TCP/IP协议栈在Linux内核中的运行时序分析
1. Linux概述
1.1 Linux操作系统架构简介
Linux操作系统总体上由Linux内核和GNU系统构成,具体来讲由4个主要部分构成,即Linux内核、Shell、文件系统和应用程序。内核、Shell和文件系统构成了操作系统的基本结构,使得用户可以运行程序、管理文件并使用系统。
内核是操作系统的核心,具有很多最基本功能,如虚拟内存、多任务、共享库、需求加载、可执行程序和TCP/IP网络功能。我们所调研的工作,就是在Linux内核层面进行分析。
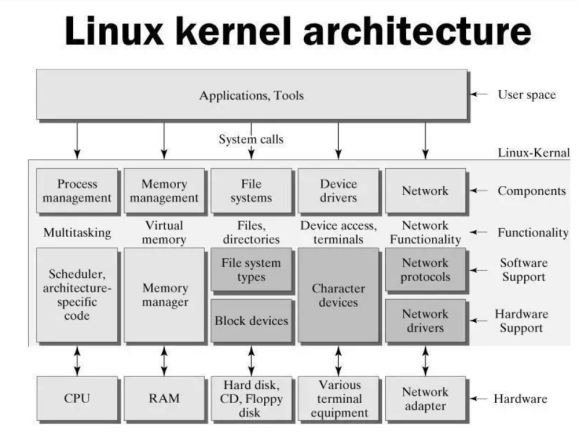
1.2 OSI、TCP/IP协议栈与Linux网络架构
1.2.1 OSI与TCP/IP协议栈
OSI(Open System Interconnect),即开放式系统互联。 一般都叫OSI参考模型,是ISO(国际标准化组织)组织在1985年研究的网络互连模型。ISO为了更好的使网络应用更为普及,推出了OSI参考模型。其含义就是推荐所有公司使用这个规范来控制网络。这样所有公司都有相同的规范,就能互联了。
OSI定义了网络互连的七层框架(物理层、数据链路层、网络层、传输层、会话层、表示层、应用层),即ISO开放互连系统参考模型。
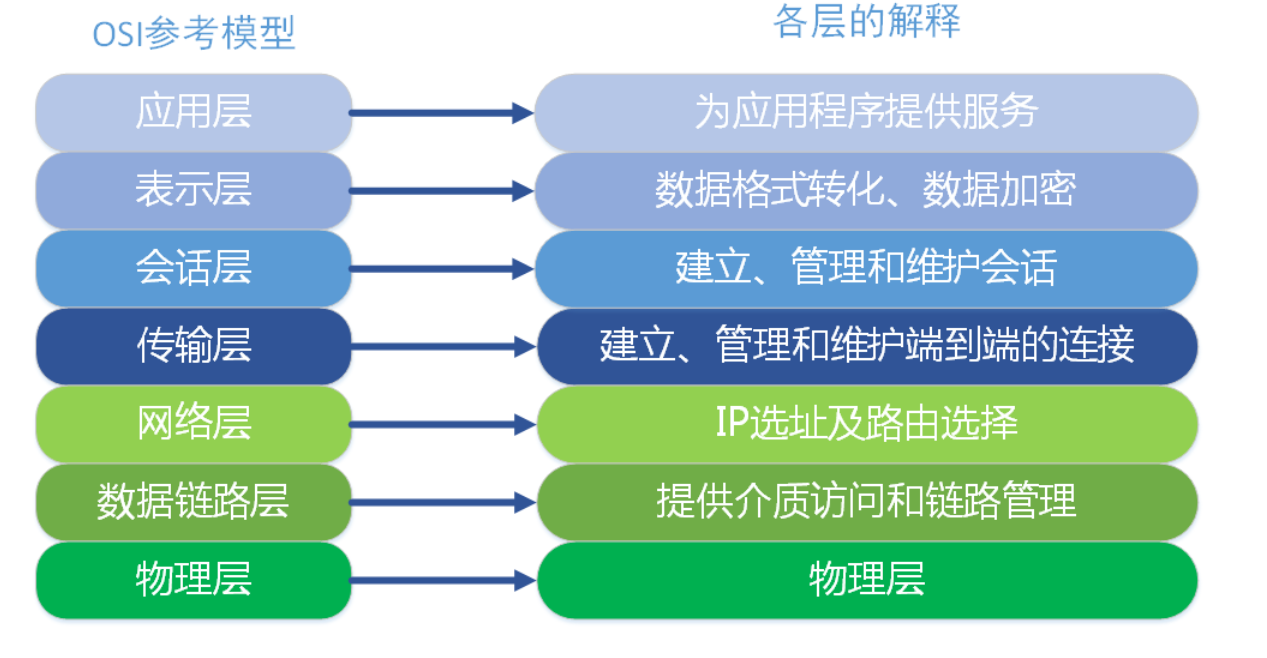
在实际使用过程中,用得最多的是TCP/IP协议,以下是OSI协议与TCP/IP协议的对比。

各层的功能如下:
1、应用层的功能为对客户发出的一个请求,服务器作出响应并提供相应的服务。
2、传输层的功能为通信双方的主机提供端到端的服务,传输层对信息流具有调节作用,提供可靠性传输,确保数据到达无误。
3、网络层功能为进行网络互连,根据网间报文IP地址,从一个网络通过路由器传到另一网络。
4、网络接口层负责接收IP数据报,并负责把这些数据报发送到指定网络上。
1.2.2 Linux网络架构
Linux的网络架构从上往下可以分为三层,分别是 :用户空间的应用层;内核空间的网络协议栈层; 物理硬件层。 其中最重要最核心的当然是内核空间的协议栈层了。
Linux网络协议栈结构Linux的整个网络协议栈都构建与Linux Kernel中,整个栈也是严格按照分层的思想来设计的,整个栈共分为五层,分别是 :
1,系统调用接口层,实质是一个面向用户空间应用程序的接口调用库,向用户空间应用程序提供使用网络服务的接口。
2,协议无关的接口层,就是SOCKET层,这一层的目的是屏蔽底层的不同协议(更准确的来说主要是TCP与UDP,当然还包括RAW IP, SCTP等),以便与系统调用层之间的接口可以简单,统一。简单的说,不管我们应用层使用什么协议,都要通过系统调用接口来建立一个SOCKET,这个SOCKET其实是一个巨大的sock结构,它和下面一层的网络协议层联系起来,屏蔽了不同的网络协议的不同,只吧数据部分呈献给应用层(通过系统调用接口来呈献)。
3,网络协议实现层,毫无疑问,这是整个协议栈的核心。这一层主要实现各种网络协议,最主要的当然是IP,ICMP,ARP,RARP,TCP,UDP等。这一层包含了很多设计的技巧与算法,相当的不错。
4,与具体设备无关的驱动接口层,这一层的目的主要是为了统一不同的接口卡的驱动程序与网络协议层的接口,它将各种不同的驱动程序的功能统一抽象为几个特殊的动作,如open,close,init等,这一层可以屏蔽底层不同的驱动程序。
5,驱动程序层,这一层的目的就很简单了,就是建立与硬件的接口层。
可以看到,Linux网络协议栈是一个严格分层的结构,其中的每一层都执行相对独立的功能,结构非常清晰。
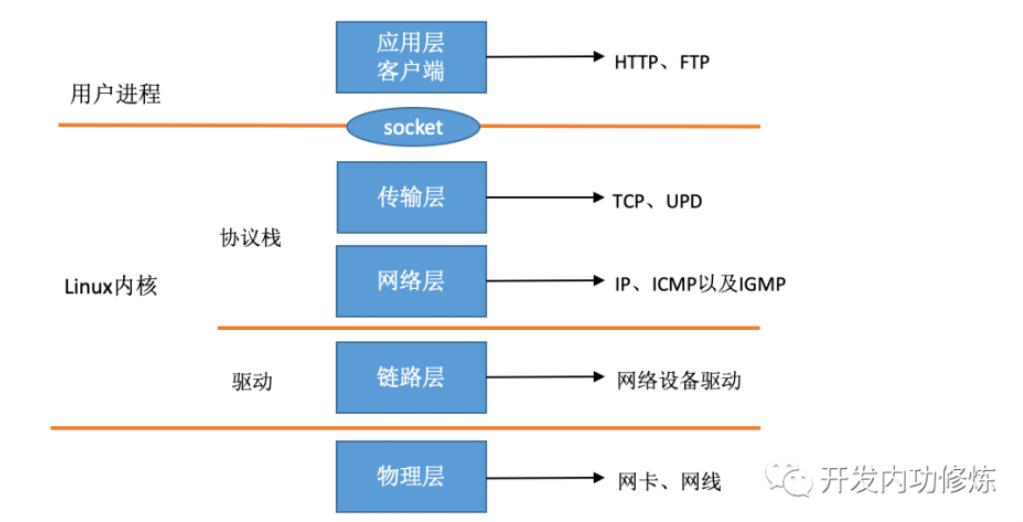
1.2.3 各层次涉及的主要数据结构与函数

2. socket简介
socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在socket接口后面,对用户来说,一组简单的接口就是全部,让socket去组织数据,以符合指定的协议。所以,我们无需深入理解tcp/ip协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵守tcp/udp标准的。
2.1 本次调研所用代码
"socketwrapper.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <fcntl.h>
#include <sys/types.h>
#define MYPORT 3490 /* 监听的端口 */
#define BACKLOG 10 /* listen的请求接收队列长度 */
#define MAXDATASIZE 100
#define IP_ADDR "127.0.0.1"
// 如果是在windows环境下
#ifdef _WIN32
#include <winsock2.h>
#include <windows.h>
#else
//如果是在其他环境下
#include <sys/wait.h>
#include <sys/time.h>
#include <unistd.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <netdb.h>
#endif
//socket服务端初始环境配置
#ifdef _WIN32
#define prepareSocket(port) \
WORD sockVersion = MAKEWORD(2, 2); \
WSADATA ws; \
if(WSAStartup(sockVersion, &ws) != 0){ \
return -1; \
} \
int ret = -1; \
struct sockaddr_in serveraddr; \
struct sockaddr_in clientaddr; \
serveraddr.sin_family = AF_INET; \
serveraddr.sin_port = htons(port); \
serveraddr.sin_addr.S_un.S_addr = INADDR_ANY; \
SOCKET sockfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); \
if(sockfd == INVALID_SOCKET){ \
printf("can not create a socket!\n"); \
return -2; \
}
#else
#define prepareSocket(addr,port) \
int sockfd = -1; \
struct sockaddr_in serveraddr; \这里定义了一个struct msghdr msg
struct sockaddr_in clientaddr; \
socklen_t addr_len = sizeof(struct sockaddr); \
serveraddr.sin_family = AF_INET; \
serveraddr.sin_port = htons(port); \
serveraddr.sin_addr.s_addr = inet_addr(addr); \
memset(&serveraddr.sin_zero, 0, 8); \
sockfd = socket(PF_INET,SOCK_STREAM,0);
#endif
//初始化client端的环境
#ifdef _WIN32
#define prepareSocketClient(addr, port) \
WORD sockVersion = MAKEWORD(2, 2); \
WSADATA ws; \
if(WSAStartup(sockVersion, &ws) != 0){ \
return -1; \
} \
int ret = -1; \
struct sockaddr_in serveraddr; \
struct sockaddr_in clientaddr; \
serveraddr.sin_family = AF_INET; \
serveraddr.sin_port = htons(port); \
serveraddr.sin_addr.S_un.S_addr = inet_addr(addr); \
SOCKET sockfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); \
if(sockfd == INVALID_SOCKET){ \
printf("can not create a socket!\n"); \
return -2; \
}
#else
#define prepareSocketClient(addr,port) \
int sockfd = -1; \
struct sockaddr_in serveraddr; \
struct sockaddr_in clientaddr; \
socklen_t addr_len = sizeof(struct sockaddr); \
serveraddr.sin_family = AF_INET; \
serveraddr.sin_port = htons(port); \
serveraddr.sin_addr.s_addr = inet_addr(addr); \
memset(&serveraddr.sin_zero, 0, 8); \
sockfd = socket(PF_INET,SOCK_STREAM,0);
#endif
//绑定server端,并开始监听
#ifdef _WIN32
#define bindServer() \
if(bind(sockfd, (LPSOCKADDR)&serveraddr, sizeof(serveraddr)) == SOCKET_ERROR){ \
printf("can not bind the port 3490!\n"); \
return -3; \
} \
if(listen(sockfd, BACKLOG) == SOCKET_ERROR){ \
printf("listen error!\n"); \
return -4; \
}
#else
#define bindServer() \
int ret = bind( sockfd, \
(struct sockaddr *)&serveraddr, \
sizeof(struct sockaddr)); \
if(ret == -1) \
{ \
fprintf(stderr,"Bind Error,%s:%d\n", \
__FILE__,__LINE__); \
close(sockfd); \
return -1; \
} \
listen(sockfd, BACKLOG);
#endif
//同意来自client的连接请求
#ifdef _WIN32
#define allowClient() \
SOCKET newfd; \
int len = sizeof(clientaddr); \
newfd = accept(sockfd, (SOCKADDR*)&clientaddr, &len); \
if(newfd == INVALID_SOCKET){ \
printf("accept error!\n"); \
return -5; \
}
#else
#define allowClient() \
int newfd = accept( sockfd, \
(struct sockaddr *)&clientaddr, \
&addr_len); \
if(newfd == -1) \
{ \
fprintf(stderr,"Accept Error,%s:%d\n", \
__FILE__,__LINE__); \
}
#endif
//client连接server
#ifdef _WIN32
#define connectServer() \
if(connect(sockfd, (struct sockaddr*)&serveraddr, sizeof(serveraddr)) == SOCKET_ERROR){ \
printf("failed to connect to server!\n"); \
closesocket(sockfd); \
return -3; \
} \
SOCKET newfd = sockfd; \
printf("connectd successfully\n");
#else
#define connectServer() \
int ret = connect(sockfd, \
(struct sockaddr *)&serveraddr, \
sizeof(struct sockaddr)); \
if(ret == -1) \
{ \
fprintf(stderr,"Connect Error,%s:%d\n", \
__FILE__,__LINE__); \
return -1; \
}
#endif
//整合某些共同操作
//server端的初始化与绑定
#ifdef _WIN32
#define initServer() \
prepareSocket(MYPORT); \
bindServer();
#else
#define initServer() \
prepareSocket(IP_ADDR, MYPORT); \
bindServer();
#endif
//client端的初始化
#ifdef _WIN32
#define initClient() \
prepareSocketClient(IP_ADDR, MYPORT); \
connectServer();
#else
#define initClient() \
prepareSocketClient(IP_ADDR, MYPORT); \
connectServer(); \
int newfd = sockfd;
#endif
//以下为关闭socket操作
//closeService————关闭newfd(一般用于server端的循环中)
//shutdownClient————客户端退出使用socket
//shutdownServer————服务端退出使用socket
#ifdef _WIN32
#define closeService() \
closesocket(newfd);
#else
#define closeService() \
close(newfd);
#endif
#ifdef _WIN32
#define shutdownClient() \
closesocket(sockfd); \
WSACleanup();
#else
#define shutdownClient() \
close(sockfd);
#endif
#ifdef _WIN32
#define shutdownServer() \
closesocket(sockfd); \
WSACleanup();
#else
#define shutdownServer() \
close(sockfd);
#endif
//定义数据发送接收功能
#define getMessage(buf, addr) \
ret = recv(newfd,buf,MAXDATASIZE,0); \
if(ret > 0) \
{ \
printf("recv \"%s\" from %s:%d\n", \
buf, \
(char*)inet_ntoa(addr.sin_addr), \
ntohs(addr.sin_port)); \
}
#define sendMessage(buf, addr) \
ret = send(newfd,buf,strlen(buf),0); \
if(ret > 0) \
{ \
printf("send \"%s\" to %s:%d\n", buf , \
(char*)inet_ntoa(addr.sin_addr), \
ntohs(addr.sin_port)); \
}
客户端:"client.c"
#include"socketwrapper.h"
int main()
{
char sendbuf[MAXDATASIZE] = "hello\0";
char recvbuf[MAXDATASIZE] = "\0";
initClient();
sendMessage(sendbuf, serveraddr);
getMessage(recvbuf, serveraddr);
system("pause");
shutdownClient();
return 0;
}
服务端:"server.c"
#include"socketwrapper.h"
int main()
{
char recvbuf[MAXDATASIZE] = "\0";
char sendbuf[MAXDATASIZE] = "hi";
initServer();
while(1)
{
allowClient();
getMessage(recvbuf, clientaddr);
sendMessage(sendbuf, clientaddr);
closeService();
}
shutdownServer();
return 0;
}
2.2 socket发送与接收具体流程
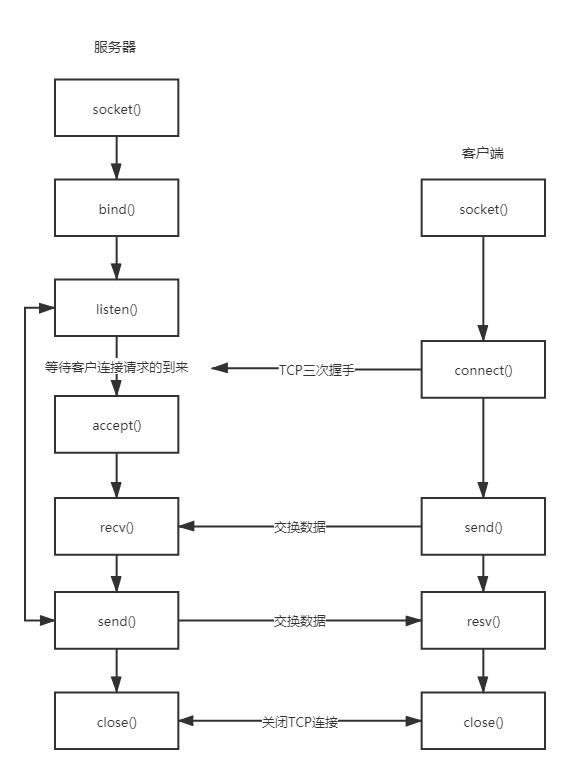
2.3 关键函数介绍
2.3.1 socket创建
#include <sys/types.h>
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
domain:
AF_INET 这是大多数用来产生socket的协议,使用TCP或UDP来传输,用IPv4的地址
AF_INET6 与上面类似,不过是采用IPv6的地址
AF_UNIX 本地协议,使用在Unix和Linux系统上,一般都是当客户端和服务器在同一台及其上的时候使用
type:
(1)SOCK_STREAM 这个协议是按照顺序的、可靠的、数据完整的基于字节流的连接。这是一个使用最多的socket类型,这个socket是使用TCP来进行传输。
(2)SOCK_DGRAM 这个协议是无连接的、固定长度的传输调用。该协议是不可靠的,使用UDP来进行它的连接。
(3)SOCK_SEQPACKET 这个协议是双线路的、可靠的连接,发送固定长度的数据包进行传输。必须把这个包完整的接受才能进行读取。
(4)SOCK_RAW 这个socket类型提供单一的网络访问,这个socket类型使用ICMP公共协议。(ping、traceroute使用该协议)。
(5)SOCK_RDM 这个类型是很少使用的,在大部分的操作系统上没有实现,它是提供给数据链路层使用,不保证数据包的顺序。
protocol:
0:默认协议
返回值
成功返回一个新的文件描述符(也叫监听套接字),失败返回-1。
2.3.2 bind绑定
在创建了套接字之后需要IP和端口号和套接字绑定在一起( IP地址:在网络环境中,唯一标识一台主机,端口号:在主机中唯一标识一个进程)。struct sockaddr *是一个通用指针类型,addr参数实际上可以接受多种协议的sockaddr结构体,而它们的长度各不相同,所以需要第三个参数addrlen指定结构体的长度。
#include <sys/types.h>
#include <sys/socket.h>
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd:文件描述符;
addr:构造出IP地址加端口号;
addrlen:sizeof(addr)长度;
返回值:成功返回0,失败返回-1,设置errno。
2.3.3 listen
创建了套接字之后通常需要等待客户端的连接,此时可以使用listen函数将该套接字转换为倾听套接字;可以指定同时连接的最大客户端数量;若达到数量上限,新客户端等待其它已链接的客户端链接结束。
#include <sys/types.h>
#include <sys/socket.h>
int listen(int sockfd, int backlog);
sockfd:文件描述符;
backlog:排队建立3次握手队列和刚刚建立3次握手队列的连接数和;
返回值:成功返回0,失败返回-1。
2.3.4 accept
当服务器倾听到一个连接之后,可以使用函数accept从倾听套接字的完成连接队列中接收一个连接,如果这个完成连接队列为空,则会使得这个进程进入睡眠状态。
#include <sys/types.h>
#include <sys/socket.h>
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
sockdf:文件描述符;
addr:传出参数,返回链接客户端地址信息,含IP地址和端口号;
addrlen:传入传出参数,传入sizeof(addr)大小,函数返回时返回真正接收到地址结构体的大小;
返回值:成功返回一个新的socket文件描述符,用于和客户端通信,失败返回-1,设置errno。
2.3.5 connect客户端连接函数
客户端需要调用connect()连接服务器,connect和bind的参数形式一致,区别在于bind的参数是自己的地址,而connect的参数是对方的地址。
#include <sys/types.h>
#include <sys/socket.h>
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
sockfd:文件描述符;
addr:传入参数,指定服务器端地址信息,含IP地址和端口号;
addrlen:传入参数,传入sizeof(addr)大小;
返回值:成功返回0,失败返回-1,设置errno。
2.3.6 send以及recv函数
#include <unistd.h>
int send(int sockfd,const void* msg,int len,int flags);
int recv(int sockfd,void* buf,int len,unsigned int flags);
sockfd:套接字描述符;
msg:要发送的信息;
buf:指定数据缓冲区;
len:指定接收或发送的数据量大小(以字节为单位);
flags:该参数设置为0
返回值:系统调用send()返回实际发送的字节数,失败返回-1;系统调用recv()返回实际读取到缓冲区的字节数,如果出错则返回-1。
2.4 socket源码分析(linux内核版本为5.4.34)
struct socket {
socket_state state;//套接字所处状态,比如CONNECTED
short type;//type是socket的类型,SOCK_DGRAM = 1, SOCK_STREAM = 2, SOCK_RAW = 3, SOCK_RDM = 4, SOCK_SEQPACKET = 5, SOCK_DCCP = 6, SOCK_PACKET = 10,
unsigned long flags//标志位,负责一些特殊的设置,比如SOCK_ASYNC_NOSPACE
struct file *file;//与socket相关的指针列表
struct sock *sk;// sk是网络层对于socket的表示
const struct proto_ops *ops;//ops是协议相关的一组操作集,协议栈中总共定义了三个strcut proto_ops类型的变量,分别是myinet_stream_ops, myinet_dgram_ops, myinet_sockraw_ops,对应流协议, 数据报和原始套接口协议的操作函数集。
struct socket_wq wq;//等待队列
};
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_node __sk_common.skc_node //raw通过raw_hash_sk sk->sk_node加入到raw_hashinfo的ht,相当于struct sock连接到了raw_hashinfo中
#define sk_nulls_node __sk_common.skc_nulls_node //tcp通过inet_hash把sk->skc_nulls_node加入到tcp_hashinfo结构中的listening_hash。见__sk_nulls_add_node_rcu
#define sk_refcnt __sk_common.skc_refcnt
#define sk_tx_queue_mapping __sk_common.skc_tx_queue_mapping
#ifdef CONFIG_XPS
#define sk_rx_queue_mapping __sk_common.skc_rx_queue_mapping
#endif
#define sk_dontcopy_begin __sk_common.skc_dontcopy_begin
#define sk_dontcopy_end __sk_common.skc_dontcopy_end
#define sk_hash __sk_common.skc_hash
#define sk_portpair __sk_common.skc_portpair
#define sk_num __sk_common.skc_num
#define sk_dport __sk_common.skc_dport
#define sk_addrpair __sk_common.skc_addrpair
#define sk_daddr __sk_common.skc_daddr
#define sk_rcv_saddr __sk_common.skc_rcv_saddr
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state //创建sk的时候,默认为TCP_CLOSE sock_init_data
#define sk_reuse __sk_common.skc_reuse
#define sk_reuseport __sk_common.skc_reuseport
#define sk_ipv6only __sk_common.skc_ipv6only
#define sk_net_refcnt __sk_common.skc_net_refcnt
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_bind_node __sk_common.skc_bind_node
#define sk_prot __sk_common.skc_prot
#define sk_net __sk_common.skc_net
#define sk_v6_daddr __sk_common.skc_v6_daddr
#define sk_v6_rcv_saddr __sk_common.skc_v6_rcv_saddr
#define sk_cookie __sk_common.skc_cookie
#define sk_incoming_cpu __sk_common.skc_incoming_cpu
#define sk_flags __sk_common.skc_flags /*
* 标志位,可能的取值参见枚举类型sock_flags.
* 判断某个标志是否设置调用sock_flag函数来
* 判断,而不是直接使用位操作。
*/
#define sk_rxhash __sk_common.skc_rxhash
socket_lock_t sk_lock; /*
* 同步锁,其中包括了两种锁:一是用于用户进程读取数据
* 和网络层向传输层传递数据之间的同步锁;二是控制Linux
* 下半部访问本传输控制块的同步锁,以免多个下半部同
* 时访问本传输控制块
*/
atomic_t sk_drops; //接收缓冲区大小的上限,当sock接收到一个包的时候,会在sock_queue_rcv_skb中判断当前队列中已有的skb占用的buffer和这个新来的buff之后是否超过了sk_rcvbuf
int sk_rcvlowat;
struct sk_buff_head sk_error_queue; //错误队列
struct sk_buff *sk_rx_skb_cache; //
struct sk_buff_head sk_receive_queue; //接收队列,等待用户进程读取。
/*
* The backlog queue is special, it is always used with
* the per-socket spinlock held and requires low latency
* access. Therefore we special case it's implementation.
* Note : rmem_alloc is in this structure to fill a hole
* on 64bit arches, not because its logically part of
* backlog.
*/
/*在接收到数据包之后,如果判断此套接口当前正被用户进程所使用,数据包将被保存到套接口结构的sk_backlog成员的head所定义的skb缓存列表中,tail指向链表的末尾,len变量记录了当前链表中所有skb的总长度。*/
struct {
atomic_t rmem_alloc;
int len;
struct sk_buff *head;
struct sk_buff *tail;
} sk_backlog;
#define sk_rmem_alloc sk_backlog.rmem_alloc
int sk_forward_alloc; //预分配缓存额度
#ifdef CONFIG_NET_RX_BUSY_POLL
unsigned int sk_ll_usec;
/* ===== mostly read cache line ===== */
unsigned int sk_napi_id;
#endif
int sk_rcvbuf; //接收缓冲区大小
struct sk_filter __rcu *sk_filter; /*
* 套接字过滤器。在传输层对输入的数据包通过BPF过滤代码进行过滤,
* 只对设置了套接字过滤器的进程有效。
*/
union {
struct socket_wq __rcu *sk_wq;
struct socket_wq *sk_wq_raw;
}; //进程等待队列。进程等待连接、等待输出缓冲区、等待读数据时,都会将进程暂存到此队列中。
#ifdef CONFIG_XFRM
struct xfrm_policy __rcu *sk_policy[2];
#endif
struct dst_entry *sk_rx_dst;
struct dst_entry __rcu *sk_dst_cache;/*目的路由项缓存,一般都是在创建传输控制块发送数据报文时,发现未设置该字段才从路由表或路由缓存中查询到相应的路由项来设置新字段,这样可以加速数据的输出,后续数据的输出不必再查询目的路由。某些情况下会刷新此目的路由缓存,比如断开连接、重新进行了连接、TCP重传、重新绑定端等操作*/
atomic_t sk_omem_alloc;
int sk_sndbuf; //发送缓冲区长度的上限,发送队列中报文数据总长度不能超过该值
/* ===== cache line for TX ===== */
int sk_wmem_queued; // persistent queue size,skb_entail中会赋值
refcount_t sk_wmem_alloc; //这个只针对发送数据,接收数据对应的是sk_rmem_alloc
unsigned long sk_tsq_flags;
union {
struct sk_buff *sk_send_head;
struct rb_root tcp_rtx_queue;
};
struct sk_buff *sk_tx_skb_cache;
struct sk_buff_head sk_write_queue; //数据包发送队列
__s32 sk_peek_off;
int sk_write_pending;
__u32 sk_dst_pending_confirm;
u32 sk_pacing_status; /* see enum sk_pacing */
long sk_sndtimeo; //套接字层发送超时,初始值为MAX_SCHEDULE_TIMEOUT
struct timer_list sk_timer; //通过TCP的不同状态,来实现连接定时器、FIN_WAIT_2定时器(该定时器在TCP四次挥手过程中结束,见tcp_rcv_state_process)以及TCP保活定时器,在tcp_keepalive_timer中实现
__u32 sk_priority; //SKB->priority就是用的该字段
__u32 sk_mark;
unsigned long sk_pacing_rate; /* bytes per second */
unsigned long sk_max_pacing_rate;
struct page_frag sk_frag;
netdev_features_t sk_route_caps;
netdev_features_t sk_route_nocaps;
netdev_features_t sk_route_forced_caps;
int sk_gso_type;
unsigned int sk_gso_max_size;
gfp_t sk_allocation;
__u32 sk_txhash;
/*
* Because of non atomicity rules, all
* changes are protected by socket lock.
*/
unsigned int __sk_flags_offset[0];
#ifdef __BIG_ENDIAN_BITFIELD
#define SK_FL_PROTO_SHIFT 16
#define SK_FL_PROTO_MASK 0x00ff0000
#define SK_FL_TYPE_SHIFT 0
#define SK_FL_TYPE_MASK 0x0000ffff
#else
#define SK_FL_PROTO_SHIFT 8
#define SK_FL_PROTO_MASK 0x0000ff00
#define SK_FL_TYPE_SHIFT 16
#define SK_FL_TYPE_MASK 0xffff0000
#endif
unsigned int sk_padding : 1,
sk_kern_sock : 1,
sk_no_check_tx : 1,
sk_no_check_rx : 1,
sk_userlocks : 4,
sk_protocol : 8,
sk_type : 16;
#define SK_PROTOCOL_MAX U8_MAX
u16 sk_gso_max_segs;
u8 sk_pacing_shift;
unsigned long sk_lingertime;
struct proto *sk_prot_creator;
rwlock_t sk_callback_lock;
int sk_err,
sk_err_soft;
u32 sk_ack_backlog;
u32 sk_max_ack_backlog;
kuid_t sk_uid;
struct pid *sk_peer_pid;
const struct cred *sk_peer_cred; //返回连接至该套接字的外部进程的身份验证,目前主要用于PF_UNIX协议族
long sk_rcvtimeo; //套接字层接收超时,初始值为MAX_SCHEDULE_TIMEOUT。
ktime_t sk_stamp; /*
* 在未启用SOCK_RCVTSTAMP套接字选项时,记录报文接收数据到
* 应用层的时间戳。在启用SOCK_RCVTSTAMP套接字选项时,接收
* 数据到应用层的时间戳记录在SKB的tstamp中
*/
#if BITS_PER_LONG==32
seqlock_t sk_stamp_seq;
#endif
u16 sk_tsflags;
u8 sk_shutdown;
u32 sk_tskey;
atomic_t sk_zckey;
u8 sk_clockid;
u8 sk_txtime_deadline_mode : 1,
sk_txtime_report_errors : 1,
sk_txtime_unused : 6;
struct socket *sk_socket; //指向对应套接字的指针
void *sk_user_data;
#ifdef CONFIG_SECURITY
void *sk_security;
#endif
struct sock_cgroup_data sk_cgrp_data;
struct mem_cgroup *sk_memcg;
void (*sk_state_change)(struct sock *sk); //当传输控制块的状态发生变化时,唤醒那些等待本套接字的进程。
void (*sk_data_ready)(struct sock *sk); //当有数据到达接收处理时,唤醒或发送信号通知准备读本套接字的进程。
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk,
struct sk_buff *skb);
#ifdef CONFIG_SOCK_VALIDATE_XMIT
struct sk_buff* (*sk_validate_xmit_skb)(struct sock *sk,
struct net_device *dev,
struct sk_buff *skb);
#endif
void (*sk_destruct)(struct sock *sk);
struct sock_reuseport __rcu *sk_reuseport_cb;
#ifdef CONFIG_BPF_SYSCALL
struct bpf_sk_storage __rcu *sk_bpf_storage;
#endif
struct rcu_head sk_rcu;
};
/* struct sk_buff是linux网络系统中的核心结构体,linux网络中的所有数据包的封装以及解封装都是在这个结构体的基础上进行。*/
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next; //列表中下一个buffer
struct sk_buff *prev; //列表中上一个buffer
union {
struct net_device *dev; //处理分组的网络设备
/* Some protocols might use this space to store information,
* while device pointer would be NULL.
* UDP receive path is one user.
*/
unsigned long dev_scratch;
};
};
struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack */
struct list_head list;
};
union {
struct sock *sk; //指向拥有此缓冲区套接字的sock数据结构。当缓冲区只是转发则不需要设置为NULL
int ip_defrag_offset;
};
union {
ktime_t tstamp; //分组到达或离开的时间
u64 skb_mstamp_ns; /* earliest departure time */
};
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8); //控制缓存,给每层使用,可以将私有变量放在此处。如果要跨越不同层,就需要调用skb_clone.
union {
struct {
unsigned long _skb_refdst; //目标入口(with norefcount bit)
void (*destructor)(struct sk_buff *skb);
};
struct list_head tcp_tsorted_anchor;
};
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
unsigned long _nfct; // 连接跟踪
#endif
unsigned int len, ////缓冲区中数据区块的大小。包括由head所指以及一些片段数据。当从一个分层移动到另一个分层时候回发生变化。协议报头也算在里面。
data_len; //只计算片段中的数据大小
__u16 mac_len, //mac报头的大小
hdr_len; //克隆的skb可写的头长度
/* Following fields are _not_ copied in __copy_skb_header()
* Note that queue_mapping is here mostly to fill a hole.
*/
__u16 queue_mapping; //多设备的队列映射
/* if you move cloned around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define CLONED_MASK (1 << 7)
#else
#define CLONED_MASK 1
#endif
#define CLONED_OFFSET() offsetof(struct sk_buff, __cloned_offset)
__u8 __cloned_offset[0];
__u8 cloned:1, //表示该结构是另一个sk_buff克隆的
nohdr:1, //payload是否被单独引用,不存在协议首部,如果被引用,则不能修改协议首部,也不能通过skb->data来访问协议首部
fclone:2, //套接字缓冲区克隆的状态位,当前克隆状态SKB_FCLONE_UNAVAILABLE-skb未被克隆;SKB_FCLONE_ORIG-在skbuff_fclone_cache分配的父skb,可以被克隆;SKB_FCLONE_CLONE-在skbuff_fclone_cache分配的子skb,从父skb克隆得到
peeked:1, //这个包已经被发现了,所以该状态位说明他已经做过了相关操作,不要再做一次
head_frag:1, //通过page_fragment_alloc分配内存
pfmemalloc:1; // PFMEMALLOC内存分配标记
#ifdef CONFIG_SKB_EXTENSIONS
__u8 active_extensions;
#endif
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
__u32 headers_start[0];
/* public: */
/* if you move pkt_type around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_TYPE_MAX (7 << 5)
#else
#define PKT_TYPE_MAX 7
#endif
#define PKT_TYPE_OFFSET() offsetof(struct sk_buff, __pkt_type_offset)
__u8 __pkt_type_offset[0];
__u8 pkt_type:3; /*
此字段根据L2的目的地址进行划分
PACKET_HOST-mac地址与接收设备mac地址相等,说明是发给该主机的
PACKET_BROADCAST-mac地址是接收设备的广播地址
PACKET_MULTICAST-mac地址接收改设备注册的多播地址之一
PACKET_OTHERHOST-mac地址不属于接收设备的地址,启用转发则转发,否则丢弃
PACKET_OUTGOING-数据包将被发出,用到这个标记的功能包括decnet,或者为每个
网络tab都复制一份发出包的函数
PACKET_LOOPBACK-数据包发往回环设备,有此标识,处理回环设备时,
可以跳过一些真实设备所需的操作
PACKET_USER-发送到用户空间,netlink使用
PACKET_KERNEL-发送到内核空间,netlink使用
PACKET_FASTROUTE-未使用
*/
__u8 ignore_df:1; //是否进行分片
__u8 nf_trace:1; //netfilter packet trace flag
__u8 ip_summed:2; /*
CHECKSUM_NONE-硬件不支持,完全由软件执行校验和
CHECKSUM_PARTIAL-由硬件来执行校验和
CHECKSUM_UNNECESSARY-没必要执行校验和
CHECKSUM_COMPLETE-已完成执行校验和
*/
__u8 ooo_okay:1;
__u8 l4_hash:1; // indicate hash is a canonical 4-tuple hash over transport port
__u8 sw_hash:1; // Driver fed us an IP checksum
__u8 wifi_acked_valid:1; //wifi_acked was set
__u8 wifi_acked:1; //whether frame was acked on wifi or not
__u8 no_fcs:1; //Request NIC to treat last 4 bytes as Ethernet FCS
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation:1;
__u8 encap_hdr_csum:1;
__u8 csum_valid:1;
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_VLAN_PRESENT_BIT 7
#else
#define PKT_VLAN_PRESENT_BIT 0
#endif
#define PKT_VLAN_PRESENT_OFFSET() offsetof(struct sk_buff, __pkt_vlan_present_offset)
__u8 __pkt_vlan_present_offset[0];
__u8 vlan_present:1;
__u8 csum_complete_sw:1;
__u8 csum_level:2;
__u8 csum_not_inet:1; //use CRC32c to resolve CHECKSUM_PARTIAL
__u8 dst_pending_confirm:1; //need to confirm neighbour
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2; //router type (from link layer)
#endif
__u8 ipvs_property:1; //skbuff is owned by ipvs
__u8 inner_protocol_type:1;
__u8 remcsum_offload:1;
#ifdef CONFIG_NET_SWITCHDEV
__u8 offload_fwd_mark:1;
__u8 offload_l3_fwd_mark:1;
#endif
#ifdef CONFIG_NET_CLS_ACT
__u8 tc_skip_classify:1; //do not classify packet. set by IFB device
__u8 tc_at_ingress:1; // used within tc_classify to distinguish in/egress
#endif
#ifdef CONFIG_NET_REDIRECT
__u8 redirected:1; //packet was redirected by a tc action
__u8 from_ingress:1; //if tc_redirected, tc_at_ingress at time of redirect
#endif
#ifdef CONFIG_TLS_DEVICE
__u8 decrypted:1;
#endif
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#endif
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
int skb_iif;
__u32 hash;
__be16 vlan_proto;
__u16 vlan_tci;
#if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS)
union { //校验和,必须包含csum_start(开始)和csum_offset(偏移)
unsigned int napi_id; //校验开始位置,相对于header
unsigned int sender_cpu; //校验和存储位置,相对于csum_start
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark; //security marking
#endif
union {
__u32 mark; //Generic packet mark, 4字节
__u32 reserved_tailroom;
};
union { // 封装的协议
__be16 inner_protocol;
__u8 inner_ipproto;
};
__u16 inner_transport_header; //封装的传输层头部相对于head的偏移
__u16 inner_network_header; // 封装的网络层头部相对于head的偏移
__u16 inner_mac_header; // 封装的链路层头部相对于head的偏移
__be16 protocol; //下一个较高层的协议,例如IP,IPv6,ARP.每种协议都有自己的函数处理例程用来处理输入的封包。驱动程序用这个字段通知上层该使用哪个处理例程。
/*不同之处在于inner_XXXX字段用于协议封装,例如XFRM加密/解密*/
__u16 transport_header; //传输层头部相对于head的偏移
__u16 network_header; //网络层头部相对于head的偏移
__u16 mac_header; //链路层头部相对于head的偏移
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail; //实际数据的尾部
sk_buff_data_t end; //缓冲区的尾部
unsigned char *head, //缓冲区的头部
*data; //实际数据的头部
unsigned int truesize; /*
缓冲区的总大小,包括skb本身和实际数据len大小,alloc_skb函数将
该字段设置为len+sizeof(sk_buff)
每当len值更新,该值也要对应更新
*/
refcount_t users; //引用计数,使用缓冲区实例的数目
#ifdef CONFIG_SKB_EXTENSIONS
/* only useable after checking ->active_extensions != 0 */
struct skb_ext *extensions;
#endif
};
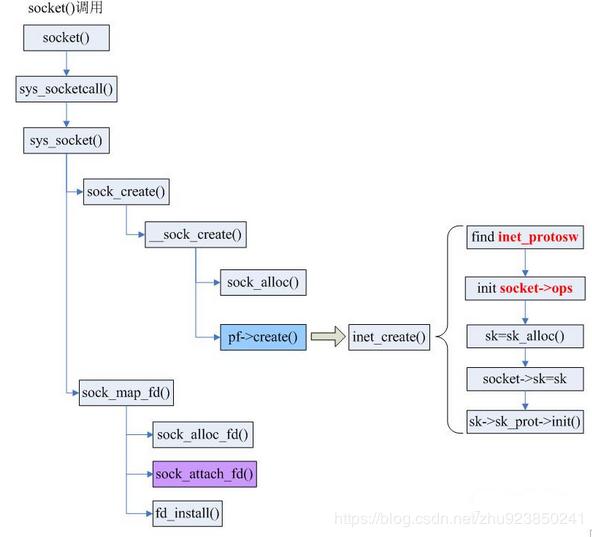
以下为socket创建过程调用链:
3. send函数执行过程分析
3.1 应用层流程
3.1.1 代码分析
/*
* Send a datagram down a socket.
*/
SYSCALL_DEFINE4(send, int, fd, void __user *, buff, size_t, len,
unsigned int, flags)
{
return __sys_sendto(fd, buff, len, flags, NULL, 0);
}
当socket创建好后,用户态调用send()函数进行数据发送时,发起系统调用,send()函数在内核的系统调用服务程序为__sys_sendto()函数。
/*以下为__sys_sendto()函数的实现*/
int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags,
struct sockaddr __user *addr, int addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
这里定义了一个struct msghdr msg,他是用来表示要发送的数据的一些属性。

还有一个struct iovec,他被称为io向量,用来表示io数据的一些信息。

所以,__sys_sendto函数其实做了3件事:
1.通过fd获取了对应的struct socket
2.创建了用来描述要发送的数据的结构体struct msghdr。
3.调用了sock_sendmsg来执行实际的发送。
/*sock_sendmsg实现*/
int sock_sendmsg(struct socket *sock, struct msghdr *msg)
{
int err = security_socket_sendmsg(sock, msg,
msg_data_left(msg));
return err ?: sock_sendmsg_nosec(sock, msg);
}
正常情况下,sock_sendmsg()会调用sock_sendmsg_nosec()来进行数据发送,而sock_sendmsg_nosec()会调用inet_sendmsg()函数。
/*inet_sendmsg实现*/
static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg)
{
int ret = INDIRECT_CALL_INET(sock->ops->sendmsg, inet6_sendmsg,
inet_sendmsg, sock, msg,
msg_data_left(msg));
BUG_ON(ret == -EIOCBQUEUED);
return ret;
}
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)
{
struct sock *sk = sock->sk;
if (unlikely(inet_send_prepare(sk)))
return -EAGAIN;
return INDIRECT_CALL_2(sk->sk_prot->sendmsg, tcp_sendmsg, udp_sendmsg,
sk, msg, size);
}
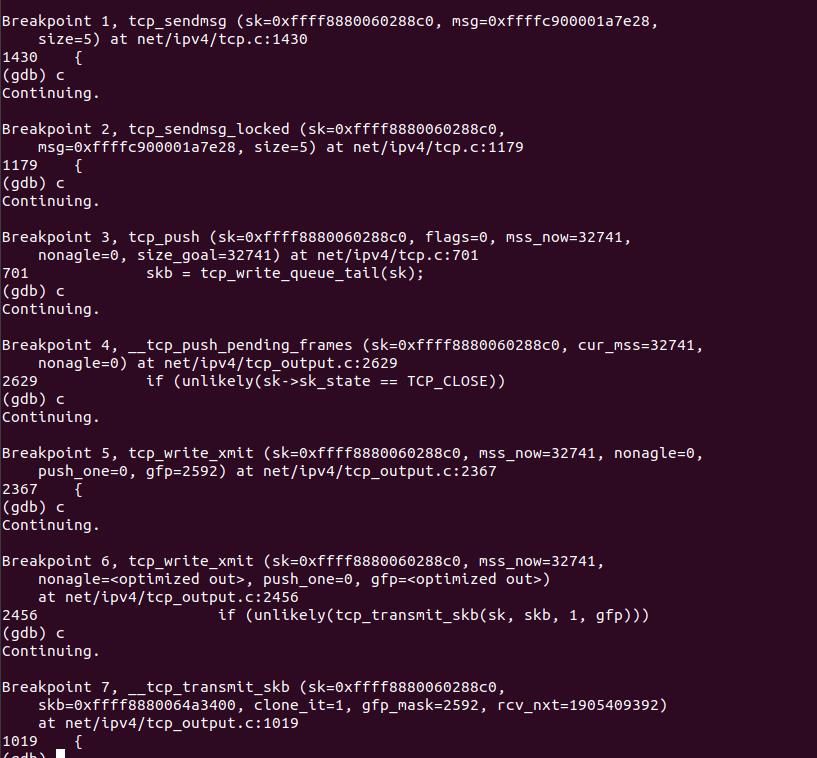
继续追踪这个函数,会看到最终调用的是tcp_sendmsg()函数,即传送到传输层。
3.1.2 gdb调试验证

3.2 传输层流程
3.2.1 代码分析
int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
{
int ret;
lock_sock(sk);
ret = tcp_sendmsg_locked(sk, msg, size);
release_sock(sk);
return ret;
}
可以看到tcp_sendmsg()中调用了tcp_sendmsg_locked()函数。
int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
{
struct tcp_sock *tp = tcp_sk(sk);
struct ubuf_info *uarg = NULL;
struct sk_buff *skb;
struct sockcm_cookie sockc;
int flags, err, copied = 0;
int mss_now = 0, size_goal, copied_syn = 0;
int process_backlog = 0;
bool zc = false;
long timeo;
flags = msg->msg_flags;
.......................
wait_for_memory:
if (copied)
tcp_push(sk, flags & ~MSG_MORE, mss_now,
TCP_NAGLE_PUSH, size_goal);
err = sk_stream_wait_memory(sk, &timeo);
在tcp_sendmsg_locked中,完成的是将所有的数据组织成发送队列,这个发送队列是struct sock结构中的一个域sk_write_queue,这个队列的每一个元素是一个skb,里面存放的就是待发送的数据。然后调用了tcp_push()函数。
struct sock{
...
struct sk_buff_head sk_write_queue;/*指向skb队列的第一个元素*/
...
struct sk_buff *sk_send_head;/*指向队列第一个还没有发送的元素*/
}
/*在tcp协议的头部有几个标志字段:URG、ACK、RSH、RST、SYN、FIN,tcp_push中会判断这个skb的元素是否需要push,如果需要就将tcp头部字段的push置一,置一的过程如下:*/
static void tcp_push(struct sock *sk, int flags, int mss_now,
int nonagle, int size_goal)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
skb = tcp_write_queue_tail(sk);
if (!skb)
return;
if (!(flags & MSG_MORE) || forced_push(tp))
tcp_mark_push(tp, skb);//对push进行标记
tcp_mark_urg(tp, flags);
if (tcp_should_autocork(sk, skb, size_goal)) {
/* avoid atomic op if TSQ_THROTTLED bit is already set */
if (!test_bit(TSQ_THROTTLED, &sk->sk_tsq_flags)) {
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPAUTOCORKING);
set_bit(TSQ_THROTTLED, &sk->sk_tsq_flags);
}
/* It is possible TX completion already happened
* before we set TSQ_THROTTLED.
*/
if (refcount_read(&sk->sk_wmem_alloc) > skb->truesize)
return;
}
if (flags & MSG_MORE)
nonagle = TCP_NAGLE_CORK;
__tcp_push_pending_frames(sk, mss_now, nonagle);
}
然后tcp_push调用了__tcp_push_pending_frames(sk, mss_now, nonagle)函数发送数据。
void __tcp_push_pending_frames(struct sock *sk, unsigned int cur_mss,
int nonagle)
{
/* If we are closed, the bytes will have to remain here.
* In time closedown will finish, we empty the write queue and
* all will be happy.
*/
if (unlikely(sk->sk_state == TCP_CLOSE))
return;
if (tcp_write_xmit(sk, cur_mss, nonagle, 0,
sk_gfp_mask(sk, GFP_ATOMIC)))
tcp_check_probe_timer(sk);
}
然后,__tcp_push_pending_frames(sk, mss_now, nonagle)中调用tcp_write_xmit()来发送数据。在发送数据包时,如果发送失败,会检查是否需要启动零窗口探测定时器,即tcp_check_probe_timer(sk)。
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
/*统计已发送的报文总数*/
sent_pkts = 0;
......
/*若发送队列未满,则准备发送报文*/
while ((skb = tcp_send_head(sk))) {
unsigned int limit;
if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
/* "skb_mstamp_ns" is used as a start point for the retransmit timer */
skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
tcp_init_tso_segs(skb, mss_now);
goto repair; /* Skip network transmission */
}
if (tcp_pacing_check(sk))
break;
tso_segs = tcp_init_tso_segs(skb, mss_now);
BUG_ON(!tso_segs);
/*检查发送窗口的大小*/
cwnd_quota = tcp_cwnd_test(tp, skb);
if (!cwnd_quota) {
if (push_one == 2)
/* Force out a loss probe pkt. */
cwnd_quota = 1;
else
break;
}
if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
is_rwnd_limited = true;
break;
......
limit = mss_now;
if (tso_segs > 1 && !tcp_urg_mode(tp))
limit = tcp_mss_split_point(sk, skb, mss_now,
min_t(unsigned int,
cwnd_quota,
max_segs),
nonagle);
if (skb->len > limit &&
unlikely(tso_fragment(sk, TCP_FRAG_IN_WRITE_QUEUE,
skb, limit, mss_now, gfp)))
break;
if (tcp_small_queue_check(sk, skb, 0))
break;
if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
break;
......
tcp_write_xmit()位于net/ipv4/tcp_output.c中,它实现了tcp的拥塞控制,然后调用了tcp_transmit_skb(sk, skb, 1, gfp)传输数据,实际上调用的是__tcp_transmit_skb()。
static int __tcp_transmit_skb(struct sock *sk, struct sk_buff *skb,
int clone_it, gfp_t gfp_mask, u32 rcv_nxt)
{
skb_push(skb, tcp_header_size);
skb_reset_transport_header(skb);
......
/* 构建TCP头部和校验和 */
th = (struct tcphdr *)skb->data;
th->source = inet->inet_sport;
th->dest = inet->inet_dport;
th->seq = htonl(tcb->seq);
th->ack_seq = htonl(rcv_nxt);
tcp_options_write((__be32 *)(th + 1), tp, &opts);
skb_shinfo(skb)->gso_type = sk->sk_gso_type;
if (likely(!(tcb->tcp_flags & TCPHDR_SYN))) {
th->window = htons(tcp_select_window(sk));
tcp_ecn_send(sk, skb, th, tcp_header_size);
} else {
/* RFC1323: The window in SYN & SYN/ACK segments
* is never scaled.
*/
th->window = htons(min(tp->rcv_wnd, 65535U));
}
......
icsk->icsk_af_ops->send_check(sk, skb);
if (likely(tcb->tcp_flags & TCPHDR_ACK))
tcp_event_ack_sent(sk, tcp_skb_pcount(skb), rcv_nxt);
if (skb->len != tcp_header_size) {
tcp_event_data_sent(tp, sk);
tp->data_segs_out += tcp_skb_pcount(skb);
tp->bytes_sent += skb->len - tcp_header_size;
}
if (after(tcb->end_seq, tp->snd_nxt) || tcb->seq == tcb->end_seq)
TCP_ADD_STATS(sock_net(sk), TCP_MIB_OUTSEGS,
tcp_skb_pcount(skb));
tp->segs_out += tcp_skb_pcount(skb);
/* OK, its time to fill skb_shinfo(skb)->gso_{segs|size} */
skb_shinfo(skb)->gso_segs = tcp_skb_pcount(skb);
skb_shinfo(skb)->gso_size = tcp_skb_mss(skb);
/* Leave earliest departure time in skb->tstamp (skb->skb_mstamp_ns) */
/* Cleanup our debris for IP stacks */
memset(skb->cb, 0, max(sizeof(struct inet_skb_parm),
sizeof(struct inet6_skb_parm)));
err = icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);
......
}
tcp_transmit_skb是tcp发送数据位于传输层的最后一步,这里首先对TCP数据段的头部进行了处理,然后调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送,自此,数据离开了传输层,传输层的任务也就结束了。
3.2.2 gdb调试验证
3.3 网络层流程
3.3.1 代码分析
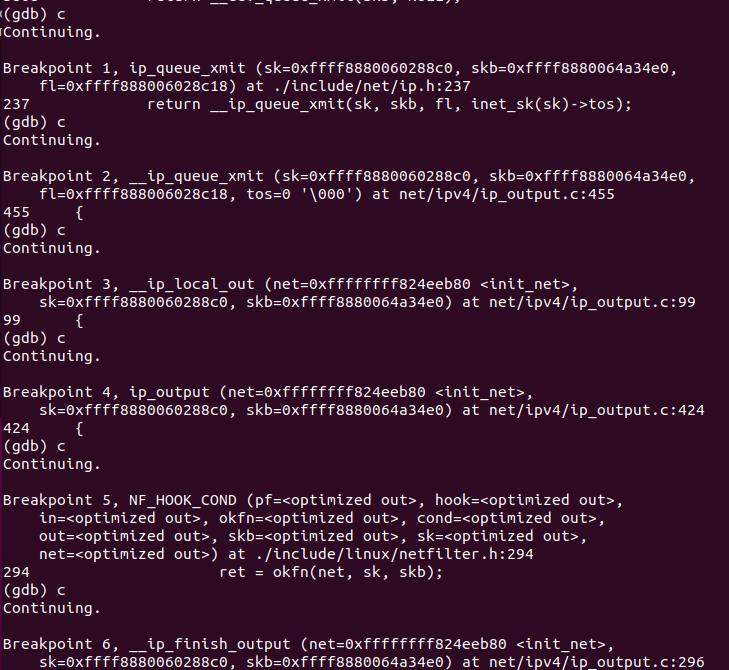
通过传输层的分析,我们得知tcp_transmit_skb调用了网络层提供的发送接口icsk->icsk_af_ops->queue_xmit(sk, skb, &inet->cork.fl);实现了数据的发送。
ip_queue_xmit是ip层提供给tcp层发送回调,大多数tcp发送都会使用这个回调,tcp层使用tcp_transmit_skb封装了tcp头之后,调用该函数。
static inline int ip_queue_xmit(struct sock *sk, struct sk_buff *skb,
struct flowi *fl)
{
return __ip_queue_xmit(sk, skb, fl, inet_sk(sk)->tos);
}
可以看到实际调用了__ip_queue_xmit
/* Note: skb->sk can be different from sk, in case of tunnels */
int ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl)
{
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
struct ip_options_rcu *inet_opt;
struct flowi4 *fl4;
struct rtable *rt;
struct iphdr *iph;
int res;
/* Skip all of this if the packet is already routed,
* f.e. by something like SCTP.
*/
rcu_read_lock();
inet_opt = rcu_dereference(inet->inet_opt);
fl4 = &fl->u.ip4;
/* 获取skb中的路由缓存 */
rt = skb_rtable(skb);
/* skb中有缓存则跳转处理 */
if (rt)
goto packet_routed;
/* Make sure we can route this packet. */
/* 检查控制块中的路由缓存 */
rt = (struct rtable *)__sk_dst_check(sk, 0);
/* 缓存过期 */
if (!rt) {
__be32 daddr;
/* Use correct destination address if we have options. */
/* 目的地址 */
daddr = inet->inet_daddr;
/* 严格路由选项 */
if (inet_opt && inet_opt->opt.srr)
daddr = inet_opt->opt.faddr;
/* If this fails, retransmit mechanism of transport layer will
* keep trying until route appears or the connection times
* itself out.
*/
/* 查找路由缓存 */
rt = ip_route_output_ports(net, fl4, sk,
daddr, inet->inet_saddr,
inet->inet_dport,
inet->inet_sport,
sk->sk_protocol,
RT_CONN_FLAGS(sk),
sk->sk_bound_dev_if);
/* 失败 */
if (IS_ERR(rt))
goto no_route;
/* 设置控制块的路由缓存 */
sk_setup_caps(sk, &rt->dst);
}
/* 将路由设置到skb中 */
skb_dst_set_noref(skb, &rt->dst);
packet_routed:
/* 严格路由选项 &&使用网关,无路由 */
if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway)
goto no_route;
/* OK, we know where to send it, allocate and build IP header. */
/* 加入ip头 */
skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0));
skb_reset_network_header(skb);
/* 构造ip头 */
iph = ip_hdr(skb);
*((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (inet->tos & 0xff));
if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df)
iph->frag_off = htons(IP_DF);
else
iph->frag_off = 0;
iph->ttl = ip_select_ttl(inet, &rt->dst);
iph->protocol = sk->sk_protocol;
ip_copy_addrs(iph, fl4);
/* Transport layer set skb->h.foo itself. */
/* 构造ip选项 */
if (inet_opt && inet_opt->opt.optlen) {
iph->ihl += inet_opt->opt.optlen >> 2;
ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0);
}
/* 设置id */
ip_select_ident_segs(net, skb, sk,
skb_shinfo(skb)->gso_segs ?: 1);
/* TODO : should we use skb->sk here instead of sk ? */
/* QOS等级 */
skb->priority = sk->sk_priority;
skb->mark = sk->sk_mark;
/* 输出 */
res = ip_local_out(net, sk, skb);
rcu_read_unlock();
return res;
no_route:
/* 无路由处理 */
rcu_read_unlock();
IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES);
kfree_skb(skb);
return -EHOSTUNREACH;
}
函数__ip_queue_xmit()提供了路由查找校验、封装ip头和ip选项的功能,封装完成之后调用ip_local_out发送数据包。
实际调用的是__ip_local_out()函数。
int __ip_local_out(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct iphdr *iph = ip_hdr(skb);
/* 设置总长度 */
iph->tot_len = htons(skb->len);
/* 计算校验和 */
ip_send_check(iph);
/* if egress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_out(sk, skb);
if (unlikely(!skb))
return 0;
/* 设置ip协议 */
skb->protocol = htons(ETH_P_IP);
/* 经过NF的LOCAL_OUT钩子点 */
return nf_hook(NFPROTO_IPV4, NF_INET_LOCAL_OUT,
net, sk, skb, NULL, skb_dst(skb)->dev,
dst_output);
}
该函数设置数据包的总长度和校验和,然后经过netfilter的LOCAL_OUT钩子点进行检查过滤,如果通过,则调用dst_output函数,实际上调用的是ip数据包输出函数ip_output。
int ip_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb_dst(skb)->dev;
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUT, skb->len);
/* 设置输出设备和协议 */
skb->dev = dev;
skb->protocol = htons(ETH_P_IP);
/* 经过NF的POST_ROUTING钩子点 */
return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING,
net, sk, skb, NULL, dev,
ip_finish_output,
!(IPCB(skb)->flags & IPSKB_REROUTED));
}
ip_output-设置输出设备和协议,然后经过POST_ROUTING钩子点,最后调用ip_finish_output,
实际调用的是__ip_finish_output()函数。
static int __ip_finish_output(struct net *net, struct sock *sk, struct sk_buff *skb)
{
unsigned int mtu;
#if defined(CONFIG_NETFILTER) && defined(CONFIG_XFRM)
/* Policy lookup after SNAT yielded a new policy */
if (skb_dst(skb)->xfrm) {
IPCB(skb)->flags |= IPSKB_REROUTED;
return dst_output(net, sk, skb);
}
#endif
/* 获取mtu */
mtu = ip_skb_dst_mtu(sk, skb);
/* 是gso,则调用gso输出 */
if (skb_is_gso(skb))
return ip_finish_output_gso(net, sk, skb, mtu);
/* 长度>mtu或者设置了IPSKB_FRAG_PMTU标记,则分片 */
if (skb->len > mtu || (IPCB(skb)->flags & IPSKB_FRAG_PMTU))
return ip_fragment(net, sk, skb, mtu, ip_finish_output2);
return ip_finish_output2(net, sk, skb);
}
__ip_finish_output()函数对skb进行分片判断,需要分片,则分片后输出,不需要分片则直接输出,调用ip_finish_output2()。
static int ip_finish_output2(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct dst_entry *dst = skb_dst(skb);
struct rtable *rt = (struct rtable *)dst;
struct net_device *dev = dst->dev;
unsigned int hh_len = LL_RESERVED_SPACE(dev);
struct neighbour *neigh;
bool is_v6gw = false;
if (rt->rt_type == RTN_MULTICAST) {
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST)
IP_UPD_PO_STATS(net, IPSTATS_MIB_OUTBCAST, skb->len);
/* Be paranoid, rather than too clever. */
/* skb头部空间不能存储链路头 */
if (unlikely(skb_headroom(skb) < hh_len && dev->header_ops)) {
struct sk_buff *skb2;
/* 重新分配skb */
skb2 = skb_realloc_headroom(skb, LL_RESERVED_SPACE(dev));
if (!skb2) {
kfree_skb(skb);
return -ENOMEM;
}
/* 关联控制块 */
if (skb->sk)
skb_set_owner_w(skb2, skb->sk);
consume_skb(skb);
skb = skb2;/* 指向新的skb */
}
if (lwtunnel_xmit_redirect(dst->lwtstate)) {
int res = lwtunnel_xmit(skb);
if (res < 0 || res == LWTUNNEL_XMIT_DONE)
return res;
}
rcu_read_lock_bh();
/*通过下一跳地址寻找邻居子系统,arp协议执行开始处,之后会调用ip_neigh_gw4()函数*/
neigh = ip_neigh_for_gw(rt, skb, &is_v6gw);
if (!IS_ERR(neigh)) {
int res;
sock_confirm_neigh(skb, neigh);
/* if crossing protocols, can not use the cached header */
res = neigh_output(neigh, skb, is_v6gw);
rcu_read_unlock_bh();
return res;
}
rcu_read_unlock_bh();
net_dbg_ratelimited("%s: No header cache and no neighbour!\n",
__func__);
kfree_skb(skb);
return -EINVAL;
}
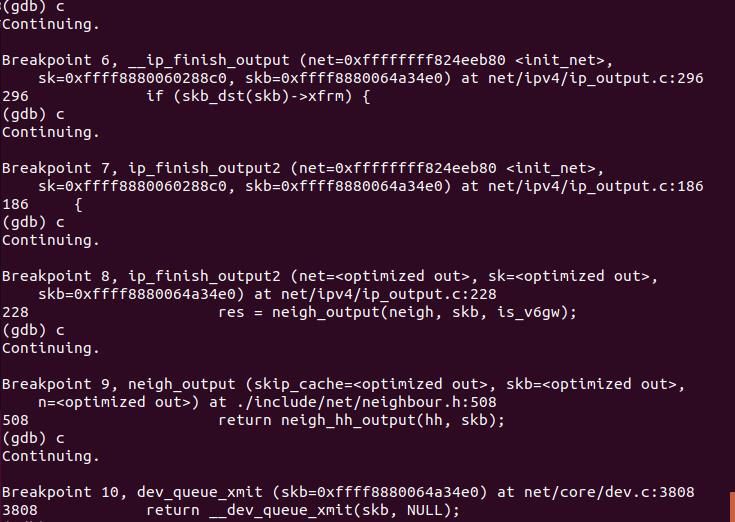
ip_finish_output2-对skb的头部空间进行检查,看是否能够容纳下二层头部,若空间不足,则需要重新申请skb;然后,获取邻居子系统,并通过邻居子系统neigh_output(neigh, skb)输出。
static inline int neigh_output(struct neighbour *n, struct sk_buff *skb)
{
const struct hh_cache *hh = &n->hh;
/* 连接状态 &&缓存的头部存在,使用缓存输出 */
if ((n->nud_state & NUD_CONNECTED) && hh->hh_len)
return neigh_hh_output(hh, skb);
/* 使用邻居项的输出回调函数输出,在连接或者非连接状态下有不同的输出函数 */
else
return n->output(n, skb);
}
输出分为有二层头有缓存和没有两种情况,有缓存时调用neigh_hh_output进行快速输出,没有缓存时,则调用邻居子系统的输出回调函数进行慢速输出;
static inline int neigh_hh_output(const struct hh_cache *hh, struct sk_buff *skb)
{
unsigned int hh_alen = 0;
unsigned int seq;
unsigned int hh_len;
/* 拷贝二层头到skb */
do {
seq = read_seqbegin(&hh->hh_lock);
hh_len = READ_ONCE(hh->hh_len);
/* 二层头部<DATA_MOD,直接使用该长度拷贝 */
if (likely(hh_len <= HH_DATA_MOD)) {
hh_alen = HH_DATA_MOD;
/* skb_push() would proceed silently if we have room for
* the unaligned size but not for the aligned size:
* check headroom explicitly.
*/
if (likely(skb_headroom(skb) >= HH_DATA_MOD)) {
/* this is inlined by gcc */
memcpy(skb->data - HH_DATA_MOD, hh->hh_data,
HH_DATA_MOD);
}
} else {
/* >=DATA_MOD,对齐头部,拷贝 */
hh_alen = HH_DATA_ALIGN(hh_len);
if (likely(skb_headroom(skb) >= hh_alen)) {
memcpy(skb->data - hh_alen, hh->hh_data,
hh_alen);
}
}
} while (read_seqretry(&hh->hh_lock, seq));
if (WARN_ON_ONCE(skb_headroom(skb) < hh_alen)) {
kfree_skb(skb);
return NET_XMIT_DROP;
}
__skb_push(skb, hh_len);
/* 发送 */
return dev_queue_xmit(skb);
}
最后通过dev_queue_xmit()向链路层发送数据包。
3.3.2 gdb调试验证
3.4 数据链路层和物理层流程
3.4.1 代码分析
int dev_queue_xmit(struct sk_buff *skb)
{
return __dev_queue_xmit(skb, NULL);
}
实际调用的是__dev_queue_xmit(),传入的参数是一个skb 数据包。
static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
struct Qdisc *q;
int rc = -ENOMEM;
bool again = false;
skb_reset_mac_header(skb);
if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP))
__skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED);
/* Disable soft irqs for various locks below. Also
* stops preemption for RCU.
*/
rcu_read_lock_bh();
skb_update_prio(skb);
qdisc_pkt_len_init(skb);
#ifdef CONFIG_NET_CLS_ACT
skb->tc_at_ingress = 0;
# ifdef CONFIG_NET_EGRESS
if (static_branch_unlikely(&egress_needed_key)) {
skb = sch_handle_egress(skb, &rc, dev);
if (!skb)
goto out;
}
# endif
#endif
/* If device/qdisc don't need skb->dst, release it right now while
* its hot in this cpu cache.
*/
/*这个地方看netdevcie的flag是否要去掉skb DST相关的信息,一般情况下这个flag是默认被设置的
*在alloc_netdev_mqs的时候,已经默认给设置了,其实个人认为这个路由信息也没有太大作用了...
*dev->priv_flags = IFF_XMIT_DST_RELEASE | IFF_XMIT_DST_RELEASE_PERM;
*/
if (dev->priv_flags & IFF_XMIT_DST_RELEASE)
skb_dst_drop(skb);
else
skb_dst_force(skb);
/*此处主要是取出此netdevice的txq和txq的Qdisc,Qdisc主要用于进行拥塞处理,一般的情况下,直接将
*数据包发送给driver了,如果遇到Busy的状况,就需要进行拥塞处理了,就会用到Qdisc*/
txq = netdev_core_pick_tx(dev, skb, sb_dev);
q = rcu_dereference_bh(txq->qdisc);
trace_net_dev_queue(skb);
/*如果Qdisc有对应的enqueue规则,就会调用__dev_xmit_skb,进入带有拥塞的控制的Flow,注意这个地 方,虽然是走拥塞控制的Flow但是并不一定非得进行enqueue操作啦,只有Busy的状况下,才会走Qdisc的 enqueue/dequeue操作进行 */
if (q->enqueue) {
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
/*此处是设备没有Qdisc的,实际上没有enqueue/dequeue的规则,无法进行拥塞控制的操作,
*对于一些loopback/tunnel interface比较常见,判断下设备是否处于UP状态*/
if (dev->flags & IFF_UP) {
int cpu = smp_processor_id(); /* ok because BHs are off */
if (txq->xmit_lock_owner != cpu) {
if (dev_xmit_recursion())
goto recursion_alert;
skb = validate_xmit_skb(skb, dev, &again);
if (!skb)
goto out;
HARD_TX_LOCK(dev, txq, cpu);
/*这个地方判断一下txq不是stop状态,那么就直接调用dev_hard_start_xmit函数来发送数据*/
if (!netif_xmit_stopped(txq)) {
dev_xmit_recursion_inc();
skb = dev_hard_start_xmit(skb, dev, txq, &rc);
dev_xmit_recursion_dec();
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
HARD_TX_UNLOCK(dev, txq);
net_crit_ratelimited("Virtual device %s asks to queue packet!\n",
dev->name);
} else {
/* Recursion is detected! It is possible,
* unfortunately
*/
recursion_alert:
net_crit_ratelimited("Dead loop on virtual device %s, fix it urgently!\n",
dev->name);
}
}
rc = -ENETDOWN;
rcu_read_unlock_bh();
atomic_long_inc(&dev->tx_dropped);
kfree_skb_list(skb);
return rc;
out:
rcu_read_unlock_bh();
return rc;
}
从对_dev_queue_xmit函数的分析来看,发送报文有2中情况:
1.有拥塞控制策略的情况,比较复杂,但是目前最常用;
2.没有enqueue的状况,比较简单,直接发送到driver,如loopback等使用。
先检查是否有enqueue的规则,如果有即调用__dev_xmit_skb进入拥塞控制的flow,如果没有且txq处于On的状态,那么就调用dev_hard_start_xmit直接发送到driver。
struct sk_buff *dev_hard_start_xmit(struct sk_buff *first, struct net_device *dev,
struct netdev_queue *txq, int *ret)
{
struct sk_buff *skb = first;
int rc = NETDEV_TX_OK;
while (skb) {
struct sk_buff *next = skb->next; /*取出skb的下一个数据单元*/
skb_mark_not_on_list(skb);
/*将此数据包送到driver Tx函数,因为dequeue的数据也会从这里发送,所以会有next*/
rc = xmit_one(skb, dev, txq, next != NULL);
/*如果发送不成功,next还原到skb->next 退出*/
if (unlikely(!dev_xmit_complete(rc))) {
skb->next = next;
goto out;
}
/*如果发送成功,把next置给skb,一般的next为空 这样就返回,如果不为空就继续发!*/
skb = next;
/*如果txq被stop,并且skb需要发送,就产生TX Busy的问题!*/
if (netif_tx_queue_stopped(txq) && skb) {
rc = NETDEV_TX_BUSY;
break;
}
}
out:
*ret = rc;
return skb;
}
可以看到在dev_hard_start_xmit()中,调用xmit_one()来发送一个到多个数据包。
static int xmit_one(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq, bool more)
{
unsigned int len;
int rc;
if (dev_nit_active(dev))
dev_queue_xmit_nit(skb, dev);
len = skb->len;
trace_net_dev_start_xmit(skb, dev);
/*调用netdev_start_xmit,快到driver的tx函数了*/
rc = netdev_start_xmit(skb, dev, txq, more);
trace_net_dev_xmit(skb, rc, dev, len);
return rc;
}
xmit_one()会调用 netdev_start_xmit(),实际调用的是__netdev_start_xmit()函数,其目的就是将封包送到driver的tx函数。
3.4.2 gdb调试验证
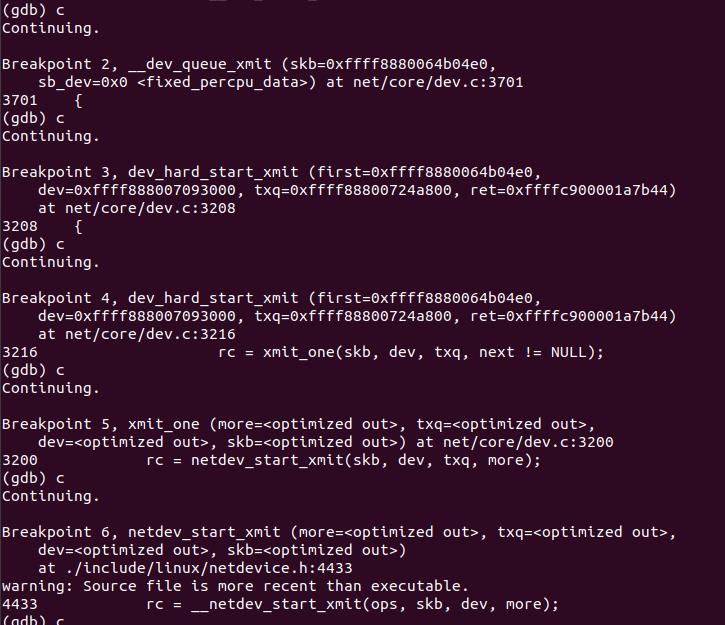
3.4.3 物理层中断处理过程分析
static inline netdev_tx_t __netdev_start_xmit(const struct net_device_ops *ops,
struct sk_buff *skb, struct net_device *dev,
bool more)
{
__this_cpu_write(softnet_data.xmit.more, more);
return ops->ndo_start_xmit(skb, dev);
}
netdev_start_xmit()会调用__netdev_start_xmit(),后者会调用ndo_start_xmit(),ndo_start_xmit()绑定到具体网卡驱动的相应函数,到这步之后,就归网卡驱动管了,不同的网卡驱动有不同的处理方式,这里不做详细介绍,其大概流程如下:
- 将skb放入网卡自己的发送队列
- 通知网卡发送数据包
- 网卡发送完成后发送中断给CPU
- 收到中断后进行skb的清理工作
在网卡驱动发送数据包过程中,会有一些地方需要和netdevice子系统打交道,比如网卡的队列满了,需要告诉上层不要再发了,等队列有空闲的时候,再通知上层接着发数据。
4.recv函数执行过程分析
4.1 应用层流程
4.1.1 代码分析
/*
* Receive a datagram from a socket.
*/
SYSCALL_DEFINE4(recv, int, fd, void __user *, ubuf, size_t, size,
unsigned int, flags)
{
return __sys_recvfrom(fd, ubuf, size, flags, NULL, NULL);
}
用户态调用的recv()函数,与前面所述的send()函数类似,真正执行的系统调用的服务程序为__sys_recvfrom()函数。
/*以下为__sys_recvfrom代码实现*/
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags,
struct sockaddr __user *addr, int __user *addr_len)
{
struct socket *sock;
struct iovec iov;
struct msghdr msg;
struct sockaddr_storage address;
int err, err2;
int fput_needed;
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_control = NULL;
msg.msg_controllen = 0;
/* Save some cycles and don't copy the address if not needed */
msg.msg_name = addr ? (struct sockaddr *)&address : NULL;
/* We assume all kernel code knows the size of sockaddr_storage */
msg.msg_namelen = 0;
msg.msg_iocb = NULL;
msg.msg_flags = 0;
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address,
msg.msg_namelen, addr, addr_len);
if (err2 < 0)
err = err2;
}
fput_light(sock->file, fput_needed);
out:
return err;
}
可以看出__sys_recvfrom()调用了sock_recvmsg()来进行数据接收。
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags)
{
int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags);
return err ?: sock_recvmsg_nosec(sock, msg, flags);
}
而sock_recvmsg()中调用了sock_recvmsg_nosec()。
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg,
int flags)
{
return INDIRECT_CALL_INET(sock->ops->recvmsg, inet6_recvmsg,
inet_recvmsg, sock, msg, msg_data_left(msg),
flags);
}
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size,
int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
if (likely(!(flags & MSG_ERRQUEUE)))
sock_rps_record_flow(sk);
err = INDIRECT_CALL_2(sk->sk_prot->recvmsg, tcp_recvmsg, udp_recvmsg,
sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
之后被调用的是inet_recvmsg(),最终被调用的函数是tcp_recvmsg()。
4.1.2 gdb调试验证

4.2 传输层流程
4.2.1 代码分析
函数tcp_recvmsg()完成从接收队列中读取数据复制到用户空间的任务;函数在执行过程中会锁定控制块,避免软中断在tcp层的影响;函数会涉及从接收队列receive_queue,预处理队列prequeue和后备队列backlog中读取数据;其中从prequeue和backlog中读取的数据,还需要经过sk_backlog_rcv回调,该回调的实现为tcp_v4_do_rcv,实际上是先缓存到队列中,然后需要读取的时候,才进入协议栈处理,此时,是在进程上下文执行的,因为会设置tp->ucopy.task=current,在协议栈处理过程中,会直接将数据复制到用户空间。
int tcp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, int nonblock,
int flags, int *addr_len)
{
......
if (sk_can_busy_loop(sk) && skb_queue_empty(&sk->sk_receive_queue) &&
(sk->sk_state == TCP_ESTABLISHED))
sk_busy_loop(sk, nonblock);
lock_sock(sk);
.....
if (unlikely(tp->repair)) {
err = -EPERM;
if (!(flags & MSG_PEEK))
goto out;
if (tp->repair_queue == TCP_SEND_QUEUE)
goto recv_sndq;
err = -EINVAL;
if (tp->repair_queue == TCP_NO_QUEUE)
goto out;
......
last = skb_peek_tail(&sk->sk_receive_queue);
skb_queue_walk(&sk->sk_receive_queue, skb) {
last = skb;
......
这里共维护了三个队列:prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,直到接收队列不为空。
/* 读取数据 */
if (!(flags & MSG_TRUNC)) {
err = skb_copy_datagram_msg(skb, offset, msg, used);
if (err) {
/* Exception. Bailout! */
if (!copied)
copied = -EFAULT;
break;
}
}
之后调用函数数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter,这里同样用了struct msghdr *msg来实现。
static int __skb_datagram_iter(const struct sk_buff *skb, int offset,
struct iov_iter *to, int len, bool fault_short,
size_t (*cb)(const void *, size_t, void *,
struct iov_iter *), void *data)
{
int start = skb_headlen(skb);
int i, copy = start - offset, start_off = offset, n;
struct sk_buff *frag_iter;
/* 拷贝tcp头部 */
if (copy > 0) {
if (copy > len)
copy = len;
n = cb(skb->data + offset, copy, data, to);
offset += n;
if (n != copy)
goto short_copy;
if ((len -= copy) == 0)
return 0;
}
/* 拷贝数据部分 */
for (i = 0; i < skb_shinfo(skb)->nr_frags; i++) {
int end;
const skb_frag_t *frag = &skb_shinfo(skb)->frags[i];
WARN_ON(start > offset + len);
end = start + skb_frag_size(frag);
if ((copy = end - offset) > 0) {
struct page *page = skb_frag_page(frag);
u8 *vaddr = kmap(page);
if (copy > len)
copy = len;
n = cb(vaddr + skb_frag_off(frag) + offset - start,
copy, data, to);
kunmap(page);
offset += n;
if (n != copy)
goto short_copy;
if (!(len -= copy))
return 0;
}
start = end;
}
skb_walk_frags(skb, frag_iter) {
int end;
WARN_ON(start > offset + len);
end = start + frag_iter->len;
if ((copy = end - offset) > 0) {
if (copy > len)
copy = len;
if (__skb_datagram_iter(frag_iter, offset - start,
to, copy, fault_short, cb, data))
goto fault;
if ((len -= copy) == 0)
return 0;
offset += copy;
}
start = end;
}
if (!len)
return 0;
/* This is not really a user copy fault, but rather someone
* gave us a bogus length on the skb. We should probably
* print a warning here as it may indicate a kernel bug.
*/
fault:
iov_iter_revert(to, offset - start_off);
return -EFAULT;
short_copy:
if (fault_short || iov_iter_count(to))
goto fault;
return 0;
}
当完成数据拷贝后,进行判断和进一步处理。
/* 已经读取了数据 */
if (copied) {
/* 有错误或者关闭或者有信号,跳出 */
if (sk->sk_err ||
sk->sk_state == TCP_CLOSE ||
(sk->sk_shutdown & RCV_SHUTDOWN) ||
!timeo ||
signal_pending(current))
break;
} else {
/* 会话终结*/
if (sock_flag(sk, SOCK_DONE))
break;
/* 有错误 */
if (sk->sk_err) {
copied = sock_error(sk);
break;
}
/* 关闭接收端 */
if (sk->sk_shutdown & RCV_SHUTDOWN)
break;
/* 连接关闭 */
if (sk->sk_state == TCP_CLOSE) {
/* 不在done状态,可能再读一个连接未建立起来的连接 */
if (!sock_flag(sk, SOCK_DONE)) {
/* This occurs when user tries to read
* from never connected socket.
*/
copied = -ENOTCONN;
break;
}
break;
}
/* 不阻塞等待 */
if (!timeo) {
copied = -EAGAIN;
break;
}
/* 有信号待处理 */
if (signal_pending(current)) {
copied = sock_intr_errno(timeo);
break;
}
}
if (copied >= target) {
/* Do not sleep, just process backlog. */
release_sock(sk);
lock_sock(sk);
} else {
sk_wait_data(sk, &timeo, last);
}
如果目标数据读取完,则处理后备队列。但是如果没有设置nonblock,同时也没有出现copied >= target的情况,也就是没有读到足够多的数据,则调用sk_wait_data将当前进程等待。也就是我们希望的阻塞方式。阻塞函数sk_wait_data所做的事情就是让出CPU,等数据来了或者设定超时之后再恢复运行。
以上我们分析的是tcp_recvmsg如何从队列中进行数据读取,接下来我们分析从IP层如何把接收到的数据放入相应队列中。
tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数;其协议操作函数结构如下所示,其中handler即为IP层向TCP传递数据包的回调函数,设置为tcp_v4_rcv。
1 static struct net_protocol tcp_protocol = {
2 .early_demux = tcp_v4_early_demux,
3 .early_demux_handler = tcp_v4_early_demux,
4 .handler = tcp_v4_rcv,
5 .err_handler = tcp_v4_err,
6 .no_policy = 1,
7 .netns_ok = 1,
8 .icmp_strict_tag_validation = 1,
9 };
而tcp_v4_rcv()函数是在IP层接收到数据后,将其回调,把数据存入相应队列。
首先调用的函数是ip_local_deliver(),
/*
* Deliver IP Packets to the higher protocol layers.
*/
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
struct net *net = dev_net(skb->dev);
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN,
net, NULL, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
之后ip_local_deliver()调用ip_local_deliver_finish(),
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
__skb_pull(skb, skb_network_header_len(skb));
rcu_read_lock();
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol);
rcu_read_unlock();
return 0;
}
ip_local_deliver_finish()调用ip_protocol_deliver_rcu(),其中就使用了回调函数tcp_v4_rcv()。
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
.........................
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv,
skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}
........................
以下为tcp_v4_rcv()的代码实现:
int tcp_v4_rcv(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
struct sk_buff *skb_to_free;
int sdif = inet_sdif(skb);
const struct iphdr *iph;
const struct tcphdr *th;
bool refcounted;
struct sock *sk;
int ret;
.....................
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
......................
}
tcp_v4_rcv()函数只要做以下几个工作:(1) 设置TCP_CB (2) 查找控制块 (3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理 (4) 接收TCP段;
tcp_v4_rcv判断状态为listen时会直接调用tcp_v4_do_rcv;如果是其他状态,将TCP包投递到目的套接字进行接收处理。如果套接字未被上锁则调用tcp_v4_do_rcv。当套接字正被用户锁定,TCP包将暂时排入该套接字的后备队列(sk_add_backlog)。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
struct dst_entry *dst = sk->sk_rx_dst;
sock_rps_save_rxhash(sk, skb);
sk_mark_napi_id(sk, skb);
if (dst) {
if (inet_sk(sk)->rx_dst_ifindex != skb->skb_iif ||
!dst->ops->check(dst, 0)) {
dst_release(dst);
sk->sk_rx_dst = NULL;
}
}
tcp_rcv_established(sk, skb);
return 0;
}
tcp_v4_do_ecv()检查状态如果是established,就调用tcp_rcv_established函数。
void tcp_rcv_established(struct sock *sk, struct sk_buff *skb)
{
const struct tcphdr *th = (const struct tcphdr *)skb->data;
struct tcp_sock *tp = tcp_sk(sk);
unsigned int len = skb->len;
/* TCP congestion window tracking */
trace_tcp_probe(sk, skb);
tcp_mstamp_refresh(tp);
............
/* Check timestamp */
if (tcp_header_len == sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) {
/* No? Slow path! */
if (!tcp_parse_aligned_timestamp(tp, th))
goto slow_path;
/* If PAWS failed, check it more carefully in slow path */
if ((s32)(tp->rx_opt.rcv_tsval - tp->rx_opt.ts_recent) < 0)
goto slow_path;
............
tcp_rcv_established()用于处理已连接状态下的输入,处理过程根据首部预测字段分为快速路径和慢速路径。
if (len <= tcp_header_len) {
/* Bulk data transfer: sender */
if (len == tcp_header_len) {
/* Predicted packet is in window by definition.
* seq == rcv_nxt and rcv_wup <= rcv_nxt.
* Hence, check seq<=rcv_wup reduces to:
*/
if (tcp_header_len ==
(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&
tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
/* We know that such packets are checksummed
* on entry.
*/
tcp_ack(sk, skb, 0);
__kfree_skb(skb);
tcp_data_snd_check(sk);
/* When receiving pure ack in fast path, update
* last ts ecr directly instead of calling
* tcp_rcv_rtt_measure_ts()
*/
tp->rcv_rtt_last_tsecr = tp->rx_opt.rcv_tsecr;
return;
} else { /* Header too small */
TCP_INC_STATS(sock_net(sk), TCP_MIB_INERRS);
goto discard;
}
} else {
int eaten = 0;
bool fragstolen = false;
if (tcp_checksum_complete(skb))
goto csum_error;
if ((int)skb->truesize > sk->sk_forward_alloc)
goto step5;
/* Predicted packet is in window by definition.
* seq == rcv_nxt and rcv_wup <= rcv_nxt.
* Hence, check seq<=rcv_wup reduces to:
*/
if (tcp_header_len ==
(sizeof(struct tcphdr) + TCPOLEN_TSTAMP_ALIGNED) &&
tp->rcv_nxt == tp->rcv_wup)
tcp_store_ts_recent(tp);
tcp_rcv_rtt_measure_ts(sk, skb);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPHPHITS);
/* Bulk data transfer: receiver */
__skb_pull(skb, tcp_header_len);
eaten = tcp_queue_rcv(sk, skb, &fragstolen);
tcp_event_data_recv(sk, skb);
if (TCP_SKB_CB(skb)->ack_seq != tp->snd_una) {
/* Well, only one small jumplet in fast path... */
tcp_ack(sk, skb, FLAG_DATA);
tcp_data_snd_check(sk);
if (!inet_csk_ack_scheduled(sk))
goto no_ack;
}
- 在快路中,对是有有数据负荷进行不同处理:
(1) 若无数据,则处理输入ack,释放该skb,检查是否有数据发送,有则发送;
(2) 若有数据,检查是否当前处理进程上下文,并且是期望读取的数据,若是则将数据复制到用户空间,若不满足直接复制到用户空间的情况,或者复制失败,则需要将数据段加入到接收队列中,加入方式包括合并到已有数据段,或者加入队列尾部,并唤醒用户进程通知有数据可读;
- 在慢路中,会进行更详细的校验,然后处理ack,处理紧急数据,接收数据段,其中数据段可能包含乱序的情况,最后进行是否有数据和ack的发送检查;
如果有数据,则使用tcp_queue_rcv()将数据加入到接收队列中。
static int __must_check tcp_queue_rcv(struct sock *sk, struct sk_buff *skb,
bool *fragstolen)
{
int eaten;
struct sk_buff *tail = skb_peek_tail(&sk->sk_receive_queue);
eaten = (tail &&
tcp_try_coalesce(sk, tail,
skb, fragstolen)) ? 1 : 0;
tcp_rcv_nxt_update(tcp_sk(sk), TCP_SKB_CB(skb)->end_seq);
if (!eaten) {
__skb_queue_tail(&sk->sk_receive_queue, skb);
skb_set_owner_r(skb, sk);
}
return eaten;
}
tcp_queue_rcv用于将接收到的skb加入到接收队列receive_queue中,首先会调用tcp_try_coalesce进行分段合并到队列中最后一个skb的尝试,若失败则调用__skb_queue_tail添加该skb到队列尾部。
之后会调用tcp_data_queue(),并且调用tcp_data_ready()。
static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
bool fragstolen;
int eaten;
.........................
if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
tcp_ofo_queue(sk);
/* RFC5681. 4.2. SHOULD send immediate ACK, when
* gap in queue is filled.
*/
if (RB_EMPTY_ROOT(&tp->out_of_order_queue))
inet_csk(sk)->icsk_ack.pending |= ICSK_ACK_NOW;
}
if (tp->rx_opt.num_sacks)
tcp_sack_remove(tp);
tcp_fast_path_check(sk);
if (eaten > 0)
kfree_skb_partial(skb, fragstolen);
if (!sock_flag(sk, SOCK_DEAD))
tcp_data_ready(sk);
return;
............................
}
void tcp_data_ready(struct sock *sk)
{
const struct tcp_sock *tp = tcp_sk(sk);
int avail = tp->rcv_nxt - tp->copied_seq;
if (avail < sk->sk_rcvlowat && !sock_flag(sk, SOCK_DONE))
return;
sk->sk_data_ready(sk);
}
tcp_data_ready()会调用sk_data_ready(),提醒当前sock有数据可读事件。
4.2.2 gdb调试验证
首先是ip层将数据传入队列;
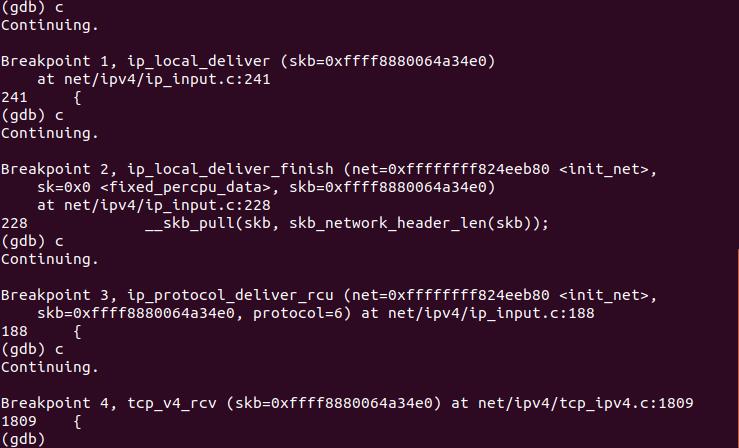
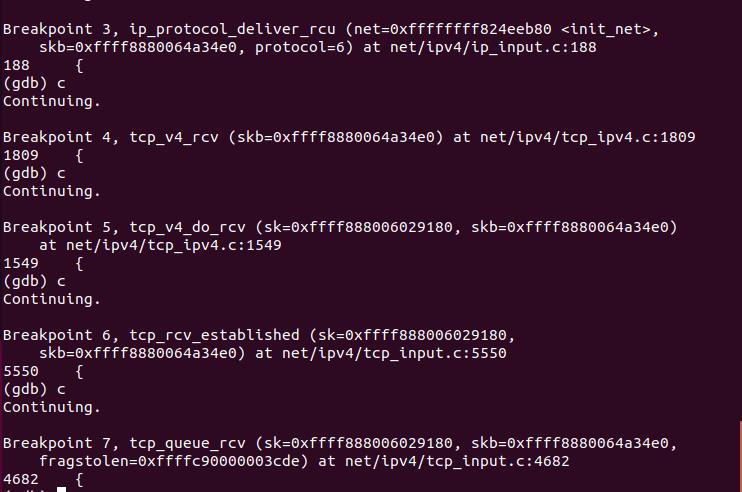
然后是tcp_recvmsg()从队列中读取数据。

4.3 网络层流程
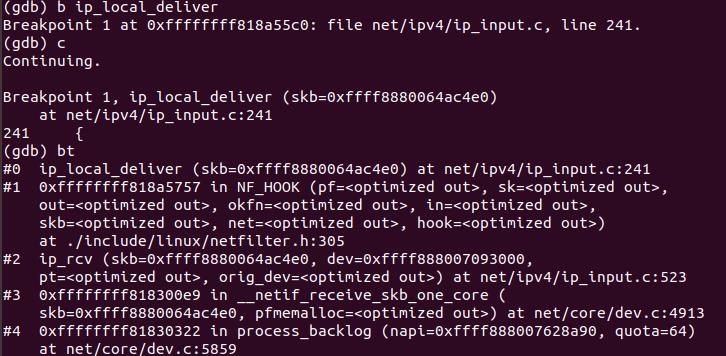
由调用栈可知,ip_rcv()是网络层接收数据的入口函数。
4.3.1 代码分析
/*
* IP receive entry point
*/
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt,
struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING,
net, NULL, skb, dev, NULL,
ip_rcv_finish);
}
ip_rcv()调用已经注册的 PRE_ROUTING netfilter hook ,最终调用ip_rcv_finish()函数。
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
/* if ingress device is enslaved to an L3 master device pass the
* skb to its handler for processing
*/
skb = l3mdev_ip_rcv(skb);
if (!skb)
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
ip_rcv()可以看成是查找路由前的IP层处理,接下来的ip_rcv_finish()会查找路由表,两者间通过调用插入的netfilter来产生关联。ip_rcv_finish()主要工作是完成路由表的查询,决定报文经过IP层处理后,是继续向上传递,还是进行转发,还是丢弃。
对于没有被丢弃的报文,那么报文最终会被dst_input(skb)处理。对于应该本地传递的报文,input指针会指向ip_local_deliver。对于该转发的报文,input会指向ip_forward。
对于ip_local_deliver()的执行过程,可见[4.2.1代码分析](####4.2.1 代码分析),此处不再赘述。
4.3.2 gdb调试验证

4.4 数据链路层和物理层流程
4.4.1 代码分析
网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核的网络模块,驱动在加载的时候将自己注册进网络模块,当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据。
主要过程如下:
1: 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,且该网卡没有开启混杂模式,该包会被网卡丢弃。
2: 网卡将数据包通过或DMA的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化。注: 老的网卡可能不支持DMA,不过新的网卡一般都支持,具体多少划给DMA使用,不同的计算机体系有所不同,很多体系全部内存都可用。
3: 网卡通过硬件中断(IRQ)通知CPU,告诉它有数据来了。
4: CPU根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数。
5: 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知CPU了,这样可以提高效率,避免CPU不停的被中断。
6: 启动软中断。这步结束后,硬件中断处理函数就结束返回了。由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致CPU没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
7: 内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第6步中是网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数。
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies +
usecs_to_jiffies(netdev_budget_usecs);
int budget = netdev_budget;
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto out;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 ||
time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
net_rps_action_and_irq_enable(sd);
out:
__kfree_skb_flush();
}
在调用net_rx_action函数执行软中断NET_RX_SOFTIRQ时会遍历poll_list链表,然后调用每个设备的poll()函数将数据帧存放在socket buffers中并通知上层协议栈。
napi_gro_receive函数是驱动通过poll注册,内核调用的函数。通过这函数的的调用,skb将会传给协议栈的入口函数__netif_receive_skb。
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb);
ret = napi_skb_finish(dev_gro_receive(napi, skb), skb);
trace_napi_gro_receive_exit(ret);
return ret;
}
static int __netif_receive_skb(struct sk_buff *skb)
{
int ret;
if (sk_memalloc_socks() && skb_pfmemalloc(skb)) {
unsigned int noreclaim_flag;
noreclaim_flag = memalloc_noreclaim_save();
ret = __netif_receive_skb_one_core(skb, true);
memalloc_noreclaim_restore(noreclaim_flag);
} else
ret = __netif_receive_skb_one_core(skb, false);
return ret;
}
//被前一函数调用
static int __netif_receive_skb_one_core(struct sk_buff *skb, bool pfmemalloc)
{
struct net_device *orig_dev = skb->dev;
struct packet_type *pt_prev = NULL;
int ret;
ret = __netif_receive_skb_core(skb, pfmemalloc, &pt_prev);
if (pt_prev)
ret = INDIRECT_CALL_INET(pt_prev->func, ipv6_rcv, ip_rcv, skb,
skb->dev, pt_prev, orig_dev);
return ret;
}
当执行函数__netif_receive_skb_one_core()时,会调用ip_rcv(),将数据包交付给网络层进行处理。
4.4.2 gdb调试验证
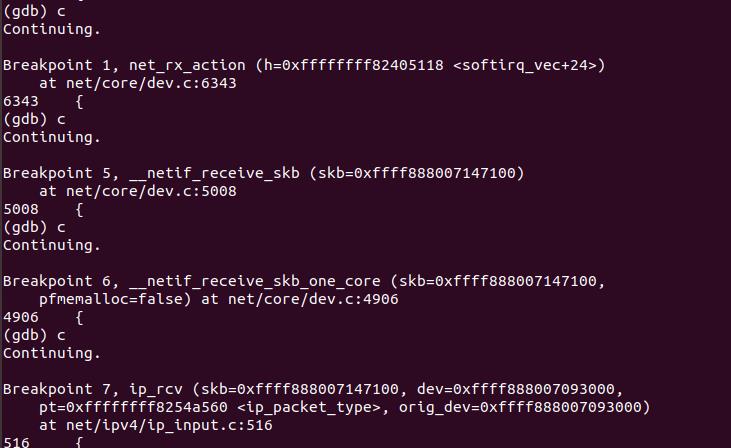
4.4.3 物理层中断处理过程分析
内核和网络设备驱动是通过中断的方式来处理的。当设备上有数据到达的时候,会给CPU的相关引脚上触发一个电压变化,以通知CPU来处理数据。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)将过度占据CPU,将导致CPU无法响应其它设备,例如鼠标和键盘的消息。因此Linux中断处理函数是分上半部和下半部的。上半部是只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。剩下将绝大部分的工作都放到下半部中,可以慢慢从容处理。2.4以后的内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。和硬中断不同的是,硬中断是通过给CPU物理引脚施加电压变化,而软中断是通过给内存中的一个变量的二进制值以通知软中断处理程序。
首先是上半部分的 硬中断 处理过程。
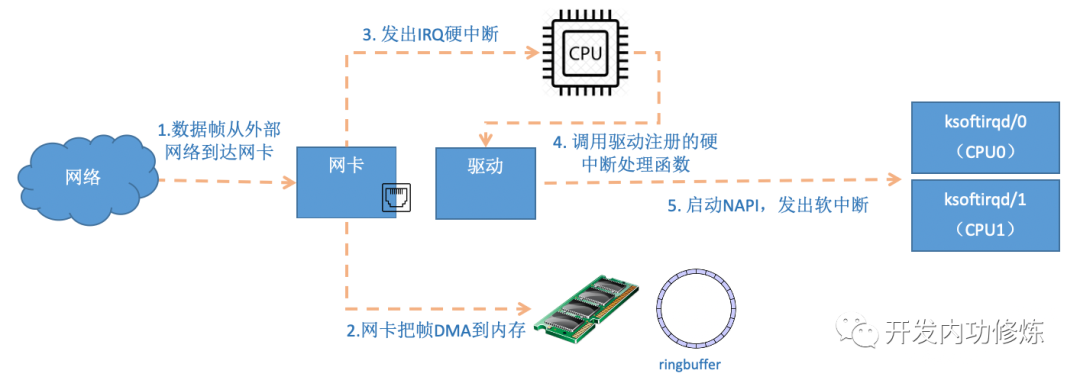
首先当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,这个时候CPU都是无感的。当DMA操作完成以后,网卡会像CPU发起一个硬中断,通知CPU有数据到达。
然后是下半部分的 软中断 处理过程。
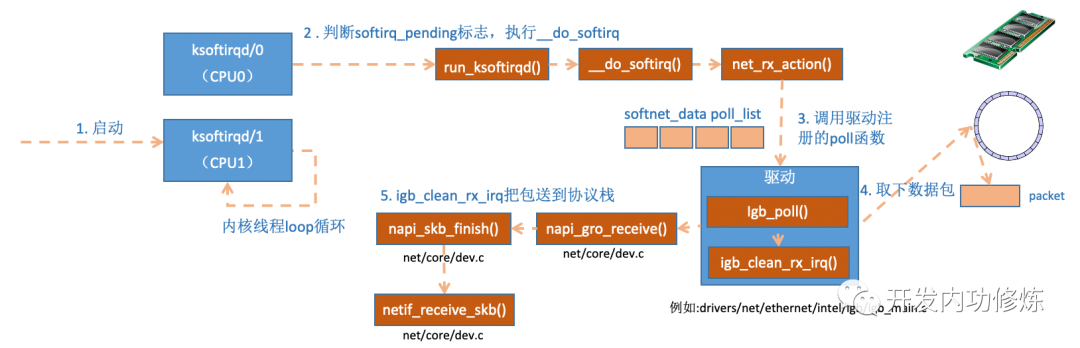
Linux的软中断都是在专门的内核线程(ksoftirqd)中进行的,因此我们非常有必要看一下这些进程是怎么初始化的,这样我们才能在后面更准确地了解收包过程。该进程数量不是1个,而是N个,其中N等于你的机器的核数。
ksoftirqd的创建过程如下:

当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数ksoftirqd_should_run和run_ksoftirqd了。不停地判断有没有软中断需要被处理。这里需要注意的一点是,软中断不仅仅只有网络软中断,还有其它类型。
那么,当ksoftirqd收到一个软中断请求的时候,它是如何来寻找对应的中断处理函数,直到调用到net_rx_action?
首先我们需要从网络子系统的初始化开始分析。

linux内核通过调用subsys_initcall来初始化各个子系统,在源代码目录里你可以grep出许多对这个函数的调用。这里我们要说的是网络子系统的初始化,会执行到net_dev_init函数。
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
BUG_ON(!dev_boot_phase);
if (dev_proc_init())
goto out;
if (netdev_kobject_init())
goto out;
INIT_LIST_HEAD(&ptype_all);
for (i = 0; i < PTYPE_HASH_SIZE; i++)
INIT_LIST_HEAD(&ptype_base[i]);
INIT_LIST_HEAD(&offload_base);
if (register_pernet_subsys(&netdev_net_ops))
goto out;
/*
* Initialise the packet receive queues.
*/
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
#ifdef CONFIG_XFRM_OFFLOAD
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
init_gro_hash(&sd->backlog);
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
dev_boot_phase = 0;
/* The loopback device is special if any other network devices
* is present in a network namespace the loopback device must
* be present. Since we now dynamically allocate and free the
* loopback device ensure this invariant is maintained by
* keeping the loopback device as the first device on the
* list of network devices. Ensuring the loopback devices
* is the first device that appears and the last network device
* that disappears.
*/
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
rc = cpuhp_setup_state_nocalls(CPUHP_NET_DEV_DEAD, "net/dev:dead",
NULL, dev_cpu_dead);
WARN_ON(rc < 0);
rc = 0;
out:
return rc;
}
在这个函数里,会为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来,这一过程发生在网卡驱动初始化的时候。
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
open_softirq()为每一种软中断都注册了一个处理函数。我们可以看到当软中断类型为NET_RX_SOFTIRQ时,其处理函数为net_rx_action()。
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
继续跟踪open_softirq后发现这个注册的方式是记录在softirq_vec变量里的。后面ksoftirqd线程收到软中断的时候,也会使用这个变量来找到每一种软中断对应的处理函数。
static struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.early_demux_handler = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
.icmp_strict_tag_validation = 1,
};
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
static int __init inet_init(void)
{
...................
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
....................
dev_add_pack(&ip_packet_type);
....................
}
类似的,接收数据到达上层协议层时,也是通过ip_rcv(),tcp_v4_rcv()和udp_rcv()这样的入口函数来进行处理。Linux内核中的fs_initcall和subsys_initcall类似,也是初始化模块的入口。fs_initcall调用inet_init后开始网络协议栈注册。通过inet_init,将这些函数注册到了inet_protos和ptype_base数据结构中了。如下图:
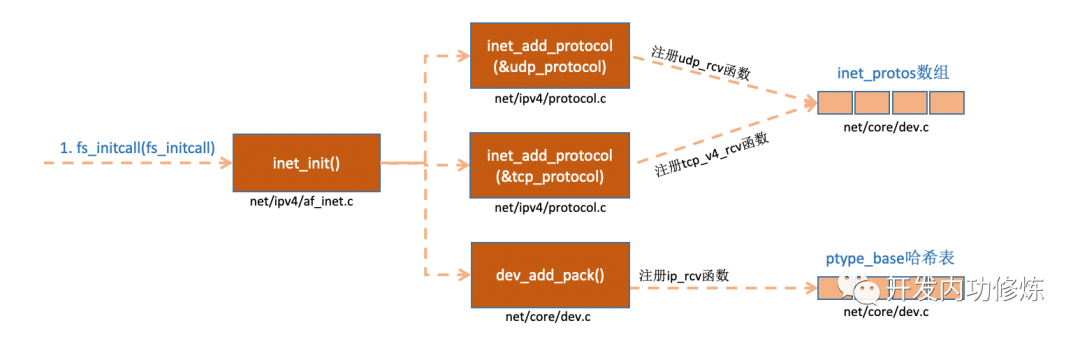
inet_add_protocol函数将tcp和udp对应的处理函数都注册到了inet_protos数组中了。再看dev_add_pack(&ip_packet_type);这一行,ip_packet_type结构体中的type是协议名,func是ip_rcv函数,在dev_add_pack中会被注册到ptype_base哈希表中。
因此软中断中会通过ptype_base找到ip_rcv函数地址,进而将ip包正确地送到ip_rcv()中执行。在ip_rcv中将会通过inet_protos找到tcp或者udp的处理函数,再而把包转发给udp_rcv()或tcp_v4_rcv()函数。
5. 时序图

参考资料:
[1] https://www.cnblogs.com/chy666/p/14290484.html "TCP/IP协议栈在Linux内核中的运行时序分析"
[2] https://www.cnblogs.com/mjq-1998/p/14289606.html "Linux网络编程——详解SOCKET"
[3] https://www.pianshen.com/article/2091244442/ "TCP/IP协议栈在Linux内核中的运行时序分析"
[4] https://www.cnblogs.com/chy666/p/14290484.html "linux内核中socket完全理解"
[5] https://www.cnblogs.com/codestack/p/12863449.html "sock skbuf 结构"
[6] https://blog.csdn.net/notbaron/article/details/79601015 "Linux协议栈(4)——sk_buff及代码"
[7] https://www.cnblogs.com/kongwy/p/14328278.html "TCP/IP协议栈在Linux内核中的运行时序分析"
[8] https://www.cnblogs.com/myguaiguai/p/12069485.html "深入理解TCP协议及其源代码-send和recv背后数据的收发过程"
[9] https://www.cnblogs.com/zhjh256/p/12227883.html "Linux网络包收发总体过程"
[10] https://mp.weixin.qq.com/s/GoYDsfy9m0wRoXi_NCfCmg "图解Linux网络包接收过程"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号