

k8s高可用安装
https://blog.csdn.net/weixin_44657145/article/details/124412065
前言
一般安装的话都只是单master多node节点的集群,但是一但master出现故障时,是非常影响使用何效率的,如果出现不可恢复的意外,只有去备份etcd然后在新的集群里面去恢复他,为了避免一系列问题,所以使用keepalived+haproxy或者keepalived+nginx实现集群高可用和均衡负载。
安装
以下分为3部分 (all node、all Slave 、all master)
准备工作
1、修改主机名称(all node)
192.168.8.221 master
192.168.8.222 master2
192.168.8.223 master3
192.168.8.224 node1
192.168.8.225 node2
192.168.8.228 VIP以上是我们将要使用的虚拟机和虚拟IP
2、修改/etc/hosts文件 (all node)
cat >> /etc/hosts << EOF
192.168.8.221 master
192.168.8.222 master2
192.168.8.223 master3
192.168.8.224 node1
192.168.8.225 node2
EOF3、关闭防火墙、关闭selinux、关闭swap(all node)
systemctl stop firewalld && systemctl disable firewalld
sed -i 's/enforcing/disabled/' /etc/selinux/config && setenforce 0
swapoff -a && sed -ri 's/.*swap.*/#&/' /etc/fstab4、安装和同步时间(all node)
#安装和同步
yum install ntpdate -y && timedatectl set-timezone Asia/Shanghai && ntpdate time2.aliyun.com
# 加入到crontab
0 5 * * * /usr/sbin/ntpdate time2.aliyun.com
# 加入到开机自动同步,/etc/rc.local
ntpdate time2.aliyun.com
#也可以采用以下方案
# 1、时间服务器安装,可以用 master当时间服务器
yum install chrony -y
vim /etc/chrony.conf
#自己作为时间同步标准
server 127.127.1.0 iburst
#允许其他主机进行时间同步
allow 192.168.8.0/24
local stratum 10
#重启服务器和设置开机启动、测试端口
systemctl restart chronyd
systemctl enable chronyd
netstat -luntp|grep 123
# 2、其他节点安装和设置
yum install chrony -y
vim /etc/chrony.conf
# 其他server都注释掉
server 192.168.8.221 iburst
#做好服务端的在重启
systemctl restart chronyd
systemctl enable chronyd
#查看设置
chronyc sources5、安装和开启ipvs(负载均衡)(all node)
#安装
yum install ipvsadm ipset sysstat conntrack libseccomp -y
#临时生效
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
#永久生效
cat <<EOF > /etc/modules-load.d/ipvs.conf
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF6、安装iptables,并设置规则。k8s引用的是这个路由规则 (all node)
# ip_vs和iptables选择一种,ip_vs比iptables好
#如果k8s环境用ip_vs,那么这步可以 省略!!!
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save7、设置系统ulimit值 (all node)
#使用ulimit -a 可以查看当前系统的所有限制值,使用ulimit -n 可以查看当前的最大打开文件数。
#新装的linux默认只有1024,当作负载较大的服务器时,很容易遇到error: too many open files。因此,需要将其改大。
#使用 ulimit -n 65535 可即时修改,但重启后就无效了。(注ulimit -SHn 65535 等效 ulimit -n 65535,-S指soft,-H指hard)
#临时设置,但重启后就无效了
ulimit -SHn 65535
# 资源配置,永久设置
vim /etc/security/limits.conf
# 末尾添加如下内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft memlock unlimited
* hard memlock unlimited8、开启一些k8s集群中必须的内核参数 (all node)
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward=1
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
fs.may_detach_mounts=1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time=600
net.ipv4.tcp_keepalive_probes=3
net.ipv4.tcp_keepalive_intvl=15
net.ipv4.tcp_max_tw_buckets=36000
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_max_orphans=327680
net.ipv4.tcp_orphan_retries=3
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_max_syn_backlog=16384
net.ipv4.ip_conntrack_max=65536
net.ipv4.tcp_max_syn_backlog=16384
net.ipv4.tcp_timestamps=0
net.core.somaxconn=16384
EOF
#使配置的内核参数生效
sysctl --system
#重启后可以查看是否生效
lsmod | grep --color=auto -e ip_vs -e nf_conntrack9、以上安装完重启系统(all node)
reboot10、安装docker (all node)
#安装docker的yum源
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#或者
https://files.cnblogs.com/files/chuanghongmeng/docker-ce.zip?t=1669080259
#安装
yum install docker-ce-20.10.3 -y
#温馨提示:由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
#如果/etc/docker 目录不存在,启动docker会自动创建。
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://xxxxxxxx.mirror.aliyuncs.com"]
}
EOF
#温馨提示:根据服务器的情况,选择docker的数据存储路径,例如:/data
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd --graph=/data/docker
#重载配置文件
systemctl daemon-reload
systemctl restart docker
systemctl enable docker.service11、高可用组件安装 HAProxy和Keepalived (all master)
yum -y install haproxy keepalived在所有Master节点上创建HAProxy配置文件
cat > /etc/haproxy/haproxy.cfg << EOF
global
log 127.0.0.1 local0
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode tcp
log global
option tcplog
option dontlognull
option redispatch
retries 3
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
# 起名
listen k8s_master
# 虚拟IP的端口
bind 0.0.0.0:16443
mode tcp
option tcplog
balance roundrobin
# 高可用的负载均衡的master
server master 192.168.3.150:6443 check inter 10000 fall 2 rise 2 weight 1
server master2 192.168.3.151:6443 check inter 10000 fall 2 rise 2 weight 1
server master3 192.168.3.152:6443 check inter 10000 fall 2 rise 2 weight 1
EOF在Master节点上创建Keepalived配置文件
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
router_id master
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3000
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 80
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 111111
}
virtual_ipaddress {
192.168.8.228
}
track_script {
check_haproxy
}
}
EOF在Master2节点上创建Keepalived配置文件:
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
router_id master2
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3000
}
#修改网卡名
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 80
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 111111
}
virtual_ipaddress {
192.168.8.228
}
track_script {
}
}
EOF在Master3节点上创建Keepalived配置文件:
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
router_id master3
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3000
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 80
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 111111
}
virtual_ipaddress {
192.168.8.228
}
track_script {
}
}
EOF在所有Master节点上创建HAProxy检查脚本 (all master)
cat > /etc/keepalived/check_haproxy.sh << EOF
#!/bin/bash
if [ `ps -C haproxy --no-header | wc -l` == 0 ]; then
systemctl start haproxy
sleep 3
if [ `ps -C haproxy --no-header | wc -l` == 0 ]; then
systemctl stop keepalived
fi
fi
EOF
#添加可执行权限
chmod +x /etc/keepalived/check_haproxy.sh启动HAProxy和Keepalived,并设置自启动 (all master)
systemctl start haproxy keepalived
systemctl enable haproxy keepalived
systemctl status haproxy keepalived在master上面查看查看keepalived工作状态
ip addr12、安装k8s组件(all node)
#跟换k8s的yum源
cat <<EOF>> /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#更换阿里源
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo#查看可以安装的版本
yum list kubeadm.x86_64 --showduplicates | sort -r
#卸载旧版本
yum remove -y kubelet kubeadm kubectl
#安装
yum install kubeadm-1.21.10 kubelet-1.21.10 kubectl-1.21.10 -y
#开机启动
systemctl enable kubelet && systemctl start kubelet13、k8s初始化配置
初始化两种方式 (master)
(1)配置文件初始化
#查看版本所需要的镜像和镜像版本
kubeadm config images list --kubernetes-version 1.21.10
#或者
kubeadm config images list --image-repository registry.aliyuncs.com
#提前拉取镜像:这一步可能拉取失败,可以手动拉取
kubeadm config images pull --config kubeadm-config.yaml
# 查看默认配置文件
kubeadm config print init-defaults
# 导出默认配置文件到当前目录
kubeadm config print init-defaults > kubeadm.yamlkubeadm-config.yaml 根据默认配置文件进行修改如下
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.3.150
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
#自己的主机名
name: master
---
apiServer:
#添加高可用配置
extraArgs:
authorization-mode: "Node,RBAC"
#填写所有kube-apiserver节点的hostname、IP、VIP
certSANs:
- master
- master2
- master3
- node01
- 192.168.3.155
- 192.168.3.150
- 192.168.3.151
- 192.168.3.152
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
#跟换镜像源
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.21.10
#虚拟IP和端口
controlPlaneEndpoint: "192.168.3.155:16443"
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd#根据配置文件初始化,自动拉取镜像
kubeadm init --config=kubeadm-config.yaml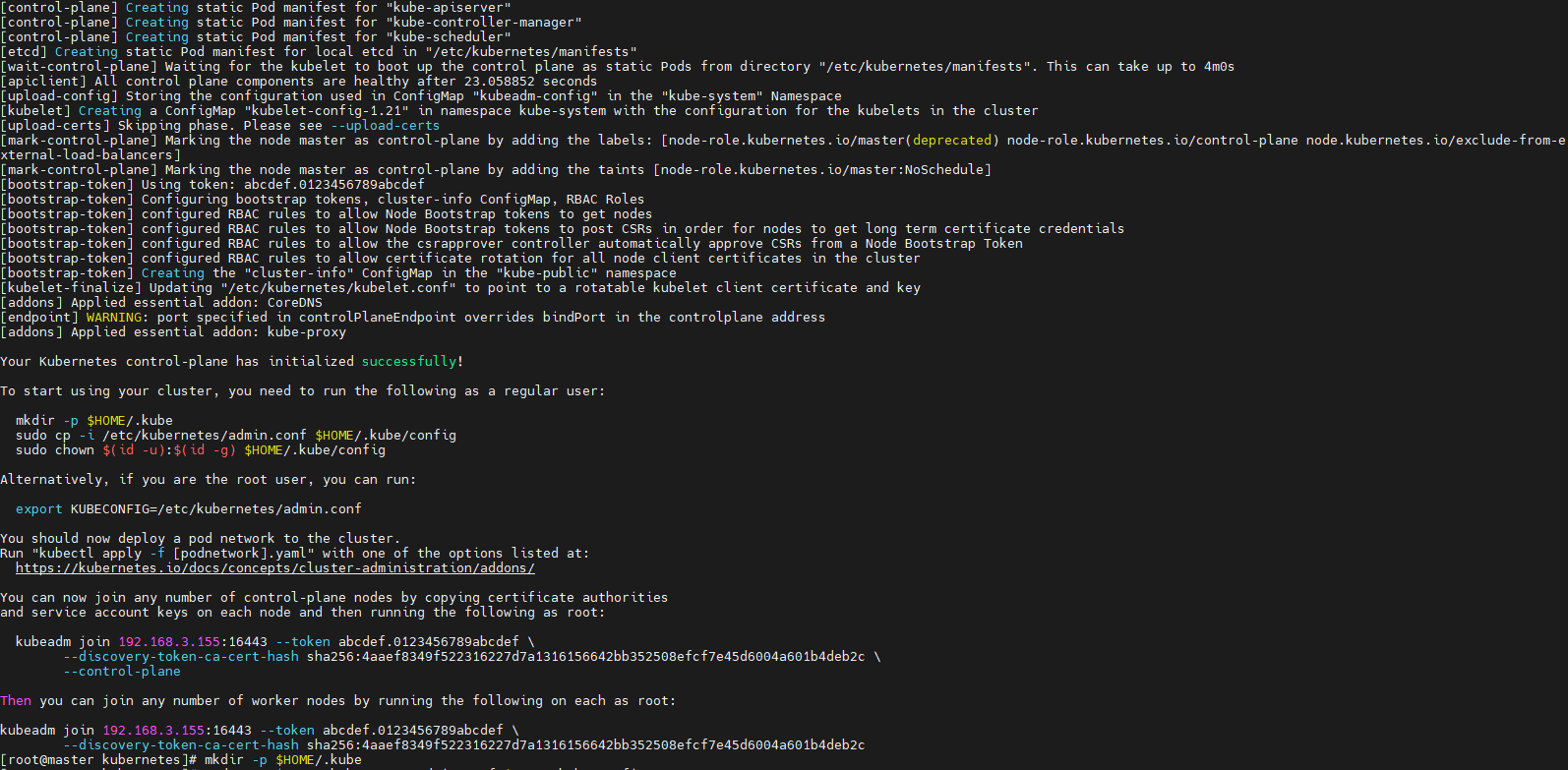
(2)命令初始化(master)
#这里只需主节点执行就可以
[kubeadm init --kubernetes-version=1.21.10 \
--apiserver-advertise-address=192.168.3.150 \ #修改这里为你的主节点ip
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 \
#如果是多master的情况需要将下面的参数加进去,地址换成VIP或者haproxy的负载地址
--control-plane-endpoint "192.168.3.155:16443"如果要手动拉取k8s镜像,可以用以下脚本
#!/bin/bash
url=registry.aliyuncs.com/google_containers
version=v1.21.0
images=(`kubeadm config images list --kubernetes-version=$version|awk -F '/' '{print $2}'`)
for imagename in ${images[@]} ; do
docker pull $url/$imagename
# docker tag $url/$imagename k8s.gcr.io/$imagename
# docker rmi -f $url/$imagename
done其他master节点加入
先拷贝证书,不然报以下错误

#先拷贝证书到其他master节点,不然加入报错 master2和master3
scp -rp /etc/kubernetes/pki/ca.* master2:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/sa.* master2:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/front-proxy-ca.* master2:/etc/kubernetes/pki
scp -rp /etc/kubernetes/pki/etcd/ca.* master2:/etc/kubernetes/pki/etcd
scp -rp /etc/kubernetes/admin.conf master2:/etc/kubernetes/执行命令

其他node节点加入
直接执行加入命令

测试是否加入成功
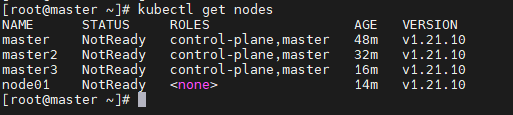
初始化网络
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml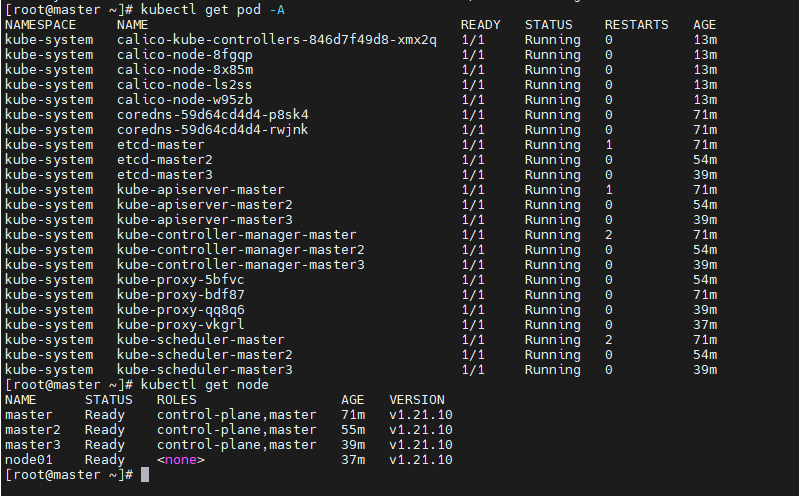
至此k8s高可用集群初始化完成。。。。
14、初始化失败可以重新初始化
[root@master01 ~]# kubeadm reset
[root@master01 ~]# rm -rf $HOME/.kube/config
k8s常见问题处理
1、k8s删除work节点,并重新加入
友情链接:
1、master节点删除后,重新加入报错,节点到集群出现 ETCD 健康检查失败错误。
https://blog.csdn.net/hunheidaode/article/details/118341102
2、生成token
kubeadm token create --print-join-command


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)