Python-Basis-11th
周二,晴,记录生活分享点滴
参考博客1:https://www.cnblogs.com/alex3714/articles/5161349.html
参考博客2:https://www.cnblogs.com/yuanchenqi/articles/5732581.html
Python版本:3.5
time模块
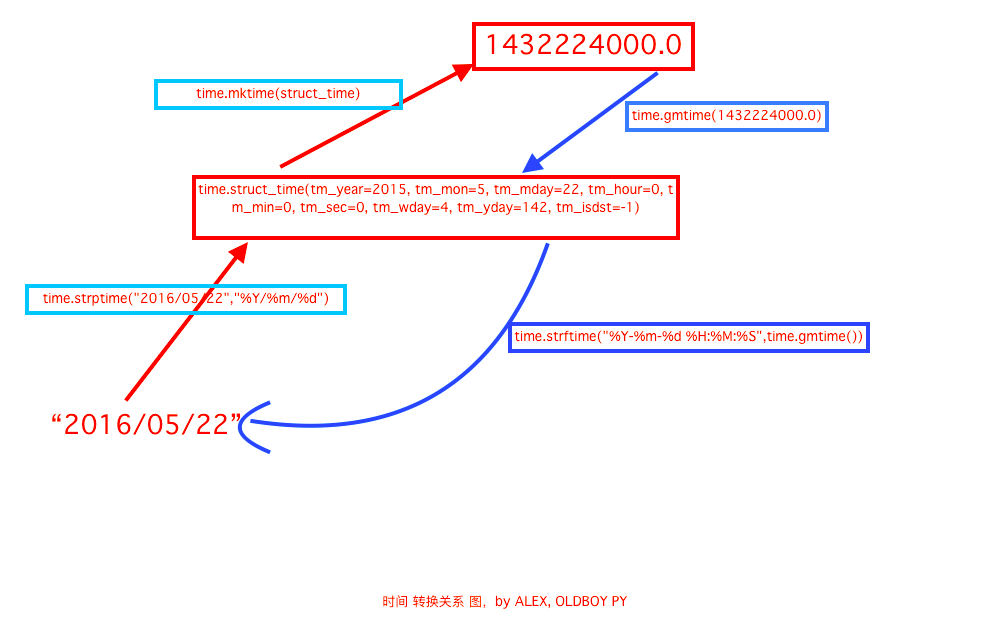
import time 1. time() # 返回当前时间的时间戳 time.time() # 1473525444.037215 2. localtime([secs]) # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 time.localtime() # time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0) time.localtime(1473525444.037215) 3. gmtime([secs]) # 与localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 4. mktime(t) # 将一个struct_time转化为时间戳。 print(time.mktime(time.localtime())) # 1473525749.0 5. asctime([t]) # 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 # 如果没有参数,会将time.localtime()作为参数传入。 print(time.asctime()) # Sun Sep 11 00:43:43 2016 6. ctime([secs]) # 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 print(time.ctime()) # Sun Sep 11 00:46:38 2016 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016 7. strftime(format[, t]) # 把一个代表时间的元组或者struct_time(如由time.localtime()和 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个元素越界,会报错 ValueError print(time.strftime("%Y-%m-%d %X", time.localtime())) # 2016-09-11 00:49:56 8. time.strptime(string[, format]) # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) # time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,tm_wday=3, tm_yday=125, tm_isdst=-1) # 在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 9. sleep(secs) # 线程推迟指定的时间运行,单位为秒。 10. clock() # 在UNIX系统上,返回的是“进程时间”,用秒表示的浮点数(时间戳)。 # 在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行 # 时间,即两次时间差。
random模块
随机数
import random print(random.random()) # (0,1)----float print(random.randint(1,3)) # [1,3] print(random.randrange(1,3)) # [1,3) print(random.choice([1,'23',[4,5]])) # 23 print(random.sample([1,'23',[4,5]],2)) # [[4, 5], '23'] print(random.uniform(1,3)) # 1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) print(item)
生成随机验证码
import random checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print checkcode
os模块
提供对操作系统进行调用的接口
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.curdir # 返回当前目录: ('.') os.pardir # 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') # 可生成多层递归目录 os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() # 删除一个文件 os.rename("oldname","newname") # 重命名文件/目录 os.stat('path/filename') # 获取文件/目录信息 os.sep # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep # 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n" os.pathsep # 输出用于分割文件路径的字符串 os.name # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") # 运行shell命令,直接显示 os.environ # 获取系统环境变量 os.path.abspath(path) # 返回path规范化的绝对路径 os.path.split(path) # 将path分割成目录和文件名二元组返回 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) # 如果path是绝对路径,返回True os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.exit(n) # 退出程序,正常退出时exit(0) sys.version # 获取Python解释程序的版本信息 sys.maxint # 最大的Int值 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform # 返回操作系统平台名称,可用于跨平台 sys.stdout.write('please:') # 标准输出,进度条中有提到 val = sys.stdin.readline()[:-1]
hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1,SHA224,SHA256,SHA384,SHA512,MD5 算法
import hashlib m=hashlib.md5() # m=hashlib.sha256() m.update('hello'.encode('utf8')) print(m.hexdigest()) # 5d41402abc4b2a76b9719d911017c592 m.update('alvin'.encode('utf8')) print(m.hexdigest()) # 92a7e713c30abbb0319fa07da2a5c4af m2=hashlib.md5() m2.update('helloalvin'.encode('utf8')) print(m2.hexdigest()) # 92a7e713c30abbb0319fa07da2a5c4af
以上加密算法存在缺陷:通过撞库可以反解。所以,对加密算法中添加自定义key再来做加密
import hashlib # ######## 256 ######## hash = hashlib.sha256('898oaFs09f'.encode('utf8')) hash.update('alvin'.encode('utf8')) print (hash.hexdigest()) # e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
import hmac h = hmac.new('alvin'.encode('utf8')) h.update('hello'.encode('utf8')) print (h.hexdigest()) # 320df9832eab4c038b6c1d7ed73a5940
logging模块
基础
默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),
默认的日志格式为 日志级别:Logger名称:用户输出消息
import logging logging.warning("user [alex] attempted wrong password more than 3 times") logging.critical("server is down") # 输出 # WARNING:root:user [alex] attempted wrong password more than 3 times # CRITICAL:root:server is down
日志级别的含义
| Level | When it’s used |
|---|---|
DEBUG |
Detailed information, typically of interest only when diagnosing problems. |
INFO |
Confirmation that things are working as expected. |
WARNING |
An indication that something unexpected happened, or indicative of some problem in the near future (e.g. ‘disk space low’). The software is still working as expected. |
ERROR |
Due to a more serious problem, the software has not been able to perform some function. |
CRITICAL |
A serious error, indicating that the program itself may be unable to continue running. |
将日志写到文件
import logging logging.basicConfig(filename='example.log',level=logging.INFO) # 把日志纪录级别设置为INFO。只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里,在这个例子,第一条日志是不会被纪录的,如果纪录debug的日志,把日志级别改成DEBUG logging.debug('This message should go to the log file') logging.info('So should this') logging.warning('And this, too') # 输出 # example.log文件 # INFO:root:So should this # WARNING:root:And this, too
将上面的日志加上时间
import logging logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p') logging.warning('is when this event was logged.') # 输出
# 06/02/2020 06:23:42 PM is when this event was logged.
日志格式
|
%(name)s |
Logger的名字 |
|
%(levelno)s |
数字形式的日志级别 |
|
%(levelname)s |
文本形式的日志级别 |
|
%(pathname)s |
调用日志输出函数的模块的完整路径名,可能没有 |
|
%(filename)s |
调用日志输出函数的模块的文件名 |
|
%(module)s |
调用日志输出函数的模块名 |
|
%(funcName)s |
调用日志输出函数的函数名 |
|
%(lineno)d |
调用日志输出函数的语句所在的代码行 |
|
%(created)f |
当前时间,用UNIX标准的表示时间的浮 点数表示 |
|
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数 |
|
%(asctime)s |
字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 |
|
%(thread)d |
线程ID。可能没有 |
|
%(threadName)s |
线程名。可能没有 |
|
%(process)d |
进程ID。可能没有 |
|
%(message)s |
用户输出的消息 |
进阶
实现:同时把log打印在屏幕和文件日志里。
logging模块记录日志的四种类型:
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger,Logger通常对应了程序的模块名
聊天工具的图形界面模块获得Logger
LOG=logging.getLogger(”chat.gui”)
核心模块获得Logger
LOG=logging.getLogger(”chat.kernel”)
Logger类型
Logger.setLevel(lel) # 指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高 Logger.addFilter(filt)、Logger.removeFilter(filt) # 添加或删除指定的filter Logger.addHandler(hdlr)、Logger.removeHandler(hdlr) # 增加或删除指定的handler Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical() # 可以设置的日志级别
handler
handler对象负责发送相关的信息到指定目的地,通过addHandler()方法添加多个handler
handler类型
Handler.setLevel(lel) # 指定被处理的信息级别,低于lel级别的信息将被忽略 Handler.setFormatter() # 给这个handler选择一个格式 Handler.addFilter(filt)、Handler.removeFilter(filt) # 新增或删除一个filter对象
每个Logger可以附加多个Handler
常用的Handler
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。
它的构造函数是:
StreamHandler([strm]) # 其中strm参数是一个文件对象,默认是sys.stderr
2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。
它的构造函数是:
FileHandler(filename[,mode]) # filename是文件名,必须指定一个文件名。 # mode是文件的打开方式,参见Python内置函数open()的用法。 # 默认是’a',即添加到文件末尾。
3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2,最后重新创建 chat.log,继续输出日志信息。
它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]]) # 其中filename和mode两个参数和FileHandler一样。 # maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。 # backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。
4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。
它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]]) # 其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。 # interval是时间间隔。 # when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值: # S 秒 # M 分 # H 小时 # D 天 # W 每星期(interval==0时代表星期一) # midnight 每天凌晨
应用
关于logger、handler的伪代码
import logging #create logger logger = logging.getLogger('TEST-LOG') logger.setLevel(logging.DEBUG) # create console handler and set level to debug ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) # create file handler and set level to warning fh = logging.FileHandler("access.log") fh.setLevel(logging.WARNING) # create formatter formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # add formatter to ch and fh ch.setFormatter(formatter) fh.setFormatter(formatter) # add ch and fh to logger logger.addHandler(ch) logger.addHandler(fh) # 'application' code logger.debug('debug message') logger.info('info message') logger.warn('warn message') logger.error('error message') logger.critical('critical message')
例子:文件自动截断
import logging from logging import handlers logger = logging.getLogger(__name__) log_file = "timelog.log" #fh = handlers.RotatingFileHandler(filename=log_file,maxBytes=10,backupCount=3) fh = handlers.TimedRotatingFileHandler(filename=log_file,when="S",interval=5,backupCount=3) formatter = logging.Formatter('%(asctime)s %(module)s:%(lineno)d %(message)s') fh.setFormatter(formatter) logger.addHandler(fh) logger.warning("test1") logger.warning("test12") logger.warning("test13") logger.warning("test14")
ConfigParser模块
常见文档格式
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
用python生成常见文档格式
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9'} config['bitbucket.org'] = {'User':'hg'} config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = '50022' # mutates the parser topsecret['ForwardX11'] = 'no' # same here config['DEFAULT']['ForwardX11'] = 'yes' with open('example.ini', 'w') as configfile: config.write(configfile)
从已生成文件中读取
>>> import configparser >>> config = configparser.ConfigParser() >>> config.sections() [] >>> config.read('example.ini') ['example.ini'] >>> config.sections() ['bitbucket.org', 'topsecret.server.com'] >>> 'bitbucket.org' in config True >>> 'bytebong.com' in config False >>> config['bitbucket.org']['User'] 'hg' >>> config['DEFAULT']['Compression'] 'yes' >>> topsecret = config['topsecret.server.com'] >>> topsecret['ForwardX11'] 'no' >>> topsecret['Port'] '50022' >>> for key in config['bitbucket.org']: print(key) # 输出内容是['DEFAULT']和['bitbucket.org'],['DEFAULT']为默认,输出其他时,默认的也跟着一起输出 ... user compressionlevel serveraliveinterval compression forwardx11 >>> config['bitbucket.org']['ForwardX11'] 'yes'
configparser增删改查语法
[section1] k1 = v1 k2:v2 [section2] k1 = v1 import ConfigParser config = ConfigParser.ConfigParser() config.read('i.cfg') # ########## 读 ########## secs = config.sections() print secs options = config.options('group2') print options item_list = config.items('group2') print item_list val = config.get('group1','key') val = config.getint('group1','key') # ########## 改写 ########## sec = config.remove_section('group1') config.write(open('i.cfg', "w")) sec = config.has_section('chung') # 判断文件里面是否有'chung'字符串,打印结果True或False sec = config.add_section('chung') config.write(open('i.cfg', "w")) # 将原来文件的内容重新生成到新文件“i.cfg”里面,如果与原文件名称相同,则覆盖原文件 config.set('group2','k1',11111) # 找到group2下面的k1,修改为11111 config.write(open('i.cfg', "w")) config.remove_option('group2','age') # 将group2下面的age删掉 config.write(open('i.cfg', "w"))
re模块
常用方法
import re re.findall # 把所有匹配到的字符放到以列表中的元素返回 re.findall('h','chung zhao') re.search # 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 re.search('h','chung zhao').group() re.match # 同search,在字符串开始处进行匹配,如果不是最开始,匹配不成功 re.match('a','abc').group() re.splitall # 以匹配到的字符当做列表分隔符, ret=re.split('[ab]','abcd') print(ret) # ['', '', 'cd'] re.sub # 匹配字符并替换 ret=re.sub('\d','abc','alvin5yuan6',1) # 用abc把\b所代表的内容替换掉 # 最后面的1表示只替换一次,所以5被替换掉,6不会 print(ret) # alvinabcyuan6 ret=re.subn('\d','abc','alvin5yuan6') # 在sub的基础上多输出了一个已替换的次数,5和6都被abc替换,所以替换了2次 print(ret) # ('alvinabcyuanabc', 2) # compile obj=re.compile('\d{3}') # 匹配一个规则对象 ret=obj.search('abc123eeee') # 然后对规则对象进行匹配,后面只有一个参数,即需要匹配的内容 print(ret.group()) # 123 # finditer ret = re.finditer('\d', 'ds3sy4784a') # 返回的结果是一个迭代器 print(ret) # <callable_iterator object at 0x0000027D2927E400> # ret是一个迭代器 print(next(ret).group()) # 3 print(next(ret).group()) # 4
普通字符
import re print(re.findall('chung', 'qwertychungasdfg')) # ['chung']
元字符
. ^ $ * + ? { }
import re # 使用 * + ? 优于 {m} {n,m} '.' # 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 ret=re.findall('a..in','helloalvin') print(ret) # ['alvin'] '^' # 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE) ret=re.findall('^a...n','alvinhelloawwwn') print(ret) # ['alvin'] '$' # 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以 ret=re.findall('a...n$','alvinhelloawwwn') print(ret) # ['awwwn'] '*' # 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a'] ret=re.findall('abc*','abcccc') # 贪婪匹配[0,+oo] print(ret) # ['abcccc'] '+' # 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb'] ret=re.findall('abc+','abccc') # [1,+oo] print(ret) # ['abccc'] '?' # 匹配前一个字符1次或0次 ret=re.findall('abc?','abccc') # [0,1] print(ret) # ['abc'] '{m}' # 匹配前一个字符m次 '{n,m}' # 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb'] ret=re.findall('abc{1,4}','abccc') print(ret) # ['abccc'] 贪婪匹配 # *,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配 ret=re.findall('abc*?','abcccccc') print(ret) # ['ab']
字符集[]
import re # 字符集 ret = re.findall('a[bc]d', 'acd') # 或的关系,所给出的字符串有b或c,都可以输出 print(ret) # ['acd'] ret = re.findall('[a-z]', 'acd') # 有a-z范围内任意字母 print(ret) # ['a', 'c', 'd'] ret = re.findall('[.*+]', 'a.cd+') # .*+字符在[]里面无特殊意义,作为普通字符进行匹配 print(ret) # ['.', '+'] # 在字符集里有功能的符号: - ^ \ ret = re.findall('[1-9]', '45dha3') # 1-9数字范围内所能匹配的数字 print(ret) # ['4', '5', '3'] ret = re.findall('[^ab]', '45bdha3') # 除了ab,其他所有的元素 print(ret) # ['4', '5', 'd', 'h', '3'] ret = re.findall('[\d]', '45bdha3') # 匹配所有数字 print(ret) # ['4', '5', '3']
转义符 \
反斜杠后边跟元字符去除特殊功能,比如 \.
反斜杠后边跟普通字符实现特殊功能,比如 \d
\d # 匹配任何十进制数;它相当于类 [0-9]。 \D # 匹配任何非数字字符;它相当于类 [^0-9]。 \s # 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。 # re.search("\s+","ab\tc1\n3").group() 结果 '\t' \S # 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。 \w # 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。 \W # 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_] \A # 只从字符开头匹配。 # re.search("\Aabc","abcjjj").group() 结果abc \Z # 匹配字符结尾,同$ \b # 匹配一个特殊字符边界,比如空格 ,&,#等 ret=re.findall('I\b','I am LIST') print(ret) # [] ret=re.findall(r'I\b','I am LIST') print(ret) # ['I'] \b在python里面有特殊意义,所以加 r
通过原生字符串解决反斜杠问题:
正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"
import re ret=re.findall('c\l','abc\le') print(ret) # [] ret=re.findall('c\\l','abc\le') print(ret) # [] ret=re.findall('c\\\\l', 'abc\le') print(ret) # ['c\\l'] ret=re.findall(r'c\\l', 'abc\le') print(ret) # ['c\\l'] # \b在ASCII表具有意义 m = re.findall('\bblow', 'blow') print(m) # [] m = re.findall(r'\bblow', 'blow') print(m) # ['blow']
分组()
import re # '(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c m = re.findall(r'(ad)+', 'add') print(m) # ['ad']把ad作为一个整体进行识别 # 如果不加括号,因为有+,可以把add都识别出来 ret = re.search('(?P<id>\d{2})/(?P<name>\w{3})', '23/com') # 命名分组 # (?P<>)是已固定的,一个括号代表一个组。d{2}匹配两个数字,w{3}匹配三个字母 print(ret.group()) # 23/com print(ret.group('id')) # 23 # 注意: ret=re.findall('www.(baidu|cnblogs).com','www.cnblosgs.com') print(ret) # ['cnblogs'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret=re.findall('www.(?:baidu|cnblogs).com','www.cnblogs.com') # 加上?:表示取消组的权限 print(ret) # ['www.cnblogs.com']
管道符 |
# '|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC' ret=re.search('(ab)|\d','rabhdg8sd') print(ret.group()) # ab
拓展
import re print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) # ['h1'] print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) # <_sre.SRE_Match object; span=(0, 14), match='<h1>hello</h1>'> print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")) # <_sre.SRE_Match object; span=(0, 14), match='<h1>hello</h1>'>
#匹配出所有的整数 import re #ret=re.findall(r"\d+{0}]","1-2*(60+(-40.35/5)-(-4*3))") ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") ret.remove("") print(ret) # ['1', '-2', '60', '5', '-4', '3']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号