MapReduce的shuffle过程
1.简单的说https://zhuanlan.zhihu.com/p/36253130
shuffle就包括
从map执行后写入数据到内存的环形缓冲区开始,然后分区、排序、合并、combine规约(可选)
从reduce开始后,copy、排序
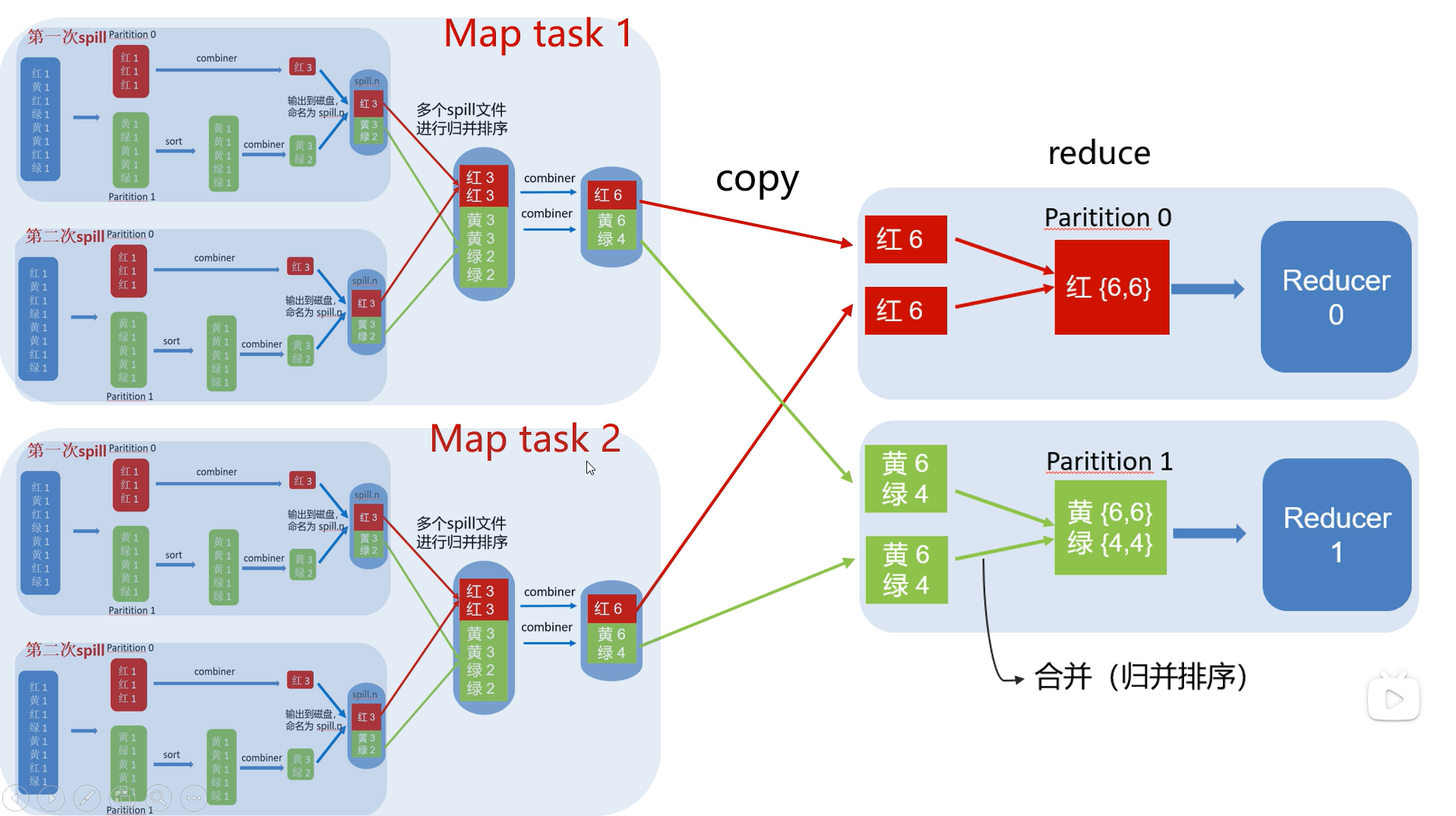
Map端流程:
- 环形内存缓存区:每个split数据交由一个map任务处理,map的处理结果不会直接写到硬盘上,会先输送到环形内存缓存区中,默认的大小是100M(可通过配置修改),当缓冲区的内容达到80%后会开始溢出,此时缓存区的溢出内容会被写到磁盘上,形成一个个spill file,注意这个文件没有固定大小。环形缓冲区存储了K-V数据以及索引信息,它们分别存储在环的不同位置。
- 在内存中经过分区、排序后溢出到磁盘:分区主要功能是用来指定 map 的输出结果交给哪个 reduce 任务处理,默认是通过 map 输出结果的 key 值取hashcode 对代码中配置的 redue task数量取模运算,值一样的分到一个区,也就是一个 reduce 任务对应一个分区的数据。(分区也可以自定义,如字母统计的,A-N一个区,O-Z一个区)这样做的好处就是可以避免有的 reduce 任务分配到大量的数据,而有的 reduce 任务只分配到少量甚至没有数据,平均 reduce 的处理能力。并且在每一个分区(partition)中,都会有一个 sort by key 排序,如果此时设置了 Combiner,将排序后的结果进行 Combine 操作,相当于 map 阶段的本地 reduce,这样做的目的是让尽可能少的数据写入到磁盘。
- 合并溢出文件:随着 map 任务的执行,不断溢出文件,直到输出最后一个记录,可能会产生大量的溢出文件,这时需要对这些大量的溢出文件进行合并,在合并文件的过程中会不断的进行排序跟 Combine 操作,这样做有两个好处:减少每次写入磁盘的数据量&减少下一步 reduce 阶段网络传输的数据量。最后合并成了一个分区且排序的大文件,此时可以再进行配置压缩处理,可以减少不同节点间的网络传输量。合并完成后着手将数据拷贝给相对应的reduce 处理,那么要怎么找到分区数据对应的那个 reduce 任务呢?简单来说就是 JobTracker 中保存了整个集群中的宏观信息,只要 reduce 任务向 JobTracker 获取对应的 map 输出位置就可以了。具体请参考上方的MapReduce工作原理。
Reduce端流程:
reduce 会接收到不同 map 任务传来的有序数据,如果 reduce 接收到的数据较小,则会存在内存缓冲区中,直到数据量达到该缓存区的一定比例时对数据进行合并后溢写到磁盘上。随着溢写的文件越来越多,后台的线程会将他们合并成一个更大的有序的文件,可以为后面合并节省时间。这其实跟 map端的操作一样,都是反复的进行排序、合并,这也是 Hadoop 的灵魂所在,但是如果在 map 已经压缩过,在合并排序之前要先进行解压缩。合并的过程会产生很多中间文件,但是最后一个合并的结果是不需要写到磁盘上,而是可以直接输入到 reduce 函数中计算,每个 reduce 对应一个输出结果文件。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通