(cjb,f)
print("结果已保存")
运行结果:
[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63]]
结果已加载
name:11
name:22
name:33
name:44
name:55
[['1', 66], ['2', 70], ['3', 58], ['4', 96], ['5', 63], ['11', 97], ['22', 87], ['33', 50], ['44', 98], ['55', 89]]
结果已保存
反序列化方法2:pickle.loads()
格式为:pickle.loads()
pickle.loads()方法跟pickle.load()方法不同:pickle.loads()方法是直接从bytes对象中读取
序列化的信息,而非从文件中读取。下面的例子是将信息保存到了文件中,所以要从文件中读取,以
pickle.loads(f.read())的方式读取。
示例如下:与上面的例子一样,将五个学生的成绩写入到成绩表中,保存在cjb.txt文件中;再次运行程序
时,读取cjb.txt中的学生信息,进行加载,再次写入数据时,以追加的方式写入。
import random
import pickle
#如果没有cjb,就让cjb=[],如果存在,就将内容读取出来
try:
with open('cjb.txt','rb')as f:
cjb=pickle.loads(f.read())
print(cjb)
print("结果已加载")
except:
cjb=[]
#写入5个学生的数据到成绩表中
for i in range(5):
name=input("name:") #姓名
cj=random.randint(50,100) #成绩
cjb.append([name,cj])
print(cjb)
#将成绩表中的数据保存到cjb.txt文件中
with open('cjb.txt','wb')as f:
f.write(pickle.dumps(cjb))
print("结果已保存")
运行结果:
[['1', 87], ['2', 59], ['3', 78], ['4', 77], ['5', 75]]
结果已加载
name:a
name:b
name:c
name:d
name:e
[['1', 87], ['2', 59], ['3', 78], ['4', 77], ['5', 75], ['a', 55], ['b', 86], ['c', 86], ['d', 61], ['e', 67]]
结果已保存
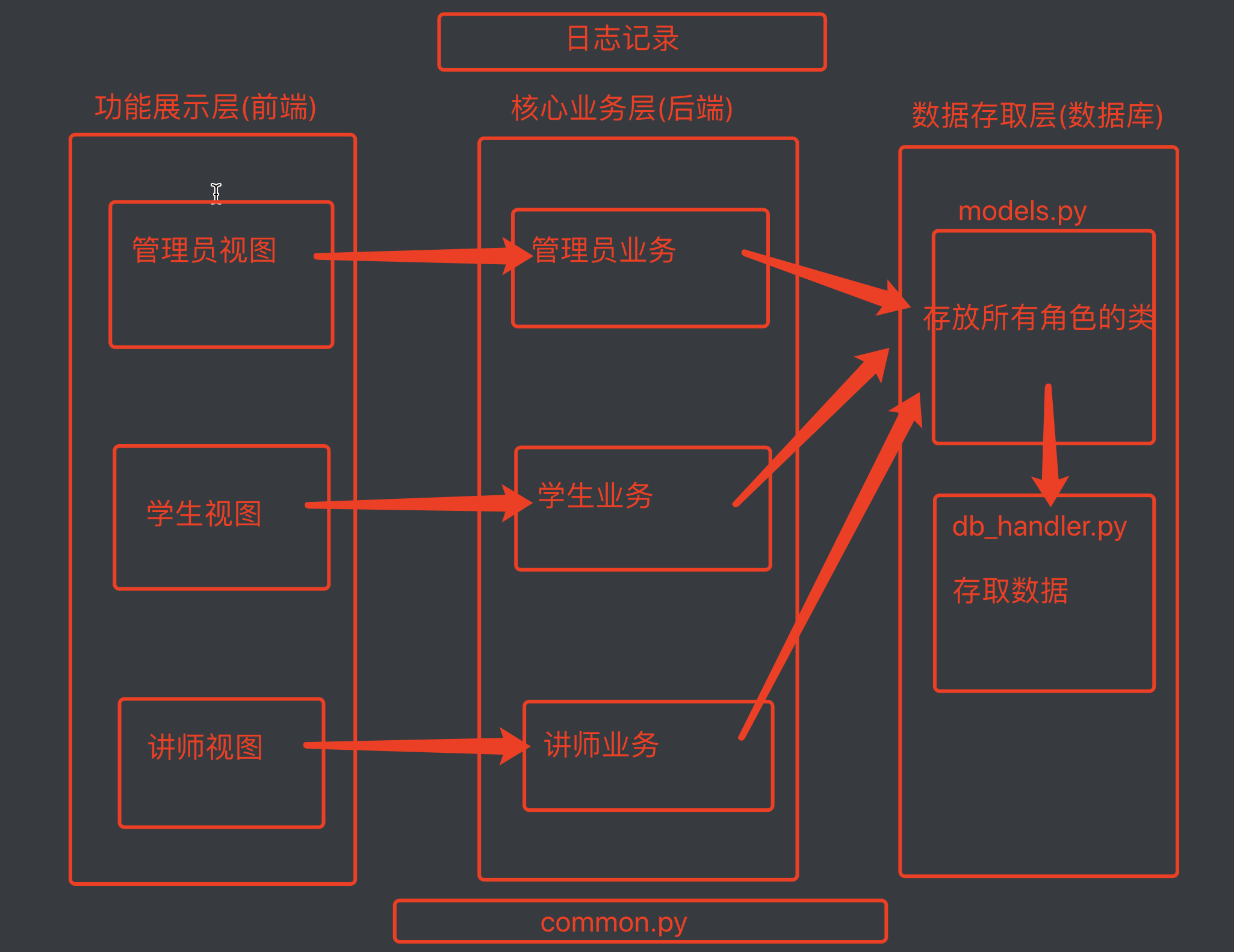
选课系统项目分析
需求分析
选课系统
角色:学校、学员、课程、讲师
要求:
1. 创建北京、上海 2 所学校
2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开
3. 课程包含,周期,价格,通过学校创建课程
4. 通过学校创建班级, 班级关联课程、讲师
5. 创建学员时,选择学校,关联班级
5. 创建讲师角色时要关联学校,
6. 提供三个角色接口
6.1 学员视图, 可以登录,注册, 选择学校,选择课程,查看成绩
6.2 讲师视图, 讲师登录,选择学校,选择课程, 查看课程下学员列表 , 修改所管理的学员的成绩
6.3 管理视图,登录,注册,创建讲师, 创建班级,创建课程,创建学校
7. 上面的操作产生的数据都通过pickle序列化保存到文件里
设计分析