PostgreSQL中的序列名很长很长怎么办
PostgreSQL中的序列名很长很长怎么办
PostgreSQL中的序列名很长很长怎么办
tag: PostgreSQL, 数据库移植
1.前言
我们回忆一下,PostgreSQL好像有对象名不超过63个字符的默认限制。详见: current/limit.html
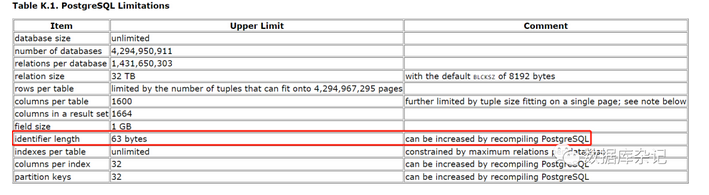
而序列名可能是由系统自动生成的那种。比如一个表定义了某一列是serial之类的,它会隐含创建一个sequence。
我们来通过简单的实例看看这是啥样的情形?本能的,你可能以为,如果表名很长,序列名是不是超长了?
2.实际验证
2.1 正常的示例:
1postgres=# create table test(id bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ test
4 Table "public.test"
5 Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
6--------+--------+-----------+----------+----------------------------------+----------+-------------+--------------+-------------
7 id | bigint | | not null | nextval('test_id_seq'::regclass) | plain | | |
8 col2 | text | | | | extended | | |
9Access method: heap
10
11postgres=# \d+ test_id_seq
12 Sequence "public.test_id_seq"
13 Type | Start | Minimum | Maximum | Increment | Cycles? | Cache
14--------+-------+---------+---------------------+-----------+---------+-------
15 bigint | 1 | 1 | 9223372036854775807 | 1 | no | 1
16Owned by: public.test.id
在这个例子中,我们建了一个普通的表test,列: id是一个8位序列类型,这样系统会为表test自动生成序列:test_id_seq,它的名字不过就是11。是<表名>_<列名>_seq,也就是len(序列名) = len(表名) + len(seq列名)+5。
这种情况发生在后者加起来不超过63的情况。
接下来,我们构造一两个边界的例子看看是什么样子的。
2.2 列名很长
建了下面这张表,让序列对应的列名长为63.
1postgres=# create table test1(col123456789012345678901234567890123456789012345678901234567890 bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ test1
4 Table "public.test1"
5 Column | Type | Collation | Nullable |
6 Default | Storage | Compression | Stats target | Description
7-----------------------------------------------------------------+--------+-----------+----------+--------------------------------------
8------------------------------------------------+----------+-------------+--------------+-------------
9 col123456789012345678901234567890123456789012345678901234567890 | bigint | | not null | nextval('test1_col1234567890123456789
100123456789012345678901234567890_seq'::regclass) | plain | | |
11 col2 | text | | |
12 | extended | | |
13Access method: heap
我们能看到,生成的序列名为:test1_col12345678901234567890123456789012345678901234567890_seq,总长也是63。

将列名最末字符换成1,结果就是:
1postgres=# create table test1(col123456789012345678901234567890123456789012345678901234567891 bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ test1
4 Table "public.test1"
5 Column | Type | Collation | Nullable |
6 Default | Storage | Compression | Stats target | Description
7-----------------------------------------------------------------+--------+-----------+----------+--------------------------------------
8------------------------------------------------+----------+-------------+--------------+-------------
9 col123456789012345678901234567890123456789012345678901234567891 | bigint | | not null | nextval('test1_col1234567890123456789
100123456789012345678901234567890_seq'::regclass) | plain | | |
11 col2 | text | | |
12 | extended | | |
13Access method: heap
生成的序列名为:test1_col12345678901234567890123456789012345678901234567890_seq,总长也是63。
名字与前边那个是一样的,对比一下看下图:

反向推理:它是把 {表名_截短后的列名_seq}构造成新的序列名。截短的原则是,从最末尾的子串进行截短。超长的部分都截掉。
2.3 表名很长
我们再看看如下示例,表名长度为63:tab123456789012345678901234567890123456789012345678901234567890
生成的序列名为:tab1234567890123456789012345678901234567890123_id1234567890_seq, 长度仍然为63.
1postgres=# create table tab123456789012345678901234567890123456789012345678901234567890(id1234567890 bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ tab123456789012345678901234567890123456789012345678901234567890
4 Table "public.tab123456789012345678901234567890123456789012345678901234567890"
5 Column | Type | Collation | Nullable | Default | S
6torage | Compression | Stats target | Description
7--------------+--------+-----------+----------+--------------------------------------------------------------------------------------+--
8--------+-------------+--------------+-------------
9 id1234567890 | bigint | | not null | nextval('tab1234567890123456789012345678901234567890123_id1234567890_seq'::regclass) | p
10lain | | |
11 col2 | text | | | | e
12xtended | | |
13Access method: heap
对比一下这两个名字:

看起来,生成的名字是:{截短后表名_列名_seq}。如果是这样,依据这个,构造一个不同的表名,看看是什么样的?
比如表名是:tab123456789012345678901234567890123456789012345678901234567891,即最末一个字符不同。我们看看:
1postgres=# create table tab123456789012345678901234567890123456789012345678901234567891(id1234567890 bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ tab123456789012345678901234567890123456789012345678901234567891
4 Table "public.tab123456789012345678901234567890123456789012345678901234567891"
5 Column | Type | Collation | Nullable | Default | S
6torage | Compression | Stats target | Description
7--------------+--------+-----------+----------+--------------------------------------------------------------------------------------+--
8--------+-------------+--------------+-------------
9 id1234567890 | bigint | | not null | nextval('tab123456789012345678901234567890123456789012_id1234567890_seq1'::regclass) | p
10lain | | |
11 col2 | text | | | | e
12xtended | | |
13Access method: heap
在这个我们想像的”反例“中,
表名:
tab123456789012345678901234567890123456789012345678901234567891
序列名:
tab123456789012345678901234567890123456789012_id1234567890_seq1
与上边的示例四个名字对比一下:

反推一下,情况也明了了,当它发现序列名可能重复时,会在seq后边加上计数器,然后前边的截断重新调整一下就实现了唯一性。这个算法看来不错。
2.4 表名和列名都很长
我们一步到位。表名:
tab123456789012345678901234567890123456789012345678901234567892 长度:63
序列列名:
col123456789012345678901234567890123456789012345678901234567890 长度:63
两者都很长。
1postgres=# create table tab123456789012345678901234567890123456789012345678901234567892(col123456789012345678901234567890123456789012345678901234567890 bigserial, col2 text);
2CREATE TABLE
3postgres=# \d+ tab123456789012345678901234567890123456789012345678901234567892
4 Table "public.tab123456789012345678901234567890123456789
5012345678901234567892"
6 Column | Type | Collation | Nullable |
7 Default | Storage | Compression | Stats target | Description
8-----------------------------------------------------------------+--------+-----------+----------+--------------------------------------
9------------------------------------------------+----------+-------------+--------------+-------------
10 col123456789012345678901234567890123456789012345678901234567890 | bigint | | not null | nextval('tab12345678901234567890123456_col12345678901234567890123456_seq'::regclass) | plain | | |
11 col2 | text | | |
12 | extended | | |
13Access method: heap
我们看看生成的序列名:tab12345678901234567890123456_col12345678901234567890123456_seq 长度:63
1表名:tab123456789012345678901234567890123456789012345678901234567892
2列表:col123456789012345678901234567890123456789012345678901234567890
3序列:tab12345678901234567890123456_col12345678901234567890123456_seq

从现象上看,它从表名中拿了30个字符,从列名中拿了前30个字符。这个应该也有一定的选择性算法。
如果我们把上边的表名调整一下,末位改为1. 得到的是下边的结果:
1postgres=# create table tab123456789012345678901234567890123456789012345678901234567891(col123456789012345678901234567890123456789012345678901234567890 bigserial, col2 text)
2;
3CREATE TABLE
4postgres=# \d+ tab123456789012345678901234567890123456789012345678901234567891
5 Table "public.tab123456789012345678901234567890123456789
6012345678901234567891"
7 Column | Type | Collation | Nullable |
8 Default | Storage | Compression | Stats target | Description
9-----------------------------------------------------------------+--------+-----------+----------+--------------------------------------
10------------------------------------------------+----------+-------------+--------------+-------------
11 col123456789012345678901234567890123456789012345678901234567890 | bigint | | not null | nextval('tab12345678901234567890123456_col1234567890123456789012345_seq1'::regclass) | plain | | |
12 col2 | text | | |
13 | extended | | |
14Access method: heap
1表名:tab123456789012345678901234567890123456789012345678901234567891
2列表:col123456789012345678901234567890123456789012345678901234567890
3序列:tab12345678901234567890123456_col1234567890123456789012345_seq1

作为对比,我们发现,它这里仍然以”去重“为思想,然后从总的表名列名全并串里头重新截短。真是妙。
至此,全部验证结束。我们可以大胆放心的使用了。
小结:
PostgreSQL中的对象名长度限制,针对序列类型的序列对象名的自动生成,还是比较巧妙的。我们也不用担心超长的问题。它会根据表名以及对应的列名,有规律的生成序列名。在认为有重复的时候,后缀可能就是_seq1, _seq2。
所以,放心大胆的用吧。只要表名列名都不超长即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号