

USACO4.2.3-Job Processing
chunlvxiong的博客
题目描述:
有N(1≤N≤1000)件产品,每个产品生产需要操作A和操作B。有M1(1≤M1≤30)件机器完成操作A,M2(1≤M2≤30)件机器完成操作B,分别给出每台机器完成相应操作的时间。产品必须先进行操作A再进行操作B,问:所有产品完成操作A的时间和所有产品完成操作B的时间是多少。
思考&分析:
第一问比较好解决,可以贪心处理。假设第i台机器加工了xi件产品,那么所有产品完成操作A的时间就是max{xi*time_a[i]}。由于每次必须有一个xi+1,那么你的贪心策略就是让(xi+1)*time_a[i]最小(也就是让这次的产品完成时间最小)。这里你可以使用堆来维护(xi+1)*time_a[i](详见代码),同时你每次也可以算出每个产品完成操作A的时间(是一个非递减序列)。
第二问很明显要借用第一问的计算结果(每个产品的完成时间)。设产品i完成操作A的时间是ti,然后我们考虑:
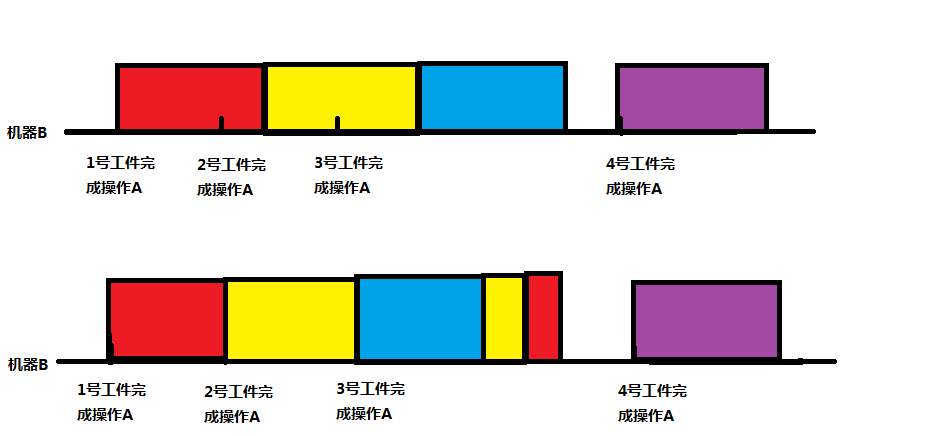
这两个图是说:交换时间段对于问题的答案无影响。-->这有什么用呢?例如:忽略4号工件,那么3号工件结束时间是t[3]+time_b,2号工件结束时间是t[2]+time_b*2,1号工件结束时间为t[1]+time_b*3-->一个简单想法:对于完成操作A的时间第i靠后的工件x,其结束时间为t[x]+time_b*i。
那么如果加入了4号工件呢?三号工件的完成时间变成了t[3]+time_b*2,然而实际上它的完成时间是t[3]*time_b-->但是这并没有关系,因为t[3]+time_b*2不可能超过t[4]+time_b,不影响最大值(如果t[3]+time_b*2大于t[4]+time_b说明最大时间是t[3]+time_b*2)。也就是说,刚才那个简单想法是行的通的。
这样问题就变得容易很多:贪心策略可以为每次让最后完成操作A的工件放到(xi+1)*time_b[i]最小的机器上(由于其t值大,所以要减小这个值以避免max过大)。那么这个维护又变成了第一问的堆维护,但要注意这次的序列不在具有非递减的性质,需要取max来获得ans。
总时间复杂度O(NlogM)。
贴代码:
#include <bits/stdc++.h> using namespace std; int n,m1,m2,a[35],b[35],end_a[1005]; struct node{ int x,y; friend bool operator <(node a,node b){ return a.x>b.x; } }; priority_queue<node>Q; void solve1(){ sort(a+1,a+m1+1); for (int i=1;i<=m1;i++) Q.push(node{a[i],i}); for (int i=1,x,y;i<=n;i++){ x=Q.top().x,y=Q.top().y; Q.pop(); end_a[i]=x; Q.push(node{x+a[y],y}); } printf("%d ",end_a[n]); while (!Q.empty()) Q.pop(); } void solve2(){ sort(b+1,b+m2+1); for (int i=1;i<=m2;i++) Q.push(node{b[i],i}); int ans=0; for (int i=n,x,y;i>=1;i--){ x=Q.top().x,y=Q.top().y; Q.pop(); ans=max(ans,end_a[i]+x); Q.push(node{x+b[y],y}); } printf("%d\n",ans); } int main(){ freopen("job.in","r",stdin); freopen("job.out","w",stdout); scanf("%d%d%d",&n,&m1,&m2); for (int i=1;i<=m1;i++) scanf("%d",&a[i]); for (int i=1;i<=m2;i++) scanf("%d",&b[i]); solve1(); solve2(); return 0; }
