
Python进阶篇笔记
一、面向对象
1、面向过程与面向对象
- 面向过程:把程序流程化
- 面向对象:把程序抽象成类,类与类之间有联系
2、类与对象
对象就是容器,是用来存放数据和功能的,对象就是数据和功能的集合
类的作用是吧对象做区分和归类,以及解决不同对象存相同数据的问题。类也是容器,也是用来存放数据和功能的。类是一个模版,是用来创建对象的
3、类的定义
使用class来定义类,类名采用驼峰体来命名,即每个单词的首字母大写。
class Person:
age = 19 # 数据
def set_age(new_age): # 功能
age = new_age
print('xxx') # 类的字代码是在定义阶段就执行了的
4、属性访问
通过类名点属性名的方式来访问类的属性。
类有一个__dict__的属性,通过类名.__dict__可以查看类中的属性,以字典的方式呈现。
Person.age # 访问数据属性
Person.set_age() # 访问函数属性
5、创建对象
创建对象也可以叫做类的实例化。通过调用类来创建对象,调用类时的返回值就是基于那个类创建的对象。
需要注意的是,调用类时类的子代码并不会被执行(而是在类的定义阶段就执行了)(除了__init__方法会在每次调用类时都执行一次)。
person1_obj = Person()
person2_obj = Person()
person3_obj = Person()
# 创建了三个对象
6、对象初始化
创建对象后,可以通过修改对象的__dict__属性(字典)中的元素来对对象进行初始化。也可以直接以对象.属性的方式来给对象添加、修改、删除属性。
person1_obj.__dict__[hobby] = '唱' # 为person1_obj对象添加gender属性
person1_obj.hobby = '跳' # 修改person1_obj对象的hobby属性
通常情况下,我们可以在类中定义一个函数__init__,注意,函数名只能是__init__不能是其他的名称。
当我们每次调用类,也就是创建对象时,就会自动执行__init__这个函数,我们可以将对象的初始化操作写入到这个函数中。
class Person:
age = 19 # 数据
def __init__(self,gender,hobby): # 第一个参数是类创建的空对象,自动传入,一般命名为self
self.gender = gender # 这里的初始化方法与在外面调用对象时修改属性时的方法是相同的
self.hobby = hobby
# 返回值默认为None,且只能为None
def set_age(new_age): # 功能
age = new_age
初始化对象时,就可将需要初始化的属性的值作为参数传入
person1_boj = Person('man',19)
调用类的过程:
- 创建空对象
- 调用
__init__方法,同时把空对象,以及把调用类时括号里的参数一同传递给__init__方法 - 返回初始化后的对象(这个对象并不是init返回的,而是类底层做的事)
7、类的属性与对象的属性
类的属性是所有对象所共有的,且类的属性更改时,所有的对象都能够感知到变化。
对象的属性是自己特有的,且给某个对象增减、修改、删除它自己的属性时,并不会影响到类的属性以及其他对象的属性。

当通过对象访问某个属性时,先在该对象的名称空间中找,如果找到了这个属性,那么这个属性就是对象自己的属性,对这个属性进行修改、删除时都不会影响到类或其他对象中的属性。如果对象中没有该属性,就到类中找。
8、绑定方法
绑定方法的作用:
绑定方法就相当于一个装饰器,它可以将调用函数的那个对象作为函数的第一个参数传进去,比如__init__的第一个参数就是调用类时所创建的那个对象。通过不同的对象来调用函数时,各自的内存地址不同,但他们最终都指向了同一个函数。
因为绑定方法的存在,所以类中的所有函数至少都要有一个参数,第一个参数通常命名为self,其值为调用绑定方法的那个对象。
列表、元组、字典、集合、字符串也都是类
ls = ['a', 'b', 'c', 'd'] # 用对象调用功能
list.append(ls, 'e') # 用类调用功能
print(ls)
二、封装
面向对象编程的三大特性:封装、继承、多态
封装也就是整合的意思,将数据和功能整合在一个容器中。
1、隐藏属性
将类中的名称命名为以两个下划线__开头,这样就可以使使用者在类的外部无法直接访问到该属性。比如将Test类中有一个属性__abc,那么使用Test.__abc或Test.abc都无法访问到属性。
(1)隐藏的本质只是一种改名操作;
改名操作是在类的定义阶段语法检查时就进行的,将类中的所有__x都改为_Test__x。其中Test是类名。
(2)对外不对内
为什么内部能够访问?:因为在定义阶段就已经将所有__x都改为了_Test__x,所以类的内部使用的都是_Test__x这个名字,所以可以访问到。而在类的外部,需要通过点_Test__x才能访问到属性__x。
(3)改名操作只会在类的定义阶段语法检查时执行一次,之后定义的以__开头的属性都不会隐藏(改名)
# 基于类隐藏属性
class Test:
__x = 10
def __f(self):
print('f')
def f2(self):
print(Test.__x) # 类的内部可以正常访问
print(Test.__f)
# 基于对象隐藏属性
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def f2(self):
print(self.__name) # 类的内部可以正常访问
print(self.__age)
2、为什么要隐藏属性?
隐藏属性的作用并不是不让外界使用,而是利用对内不对外的特点,使设类的计者能够严格的控制使用者对属性的各种操作。
比如使用者需要更改某个属性age,而age需要是整型,我们就可以通过在类内部写一个功能set_age,使得使用者需要更改age属性时,调用set_age来更改,我们可以通过编写set_age中的代码来限制age的类型或值的范围等。
隐藏函数属性的作用:隔离复杂度
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self): # 查看属性
return self.__name
def get_age(self): # 查看属性
return self.__age
def set_age(self, new_age): # 修改属性
if type(new_age) is not int:
print('年龄应该为整型')
return
if not 0 <= new_age <= 150:
print('年龄应该在0~150之间')
return
self.__age = new_age
obj = Test('tom', 18)
obj.set_age(20)
print(obj.get_age())
3、property
为什么要用装饰器?
当我们将当我们将类中的数据隐藏后,用户对类中的数据进行查改删时,只能通过调用对应的方法来完成;
如,用户想要获取age这个数据属性时,用的是obj.get_age(),从形式上看,这是调用了一个函数,并不像是获取数据属性;而用户期望的是调用age时,直接obj.age就行。装饰器很好的解决了这个问题,让用户能够以容易理解的方式,来使用类。
使用装饰器前,对属性进行查改删很繁琐
# 使用装饰器前
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
def get_name(self): # 查看属性
return self.__name
def get_age(self): # 查看属性
return self.__age
def set_age(self, new_age): # 修改属性
if type(new_age) is not int:
print('年龄应该为整型')
return
if not 0 <= new_age <= 150:
print('年龄应该在0~150之间')
return
self.__age = new_age
def del_age(self): # 删除属性
del self.__age
obj = Test('abc', 18)
print(obj.get_age()) # 获取属性
obj.set_age(20) # 修改属性
obj.del_age() # 删除属性
使用装饰器后,能够以一种符合习惯的方式对属性进行操作。
# 使用装饰器后
class Test:
def __init__(self, name, age):
self.__name = name
self.__age = age
@property # 相当于get_age = property(get_age)
def age(self): # 查看属性 下面的函数名得修改成和这个一样的(不理解???)名称空间不会冲突吗?
return self.__age
@age.setter # 只能使用固定的方法吗???修改只能setter?删除只能deleter?如果需要实现其他功能呢?
def age(self, new_age): # 修改属性
if type(new_age) is not int:
print('年龄应该为整型')
return
if not 0 <= new_age <= 150:
print('年龄应该在0~150之间')
return
self.__age = new_age
@age.deleter
def age(self): # 删除属性
del self.__age
obj = Test('aaa', 19)
print(obj.age) # 查看属性
obj.age = 20 # 修改属性
print(obj.age)
del obj.age # 删除属性
三、继承
继承:继承是一种创建新类的方式,通过继承创建的类称为子类,被继承的类称为父类(或基类)。
继承的作用:
继承的作用域类的作用类似,类是为了解决对象有共同属性的问题,继承是为了解决类有共同属性的问题。通过继承的方式,可以将类中共同的属性提取到父类中,只需存储一份,解决代码冗余的问题。
1、单继承与多继承
class Parent1:
pass
class Parent2:
pass
class Child1(Parent1): # 单继承
pass
class Child2(Parent1, Parent2): # 多继承
pass
# 通过类名点__bases__可以查看类的父类
print(Child1.__bases__)
print(Child2.__bases__)
# (<class '__main__.Parent1'>,)
# (<class '__main__.Parent1'>, <class '__main__.Parent2'>)
多继承的优缺点:
- 优点:一个子类可以同时遗传多个父类的属性。
- 缺点:1、违背了人的思维习惯;2、多继承会让代码的可读性变差。
单继承:每个子类的父类是唯一的,我们可以很清楚的知道某个子类是属于某个父类。当访问子类中没有的属性时,会去它的父类找,父类没有去爷爷类找,查找线路是唯一的。
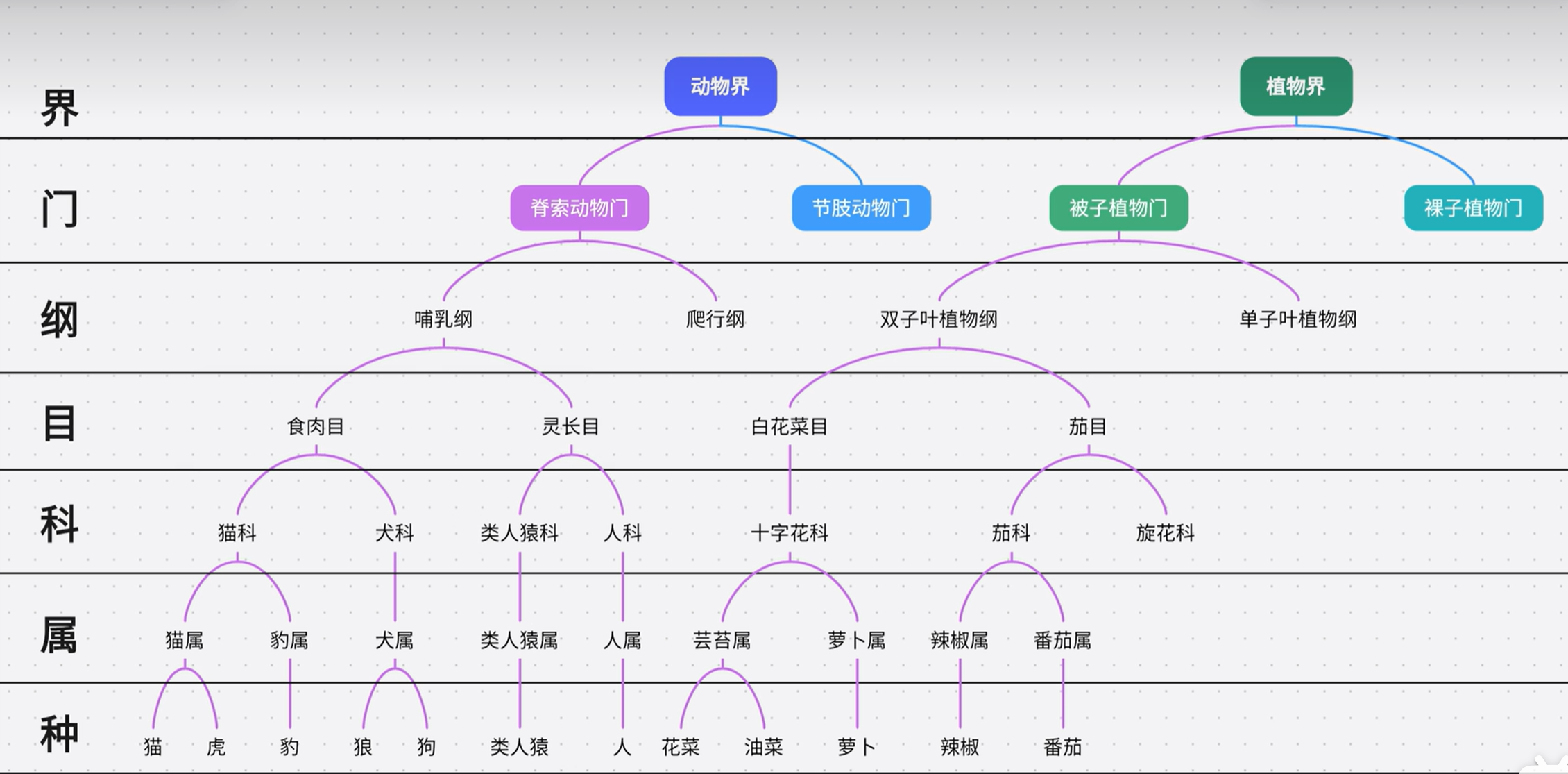
多继承:一个子类可以同时属于多个父类,当需要访问子类中没有的属性时,不知道需要先从哪个父类中找。
例如下图中,猫既属于犬科,又属于类人猿科。
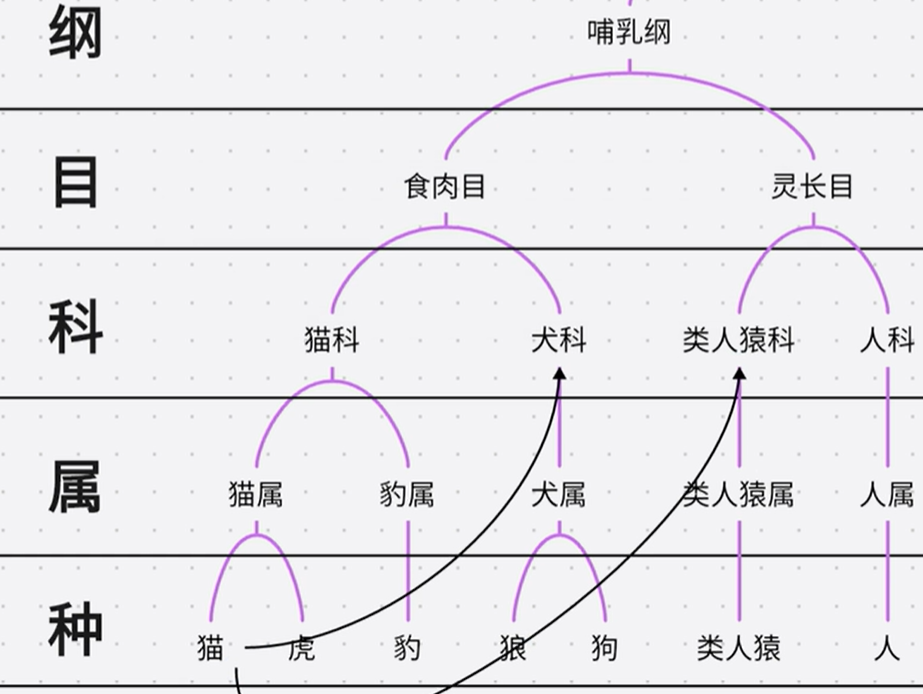
所以,不建议使用多继承。如果必须使用多继承,应该使用Mixins,后面会讲。
2、新式类与经典类
在python2中有经典类与新式类之分
- 新式类:继承了object类的子类,以及继承了这个子类的子子孙孙类。
- 经典类:没有继承object类的子类,以及继承了这个子类的子子孙孙类。
object类时Python的内置类。
在python3中,所有的类都是新式类,也就是如果一个类没有继承任何父类,那么它就默认继承object类。
所以我们可以在定义类时使类继承object类,这样可以使我们的代码兼容Python2。
class Parent1:
pass
print(Parent1.__bases__) # 默认继承object类
# (<class 'object'>,)
class Parent1(object): # 手动继承object类,使得代码在Python中也可以正常使用
pass
在pytohn中,所有的新式类的最终的类都继承自object类。
3、继承的特性:遗传
当子类继承父类后,父类所拥有的属性,子类也能够访问。父类有,子类就有;子类没有的就去父类找,子类有的就用它自己的。
4、派生
有如下两个类:
class Chinese:
star = 'earth' # 两个类共同的属性
nation = 'China'
def __init__(self, name, age, gender): # 两个类共同的属性
self.name = name
self.age = age
self.gender = gender
def speak_chinese(self):
print(f'{self.name}在说普通话')
class American:
star = 'earth'
nation = 'America'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def speak_english(self):
print(f'{self.name}在说英语')
将两个类中共同的属性提取出来,放到一个新的类中,使这两个类继承这个新的类
class Human:
star = 'earth'
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
class Chinese(Human):
nation = 'China'
def speak_chinese(self):
print(f'{self.name}在说普通话')
class American(Human):
nation = 'America' # 子类派生父类中没有的属性
star = 'earthxxx' # 子类派生出与父类同名的属性,子类调用时以子类为准
def speak_english(self):
print(f'{self.name}在说英语')
wy_obj = Chinese('我呀',19,'man')
print(wy_obj.star)
wy_obj.speak_chinese()
print(wy_obj.nation)
# earth
# 我呀在说普通话
# China
派生的第一种情况:子类派生出父类没有的属性。例如上面代码中nation、speak_chinese、speak_english。
派生的第二种情况:子类派生出与父类同名的属性,子类调用时以子类为准。例如American中的star。
派生的第三种情况:子类需要增加一种新的功能,但是这个新的功能并不是完全覆盖父类新的功能,而是把父类的功能拿过来,在它的基础上做一些扩展。(也就是子类重用父类的功能,并在其基础上增减功能)
例如,如果需要在Chinese类实例化对象时,添加一个balance属性,那么可以这样做
class Human:
star = 'earth'
def __init__(self, name, age, gender):
# 不能直接在父类中增加,因为其他子类可能不需要balance这个属性
self.name = name
self.age = age
self.gender = gender
class Chinese(Human):
nation = 'China'
def __init__(self, name, age, gender,balance):
Human.__init__(self,name, age, gender)
# 注意:这里不能使用self.__init__,不然调用的就是Chinese类中的__init__
# 我们需要调用的事父类Human中的__init__
self.balance = balance
def speak_chinese(self):
print(f'{self.name}在说普通话')
obj = Chinese('我呀',19,'man',100)
print(obj.balance)
# 100
5、单继承属性查找
属性查找顺序:对象->类->父类->...->object,再找不到就报错。
单继承属性查找案例:
class Test1:
def f1(self):
print('Test1.f1')
def f2(self):
print('Test1.f2')
self.f1()
class Test2(Test1):
def f1(self):
print('Test2.f1')
obj = Test2()
obj.f2()
# Test1.f2
# Test2.f1
查找过程:
- 执行obj.f2()时,现在obj内找,没有找到f2,然后去类中找,也就是在Test2中找。
- Test2中也没有,去父类Test1中找,找到f2,将obj对象作为参数传给f2。
- 执行f2,打印'Test1.f2',然后执行self.f1(),也就是obj.f1()。
- 先在obj中找,没有,去Test2中找,找到f1,执行f1,打印'Test2.f1'。
如果需要在f2中访问到的是Test1的f1,可以将self.f1()改为Test1.f1(self)。也可以使用隐藏属性的方法实现:
class Test1:
def __f1(self): # _Test1__f1
print('Test1.f1')
def f2(self):
print('Test1.f2')
self.__f1() # _Test1__f1
class Test2(Test1):
def __f1(self): # _Test2__f1
# 这里是f1(self)也不影响
print('Test2.f1')
obj = Test2()
obj.f2()
这是f2中访问的就是_Test1__f1,而不会访问到test2中的_Test2__f1
6、多继承属性查找
菱形继承与MRO
菱形继承:一个类继承了多个父类,而着多个父类有通过一系列的继承关系,最终都继承自一个非object类。
注意:非object类的意思是除object以外的类,它可以是应该继承了object类的类。
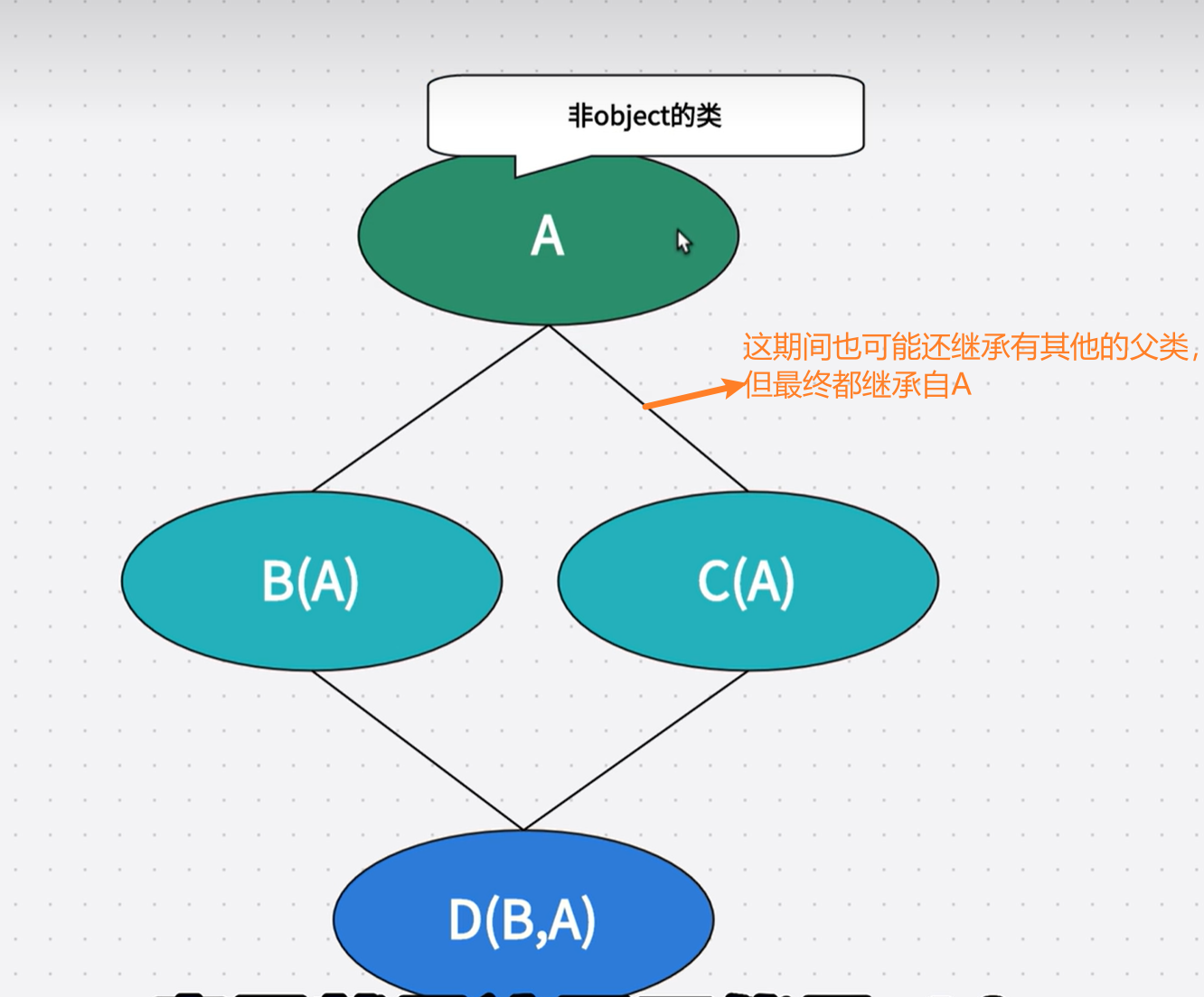
Python中类的属性的查找顺顺序是根据类的MRO列表来进行查找的,每个类都有一个MRO列表(仅限于新式类)。
MRO列表是通过C3算法实现的。
# 类的关系与上图中对应
class A:
def f1(self):
print('A.f1')
class B(A):
def f1(self):
print('B.f1')
class C(A):
def f1(self):
print('C.f1')
class D(B, C): # 如果B,C互换位置,那就是先找C再找B
def f2(self):
print('D.f2')
print(D.mro())
# [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
obj = D()
obj.f1()
当使用对象访问属性时,会先在对象中查找,然后再到对象的类中查找,之后便是根据该类的MRO列表的顺序进行查找。
例如,上面的代码中,先在obj中f1,找不到;再去D中找,找不到;然后按照D的MRO列表依次在B,C,A,object中找,最后都找不到就报错。
如果使用类访问属性,那么就直接按照该类的MRO列表的顺序来查找。
非菱形继承的属性查找顺序
对于非菱形继承来说,经典类和新式类的查找顺序都是一样的,区别在于新式类最后会在object中查找。
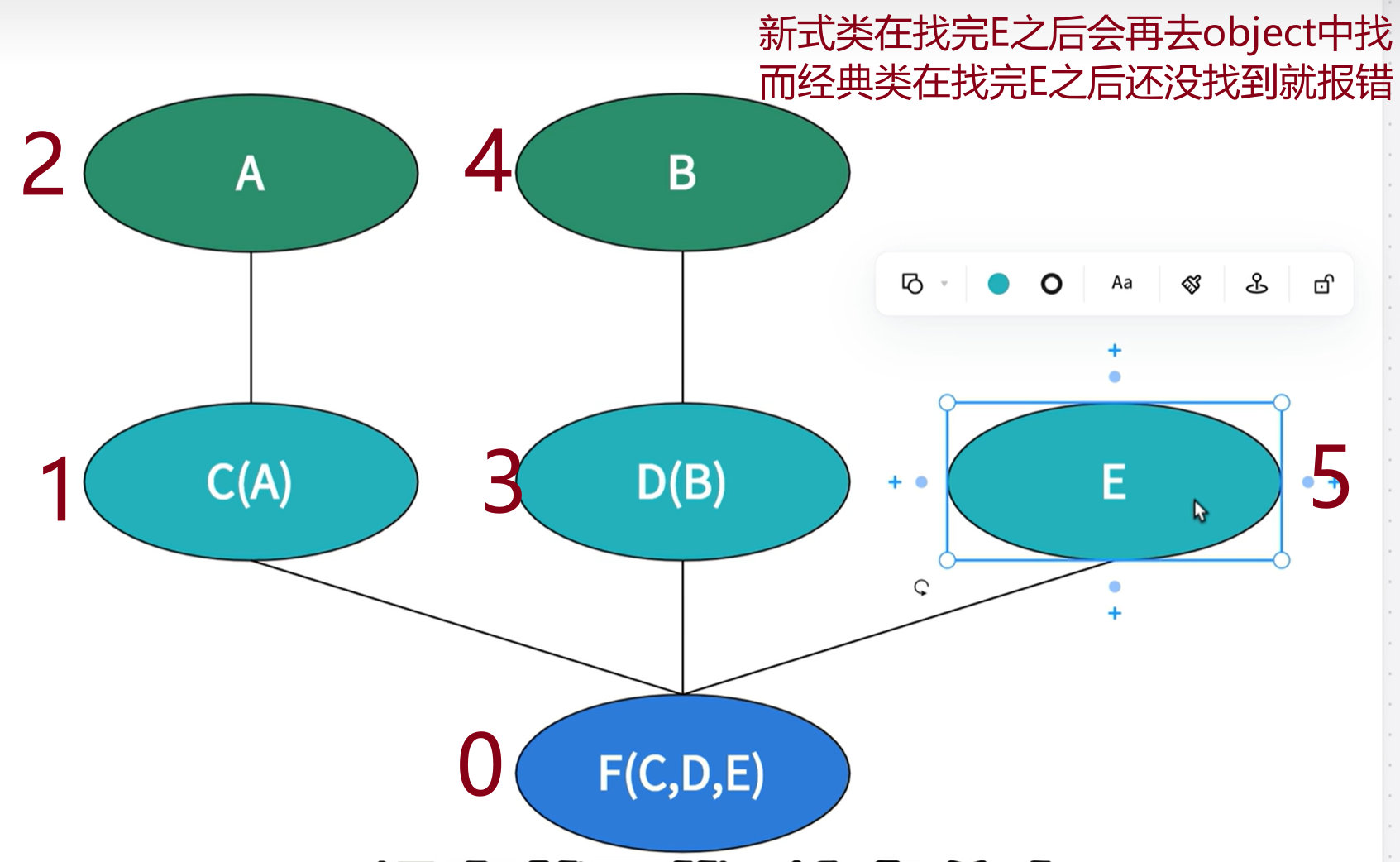
# 非菱形继承
class A:
def f1(self):
print('A.f1')
class B:
def f1(self):
print('B.f1')
class C(A):
def f1(self):
print('C.f1')
class D(B):
def f1(self):
print('D.f1')
class E:
def f1(self):
print('E.f1')
class F(C, D, E):
def f1(self):
print('F.f2')
print(F.mro())
# [<class '__main__.F'>, <class '__main__.C'>, <class '__main__.A'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class 'object'>]
obj = F()
obj.f1()
菱形继承的属性查找顺序
经典类:深度优先查找。找第一条分支时就要找共同的父类。
新式类:广度优先查找,找最后一条分支时才找共同的父类。
注意:这里的官渡优先与数据结构中有些区别。
经典类,由于Python3中的类都是新式类,所以只有在python2中才能检验经典类的代码。
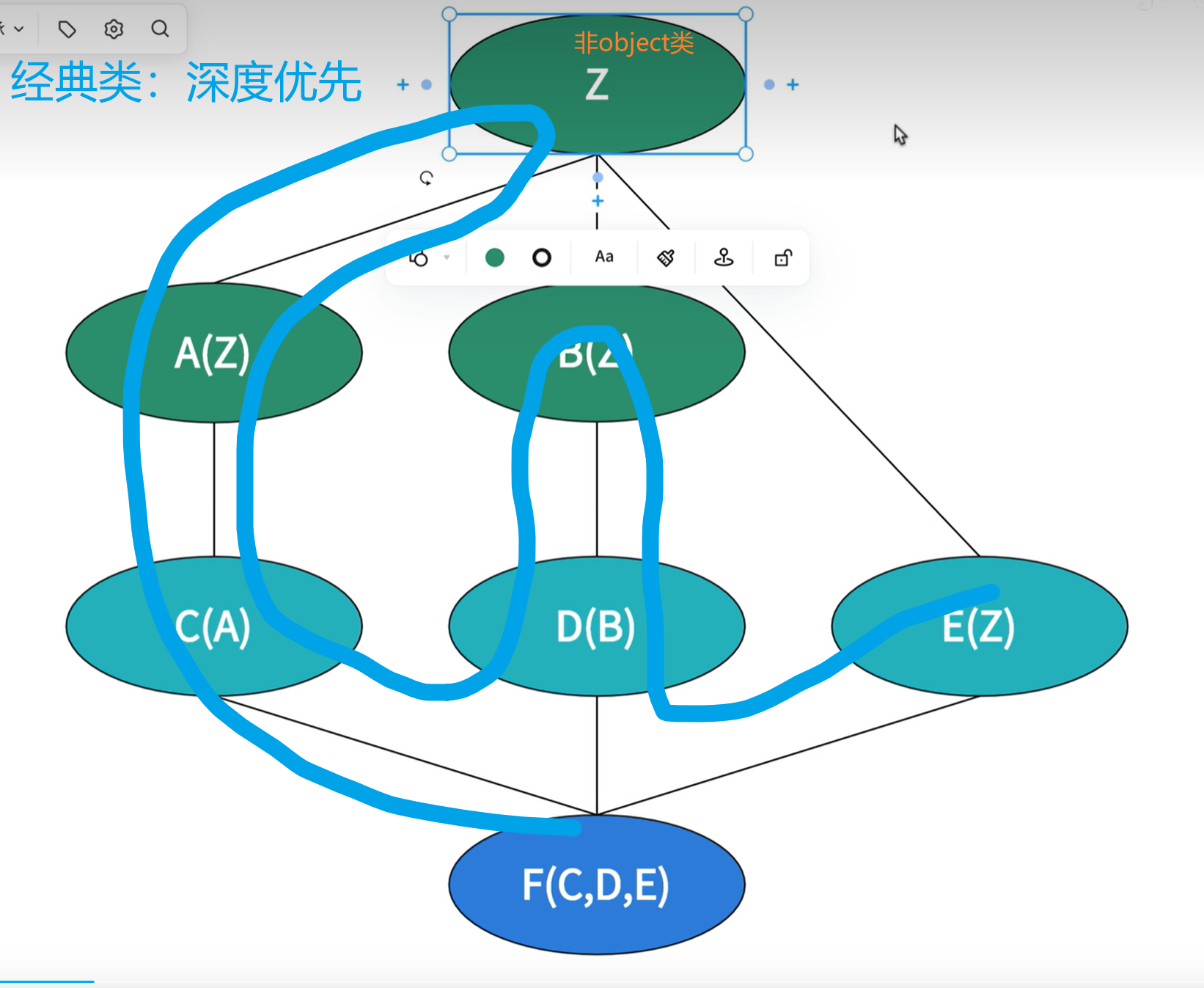
新式类
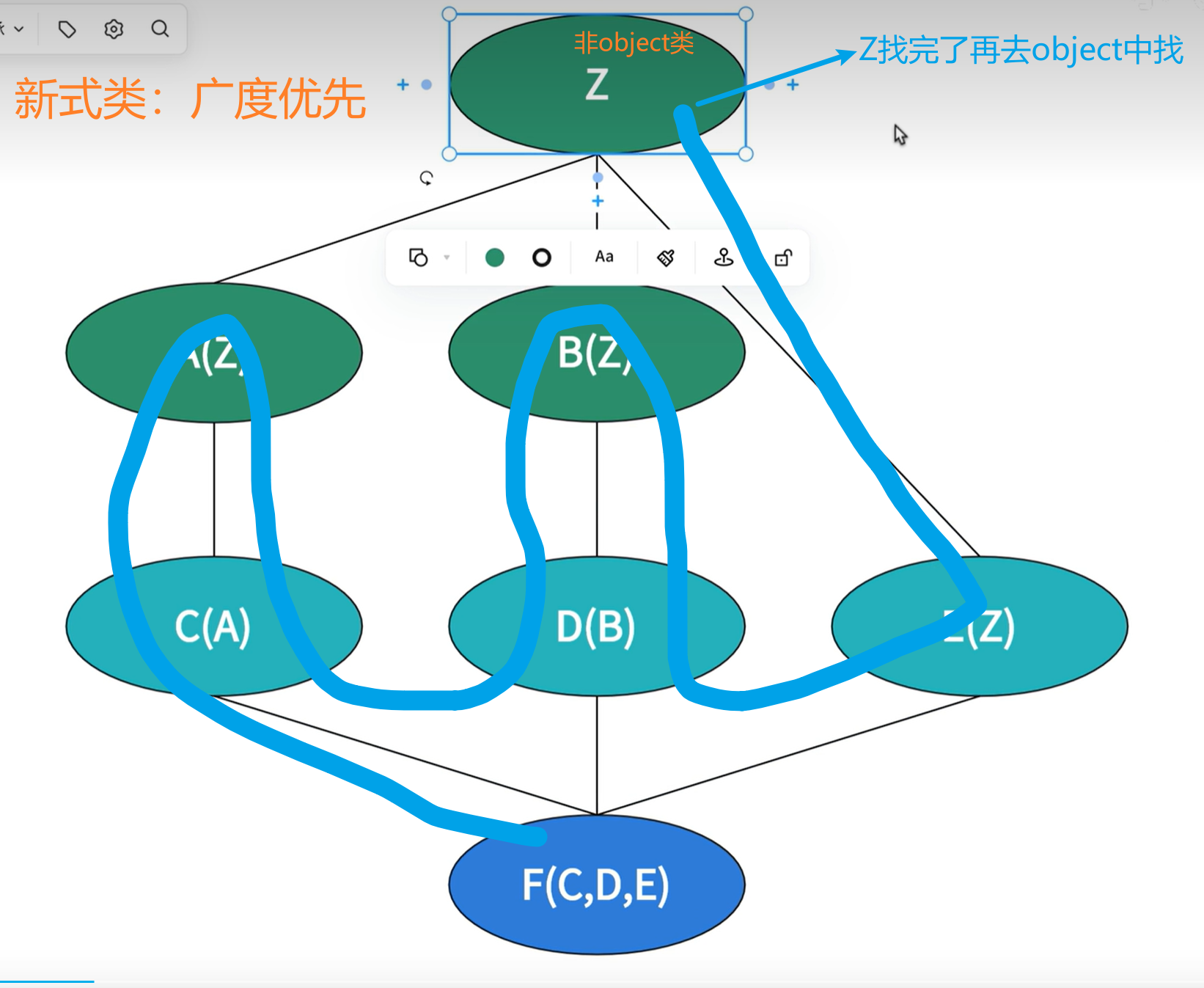
# 菱形查找,与上图相对应
class Z:
def f1(self):
print('Z.f1')
class A(Z):
def f1(self):
print('A.f1')
class B(Z):
def f1(self):
print('B.f1')
class C(A):
def f1(self):
print('C.f1')
class D(B):
def f1(self):
print('D.f1')
class E(Z):
def f1(self):
print('E.f1')
class F(C, D, E):
def f1(self):
print('F.f2')
print(F.mro())
# [<class '__main__.F'>, <class '__main__.C'>, <class '__main__.A'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.Z'>, <class 'object'>]
# 该结果为python3中的新式类的结果,python2中经典类没有MRO。
obj = F()
obj.f1()
# 如果需要验证经典类,需要使用python2解释器来运行
7、MixIns机制
MixIns机制实际上就是一种命名规范,目的是为了使代码在语义层面上满足“什么是什么的关系”,也称为“is-a”关系。
多继承违背了人类的思维习惯,在人类的思维习惯中,继承应该表示“什么是什么”的关系,比如鸡鸭鹅,它们都可以继承家禽这个类,我们可以说它们都是家禽。但如果它们有继承了其他类,那我们说他们“是“什么就不太准确了。
在使用多继承时,应该规避一下两点问题:
- 继承结构不要太复杂,也就是继承的层级不要太多。
- 要满足什么“是”什么的关系。
为了使多继承能够满足什么“是”什么的关系,可以通过MixIns机制来实现:
MixIns机制
MixIn able ible
class Fowl: # 家禽类
pass
class SwimMixIn:
def swimming(self):
pass
class Chicken(Fowl): # 鸡
pass
class Duck(SwimMixIn, Fowl): # 鸭 # 表达“是”的关系的Fowl类要放到最后
pass
class Goose(SwimMixIn, Fowl): # 鹅
pass
在上面的代码中,鸡鸭鹅都是家禽,他们都继承Fowl类,表达的是“什么是什么”的关系。而游泳只是鸭和鹅所具备的某种功能,也就类似于一个增加某种功能的插件。
我们在Swin后加上后缀MixIn,用来表示SwimMixIn这个类只是为了给其子类混入一些工能的,而不是表达“是”的关系,这样,当我们阅读代码时,就能够清楚的知道某个类的“是”的关系。
MixIns并不会对代码逻辑产生影响,SwimMixIn类仍然是鸭和鹅的父类,与没加MixIns之前是完全相同的。只是能够然我们在阅读代码时能够更容易理清类之间的关系。
MixIns需要注意的点:
- MixIns类必须表示为一种功能(类似于插件),而用来表达“是”这种关系的类,才能是一种事物(如家禽)。
- MixIns类一般以MixIn、able、ible作为后缀。
- MixIns的责任必须单一,也就是一种MixIns类表示一种功能。
- MixIns类中的功能不能依赖于他的子类。比如SwimMixIn中功能的实现不能去调用(依赖)Duck或Goose中的功能。
- 使用MixIns机制实现多继承时,一个子类可以继承多个MixIns类,但是表达“是”的关系的类一定要放到最后,而且只能继承一个。不建议继承太多的MixIns,会使代码可读性变差。
8、super
下面的代码是在讲派生的第三种情况,为子类增加新的功能时的实现方案。这种方案没有依赖继承关系。
class Human:
star = 'earth'
def __init__(self, name, age, gender):
# 不能直接在父类中增加,因为其他子类可能不需要balance这个属性
self.name = name
self.age = age
self.gender = gender
class Chinese(Human):
nation = 'China'
def __init__(self, name, age, gender,balance):
Human.__init__(self,name, age, gender)
# 注意:这里不能使用self.__init__,不然调用的就是Chinese类中的__init__
# 我们需要调用的事父类Human中的__init__
self.balance = balance
def speak_chinese(self):
print(f'{self.name}在说普通话')
现在我们可以使用super功能来实现,super是基于继承关系来实现的,推荐使用。
class Human:
star = 'earth'
def __init__(self, name, age, gender):
# 不能直接在父类中增加,因为其他子类可能不需要balance这个属性
self.name = name
self.age = age
self.gender = gender
class Chinese(Human):
nation = 'China'
def __init__(self, name, age, gender,balance):
# Human.__init__(self,name, age, gender)
# super(Chinese,self).__init__(name, age, gender) # python2中必须这么用
super().__init__(name, age, gender) # python3中两个参数可以省略
self.balance = balance
def speak_chinese(self):
print(f'{self.name}在说普通话')
print(Chinese.mro())
# [<class '__main__.Chinese'>, <class '__main__.Human'>, <class 'object'>]
obj = Chinese('我呀',19,'man',100)
print(obj.__dict__)
super会参照self所属类的MRO列表,从当前所在的类的下一个类开始找属性。super只能用在新式类中。
例如,上面的代码中self(也就是obj)所属的类类Chinese,而super当前所在的类也刚好是Chinese,在Chinese的mro列表中,Chinese的下一个类时Human,所以会从Human中开始找属性。
注意:当前所在的下一个类不一定就是对象所属类的父类。举例如下:
class A:
def f1(self):
print('A.f1')
super().f1() # 这里找到的f1是B中的f1
class B:
def f1(self):
print('B.f1')
class C(A, B):
pass
obj = C()
obj.f1()
print(C.mro())
# A.f1
# B.f1
# [<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
四、多态
多态是一种编程思想,多态性是指在不考虑对象具体类型的情况下,而直接使用对象。
# 多态
# 汽车:奔驰、理想、奥拓
class Car:
def run(self):
print('开始跑', end=' ')
class Benz(Car):
def run(self):
super().run()
print('加98号汽油') # 在父类的基础上扩展一下自己不一样的地方
class Lx(Car):
def run(self):
super().run()
print('充电')
class Auto(Car):
def run(self):
super().run()
print('加92号汽油')
car1 = Benz() # 奔驰
car2 = Lx() # 理想
car3 = Auto() # 奥拓
# 三者都是汽车,都能“跑”。
# 三者都是汽车类,汽车类下有run方法,无论它们自己有没有run方法,最终都可以找到run方法。
car1.run()
car2.run()
car3.run()
def drive_car(car): # 这个函数相当于一个统一的接口
car.run()
# 统一了使用标准,无论对象怎么变,使用者都是用同一种方法去调用
drive_car(car1) # 要使用run功能,只需将对象传给接口即可
drive_car(car2)
drive_car(car3)
多态概念举例,len()方法
len方法可以统计字符串、列表、字典等类型的长度,实际上是调用了这些类型下的__len__()方法,
# len()
# 字符串、列表、字典下都有__len__()方法,用于统计其长度
# len()方法就是基于这个特性(多态),调用这些类型的__len()__方法,从而获取到长度
print('aba'.__len__())
print([1,2,3].__len__())
print({'a':1,'b':2}.__len__())
# 我们可以写一个len方法
def my_len(obj):
return obj.__len__()
# 这样,无论是什么类型的数据,我们都可以通过len这个统一的接口来获取它的长度
print(my_len('aba'))
print(my_len([1,2,3]))
print(my_len({'a':1,'b':2}))
鸭子类型
上面的多态介绍,多态是按照继承的方式来使用的,但对于Python来说,在使用多态时,可以不依赖于继承,只需要在定义时按照规范来命名即可。这就是鸭子类型。
例如,在Linux中,一切皆文件,就是使用了这种统一的思想。
# 鸭子类型
# linux:一切皆文件
class Disk: # 磁盘
# 磁盘与内存都不是文件,但是我们可以定义一个文件的读和写操作,
# 这样使磁盘和内存看起来像文件,当使用某个对象时,不需要考虑他是哪一种类型,都可直接对它进行read和write操作。
def read(self):
print('Disk.read')
def write(self):
print('Disk.write')
class Memory: # 内存
def read(self):
print('Memory.read')
def write(self):
print('Memory.write')
class Txt:
def read(self):
print('Txt.read')
def write(self):
print('Txt.write')
Python鸭子类型的思想是:不使用一个共同的父类去限制子类,而是将这些毫无相关性的子类做的像一点就行了(就像上面的例子中,每个类都有read和write方法)。
抽象基类
抽象基类可以让父类来规范子类,所有继承抽象基类的子类,必须定义父类规定的方法。例如下面的例子,强制让子类自行实现run方法。
注意:抽象基类不可以用于实例化对象。
# 抽象基类
import abc
class Car(metaclass=abc.ABCMeta): # 将父类作为一个抽象基类
@abc.abstractmethod
def run(self): # 给父类中的run方法加上装饰器后,子类就必须自己定义一个run方法,如果没有,就会报错
pass
class Benz(Car):
pass # 子类中没有run方法
# car1 = Benz()
# 报错TypeError: Can't instantiate abstract class Benz with abstract method run
class Lx(Car):
def run(self):
pass
class Auto(Car):
def run(self):
pass
# car1 = Benz()
car2 = Lx()
car3 = Auto()
car1.run()
car2.run()
car3.run()
# 注意:抽象基类不能实例化对象
a = Car()
# TypeError: Can't instantiate abstract class Car with abstract method run
五、绑定方法与非绑定方法
回顾一下绑定方法是什么,在类中定义函数时,Python会自动将调用该方法的对象作为函数的第一个参数传给函数,这时这个方法就叫对象的绑定方法。
class Mysql:
def __init__(self, ip, port):
self.ip = ip
self.port = port
def f1(self): # 对象作为第一个参数传进来
print(self.ip, self.port) # 函数需要用到对象,所以该方法就应该绑定给对象,将对象传进来。
obj = Mysql('127.0.0.1',3306) # 实例化对象
print(obj.f1) # 打印f1的地址
# <bound method Mysql.f1 of <__main__.Mysql object at 0x000001B47A89A8F0>>
# bound method表示绑定方法,f1绑定给了Mysql下的对象
绑定给对象的方法叫绑定方法,在使用时会自动把类传进去,绑定给类使用的方法叫类方法,使用时会自动将类传进去。
静态方法,就是类下面的普通函数,调用时与普通函数一样,不会将对象或者类传进去。
# 需求:从配置文件settings中获取IP和端口
import settings
class Mysql:
def __init__(self, ip, port):
self.ip = ip
self.port = port
def f1(self): # 绑定方法
print(self.ip, self.port)
@staticmethod # 静态方法,不会自动传入类或对象
def f2():
print('嘿嘿嘿')
@classmethod # 类方法
def instance_from_conf(cls): # 类方法的第一个参数一般用cls来命名
print(cls)
obj1 = cls(settings.IP, settings.PORT) # 这个函数的作用是通过cls类来实例化对象,并返回对象。
return obj1
obj = Mysql.instance_from_conf()
print(obj.f1)
print(obj.f2)
print(Mysql.f2)
print(Mysql.instance_from_conf)
# <bound method Mysql.f1 of <__main__.Mysql object at 0x00000229B5C4FDF0>> # 绑定方法(绑定给对象)
# <function Mysql.f2 at 0x00000229B5C571C0> # 普通函数
# <function Mysql.f2 at 0x00000229B5C571C0> # 无论是通过类或对象调用,它都是普通函数
# <bound method Mysql.instance_from_conf of <class '__main__.Mysql'>> # 类方法
六、反射机制
反射机制指的是:在程序运行过程中动态获取对象信息,以及动态调用对象方法的功能。
为什么要有反射?
举例如下:
我们定义一个函数f,它接收一个对象,函数内部需要使用该对象的一些属性(例如age属性),但又不知道对象是否有这个属性。为了保证程序在运行时不报错,我们可以在前面加一个判断,通过调用对象的__dict__属性来判断对象是否有age属性。
def f(obj):
if 'age' not in obj.__dict__: # 判断对象是否有age属性
return # 没有属性就正常退出
# 但并非所有的对象都允许调用__dict__属性,例如19
# AttributeError: 'int' object has no attribute '__dict__'. Did you mean: '__dir__'?
print(obj.age)
f(19)
这个思路是么什么问题的,但是,并不是所有的对象都允许调用__dict__属性,所以我们需要使用另一种方法来获取对象的信息。
下面介绍Python中实现反射机制的方法。
我们可以使用一个内置函数dir来获取到对象的列表,列表中的元素是对象的属性名,但是它是字符串类型的,不能调用,也就是不能“点”这个字符串。
class Human:
def __init__(self,name,age):
self.name = name
self.age = age
def info(self):
print('name:',self.name,'age:',self.age)
obj = Human('创',19)
print(dir(obj))
# ['__class__', '__delattr__', '__dict__', '__dir__','age', 'info', 'name'] # 太多了,只复制了一部分
print(dir(obj)[-1]) # name
# obj.dir(obj)[-1] # dir(obj)[-1]是字符串类型,不能点它
Python提供了四个内置函数:hasattr,getattr,setattr,delattr下面来讲述它们的作用。
hasattr用于判断对象是否有某个属性
print(hasattr(obj, 'name')) # Ture
print(hasattr(obj, 'x')) # False
getattr用于获取对象的属性
print(getattr(obj, 'name'))
print(getattr(obj, 'x','没有这个属性')) # 如果对象没有这个属性,就会返回第三个参数
# 如果对象没有属性,第三个参数为空的话会报错
setattr用于给属性赋值
setattr(obj,'age',18) # 将age值更改为18
print(obj.age)
delattr用于删除属性
# delattr(obj,'info') # 好像只能删属性,不能删方法
delattr(obj,'age') # 删除age属性
print(obj.__dict__) # {'name': '创'}
反射的作用就是在不知道对象是什么的情况下,能够动态的分析出来对象有哪些属性和方法,或者说是,在不知道使用者会调用对象的什么属性的情况下,让程序动态的分析出来调用到功能到底有没有,有就调用,没有就跳过。所以说,反射是一种程序动态分析的能力。
反射案例
class Ftp:
def put(self):
print('正在上传数据。。。')
def get(self):
print('正在下载数据。。。')
def interact(self):
opt = input('>>>')
getattr(self, opt, self.warning)() # 功能不存在时返回self.warning的地址,地址后面跟括号()就是对这个函数的调用
def warning(self):
print('功能不存在!')
obj = Ftp()
obj.interact()
七、内置方法
类的内置方法就是,定义在类里面,以__开头和__结尾的方法,这些内置方法的特点是,会在满足条件时自动执行。其作用就是为了定制化对象或类,比如构造方法__init__,会在实例化对象时自动执行,给对象定制独有的属性。
1、__str__
在打印对象时自动执行,返回一个字符串类型的值,打印的就是返回的字符串。
class Human:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
print('123') # 打印对象时会自动执行str下的方法
return f'<{self.name}: {self.age}>' # 打印的就是这返回的字符串,可以自定义。
obj = Human('张大仙', 73)
print(obj.__str__())
print(obj) # <张大仙:73>
2、__del__
__del__会在删除对象之前自动执行。
# 2、__del__
class Human:
def __init__(self, name, age):
self.name = name
self.age = age
def __del__(self):
print('__del__执行了')
self.f.close() # 比如类中的某个方法打开了一个文件,在程序执行完后,就告诉操作系统,让它把这个文件关闭
del obj # 删除obj时,会先执行__del__方法
# 如果没有手动删除对象,那么在程序运行完后,释放资源时也会执行__del__方法。
__del__的作用:
当对象中的某个属性使用了操作系统中的资源(比如打开文件,或发起网络连接),当程序执行完毕后,Python只会释放python程序所占用的资源,而不会去释放操作系统的资源。此时,就需要通过__del__方法,来告知(并不是由python释放)操作系统,将程序所占用的资源释放。
八、元类
Python中一切皆对象,类也是对象。类也是通过某个类实例化产生的。
元类就是实例化产生类的类。元类-->实例化-->类-->实例化-->对象
用class这个关键字定义的所有类,以及python内置的类,都是通过type这个类实例化产生的。
class Human():
pass
print(Human) # <class '__main__.Human'>
print(type(Human)) # <class 'type'>
print(type(int)) # <class 'type'>
1、分析class的底层逻辑
# 分析class的底层逻辑
# 1、类名
class_name = 'Human'
# 2、基类
class_bases = (object,) # 元组中是要继承的父类
# 3、执行类子代码,产生名称空间
class_dic = {} # 这个字典与__dict__一样,存放属性及其内存地址。
class_body = '''
def __init__(self, name, age):
self.name = name
self.age = age
def info(self):
print('name:', self.name, 'age:', self.age)
'''
exec(class_body, {}, class_dic)
# 第二个参数是一个字典,如果class_body中的子代码使用到了全局名称空间的变量,就需要通过这个字典将变量传入
# 第三个参数,将子代码执行时产生的名字放到第三个参数class_dic中。
print(class_dic) # {'__init__': <function __init__ at 0x0000016CA810F2E0>, 'info': <function info at 0x0000016CA810EC20>}
# 4、调用元类
# 如果没有指定元类,class默认使用的就是type类。
Human = type(class_name, class_bases, class_dic)
# 通过调用元类得到了一个类Human。注:Human只是一个名称而已,真正的类是它指向的内存地址,也就是元类type返回的值。
# print(Human)
obj = Human('张大仙', 73)
obj.info() # name: 张大仙 age: 73
2、自定义元类
类实例化的过程
Human = Mytype(class_name, class_bases, class_dic) # Mytype是自定义的元类
# 括号中三个参数的含义分别是类名,基类,类的名称空间。
1、调用Mytype的__new__方法,产生一个空对象Human
2、调用Mytype的init方法,初始化对象Human(初始化对象时,会将这三个参数传入class_name, class_bases, class_dic)
3、返回初始化好的对象Human
实现自定义元类的代码如下:
# Mytype是自定义的元类
class Mytype(type): # 只有继承了type的类才是元类
# 元类的__init__方法用于初始化对象(也就是基于元类创建的类)
def __init__(self, class_name, class_bases, class_dic):
# 初始化对象Human时,会将这三个参数也传入class_name, class_bases, class_dic
print('Mytype.__init__')
class Human(object,metaclass=Mytype): # 使用自定义元类Mytype创建类Human
# metaclass需要写在最后,其前面是是继承的其他父类(比如object)
# metaclass用于指定继承的元类,默认为type
def __init__(self, name, age):
self.name = name
self.age = age
raise关键字
程序执行到raise时就会直接报错,抛出报错信息,不再往下执行。
# raise关键字
raise NameError('类名不能有下划线') # 也可以是TypeError或者其他的
# 报错信息如下:
"""
Traceback (most recent call last):
File "F:\MyCode\Python_Study\进阶篇\06-元类.py", line 73, in <module>
raise NameError('类名不能有下划线')
NameError: 类名不能有下划线
"""
__init__初始化对象
通过编写自定义元类中__init__的子代码,实现定义类时类名不能有下划线,且必须写文档注释。代码如下:
# 自定义元类
class Mytype(type):
def __init__(self,class_name,class_bases,class_dic):
if '_' in class_name:
raise NameError('类名不能有下划线')
# if not self.__doc__: # 这样应该也可以吧?
if not class_dic.get('__doc__'):
# class_dic是一个字典,使用get功能获取key对应的值,key不存在则返回None
raise SyntaxError('必须写文档注释')
class Human(metaclass=Mytype):
# """
# 这是Human
# """
def __init__(self,name,age):
self.name = name
self.age = age
不符合规范时,报错信息如下:
"""
Traceback (most recent call last):
File "F:\MyCode\Python_Study\进阶篇\06-元类.py", line 96, in <module>
class Hu_man(metaclass=Mytype):
File "F:\MyCode\Python_Study\进阶篇\06-元类.py", line 88, in __init__
raise NameError('类名不能有下划线')
NameError: 类名不能有下划线
或
Traceback (most recent call last):
File "F:\MyCode\Python_Study\进阶篇\06-元类.py", line 96, in <module>
class Human(metaclass=Mytype):
File "F:\MyCode\Python_Study\进阶篇\06-元类.py", line 93, in __init__
raise SyntaxError('必须写文档注释')
SyntaxError: 必须写文档注释
"""
__new__创建空对象
__new__方法是在调用类的第一个被执行的方法,它的作用是创造一个空对象。
class Mytype(type):
def __init__(self, class_name, class_bases, class_dic):
print('Mytype.__init__') # __init__并没有被执行
# 因为__new__返回值为空,空对象没有造出来,自然也就不执行__init__
def __new__(cls, *args, **kwargs):
print('Mytype.__new__') # Mytype.__new__
class Human(object, metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
查看__new__方法的参数的含义
# 查看__new__的参数的含义
class Mytype(type):
def __init__(self, class_name, class_bases, class_dic):
print('Mytype.__init__')
def __new__(cls, *args, **kwargs):
print('Mytype.__new__') # Mytype.__new__
# cls就是Mytype
print(cls) # <class '__main__.Mytype'>
# *args就是class机制第四部传进来的参数class_name, class_bases, class_dic
print(*args) # Human (<class 'object'>,) {'__module__': '__main__', '__qualname__': 'Human', '__init__': <function Human.__init__ at 0x000002DB2405EA70>}
# 类名:Human 基类:object 名称空间:字典里的内容。
print(**kwargs) # 空
class Human(object, metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
重写__new__方法
# 重写__new__方法
class Mytype(type):
def __init__(self, class_name, class_bases, class_dic):
print('Mytype.__init__')
def __new__(cls, *args, **kwargs):
# __new__的功能是用来造新对象(比如下面的Human类)的。
# 我们目前并没有什么功能可以造空对象,
# 可以调用Mytype的父类(type)的功能来造空对象
# super().__new__(cls, *args, **kwargs) # cls也要传,在这里它不会自动传参
# type.__new__(cls, *args, **kwargs) # 两种方法都可以
return type.__new__(cls, *args, **kwargs) # 将造好的对象返回
class Human(object, metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
__call__对象加括号调用时,被调用的方法
对象加括号调用
class Test():
def __init__(self,name,age):
self.name = name
self.age = age
obj = Test('创',19)
obj()
# Test中没有__call__方法时,不可调用
# TypeError: 'Test' object is not callable
__call__方法会在对象加括号调用时触发
# __call__方法会在对象加括号调用时触发
class Test():
def __init__(self,name,age):
self.name = name
self.age = age
def __call__(self, *args, **kwargs):
print('Test.__call__')
return 'abd'
obj = Test('创',19)
obj()
# obj()等价于obj.__call__(),与__str__()方法类似,
# __str__方法是在打印时触发,__call__是在对象被调用时时触发。
res = obj(1,23,a=666) # 调用时也可以传参
print(res) # 返回值是__call__的返回值。
如果想把一个对象做成一个可加括号调用的对象,就在对象的类里面加一个__call__方法。
问题:obj调用时Test中没有__call__方法,就报错,它为什么不去Test的父类type找?
Human调用时,Mytype中没有call,它为什么不报错,说是去type里找?
答:可能是因为Test的父类是object,而object中没有__call__方法吧。
print(type(Test)) # <class 'type'> print(Test.__base__) # 父类<class 'object'> # print(Mytype.__base__) # 父类<class 'type'> print(object.__base__) # None print('__call__' in type.__dict__) # True print('__call__' in object.__dict__) # False
注意:要区分“类”与“类型”。不是继承了谁,他的类型就是谁。举例如下:
class Test():
pass
print(Test.__base__) # 父类<class 'object'>
print(type(Test)) # 类型<class 'type'>
class Mytype(type): # 元类比较特殊
pass
print(Mytype.__base__) # 父类<class 'type'>
print(type(Mytype)) # 类型<class 'type'>
所有的类往深了分析,其实都是由内置元类type造出来的。
call方法分析
先回顾一下,class的机制:
1、产生类名class_name
2、产生基类clas_bases
3、产生名称空间class_dic
4、调用元类Human = type(class_name, class_bases, class_dic)
再回顾类实例化(造对象)的过程:
1、调用类的__new__方法,产生一个空对象Human
2、调用类的__init__方法,初始化对象Human
3、返回初始化好的对象Human
现在将实例化的这三个步骤与call方法联系起来:
Human = Mytype(class_name, class_bases, class_dic) # 使用自定义元类造对象(造类)
Mytype加括号调用时,调用了内置元类type的__call__(因为Mytype中没有,所以去其父类type中找),再type的call方法下,执行了下面三步:
# 1、调用Mytype的__new__方法,产生一个空对象Human
# 2、调用Mytype的__init__方法,初始化对象Human
# 3、返回初始化好的对象Human
各对象加括号调用时触发的call方法:
对象() --> 类内部的__call__
类() --> 自定义元类内部的__call__,当然,如果类使用的元类是内置类type,触发的自然也是type的call
自定义元类() ---> 内置元类type的__call__
自定义call方法
现在我们就知道了,在下面的代码中,使用Human实例化对象时,触发的就是其使用的自定义元类Mytype的call、
class Mytype(type):
def __call__(self, *args, **kwargs): # 思考:如果我不写call,它也能实例化对象,应该是调用了type的call,参数是怎么传递的呢?
return 'abc'
class Human(metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
obj = Human('创',19) # Human加括号调用,触发元类Mytype
print(obj) # abc
那么正常情况下,Human实例化对象时,Mytype里的call到底做了什么呢?
触发Mytype的__call__方法
# 1、调用Human的__new__方法
# 2、调用Human的__init__方法
# 3、返回初始化好的对象
为什么是Human的new和init方法?因为Human作为第一个参数self自动传入call。
class Mytype(type):
def __call__(self, *args, **kwargs): # 这里的参数就是实例化obj时Human的参数
print(self) # <class '__main__.Human'>
print(args) # ('创', 19)
print(kwargs) # {}
class Human(metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
obj = Human('创',19)
现在我们就可以自己来实现call方法了:
# 自定义call方法
class Mytype(type):
def __call__(self, *args, **kwargs):
# 1、调用Human的__new__方法
# 注意,self参数也要传。因为我们现在是通过类来它自己的方法,只有通过对象调用类的方法的时候,才会把对象作为第一个参数自动传入。
Human_obj = self.__new__(self)
# 2、调用Human的__init__方法
self.__init__(Human_obj, *args, **kwargs) # 把空对象以及初始化对象的参数传入
# __init__执行完后,对象就初始化好了。下面可以做一些定制化操作。
# 定制化:比如,给对象的每个属性名,前面都加上“H_”
dic = {}
for key in Human_obj.__dict__:
dic[f'H_{key}'] = Human_obj.__dict__[key]
Human_obj.__dict__ = dic
# 注意,不要习惯性的使用self,现在的self是Human,Human_obj才是实例化后的对象obj
# 3、返回初始化好的对象
return Human_obj
class Human(metaclass=Mytype):
def __init__(self, name, age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
# 通过调用Human的父类的new方法来造一个空的Human对象
obj = super().__new__(cls) # 这里只需造一个空对象就行,其他参数就不用传了。
# 这里也可以写一些定制化操作
return obj
obj = Human('创',19)
print(obj.__dict__) # {'H_name': '创', 'H_age': 19}
通过上面的分析,我们可以知道,有三个地方可以定制化对象的属性。比如定制化obj的属性,可以在Human的new和init里,还可以在元类Mytype的call里进行修改。
如果Human里也有一个call方法,那么这个call方法,只有在Human的对象obj加括号调用时才会触发:
class Human():
def __call__(self, *args, **kwargs):
print(f'你调用了{self}')
obj = Human()
obj() # 你调用了<__main__.Human object at 0x000001FC6705BAC0>
3、属性查找
通过对象找属性,依照对象=》类=》父类=》object的顺序,不会去元类里找
通过类找属性,类=》父类=》object,找不到去元类找
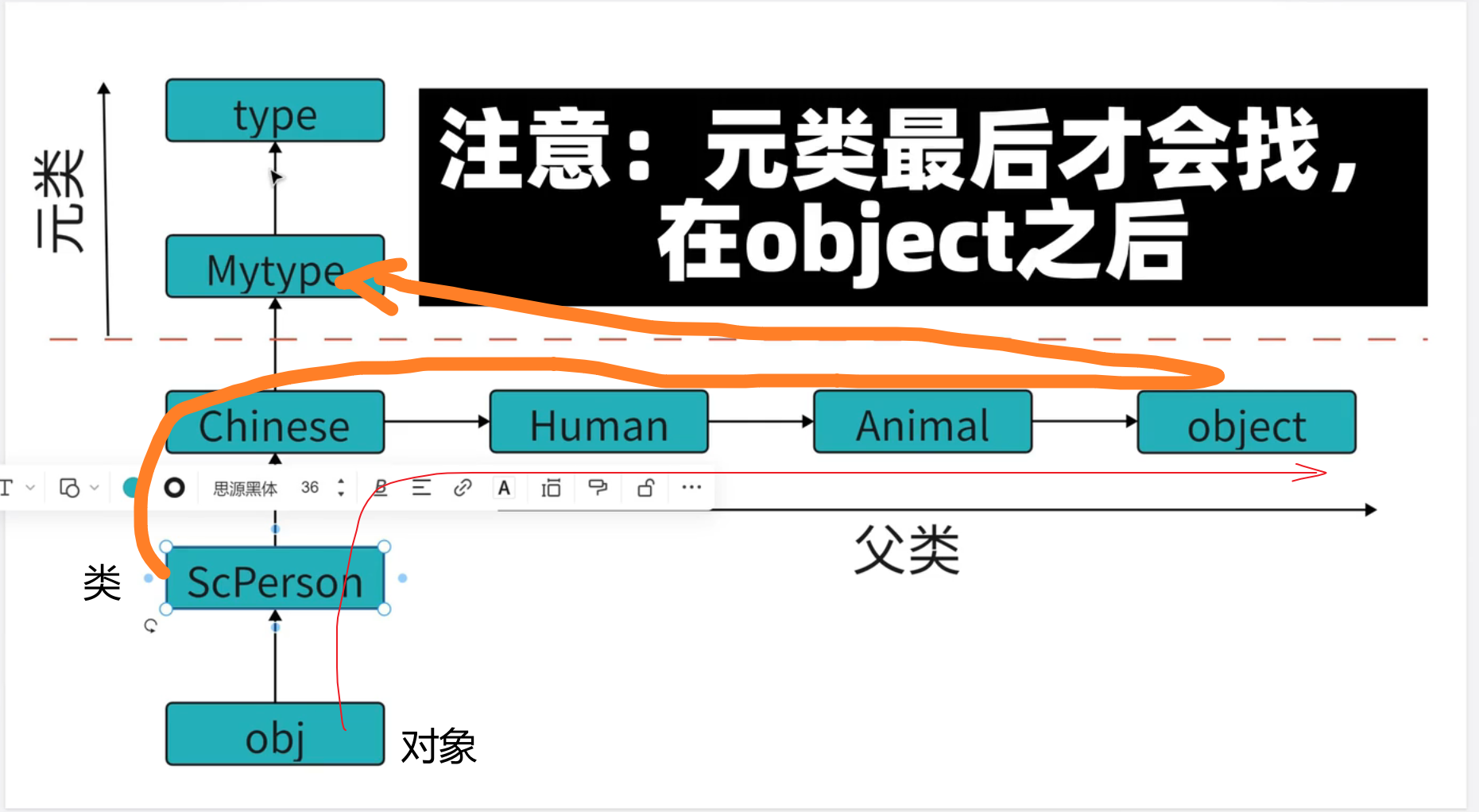
猜测:Mytype也没有,可能还会去type里面找吧。
下面是与上图关系对应的代码:
# 属性查找
# 对象=》类=》父类=》object
class Mytype(type):
age = 18
def __call__(self, *args, **kwargs):
# ScPerson调用的,self就是ScPerson
# print(object.__new__ is self.__new__) # Ture
obj = self.__new__(self) # 在这个代码中,ScPerson找到的__new__方法是在object中找到的
# self查找__new__的顺序为ScPerson-》Chinese-》Human-》Animal-》object,object找到了,就不去元类找了。
self.__init__(obj, *args, **kwargs)
return obj
class Animal(object):
age = 17
pass
class Human(Animal):
age = 16
pass
class Chinese(Human, metaclass=Mytype):
age = 15
pass
class ScPerson(Chinese):
age = 14
pass
obj = ScPerson() # 此时触发的是Mytype中的call
# 通过对象找属性,依照对象=》类=》父类=》object的顺序,不会去元类里找
print(obj.age)
# 通过类找属性,类=》父类=》object,找不到去元类找
print(ScPerson.age)
# 只要父类使用了元类,它的子类都会使用这个元类
print(type(ScPerson)) # <class '__main__.Mytype'>
print(type(Human)) # <class 'type'>
九、单例模式
单例模式的目的是为了保证某一个类只能有一个实例化对象存在。单例模式可以保证内存中只有一个实例化对象,优化了内存资源。
实现单例模式的方法有六种:模块、类装饰器、类绑定方法、__new__方法、元类、并发。
1、模块
在模块中实例化对象,使用时,将实例化的对象以模块的方式导入。
模块内容如下:
# 模块名:魔铠实现单例模式
class Human():
def __init__(self,name,age):
self.name = name
self.age = age
obj = Human('创',19) # 在模块中创还能对象
使用对象时,将对象导入即可:
from 模块实现单例模式 import obj
print(obj)
# <模块实现单例模式.Human object at 0x000001F1B3B7E110>
from 模块实现单例模式 import obj
print(obj) # 即使再次导入,使用的还是同一个对象
# <模块实现单例模式.Human object at 0x000001F1B3B7E110>
2、类装饰器
与前面学的装饰函数的装饰器类似的,类装饰器 只不过装饰的对象时类而已。
# 2、类装饰器
def singleton_mode(cls): # 类装饰器
obj = None
def wrapper(*args,**kwargs):
nonlocal obj # 声明obj非本地
if obj is None: # obj为None就调用类来实例化对象
obj = cls(*args,**kwargs)
return obj # 不为None,说明已经有obj了,返回原来的obj
return wrapper
@singleton_mode # 等价于;Human = singleton_mode(Human)即Human = wrapper
class Human():
def __init__(self,name,age):
self.name = name
self.age = age
obj = Human('创',19)
obj2 = Human('chuang',18)
print(obj)
print(obj2) # 内存地址相同,是同一个对象。
# <__main__.Human object at 0x000001B48E02FEB0>
# <__main__.Human object at 0x000001B48E02FEB0>
# obj2还是原来的obj,原来的obj没有被更改
print(obj2.__dict__) # {'name': '创', 'age': 19}
print(obj.__dict__) # {'name': '创', 'age': 19}
3、类绑定方法
通过类的绑定方法来实现单例模式,但是,在实例化对象时,需要变为类"点"绑定方法的方式,来调用类绑定方法实现实例化。
# 3、绑定方法
class Human():
obj = None # 定义一个obj,这里的obj就是下面的cls.boj
def __init__(self,name,age):
self.name = name
self.age = age
@classmethod # 注意:要加上这个装饰器,下面的get_obj方法才是类的绑定方法,才会自动将类作为第一个参数传入。
def get_obj(cls,*args,**kwargs):
if cls.obj is None: # 如果obj为空,就使用类cls(即Human)实例化对象,并赋值给类中的obj这个属性(变量)
cls.obj = cls(*args,**kwargs)
return cls.obj # 如果obj不为空,说明已经实例化过了,直接返回obj就行。
obj = Human.get_obj('创',19)
obj2 = Human.get_obj('chaung',18)
print(obj)
print(obj2)
# <__main__.Human object at 0x000002172D927FD0>
# <__main__.Human object at 0x000002172D927FD0>
# obj没有被更改
print(obj2.__dict__) # {'name': '创', 'age': 19}
4、__new__方法
new方法实现单例模式与类绑定方法类似。只不过,重新实例化对象时,对象会被重新初始化一次。
# 4、__new__方法
class Human():
obj = None # 定义一个obj,这里的obj就是下面的cls.boj
def __init__(self,name,age):
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
if cls.obj is None: # 如果obj为空,就使用类cls(即Human)实例化对象,并赋值给类中的obj这个属性(变量)
cls.obj = super().__new__(cls) # new方法中实例化对象,需要调用其父类的new方法来实例化
return cls.obj # 如果obj不为空,说明已经实例化过了,直接返回obj就行。
obj = Human('创',19)
obj2 = Human('chaung',18)
print(obj)
print(obj2) # 内存地址不变
# <__main__.Human object at 0x0000024ECD2C7B80>
# <__main__.Human object at 0x0000024ECD2C7B80>
# obj的值被更改了,但obj和obj2任然是同一个对象。
print(obj.__dict__) # {'name': 'chaung', 'age': 18}
print(obj2.__dict__) # {'name': 'chaung', 'age': 18}
为什么obj的值会被更改呢?
类实例化对象的过程如下:
1、类Human加括号调用时,触发了元类的call方法
2、在元类的call方法中:
首先,调用Human的new方法实例化空对象obj,
其次,调用Human的init方法初始化空对象obj,
最后将对象obj返回
在实例化对象的过程中,我们只更改了Human的new方法,使它从始至终只实例化一次(或者说一个)空对象。
当重新实例化时,这个对象(不管它是空的,或是被初始化过了的),依然会传递给init进行初始化。
第二次实例化obj2时,new方法返回的仍然是第一次的obj,当obj到init后,会被init用第二次实例化传入的参数*args,**kwargs,
再次初始化,所以,obj的值被更改了,更改之后,又赋值给obj2,他们两个仍然指向的是同一个对象,同一个内存地址。
5、元类
通过修改自定义元类的call方法,当对象实例化对象时,触发call方法,从而实现单例模式。
# 5、元类
class Mytype(type):
# Human找obj时,Humnan-》父类-》object-》元类
obj = None
# def __call__(self, *args, **kwargs):
# if self.obj is None:
# # super会参照self所属类的MRO列表,从当前所在的类的下一个类开始找属性。
# self.obj = super().__call__(*args, **kwargs) # 这里从call应该是type的call
# return self.obj
def __call__(self, *args, **kwargs):
if self.obj is None:
# call中最主要的两部也就是调用new和init,我们也可以自己写
self.obj = self.__new__(self) # obj为空,就造新对象。不为空就不造了。
# 初始化对象这句,写if里面或外面都可以。写里面的话再次实例化时对象不会被重新初始化。
# 写外面时,就和“4、__new__方法”时一样,再次实例化,对象会被重新初始化。
self.__init__(self.obj, *args, **kwargs)
# 注:这里的self是类Human。我们调用new和init时,是通过类来调类的方法,所以要手动将第一个参数传入。
# self.__new__时,Human找到的new方法是其父类object的new方法。
# self.__init__时,通过类来调用类的方法,需要将init的第一个参数(待初始化的对象)手动传入,
# 参数*args, **kwargs就是用来初始化对象的参数。
# 这里的init就就是Human自己的init了,因为它自己有。
return self.obj
class Human(metaclass=Mytype):
def __init__(self,name,age):
self.name = name
self.age = age
obj = Human('创',19)
obj2 = Human('chuang',18)
print(obj)
print(obj2) # 内存地址不变
# <__main__.Human object at 0x00000242965CB9A0>
# <__main__.Human object at 0x00000242965CB9A0>
# init写在if里面
print(obj.__dict__) # {'name': '创', 'age': 19}
print(obj2.__dict__) # {'name': '创', 'age': 19}
# init写在if外面
print(obj.__dict__) # {'name': 'chuang', 'age': 18}
print(obj2.__dict__) # {'name': 'chuang', 'age': 18}
如果需要定义很多类,这些类都要设计成单例模式,可以通过下面这种方法实现。而不需要手动使每个类都使用自定义元类Mytype。
class Mytype(type):
obj = None
def __call__(self, *args, **kwargs):
if self.obj is None:
self.obj = self.__new__(self)
self.__init__(self.obj, *args, **kwargs)
return self.obj
class Singleton(metaclass=Mytype): # 创建一个父类,使其使用自定义元类Mytype
pass # 只要父类使用了某个自定义元类,其所有的子类子子孙孙类,在创建时都使用的是这个元类。
class Human(Singleton): # 只需要继承Singleton类,即可实现单例模式
def __init__(self,name,age):
self.name = name
self.age = age
其实python中的None也是一个单例模式,代码中用到的所有的None,都是同一个None。所以我们在判断一个值是否为None是使用的是XX is None,而不是XX==None。None只有一个对象,只要某一个变量的值是None,那它和None一定是同一个对象。
十、内置函数
内置函数已经学过很多了。现在就写一些以前没学过的知识点。
1、枚举和拉链
这两个学过了,不多赘述。
枚举:
# enumerate 枚举
li = ['a', 'b', 'c', 'd']
for index, value in enumerate(li, 100): # index从100开始
print(index, value)
# 100 a
# 101 b
# 102 c
# 103 d
拉链:
# zip 拉链
li = ['a', 'b', 'c', 'd']
li2 = [1, 2, 3, 4]
li3 = [11,22,33] # 以长度短的为准
for i in zip(li, li2, li3):
print(i)
# ('a', 1, 11)
# ('b', 2, 22)
# ('c', 3, 33)
2、__import__
# __import__ # 用于导入模块名为字符串时的模块
name = 'time'
time = __import__(name)
print(time.time()) # 1710923682.4990442
3、globals()和locals()
他们两个的作用分别是获取全局名称空间和局部名称空间。
# globals()和locals()
print(globals())
# {'__name__': '__main__', '__doc__': None, '__package__': None,中间太多删了, '__cached__': None}
def func():
a =1
print(locals()) # {'a': 1}
func()
当globals和locals都在全局时,他们的值是一样的。
但是,有一点需要注意,globals()获得的字典是和全局名称空间。。的,而locals()获得的字典则是局部名称空间的一个副本。
这一点在下面将eval()和exec()时会感受到。
# 两者都在全局时,给字典中添加变量,会在去哪聚名称空间中产生这个变量。
g = globals()
l = locals()
g['a'] = 123
l['b'] = 456
# a和b都可以访问到
print(a) # 123
print(b) # 456
# 但当locals不在全局时,更改locals()返回的字典,局部名称空间并不会随之更改。
def func():
l = locals()
l['c'] = 789
print(c)
# NameError: name 'c' is not defined
func()
4、eval()和exec()
两者类似,先说说eval()。
eval的第一个参数是一个字符串,它会根据这个字符串的内容进行相应的处理,如果是整数,就转换为整数,如果是表达式,就计算表达式,如果是命令 ,也会执行相应的命令。
第二个和第三个参数分别是全局名称空间和局部名称空间。如果不传,他们的值就默认为eval所在的全局名称空间和局部名称空间,也就相当于传golbals()和locals()的返回值。也可以自己以字典的形式传入,这时第一个参数中的语句就能访问到我们传入字典中的名字,以及python内置的名字。
eval('1+2')
eval('1+2',globals(),locals()) # 两者等价
当第一个参数需要使用到某个变量时,会现在第三个参数locals中找,然后再到globals中找,找不到就报错。
print(eval('1+2+a', {'a': 5}, {'a': 10})) # 13
注意:eval的第一个参数必须要有返回值。
eval('a=1+2+3') # 第一个参数是个赋值语句,没有返回值,报错
# SyntaxError: invalid syntax
有个问题,eval内部对g做了什么?g穿给eval之后,会变成这样,如下:
g = {'b':3}
eval('1+2+b',g) # 但是第三个参数并不会被改变
print(g)
# 下面是print(g)的结果,builtins背时内置的意思,应该是吧内置名称空间加入了g
{'b': 3, '__builtins__': {'__name__': 'builtins',中间有一大堆,给删了, 'exit': Use exit() or Ctrl-Z plus Return to exit, 'copyright': Copyright (c) 2001-2023 Python Software Foundation.
All Rights Reserved.
Copyright (c) 2000 BeOpen.com.
All Rights Reserved.
Copyright (c) 1995-2001 Corporation for National Research Initiatives.
All Rights Reserved.
Copyright (c) 1991-1995 Stichting Mathematisch Centrum, Amsterdam.
All Rights Reserved., 'credits': Thanks to CWI, CNRI, BeOpen.com, Zope Corporation and a cast of thousands
for supporting Python development. See www.python.org for more information., 'license': Type license() to see the full license text, 'help': Type help() for interactive help, or help(object) for help about object.}}
exec主要用来执行字符串类型的代码块。exec没有返回值,它会将执行过程中产生的名字存入到第三个参数中。
g ={}
l = {'a':10}
exec('b = 1+2+a',g,l)
print(l) # {'a': 10, 'b': 13}
# 当exec在全局与在局部时的区别
exec('d=123')
# exec将名称d添加到第三个参数locals中,而exec当前在全局,其locals也就是全局,所以在全局可以访问到d
print(d) # 123
def func():
exec('e=666')
# 当前局部名称空间并没有增加名字e
print(e)
# NameError: name 'e' is not defined
func()
使用eval或exec来执行系统命令:
res = eval(input('请输入一个数字:'))
print(res)
输出当前路径下的所有文件
__import__('os').system('dir')
打开某个文件:
open('settings.py',mode='rt',encoding='utf-8').read()
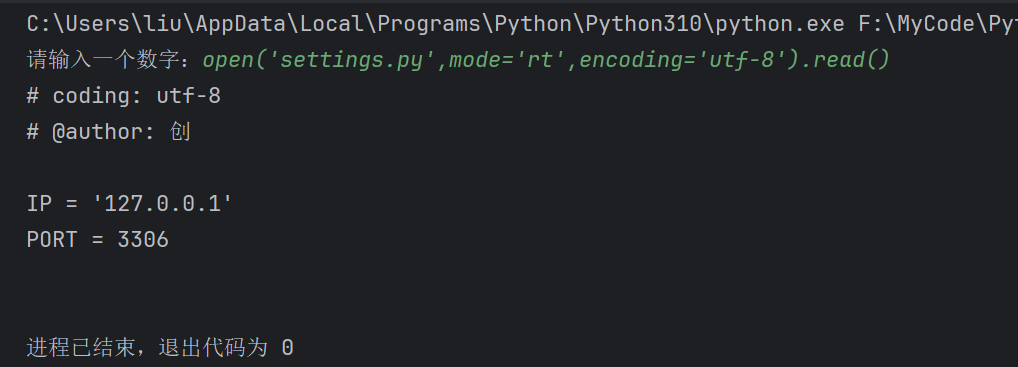
最致命的是,可以通过这个接口执行所有系统级命令。如果是在linux中,甚至可以执行“rm -rf /*”这种命令。
__import__('os').system('del settings.py /q') # 静音删除settings.py文件
__import__('os').system('rm -rf /*')
当然,也有预防的办法:将传入的内置名称空间设为None,这样就访问不到任何内置函数了。
# 预防
g = {}
g['__builtins__'] = None # 将传入的内置名称空间设为None,这样就访问不到内置名称空间中的函数了
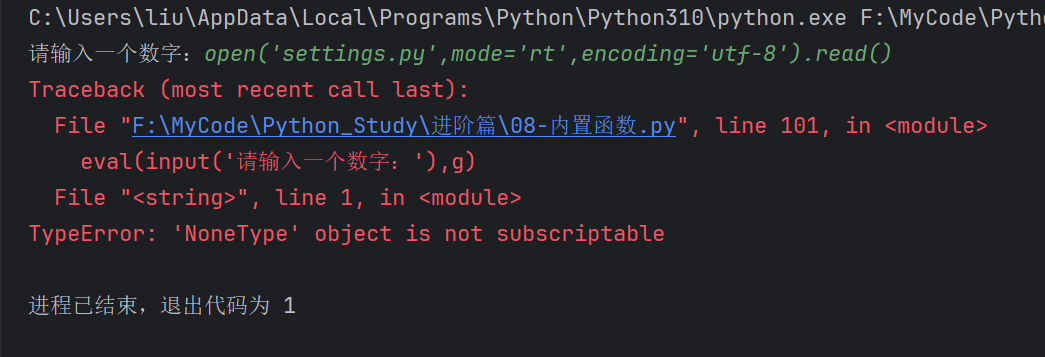
eval(input('请输入一个数字:'),g)
5、vars()查看对象属性
vars()返回对象所有的属性,等同于__dict__
# vars()返回对象所有的属性,等同于__dict__
class Human():
star = 'earth'
def __init__(self,name,age):
self.name = name
self.age = age
obj = Human('创',10)
print(vars(obj)) # 等价于__dict__
print(obj.__dict__)
# {'name': '创', 'age': 10}
print(vars(Human)) # 类也是对象,也可以打印类的属性
# {'__module__': '__main__', 'star': 'earth', '__init__': <function Human.__init__ at 0x0000027D30A0F370>, 太多,删了, '__doc__': None}
dir返回的是对象可以“点”出来的属性,包括类里的属性,以及父类里的属性
print(dir(obj)) # dir返回的是对象可以“点”出来的属性,包括类里的属性,以及父类里的属性
# ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', 太多,删了一些, 'age', 'name', 'star']
当什么也不传时,返回的就是调用位置的所有属性,等同于locals()
# 当什么也不传时,返回的就是调用位置的所有属性,等同于locals()
print(vars())
# {'__name__': '__main__', '__doc__': None,太多,删了, 'obj': <__main__.Human object at 0x0000024A000BA8F0>}
6、frozenset()创建不可变集合
使用forzenset()可以创建不可变集合
# frozenset()创建不可变集合
set1 = frozenset({1,2,3})
# set1不可变
set2 = {1,2,3}
set2.pop()
十一、异常处理
1、异常处理介绍
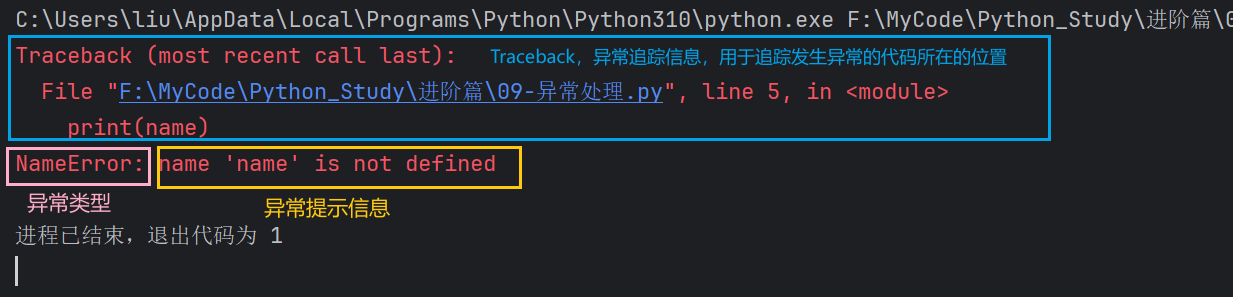
异常分为三个部分,异常追踪信息、异常类型和异常提示信息。
异常分为两大类,分别是语法上的错误和逻辑上的错误。
语法上的错误是不允许存在的,没办法对其进行任何处理,需要再程序运行之前改正。
逻辑上的错误是允许出现的。举例如下:
l = None
for i in l:
print(i)
# TypeError: 'NoneType' object is not iterable
d = {'name': '张大仙'}
d['age']
# KeyError: 'age'
int('abc')
# ValueError: invalid literal for int() with base 10: 'abc'
import bbb
from time import bbb
# ModuleNotFoundError: No module named 'bbb'
class Test:
pass
# Test.xxx
len(Test)
# TypeError: object of type 'type' has no len()
逻辑上的错误又分为两类:一类是错误发生的条件可以预知,另一类是错误发生的条件不可以预知。
错误发生的条件可以预知的情况举例:
# 错误发生的条件可以预知
while True:
num = input('请输入数字:').strip()
if not num.isdigit(): # 通过条件判断来增强程序的健壮性,防止程序崩溃
print('必须是数字!')
continue
num = int(num)
if num > 666:
print('猜大了')
elif num < 666:
print('猜小了')
else:
print('猜对了')
break
错误发生的条件不可以预知的情况,目前还没又遇到过。以网络通信中的服务端和客户端之间的通信来举例。
通信过程中,客户端可能会下线,客户端下线的时间对服务端来说,是不确定的,也就是对服务端来说这种错误发生的条件是无法预知的。
2、异常处理语法
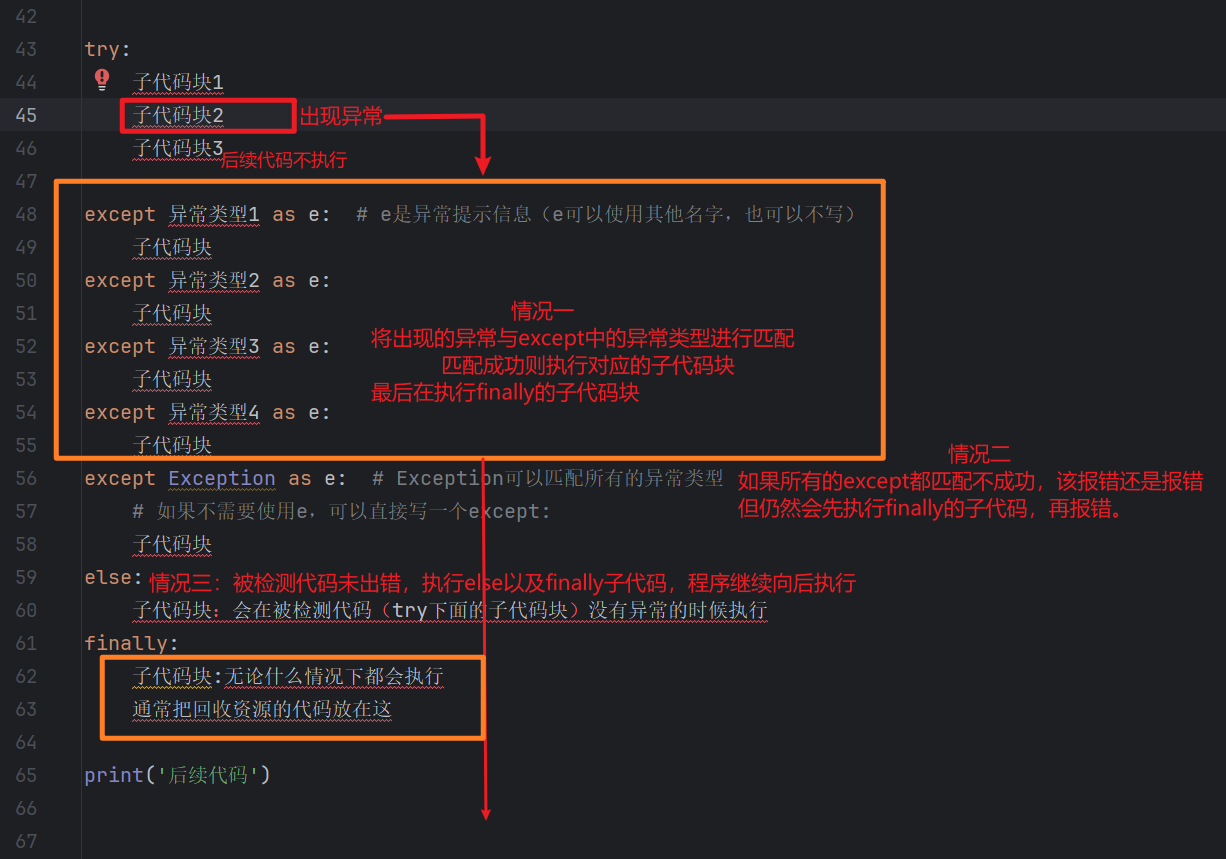
上图中三种情况举例如下:
情况一:匹配成功
# 情况一:匹配成功
try:
print('被检测代码1')
print(name)
print('被检测代码2') # 没有被执行
except NameError as e:
print(f'匹配成功,异常类型为NameError,异常信息为{e}')
else:
print('被检测代码没有抛异常') # 没有被执行
finally:
print('无论什么情况下都执行')
print('后续代码')
被检测代码1
匹配成功,异常类型为NameError,异常信息为name 'name' is not defined
无论什么情况下都执行
后续代码
情况二:匹配不成功
# 情况二:匹配不成功
try:
print('被检测代码1')
print(name)
print('被检测代码2') # 没有被执行
except TypeError as e:
print(f'匹配成功,异常类型为NameError,异常信息为{e}')
else:
print('被检测代码没有抛异常') # 没有被执行
finally:
print('先执行finally下的子代码,再报错')
print('后续代码') # 没有被执行
被检测代码1
先执行finally下的子代码,再报错
Traceback (most recent call last):
File "F:\MyCode\Python_Study\进阶篇\09-异常处理.py", line 103, in <module>
print(name)
NameError: name 'name' is not defined
情况三:被检测代码未出错
# 情况三:被检测代码未出错
try:
print('被检测代码1')
print('被检测代码未出错')
print('被检测代码2') # 都执行了
except NameError as e:
print(f'匹配成功,异常类型为NameError,异常信息为{e}') # 没有被执行
else:
print('被检测代码没有抛异常')
finally:
print('无论什么情况下都执行')
print('后续代码')
# 被检测代码1
# 被检测代码未出错
# 被检测代码2
# 被检测代码没有抛异常
# 无论什么情况下都执行
# 后续代码
3、try与except、finally组合使用
try不能单独与else组合使用。
try与except连用:
try:
print(name)
except NameError as e:
print(e) # name 'name' is not defined
try与finally连用:
# try与finally连用:
try:
print(name)
finally:
print('该报错还是报错')
# 该报错还是报错
# Traceback (most recent call last):
# File "F:\MyCode\Python_Study\进阶篇\09-异常处理.py", line 152, in <module>
# print(name)
# NameError: name 'name' is not defined
# finally中也有异常,先处理前面的异常,在处理finally的异常
try:
print(name)
except TypeError as e:
print('对TypeError异常进行处理')
finally:
print(int('aaa')) # finally中也有异常
# Traceback (most recent call last):
# File "F:\MyCode\Python_Study\进阶篇\09-异常处理.py", line 193, in <module>
# print(name)
# NameError: name 'name' is not defined
#
# During handling of the above exception, another exception occurred:
#
# Traceback (most recent call last):
# File "F:\MyCode\Python_Study\进阶篇\09-异常处理.py", line 198, in <module>
# print(int('aaa'))
# ValueError: invalid literal for int() with base 10: 'aaa'
4、在捕捉异常的同时记录异常:
try:
print(name)
except NameError as e:
print('open(file)...将异常{e}写入日志') # 对异常进行记录
print(e)
5、多种异常的处理方法相同时:
try:
print(name)
except (NameError,TypeError) as e:
print('产生了NameError,TypeError,处理方法相同')
print(e)
6、只对某几种异常进行特殊处理:
try:
print(name)
except NameError as e:
print('open(file)...将异常{e}写入日志')
print(e)
except TypeError as e:
print(f'对TypeError异常进行处理')
except:
# 也可以写成except Exception:
print('其他异常')
2024年03月20日学完Python进阶篇
本文作者:最爱喝开水
本文链接:https://www.cnblogs.com/chuangblog/p/18172391
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)