
模块导入,模块查找顺序,软件开发目录
模块导入
循环导入的问题
"""
模块循环导入
A:模块
def test():
f()
B: 模块
def f()
test()
循环导入导致的问题:
两个模块直接相互导入,且相互使用其名称空间中的名字,但是有些名字没有产生就使用,就出现了循环
导入问题,你引用我,我又引用你,无限循环导入
循环导入的时候极有可能出现某个名字还没有被创建就使用的情况导致报错
这是一种错误的方式
在大型py项目中,需要很多python,由于架构不当,会出现相互引用模块
避免产生循环导入:
1.from导入马上会使用名字,极容易出现错误,建议循环导入情况下,使用import导入
2.先提前产生名字,在导入模块
3.将导入逻辑放在函数中,将导入的逻辑延后到函数的调用,只要调用在产生名字后即可
4,if __name__=='__main__': 该方法可以阻止一个无用代码被重复调用多次
5.把导入的语句放在最后,先让函数们加载完
"""
判断文件类型
在python,xx.py文件可以分为两种类型
1.执行文件
2.被导入文件
Python中的模块(.py文件)在创建之初会自动加载一些内建变量,__name__就是其中之一。Python模块
中通常会定义很多变量和函数,这些变量和函数相当于模块中的一个功能,模块被导入到别的文件中,可以调
用这些变量和函数。那么这时 __name__ 的作用就彰显了,它可以标识模块的名字,可以显示一个模块的某
功能是被自己执行还是被别的文件调用执行,假设模块A、B,模块A自己定义了功能C,模块B调用模块A,现在
功能C被执行了:
如果C被A自己执行,也就是说模块执行了自己定义的功能,那么 __name__=='__main__'
如果C被B调用执行,也就是说当前模块调用执行了别的模块的功能,那么__name__=='A'(被调用模块的名字)
它有一个内置函数__name__
当__name__所在的文件是执行文件的时候 结果是__main__
当__name__所在的文件是被导入文件时候 结果是文件名(模块名)
__name__ 是属于 python 中的内置类属性,就是它会天生就存在与一个 python 程序中,代表对应程序名称。
也分两种情况:
1)当python程序自己执行时,__name__变量的值就是:__main__
2) 当python程序是作为模块被导入时,那么__name__变量的值就是:程序的文件名,也就是.py前面的文件名称。
"""
由于上述代码在很多启动脚本中经常使用 所以有简写方式
直接输入main之后按tab键即可
"""
模块的查找顺序
"""
1.先从内存空间中查找
2.再从内置模块中查找
3.最后去sys.path查找(类似于我们前面学习的环境变量)
如果上述三个地方都找不到 那么直接报错!!!
"""
验证从内存中查找
下图是模块a和模块b内的代码
在模块a中导入一个time模块,让函数等待15秒后再执行,在这15秒的时间内我们删除模块b,如果能正常打印就说明从内存中查找
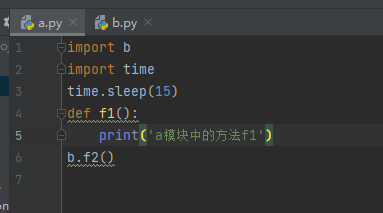
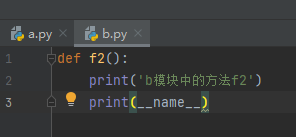
下图就是执行结果,在模块b被删除了的情况下,很明显正常打印了,
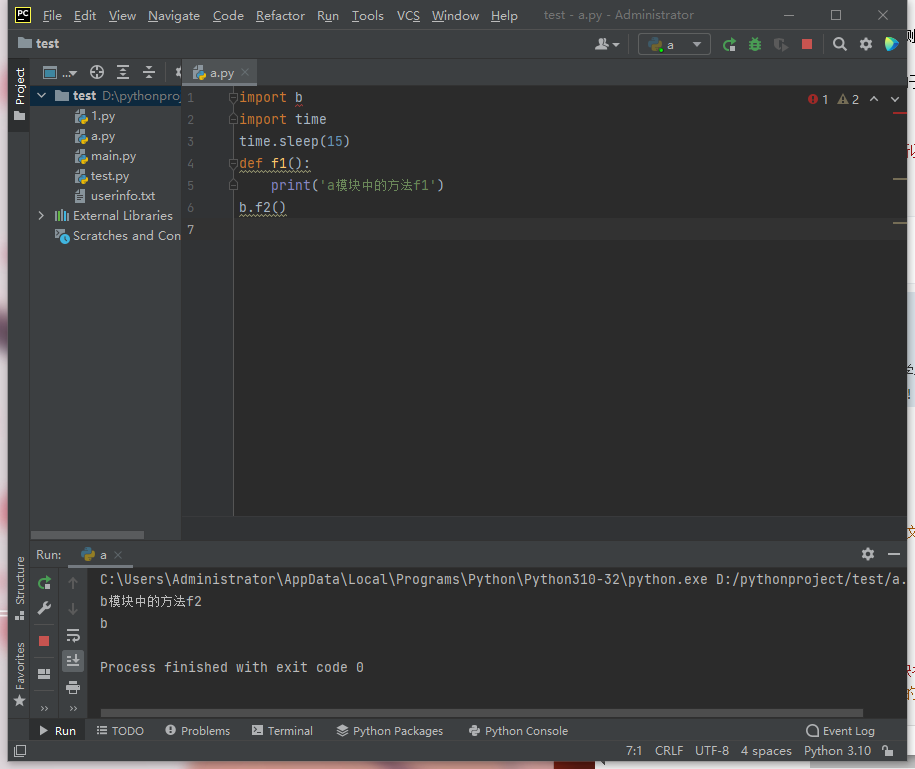
验证再从内置模块中查找
import time
print(time)
print(time.time())
执行结果:
<module 'time' (built-in)>
1648196754.2162976
"""强调:在创建py文件时候一定不要跟模块名(内置、第三方)冲突!!!"""
验证sys.path(类似于我们前面学习的环境变量)
import sys
print(sys.path)
当内存中和内置中都没有要查找的模块时 就会去下面的路径中挨个查找
['D:\\pythonproject\\test', 'D:\\pythonproject\\test',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310-32\\python310.zip',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310-32\\DLLs',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310-32\\lib',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310-32',
'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310-32\\lib\\site-packages']
"""
sys.path中虽然有很多路径 但是只需要重点关注第一个
第一个其实就是执行文件所在的路径
###############################################################
查找模块的时候只需要站在执行文件所在的路径查看即可
###############################################################
"""
解决sys.path路径问题
第一种
import sys
#因为sys.path是一个列表所以我们可以使用append方法进行追加
sys.path.append(r'D:\pythonproject\test\AAA')
import a
a.f1()
"""
pycharm会自动将项目目录所在的路径添加到sys.path中
"""
第二种
利用from...import...句式指名道姓的查找
from AAA import a 从文件夹AAA中导入a模块
from AAA.BBB import c 从AAA文件夹中的子文件BBB中导入模块c
绝对导入与相当导入
绝对导入
在导入模块的时候一切查找模块的句式都是以执行文件为准
无论导入的句式是在执行文件中还是在被导入文件中!!!
绝对导入:
在python的执行文件或模块中,使用类似import 模块名、import 包名.模块名 、from 包名.模块名
import 内容等导入语法时,就是在用绝对路径导入模块。
按照执行文件所在的路径一层层往下查找
相对导入
相对导入:
使用相对导入,就不需要考虑执行文件到底是谁了,只需要知道模块与模块之间的相对位置
语法:
from . import module # 导入当前目录下的module
from .. import module # 导入上一级目录下的module
from ... import module # 导入上上级目录下的module
from .module import content # 导入当前目录下模块的内容
from ..dir1.module import content # 导入父级目录下的dir1目录下的模块中的内容
from ..dir1.dir2 import module # 导入上上级目录下的dir1目录下的dir2目录下的模块
相对导入的语法很强大,但是需要注意的是:
1.相对导入不能在执行文件中使用,只能在被导入的模块中使用。
2.根据相对路径的查找过程中的目录不一定得是一个pthon包,可以是一个普通目录。
3.但是,顶级包之间不能互相访问(与执行文件处于一个目录下的包是顶级包)。
例如目录结构:

执行main.py,即main.py所在目录下的A包和B包是顶级包,不能互相访问,所以a.py不能导入B包中的b.py。
如果出现顶级包之间的互相访问,python解释器会报错:
ValueError: attempted relative import beyond top-level package
不得已的方法:
实在是想实现顶级包之间的相互访问,就需要向sys.path添加目标模块所在的目录,再使用绝对导入来加载目标模块。
包
什么是包
包是模块的另一种形式,包的本质就是一个含有__init__.py文件的文件夹
如何使用包
导入包就是在导入包下的__init__.py 与模块的导入无差
import...
from ... import ...
主要的问题有:
1.包内所有的文件都是被导入的,而不是直接运行
2.包内部模块之间的导入可以使用绝对导入(以包的根目录为基准)与相对导入(以当前被导入的模块所在的目录为基准)推荐使用相对导入
3.当文件是执行文件是,无法在该文件内使用相对导入的语法,只有在文件是被当做模块导入时,该文件内才能使用相对导入的语法
4.凡是在导入是带点( . )的,点的左边都必须是一个包
例:
我们在a/b/version.py中想要导入a/c/manage.py
在a/b/version.py
#绝对导入
from a.c import manage
manage.main()
#相对导入
from ..c import manage
manage.main()
"""
在导入包的时候 索要名字其实是跟包里面的__init__.py要
1.如果想直接通过包的名字使用包里面所有的模块 那么需要在__init__.py中提前导入
上述方式的好处在于__init__可以提前帮你准备好可以使用的名字
2.也可以直接忽略__init__的存在使用绝对导入即可
上述方式的好处在于不需要考虑包的存在 直接当成普通文件夹即可
"""
编程思想演变
1.小白阶段
此阶段写代码就是在一个文件内不停地堆叠代码的行数(面条版本)
2.函数阶段
此阶段写代码我们学会了将一些特定功能的代码封装到函数中供后续反复调用
3.模块阶段
此阶段不单单是将功能代码封装成函数,并且将相似的代码功能拆分到不同的py文件中便于后续的管理
软件开发目录规范
1.bin文件夹
存放程序的启动文件 start.py
2.conf文件夹
存放程序的配置文件 settings.py
3.core文件夹
存放程序的核心业务 src.py
就是最为重要的代码 能够实现具体需求
4.lib文件夹
存放程序公共的功能 common.py
5.db文件夹
存放程序的数据 userinfo.txt
6.log文件夹
存放程序的日志记录 log.log
7.readme文本文件
存放程序的说明、广告等额外的信息
1.软件定位,软件的基本功能。
2.运行代码的方法: 安装环境、启动命令等。
3.简要的使用说明。
4.代码目录结构说明,更详细点可以说明软件的基本原理。
5.常见问题说明。
8.requirements.txt文本文件
存放程序需要使用的第三方模块及对应的版本
软件目录结构规范是为了达到一下2点:
可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试
目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之
下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
