PostgreSQL插件 pg_repack 回收膨胀的空间占用
:PostgreSQL插件(2): pg_repack 回收膨胀的空间占用
编者荐语:
报考PG数据库专家 上盘古云课堂
以下文章来源于数据库杂记 ,作者SeanHe
1、前言
我们前边曾经介绍过PostgreSQL数据库在生产环境中确实经常会发生表膨胀现象,如果不及时进行清理,无论是对系统性能,还是资源消耗,都有很大影响。尤其是在云环境中,资源的消耗直接与费用相关,所以,就更显得重要了。
Vacuum Full,由于要长时间锁表,并且锁的粒度比较大:
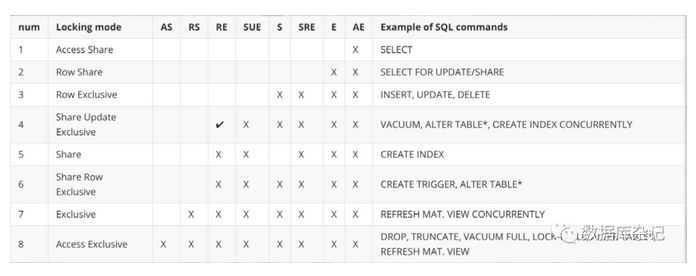
你能看到,它用的是8级锁,在业务频繁的生产环境中,基本上没有用武之地,有时候就像一块鸡肋。只能在每年的几个维护周期偶尔用一用。里边的VACUUM倒是可以一用,但是回收空间的效果并不是很好,它是4级锁。
基于这种情形,就有一些开源的插件用到了PG中。如:
pg_repack, pgcompacttable, pg_sequeeze。
因为pg_repack在一些云厂商中大量使用,这里主要就对它进行一些基本介绍。
2、pg_repack基本思想
pg_repack的处理方式是创建一张新表,再将历史数据从原表中拷贝一份到新表。在拷贝过程中为了避免表被锁定,会创建了一个额外的日志表来记录原表的改动,并添加了一个涉及INSERT、UPDATE、DELETE操作的触发器将变更记录同步到日志表。当原始表中的数据全部导入到新表中,索引重建完毕以及日志表的改动全部完成后,pg_repack会用新表替换旧表,并将原旧表Drop掉。此工具过程简单且靠谱,单需要额外的磁盘空间来报错临时创建的中间表。
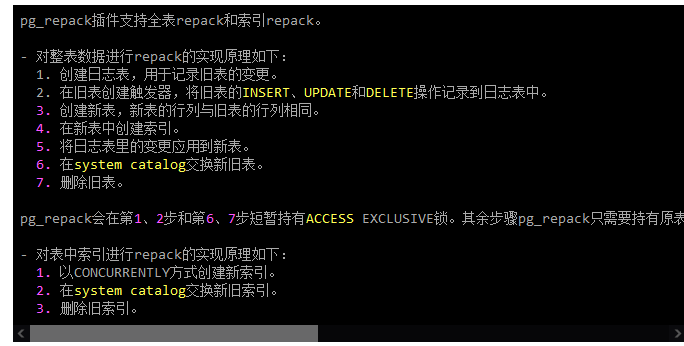
pg_repack插件支持全表repack和索引repack。
- 对整表数据进行repack的实现原理如下:
1. 创建日志表,用于记录旧表的变更。
2. 在旧表创建触发器,将旧表的INSERT、UPDATE和DELETE操作记录到日志表中。
3. 创建新表,新表的行列与旧表的行列相同。
4. 在新表中创建索引。
5. 将日志表里的变更应用到新表。
6. 在system catalog交换新旧表。
7. 删除旧表。
pg_repack会在第1、2步和第6、7步短暂持有ACCESS EXCLUSIVE锁。其余步骤pg_repack只需要持有原表的ACCESS SHARE锁,不影响原表的INSERT、UPDATE和DELETE。
- 对表中索引进行repack的实现原理如下:
1. 以CONCURRENTLY方式创建新索引。
2. 在system catalog交换新旧索引。
3. 删除旧索引。
同时,
-
pg_repack需要额外的存储空间。全表repack时,剩余存储空间大小需要至少是被清理的表大小的2倍。
-
pg_repack无法操作临时表。
-
pg_repack无法操作GiST索引。
-
pg_repack运行时无法对正在进行repack的表执行DDL操作。pg_repack会持有ACCESS SHARE锁,禁止DDL执行。
-
重建表和索引时会占用较多的磁盘IO,使用时请提前评估是否影响业务。以ESSD PL1云盘为例,repack 100 GB的表时,可能会达到IO吞吐上限(250MB/s)。
-
pg_repack插件需要配合客户端使用,需要先安装pg_repack客户端,然后通过命令行使用pg_repack插件。
3. 简单实验验证
1) 下载安装
下载:
wget https://api.pgxn.org/dist/pg_repack/1.4.8/pg_repack-1.4.8.zip 原始地址:https://pgxn.org/dist/pg_repack/
https://github.com/reorg/pg_repack
解压编译安装2进制包:
unzip pg_repack-1.4.8.zip
make && sudo make install
经此一步,相应的pg_repack会被安装到psql, pg_config相同的bin目录 下边。
另外,还要安装插件本身:
postgres=# \c mydb
You are now connected to database "mydb" as user "postgres".
mydb=# create extension pg_repack;
CREATE EXTENSION
mydb=# \dx+ pg_repack ;
Objects in extension "pg_repack"
Object description
-------------------------------------------------------------------------------
function repack.conflicted_triggers(oid)
function repack.disable_autovacuum(regclass)
function repack.get_alter_col_storage(oid)
function repack.get_assign(oid,text)
function repack.get_columns_for_create_as(oid)
function repack.get_compare_pkey(oid,text)
function repack.get_create_index_type(oid,name)
function repack.get_create_trigger(oid,oid)
function repack.get_drop_columns(oid,text)
function repack.get_enable_trigger(oid)
function repack.get_index_columns(oid,text)
function repack.get_order_by(oid,oid)
function repack.get_storage_param(oid)
function repack.get_table_and_inheritors(regclass)
function repack.oid2text(oid)
function repack.repack_apply(cstring,cstring,cstring,cstring,cstring,integer)
function repack.repack_drop(oid,integer)
function repack.repack_indexdef(oid,oid,name,boolean)
function repack.repack_index_swap(oid)
function repack.repack_swap(oid)
function repack.repack_trigger()
function repack.version()
function repack.version_sql()
schema repack
view repack.primary_keys
view repack.tables
(26 rows)
2) 模拟一张表的膨胀回收
create table t3 (id int);
insert into t3 values(1);
begin;
\set VERBOSE verbose
\set timing on
do language plpgsql $$
declare
tcount int = 100000;
begin
for i in 1..tcount loop
update t3 set id = id+1;
end loop;
end;
$$;
commit;
DO
Time: 120762.618 ms (02:00.763)
mydb=*# commit;
[01:22:34-postgres@centos2:/pgccc/myts]$ pg_repack -t public.t3 -j 2 -d mydb
NOTICE: Setting up workers.conns
WARNING: relation "public.t3" must have a primary key or not-null unique keys
看到没,它需要目标表有主键或Unique Key。所以,需要提前准备好。
mydb=# alter table t3 add primary key (id);
ALTER TABLE
select * from pgstattuple('t3')\gx
-[ RECORD 1 ]------+--------
table_len | 3629056
tuple_count | 1
tuple_len | 28
tuple_percent | 0
dead_tuple_count | 0
dead_tuple_len | 0
dead_tuple_percent | 0
free_space | 3614416
free_percent | 99.6
[01:25:36-postgres@centos2:/pgccc/myts]$ pg_repack -t public.t3 -j 2 -d mydb
NOTICE: Setting up workers.conns
INFO: repacking table "public.t3"
结束以后再次查询使用情况:
mydb=# select * from pgstattuple('t3')\gx
-[ RECORD 1 ]------+------
table_len | 8192
tuple_count | 1
tuple_len | 28
tuple_percent | 0.34
dead_tuple_count | 0
dead_tuple_len | 0
dead_tuple_percent | 0
free_space | 8128
free_percent | 99.22
发现table_len也变了。
我们使用pgstattuple查询,一下看到表的大小从3629056降到8K。这里也使用了-j 2并行的方式进行回收,以提高速度。
上边的动作看起来比较顺利,因为它是在superuse: postges下运行的。
有两个参数需要注意:
-D, --no-kill-backend don't kill other backends when timed out
-k, --no-superuser-check skip superuser checks in client
前一个-D,如果不设定,超时的时候可能会把其它的backend 进程给误杀了。
-k ,跳过superuser检查,这是专门给权限不足的用户设定的,尤其是在Cloud环境中的使用,更是如此,很多时候,并不给你superuser的权限。
4. 模拟非superuser的使用
我们使用在db: mydb下先来安装pg_repack。然后尝试用它的普通用户mydb来使用pg_repack.
[04:51:06-postgres@centos1:/var/lib/pgsql/14/data]$ psql mydb -U postgres
psql (14.7)
Type "help" for help.
mydb=# create extension pg_repack;
CREATE EXTENSION
mydb=# \dx
List of installed extensions
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
file_fdw | 1.0 | public | foreign-data wrapper for flat file access
pageinspect | 1.9 | public | inspect the contents of database pages at a low level
pg_buffercache | 1.3 | public | examine the shared buffer cache
pg_freespacemap | 1.2 | public | examine the free space map (FSM)
pg_repack | 1.4.7 | public | Reorganize tables in PostgreSQL databases with minimal locks
pg_stat_statements | 1.9 | public | track planning and execution statistics of all SQL statements executed
pg_visibility | 1.2 | public | examine the visibility map (VM) and page-level visibility info
pgstattuple | 1.5 | public | show tuple-level statistics
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
postgres_fdw | 1.1 | public | foreign-data wrapper for remote PostgreSQL servers
(10 rows)
使用mydb用户建表模拟数据膨胀暂不能回收空间。
mydb=# \c - mydb
You are now connected to database "mydb" as user "mydb".
mydb=> create table t1(id int primary key, col2 varchar(32));
CREATE TABLE
mydb=> insert into t1 select n, 'test' || n from generate_series(1, 500000) as n;
INSERT 0 500000
mydb=> delete from t1 where id < 300000;
DELETE 299999
mydb=> select pg_total_relation_size('t1');
pg_total_relation_size
------------------------
33423360
(1 row)
调用pg_repack,看下:
[04:56:15-postgres@centos1:/var/lib/pgsql/14/data]$ pg_repack -t public.t1 -D -j 2 -d mydb -U mydb -k
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
^
我的乖乖,使用了-k,也不能用。这种情况下,只能通过 superuser进行授权才行。因为repack这个schema是postgres用户创建的。
我们再试下授权以后是否好使。
mydb=> \c - postgres
You are now connected to database "mydb" as user "postgres".
mydb=# GRANT USAGE ON SCHEMA repack to mydb;
GRANT
mydb=# GRANT SELECT ON ALL TABLES IN SCHEMA repack to mydb;
GRANT
mydb=# GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA repack to mydb;
GRANT
再次运行:
出现大量的这种错:
DETAIL: query was: SELECT repack.repack_drop($1, $2)
ERROR: query failed: ERROR: must be superuser to use repack_drop function
DETAIL: query was: SELECT repack.repack_drop($1, $2)
ERROR: query failed: ERROR: must be superuser to use repack_drop function
DETAIL: query was: SELECT repack.repack_drop($1, $2)
ERROR: query failed: ERROR: must be superuser to use repack_drop function
DETAIL: query was: SELECT repack.repack_drop($1, $2)
^Z
找到lib/repack.c, line: 105-109, 注掉相关的错误处理:
/* check access authority */
static void
must_be_superuser(const char *func)
{
/*
if (!superuser())
elog(ERROR, "must be superuser to use %s function", func);
*/
}
再补上一刀,关于权限:
mydb=# alter schema repack owner to mydb;
ALTER SCHEMA
我们再看看结果:
[05:31:56-postgres@centos1:/pgccc/source/pg_repack/pg_repack-1.4.8]$ pg_repack -t public.t1 -D -j 2 -d mydb -U mydb -k
NOTICE: Setting up workers.conns
INFO: repacking table "public.t1"
这下好像是成功了,绕了几个圈。
[05:32:01-postgres@centos1:/pgccc/source/pg_repack/pg_repack-1.4.8]$ psql mydb -U mydb
psql (14.7)
Type "help" for help.
mydb=> select pg_total_relation_size('t1');
pg_total_relation_size
------------------------
13402112
(1 row)
这下表的大小从原来的:33423360降到了13402112字节。因为删掉了约60%的记录总量,所以也符合预期。
5. 总结:
如果真的是限制到了普通用户,那么:
1)要足量的赋权:
GRANT USAGE ON SCHEMA repack to mydb;
GRANT SELECT ON ALL TABLES IN SCHEMA repack to mydb;
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA repack to mydb;
alter schema repack owner to mydb;
ALTER SCHEMA
这里的第2行也可以不要。因为整个schema的owner都给了用户mydb了。
2) 修改pg_repack的代码 lib/repack.c,把superuser的检查的去掉,否则那个-k还真的绕不过去。话说,如果这个全让DBA来干的话,给个superuser 也在情理之中。可是在cloud环境中,权限分配错综复杂。只能想办法绕过去。(lib/repack.c: line 105 ~ 109)
/* check access authority */
static void
must_be_superuser(const char *func)
{
/*
if (!superuser())
elog(ERROR, "must be superuser to use %s function", func);
*/
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号