

From the previous blog, I know that there are a lot of zero, which will trigger many questions, such as unpredictability in test data, unavailability of preplexity. So, now we introduce the method smoothing.
previous : P(wi | wi-1) = c(wi-1, wi) / c(wi)
using smoothing: P(wi | wi-1) = ( c(wi-1, wi) + 1 ) / (c(wi-1) + V)
Then we can ensure that the p will not be zero. Now we can estimate this mothed.
We can use the Reconsitituted formula: c(wi-1, wi) = P(wi | wi-1) * c(wi-1) = ( c(wi-1, wi) + 1 ) / (c(wi-1) + V) * c(wi-1).
By using this formula, we can gain the the difference between them as following.
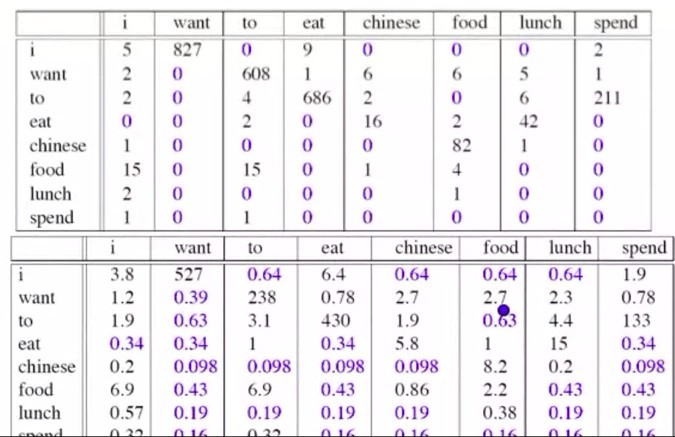
So add-one smoothing makes massive changes to our accounts. In other word, add-one estimation is a very blunt instrument. So in practice we don't actually use add-one smoothing for n-grams. we have better methods. But we do use add-one smoothing for other kinds of NLP models such text classification, or it will be used in similar kinds of domain where the number of zeros isn't so enormous.

