在Windows的idea上打包,然后在Linux的Hadoop集群上跑MapReduce
以Wordcount为例:
1.写MapReduce的流程是什么?
可以总结为三个过程:
一是写Mapper,重写map方法时,是每输入一行数据就调用一次map方法,如第一行i am;第二行a student;那么总共会调用两次map方法
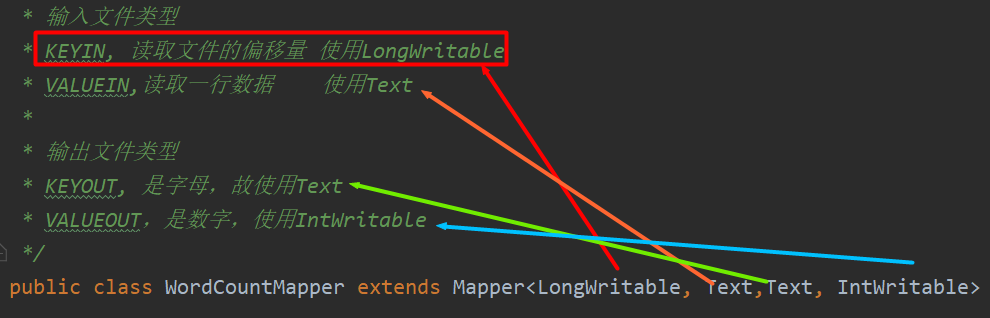
二是写Reducer,重写reduce方法时,是一组相同key的values就调用一次reduce方法,如mapper后的数据为a 1 1 1;b 1 1;c 1;可以看到有三组,那么总共就调用三次reduce方法
三是写Driver驱动类
写完后,对其进行打包,然后发送到Linux的Hadoop集群上
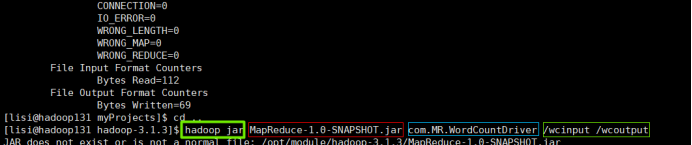
2.在Linux上写跑jar包的指令
hadoop jar是固定的;
红色框是jar包的名称;
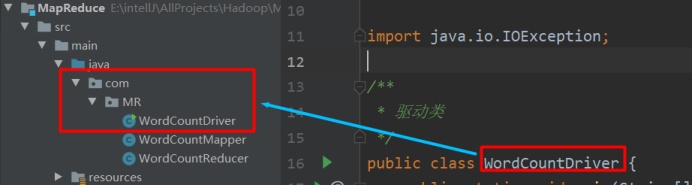
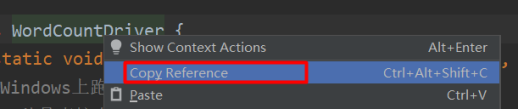
蓝色框是驱动类的类路径;
最后是输入路径和输出路径;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号