fluentd中,sample输入插件的作用是什么?
in_sample输入插件的作用是什么?
- sample输入插件,用来产生样本事件。
- 主要用于:测试,调试,和压力测试。
- 这个插件,包含在fluentd的核心代码中
- sample是由dummy插件而来。dummy在1.11.1版本之后,改名为sample.
示例配置
<source> @type sample sample {"hello":"world"} # 后面是具体生成的数据 tag sample </source> <match sample.**> @type stdout </match>
fluentd是1.11.1及之前的版本,使用如下的配置
<source> @type dummy dummy {"hello":"world"} tag dummy </source> <match sample.**> @type stdout </match>
修改配置后,重启fluentd服务
systemctl restart td-agent
查看fluentd的日志
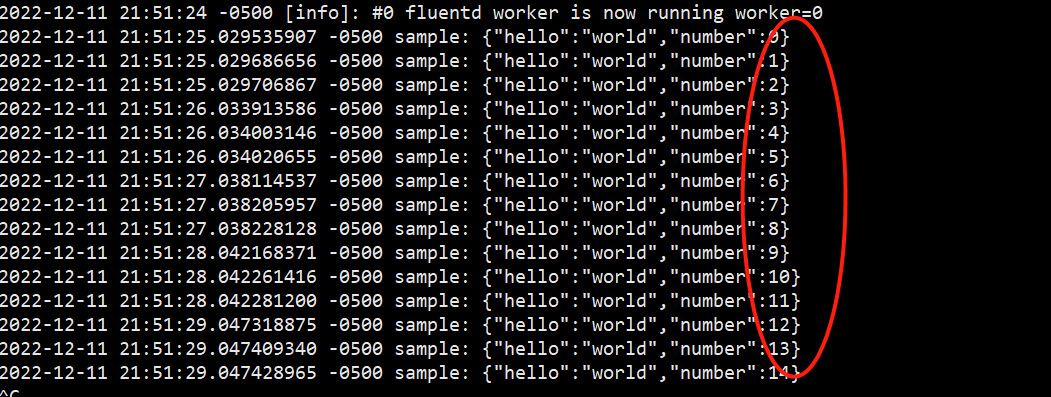
2022-12-11 21:13:16.025463038 -0500 sample: {"hello":"world"}
2022-12-11 21:13:17.030226348 -0500 sample: {"hello":"world"}
2022-12-11 21:13:18.034567035 -0500 sample: {"hello":"world"}
2022-12-11 21:13:19.035534972 -0500 sample: {"hello":"world"}
2022-12-11 21:13:20.041229570 -0500 sample: {"hello":"world"}
2022-12-11 21:13:21.044743524 -0500 sample: {"hello":"world"}
2022-12-11 21:13:22.050372237 -0500 sample: {"hello":"world"}
2022-12-11 21:13:23.054434973 -0500 sample: {"hello":"world"}
2022-12-11 21:13:24.057681448 -0500 sample: {"hello":"world"}
2022-12-11 21:13:25.061615612 -0500 sample: {"hello":"world"}
2022-12-11 21:13:26.064179152 -0500 sample: {"hello":"world"}
可以看到,每隔1秒钟,就会产生一次,样本或者说样例事件。
参数说明
sample有如下的其他的可以配置的参数
sample
后面接要生成的样例数据。是json格式。
数组形式,或者对象格式。
[{"message":"sample"}]
- 对象形式(大括号)
<source> @type sample sample {"hello":"world","time":"firsttest"} auto_increment_key number tag sample rate 3 </source> <match sample.**> @type stdout </match>
日志
2022-12-11 22:02:12.015593374 -0500 sample: {"hello":"world","time":"firsttest","number":96}
2022-12-11 22:02:12.015692296 -0500 sample: {"hello":"world","time":"firsttest","number":97}
2022-12-11 22:02:12.015711858 -0500 sample: {"hello":"world","time":"firsttest","number":98}
2022-12-11 22:02:13.019935712 -0500 sample: {"hello":"world","time":"firsttest","number":99}
2022-12-11 22:02:13.020026300 -0500 sample: {"hello":"world","time":"firsttest","number":100}
2022-12-11 22:02:13.020047705 -0500 sample: {"hello":"world","time":"firsttest","number":101}
2022-12-11 22:02:14.024082817 -0500 sample: {"hello":"world","time":"firsttest","number":102}
2022-12-11 22:02:14.024174741 -0500 sample: {"hello":"world","time":"firsttest","number":103}
2022-12-11 22:02:14.024206715 -0500 sample: {"hello":"world","time":"firsttest","number":104}
2022-12-11 22:02:15.028988007 -0500 sample: {"hello":"world","time":"firsttest","number":105}
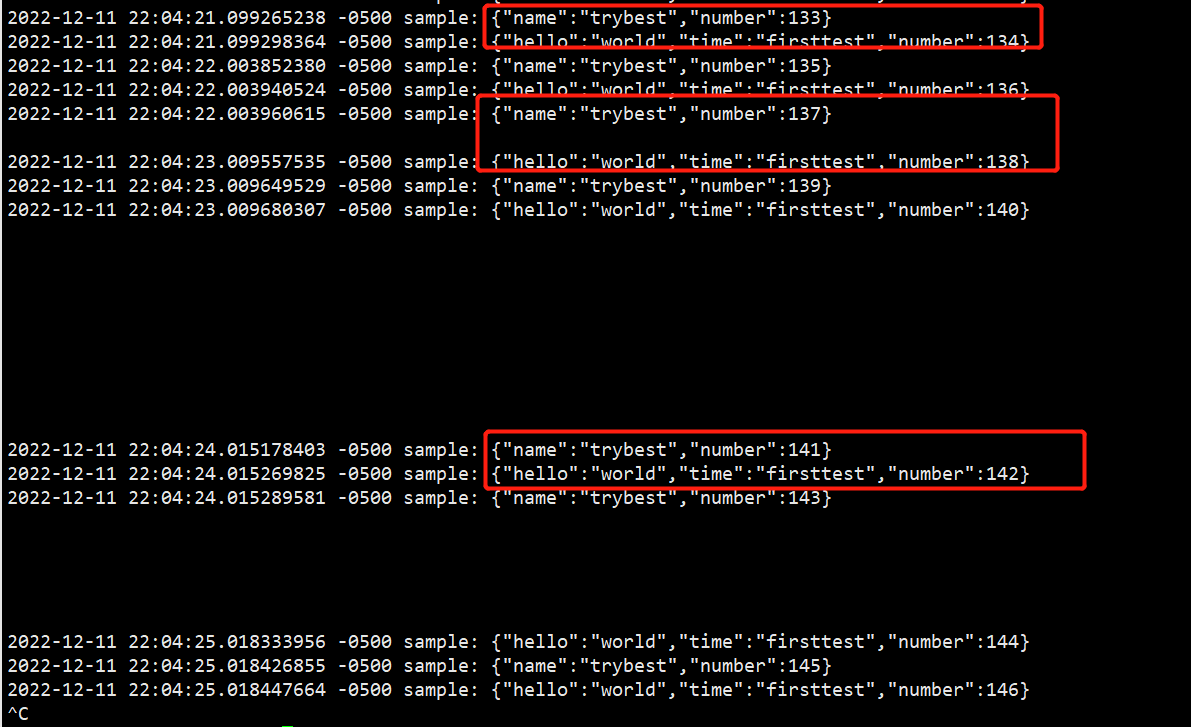
- 数组格式(方括号)
<source> @type sample sample [{"hello":"world","time":"firsttest"},{"name":"trybest"}] auto_increment_key number # 每个数据都有自增key和value tag sample rate 3 # 每秒钟3个事件 </source> <match sample.**> @type stdout </match>
日志
每个json对象,都是一个单独的事件!
size
每次触发,事件流的事件数(默认:1)
<source> @type sample sample {"hello":"world"} # 后面是具体生成的数据 tag sample size 3 </source> <match sample.**> @type stdout </match>
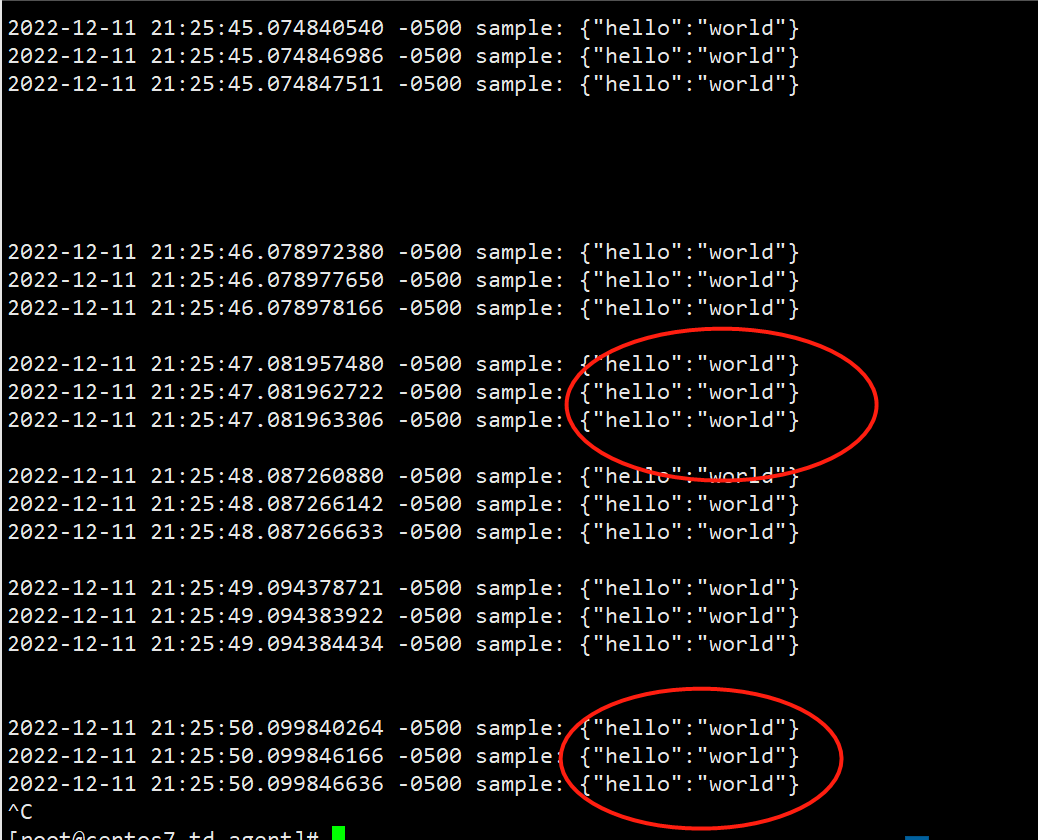
修改为3,之后,看fluentd的日志
每一次的采样,都会生成3个事件(size 3)
rate
控制每秒钟,产生的事件数(默认:1)—— 一个事件是一个事件流。
<source> @type sample sample {"hello":"world"} # 后面是具体生成的数据 tag sample rate 4 </source> <match sample.**> @type stdout </match>
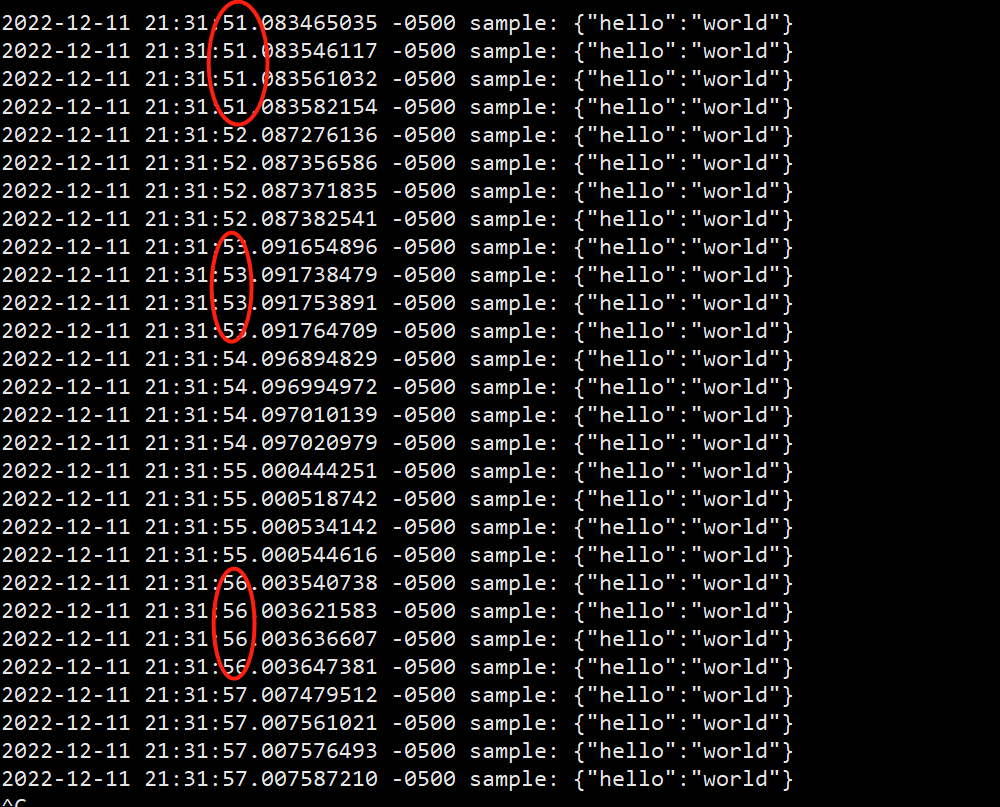
重启fluentd服务,查看日志
每秒钟生成4个事件。
size和rate之间,有什么区别呢?
如果是如下的配置,既有size,又有rate
<source> @type sample sample {"hello":"world"} tag sample rate 4 size 3 </source> <match sample.**> @type stdout </match>
查看日志
每次输出12个事件。
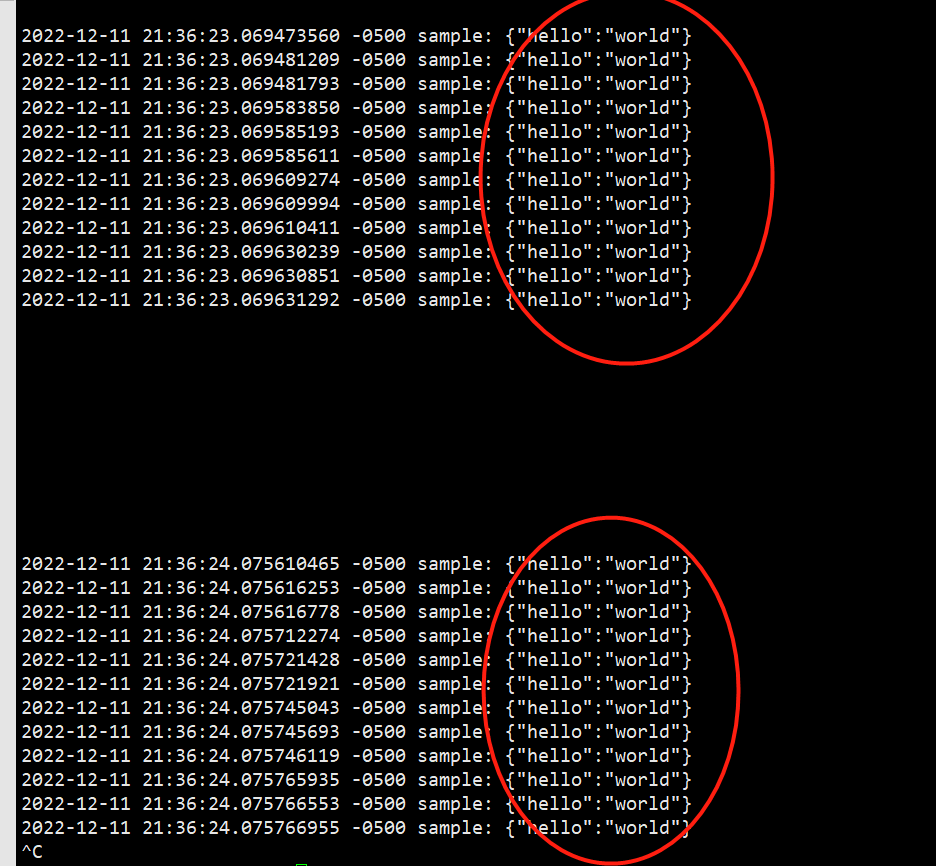
所以:
rate: 每秒钟的事件数,或者说事件流的数量。
size: 一个事件流中的事件数
两个参数都有的话,就是相乘的关系。
auto_increment_key
可以在采样数据中,定义一个自增的字段。
如:
<source> @type sample sample {"hello":"world"} auto_increment_key number # 指定自增的key tag sample rate 3 </source> <match sample.**> @type stdout </match>
输出的日志:增加了number的key,值是一个自增的值,附加在采样数据的后面。