
sklearn中CountVectorizer使用小记录
CountVectorizer的参数中可传入分词器
vectorizer = CountVectorizer(tokenzer.cut) corpus = [ "中文的信息无处不在"] X=vectorizer.fit_transform(corpus)

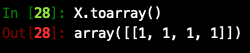

CountVectorizer的参数中可传入分词器
vectorizer = CountVectorizer(tokenzer.cut) corpus = [ "中文的信息无处不在"] X=vectorizer.fit_transform(corpus)

