Python-Basis-13th
周四,晴,记录生活分享点滴
参考博客1:https://www.cnblogs.com/yuanchenqi/articles/5732581.html
参考博客2:https://www.cnblogs.com/alex3714/articles/5765046.html
Python版本:3.5
模块和包
模块的概念
在Python中,一个.py文件就称之为一个模块(Module)。
模块提高了代码的可维护性,分为三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
模块导入方法
import 语句
import module1[, module2[,... moduleN] # 导入同级别即当前目录的模块
from…import 语句
from modname import name1[, name2[, ... nameN]] # 从modname目录下导入name模块
from…import* 语句
from modname import* # 导入modname模块所有的项目
运行本质
1 import test 2 from test import add # 1和2都是通过sys.path找到test.py,然后执行test脚本(全部执行),区别是1会将test这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
包(package)
__init__.py
- 每一个包目录下面都会有一个 __init__.py 的文件,__init__.py 可以是空文件,也可以有Python代码,__init__.py 本身就是一个模块
- 调用包就是执行包下的__init__.py文件
BASEDIR、__name__变量
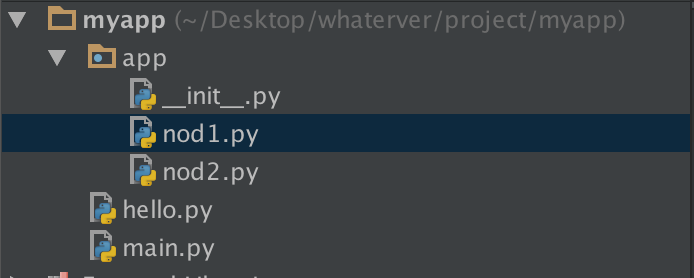
- 找nod1里import hello
- 在pycharm可以找到,因为pycharm把myapp这一层路径加入到了sys.path里面;
- 在命令行运行报错,需要把这个路径加进去
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) import hello hello.hello1()
使.py既可导入又可执行
if __name__=='__main__': print('ok')
引用模块过程
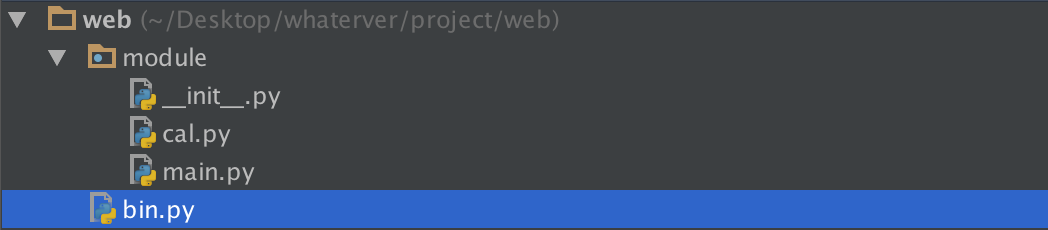
##-------------cal.py def add(x,y): return x+y ##-------------main.py import cal #from module import cal def main(): cal.add(1,2) ##--------------bin.py from module import main main.main()
注意
- from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本,sys.path里有bin.py的当前环境,即/Users/yuanhao/Desktop/whaterver/project/web这层路径。
- 无论import what , 解释器都会按这个路径找。
- 所以当执行到main.py时,import cal会找不到,因为sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而 from module/. import cal 时,解释器就可以找到了。
目录结构
假设项目名为foo
Foo/ |-- bin/ | |-- foo | |-- foo/ | |-- tests/ | | |-- __init__.py | | |-- test_main.py | | | |-- __init__.py | |-- main.py | |-- docs/ | |-- conf.py | |-- abc.rst | |-- setup.py |-- requirements.txt |-- README
1. bin/: 存放项目的一些可执行文件,可以起其他名,例如 script/ 之类的。
2. foo/: 存放项目的所有源代码。
(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。
(2) 其子目录 tests/ 存放单元测试代码;
(3) 程序的入口最好命名为 main.py
3. docs: 存放一些文档。
4. setup.py: 安装、部署、打包的脚本。
5. requirements.txt: 存放软件依赖的外部Python包列表。
6. README: 项目说明文件。
(1)软件定位,软件的基本功能。
(2)运行代码的方法: 安装环境、启动命令等。
(3)简要的使用说明。
(4)代码目录结构说明,更详细点可以说明软件的基本原理。
(5)常见问题说明。
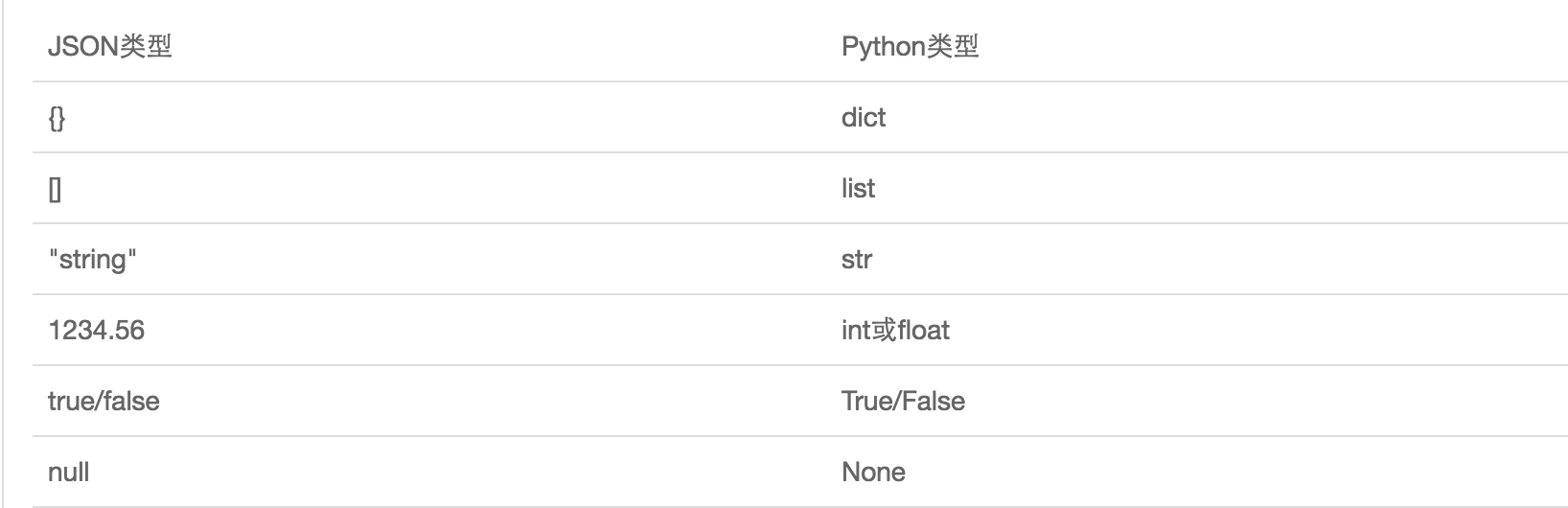
json & pickle
序列化
- 把对象(变量)从内存中变成可存储或传输的过程。
- 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化。
json
- 在不同的编程语言之间传递对象,需要把对象序列化为标准格式。
- JSON表示一个字符串,可以被所有语言读取,也可以存储到磁盘或者通过网络传输。
- JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取。
#----------------------------序列化 import json dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=json.dumps(dic) print(type(j))#<class 'str'> f=open('序列化对象','w') f.write(j) #-------------------等价于json.dump(dic,f) f.close() #-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
注意
import json #dct="{'1':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}' print(json.loads(dct)) #conclusion: 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
pickle(不推荐)
只能用于Python,并且可能不同版本的Python彼此都不兼容
##----------------------------序列化 import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic) print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes' f.write(j) #-------------------等价于pickle.dump(dic,f) f.close() #-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
shelve模块
- shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写
- key必须为字符串,而值可以是python所支持的数据类型
import shelve f = shelve.open(r'shelve.txt') # f['stu1_info']={'name':'chung','age':'23'} # f['stu2_info']={'name':'zack','age':'30'} # f['school_info']={'website':'cnblogs.com','city':'beijing'} # f.close() print(f.get('stu_info')['age'])
xml模块
xml是实现不同语言或程序之间进行数据交换的协议
与json差不多,但是 json 使用起来更简单,需要会读xml,写的时候用 json
格式
通过<>节点来区别数据结构
<?xml version="1.0"?> <data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
操作xml
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text) #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
创建xml
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") age.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号