
Python笔记
第一章、Python概述
1.1 扩展库安装方法(了解即可)
使用pip命令安装扩展库。
在cmd命令行中输入pip,回车后可以看到pip命令的使用说明。
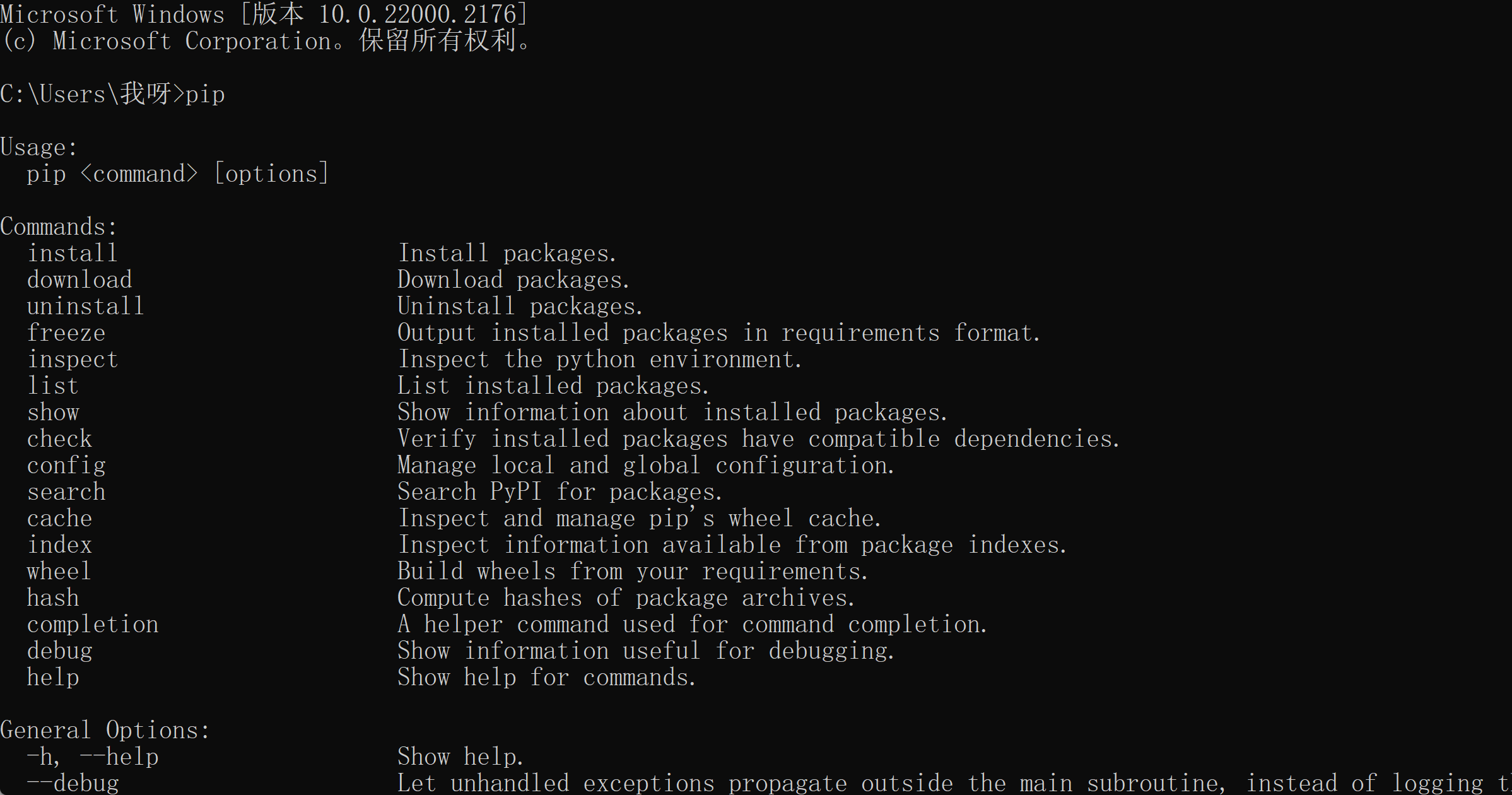
1.2 常用的pip命令(了解即可)
| pip命令示例 | 说 明 | |
|---|---|---|
| pip freeze[>requirements.txt] | 列出已安装扩展库及其版本号(不知道怎么用。。?) | |
| pip install SomePackage[=version] | 在线安装SomePackage扩展库的指定版本 | |
| pip install SomePackage.whl | 通过whl文件离线安装扩展库 | |
| pip install packagel package2 .. | 依次(在线)安装packagel、package2等扩展库 | |
| pip install -r requirements.txt | 安装requirements.xt文件中指定的扩展库 | |
| pip install -upgrade SomePackage | 升级SomePackage扩展库 | |
| pip uninstall SomePackage[=version] | 卸载SomePackage扩展库 | |
| python.exe -m pip install --upgrade pip | 升级pip |
使用示例
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # 指定国内镜像源下载
pip install PyPDF2 # 安装PyPDF2模块
pip install PyPDF2==3.0.1 # 安装3.0.1版本
pip install -upgrade PyPDF2 # 升级PyPDF2
pip uninstall PyPDF2 # 卸载PyPDF2
1.3 导入包/模块的方法(需要并入到模块中)
直接导入(常用) import 模块名
import math # 导入math
math.sqrt(10) # 通过math.调用math模块下的功能
起别名 import 模块名 as 别名
import math as ma
ma.sqrt(20) # 使用别名
math.sqrt(20) # 也可使用原名
导入模块下的某个功能 form 模块名 import 功能名 (as 功能别名)
form math import sqrt
sqrt(30) # 不需要加前缀,直接使用
form math import sqrt as sq # 起别名
sq(40)
导入模块下的全部功能 form 模块名 import *
form math import * # 将math模块中的所有都导入,容易产生名称冲突
sqrt(50)
sin(1)
1.4 dir()和help()
dir(模块名) # 查看模块中的功能
help(模块功能名) # 查看功能的使用方法
1.5 编程语言的分类方式
1、编译型或解释型
2、强类型或弱类型
- 强类型:一个变量如果被指定了是某种数据类型,如果不经过强制转换,那么它就永远是这个数据类型了
- 弱类型:数据类型可以被忽略,随着调用方式的不同,数据类型可以随意切换(php,js)
3、动态型或静态型
- 动态型:运行时才会进行数据类型的检查,变量在定义时不会指定数据类型,而是在赋值完成后才确定数据类型
- 静态型:定义时就规定变量的类型,在赋值是若传其他lx的值,则会报错
python是一门解释型强类型动态语言。
第二章、内置对象,运算符,表达式,关键字
2.1 Python常用内置对象
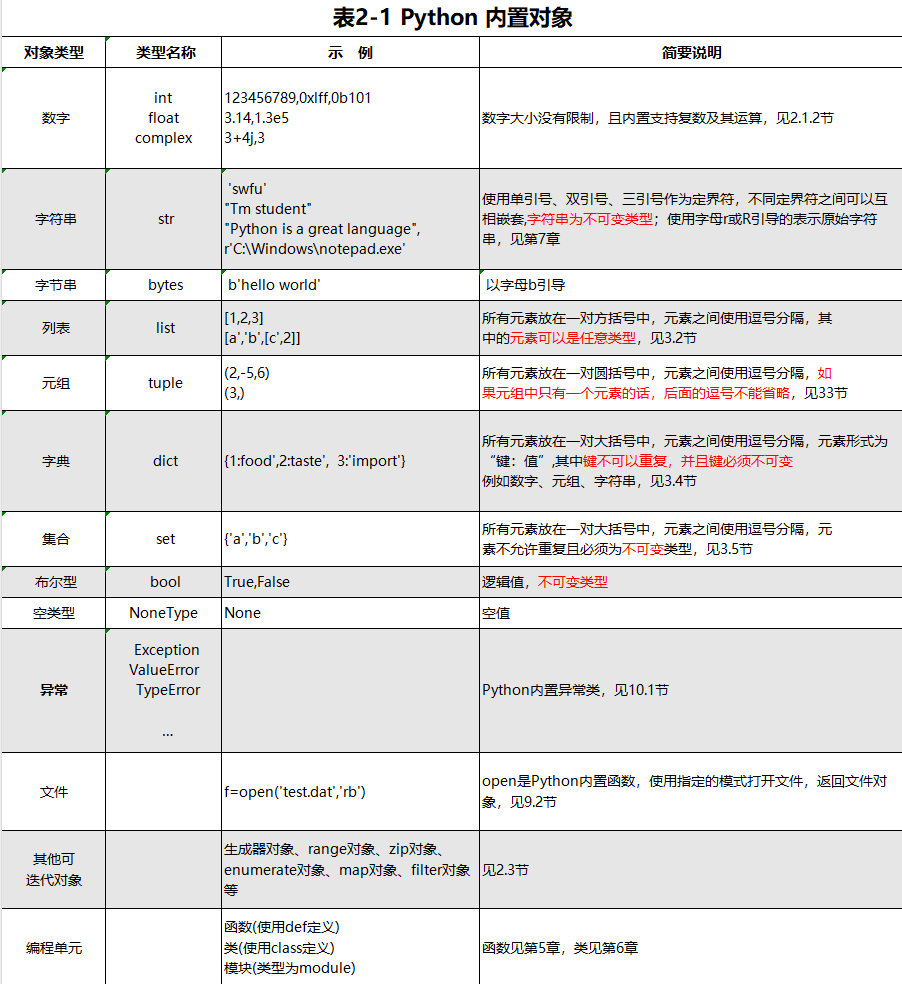
注意bool类型的值:
print(True==1) # True
print(False==0) # True
print(True==2) # False
2.1.1 常量与变量
常量:实际上python中并没有常量,约定将变量名全部大写的变量当做常量,但实际上它仍然是变量。
变量:一般是指值可以变化的量。
在Python中,不需要先声明变量名及其类型,赋值语句可以直接创建任意类型的变量。
赋值语句的执行过程是:首先把等号右侧表达式的值计算出来,然后在内存中寻找一个位置把值存储进去,最后创建变量并引用这个内存地址。也就是说,Python 变量并不直接存储值,而是存储了值的内存地址或者引用,所以,不仅变量的值可以改变,变量的类型也可以随时发生改变。
变量名的命名规范:
- 以字母、汉字、或下划线开头。
- 变量名中不能有空格或标点符号。
- 不能使用关键字作为变量名,如if、else、for、等都是非法的。
- 变量名区分大小写,如abc与Abc是不同的变量。
- 不建议使用系统内置的模块名,类型名、或函数名,以及导入的模块名及其成员名。
垃圾回收机制(待补充)
内存中,引用计数为0的数据会被作为垃圾回收(释放)
引用计数:只要能够访问到某个值的方式都叫一种引用。可以简单的看做是有几个变量名和某个数据绑定,那么那个数据的引用计数就为几。变量名和数据的绑定关系可以看做是c语言中的指针。
使用引用计数来扫描并回收垃圾,用标记清除解决引用计数回收不了的垃圾,用分代或回收解决标记清除扫描时的效率问题。
垃圾回收机制有下面三种:
-
循环引用
循环引用之内存泄漏问题 - 《python零基础到全栈系列》_哔哩哔哩_bilibili
-
标记清除
标记清除机制 - 《python零基础到全栈系列》_哔哩哔哩_bilibili
-
分代回收
分代回收机制 - 《python零基础到全栈系列》_哔哩哔哩_bilibili
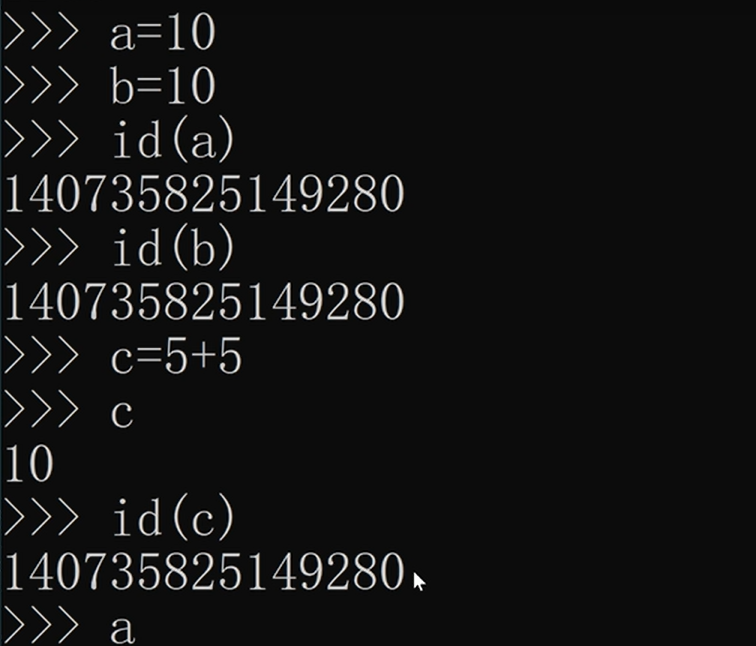
小整数池
python运行时就会直接为一些常用到的值申请内存空间,后续用到时不再重新申请,而是直接将那个变量指向那个内存地址。
小整数池范围:-5到256的整数。
除小整数池之外还有一些经常用到的值,例如字母a、b、c之类的。
Pycharm会扩大小整数池以及一些常用到的字符串。所以下面的代码在pycharm中运行与cmd中可能不同。
2.1.2 整数、实数、复数
二进制:以0b开头
八进制:以0o开头
十六进制:以0x开头
Python支持任意大的数字。但是由于精度问题,Python对于实数运算可能存在一些误差,应尽量避免在实数之间直接进行相等性测试。例如
>>>0.4-0.3
0.10000000000000003
Python内置支持复数运算,形式与数学上一致。
为了提高可读性,Python3.6X及以上版本支持在数字中间插入单个下划线对数字进行分组,但下划线不能出现在数字开头或结尾。例如1000000可以写成1_000_000。
>>>1_000_000
1000000
2.1.3 字符串
Python 使用单引号、双引号、三单引号、三双引号作为定界符来表示字符串,并且不同的定界符之间可以互相嵌套。另外,Python 3.x 全面支持中文,使用内置函数 len()统计长度时中文和英文字母都作为一个字符对待,甚至可以使用中文作为变量名。
(字符串的操作有很多,这里只是介绍一些基础的用法,后面会单独一章来讲字符串的用法)
(1)字符串的定义
s1='apple'
s2="banana"
s3='''ege'''
(2)字符串索引
# 在字符串变量名后更[n],获取n号索引
s='abcdef'
s[0] # 获取字符串s中的第0号索引的值 a
s[-1] # 向后索引,获取倒数第一个值 f
(3)字符串切片
注意:字符串的切片是将指定部分复制一份返回,并不会改变原来的字符串。
- 切片 [开始:结束:步长(默认为1)] 顾头不顾尾,从后往前切片时也是不取最后取的那一个
- 无论是行前往后索引,还是从后往前索引,都是不取后面的那个索引的值,也就是第二个参数的值。
- 例如从1取到3,那么不包含3,从3取到1,那么不包含1
# 切片 [开始:结束:步长(默认为1)] 顾头不顾尾,从后往前切片时也是不取最后取的那一个
# 无论是行前往后索引,还是从后往前索引,都是不取后面的那个索引的值,也就是第二个参数的值。
# 例如从1取到3,那么不包含3,从3取到1,那么不包含1
s='abcdef'
s[0:3] # 获取第0号索引到第3号索引(不包含3号)的片段 abc
s[2:5] # cde
s[3:] # 省略第二个参数,表示截取到字符串末尾(包含最后一个字符) ef
S[:] # 第一、二个参数都省略,获取整个字符串 abcdef
s[0:5:2] # 从0号索引到5号索引(不包含5号)之间,每隔一个字符取一个值 ace
s[3:-1] # 获取3号索引到-1号索引(不包含-1号)的片段 de
# 反向切片(步长为负数)
s[4:1:-1] # edc
s[-1:2:-1] # 从倒数第一个到2号索引(不包含2号),从后往前获取它们之间的片段 fed
s[::-1] # 反转整个字符串 fedcba
2.1.4 列表、元组、字典、集合
列表、元组、字典、集合都是Python内置的容器对象,可以包含和持有多个元素。
这些后面第三章序列结构会细讲,这里只是简单提一下。
(1)列表
# 使用[]和赋值语句就可以创建列表
l=[123,'abc',[111,'lll'],(123,666,'fjdksla'),{1,2,3,'fdsa'},{1:'one'}]
列表是可变类型
(2)元组
# 使用()和赋值语句就可以创建元组
tup = ('sjsjsjskk', 455665, (1, 2), [3, 4], {5, 6}, [7, {8, 9, (10, 11)}])
元组是不可变类型
(3)字典
# 使用{}和赋值语句就可以创建字典,但{}中的元素要是“key:vallue"这样的键值对
d = {'one': '1', 'two': 2, 'dictionary': '字典', 'name': '我呀'}
字典是可变类型,但字典的键(key)必须为不可变类型
(4)集合
# 使用{}和赋值语句就可以创建集合
s = {'fnshbhbhb', 1, (2, 3), (4), (5, 6), 1, 4}
集合中的元素必须是不可变类型
集合与数学中的集合一样,具有去重的特性,集合中相同的元素只会保存一个
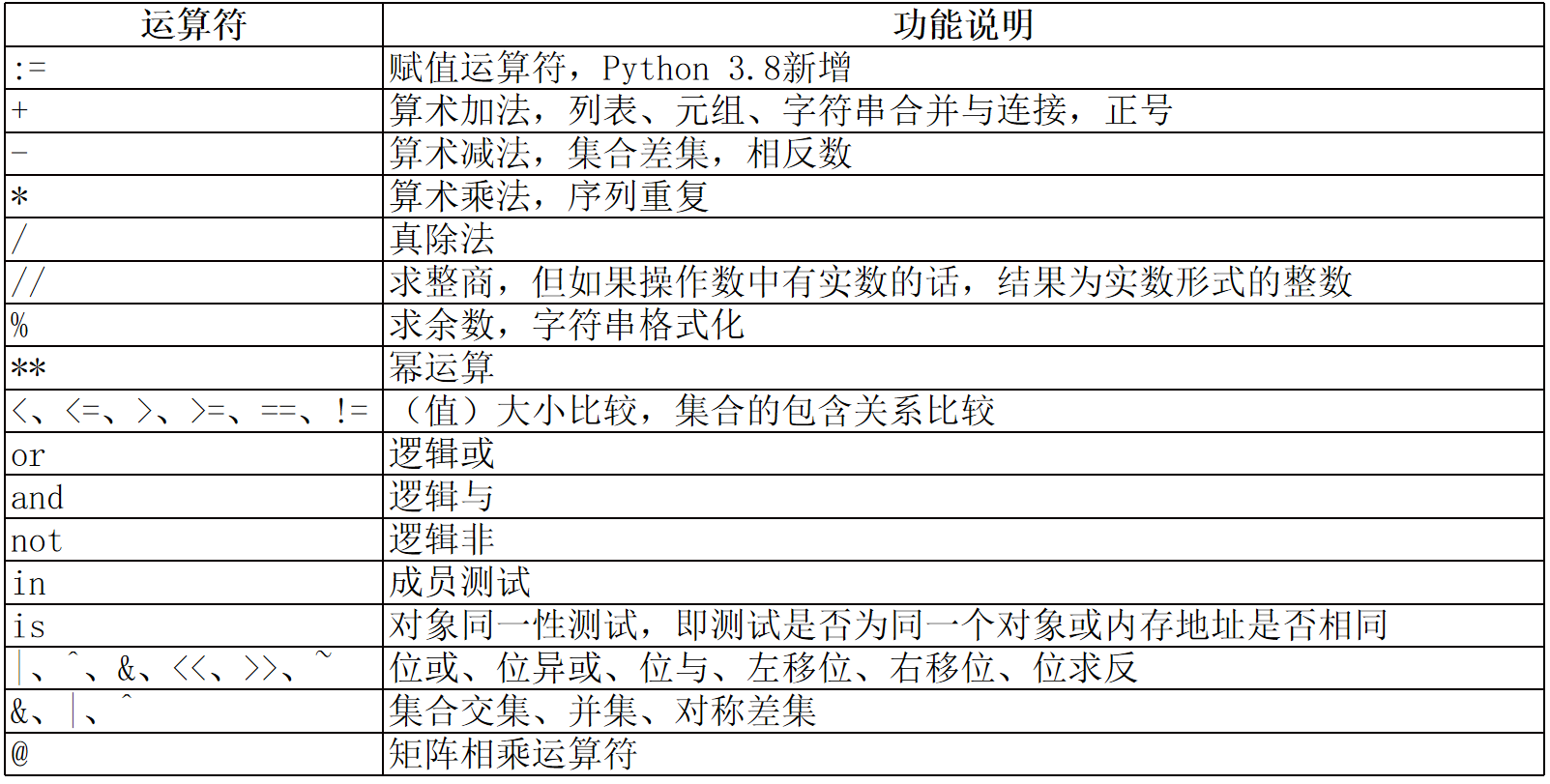
2.2 Python运算符运算符与表达式
这是对python运算符的汇总,示例代码中包含了很多后面才会讲到的内容,暂时看不懂也没有关系,只要知道每个运算符是用来干什么的,有什么用就行,这些运算符及用法在后面的代码中会反复出现,如果在后面的代码中出现了看不懂的用法,在回来差一下,时间久了自然就能都掌握了。
+
print('{0:-^30}'.format(' + ')) # 这里是格式化输出,看不懂没关系,与这部分的内容无关
# 算数加法
my_sum = 1 + 2 + 3
print(my_sum)
# 列表合并
ls1 = ['a', 'b', 'c']
ls2 = [1, 2, 3]
ls3 = ls1 + ls2
print(ls3)
# 元组合并
tup = (1, 2, 3) + (4, 5, 6,)
print(tup)
# 字符串拼接(直接用+号拼接的效率很低,推荐使用格式化字符的方法进行拼接)
s = 'abc' + 'def'
print(s)
-
print('{0:-^30}'.format(' - '))
# 算数减法
a = 1 - 2 - 3
print(a)
# 集合差集
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6}
set3 = set1 - set2
print(set3)
print(set2 - set1) # 空集
*
print('{0:-^30}'.format(' * '))
# 算数乘法
b = 1 * 2 * 3 * 4 * 5
print(b)
# 序列重复
# 字典与集合不可进行乘法,应为集合中不存在重复元素,字典的key不可重复
l = [1, 2, 3]
s = 'abc'
tup = (7, 8, 9)
set4 = {1, 2, 3}
dic = {1: 'one', 2: 'two', 3: 'three'}
print(l * 3)
print(s * 3)
print(tup * 3)
/
print('{0:-^30}'.format(' / '))
# 真除法,结果为实数
print(3 / 2)
print(3 / 2.0) # 结果都为1.5
#
//
print('{0:-^30}'.format(' // '))
# 求整商,结果为整数,但如果操作数中有实数,那么结果为实数形式的整数。
print(5 // 2, type(5 // 2)) # 2 int
print(5 // 2.0, type(5 // 2.0)) # 2.0 float
%
print('{0:-^30}'.format(' % '))
# 求余数
print(5 % 2)
print(6 % 3)
print(3 % 5) # 商0,余3
# 字符串格式化
height = 178.0 # float
weight = 76 # int
b = '娃哈哈' # str
print('这就是传说中的%s,太酷啦!' % b)
print('保留3位小数:%.3f') # 字符串后面没有%和对应的变量的话就是常规输出
print('保留3位小数:%.3f' % height) # 与c语言的%类似
print('我的身高为%.2f,我的体重为%d' % (height, weight)) # 多个值要放在元组中,按前后顺序
tup = (height, weight)
print('我的身高为%.2f,我的体重为%d' % tup) # 直接放一个元组变量也是可以的
print('我的身高为%(身高).3f,我的体重为%(体重)d' % {'体重': weight, '身高': height}) # 使用字典,按key传值
**
print('{0:-^30}'.format(' ** '))
# 幂运算,具有右结合性
print(3 ** 3)
print(2 * 3 ** 3)
< <= > >= == !=
print('{0:-^30}'.format(' < <= > >= == != '))
# 值的比较
print(3 < 2)
print('abc' < 'abd', 'abc' >= 'aaa', 'abc' < 'abca') # 对应字符比较(ASCII码值),只要其中一对比出结果了,就不再进行后面的比较(都相等的话,长度长的大)
print('abcdef' == 'abcde') # 每一个字符都要相等
print(['a', 2, 5] >= ['a', 2, 5]) # 列表之间的比较也是一个元素一个元素的比,但对应元素必须是同类型的。
print((1, 2, 3) > (3, 2, 1), (1, 2, 3) <= (1, 2, 6))
print({1: 'one', 2: 'two'} != {3: 'one', 4: 'two'}) # 字典之间只能支持==和!=
# 集合的包含关系比较
print('{0:-^30}'.format('集合包含关系'))
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 <= set2)
print(set1 == set2)
print(set1 > set2)
print(set1 >= set2)
print(set1 != set2)
# < 真子集 <= 子集(两个集合可以相等)
# == 相等 != 不相等
and or not
print('{0:-^30}'.format(' and or not '))
if True and False:
print('与')
if True or False:
print('或')
if not False:
print('非')
in
print('{0:-^30}'.format(' in '))
# 成员运算符
print('{0:-^20}'.format('in'))
print('a' in 'abc')
print('a' in ['a', 'b', 'c'])
print('a' in {1: 'a', 2: 'b'}) # 字典中找的是key
print('a' in ('a', 1, 'c'))
print('a' in {'a', 'b', 'c'})
is
print('{0:-^30}'.format(' is '))
# 对象同一性测试,即测试是否为同一对象或内存地址是否相同
a = ['abc']
b = a
print(type(a))
print(type(b))
print(a is b)
def func():
pass
f = func
print(func, f) # 打印func和f的地址
print(f is func)
| ^ & << >> ~
# 位或,位异或,位与,左移位,右移位,位求反
print('{0:-^30}'.format(' | ^ & << >> ~ '))
print(6 ^ 7) # 0b110与0b111进行异或运算
print(0b11 & 0b110) # 0b011与0b110进行与运算
print(0 | 1) # 或运算
print(0b110 << 1) # 左移一位,变为0b1100
print(6 << 1) # 转为二进制后,左移一位
print(0b1100 >> 2) # 右移2位,变为0b11
print(~0b111) # 位求反 结果为-8 ???和预期结果不同 -0b111-0b1得到-0b1000,就是-8
& | ^
# 集合的交集,并集,对称差集
print('{0:-^30}'.format(' & | ^ '))
set1 = {1, 2, 3, 4, 5, 6, 7, 8, 9}
set2 = {1, 2, 3, 4, 5, 6, 0}
print(set1 & set2) # 交集
print(set1 | set2) # 并集
print(set2 - set1) # 对称差集(只在A中出现的元素,即A去掉AB的部分)
print(set1 - set2) # 只在set1中出现的元素
其他
# Python不支持自增和自减运算符(++、--)
i = 3
print(++i) # 解释为两个正号
print(+(+i)) # 与++i等价
print(i++) # 语法不支持
--i也与++i类似,表示两个负号,负负得正
# 另外的一些运算符
下标运算符:[]
属性访问运算符:.
复合赋值运算符:+=、-=、*=、/=、//=、**=、|=、^= (|=和^=还不知道是什么意思)
a += 1 等价于 a = a+1
其他的也是类似的。
2.3 Python常用内置函数
前言:内置函数这部分用到的知识很多,不需要一次性全部掌握,但是对于这些函数,至少需要知道它们有什么功能,以及怎么使用。当需要实现某个功能时,能够想起某个内置函数能够实现这个功能就行了。这里将常用内置函数做个汇总,以后记不清楚用法可以来这里查找。
内置函数不需要额外导入任何模块,就可以直接使用,具有非常快的运行速度,推荐优先使用。
使用下面这个命令可以查看所有内置函数和内置对象
dir(__builtins__)

一、判断
1、判断iter中所有元素是否都与True等价 all(iterable,/)
如果可迭代对象中所有元素都等价于True则返回True,否则返回False
print(all([1, 2, 3])) # Ture
print(all([0,0,1])) # False
print(all([])) # Ture 为什么是T?
2、判断iter中是否存在元素与True等价 any(iterable,/)
只要可迭代对象iterable中存在等价于True的元素就返回True,否则返回False
print(any([1, 2, 3])) # Ture
print(any([0,0,1])) # Ture
print(any([0,0,0])) # False
print(any('abc')) # Ture
print(any([])) # False 为什么是F?因为空列表中不存在 等价于True的元素
3、判断x的值等价于True bool(x)
如果参数x的值等价于True就返回True,否则返回False
print(bool([])) # F
print(bool(0)) # F
print(bool([1])) # T
print(bool('0')) # T
4、判断obj是否为可调用对象 callable(obj,/)
如果obj为可调用对象就返回True,否则返回False。
Python中的可调用对象包括内置函数、标准库函数、扩展库函数、自定义函数、lambda表达式、
类、类方法、静态方法、实例方法、包含特殊方法__call__的类的对象
print(callable(int)) # Ture
print(callable('abc')) # False
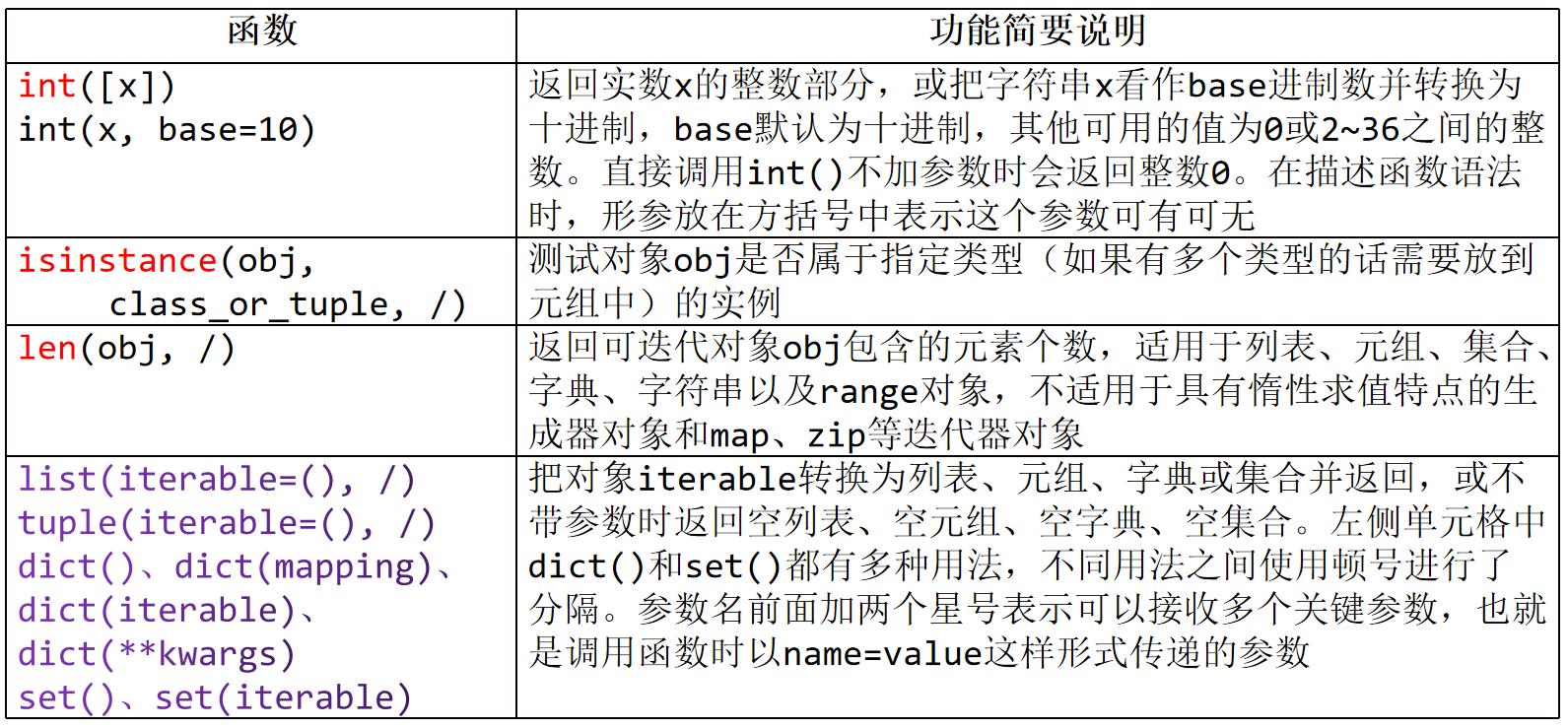
5、测试obj是否属于指定类型 isinstance(obj,class or tuple,/)
测试对象obj是否属于指定类型的实例(如果有多个类型的话需要放到元组中),返回值为bool类型
print(isinstance([1, 2, 3], list)) # True
print(isinstance((2), tuple)) # False
print(isinstance((2,), tuple)) # True
多种类型的话需要放在元组中,只要满足任意一种类型,就返回True
print(isinstance('abc',(list,tuple,str,))) # True
二、转换
1、bytes()
(0)字节对象的解释(不可变类型,与字符串相似)
print(type('abc'),type(b'abc')) # 'abc'时str对象,b'abc'是bytes对象
(1)创建空字节对象 bytes() or bytes(int)
参数为空或整形(2、8、10、16进制都可以),创建指定长度的0填充的字节对象
print(bytes()) # 创建一个空的字节对象
print(type(bytes())) # <class 'bytes'>
print(bytes(10)) # 创建10个字节的以0填充的字节对象 b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
print(bytes(0b11)) # 创建三个字节的以0填充的字节对象 b'\x00\x00\x00'
print(bytes(0xA)) # 创建10个字节的以0填充的字节对象 b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
(2)将iter中的每个元素转换为其对应的ASCII字符 bytes(iterable of ints)
参数为可迭代对象,将可迭代对象中的每个元素x(x为int且0<=x<=255),按照x的数值对应的ASCII码表的字符来显示
例如,x值为65(或0x41,或0b01000001),65对应的ASCII表中的字符为'A',那么转换为字节对象后,它表示为b'A'
但是,如果x的值对应的ASCII字符不可显示(如响铃,退格),那么就用16进制来表示它,如响铃(值为7)那么结果为b'\x07'
如果是换行符\n、制表符\t、回车符\r、退格符\b、换页符\f、反斜杠\、单引号'、双引号"这些容易产生混淆的特殊字符,那么也可能是用16进制来表示,但是用print输出时,会自动解码这些字节,并用其对应的字符表示。
print(bytes(range(10))) # 十进制值为0到9的ASCII字符(不可显示的用16进制表示)
print(bytes([0,1,2,3,4,5,6,7,8,32])) # 32对应的字符为Space空格
print(bytes(range(65,71))) # 65到70的ASCII字符
print(bytes([10, 9, 13, 8, 12, 92, 39, 34])) # 对应的特殊字符:换行符\n、制表符\t、回车符\r、退格符\b、换页符\f、反斜杠\、单引号'、双引号"
print(bytes([65,0b01000001,0x41])) # 字符A对应的三种进制的值
print(bytes([65]),bytes((66,))) # 也可以通过这样的方式转换单个字符,只要是可迭代对象都可以
输出结果:
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t'
b'\x00\x01\x02\x03\x04\x05\x06\x07\x08 '
b'ABCDEF'
b'\n\t\r\x08\x0c\\\'"'
b'AAA'
b'A' b'B'
(3)将字符串转换为字节序列 bytes(string,encoding[,errors])
将给定字符串转换为字节序列,encoding表示指定的字符编码方式
print(bytes('abc',encoding='UTF-8')) # b'abc'
print(bytes('字节序列',encoding='utf-8')) # b'\xe5\xad\x97\xe8\x8a\x82\xe5\xba\x8f\xe5\x88\x97'
在 Python 3.x 版本中,如果字符串中只包含 ASCII 码对应的字符,则 print 函数会直接输出这些字符而不会转换为 UTF-8 编码值。
(4)bytes(bytes or buffer)
通过缓冲区协议复制现有二进制数据(还没学过,略)
print(bytes(b'hello world')) # 使用一个 bytes 对象来创建一个新的 bytes 对象
2、进制转换
(1)转为2进制 bin(number,/)
返回整数number(number可以是十、八、十六进制等,下同)的二进制形式的字符串,例如表达式bin(5)的值是'0b101'
print(bin(520)) # 0b1000001000
print(bin(10)) # 0b1010
print(bin(0o10)) # 0b1000
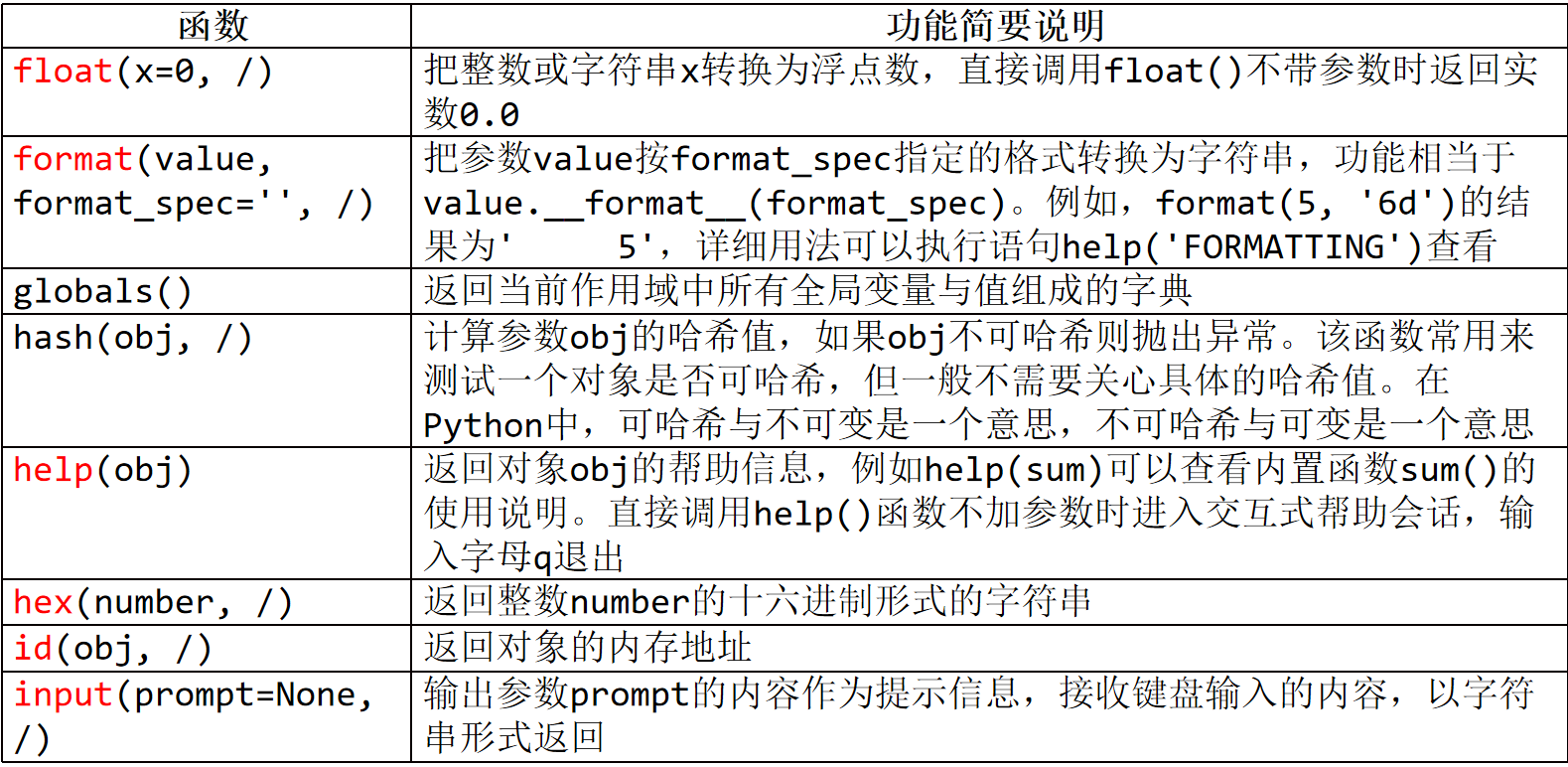
(2)转为16进制 hex(number,/)
返回整数number的16进制形式的字符串
print(hex(15)) # 0xf
print(hex(8)) # 0x8
print(hex(32)) # 0x20
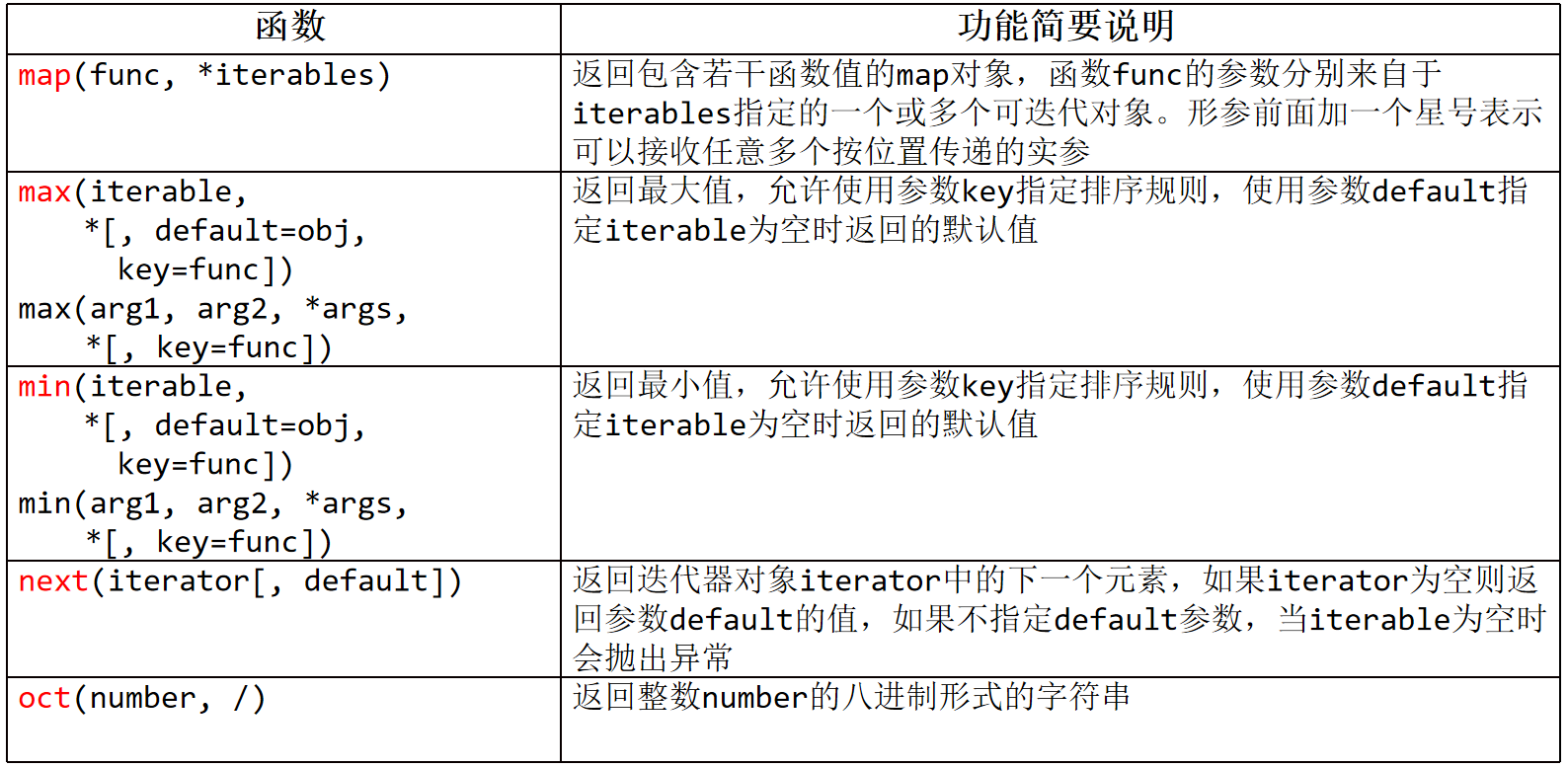
(3)转为8进制 oct(number,/)
返回整数number的8进制形式的字符串
print(oct(8)) # 0o10
print(oct(16)) # 0o20
print(oct(2)) # 0o2
转10进制是int()
3、字符编码转换
(1)返回单个字符的Unicode编码 ord(c,/)
返回字符串c的Unicode编码,c的长度为1,也就是一个字符
print(ord('刘')) # 21016
print(ord('a')) # 97
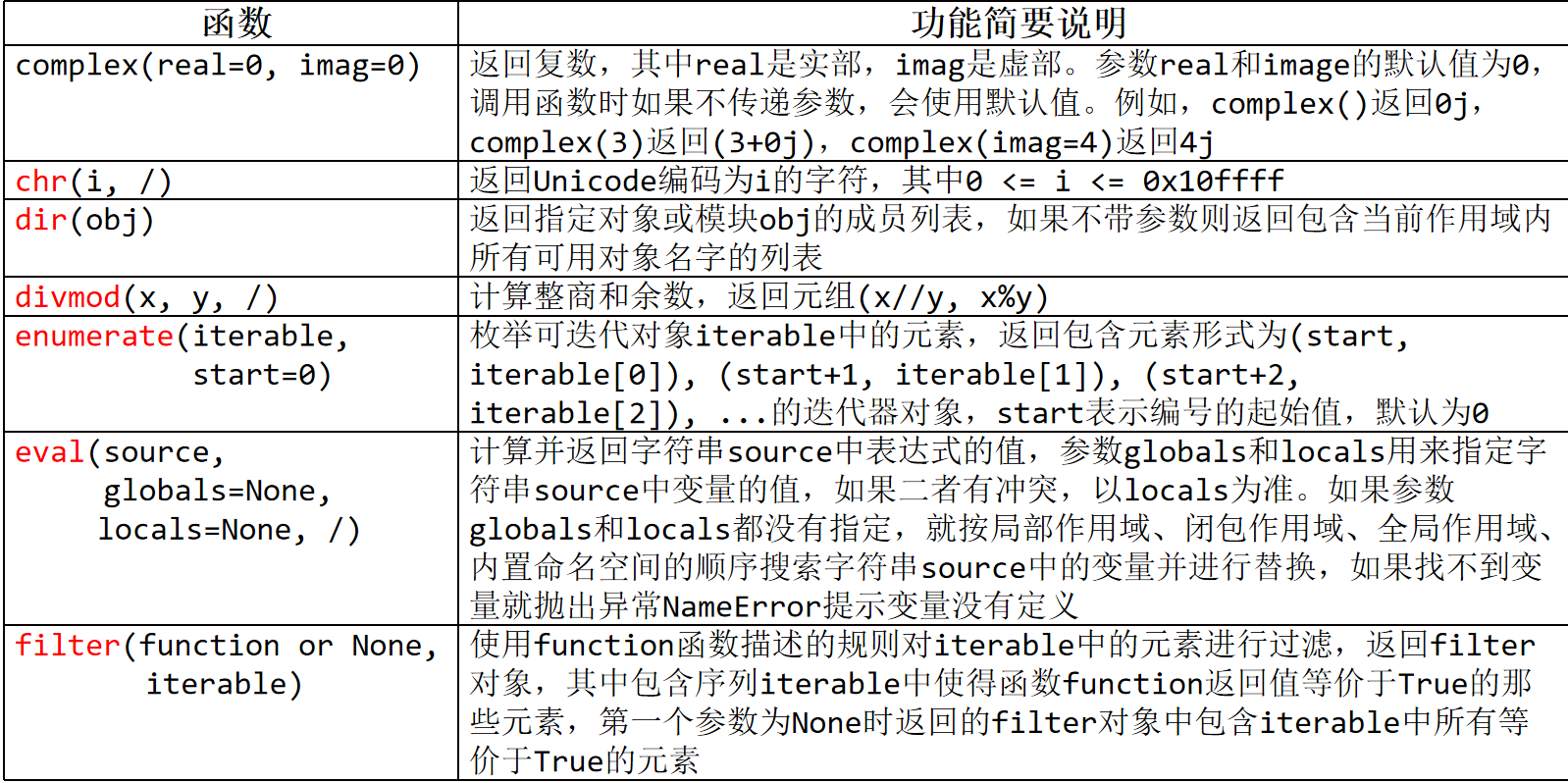
(2)返回指定Unicode编码对应的字符 chr(i,/)
返回Unicode编码为i的字符,(0<=0<-0x10ffff)(十进制1114111)
print(chr(21016))
print(chr(97))
print(chr(65))
print(chr(0x41))
print(chr(10)) # 换行符
输出结果:
刘
a
A
A
4、数据类型转换
(1)float(x=0,/)
把整数或字符串x转换为浮点数,不带参数时返回指数0.0
字符串x必须长得像浮点数或整数,比如像'数字'或'数字.数字'这样的字符串
print(float(10)) # 整数转为浮点数 10.0
print(float(1.23)) # 浮点数 1.23
print(float('1.23')) # 字符串转浮点数 1.23
print(float('123')) # 字符串转浮点数 123.0
print(float('10c')) # 报错 ValueError: could not convert string to float: '10c'
(2)int([x]) or int(x,base=10)
a、将数字或字符串转换为整数,字符串必须长得像整数,比如'数字'这种形式
print(int()) # 不带参数时返回整数0
print(int(10.123)) # 返回整数部分
print(int('123')) # 将字符串转换为整数
print(int('10.123')) # 报错 ValueError: invalid literal for int() with base 10: '10.123'
b、将x转换为十进制,用base指明x是几进制的数,
此时x的类型应为str | bytes | bytearray,base的值为0或2~36之间的整数
print(int('0xF',16)) # 将16进制转换为10进制
print(int('11',2)) # 将2进制转换为10进制
print(int('11',8)) # 将8进制转换为10进制
print(int('11',3)) # 将3进制转换为10进制
print(int(b'F',16)) # 将bytes的16进制转换位10进制
print(int(b'111',2)) # 将bytes的2进制转换位10进制
当base=0时,更具字符串的的前缀来判断字符串的进制,不是0b、0o、0x开头的就默认为10进制
print(int('0b111',base=0)) # 识别为2进制
print(int('0o10',base=0)) # 识别为8进制
print(int('0xA',base=0)) # 识别为16进制
print(int('123',base=0)) # 识别为10进制
print(int(b'0xA',base=0)) # 识别为16进制
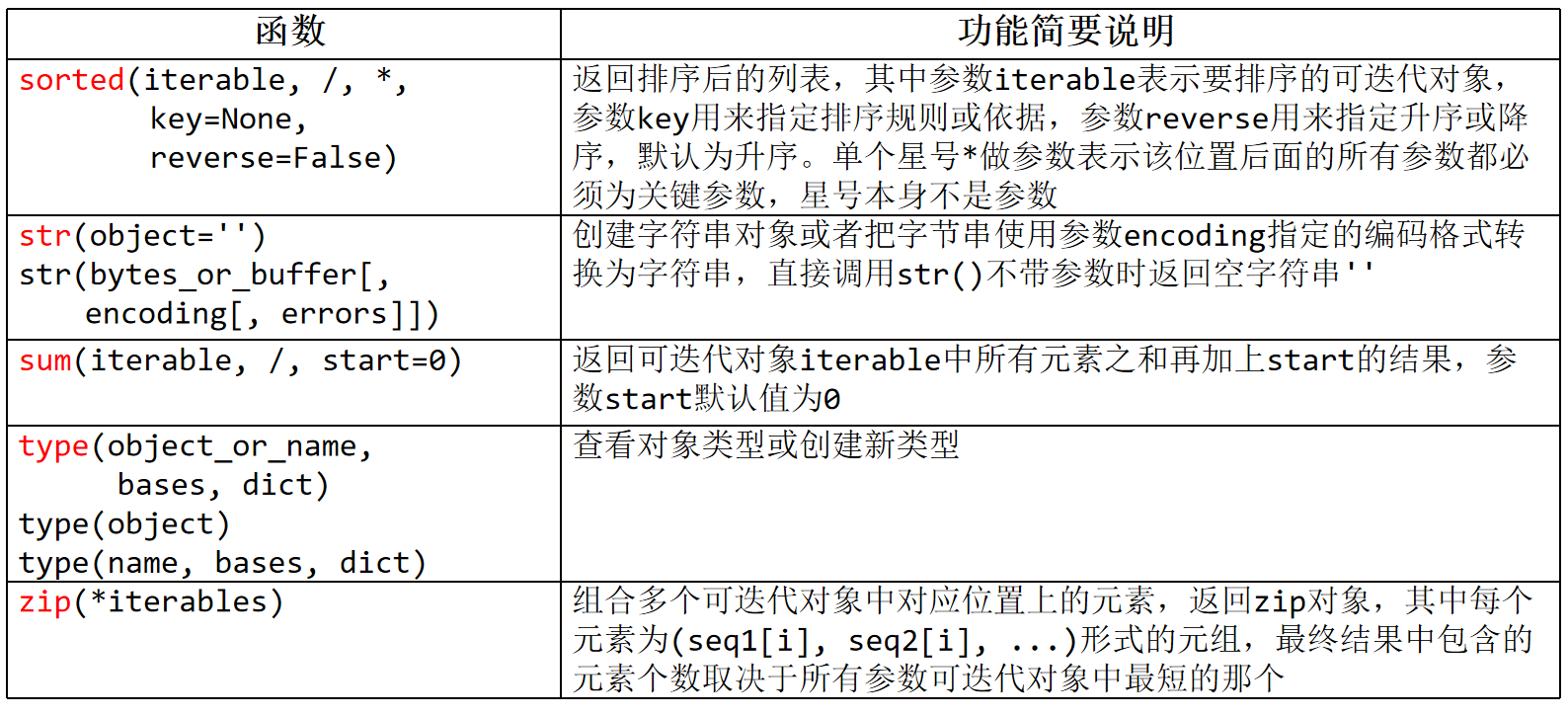
(3)str(object='') or str(bytes or buffer[,encoding[,errors]])
创建字符串对象或者把字节串使用参数encoding指定的编码格式转换为字符串,
直接调用str()不带参数时返回空字符串''
s1 = str() # 不带参数时返回空字符串
liu = bytes('刘','utf-8') # 将字符串用指定编码转换成字节串
print(liu) # b'\xe5\x88\x98'
s2 = str(liu,'utf-8') # 用指定编码将字节串转换为字符串
将其他类型转换为str
list_str = str([1,2,3]) # 将列表转换为字符串
tuple_str = str((1,2,3)) # 将元组转换为字符串
set_str = str({1,2,3,}) # 将集合转换为字符串
dict_str = str({1:[1,2]}) # 将字典转换为字符串
print(s1,type(s1)) # s1是空字符,打印时看不出来
print(s2,type(s2))
print(list_str,type(list_str))
print(tuple_str,type(tuple_str))
print(set_str,type(set_str))
print(dict_str,type(dict_str))
打印结果:
<class 'str'>
刘 <class 'str'>
[1, 2, 3] <class 'str'>
(1, 2, 3) <class 'str'>
{1, 2, 3} <class 'str'>
{1: [1, 2]} <class 'str'>
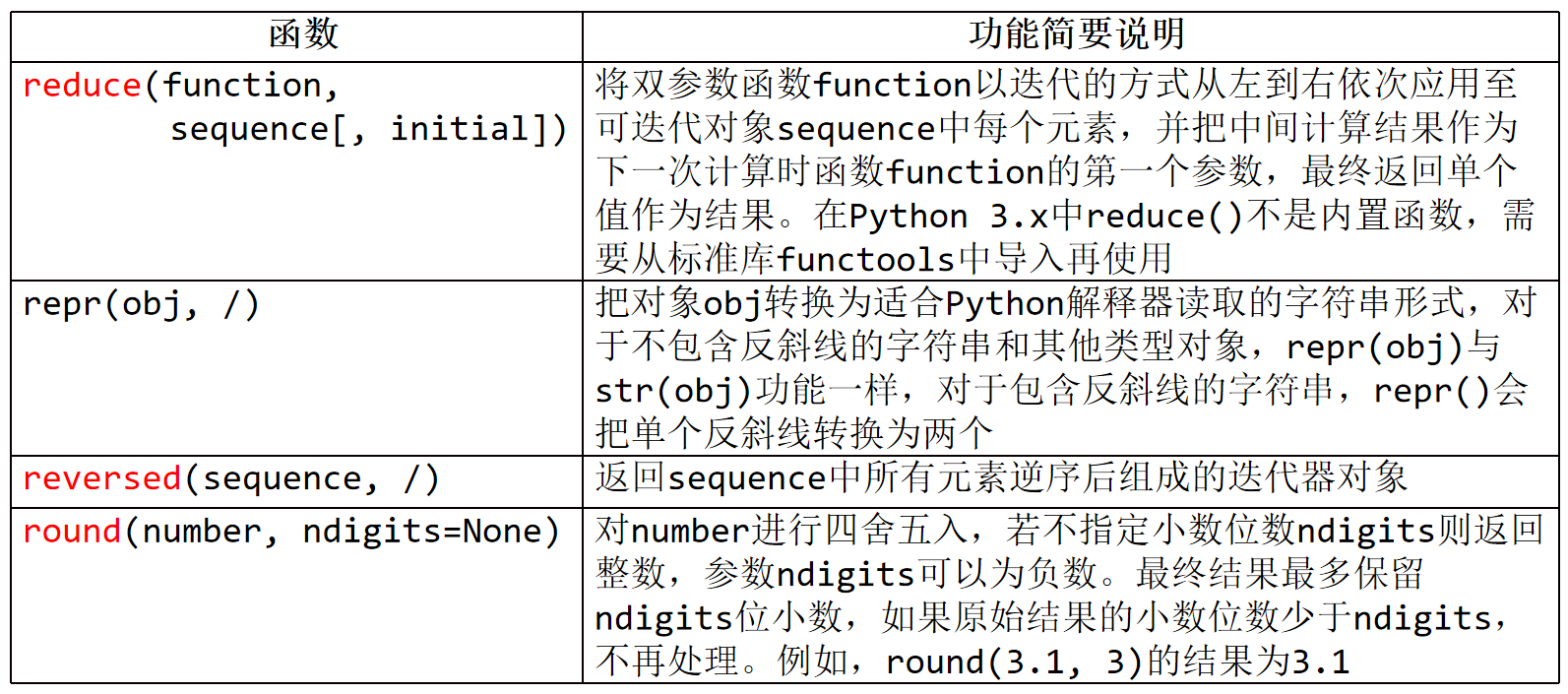
(4)repr(obj,/) 转为字符串
把对象obj转换为适合Python解释器读取的字符串形式,
对于不包含反斜线的字符串和其他类型对象,repr(obj)与str(obj)功能一样,
对于包含反斜线的字符串,repr()会把单个反斜线转换为两个
print(repr('Python实验\实验2-Python内置函数\实验2 Python内置函数.txt'))
print(str('Python实验\实验2-Python内置函数\实验2 Python内置函数.txt'))
输出结果:
'Python实验\\实验2-Python内置函数\\实验2 Python内置函数.txt'
Python实验\实验2-Python内置函数\实验2 Python内置函数.txt
(5)创建/转换为列表、元组、字典或集合
list(iterable=(),/)
tuple(iterable=())
dict()、dict(mapping)、dict(iterable)、dict(**kwargs)
set()、set(iterable)
把可迭代对象iterable转换为列表、元组、字典或集合并返回,
或不带参数时返回空列表、空元组、空字典、空集合。
参数名前面加两个星号表示可以接收多个关键参数,也就是调用函数时以name=value.这样形式传递的参数
print(list(range(5))) # 把可迭代对象转换成列表、元组、集合并返回
print(tuple(range(5)))
print(set(range(5)))
print(set([1,2,3]))
print(dict([(1,'noe'),(2,'two'),(3,'three')])) # 通过可迭代对象创建字典
print(dict(((1,'noe'),(2,'two')))) # 通过可迭代对象创建字典
print(dict(a=1,b=2,c=3)) # 通过关键字参数创建字典
print(dict({'a': 1, 'b': 2, 'c': 3})) # 通过映射创建字典
print(list(),tuple(),set(),dict()) # 不带参数时返回空列表、空元组、空集合、空字典。
输出结果:
[0, 1, 2, 3, 4]
(0, 1, 2, 3, 4)
{0, 1, 2, 3, 4}
{1, 2, 3}
{1: 'noe', 2: 'two', 3: 'three'}
{1: 'noe', 2: 'two'}
{'a': 1, 'b': 2, 'c': 3}
{'a': 1, 'b': 2, 'c': 3}
[] () set() {}
三、计算
1、abs(x,/)
返回数字x的绝对值或复数x的模
print(abs(-6)) # 6
print(abs(3 + 4j)) # 5
2、complex(real=0,imag=0)
返回复数,其中real是实部,imag是虚部。参数real和image的默认值为0
调用函数时如果不传递参数,会使用默认值。例如,complex()返回j,complex(3)返回(3+0j),complex(imag=4)返回4j
a=complex()
b=complex(3.4)
c=complex(3,4)
print(a,b,c) # 0j (3.4+0j) (3+4j)
3、divmod(x,y,/)
计算整商和余数,返回元组(x//y,x%y)
print(divmod(5,2)) # (2, 1)
print(divmod(5,9)) # (0, 5)
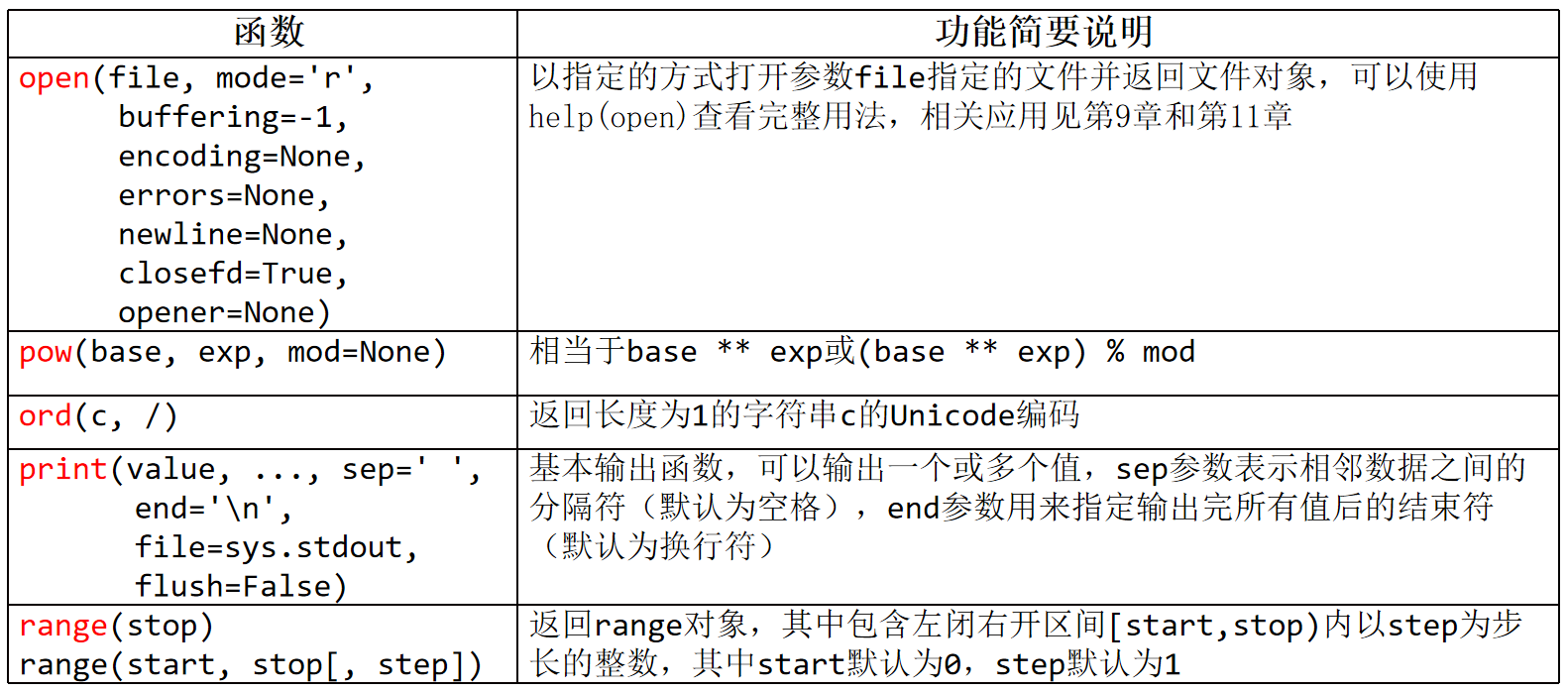
4、pow(base,exp,mod=None)
幂运算,相当于base**exp或(base**exp)%mod
print(pow(2,3)) # 2**3==8
print(pow(2,3,3)) # (2**3)%3
5、round(number,ndigits=None)
对number进行四舍五入,若不指定小数位数ndigits则返回整数,参数ndigits可以为负数。
最终结果最多保留ndigits位小数,如果原始结果的小数位数少于ndigits,不再处理。
print(round(3.96,)) # 不指定ndigits参数时返回整数(也是四舍五入)
print(round(3.14,1)) # 保留一位小数
print(round(1.78,1)) # 四舍五入
print(round(3.14,3)) # 原始结果的小数位数少于ndigits,不再处理
print(round(183.14,-1)) # 用负数进行舍入
print(round(183.14,-2)) # 用负数进行舍入
输出结果:
4
3.1
1.8
3.14
180.0
200.0
6、sum(iterable,/start=0)
返回可迭代对象iterable中所有元素之和,再加上start的结果,参数start默认值为0
print(sum([1, 2, 3, 4, 5])) # 15
print(sum((1, 2, 3, 4, 5),start=100)) # 115
7、eval(source,globals=None,locals=None,/)
计算并返回字符串source中表达式的值,参数globals和loca1s用来指定字符串source中变量的值
如果二者有冲突,以locals为准。如果参数globals和locals都没有指定,就按局部作用域、闭包作用域、全局作用域、内置命名空间的顺序(LEGB)搜索字符串source中的变量并进行替换,如果找不到变量就抛出异常NameError提示变量没有定义
(1)字符串表达式求值
a = eval('1+2+3+4')
b = eval('3**3')
c = eval('5/2')
d = eval('6%3')
print(a,b,c,d) # 10 27 2.5 0
e = eval('666') # 效果类似于将字符串转换为数字,但它可以判断字符串是int还是float类型,然后返回对应类型的值
f = eval('6.66')
print(e,f,type(e),type(f)) # 666 6.66 <class 'int'> <class 'float'>
print(eval('1+2'+'*2')) # 5
# 先将字符串'1+2'和'*2'拼接,变成'1+2*2'然后再计算。
(2)字符串表达式中使用变量名
位置参数globals和locals需要是映射类型(比如字典),globals必须是字典。globals和locals默认为当前全局变量和局部变量
这两个参数一般不指定,使用如果参数形式是字典时,key必须是str,value可以是任何东西
x,y,z = 1,2,3
g = eval('x+y+z') # 不指定
h = eval('x+y+z',{'x':10,'y':20,'z':30}) # 这里的修改并不会更改局部或全局变量的值
i = eval('x+y+z',globals()) # globals()返回的是一个字典,key为全局变量名,value为对应变量的值
j = eval('i-j',{'i':x,'j':y,'z':66}) # 可以把globals和locals参数当做是将字符串中的字符替换的作用
k = eval('i+j',{'i':'abc','j':'def'})
l = eval('x+y',{'x':x,'y':y},{'x':100}) # 两参数冲突时,以locals为准
print(f'g={g},h={h},i={i},j={j},k={k},l={l}') # g=6,h=60,i=6,j=-1,k=abcdef,l=102
8、hash(obj)
返回给定对象的哈希值。两个比较相等的对象也必须具有相同的哈希值,但反过来则不一定正确。
如果对象不可哈希,则会报错,一般用于判断对象是否可哈希。
print(hash(123))
print(hash(True)) # True==1,所以哈希值相同
print(hash(1))
print(hash(4567823484))
print(hash((4567823484,7854612))) # 计算元组的哈希值
print(hash([1,2,3])) # 报错,列表不可哈希
可变与不可变
不可变类型(可哈希):int整型、float浮点型、bool布尔类型、str字符串、tuple元组
不可变类型的特点是一旦创建,就无法再次修改,只能通过重新创建对象来改变其值。
可变类型(不可哈希):list列表、dict字典、set集合
可变类型的特点是可以对其进行增删改操作,即可以修改已经存在的对象。
注意:所有不可变类型在被修改时都会创建一个新的对象,并将变量名指向新对象。而原先的那个变量仍然还在内存中。
例如:
不可变类型
s1 = 'abc'
s2 = s1 # 相当于让s2也指向'abc'
print(id(s1),id(s2)) # 两者id(内存地址)相同
s1 = 'def' # 创建一个新对象,并让s1指向它
print(s1,s2) # 原来的对象'abc'并没有被修改。 def abc
print(id(s1),id(s2)) # id不同了
可变类型
l1 = [1,2,3]
l2 =l1 # l1和l2同时指向[1,2,3]
del l2[0] # 删除l2中的第0个元素
print(l1,l2) # l1和l2中的第0个元素都被删除了
print(id(l1),id(l2)) # 两者id仍然相同
9、len(obj,/)
返回可迭代对象obj包含的元素个数,适用于列表、元组、集合、字典、字符串以及range对象,
不适用于具有惰性求值特点的生成器对象和map、zip等迭代器对象
print(len([1, 2, [3, 4]])) # 3
print(len(range(10))) # 10
print(len({1,2,3,4,5,5,5})) # 5
10、reduce(function,sequence[,initial])
将双参数函数function以迭代的方式从左到右衣次应用至可迭代对象sequence中每个元素,
并把中间计算结果作为下一次计算时函数Function的第一个参数,最终返回单个值作为结果。
在Python3.x中reduce()不是内置函数,需要从标准库functools中导入再使用.
reduce()的参数:
function:用于累积操作的二元函数,它接受两个参数,其中第一个参数是上一次累积操作的结果,第二个参数是当前迭代的元素值。
iterable:一个可迭代对象,用于提供要累积的元素。
initializer(可选):用于初始化累积结果的可选参数。
reduce() 函数的工作过程如下所示:
1、reduce() 函数将可迭代对象中的第一个和第二个元素作为参数传递给指定的二元函数,并计算它们的结果。
2、reduce() 函数将上一步计算出的结果和可迭代对象中的第三个元素作为参数传递给指定的二元函数,并计算它们的结果。
3、重复上述过程,直到迭代完所有元素。最终的结果即为所有元素的累积结果。
from functools import reduce
计算1+2+3+4+5的值
print(reduce(lambda x, y: x + y, [1, 2, 3, 4, 5])) # 15
四、处理
1、enumerate(iterable,start=0)
枚举可迭代对象iterable中的元素,返回包含元素形式为(start,iterable[]),
(start+1,iterable[1]),(start+2,iterable[2])...的迭代器对象,start表示编号的起始值,默认为0
abc = enumerate(['a', 'b', 'c'], 1) # 返回enumerate的迭代器对象
print(list(abc),type(abc)) # [(1, 'a'), (2, 'b'), (3, 'c')] <class 'enumerate'>
2、filter(function or None,iterable)
使用function函数描述的规则对iterable中的元素进行过滤,返回filter对象,
其中包含序列iterable中使得函数Function返回值等价于True的那些元素,
第一个参数为None时返回的filter对象中包含iterable中所有等价于True的元素
fil1 = filter(None, [0, 0.0, 1, 3, True, False, [], (1,)]) # 第一个参数为None
print(fil1, list(fil1)) # 返回迭代器中值等价于True的元素[1, 3, True, (1,)]
fil2 = filter(lambda item: type(item) is int, [0, 1, 3, True, False, [], (1,)]) # 返回int类型的元素
fil3 = filter(lambda item: item>2, [0, 1, 3, True, False,]) # 返回大于2的元素
print(list(fil2),list(fil3)) # [0, 1, 3] [3]
注意:False0,True1
3、format(args)
格式化字符串
string.format(args) 其中,string 是待格式化的字符串,args 是一个或多个待填充到字符串中的值
a='my name is {},my age is {}.'.format('我呀',18) # 按位置传
print(a)
b='my name is {0}{0}{0},my age is {1}{1}{1}{0}{0}.'.format('我呀',18) # 按位置索引
print(b)
c='my name is {}{name}{name},my age is {age}{age}.'.format(123,name='我呀',age=18) # key=value
print(c)
d='{}{}{name}{age}'.format(123,456,name='我呀',age=18) # 混用
print(d)
e='10/3={:.1f},5/2={num},5/2={num:.2f}'.format(3.3333,num=2.5) # 指定精度
print(e)
打印结果:
my name is 我呀,my age is 18.
my name is 我呀我呀我呀,my age is 181818我呀我呀.
my name is 123我呀我呀,my age is 1818.
123456我呀18
10/3=3.3,5/2=2.5,5/2=2.50
格式化填充 {索引/key : 填充符号^><长度} # 长度不足时才采用填充符号填充
g='{0:*^8},,,{2:!>9}{1:#<7},{3:#<2}'.format('one','two','three','four') # ^两边,>左填,<右填
print(g)
h = '{name:=^10}'.format(name='我呀') # key=value
print(h)
打印结果:
**one***,,,!!!!threetwo####,four
====我呀====
4、map(func,*iterables)
返回包含若干函数值的map对象,函数func的参数分别来自于iterables指定的一个或多个可迭代对象。
形参前面加一个星号表示可以接收任意多个按位置传递的实参,可迭代对象有多个时,以长度最短的为准
a = map(lambda item: item + '娃哈哈', ['noe', 'two', 'three'])
print(list(a)) # ['noe娃哈哈', 'two娃哈哈', 'three娃哈哈']
b = map(lambda x,y:x+y,range(10),range(5)) # func接收多个参数,以长度短的为准(range(5))
print(list(b)) # [0, 2, 4, 6, 8]
上面的匿名函数lambda x,y:x+y等价于
def func(x,y):
return x+y
5、max() and min()
max(),返回最大值,允许使用参数key指定排序规则,使用参数default指定iterable为空时返回的默认值
max(iterable,*[default=obj,key=func])
max(arg1,arg2,*args,*[key=func])
min(),返回最小值,与max()类似
min(iterable,*[default=obj,key=func])
min(arg1,arg2,*args,*[key=func])
print(max([1, 2, 3, 4, 5]))
print(max([],default='对象为空'))
print(max(['apple','banana','orange',])) # 用字符串的比较规则进行比较
print(max(['apple','bananas','orange'],key=len)) # 以长度作为比较的依据,比较出最长的元素。
print(max(1,2,3,4,5.5,5,6,6.6))
print(max([1,2,3],[4,5])) # 比较的是列表中的对应的元素,然后返回大的那个列表
print(max((1,2,3),(0,5,6),(-1,66)))
输出结果:
5
对象为空
orange
bananas
6.6
[4, 5]
(1, 2, 3)
6、next(iterator[,default])
返回迭代器对象iterator中的下一个元素,如果iterator为空则返回参数default的值,
如果不指定default参数,当iterable为空时会抛出异常
l = [1,2,3,4,5,6,[7,8]]
iterator1 = l.__iter__() # __iter__()方法将可迭代对象生成迭代器,__ietr__()与iter()是等价的
print(next(iterator1))
print(iterator1.__next__()) # __next__()与next()是等价的
print(next(iterator1))
while True:
try:
print(iterator1.__next__())
except StopIteration: # 捕捉到StopIteration异常后执行下面缩进的代码
print('停止迭代StopIteration')
break
输出结果:
1
2
3
4
5
6
[7, 8]
停止迭代StopIteration
7、reversed(sequence,/)
返回sequence中所有元素逆序后组成的迭代器对象
a = reversed([1,2,3,4,5,6])
b = reversed((1,2,3,4,5,6))
print(list(a),list(b))
输出:[6, 5, 4, 3, 2, 1] [6, 5, 4, 3, 2, 1]
8、sorted(iterable, *, key=None, reverse=False)
返回一个新的排序后的列表,不会修改原始的可迭代对象。
参数:
iterable 表示要排序的可迭代对象,
key 是一个用于指定排序规则的函数,这个函数可以同时指定多种排序规则,例如先按长度再按字符排序。
reverse 是一个布尔值,表示是否要对结果进行反向排序,默认为 False。
fruits = ['banana', 'apple', 'orange', 'pear']
sorted_fruits = sorted(fruits) # 默认为从正向(从小到大)排序
print(sorted_fruits) # 输出:['apple', 'banana', 'orange', 'pear']
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_numbers = sorted(numbers, reverse=True) # 反向排序
print(sorted_numbers) # 输出:[9, 6, 5, 5, 5, 4, 3, 3, 2, 1, 1]
words = ['cat', 'dog', 'elephant', 'giraffe', 'ant']
sorted_words = sorted(words, key=len) # 以长度来排序
print(sorted_words) # 输出:['cat', 'dog', 'ant', 'giraffe', 'elephant']
words = ['cat', 'dog', 'elephant', 'giraffe', 'ant','zz']
sorted_words = sorted(words, key=lambda item: (len(item),item)) # 先以长度来排序,再按字符排序
print(sorted_words) # 结果['zz', 'ant', 'cat', 'dog', 'giraffe', 'elephant']
9、zip(*iterables)
组合多个可迭代对象中对应位置上的元素,返回zip对象,
其中每个元素为(seq1[i],seq2[i],...)形式的元组,
最终结果中包含的元素个数取决于所有可迭代对象参数中最短的那个
a = zip(range(1,6), ['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight'])
print(list(a)) # 结果取决于最短的那个
结果:[(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four'), (5, 'five')]
b = zip(range(1,6), ['one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight'],('一','二','三'))
print(list(b))
# 结果:[(1, 'one', '一'), (2, 'two', '二'), (3, 'three', '三')]
五、其他
1、globals()
返回当前作用域中所有全局变量与其值所组成的字典,只包含在globals()执行前就已经存在的变量
print(globals()) # 例如{'__name__':'__main__'}
globals()['a']=123 # 改变globals()字典时,会影响到全局名称空间的名称查找
print(globals()) # 字典中增加了'a':123
print(a) # 因为在globals()字典中添加了名称a,所以能够找到a这个变量。
2、locals()
返回当前作用域中所有局部变量与其值所组成的字典(与globals类似)
print(locals()) # 因为当前作用于就是全局,所以结果与globals()一样
def func():
a=666
print(globals()) # 返回的是全局的变量,与外面的globals()一样
print(locals()) # 局部作用域(func函数内)只有变量a。结果为{'a': 666}
func()
3、help(obj)
查看对象的帮助信息
print(help(input))
不加入参数时进入交互式回话,按q退出(输入q,然后回车),
交互式会话大概就是在help>提示符后输入对象名称,就会输出其帮助信息
help()
4、id(obj,/)
返回对象的内存地址
a = 123
print(id(a)) # print是以十进制输出的 1338396053552
5、input(prompt=None,/)
输出prompt的内容作为提示信息,接受键盘输入的内容,并以字符串的形式返回。
password = input('请输入你的密码:')
print(password,type(password)) # 123 <class 'str'>
6、print(value1,value2,...,sep=' ',end='\n')
基本输出函数,可以输出一个或多个值,
sep参数表示相邻数据之间的分隔符(默认为空格),end参数用来指定输出完所有值后的结束符(默认为换行符)
sep和end的类型都只能是str或None
print([1,2,3],'abc',sep='娃哈哈',end='结束') # [1, 2, 3]娃哈哈abc结束
7、open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
其中,各参数的含义如下:
file:要打开的文件名(包括路径)。可以是一个字符串或一个 bytes 对象(Python 3.x)。
mode:打开文件时的模式,常用的为 'r'(只读,默认值)、'w'(写入)、'a'(追加)、'x'(排它,创建一个新文件并写入)等。另外,还可以通过添加 'b'、't' 或 '+' 来指定文件是否以二进制模式打开、是否以文本模式打开以及是否同时支持读写等操作。
buffering:缓存大小,用于控制文件 I/O 的缓冲行为。当 buffering 等于 0(默认值)时,表示不缓冲;当为 1 时,表示使用默认缓冲方式(通常为全缓冲);当为正整数时,表示缓冲区大小(单位为字节);当为负数时,表示按照系统缓冲方式处理(通常为行缓冲)。
encoding:用于解码或编码文件内容的字符集。文件以文本模式打开时,该参数默认为 None,表示使用系统默认编码;文件以二进制模式打开时,该参数不起作用。
errors:指定编解码时的错误处理方式,常用的有 'strict'(默认值,表示遇到非法字符时抛出异常)、'ignore'(忽略非法字符)、'replace'(用 ? 取代非法字符)等。
newline:表示写入文件时的换行符,常用的有 '\n'(Unix/Linux)、'\r\n'(Windows)等。
closefd:当 open() 函数的 file 参数为一个整数类型的文件描述符(即通过 os.open() 等函数获得的)时,该参数确定是否在调用 close() 时同时关闭该文件。
opener:一个 Python 函数,用于打开文件时使用自定义的方法(一般很少用到,可以忽略)。
open()函数的返回值是一个文件对象,可以通过该对象进行文件的读写操作。
open()函数长与with语句一同使用,with用于自动关闭文件
with open(r'实验2 Python内置函数.txt',mode='rt',encoding='utf-8')as f: # as的作用是将open()的返回值赋值给f
res = f.read() # 一次性读取文件的所有内容并赋值给res
print(res)
8、range(start,stop[,step])
用于生成一系列连续的整数,返回range对象
star,stop,step分别为开始,结束,步长
左闭右开区间,顾头不顾尾,stop的值取不到。
print(list(range(10))) # 0到9的整数
print(list(range(0,10))) # 与range(10)等价
print(list(range(0,11,2))) # 0到11之间的偶数(不包含11)
print(list(range(10,0,-1))) # 10到0的整数(不包含0)
输出结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[0, 2, 4, 6, 8, 10]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
9、type(obj)
(1)返回obj对象的类型
print(type([1, 2, 3])) # <class 'list'>
print(type({1:'one'})) # <class 'dict'>
(2)创建新的类型
使用 type() 函数定义了一个名为 MyClass 的新类。
第一个参数指定了类名,第二个参数是一个元组,包含基类的类型对象,第三个参数是一个字典,包含类的成员变量和方法。
在这个例子中,我们定义了一个名为 x 的成员变量,其值为 42。
MyClass = type("MyClass", (object,), {"x": 42})
上面的代码等价于:
class MyClass(object): # 用这种方式更好一些
x = 42
2.4 Python关键字简要说明
前言:关键字没必要一次性全部记住,只需要达到,在用到时能够想起来,以及在代码中看到某个关键字是知道它的作用就可以了。
Python关键字只允许用来表达特定的语义,不允许通过任何方式改变它们的含义,也不能用来做变量名、函数名或类名等标识符。
在Python开发环境中导入模块keyword之后,可以使用print(keyword.kwlist)查看所有关键字。
import keyword
print(keyword.kwlist)

第三章、Python序列结构
前言:序列结构是重点,需要能够熟练的掌握每个序列结构的基础用法,以及它们各自的特性。
3.1 Python序列概述
3.2 列表
列表是最重要的Python内置对象之一,是包含若干元素的有序连续内存空间。
在形式上,列表的所有元素放在一对方括号[]中,相邻元素之间使用逗号分隔。
在Python中,同一个列表中元素的数据类型可以各不相同,可以同时包含整数、实数、字符串等基本类型的元素,也可以包含列表、元组、字典、集合、函数以及其他任意对象。如果只有一对方括号而没有任何元素则表示空列表。
[10, 20, 30, 40]
['crunchy frog', 'ram bladder', 'lark vomit']
['spam', 2.0, 5, [10, 20]]
[['file1', 200,7], ['file2', 260,9]] # 列表中嵌套列表
[{3}, {5:6}, (1, 2, 3)]
[] # 空列表
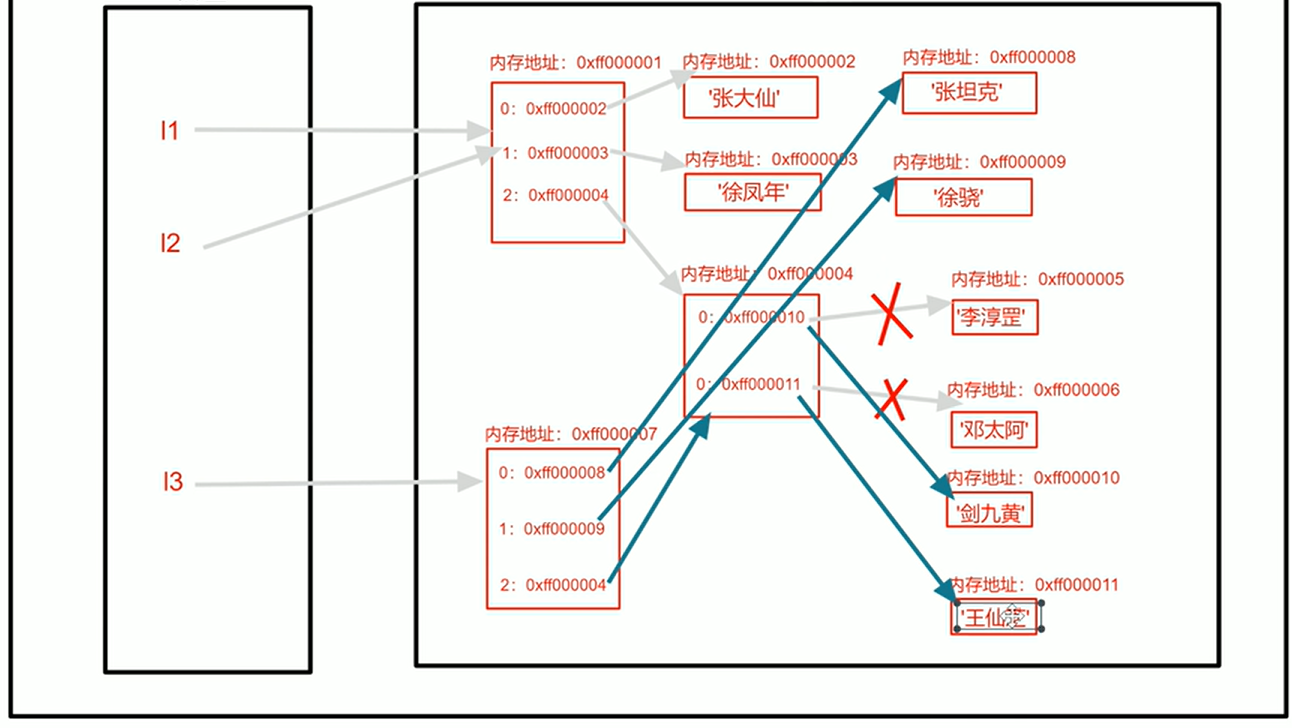
列表并不会存储元素的值,只会存储元素的索引和值的内存地址。值是在单独的内存空间中的。字典中的key也是如此。(这里在讲浅拷贝与深拷贝时会详细说明)
可以理解为列表就存的就是其元素的值的目录,具体内容并不存储在列表中。
列表存储的是值的内存地址以及其索引。真正的值存放在单独的内存空间。如下图:
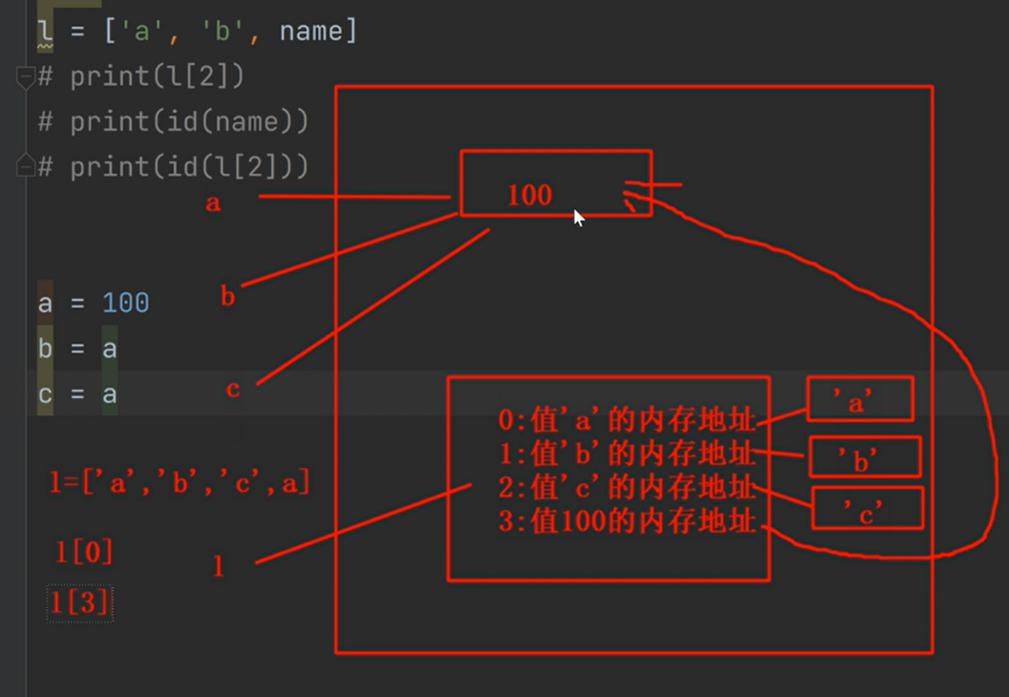
例子:
当变量name被重新赋值后,输出l[2],列表2号索引的值仍然是’张大仙‘,所以列表中存储的是name所指向的那个值的内存地址,也就是‘张大仙’这个值的内存地址。
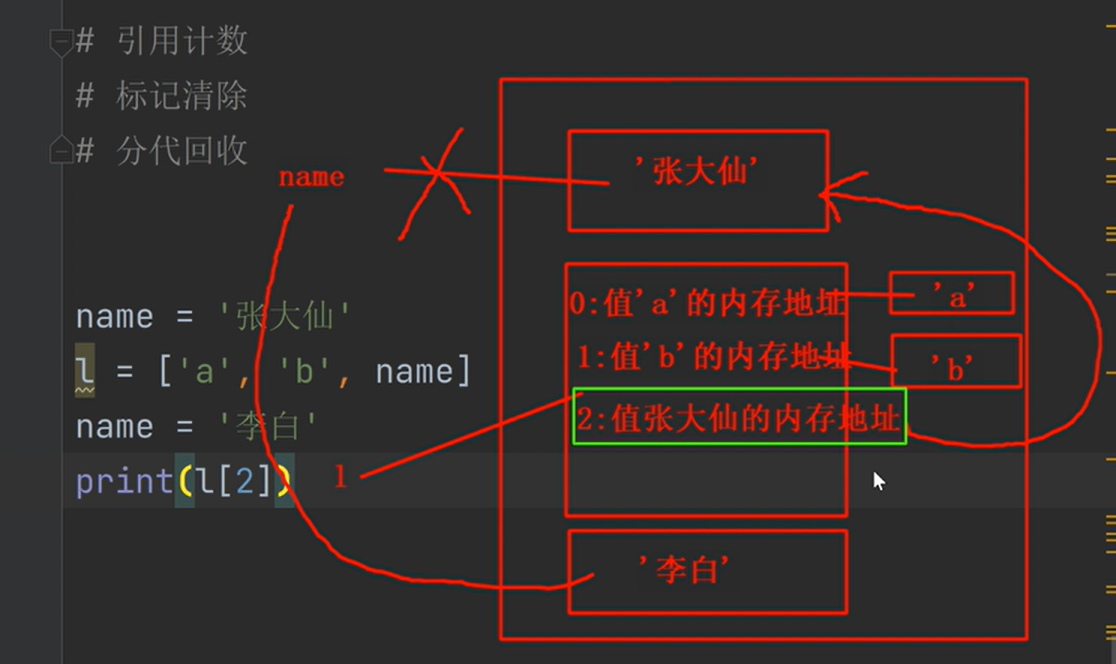
当name被重新赋值后,由于列表l中还有对‘张大仙’这个值的引用,所以这个值并不会被删除。
3.2.1 列表创建与删除
使用“=”直接将一个列表赋值给变量即可创建列表对象。
a_list = ['a', 'b', 'mpilgrim', 'z', 'example']
a_list = [] # 创建空列表
也可以使用list()函数把元组、range对象、字符串、字典、集合或其他有限长度的可迭代对象转换为列表。
list((3,5,7,9,11)) # 将元组转换为列表
[3, 5, 7, 9, 11]
list(range(1, 10, 2)) # 将range对象转换为列表
[1, 3, 5, 7, 9]
list('hello world') # 将字符串转换为列表
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
list({3,7,5}) # 将集合转换为列表
[3, 5, 7]
list({'a':3, 'b':9, 'c':78}) # 将字典的“键”转换为列表
['a', 'c', 'b']
list({'a':3, 'b':9, 'c':78}.items()) # 将字典的“键:值”对转换为列表
[('b', 9), ('c', 78), ('a', 3)]
list() # 创建空列表
[]
当一个列表不再使用时,可以使用del命令将其删除。
x = [1, 2, 3]
del x # 删除列表对象
x # 对象删除后无法再访问,抛出异常
NameError: name 'x' is not defined
3.2.2 列表元素访问
创建列表之后,可以使用整数作为下标来访问其中的元素,其中0表示第1个元素,1表示第2个元素,2表示第3个元素,以此类推;列表还支持使用负整数作为下标,其中-1表示最后1个元素,-2表示倒数第2个元素,-3表示倒数第3个元素,以此类推。
x = list('Python') # 创建列表x
print(x)
# ['P', 'y', 't', 'h', 'o', 'n']
x[0] # 下标为0的元素,第一个元素
'P'
x[-1] # 下标为-1的元素,最后一个元素
'n'
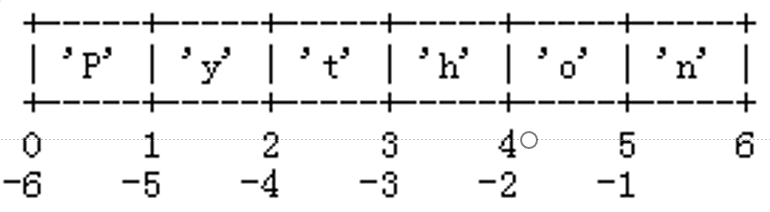
3.2.3 列表常用方法
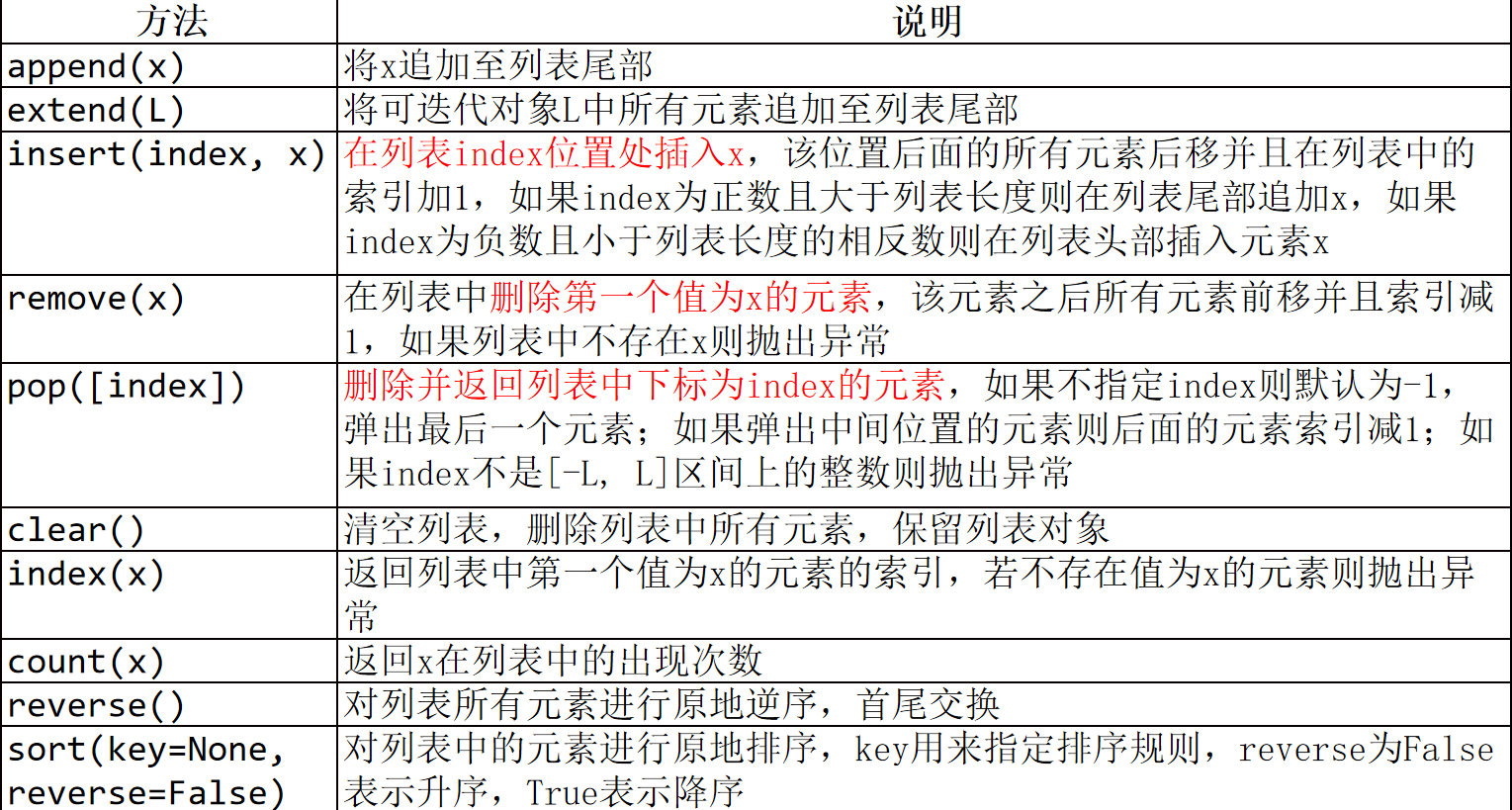
添加
1.append(x)
将x追加到列表的末尾
l = [1,2,3]
l2 = [3,4,5]
l.append(666)
print(l)
# [1, 2, 3, 666]
l.append(l2)
print(l)
# [1, 2, 3, 666, [3,4,5]]
2.exted(iterable)
将可迭代对象中的元素追加到列表
l1 = [1,2,3]
l2 = [4,5,6]
l1.extend(l2)
print(l1)
# [1, 2, 3, 4, 5, 6]
3.insert(index,x)
在列表index位置处插入x,该位置后面的所有元素后移并且在列表中的索引加1,如果index为正数且大于列表长度则在列表尾部追加x,如果index为负数且小于列表长度的相反数则在列表头部插入元素x
l = [1,2,3,4,5]
l.insert(1000,'插入列表尾部')
print(l)
# [1, 2, 3, 4, 5, '插入列表尾部']
l.insert(-1000,'插入列表头部')
print(l)
# ['插入列表头部', 1, 2, 3, 4, 5, '插入列表尾部']
l.insert(3,'插到索引为3的元素的位置,成为l[3]这个元素')
print(l)
# ['插入列表头部', 1, 2, '插到索引为3的元素的位置,成为l[3]这个元素', 3, 4, 5, '插入列表尾部']
l.insert(-2,'在倒数第二个位置插入')
print(l)
# ['插入列表头部', 1, 2, '插到索引为3的元素的位置,成为l[3]这个元素', 3, 4, '在倒数第二个位置插入', 5, '插入列表尾部']
删除
1.remove(x)
在列表中删除第一个值为x的元素,该元素之后所有元素前移并且索引减1,如果列表中不存在x则抛出异常
l = [1,2,3,1,2]
l.remove(1)
print(l)
# [2, 3, 1, 2]
5.del L
删除列表或其中的元素,
del 后跟一个变量名时,是解除变量名与它指向的那个值的绑定关系,当那个值的引用计数变为0时,将被删除,也起到了删除的作用。
l = ['a','b','c','d','e']
del l[3] # 删除元素'd'
print(l)
del l # 删除列表l
6.pop([index])
删除并返回列表中下标为index的元素,如果不指定index!则默认为-l,弹出最后一个元素;如果弹出中间位置的元素则后面的元素索引减1;如果index?不是[-L,L]区间上的整数则抛出异常
l = [1,2,3,1,2]
x = l.pop(4) # 删除并返回l[4]
print(x,l)
# 2 [1, 2, 3, 1]
y = l.pop() # 默认弹出最后一个
print(y,l)
# 1 [1, 2, 3]
7.clear()
清空列表,保留列表对象
l = [1,2,3,1,2]
l.clear()
print(l)
# []
查找
8.index(x)
返回列表中第一个值为x的元素的索引,若不存在值为x的元素则抛出异常
l = ['a','b','c']
print(l.index('b'))
# 1
print(l.index('bc'))
# ValueError: 'bc' is not in list
统计
9.count(x)
返回x在列表中出现的次数
l = [1,2,3,1,2]
print(l.count(1))
# 2
排序
10.reverse()
对列表所有元素进行原地逆序,首尾交换
l = [1,2,3,4,5,6]
l.reverse()
print(l)
# [6, 5, 4, 3, 2, 1]
11.sort(key=None,reverse=False)
对列表中的元素进行原地排序,key用来指定排序规则,reverse为False表示升序,True表示降序
l1 = [1,3,4,10,2,6,]
l1.sort() # 将l1按值的大小,从小到大排序
print(l1)
# [1, 2, 3, 4, 6, 10]
l2 = ['2sa','cccfd','123456','112','z']
l2.sort(key=len,reverse=True) # 将l2按长度降序排序
print(l2)
# ['123456', 'cccfd', '2sa', '112', 'z']
列表暂时掌握这些用法就可以了,后面遇到还会补充。
3.2.4 列表对象支持的运算符
加法运算符+也可以实现列表增加元素的目的,但不属于原地操作,而是返回新列表,涉及大量元素的复制,效率非常低。
>>> x = [1, 2, 3]
>>> id(x)
53868168
>>> x = x + [4] # 连接两个列表
>>> x
[1, 2, 3, 4]
>>> id(x) # 内存地址发生改变
53875720
>>> x += [5] # 为列表追加元素; x+=[5]等价于x=x+[5]
>>> x
[1, 2, 3, 4, 5]
>>> id(x) # 内存地址不变
53875720
乘法运算符*可以用于列表和整数相乘,表示序列重复,返回新列表。
>>> x = [1, 2, 3, 4]
>>> id(x)
54497224
>>> x = x * 2 # 元素重复,返回新列表
>>> x
[1, 2, 3, 4, 1, 2, 3, 4]
>>> id(x) # 地址发生改变
5460392
>>> x *= 2 # 元素重复,原地进行
>>> x
[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4]
>>> id(x) # 地址不变
54603912
成员测试运算符in可用于测试列表中是否包含某个元素,查询时间随着列表长度的增加而线性增加,同样的操作对于集合而言则是常数级的。
>>> 3 in [1, 2, 3]
True
>>> 3 in [1, 2, '3']
False
关系运算符可以用来比较两个列表的大小。
>>> [1, 2, 4] > [1, 2, 3, 5] # 逐个比较对应位置的元素,直到某个能够比较出大小为止
True
>>> [1, 2, 4] == [1, 2, 3, 5]
False
3.2.5 内置函数对列表的操作

3.2.6 列表推导式语法与应用案例
推导式也叫生成式、列表、字典、集合生成式,以及生成器在后面的序列结构总结中,会放在一起详细的讲。
列表推导式使用非常简洁的方式来快速生成满足特定需求的列表,代码具有非常强的可读性。
列表推导式语法形式为:
[expression for expr1 in sequence1 if condition1
for expr2 in sequence2 if condition2
for expr3 in sequence3 if condition3
...
for exprN in sequenceN if conditionN]
expression是添加到列表中的元素。
在列表推导式中可以使用if子句对列表中的元素进行筛选,只在结果列表中保留符合条件的元素。
列表推导式在逻辑上等价于一个循环语句,只是形式上更加简洁。例如:
aList = [x*x for x in range(10)]
# 相当于
aList = []
for x in range(10):
aList.append(x*x)
freshfruit = [' banana', ' loganberry ', 'passion fruit ']
aList = [w.strip() for w in freshfruit] # w.strip()的作用是将字符串w两端的空白字符去除
# 等价于下面的代码
aList = []
for item in freshfruit:
aList.append(item.strip())
例3-1 使用列表推导式实现嵌套列表的平铺。
vec = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
result = [num for elem in vec for num in elem]
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
在这个列表推导式中有2个循环,其中第一个循环可以看作是外循环,执行的慢;而第二个循环可以看作是内循环,执行的快。上面代码的执行过程等价于下面的写法:
vec = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
result = []
for elem in vec:
for num in elem:
result.append(num)
# [1, 2, 3, 4, 5, 6, 7, 8, 9]
例3-2 在列表推导式中使用if过滤不符合条件的元素。
在列表推导式中可以使用if子句对列表中的元素进行筛选,只在结果列表中保留符合条件的元素。
下面的代码可以列出当前文件夹下所有Python源文件:
# 因为使用了os模块,以及一些字符串的方法,所以理解起来可能有些吃力,现在看不懂没关系,只要理解了列表生成式的原理即用法就行了。
import os
l = [filename for filename in os.listdir('.') if filename.endswith(('.py', '.pyw'))]
os.listdir('.')的作用是返回一个列表,其中包含指定目录下的文件名。'.'代表当前文件所在目录。
filename.endswith('.py', '.pyw')的作用是判断字符串filename是否以'.py'或'.pyw'结尾,是则返回True
下面的代码用于从列表中选择符合条件的元素组成新的列表:
aList = [-1, -4, 6, 7.5, -2.3, 9, -11]
[i for item in aList if item>0] # 所有大于0的数字
[6, 7.5, 9]
下面的代码使用列表推导式查找列表中最大元素的所有位置。
>>> from random import randint
x = [randint(1, 10) for i in range(20)] # 20个介于[1, 10]的整数
# [10, 2, 3, 4, 5, 10, 10, 9, 2, 4, 10, 8, 2, 2, 9, 7, 6, 2, 5, 6]
m = max(x)
[index for index, value in enumerate(x) if value == m] # 最大整数的所有出现位置
# [0, 5, 6, 10]
enumerate(x)函数的功能是枚举可迭代对象x中的元素,返回类似(start+1,iterable[1]),(start+2,iterable[2])...的迭代器对象
例3-3 在列表推导式中同时遍历多个列表或可迭代对象。
[(x, y) for x in [1, 2, 3] for y in [3, 1, 4] if x != y]
# [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
[(x, y) for x in [1, 2, 3] if x==1 for y in [3, 1, 4] if y!=x]
# [(1, 3), (1, 4)]
对于包含多个循环的列表推导式,一定要清楚多个循环的执行顺序或“嵌套关系”。例如,上面第一个列表推导式等价于
result = []
for x in [1, 2, 3]:
for y in [3, 1, 4]:
if x != y:
result.append((x,y))
result
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
3.2.7 切片
在形式上,切片使用2个冒号分隔的3个数字来完成。
[start:end:step]
- 第一个数字start表示切片开始位置,默认为0(step>0时)或-1(step<0时);
- 第二个数字end表示切片截止(但不包含)位置(默认为列表长度);
- 第三个数字step表示切片的步长(默认为1)。
当start为0时可以省略,当end为列表长度时可以省略,当step为1时可以省略,省略步长时还可以同时省略最后一个冒号。
当step为负整数时,表示反向切片,这时start应该在end的右侧才行。
(列表、元组的切片操作与字符串的切片操作类似,可通过类比的的方法来进行学习。)
(1)使用切片获取列表部分元素
使用切片可以返回列表中部分元素组成的新列表。与使用索引作为下标访问列表元素的方法不同,切片操作不会因为下标越界而抛出异常,而是简单地在列表尾部截断或者返回一个空列表,代码具有更强的健壮性。
>>> aList = [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[::] # 返回包含原列表中所有元素的新列表 等价于aList[:::]
[3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[::-1] # 返回包含原列表中所有元素的逆序列表
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]
>>> aList[::2] # 隔一个取一个,获取偶数位置的元素
[3, 5, 7, 11, 15]
>>> aList[1::2] # 隔一个取一个,获取奇数位置的元素
[4, 6, 9, 13, 17]
>>> aList[3:6] # 指定切片的开始和结束位置
[6, 7, 9]
>>> aList[0:100] # 切片结束位置大于列表长度时,从列表尾部截断
[3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[100] # 抛出异常,不允许越界访问
IndexError: list index out of range
>>> aList[100:] # 切片开始位置大于列表长度时,返回空列表
[]
>>> aList[-15:3] # 进行必要的截断处理 等价于aList[0:3]
[3, 4, 5]
>>> len(aList)
10
>>> aList[3:-10:-1] # 位置3在位置-10的右侧,-1表示反向切片
# 这个列表的-10号索引等价于0号索引
[6, 5, 4]
>>> aList[3:-5] # 位置3在位置-5的左侧,正向切片
[6, 7]
(2)使用切片为列表增加元素
可以使用切片操作在列表任意位置插入新元素,不影响列表对象的内存地址,属于原地操作。
aList = [3, 5, 7]
aList[len(aList):]
[]
aList[len(aList):] = [9] # 在列表尾部增加元素
aList[:0] = [1, 2] # 在列表头部插入多个元素
aList[3:3] = [4] # 在列表中间位置插入元素
aList
[1, 2, 3, 4, 5, 7, 9]
(3)使用切片替换和修改列表中的元素
# 猜测:使用切片替换列表元素时,赋值号的右边应该要是一个可迭代对象才可
>>> aList = [3, 5, 7, 9]
aList[:3] = [1, 2, 3] # 替换列表元素,等号两边的列表长度相等
[1, 2, 3, 9]
aList[3:] = [4, 5, 6] # 切片连续,等号两边的列表长度可以不相等
[1, 2, 3, 4, 5, 6]
aList[::2] = [0]*3 # 隔一个修改一个
aList
[0, 2, 0, 4, 0, 6]
aList[::2] = ['a', 'b', 'c'] # 隔一个修改一个
aList
['a', 2, 'b', 4, 'c', 6]
>>> aList[1::2] = range(3) # 序列解包的用法
>>> aList
['a', 0, 'b', 1, 'c', 2]
>>> aList[1::2] = map(lambda x: x!=5, range(3))
>>> aList
['a', True, 'b', True, 'c', True]
>>> aList[1::2] = zip('abc', range(3)) # map、filter、zip对象都支持这样的用法
>>> aList
['a', ('a', 0), 'b', ('b', 1), 'c', ('c', 2)]
>>> aList[::2] = [1] # step不为1时等号两边列表长度必须相等
ValueError: attempt to assign sequence of size 1 to extended slice of size 3
(4)使用切片删除列表中的元素
>>> aList = [3, 5, 7, 9]
aList[:3] = [] # 删除列表中前3个元素
[9]
# 也可以结合使用del命令与切片结合来删除列表中的部分元素,并且切片可以不连续。
aList = [3, 5, 7, 9, 11]
del aList[:3] # 切片元素连续
[9, 11]
aList = [3, 5, 7, 9, 11]
del aList[::2] # 切片元素不连续,隔一个删一个
[5, 9]
3.3 元组
3.3.1 元组创建与元素访问
x = (1, 2, 3) # 直接把元组赋值给一个变量
type(x) # 使用type()函数查看变量类型
# <class 'tuple'>
x[0] # 元组支持使用下标访问特定位置的元素
# 1
x[-1] # 最后一个元素,元组也支持双向索引
# 3
x[1] = 4 # 元组中元素的数量和引用都是不可变的
# TypeError: 'tuple' object does not support item assignment
x = (3) # 这和x = 3是一样的
print(x)
# 3
x = (3,) # 如果元组中只有一个元素,必须在后面多写一个逗号
print(x)
(3,)
x = () # 空元组
x = tuple() # 空元组
tuple(range(5)) # 将其他迭代对象转换为元组
# (0, 1, 2, 3, 4)
3.3.2 元组与列表的异同点
- 列表和元组都属于有序序列,都支持使用双向索引访问其中的元素,以及使用count()方法统计指定元素的出现次数和index()方法获取指定元素首次出现的索引,len()、map()、filter()等大量内置函数和+、in等运算符也都可以作用于列表和元组。
- 元组属于不可变(immutable)序列,不可以修改元组中元素的引用,也无法为元组增加或删除元素。
- 元组没有提供append()、extend()和insert()等方法,无法向元组中添加元素;同样,元组也没有remove()和pop()方法,也不支持对元组元素进行del操作,不能从元组中删除元素,而只能使用del命令删除整个元组。
- 元组也支持切片操作,但是只能通过切片来访问元组中的元素,不允许使用切片来修改元组中元素的值,也不支持使用切片操作来为元组增加或删除元素。
- 元组占用内存比列表略少。如果定义了一系列常量值,主要用途仅是对它们进行遍历或其他类似用途,而不需要对其元素进行任何修改,那么一般建议使用元组而不用列表。
- 元组在内部实现上不允许修改,使得代码更加安全,例如调用函数时使用元组传递参数可以防止在函数中修改元组,而使用列表则很难保证这一点。
- 元组可用作字典的键,也可以作为集合的元素。列表不能当作字典键使用,也不能作为集合中的元素。
若元组中有可变类型的元素,那么仍然是可以更改可变类型的元素中的内容的,比如
tup = (1,2,[3,4])
tup[2][0] = 666 # 因为列表是可变类型,改变其内容时,它的地址不会改变,所以对于元组来说,2号索引的值并没有被改变。
print(tup)
# (1,2,[666,4])
# 现在理解不了没关系,只要知道可以怎么做就行。
3.4 字典
字典(dictionary)是包含若干“键:值”元素的无序可变序列,字典中的每个元素包含用冒号分隔的“键”和“值”两部分,表示一种映射或对应关系,也称关联数组。
定义字典时,每个元素的“键”和“值”之间用冒号分隔,不同元素之间用逗号分隔,所有的元素放在一对大括号“{}”中。一个键值对叫做字典的一个元素。
字典中元素的“键”可以是Python中任意不可变数据,例如整数、实数、复数、字符串、元组等类型等可哈希数据,但不能使用列表、集合、字典或其他可变类型作为字典的“键”。
字典中的“键”不允许重复,“值”是可以重复的。
3.4.1 字典的创建
使用赋值运算符“=”将一个字典赋值给一个变量即可创建一个字典变量。
aDict = {'server': 'db.diveintopython3.org', 'database': 'mysql'}
也可以使用内置类dict以不同形式创建字典。
x = dict() # 空字典
print(type(x)) # 查看对象类型
#<class 'dict'>
x = {} # 空字典
keys = ['a', 'b', 'c', 'd']
values = [1, 2, 3, 4]
dictionary = dict(zip(keys, values)) # 根据已有数据创建字典
d = dict(name='Dong', age=39) # 以关键参数的形式创建字典
aDict = dict.fromkeys(['name', 'age', 'sex'])# 以给定内容为“键”,创建“值”为空的字典
print(aDict)
# {'name': None, 'age': None, 'sex': None}
扩展:fromkeys的用法
fromkeys() 是字典(dict)的一个函数,用于创建一个新的字典。该方法会返回一个新的字典,并将键名列表中的每个键与默认值关联起来。
fromkeys() 方法可以接收两个参数,第一个参数是可迭代对象,其中的元素作为字典的键,第二个参数是该字典所有键对应的值的默认值(可以是任意类型,默认为None)。
keys = ['a', 'b', 'c']
value = 0
new_dict = dict.fromkeys(keys, value) # 这里的dict.通过类名来调用类下面的方法
new_dict = {}.fromkeys(keys, value) # 也可以用实例对象(这里以空字典为例)来调用
print(new_dict)
# 输出 {'a': 0, 'b': 0, 'c': 0}
上面代码中,我们创建了一个键名列表 keys,并将默认值 0 作为参数传入 fromkeys() 方法中。fromkeys() 方法返回了一个新的字典,并将键名列表中的每个键与默认值 0 关联起来,最终结果是 {'a': 0, 'b': 0, 'c': 0}。
需要注意的是,fromkeys() 方法并不会改变原有字典的内容,而是返回一个全新的字典对象。
3.4.2 字典元素的访问
字典中的每个元素表示一种映射关系或对应关系,根据提供的“键”作为下标就可以访问对应的“值”,如果字典中不存在这个“键”会抛出异常。
aDict = {'age': 39, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
print(aDict['age']) # 指定的“键”存在,返回对应的“值”
# 39
print(aDict['address']) # 指定的“键”不存在,抛出异常
# KeyError: 'address'
字典对象提供了一个get()方法用来返回指定“键”对应的“值”,并且允许指定该键不存在时返回特定的“值”(默认为空值None)。例如:
aDict.get('age') # 如果字典中存在该“键”则返回对应的“值”
print(aDict.get('age'))
# 39
print(aDict.get('address', 'Not Exists.')) # 指定的“键”不存在时返回指定的默认值
# 'Not Exists.'
使用字典对象的items()方法可以返回字典的键、值对。
使用字典对象的keys()方法可以返回字典的键。
使用字典对象的values()方法可以返回字典的值。
aDict = {'age': 39, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
print(aDict.keys())
print(aDict.values())
print(aDict.items())
# 结果如下:
dict_keys(['age', 'score', 'name', 'sex'])
dict_values([39, [98, 97], 'Dong', 'male'])
dict_items([('age', 39), ('score', [98, 97]), ('name', 'Dong'), ('sex', 'male')])
也可以对字典对象进行迭代或者遍历,默认是遍历字典的“键”,如果需要遍历字典的元素(即键值对)必须使用字典对象的 items0方法明确说明,如果需要遍历字典的“值”则必须使用字典对象的values0方法明确说明。
当使用 len()、max()、min()、sum()、sorted()、enumerate()、map()、filter()等内置函数以及成员测试运算符 in 对字典对象进行操作时,也遵循同样的约定。
aDict = {'age': 39, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
for key in aDict: # 默认遍历值
print(key,end=',')
# age,score,name,sex,
for value in aDict.values(): # 遍历值
print(value,end=',')
for key,value in aDict.items(): # 同时遍历键和值
print(key,value,end=', ')
# age 39, score [98, 97], name Dong, sex male,
for item in aDict.items(): # 变量字典的元素
print(item,end=',')
# ('age', 39),('score', [98, 97]),('name', 'Dong'),('sex', 'male'),
3.4.3 元素的添加、修改与删除
1.添加
当以指定“键”为下标为字典元素赋值时,有两种含义:
- 若该“键”存在,则表示修改该“键”对应的值;
- 若不存在,则表示添加一个新的“键:值”对,也就是添加一个新元素。
>>> aDict = {'age': 35, 'name': 'Dong', 'sex': 'male'}
aDict['age'] = 39 # 修改元素值
print(aDict)
{'age': 39, 'name': 'Dong', 'sex': 'male'}
aDict['address'] = 'SDIBT' # 添加新元素
print(aDict)
{'age': 39, 'name': 'Dong', 'sex': 'male', 'address': 'SDIBT'}
使用字典对象的update()方法可以将字典b的“键:值”一次性全部添加到a,如果两个字典中存在相同的“键”,则以字典b中的“值”为准,对当前字典a进行更新(也就是新的值会替换旧的值)。
aDict = {'age': 37, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
aDict.update({'a':97, 'age':39}) # 修改'age'键的值,同时添加新元素'a':97
print(aDict)
{'age': 39, 'score': [98, 97], 'name': 'Dong', 'sex': 'male', 'a': 97}
2.删除
如果需要删除字典中指定的元素,可以使用del命令。
aDict = {'age': 37, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
del aDict['age'] # 删除字典元素
print(aDict)
# {'score': [98, 97], 'name': 'Dong', 'sex': 'male', 'a': 97}
也可以使用字典对象的pop()和popitem()方法弹出并删除指定的元素,例如:
aDict = {'age': 37, 'score': [98, 97], 'name': 'Dong', 'sex': 'male'}
x = aDict.popitem() # 随即弹出一个元素,对空字典会抛出异常(其实并非随机,而是弹出最后一个加入到字典的值)
print(x)
# ('sex', 'male')
x = aDict.pop('age') # 弹出指定键对应的元素
print(x)
# 37
print(aDict)
# {'score': [98, 97], 'name': 'Dong'}
3.4.4 字典的应用案例
例3-4 首先生成包含 1000 个随机字符的字符串,然后统计每个字符的出现次数。
import string
import random
x = string.ascii_letters + string.digits
z = ''.join((random.choice(x) for i in range(1000))) # 将1000个字符拼接成一个字符串z
# 上面看不懂没关系,重点在下面的for循环
d = dict()
for ch in z: # 遍历字符串,统计频次
d[ch] = d.get(ch, 0) + 1 # 已出现次数加1,第二个参数是字典中没有ch时的返回值
for k, v in sorted(d.items()): # 获取d中的键值对,并对其进行遍历
print(k, ':', v) # 查看统计结果
对于上面的代码的解释:
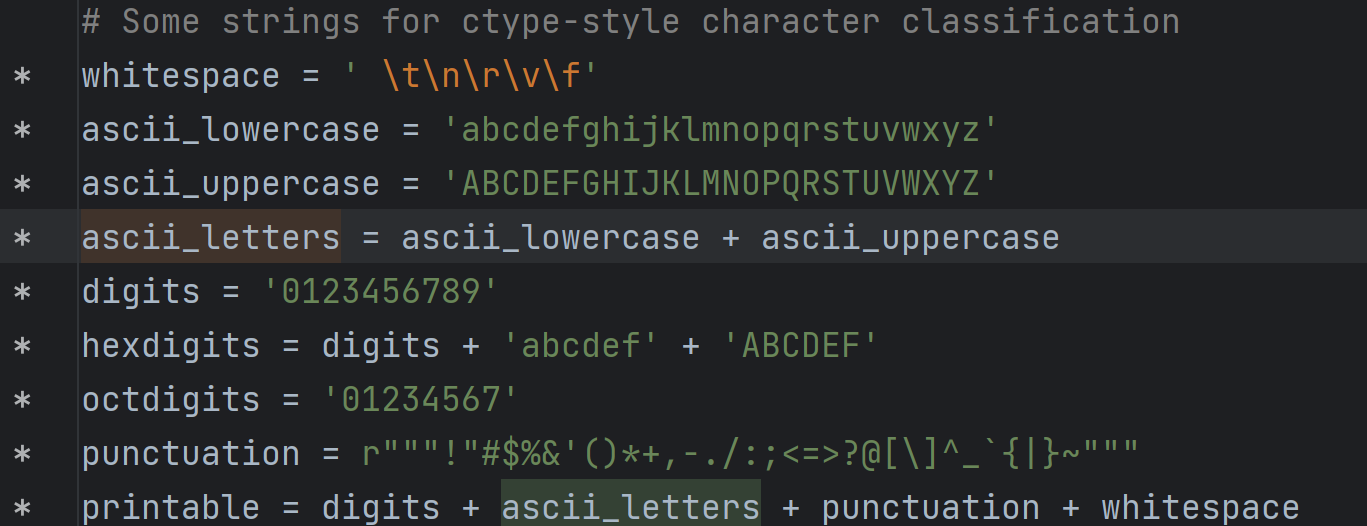
string.ascii_letters是一个包含英文字母大小写的字符串,即字符串'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'string.digits是0~9十个数字组成的字符串,即
'0123456789'所以x=='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'
下面这张图是string模块中中的代码。
z = ''.join((random.choice(x) for i in range(1000)))的含义是:从x中随机选出1000个字符(每次选一个,选了1000次),每个字符之间用空字符串''进行拼接,组成一个字符串,再赋值给z。
d[ch] = d.get(ch, 0) + 1的含义是:若字典d中没有ch,则将ch作为键添加到字典d中,其对应的值为1;若字典d中有ch,则将ch对应的值的值加1。d.get(ch, 0)的作用是获取d中键为ch的元素对应的值,若字典中没有ch,则返回0。
例3-5 字典排序
dic = {'张三':79,
'李四':66,
'王五':80}
# 方法一
l = list(sorted(dic.keys(),key=lambda item:dic[item],reverse=True))
i = 1
for name in l:
print(i,name,dic[name])
i +=1
# 方法二
res = sorted(dic.items(),key=lambda item:item[1],reverse=True)
i=1
for item in res:
print(i,item[0],item[1])
# 方法三
res = sorted(dic.items(),key=lambda item:item[1],reverse=True)
for i,tup in enumerate(res,1): # 枚举
print(i,tup[0],tup[1])
# 输出结果:
1 王五 80
2 张三 79
3 李四 66
3.5 集合
集合(set)属于Python无序可变序列,使用一对大括号作为定界符,元素之间使用逗号分隔,同一个集合内的每个元素都是唯一的,元素之间不允许重复。
集合中只能包含数字、字符串、元组等不可变类型(或者说可哈希)的数据,不能包含列表、字典、集合等可变类型的数据。
集合不能直接访问其中的元素,通常将集合作为一个整体进行操作。
3.5.1 集合对象的创建与删除
直接将集合赋值给变量即可创建一个集合对象。
a = {3, 5} # 创建集合对象
使用函数set()函数可将列表、元组、字符串、range对象等其他有限长度的可迭代对象转换为集合,如果原来的数据中存在重复元素,则在转换为集合的时候只保留一个;如果原序列或迭代器对象中有不可哈希的值无法转换成为集合,抛出异常。
a_set = set(range(8, 14)) # 把range对象转换为集合
print(a_set)
# {8, 9, 10, 11, 12, 13}
b_set = set([0, 1, 2, 3, 0, 1, 2, 3, 7, 8]) # 转换时自动去掉重复元素
print(b_set)
# {0, 1, 2, 3, 7, 8}
x = set() # 空集合
print(x,type(x))
# set() <class 'set'>
3.5.2 集合操作与运算
1、集合元素增加与删除
(1)增加
add()方法可以增加新元素(元素需要是不可变类型),如果该元素已存在则忽略该操作,不会抛出异常;
s = {1, 2, 3}
s.add(3) # 添加元素,重复元素自动忽略
print(s)
# {1, 2, 3}
s.add((1,2,3)) # 添加一个元素,这个元素是一个元组
print(s)
# {1, 2, 3, (1, 2, 3)}
update()方法用于合并另外一个集合中的元素到当前集合中,并自动去除重复元素。
s.update({3,4}) # 更新当前字典,自动忽略重复的元素
print(s)
# {1, 2, 3, 4}
(2)删除
-
pop()方法用于随机删除并返回集合中的一个元素,如果集合为空则抛出异常;
-
remove()方法用于删除集合中的指定元素,如果指定元素不存在则抛出异常;
-
discard()用于从集合中删除一个特定元素,如果元素不在集合中则忽略该操作;
-
clear()方法清空集合删除所有元素。
et1 = {0, 1, 2, 3, 7, 8}
set2 = set()
x = set1.pop() # 随机删除并返回一个元素
print(x)
# 0
# set2.pop() # 集合为空,抛异常(从一个空集合中弹出)
# KeyError: 'pop from an empty set'
set1.remove(8) # 删除元素8
print(set1)
# {1, 2, 3, 7}
# set1.remove(10) # 元素10不存在,抛异常
# KeyError: 10
set1.discard(2) # 删除元素2
print(set1)
# {1, 3, 7}
set1.discard(10) # 集合中不存在10,忽略操作
print(set1)
# {1, 3, 7}
set1.clear() # 清空集合
print(set1)
# set() # 空集合
2、集合运算
my_hobbies = {'吃饭','睡觉','追剧','打游戏','滑板','听小说'}
her_hobbies = {'吃饭','睡觉','追剧','听歌'}
取交集 & .intersection()
common_hobbies = my_hobbies & her_hobbies
print(common_hobbies)
# {'睡觉', '追剧', '吃饭'}
取并集 | .union()
print(my_hobbies | her_hobbies)
# {'听歌', '追剧', '吃饭', '听小说', '打游戏', '睡觉', '滑板'}
取差集 - .difference()
A-B的结果为A除去A&B
记:A除去A与B共有的
print(my_hobbies - her_hobbies)
# {'打游戏', '滑板', '听小说'}
print(her_hobbies - my_hobbies)
# {'听歌'}
对称差集 ^ .symmetric_difference()
A^B的结果是A中有,B中没有的元素,并上B中有,A中没有的元素。
记:两者各自独有的
print(my_hobbies - her_hobbies | her_hobbies - my_hobbies)
print(her_hobbies ^ my_hobbies) # 两者等价
# {'打游戏', '滑板', '听歌', '听小说'}
父子集,即包含关系 父集.issuperset(),子集.issubset()
# A.issuperset(B),B是A的子集吗? A.issubset(B),A是B的子集吗?
# 两者相等,互为父子,结果都为Ture
s1 = {1,2,3}
s2 = {1,2,3}
s3 = {1,2,5}
s4 = {1,2}
print(s1 > s4) # T s4是s1的真子集吗?(s1真包含于s2)
print(s1 > s2) # F s2是s1的真子集吗?
print(s1 >= s2) # T s2是s1的子集吗?
print(s1 <= s2) # T s1是s2的子集吗?
print(s1.issuperset(s2)) # T s2是s1的子集吗?
print(s2.issubset(s3)) # F s2是s3的子集吗?
update 更新
将可迭代对象中的元素加入到集合中,相同元素只保留一个。(可迭代对象中的元素必须是不可变类型)
s1 = {2,4,5,6}
s2 = {1,2,3,9}
s1.update(s2) # 将s1更新为s1和s2的并集
print(s1)
# {1, 2, 3, 4, 5, 6, 9}
s3 = {111,222,333}
s3.update([111,666,999]) # 将列表中的元素加入到s3中
print(s3)
# {111,222,333,111,666,999}
# .union/intersection/difference/symmetric_difference/update()
# 取 并 交 差 对称差 并更新
s1 = {1,2,3,4}
s2 ={3,4,5}
s1.intersection_update(s2) # 将集合s1更新为s1与s2的交集
s1 = s1.intersection(s2) # 与上面的代码等价
# 同理
s1.difference_update(s2) # 取差集并更新
s1.symmetric_difference_update(s2) # 取对称差集并更新
并集.union()没有union_update()
.isdisjoint() 判断两个集合是否有交集
# .isdisjoint()判断两个集合是否有交集
s1 = {1,2,3,4}
s2 ={3,4,5}
s1.isdisjoint(s2) # 判断s1和s2是否有交集,有则返回True
3.5.3 集合应用案例
例3-5
使用集合快速提取序列中单一元素,即提取出序列中所有不重复元素。
import random
# 生成100个介于0到9999之间的随机数
listRandom = [random.choice(range(10000)) for i in range(100)]
newSet = set(listRandom)
print(newSet)
例3-6 返回指定范围内一定数量的不重复数字。
import random
def randomNumbers(number, start, end):
'''使用集合来生成number个介于start和end之间的不重复随机数'''
data = set()
while len(data)<number: # 如果集合元素小于number个,那就进行生成随机数,添加到集合中
element = random.randint(start, end) # 生成随机数
data.add(element) # 添加到集合,若集合中已存在元素element,则加了等于没加
return data
data = randomNumbers(10, 1, 100)
print(data)
例3-7 测试指定列表中是否包含非法数据。
import random
# 。。。这个看不懂它是要干嘛。。。。略过
lstColor = ('red', 'green', 'blue')
colors = [random.choice(lstColor) for i in range(10000)] # 从lstColor中随机取出一个元素,放到列表中,取10000次,列表中有10000个元素。
if (set(colors)-set(lstColor)): # 转换为集合之后再比较
print('error') # 两集合差集不为空
else:
print('no error')
3.6 序列结构总结
3.6.1 序列结构的类型与分类
-
序列结构类型
- 容器类型:列表、元组、字典、集合
- 标量、原子类型:整型、浮点型、字符串
-
按照可变与不可变划分
-
可变类型:列表、字典、集合
-
不可变类型:整型、浮点型、字符串、元组
-
-
按照访问方式区分
-
通过变量名访问:整型、浮点型
-
通过索引访问指定的值(序列类型):字符串、列表、元组
-
通过key访问指定的值(映射类型):字典
-
通过变量名访问整体(无法访问某一个值):集合
-
3.6.2 生成式与生成器
由于列表生成式与字典、集合生成式,都差不多,所以着重说一说列表生成式,其他的类比即可。
列表生成式
列表生成式的格式:
列表 = [结果 for item in 可迭代对象 if 条件] # if可有可无,默认条件成立
- 结果可以是变量、常量、函数等,也可以是一个列表生成式,只要最终能产生一个值就可以
- if 条件不写的话默认为True
列表生成式的执行过程如下:
ls = [i**2 for i in range(6) if i%2==1] # 以这个为例
print(ls) # [1, 9, 25]
- 遍历可迭代对象,从中取出第一个值,复制赋值给i
- 判断if后的条件,若条件成立,则将左侧的结果(本例中为i**2)放入到列表ls中。若条件不成立,则不放入列表。
- 进入下一次循环,取出可迭代对象的下一个值,继续重复步骤1和2,直到for循环结束。
下面说些例子:
# 以函数作为列表生成式中的“结果”
def f(s):
if s.endswith('型'): # 如果字符串s以'型'结尾,则返回True
new_l.append(s) # 将以以'型'结尾的字符串加入到new_l中
return 6 # 返回值为6,下方列表生成式
l = ['列表', '元组', '字典', '字符串', '整型', '浮点型']
new_l = []
ls = [f(i) for i in l] # “结果”可以是个函数,调用函数并将函数的返回值添加到列表中
print(ls) # [6, 6, 6, 6, 6, 6] # l中有6个元素,f()被调用了6测,每次都将返回值放入到列表ls中
print(new_l) # ['整型', '浮点型']
# 列表生成式的嵌套
l1 = [[i for i in range(10) if i >6] for _ in range(3)] # 与for循环一样,如果不许要用到可迭代对象中取出的值,可以在i的位置填下划线_
print(l1)
# 等价于
l2 = []
for _ in range(3): # 外层循环相当于[l2_item for _ in range(3)]
l2_item = []
for i in range(10): # 内层循环相当于[i for i in range(10) if i >6]
if i >6:
l2_item.append(i)
l2.append(l2_item)
print(l2)
集合生成式
l = ['列表', '元组', '字典', '字符串', '整型', '浮点型']
tup = {i for i in l}
print(tup, type(i))
字典生成式
字典生成式与其他生成式的区别就是,“结果”中需要有两个值,两个值之间用冒号分隔开。只有一个值的话,是集合生成式。
l = [('列表', 1), ('元组', 2), ('字典', 3), ('字符串', 4), ('整型', 5), ('浮点型', 6)]
dic = {key: value for key, value in l}
print(dic, type(dic)) # {'列表': 1, '元组': 2, '字典': 3, '字符串': 4, '整型': 5, '浮点型': 6} <class 'dict'>
dic2 = {i:None for i in range(5)}
print(dic2) # {0: None, 1: None, 2: None, 3: None, 4: None}
d = {s:chr(s) for i in range(65,65+26)} # 值为大写字母,键为值对应的ASCII码值
生成器表达式
元组是不可变类型,不能往里添加值,所以元组是没有生成式的。下面使用小括号括起来的叫生成器表达式。
生成器表达式的结果是一个生成器对象。生成器对象类似于迭代器对象,具有惰性求值的特点,只在需要时生成新元素,并且每个元素只生成一次,空间占用非常少,尤其适合大数据处理的场合。
res = (i for i in range(4)) # 生成器表达式
print(res) # res是一个生成器对象
# <generator object <genexpr> at 0x000001FAD2886180>
print(next(res)) # 使用next()方法来获取生成器中的值 0
print(res.__next__()) # 使用next()方法来获取生成器中的值 1
print(res.send(None)) # 也可以使用send方法 2
print(res.send(12342453)) # 也可以使用send方法 3
print(res.send(12342453)) # 值取完后,抛StopIteration异常
res = (ch for ch in 'hello world')
l = list(res) # 可以使用list(),tuple()等方法将生成器对象转换为列表或元组
print(l)
print(res.__next__()) # 由于在转换的过程中,生成器中的值已经全部被取出来了,所以此时抛出StopIteration异常
访问生成器中的值时,只能从前往后正向访问每个元素,没有任何方法可以再次访问已访问过的元素,也不支持使用下标访问其中的元素。当所有元素访问结束以后,如果需要重新访问其中的元素,必须重新创建该生成器对象,enumerate、filter、map、zip等其他迭代器对象也具有同样的特点。
注意:生成器本身是没有值的,只有调用时,才会执行一次生成器表达式中的for循环,然后取出一个值来,再调用一次再执行for循环。。。
当然,除了使用next()方法,也可以使用for循环迭代取出生成器对象中的元素
g = ((i+2)**2 for i in range(10))
for item in g: # 使用循环直接遍历生成器对象中的元素
print(item, end=' ')
# 4 9 16 25 36 49 64 81 100 121
生成器对象中每个元素只能使用一次,访问过的元素不再存在,filter对象、map对象以及其他迭代器对象也具有同样的特点。
x = filter(None, range(10)) # filter对象也具有类似的特点
# x中包含有1, 2, 3, 4, 5, 6, 7, 8, 9这十个有序序列,访问时从前往后访问
print(3 in x) # 依次访问x中的元素,直到找到3这个元素(返回True),或访问完所有元素(都没找到返回False)
True
print(4 in x) # 上一条语句访问到了元素3,现在继续访问下一个元素,也就是4,返回True
True
print(2 in x) # 执行完上面两条语句后,元素1,2,3,4,都已经被访问过了,继续往后访问,直到将剩下所有元素访问都没有找到2,返回False
False
print(5 in x) # 由于所有元素都被访问过了,所以x中是空的,返回False
False
x = map(str, range(20)) # map对象也具有类似的特点
print('0' in x)
# True
print('0' in x) # 不可再次访问已访问过的元素
# False
思考:使用一个可迭代对象创建一个生成器后,使用for循环对生成器迭代取值时,改变可迭代对象,生成器会怎样?
案例:统计文件字符数
with open(r'date\read.txt', mode='rt', encoding='utf-8') as f:
# 方案一:使用for循环读取每一行内容,并统计字数。缺点是不够简洁,需要写四行代码
'''
size = 0
for line in f:
size += len(line)
'''
# 方案二:使用列表生成式将每一行的字符数都放在列表里,再对列表求和
'''
size = sum([len(line) for line in f]) # 如果文件行数很多时,列表所占的空间也会很大
'''
# 方案三:将使用生成器,来统计字符数,一次读一行,内存中每次只有一行的内容和字符长度。
# size = sum((len(line) for line in f)) # 生成一个生成器,减少内存占用
size = sum(len(line) for line in f) # 这种情况下,可将生成器表达式的()去掉
print(size)
深浅拷贝
普通赋值
ls1 = ['肖宫', '万叶', '班尼特', ['钟离', '托马', '莱伊啦']]
# ls2=ls1 完全使用同一地址(改变任意一个的内容,另一个都会跟着改变)
浅拷贝copy()
这部分是自己写的例子(要看示意图的话直接看下一部分代码)
ls3 = ls1.copy()
print(id(ls1), id(ls3)) # 拷贝了第一层的索引和地址给新列表,
# 相当于只给ls3开辟了新内存空间,深层数据仍共用同一内存空间
1824275417088 1824275418944 # ls1和ls2的id(不同)
print(id(ls1[0]), id(ls1[1]), id(ls1[2]), id(ls1[3]))
print(id(ls3[0]), id(ls3[1]), id(ls3[2]), id(ls3[3]))
1824271691536 1824272142896 1824272143472 1824271815360
1824271691536 1824272142896 1824272143472 1824271815360 # 列表中数据的id都一样
说明拷贝的只是容器本身,但容器中的数据还是原来的数据,并没有重新复制一份。
# '肖宫','万叶','班尼特'为不可变类型,改变时会重新开辟空间,不会改变原值
# 但['钟离','托马','莱伊啦']列表为可变类型
ls3[0] = '散兵'
ls3[1] = '珐露珊'
ls3[2] = '迪奥娜'
ls3[3][0] = '莱伊啦'
print(ls3) # ['散兵', '珐露珊', '迪奥娜', ['莱伊啦', '托马', '莱伊啦']]
# 由于字符串是不可变类型,所以ls3的前三个元素执行上面的赋值操作后,会将元素的内存地址改变为新的值的内存地址
print(ls1) # ['肖宫', '万叶', '班尼特', ['莱伊啦', '托马', '莱伊啦']]
# ls1的前三个元素仍然是'肖宫', '万叶', '班尼特'的内存地址。
ls3[3][0] = '莱伊啦' 这个赋值操作相当于更改['钟离', '托马', '莱伊啦'](假设这个列表为ls4)这个列表的第0个元素,即ls4[0]='莱伊啦',所以ls4变成了['莱伊啦', '托马', '莱伊啦']。
因为ls1和ls3的最后一个元素的地址都是ls4这个列表的地址,所以当ls4改变后,ls1和ls3的最后一个元素也跟着改变。
# 但是若为ls3[3]='莱伊啦'则...(这是因为这个赋值操作将ls3[3]的内存地址变成了'莱伊拉'的内存地址)
# ls3=['散兵', '珐露珊', '迪奥娜', '莱伊啦']
# ls1=['肖宫', '万叶', '班尼特', ['钟离', '托马', '莱伊啦']]
这是小飞的例子,与下面的示意图符合
l1 = ['张大仙', '徐凤年', ['李淳罡', '邓太阿']]
# 浅拷贝
l3 = l1.copy()
print(l3)
print(id(l1),id(l3))
print(id(l1[0]), id(l1[1]), id(l1[2]))
print(id(l3[0]), id(l3[1]), id(l3[2]))
l3[0] = '张坦克'
l3[1] = '徐骁'
l3[2][0] = '剑九黄'
l3[2][1] = '王仙芝'
print(l1)
print(l3)
下面是示意图(小飞视频中的深浅拷贝之浅拷贝 - 《python零基础到全栈系列》_哔哩哔哩_bilibili):
以后有时间再自己画图
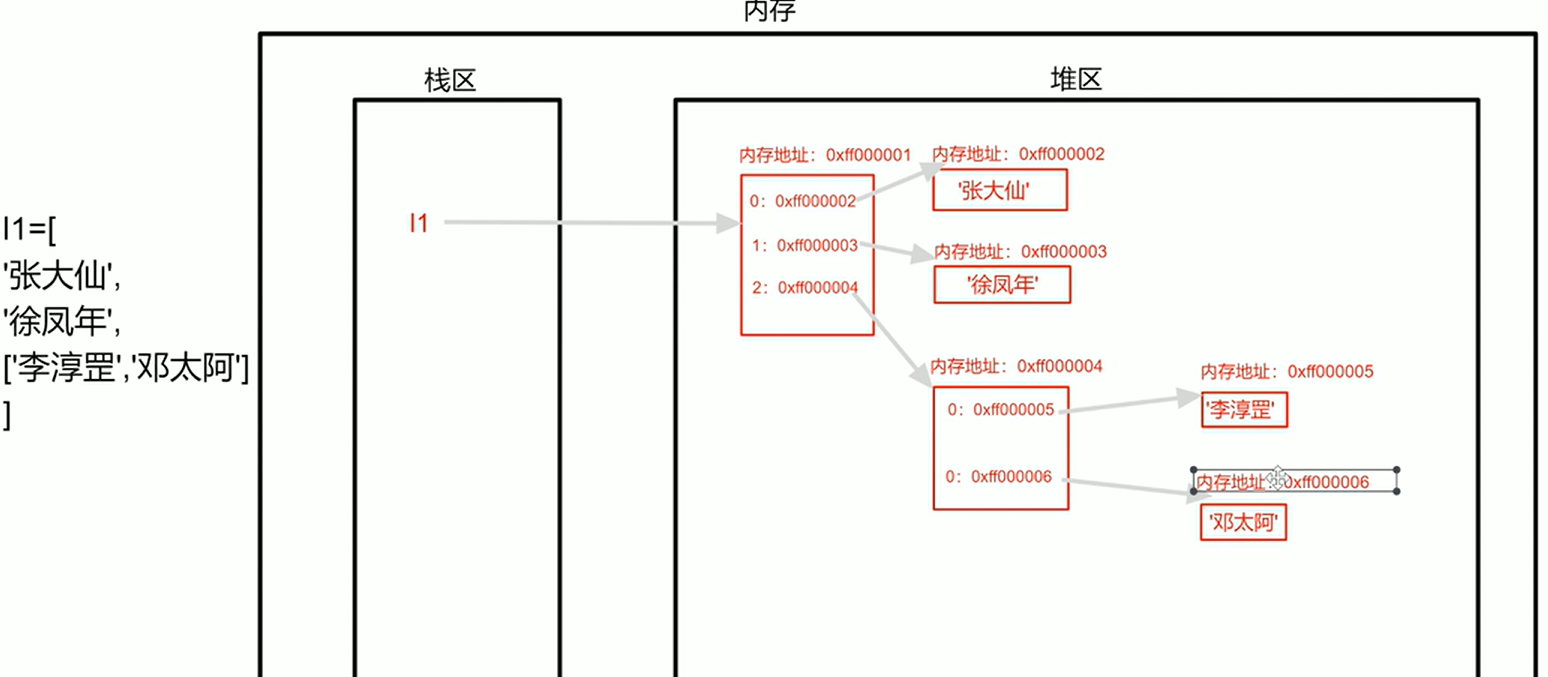
更改l3的值之后
深拷贝
l1 = ['肖宫', '万叶', '班尼特', ['钟离', '托马', '莱伊啦']]
import copy
l2 = copy.deepcopy(l1)
print(id(l1[0]), id(l1[1]), id(l1[2]), id(l1[3])) # 不可变类型仍用同一内存单元,改变时再开辟新的单元
print(id(l2[0]), id(l2[1]), id(l2[2]), id(l2[3])) # 可变类型则直接开辟新的内存单元
# 完全开辟一个新列表,互不影响
l2[0] = '散兵'
l2[1] = '珐露珊'
l2[2] = '迪奥娜'
l2[3][0] = '莱伊啦'
print(l1)
print(l2)
注:浅拷贝时,若元素是不可变类型则原容器和拷贝后的两个容器类型不会互相影响,若元素中有可变类型,两个容器不能够做到完全独立。深拷贝是两个容器互相独立,容器中不可变类型的元素不会重新复制一份,因为它不会影响两个容器的独立性,可变类型的容器则会重新开辟写的内存单元,也就是复制了一份放到另一个地方,而不是单纯的引用。
第四章、选择结构与循环结构
4.1 条件表达式
在选择和循环结构中,条件表达式的值只要不是False、0(或0.0、0j等)、空值None、空列表、空元组、空集合、空字典、空字符串、空range对象,Python解释器均认为与True等价。
将表达式的值作为参数传递给内置函数bool()时,若返回值为True,则说明这个作为条件表达式时表示条件成立,反之条件不成立。
>>> bool(3), bool(-5), bool(3.14), bool(0) # 0之外的数字都等价于True
(True, True, True, False)
>>> bool('a'), bool('董付国'), bool(' '), bool('')
# 包含任意内容的字符串都等价于True
(True, True, True, False)
>>> bool([3]), bool([map,zip]), bool([]) # 包含任意内容的列表都等价于True
(True, True, False)
>>> bool(()), bool({}), bool(set()) # 空元组、空字典、空集合等价于False
(False, False, False)
>>> bool(range(8,5)), bool(range(5,3)), bool(range(-3))
# 空的range对象有很多
(False, False, False)
>>> bool(sum), bool((i for i in range(5))) # 函数、生成器对象等价于True
(True, True)
补充:显示布尔值与隐式布尔值
# 下面这些都是显式布尔值
明天==’周六’ -> True
年龄>18 -> True
True
False
# 下面这些是隐式布尔值
0、None、空(空字符串、空列表、空字典)->False
其他所有的值都是True
10 -> True
0 -> False
None -> False
'张大仙' -> True
'' -> False
' ' -> True
[]、{} -> False
(1)关系运算符
Python中的关系运算符可以连续使用,这样不仅可以减少代码量,也比较符合人类的思维方式。
>>> print(1<2<3) # 等价于1<2 and 2<3
True
print(1<2>3)
False
print(1<3>2)
True
在Python语法中,条件表达式中不允许使用“=”,避免了误将关系运算符“==”写作赋值运算符“=”带来的麻烦。在条件表达式中使用赋值运算符“=”将抛出异常,提示语法错误。
>>> if a=3: # 条件表达式中不允许使用赋值运算符
SyntaxError: invalid syntax
if (a=3) and (b=4):
SyntaxError: invalid syntax
(2)逻辑运算符
逻辑运算符and、or、not分别表示逻辑与、逻辑或、逻辑非。对于and而言,必须两侧的表达式都等价于True,整个表达式才等价于True。优先级not>and>or。
对于or而言,只要两侧的表达式中有一个等价于True,整个表达式就等价于True;对于not而言,如果后面的表达式等价于False,整个表达式就等价于True。
>>> 3 and 5 # 整个表达式的值是最后一个计算的子表达式的值
5
>>> 3 or 5
3
>>> 0 and 5 # 0等价于False
0
>>> 0 or 5
5
>>> not [1, 2, 3] # 非空列表等价于True
False
>>> not {} # 空字典等价于False
True
逻辑运算符and和or具有短路求值或惰性求值的特点,可能不会对所有表达式进行求值,而是只计算必须计算的表达式的值。
比如0 and (3-1+1*6)这个表达式,从前往后判断,发现and左边等价于False,那么整个表达式的值就是False(无论右边是T还是F),后面的表达式几不会在进行判断,如果右边的表达式中有函数那也不会执行那个函数)。
# 短路求值示例
i = 1
def func():
print('执行了func')
return True
print((i-1) and func()) # 因为i-1==0,等价于False,整个表达式的值为假,所以不再执行后面的func函数
# 0
print(i+123 or func()) # 因为i+123=124,等价于True,整个表达式的值为真,所以不再执行后面的func函数
# 124
4.2 选择结构
常见的选择结构有单分支选择结构、双分支选择结构、多分支选择结构以及嵌套的分支结构,也可以构造跳转表来实现类似的逻辑。
循环结构和异常处理结构中也可以带有“else”子句,可以看作是特殊形式的选择结构。
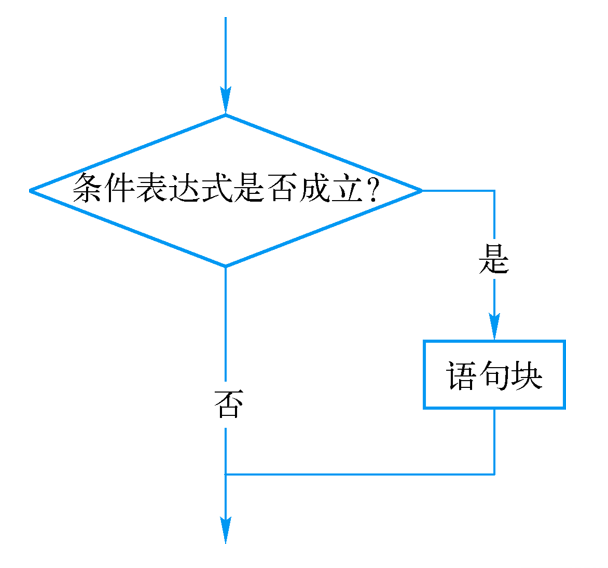
4.2.1 单分支选择结构
if 表达式:
语句块
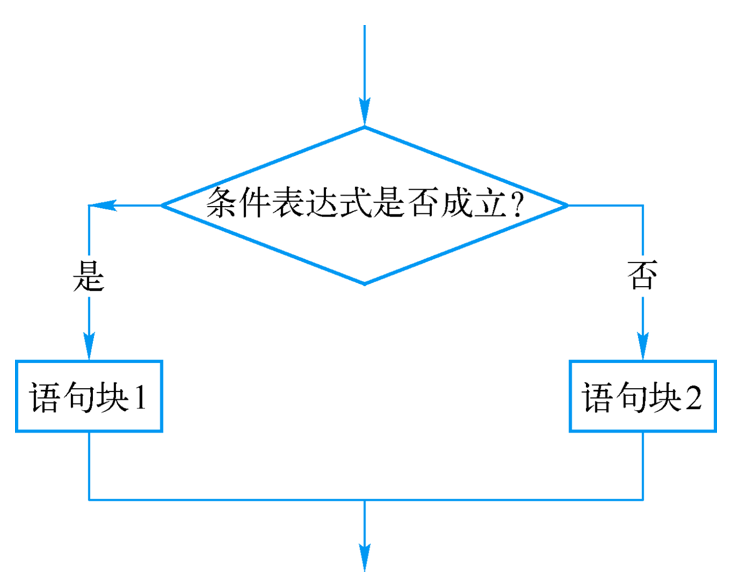
4.2.2 双分支选择结构
if 表达式:
语句块1
else:
语句块2
三元运算符
Python还提供了一个三元运算符,并且在三元运算符构成的表达式中还可以嵌套三元运算符,可以实现与选择结构相似的效果。语法为
value1 if condition else value2
当条件表达式condition的值与 True等价时,表达式的值为value1,否则表达式的值为value2。
>>> a = 5
>>> print(6 if a>3 else 5)
6
>>> b = 6 if 5>13 else 9 # 等于号的优先级非常低
>>> b
9
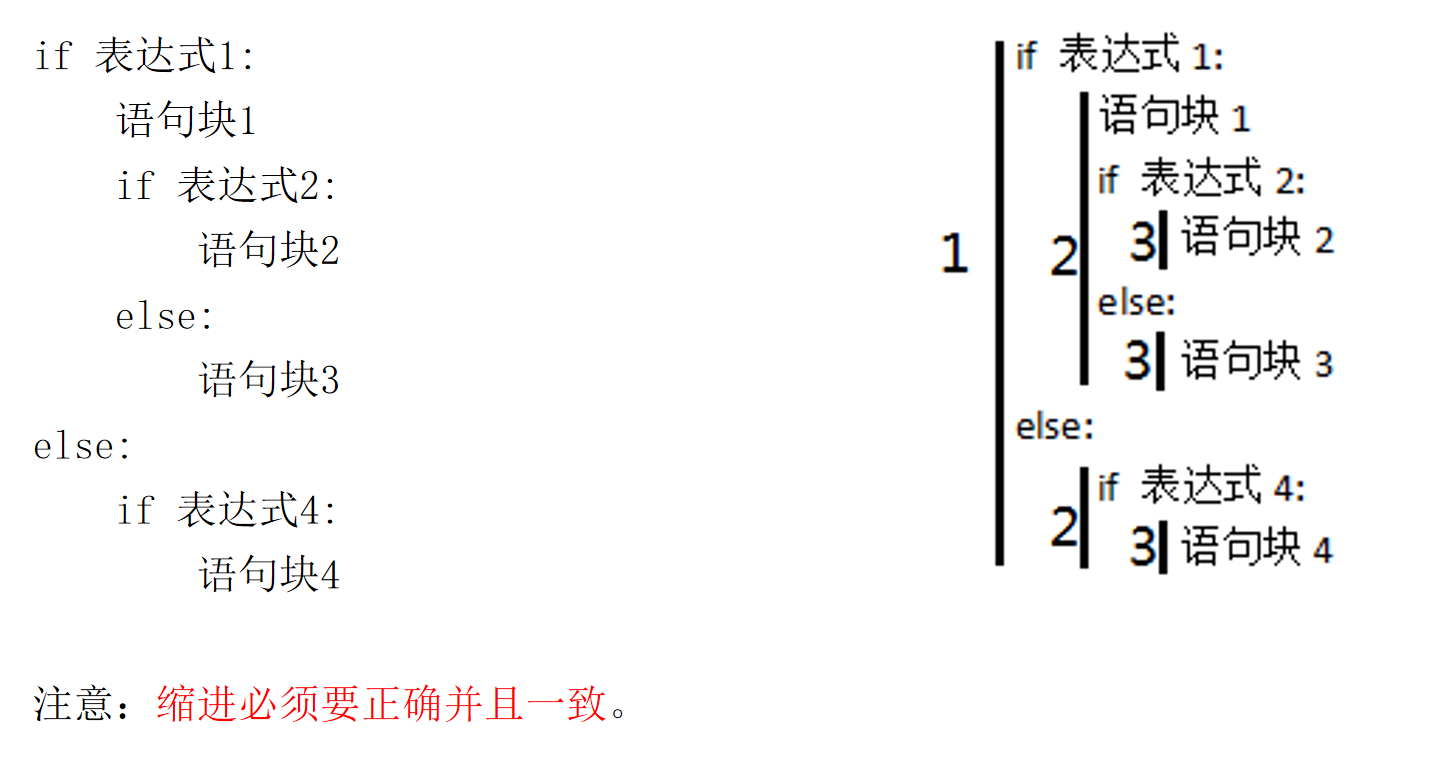
4.2.3 多分支选择结构
if 表达式1:
语句块1
elif 表达式2:
语句块2
elif 表达式3:
语句块3
else:
语句块4
其中,关键字elif是else if的缩写。
例4-4 使用嵌套选择结构将成绩从百分制变换到等级制。
def func(score):
degree = 'DCBAAF'
if score > 100 or score < 0:
return 'wrong score.must between 0 and 100.'
else:
index = (score - 60) // 10
if index >= 0:
return degree[index]
else:
return degree[-1]
print(func(89))
4.3 循环结构
Python主要有for循环和while循环两种形式的循环结构,多个循环可以嵌套使用,并且还经常和选择结构嵌套使用来实现复杂的业务逻辑。
-
while循环一般用于循环次数难以提前确定的情况,当然也可以用于循环次数确定的情况;
-
for循环一般用于循环次数可以提前确定的情况,尤其适用于枚举或遍历序列或迭代器对象中元素的场合。
对于带有else子句的循环结构,如果循环因为条件表达式不成立或序列遍历结束而自然结束时则执行else结构中的语句,如果循环是因为执行了break语句而导致循环提前结束则不会执行else中的语句。
4.3.1 for循环与while循环
两种循环结构的完整语法形式分别为:
while 条件表达式:
循环体
[else:
else子句代码块]
for 循环变量 in 可迭代对象:
循环体
[else:
else子句代码块]
例4-6 编写程序,打印九九乘法表。
for i in range(1, 10):
for j in range(1, i+1):
print('{0}*{1}={2}'.format(i,j,i*j), end=' ')
print()
4.3.2 break与continue语句
break与continue语句只能在循环中使用(for循环和while循环都可以)。
一旦break语句被执行,将使得break语句所属层次的循环提前结束(包括循环后面跟着的else子句);
continue语句的作用是提前结束本次循环,忽略continue之后的所有语句,提前进入下一次循环。
例4-7 编写程序,计算小于100的最大素数。
for n in range(100, 1, -1):
if n%2 == 0: # 偶数,不可能是素数。排除偶数,下面就只考虑奇数的情况。
continue
# 偶数的倍数一定是偶数,也一定不是素数。
for i in range(3, int(n**0.5)+1, 2): # 步长为2,只考虑是否是奇数的倍数。
if n%i == 0: # 判断n是否有除1以外的因数。
break # 结束内循环
else:
print(n)
break # 结束外循环
为什么判断因子时只需要判断到n**0.5就可以了?
答:若n有因子a和b,则n = a * b,而a和b中必有一个小于等于n的平方根。所以只需要判断小于n的平方根的数就可以了。
举个例子,如果n=36,因子可以是1和36,2和18,3和12,4和9,6和6。判断36是否有1和它本身之外的因子时,只需要判断2到6之间的数即可。
例4-9 编写程序,判断今天是今年的第几天。
import time
date = time.localtime() # 获取当前日期时间
year, month, day = date[:3]
day_month = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
if year%400==0 or (year%4==0 and year%100!=0): # 判断是否为闰年
day_month[1] = 29
if month==1:
print(day)
else:
print(sum(day_month[:month-1])+day)
下面的例子以后在来慢慢分析。。。。。。
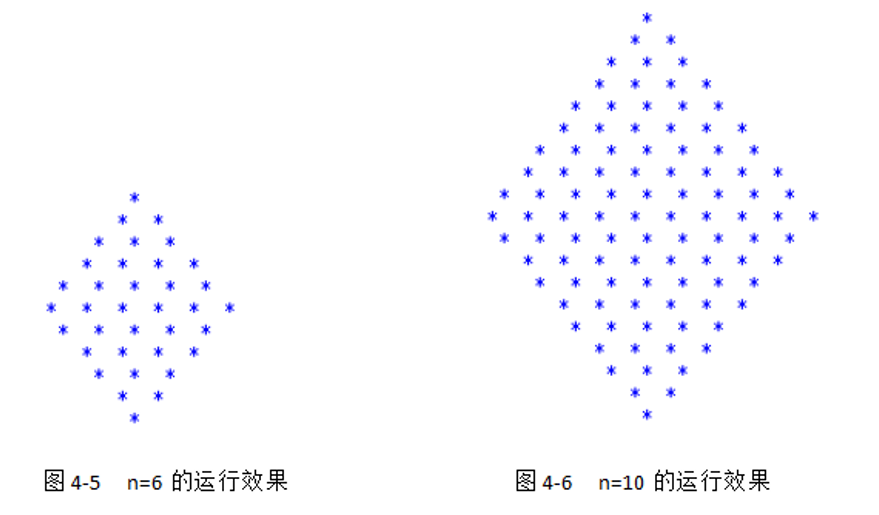
例4-10 编写代码,输出由星号*组成的菱形图案,并且可以灵活控制图案的大小。
def main(n):
for i in range(n):
print((' * '*i).center(n*3)) # .center()用于格式化填充字符串
for i in range(n, 0, -1):
print((' * '*i).center(n*3))
main(6)
main(10)
例4-11 快速判断一个数是否为素数。
n = input("Input an integer:")
n = int(n)
if n in (2,3):
print('Yes')
# 偶数必然不是素数
elif n%2 == 0:
print('No')
else:
# 大于5的素数必然出现在6的倍数两侧
# 因为6x、6x+2、6x+3、6x+4肯定不是素数,假设x为大于1的自然数
m = n % 6
if m!=1 and m!=5:
print('No')
else:
for i in range(3, int(n**0.5)+1, 2):
if n%i == 0:
print('No')
break
else:
print('Yes')
例4-12 编写程序,计算组合数C(n,i),即从n个元素中任选i个,有多少种选法。
根据组合数定义,需要计算3个数的阶乘,在很多编程语言中都很难直接使用整型变量表示大数的阶乘结果,虽然Python并不存在这个问题,但是计算大数的阶乘仍需要相当多的时间。本例提供另一种计算方法:以Cni(8,3)为例,按定义式展开如下,对于(5,8]区间的数,分子上出现一次而分母上没出现;(3,5]区间的数在分子、分母上各出现一次;[1,3]区间的数分子上出现一次而分母上出现两次。
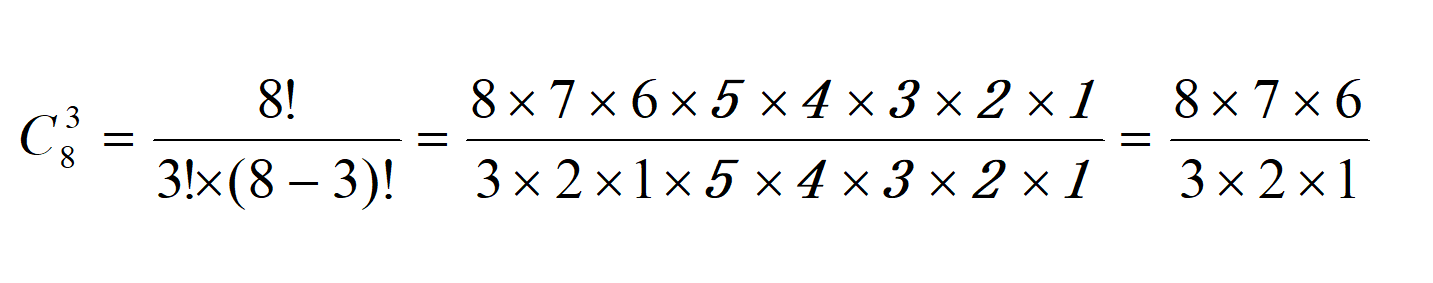
def cni(n, i):
if not (isinstance(n,int) and isinstance(i,int) and n>=i):
print('n and i must be integers and n must be larger than or equal to i.')
return
result = 1
min_, max_ = sorted((i, n-i))
for i in range(n, 0, -1):
if i > max_:
result *= i
elif i <= min_:
result //= i
return result
print(cni(6, 2))
第五章、函数
5.1 函数的定义与使用
5.1.1 函数调用与基本语法
函数定义语法:
def 函数名([参数列表]):
'''
注释
'''
函数体
注意事项
- 函数形参不需要声明类型,也不需要指定函数返回值类型
- 即使该函数不需要接收任何参数,也必须保留一对空的圆括号
- 括号后面的冒号必不可少
- 函数体相对于def关键字必须保持一定的空格缩进
- Python允许嵌套定义函数
- 可以没有返回值,默认返回None
- return返回多个值时,会将这些值封装为元组。
- 函数定义时并不会执行函数的代码,只会检查语法,只有在函数被调用时,函数才会被执行。
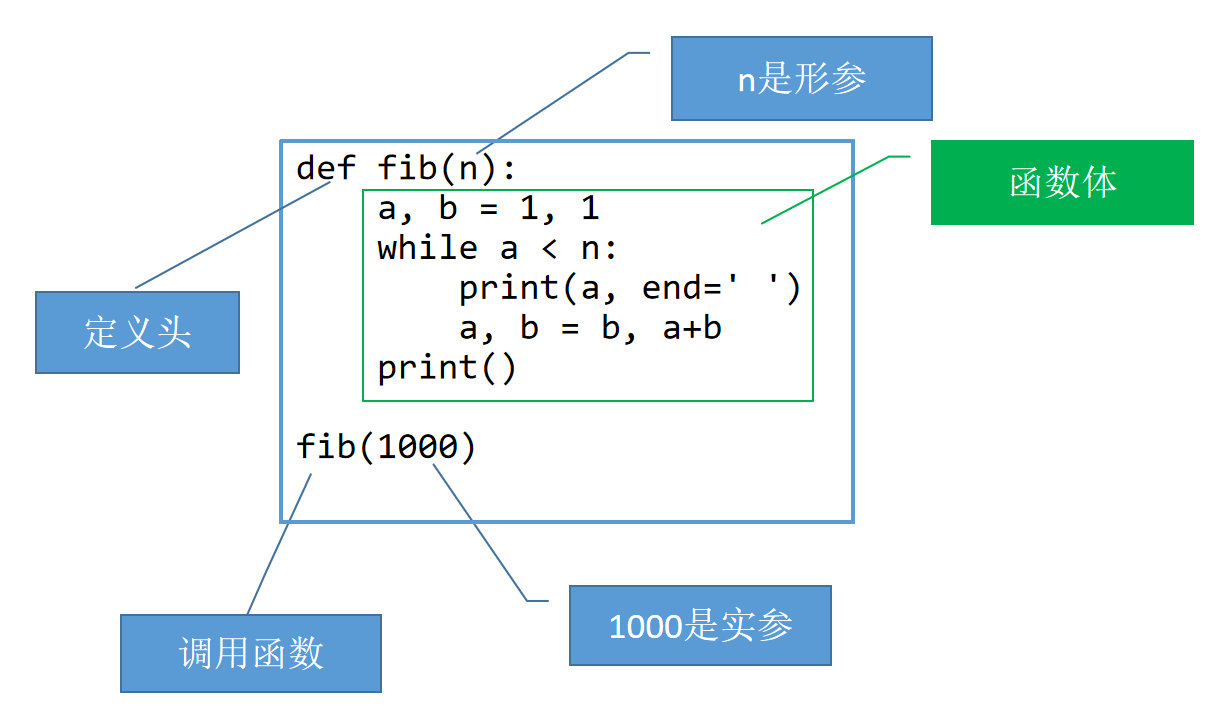
例5-1 编写生成斐波那契数列的函数并调用。
5.1.2 函数递归调用
前言:递归这部分比较难理解,目前掌握函数的递归过程以及原理即可。至于使用递归进行全排列之类算法,单独放到算法那部分进行详细分析。
函数的递归调用是函数调用的一种特殊情况,函数调用自己,自己再调用自己,自己再调用自己,...,当某个条件得到满足的时候就不再调用了,然后再一层一层地返回直到该函数第一次调用的位置。
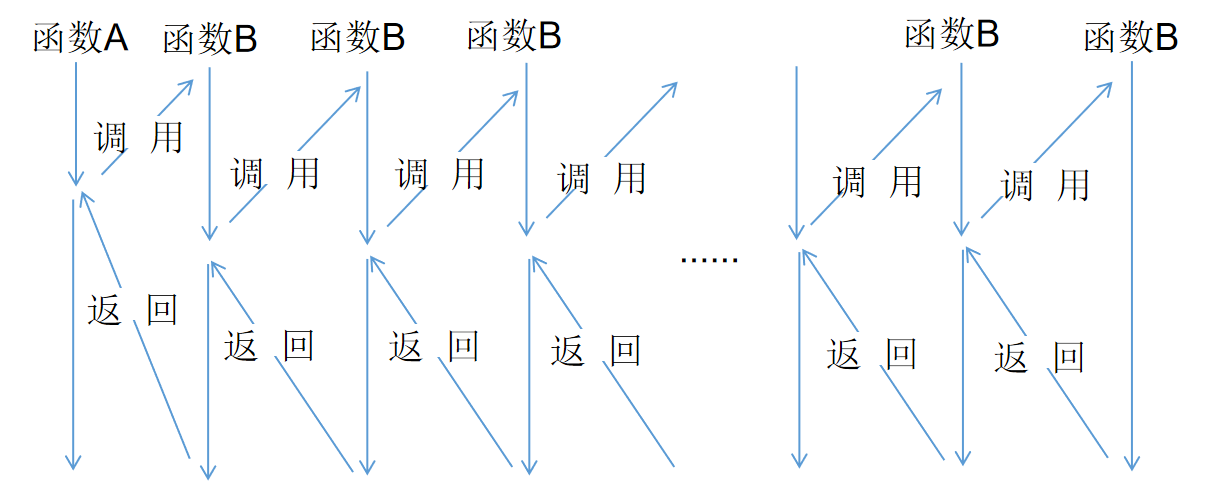
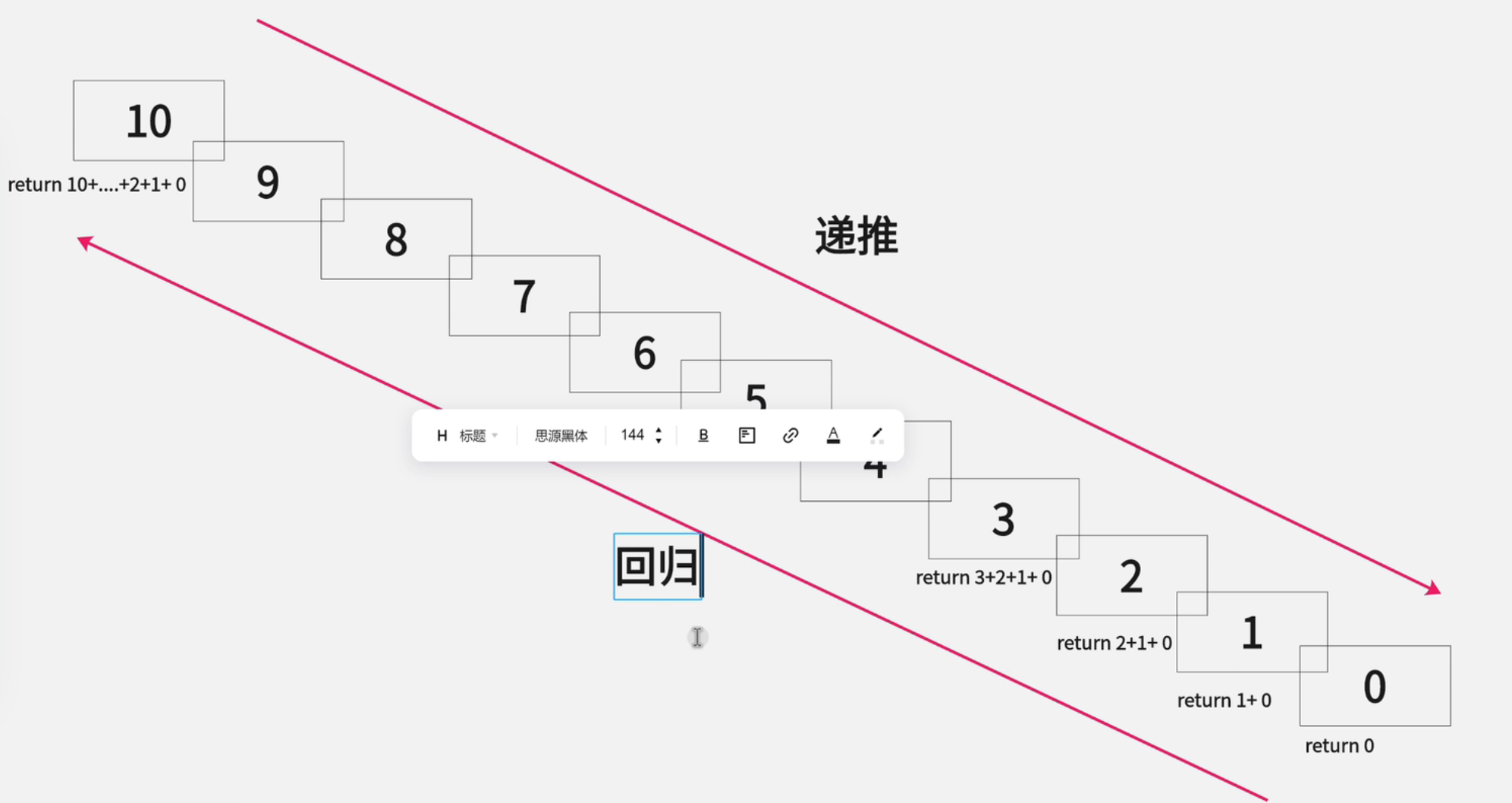
函数递归通常用来把一个大型的复杂问题层层转化为一个与原来问题本质相同但规模很小、很容易解决或描述的问题,只需要很少的代码就可以描述解决问题过程中需要的大量重复计算。在编写递归函数时,应注意以下几点。
- 每次递归应保持问题性质不变。
- 每次递归应使用更小或更简单的输入。
- 必须有一个能够直接处理而不需要再次进行递归的特殊情况来保证递归过程可以结束。
- 函数递归深度不能太大,否则会导致内存崩溃。
因为每一层递归都会创建一个局部名称空间,所以python对递归层数做了限制,默认情况下最大是1000层。当然也可以更改最大递归深度(层级),但不建议修改。
import sys
print(sys.getrecursionlimit()) # 查看最大递归深度,默认为1000
# sys.setrecursionlimit(2000) # 修改最大递归深度
print(sys.getrecursionlimit())
直接调用与间接调用:
# 直接调用
def func():
print('love')
func()
func()
# 间接调用
def func1():
func2()
def func2():
func1()
func1()
小案例:
# 计算1到10的和
def my_sum(n):
if n <= 0: # n<=0时就可以结束递归了,然后依次返回上一层递归
return 0
else:
return n + my_sum(n - 1) # 1到10的和等于,10+(1到9的和),依次类推
print(my_sum(10))
案例:把下列列表的值分别打印出来
# 把下列列表的值分别打印出来
l = [1, [2, 3, [4, 5, 6, [7, 8, 9, [10]]]]]
# l=[1,2,[3,4]]
def func(l):
for i in l:
if type(i) is list: # 如果元素i是列表,那就继续调用func对列表i进行遍历。
func(i)
else:
print(i) # 如果元素i不是列表,就打印它
func(l)
案例:将‘abcd’做全排列
这里理解不了也没关系,全排列将单独拿出来,放在算法那一部分进行详解。
大概思想就是将level依次与后面的数字互换(包括他自己),每换一次就有一种新的排列,然后在对新排列的level后的部分继续做全排列。后面的部分做全排列的过程也是一样,只是少了一个元素。
比如:我需要给abcd做全排列,那么我先将a与a交换,然后再对bcd做全排列。然后再将a与b交换,对acd做全排列。再将a与c交换,对bad做全排列。再将a与d交换,对bca做全排列。
# 把下面字符串做全排列
s = 'abcd'
l = list(s)
def func2(l, level):
if level == len(l): # 输出此时的排列,range(level, len(l))为空,for循环不执行,返回上一层递归
print(l)
for i in range(level, len(l)):
l[level], l[i] = l[i], l[level] # l[level]和它后面的每一个元素互换
func2(l, level + 1) # 对l[level]后面的len(l)-level个元素进行全排列
l[level], l[i] = l[i], l[level] # 再换回来
例5-2 使用递归法对整数进行因数分解。
from random import randint
def factors(num):
# 每次都从2开始查找因数
for i in range(2, int(num**0.5)+1):
# 找到一个因数
if num%i == 0:
facs.append(i)
# 对商继续分解,重复这个过程
factors(num//i)
# 注意,这个break非常重要
break
# 没有break的话,当商分解完成后,循环还会继续执行,继续寻找num的因子
else:
# 不可分解了,自身也是个因数
facs.append(num)
facs = [] # 用来存放因子
n = randint(2, 10**8) # 生成随机数
factors(n) # 调用递归函数进行因式分解
result = '*'.join(map(str, facs)) # 将因子使用*连接为一个字符串
if n == eval(result): # 使用eval计算因式分解后的式子,计算结果等于n,说明因式分解正确。
print(n, '= '+result) # 输出n=因式分解后的式子
5.2 函数参数
函数定义时圆括弧内是使用逗号分隔开的形参列表(parameters),函数可以有多个参数,也可以没有参数,但定义和调用时一对圆括弧必须要有,表示这是一个函数并且不接收参数。
调用函数时向其传递实参(arguments),根据不同的参数类型,将实参的引用传递给形参。(注意:这里传的是实参的引用,也就是实参和形参指向的是同一个值【指向的内存地址相同】)
5.2.1 位置参数
定义位置参数(positional arguments)是比较常用的形式,调用函数时实参和形参的顺序必须严格一致,并且实参和形参的数量必须相同。
>>> def demo(a, b, c):
print(a, b, c)
>>> demo(3, 4, 5) # 按位置传递参数
3 4 5
>>> demo(3, 5, 4)
3 5 4
>>> demo(1, 2, 3, 4) # 实参与形参数量必须相同
TypeError: demo() takes 3 positional arguments but 4 were given
5.2.2 默认值参数
在调用函数时,可以不用为设置了默认值的形参传递实参,此时函数将会直接使用函数定义时设置的默认值,当然也可以通过显式赋值来替换其默认值。在调用函数时是否为默认值参数传递实参是可选的。
需要注意的是,在定义带有默认值参数的函数时,任何一个默认值参数右边都不能再出现没有默认值的普通位置参数,否则会提示语法错误。
带有默认值参数的函数定义语法如下:
def 函数名(……,形参名=默认值):
函数体
>>> def say(message, times=1):
print((message+' ') * times)
>>> say('hello') # 此时time默认为1
hello
>>> say('hello', 3) # 默认值参数要在普通位置参数后面(默认参数可以像位置参数一样传值)
hello hello hello
默认参数的值是在函数定义阶段被赋值的
证明如下:
b = 10
def func(y=b):
print(f'y={y}')
# 在调用函数之前修改b的值
b = 20
func() # 调用函数,不传递参数,形参使用默认值
print(f'b={b}')
# 输出结果如下
y=10 # 可以看到,虽然在调用函数前更改了b的值,但是y的值仍然是10
b=20
函数默认参数可以指定为任意类型,但不建议指定为可变类型,因为可变类型的值容易收到函数外部影响,而改变函数内部的执行
案例:编写一个与append功能相同,但能够一次添加两个值的函数。
def my_append(x,y,l=[]):
l.append(x)
l.append(y)
return l
print(my_append(1, 2))
为了更加规范,默认参数不应该为可变类型,所以可以上面的代码进行改进:
??感觉上面的代码也没什么问题呀,l被赋值为空列表,这个列表不可能会被函数外影响到吧?????
def my_append(x, y, l=None):
if l is None: # 如果没有传l这个参数,那就把他赋值为一个空列表
l = []
l.append(x)
l.append(y)
return l
5.2.3 关键字参数
通过关键参数可以按参数名字传递实参,明确指定哪个实参传递给哪个形参,实参顺序可以和形参顺序不一致,但不影响参数值的传递结果,避免了用户需要牢记参数位置和顺序的麻烦,使得函数的调用和参数传递更加灵活方便。
>>> def demo(a, b, c=5):
print(a, b, c)
demo(3, 7)
3 7 5
demo(a=7, b=3, c=6)
7 3 6
demo(c=8, a=9, b=0) # 按名字传递实参,顺序可以不一致
9 0 8
5.2.4 不定长参数
不定长度参数(也叫可变长参数)主要有两种形式:在参数名前加1个*或2个**
- *args用来接收多个位置参数并将其放在元组中
- **kwargs用来接收多个关键参数并将其放在字典中
一般情况下,可变长位置参数只用args这个变量名,关键字参数使用kwargs这个变量名,当然也可以使用其他的变量名。在传递参数时,不定长参数可以为0个或多个。
可变长度的位置参数
def func(x,y,*args):
print(x,y,args)
func(1,2,3,4,5,6)
# 输出:1 2 (3, 4, 5, 6) # 多余的位置参数被*args接受,并打包为元组
案例:设计一个函数,返回接受的参数的和
def my_sum(*args): # args = (1,2,3,4,5) 打包为元组
res = 0
for i in args: # 这里可以直接用一个sum函数求值
res += i
return res
print(my_sum(1, 2, 3, 4, 5)) # 15
print(my_sum()) # 0个参数 # 0
可变长度的关键字参数
def abc(a, b, c=1, **kwargs): # kwargs = {'d': 123456, 'e': 789, 'f': 1391} 打包成字典
print(a, b, c, kwargs)
abc(1, 2, c=213, d=123456, e=789, f=1391)
# 输出:1 2 213 {'d': 123456, 'e': 789, 'f': 1391}
**kwargs的用法
>>> def demo(**kwargs):
for item in kwargs.items():
print(item)
>>> demo(x=1, y=2, z=3) # 将多个关键字参数打包为一个个二元组(('x', 1),('y', 2),('z', 3))
('x', 1)
('y', 2)
('z', 3)
将*和**不仅可以用于形参,还可以用于实参中,用于实参是叫序列解包,
5.2.5 传递参数时的序列解包
传递参数时,可以通过在实参序列前加一个星号将其解包为普通位置参数,然后传递给多个单变量形参。
*后面跟可迭代对象(列表,字符串,元组,字典), 字典被解包后只能取到key
def demo(a, b, c):
print(a+b+c)
l = [1, 2, 3]
demo(*l) # 将列表解包为1,2,3三个值,并分别传递给三个参数
# 6
tup = (1, 2, 3)
demo(*tup)
# 6
dic={'a':1,'b':2,'c':3}
def func(x,y,z):
print(x,y,z)
func(*dic) # 列表的键被解包为'a','b','c'三个值,并传给三个参数。
# 输出:a b c
# 混合
def abc1(x, y, z=123, *args, **kwargs):
print(x, y, z, args, kwargs)
s = '将可迭代对象解包并作为实参传给形参'
abc1(*s) # 解包为:'将','可','迭',('代', '对', '象', '解', '包', '并', '作', '为', '实', '参', '传', '给', '形', '参')
# 输出:将 可 迭 ('代', '对', '象', '解', '包', '并', '作', '为', '实', '参', '传', '给', '形', '参') {}
# kwargs没有接受到参数,所以是一个空字典。
解包之后传递参数的规则与正常使用变量时一样
如果函数实参是字典,可以在前面加两个星号进行解包,等价于关键参数。
dic={'a':1,'b':2,'c':3}
def func(a=111,b=222,c=333):
print(a,b,c)
func(**dic) # 将dic解包,等价于func(a=1,b=2,c=3)
# 输出:1 2 3
只以*和**做为参数:
def abc2(*arge, **kwargs):
print(arge, kwargs)
abc2()
abc2(1, 2, 3, a=2, b=3, c=4, d=5, e=6)
*和**的用法,装饰器是会用到,形式类似下面这样:
def f1(x, y, z, a, b, c):
print(x, y, z, a, b, c)
def f2(*args, **kwargs): # 打包args=(1,2,3) kwargs={'a':1,'b':2,'c':3}
f1(*args, **kwargs) # 打散f1(1,2,3,a=1,b=2,c=3)
f2(1, 2, 3, a=1, b=2, c=3)
# 常用于装饰器。
函数参数总结
1、参数值的传递是引用传递
Python中,所有值的传递都是内存地址的传递,内存地址是对值的引用。即Python中所有值的传递,都是引用传递。
- 当传递的值是不可变类型时,更改任意其中一个变量,那个变量都会指向一个新的内存地址,两者不会相互影响。
- 当传递的值是可变类型时,更改其中一个变量的元素,由于可变类型更改时内存地址不会变,两个变量仍然指向同一个内存地址,两者会互相影响。
2、各种参数的先后顺序
在函数定义或传递参数时,需遵循以下原则:
- 关键字参数必须在位置参数之后(包括可变长位置参数)。(主要体现在传值时)
- 默认值参数必须在位置参数之后。
- 可变长关键字参数必须在可变长位置参数之后。
- 可变长关键字参数必须在默认参数之后。
为了确保参数传递的一致性和避免产生歧义,推荐使用下面这种顺序来定义和传递参数。
位置>*args>默认>关键字>**kwargs
建议将默认参数放在位置参数之后,关键字参数之前,有助于区分这两种参数:
# 例如a是位置参数,b是默认值参数,c是关键字参数
def func(a,b=2,c):
print(a,b,c)
# 这样有了默认值参数在中间隔开,我们就能够一眼看出哪些是位置参数,哪些是关键字参数。
# 当然,这只是一种约定。实际上默认值参数放在位置参数之后,可变长关键字参数之前都是可以的。
# 注意:!!!默认值参数一定不要放在可变长位置参数之前!!!(后面“参数顺序错误的后果”中有示例)
位置参数与关键字参数的区别:
- 在定义时,它们在形式上都是一样的,没有什么区别。
- 在传值时,直接写一个变量或值,按照位置进行传递的是位置参数;使用键值对(如a=1)方式传递的是关键字参数。
# 位置参数与关键字参数在定义时没有区别,它们的区别在于传值的方式。
def func(a,b,c):
print(a,b,c)
func(1,2,3) # 都使用位置位置来传,那么就都是位置参数
func(1,2,c=3) # a,b是位置,c是关键字
func(1,b=2,3) # 假设a,b,c都是位置参数,但当我使用关键字的方式来给b进行传值时,b后面的c也需要用关键字的方式来进行传值
# 虽然关键字参数也可以当做位置参数,使用位置来进行传值,
# 但是需要注意,如果关键字参数之前有可变长位置参数,那么多余的位置参数就被args全部接受,关键字参数c就接收不到值了。这时候必须使用关键字参数的方法来对c进行传值。
def func(a,*args,c):
print(a,args,c)
func(1,2,3) # 都使用位置位置来传,那么就都是位置参数
func(1,*[2,22,33],c=3) # a,b是位置,c是关键字
3、各种参数混用
def func(a, b, *args, c=3, d=4, e, f, g, **kwargs):
print('位置参数:', a, b)
print('默认值参数:', c, d)
print('可变长位置参数:', args)
print('关键字参数:', e, f, g)
print('可变长关键字参数:', kwargs)
func(10, 20, 111, *[222, 333], d=40,g='关键字参数g', **{'f': '关键字参数f', 'h': '关键字参数h', 'e': '关键字参数e'})
# 输出结果:
位置参数: 10 20
默认值参数: 3 40
可变长位置参数: (111, 222, 333)
关键字参数: 关键字参数e 关键字参数f 关键字参数g
可变长关键字参数: {'h': '关键字参数h'}
# c的值仍然为3,所以多余的位置参数111和*[222,333]解包后的值并没有传给c。这和直接写位置参数时不同。
def func2(a, b, c=3):
print(f'a={a},b={b},c={c}')
func2(10, 20, 30) # 这时候第三个位置参数会传给c
# a=10,b=20,c=30
对于上面代码中函数参数传递过程的解释:
解释:
10和20按照位置传给位置参数a和b
多余的位置参数111,222,333传给args
默认值参数c保持默认值3,d被更改为40
关键字参数g被赋值为'关键字参数g',
字典解包后得到【f='关键字参数f', h='关键字参数h', e='关键字参数e'】,其中e和f作为按照对应的变量名传递给关键字参数e和f。而多余的h则传给kwargs。
4、参数顺序错误的后果
(1)在位置参数之前使用关键字方式传值
def func(a,b,c):
print(a,b)
func(1,b=2,3) # 运行时提示:位置参数在关键字参数后面
SyntaxError: positional argument follows keyword argument
func(1,b=2,*[3]) # 运行时提示:参数b获取了多个值
TypeError: func() got multiple values for argument 'b'
(2)不经意间更改了默认参数的值
# 1、位置->可变长位置->默认
# 如果位置参数和默认参数之间有可变长位置参数,那么多余的位置参数会被可变长位置参数吸收,不会影响到默认值参数
def func(a,b,*args,c=3):
print(a,b,args,c)
func(1,2,3,4,5,6)
# 1 2 (3, 4, 5, 6) 3
func(1,2,*[3,4,5,6])
# 1 2 (3, 4, 5, 6) 3
# 2、位置->默认->可变长参数
# 如果默认值参数在可变长位置参数之前,那么如果要给可变长参数传值,那么势必会更改默认值参数(或者说给默认值参数重新赋值)
def func(a,b,c=666,d=666,*args):
print(a,b,c,d,args)
func(1,2,3,4,5,6,7) # 本来是想将3,4,5,6,7传给可变长位置参数的,但却更改了默认值参数的值
# 1 2 3 4 (5, 6, 7)
func(1,2,*[3,4,5,6,7])
# 1 2 3 4 (5, 6, 7)
func(1,2,666,666,*[5,6,7]) # 给默认值参数继续赋值为原来的值
# 1 2 666 666 (5, 6, 7)
# 同样的,如果默认值参数后面有可变长关键字参数,如果可变长关键字参数中有和默认值参数同名的关键字,那么默认值参数也会被更改
def func(a,b,c=666,d=666,**kwargs):
print(a,b,c,d,kwargs)
func(1,2,e=5,f=6,c=123456)
# 1 2 123456 666 {'e': 5, 'f': 6}
func(1,2,**{'e':5,'f':6,'d':123456})
# 1 2 666 123456 {'e': 5, 'f': 6}
# 3、位置->默认
# 如果位置参数后面紧跟着默认值参数,如果多传了一个或多个位置参数,
# 那么多余的参数会按顺序传递给默认值参数,从而改变默认值参数的值.
def func(a,b,c=3):
print(a,b,c)
func(10,20,30) # 默认值参数c的值被更改为30
# 10 20 30
5.3 名称空间
5.3.1 三种名称空间
名称空间(namespace)和作用域的示意图如下:
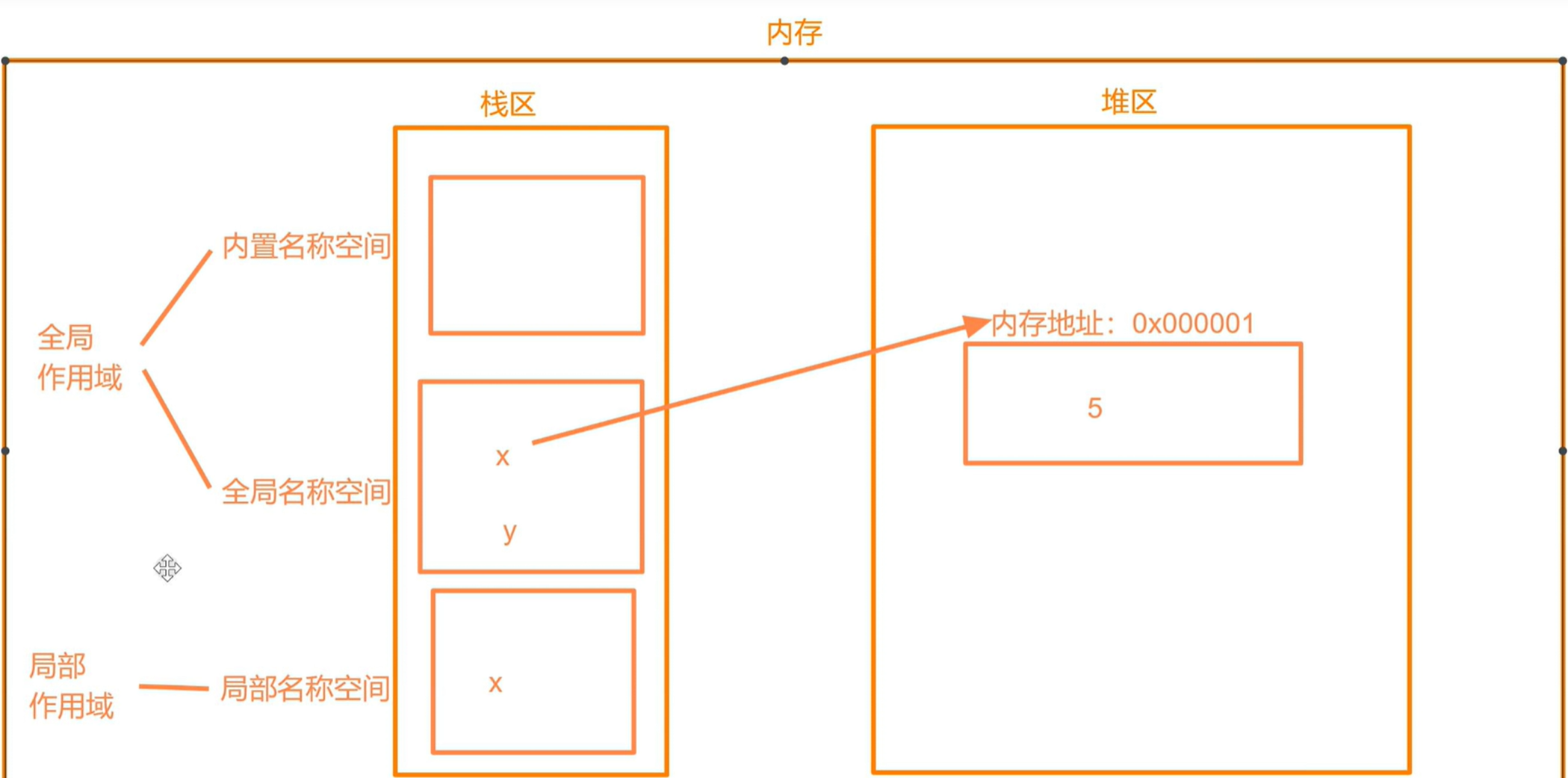
栈区中存储的就是名字和内存地址的绑定关系,名称空间就是将栈区中的名称进行了分类,作用域就是在名称空间的基础上再对名称空间进行分类。
先了解运行python程序的三个阶段:
- python解释器启动。产生python内置的名字。
- 把python文件当做文本内容读入内存。
- 识别python语法。产生变量名、函数名,模块名
1、内置名称空间
内置名称空间中用来存放python内置的名字。当python解释器启动时,就会创建内置名称空间。程序执行完毕后,python解释器关闭,内置名称空间销毁。
2、全局名称空间
全局名称空间中存放python文件(或模块)内定义的函数名、类名、模块名。函数内部定义的名字(包括函数的参数)除外。
总结:只要不是python内置的名字,也不是函数内部定义的名字,剩下的就是全局名称空间的名字。
全局名称空间会在python执行时之前产生,在程序执行完后销毁。
每个python文件(或模块)都有他自己的名称空间,这个名称空间就叫做全局名称空间。目前只考虑单个python的情况,先认为全局名称空间就只有一个。
3、局部名称空间
内部名称空间中存放函数内部定义的名字,包括函数的参数。在函数调用时产生,调用结束后销毁。
所以局部名称空间可以有很多个,调用一次函数就产生一个。
5.3.2 名称空间的加载顺序及查找优先级
1、名称空间的加载顺序
python启动,加载内置名称空间,接着python解释器把文件读入内存,然后加载全局每次空间,加载完成后,识别python语法,执行代码。
# python解释器启动,加载内置名称空间
import os # 将os与time这两个名称加入到全局名称空间
import time
def func(x): # 将func这个名称加入到全局
y = 1
a=1 # 将a与b加入到全局
b=2
func(1) # 调用函数,将x与y加入到局部名称空间,调用完毕后局部名称空间销毁
func(1) # 调用函数,将x与y加入到局部名称空间,调用完毕后局部名称空间销毁
2、名称空间的查找优先级
局部名称空间>全局名称空间>内置名称空间
先从当前名称空间找,找不到,再往下一空间找(只会从左边到右边,按顺序,不会逆着找)
下面举例说明:
例1:
def f1():
print(x) # 局部(没有)———>全局(x=1)
x = 1 # 将x放入全局变量
f1() # 此时调用f1,还未执行到x=2,此时全局变量中的x=1,打印结果为1
x = 2
例2:
input = 'aaa'
def func():
input = 'bbb'
print(input)
func()

当全局中也没有input变量时,就去内置中找,input时python的内置函数,使用print打印时就会出现<built-in function input>这样的信息,built-in是内置的意思,function是函数的意思,这句话的意思就是“内置函数input”。
如果在使用del 删除内置的input名称后,再输出时就会提示名称不存在NameError: name 'input' is not defined,如下图所示。
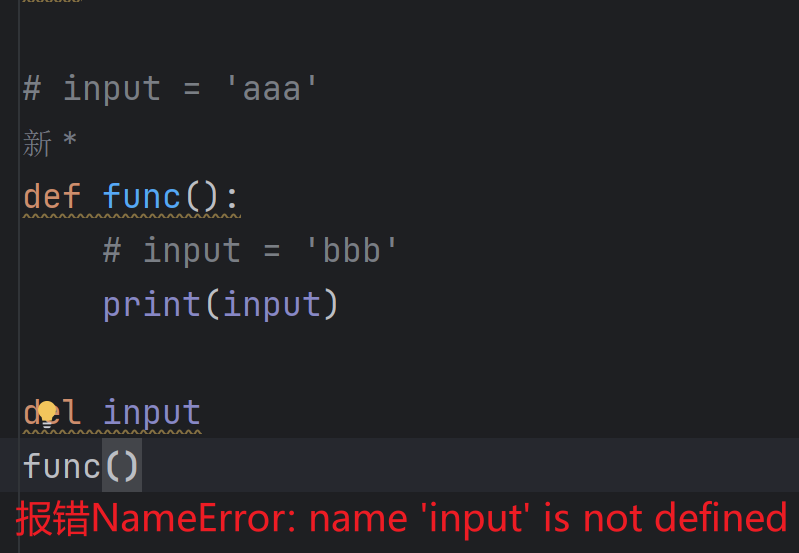
注意:这里删除input时全局中不能有input这个变量,不然删除的就是全局的input,而不是内置的input(名称空间查找优先级:全局>内置)

例3:
def func():
print(x) # 定义函数时并不会执行函数子代码
x = 10 # 执行完x=10后,全局名称空间中就有x了
func() # 此时调用函数,函数执行print时,先在局部找x,没有找到,然后再去全局找,全局中有x,所以输出x=10
3、名称空间的查找顺序以定义阶段为准,与调用位置没有任何关系
举例说明:
例1:
x = 1
def f1():
print(x) # 在局部名称空间(f1)找(没有)-->全局名称空间找(x=1)
def f2():
x = 2
f1() # 由于f1在定义时已经确定了局部名称空间中没有x,需要到全局中找,所以调用f1时输出的是全局的x
f2() # 输出结果为1
为了方便理解下一个例子,这里先补充一下:函数嵌套定义时(多个局部名称空间)名称空间的查找顺序
input = 3 # 全局的input
def f1():
input = 2 # f1的局部的input
def f2(): # python可在函数中嵌套定义函数
input = 1 # f2局部的input
print(input)
f2()
f1()
执行print时,input的查找顺序是,先查找f2的局部的input,如果没有,再去f1的局部找,还没有,再去全局找,全局也没有,那就去内置找,内置也没有,就提示名称没有找到。
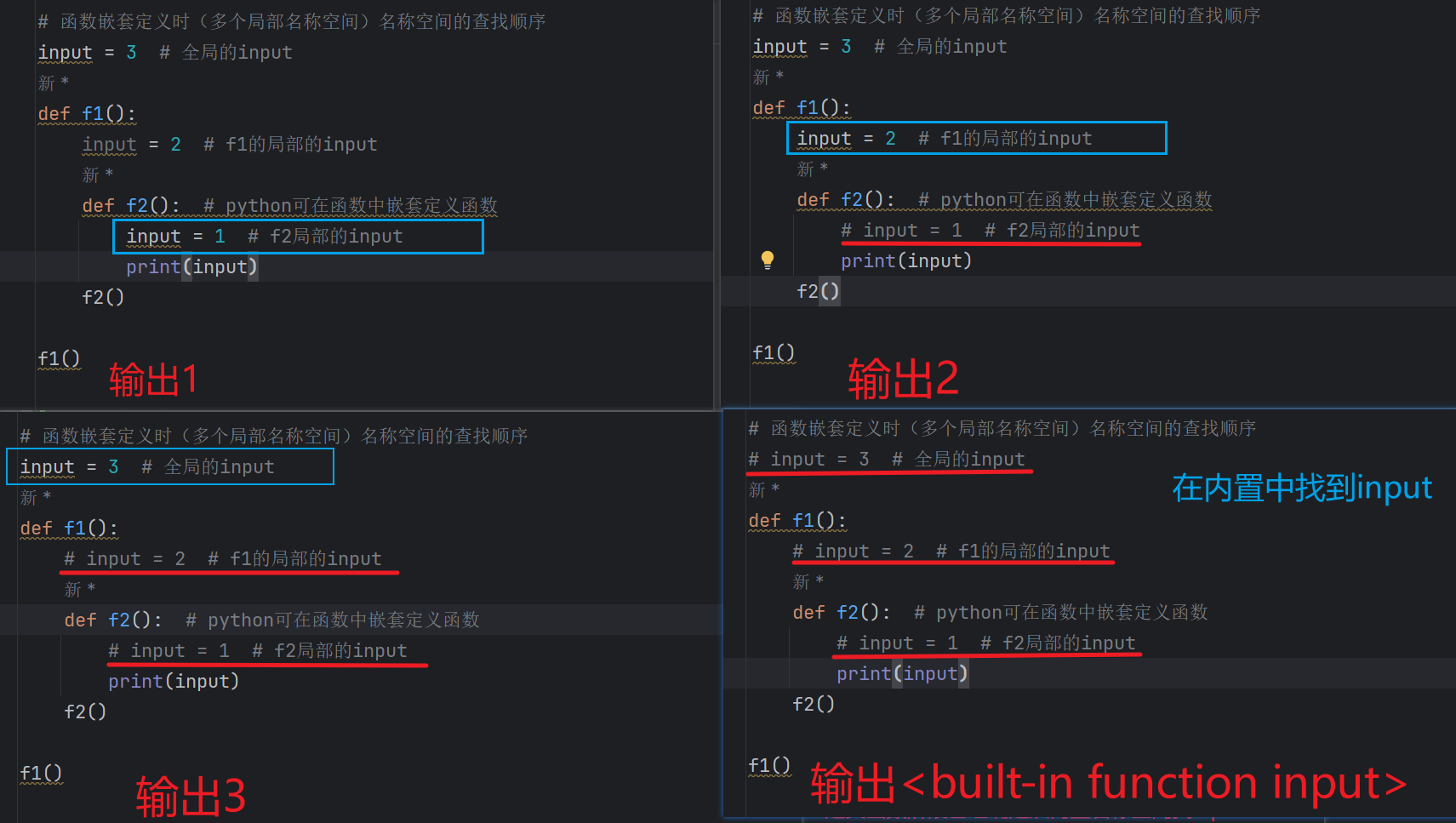
在函数调用前将input删除,找不到,就会报错
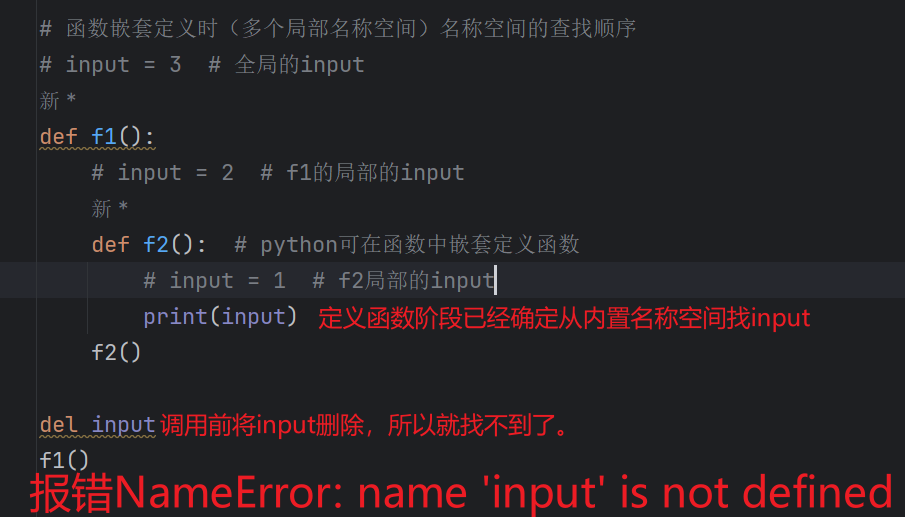
例2:
input = 3 # 全局的input
def f1():
def f2():
print(input)
# 在函数的定义阶段时就发现f1的局部名称空间下有input,所以当函数f2被调用时就会直接在f1的局部名称空间中找input
f2()
# 当f2被调用时,发现input还没有被赋值,所以报错NameError: free variable 'input' referenced before assignment in enclosing scope
input = 1
f1()
5.4 作用域
5.4.1 作用域的特点
变量起作用的代码范围称为变量的作用域,不同作用域内变量名可以相同,互不影响。
在函数内部定义的普通变量只在函数内部起作用,称为局部变量。当函数执行结束后,局部变量自动删除,不再可以使用。
局部变量的引用比全局变量速度快,应优先考虑使用。
作用域分为全局作用域和局部作用域,范围及特点如下:
- 全局作用域:内置名称空间,全局名称空间
- 全局存活
- 全局有效
- 局部作用域:局部名称空间
- 临时存活:函数调用时存活,调用结束后死亡
- 局部有效:只在函数内部有效
5.4.2 名称空间的另一种分类方式:LEGB
- B:built-in 内置
- G:global 全局
- E:enclosing 封闭(除本地外的局部作用域)
- L:local 本地(当前位置)
# 内置:built-in
# 全局:global
def f1():
# enclosing
def f2():
# enclosing
def f3(x):
# local # 这里的local指的是当前所在的作用域
print(x)
print(x)中x的查找循序为f3-->f2-->f1-->全局-->内置,即local-->enclosing-->global-->built-in,和前面所说的局部-->全局-->内置是一样的,只是对局部作用域进行了更细致的划分。
5.4.3 global关键字
全局变量可以通过关键字global来定义。这分为两种情况:
- 一个变量已在函数外定义,如果在函数内需要为这个变量赋值,并要将这个赋值结果反映到函数外,可以在函数内使用global将其声明为全局变量。
- 如果一个变量在函数外没有定义,在函数内部也可以直接将一个变量定义为全局变量,该函数执行后,将增加一个新的全局变量。
global关键字用于在函数内部引用和修改全局变量。如果在函数内部想要访问和修改全局变量,需要使用global关键字声明该变量是全局变量。
x = 10 # 定义全局变量x
def foo():
global x # 声明x是全局变量
x = 20 # 将全局的x更改为20
print(x)
foo() # 输出 20
print(x) # 输出 20 # 全局的x也被改变了
>>> def demo():
global x
x = 3
y = 4
print(x,y)
>>> x = 5 # 在全局定义了x
>>> demo() # 由于x已经在全局调用,所以此时函数中的x是对全局x的引用
3 4
>>> x
3
>>> y
NameError: name 'y' is not defined # y是函数中的局部变量,函数执行完后,就删除了
>>> del x # 将全局的x删除
>>> x
NameError: name 'x' is not defined # 此时全局中已经没有变量x
>>> demo() # 再次调用函数,此时全局中没有x,所以函数中的global x是新定义了一个全局的x
3 4
>>> x # 由于在函数中定义了一个全局的x,所以此时全局中能够访问到x
3
>>> y
NameError: name 'y' is not defined # y在函数执行完后,就被释放了
如果局部变量与全局变量具有相同的名字,那么该局部变量会在自己的作用域内隐藏同名的全局变量。也就是说,是先使用局部变量,局部中没有那个变量了再到全局寻找,如果全局有,那使用的就是全局变量。
相同名称的局部变量与全局变量在内存中的位置是不同的,以使用id()来查看变量在内存中的位置。
>>> def demo():
x = 3 # 创建了局部变量,并自动隐藏了同名的全局变量
>>> x = 5
>>> x
5
>>> demo()
>>> x # 函数执行不影响外面全局变量的值
5
但对于可变类型来说,可以不需要global声明就可以更改其元素的值。下面以列表举例
l = [1,2,3]
def func():
# l = [6,7,8] # 这里不能直接给l赋值
l.append(4) # 给全局的l增加一个元素4
func()
print(l) # [1, 2, 3, 4]
5.4.4 nonlocal关键字
nonlocal可以让函数修改其外层嵌套的函数中的变量,nonlocal 关键字只能用于嵌套函数中,不能够作用于全局与内置。
nonlocal什么的变量的查找顺序是:向外层嵌套的函数一层一层的向外找,找到最外层函数了还没找到,就报错,并不会向全局和内置中找。
按照LEGB的名称空间分类方式来讲就是,nonlocal声明的变量是在enclosing中找。
x = 10
def func1():
x = 20 # 如果将这里的x注释掉,则会报错(甚至都不用调用函数就提示未找到x)
def func2():
nonlocal x
x = 30 # 这里修改的是func1中的x
print('调用func2之前的x:', x) # 20
func2()
print('调用func2之后的x:', x) # 30
func1()
print('全局的x', x) # 10
x = 10
def f1():
x=20 # 如果f2中没有x,f1中有,那f3中的x就是f1中的。如果f1中也没有x,那么就找不到x,报错。(不会去全局找)
def f2():
x=30 # 如果f2中有x,那么f3中声明的x就是f2中的
def f3():
nonlocal x # 声明x是非本地的
x = 40
总结:需要修改本地的变量直接修改即可;需要修改本地之外的局部作用域中的变量,需要用nonlocal来声明;需要修改全局的变量,就用global来声明。
5.5 lambda表达式
lambda表达式可以用来声明匿名函数,也就是没有函数名字的临时使用的小函数,尤其适合需要一个函数作为另一个函数参数的场合。也可以定义具名函数。
lambda表达式只可以包含一个表达式,该表达式的计算结果可以看作是函数的返回值,不允许包含复合语句,但在表达式中可以调用其他函数。
lambda 与def定义函数基本类似:
lambda x,y=1,*args,**kwargs: x+y # 由于这里的args和kwargs并没有返回,所以没有啥意义,理解不了的话可以忽略他们
# 等价于:
def func(x,y=1,*args,**kwargs): # 区别只是lambda定义的函数没有名字而已
return x+y
res = (lambda x,y=1:x+y)(20) # 也可以通过这样的方式调用匿名函数,但是通常不会这样用.后面的括号域调用有名函数的括号一样,里面放的是函数所需参数。
print(res) # 21
res = (lambda x:print('你好'))(1) # 也可以在lambda的返回值处写一个函数的调用,返回的是函数的返回值
# print()的返回值是None,所以res的值为None,print('你好')也会执行。
print(res)
输出:
你好
None
>>> f = lambda x, y, z: x+y+z # 可以给lambda表达式起名字
>>> f(1,2,3) # 像函数一样调用(一般不这样用)
6
>>> g = lambda x, y=2, z=3: x+y+z # 参数默认值
>>> g(1)
6
>>> g(2, z=4, y=5) # 关键参数
11
>>> L = [1,2,3,4,5]
>>> print(list(map(lambda x: x+10, L))) # 模拟向量运算
[11, 12, 13, 14, 15]
>>> L
[1, 2, 3, 4, 5]
>>> data = list(range(20)) # 创建列表
>>> data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
>>> import random
>>> random.shuffle(data) # 打乱顺序
>>> data
[4, 3, 11, 13, 12, 15, 9, 2, 10, 6, 19, 18, 14, 8, 0, 7, 5, 17, 1, 16]
>>> data.sort(key=lambda x: x) # 和不指定规则效果一样
>>> data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
>>> data.sort(key=lambda x: len(str(x))) # 按转换成字符串以后的长度排序
>>> data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
>>> data.sort(key=lambda x: len(str(x)), reverse=True) # 降序排序
>>> data
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
5.6 装饰器
5.6.1 装饰器
开放封闭原则
- 开放:对扩展功能(增加功能)开放,扩展功能的意思是,在源代码不做任何改变的情况下为其增加功能
- 封闭:对修改源代码是封闭的
装饰器:不修改被装饰对象的源代码,也不修改调用方式的前提下,给被装饰对象添加新的功能,的可调用对象。
下面举例说明:
需求:添加一个统计代码运行时间,并将运行时间打印到终端的功能。
# 源代码
def inside(group,s):
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print('全军出击')
方案一
# 方案一
# 没有修改调用方式,但修改了源代码
import time # 导入time模块 time.time()可获取当前时间的时间戳
def inside(group,s):
start = time.time() # 添加的功能
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print('全军出击')
end = time.time() # 添加的功能
print(end-start) # 添加的功能
inside('蓝',5)
方案二
# 方案二
# 没有修改被装饰对象的代码,也没有修改调用方式,并且为其增加了新的功能,但重复代码过多,代码冗余
def inside(group,s):
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print('全军出击')
# 每调用一次都要使用重复的三行代码去统计时间,代码冗余
start = time.time()
inside('蓝',5)
end = time.time()
print(end - start)
start = time.time()
inside('蓝',5)
end = time.time()
print(end - start)
方案三
# 方案三
# 解决了方案二的代码冗余问题,也没有修改源代码,并添加了新的功能,但更改了调用的方式
def inside(group,s):
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print('全军出击')
def wrapper():
start = time.time()
inside('蓝',5) # 被装饰的函数参数写死
end = time.time()
print(end - start)
wrapper() # 修改了调用方式
方案四
# 方案四
# 在方案三的基础上,暂且不考虑调用方式被更改的问题。解决函数参数写死的问题
def inside(group,s,b):
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print(f'{b}出击') # 这里改了一下,将全军出击,该为了XX出击(与所要说的装饰器无关)
def wrapper(*args,**kwargs): # 这里传参可参考“可变长度的参数”那部分的内容来理解
start = time.time()
inside(*args,**kwargs) # 但是这里的被装饰对象被写死了
end = time.time()
print(end - start)
wrapper('红',s=3,b='炮车')
方案五
# 方案五
# 暂且不考虑调用方式被更改的问题。解决被装饰对象写死的问题
def inside(group,s,b): # 这是一个被装饰对象
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print(f'{b}出击')
def recharge(): # 这也是一个被装饰对象
for i in range(101):
print(f'正在充电 %{i}')
time.sleep(0.1)
print('电已充满')
def f(func): # 将被装饰对象传进来
# 当f被调用时,wrapper并不会被执行;f的作用只是将受到的实参赋值给func,并将wrapper的地址返回,以便能在全局调用;
def wrapper(*args,**kwargs):
start = time.time()
func(*args,**kwargs)
end = time.time()
print(end - start)
return wrapper # 将wrapper的地址作为函数f的返回值,使得能够在全局调用到wrapper
res = f(inside) # 将inside函数传给f。f返回一个如同方案四中的装饰器wrapper
res('蓝',s=3,b='全军')
res = f(recharge) # 另一个函数recharge也可以用同样的方法被装饰了。
res() # 但调用方式被更改了。
方案七
方案六好像写漏了,有可能是当时写的时候编漏了,为了与代码中的保持一致,这里就不改了。
# 方案七
# 解决调用方式被更改的问题
def inside(group,s,b):
print('欢迎来到王者荣耀')
print(f'你出生在{group}方阵营')
print(f'敌军还有{s}秒到达战场')
time.sleep(s)
print(f'{b}出击')
def recharge():
for i in range(101):
print(f'正在充电 %{i}')
time.sleep(0.1)
print('电已充满')
def f(func):
def wrapper(*args,**kwargs):
start = time.time()
func(*args,**kwargs)
end = time.time()
print(end - start)
return wrapper
inside = f(inside) # 将wrapper赋值给被装饰对象函数名,将其覆盖(替换)。这一步后面会使用语法糖实现
inside('蓝',s=3,b='全军') # 表面上调用的是inside,实际上调用的是wrapper,但参数传递仍相同
recharge = f(recharge)
recharge()
方案八 最终版本
# 方案八
# 解决无法接收被装饰对象返回值问题 最终版本
def recharge(n):
for i in range(n,101):
print(f'\r正在充电{"▥"*int(i/10)} %{i}',end='') # ▥,这里给这个函数优化了一下,重点是在后面
time.sleep(0.01)
print('\n电已充满')
return 666
def f(func):
def wrapper(*args,**kwargs):
start = time.time()
response = func(*args,**kwargs) # 用一个变量接着被装饰对象的返回值
end = time.time()
print(end - start)
return response # 返回被装饰对象的返回值
return wrapper
recharge = f(recharge) # 这一步后面可使用语法糖替代
res = recharge(20) # 这里相当于调用了wrapper,wrapper的返回值为response,response又是被装饰对象func的返回值。
print(res) # 所以这里拿到的就是被装饰对象的的返回值
语法糖
写在被装饰对象之前,装饰器之后。更准确的说是语法糖后面需要紧跟被装饰对象,中间不能有其他任何语句。
# 语法糖 @装饰器名
# 替代了将被装饰对象的函数名中的内存地址替换成wrapper的内存地址(方案七、八)的操作
# 最终的装饰器
def count_time(func): # 装饰器名为count_time
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs) # 用一个变量接着被装饰对象的返回值
end = time.time()
print(end - start)
return res # 返回被装饰对象的返回值
return wrapper
@count_time # 写在被装饰函数前,装饰器后。 语法糖的作用相当于recharge = count_time(recharge)
def recharge(n):
for i in range(n, 101):
print(f'\r正在充电{"▥" * int(i / 10)} %{i}', end='') # ▥
time.sleep(0.01)
print('\n电已充满')
return 666
recharge(10) # 使用语法糖后可就可直接调用被装饰函数
设置装饰器模版
def outer(func):
def wrapper(*args, **kwargs):
res = func(*args, **kwargs)
return res
return wrapper
设置装饰器模版:打开设置
出现提示时,直接回车就会补全设置的装饰器模版。
练习:写一个认证功能的装饰器
使用户输入账号和密码,账号密码正确时才执行home功能
def auth(func):
def wrapper(*args,**kwargs):
uid = input('请输入账号:')
pwd = input('请输入密码:')
if uid == 'chuang' and pwd == '123':
res = func(*args,**kwargs) # 条件成立时才执行home函数
return res # res也要在缩进里面,否则条件不成立是res没有被赋值,就会报错
else:
print('账号或密码错误!')
return wrapper
@auth
def home():
print('welcome')
home()
完美伪装
完美伪装就是使装饰器的某些属性变得和被装饰函数的某些属性相同。比如说函数名(__name__)、函数文档注释(__doc__)。
其实前面所说的装饰器就已经能够实现装饰的功能了,不做完美伪装一般也不会对使用有什么影响。
为了方便演示,就以下面这段代码为例:
def outer(func):
def wrapper(*args,**kwargs):
res = func(*args,**kwargs) # 不为home添加任何功能
return res
return wrapper
# @outer
def home():
"""这是home"""
print('welcome')
# 将语法糖注释掉,打印home被装饰前的属性
print(home) # 函数名和地址
print(home.__name__) # 函数名
print(home.__doc__) # 函数文档注释
<function home at 0x000001C7459876D0>
home
这是home
# 装饰后的home的属性
<function outer.<locals>.wrapper at 0x000001711E507760>
wrapper
None
# 可以看到,装饰后的home实际上是装饰器中的wrapper这个函数。
为了使这些属性也保持相同,我们可以在装饰器内部作如下处理:
def outer(func):
def wrapper(*args,**kwargs):
res = func(*args,**kwargs) # 不为home添加任何功能
return res
wrapper.__name__ = func.__name__ # 将func也就是home的属性赋值给wrapper后,
wrapper.__doc__ = func.__doc__ # 再查看wrapper的属性时就可以和home的属性保持一致
# home还有很多其他的属性、、、
return wrapper
但是,一个函数拥有很多的属性,我们一个个更改的话很麻烦。python给我们提供了一个功能warps,warps其实也是应该装饰器,它可以更改被装饰函数的属性。
from functools import wraps # 只导入functools模块下的wraps功能
def outer(func):
@wraps(func) # wraps是个有参装饰器,将参数func的所有属性全部赋值给被装饰对象wrapper的属性
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper
# @outer
def home():
"""这是home"""
print('welcome')
print(home)
print(home.__name__)
print(home.__doc__)
<function home at 0x0000022655FC6EF0>
home
这是home
# 这时候再打印被装饰后的home的属性,可以看到,就像没有被装饰后一样了。
5.6.2 有参装饰器
当函数内部需要参数时,我们有两种方式可以实现,直接通过参数从传入或通过闭包函数传入。
现在考虑如何给装饰器传参,也就是有参装饰器。
如果直接将参数作为装饰器的参数直接传入,但由于语法糖的限制,outer的参数只能有一个。所以这个方法不行。
def outer(func,aaa): # 如果直接将aaa作为装饰器的参数传入
def wrapper(*args,**kwargs):
print(aaa) # 如果装饰器内部需要一个参数aaa
res = func(*args,**kwargs)
return res
return wrapper
@outer # 语法糖的作用等价于home = outer(home),但由于我们给outer增加了一个参数,所以会提示“缺少一个必须的位置参数
def home(): # 以被装饰对象home为例
print('this is home')
如果不使用语法糖呢?比如向下面这样:
home = outer(home,'hello') # 直接使用赋值语句,给aaa传一个值'hello'进去
这样作虽然也可以,但是会使代码显得没有那么简洁,为了使代码看起来更加高级,我们使用下面这种方法来实现有参装饰器。
使用闭包函数的特点,在装饰器外再包一层函数,将装饰器所需要的函数传递进去。
def g_outer(aaa): # 在outer再包一层函数g_outer,用于将装饰器所需要的参数传入
def outer(func):
def wrapper(*args,**kwargs):
print(aaa) # 如果装饰器内部需要一个参数aaa
res = func(*args,**kwargs)
return res
return wrapper
return outer # 这里别忘了将outer的名称返回,这样才可以在全局中调用到它
当使用这种方法之后,我们对函数进行装饰时就需要这样做:
outer = g_outer('hello') # 将参数aaa的值传入,并将g_outer内部的outer返回,并赋值给outer,使得outer能够在全局调用
@outer # 与与无参装饰器一样,home = outer(home)。outer还是原来的outer,所以不需要改
def home(): # 被装饰对象home
print('this is home')
outer = g_outer('123456789') # 如果装饰器所要的参数不同时,还需要在写一遍这个语句,将所需的参数传入
@outer
def home2(): # 被装饰对象home2
print('this is home2')
虽然这样做已经实现了将参数传入到装饰器中,但是,如果需要的参数不同,每次装饰函数时都需要写两条语句,感觉还不够简洁,下面再进行优化一下。
注意到,上面的代码中我们将g_outer()的返回值赋值给outer,然后再使用@outer对函数进行装饰,那我们也可以直接将g_outer()放在@后面,就像下面这样:
@g_outer('hello') # 等价于@outer 再等价于home = outer(home)
@后面原本跟着的是outer,但由于outer是g_outer()的返回值,所以直接将g_outer()放在@后面也是一样的。(如果不理解,可以看前面函数的传递,将函数的返回值作为函数的参数进行传递的那部分内容)
有参装饰器最终版本
至此,有参装饰器的最终版本为:(这里也可以将模版加入到PyCharm的实时模版)
def g_outer(x):
def outer(func):
def wrapper(*args,**kwargs):
res = func(*args,**kwargs)
return res
return wrapper
return outer
# 装饰函数的方式:
@g_outer('装饰器参数x') # 当然也可以穿多个参数,但g_outer那里也要跟着改。
def home(): # 被装饰对象
pass
案例
案例:在前面写的,认证功能的装饰器的基础上,通过传入的参数来控制认证的方式。
def auth(source): # 通过source参数来控制使用何种认证方式
def outer(func):
def wrapper(*args, **kwargs):
account_number = input('请输入账号:')
password = input('请输入密码:')
if source == 'file':
print("基于文件的登录验证") # 这个功能根据前面学过的知识是可以写出来的(具体代码放在后面)
elif source == 'mysql':
print('基于mysql的登录验证') # 实际功能从略,使用print来代替
elif source == 'ldap':
print('基于ldap的登录验证')
else:
print('不支持此类验证')
return wrapper
return outer
@auth('ldap')
def home():
print("this is home")
home()
print("基于文件的登录验证")
with open(r'date\user', encoding='utf-8', mode='rt') as f:
for res in f:
l = res.split('---')
if not (l[0] == account_number and l[1] == password):
continue # 账号密码不正确就直接进入下一次循环
print('账号密码正确')
res = func(*args, **kwargs)
return res # 账号密码正确,执行完被装饰对象func后,就可以退出装饰器,并将func的返回值返回了
else: # 读取完文件中所有的账号密码,仍然没有匹配,就提示错误
print('账号或密码错误')
5.6.3 装饰器叠加
直接说例子:
为了方便理解,这里以三个无参装饰器为例。实际上就算是有参装饰器,执行原理和过程也是一样的。
# 装饰器1
def outer1(func1):
def wrapper1(*args, **kwargs):
print('wrapper1打开')
res1 = func1(*args, **kwargs) # func1= 原prt
print('wrapper1退出')
return res1
return wrapper1
# 装饰器2
def outer2(func2):
def wrapper2(*args, **kwargs):
print('wrapper2打开')
res2 = func2(*args, **kwargs) # func2= outer1.wrapper1 相当于wrapper1(*args, **kwargs)
print('wrapper2退出')
return res2
return wrapper2
# 装饰器3
def outer3(func3):
def wrapper3(*args, **kwargs):
print('wrapper3打开')
res3 = func3(*args, **kwargs) # func3= outer2.wrapper2 相当于wrapper2(*args, **kwargs)
print('wrapper3退出')
return res3
return wrapper3
# 有多个装饰器时,先执行被装饰函数头顶上的,然后依次往上
@outer3 # prt = outer3(prt)即 outer3(wrapper2) prt-->wrapper3 func3-->wrapper2
@outer2 # prt = outer2(prt)即 outer2(wrapper1) prt-->wrapper2 func2-->wrapper1
@outer1 # prt = outer1(prt) prt-->wrapper1 func1-->原来的prt
def prt():
print('鸡蛋鸭蛋荷包蛋')
return '搞快点!搞快点!'
res = prt()
print(res)
先说一下语法糖的执行顺序:先执行被装饰函数头顶上的语法糖,然后依次向上执行
(为了方便,下面的wrapper1、2、3简称为w1、2、3。func1、2、3简称为f1、2、3。)
- 首先执行@outer1,等价语句为prt = outer1(prt)。执行完毕后,outer1的参数func1指向的是原被装饰对象prt的内存地址;全局中的prt指向w1的内存地址。
- 其次执行@outer2,等价语句为prt = outer2(prt)。执行完毕后,outer2的参数func2指向的是w1的内存地址;全局中的prt指向w2的内存地址。
- 其次执行@outer3,等价语句为prt = outer3(prt)。执行完毕后,outer3的参数func3指向的是w2的内存地址;全局中的prt指向w3的内存地址。
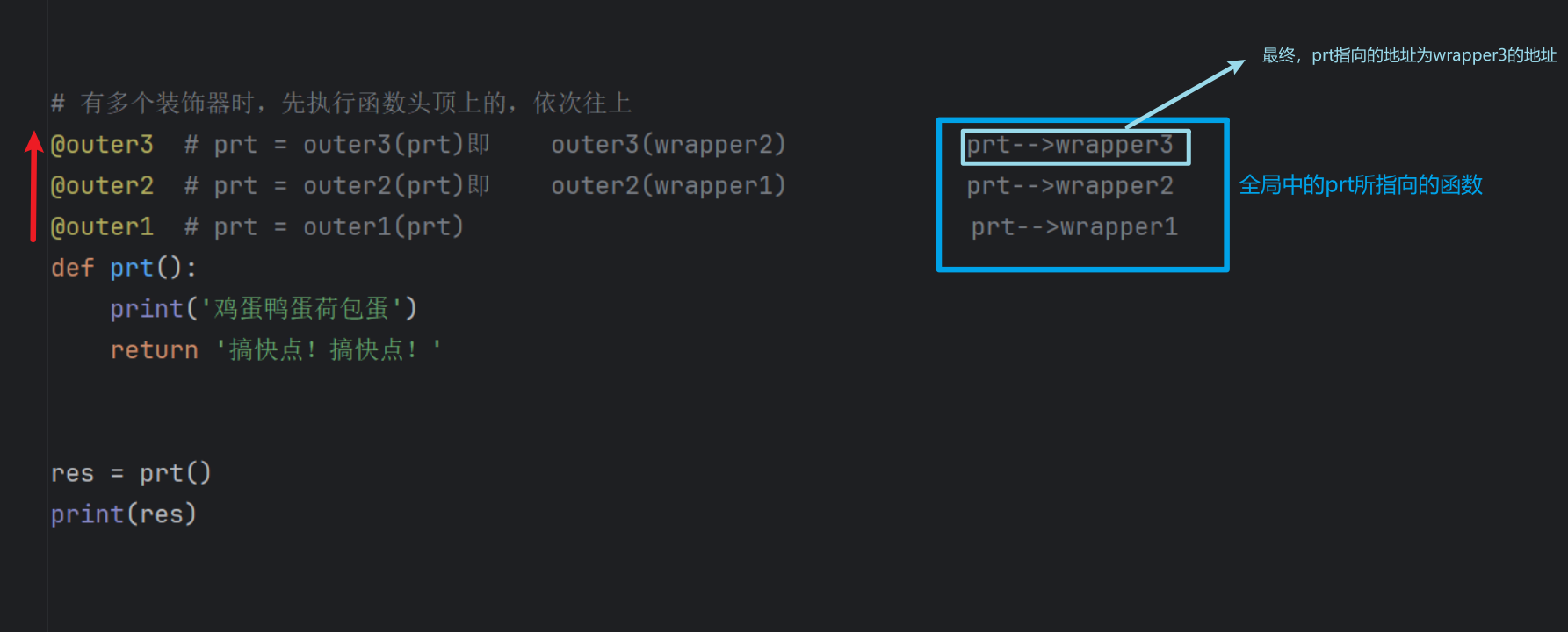
语法糖执行完毕后我们对各变量所指向的内存地址做个总结:
| 变量名 | 实际指向的内存地址 |
|---|---|
| prt | wrapper3 |
| func3 | wrapper2 |
| func2 | wrapper1 |
| func1 | 原来的prt |
装饰后调用prt的执行过程:
根据上面的分析,全局中的prt最终指向的是wrapper3的地址,所以调用prt时,就会先执行wrapper3中的代码。执行过程如下:
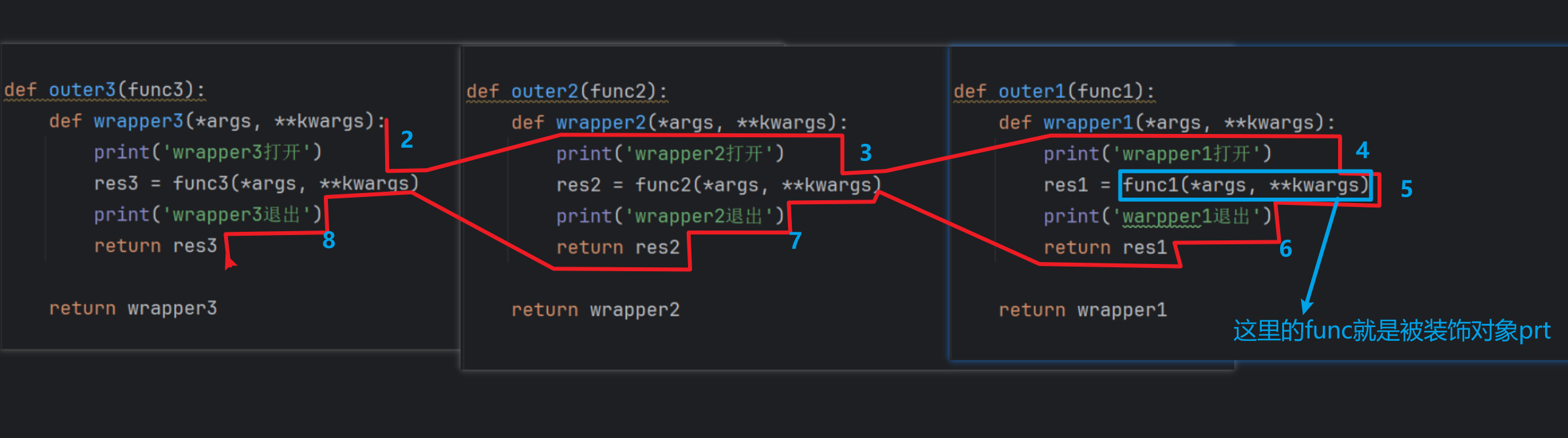
- 首先是执行全局中的代码
res = prt(),调用prt,由于prt指向的是w3的地址,所以接下来执行的是w3的字代码。 - 在w3中先执行print,打印
wrapper3打开,然后执行下一行,将w3接受到的参数(虽然本例中没有传参数)原封不动的传给f3,由于f3指向的是w2的地址,所以接下来执行的是w2的字代码。 - 在w2中,与w3一样,先
print('wrapper2打开'),然后将w2的参数原封不动的给f2,执行f2,f2指向的是w1的地址,所以接下来执行的是w1的字代码。 - 在w1中,执行print('wrapper1打开'),然后将w1的参数有给f1,执行f1,由于f1指向的是被装饰函数prt的地址,所以接下来执行prt的字代码。
- 在prt中,打印print('鸡蛋鸭蛋荷包蛋'),然后将返回值'
搞快点!搞快点!'return出去,prt执行完毕退出。 - 返回调用prt的地方,也就是w1的
res1 = func1(*args, **kwargs)这一行,f1(也就是prt)执行完后,将返回值'搞快点!搞快点!'赋值给res1,然后执行下一行打印print('wrapper1退出'),最后将返回值res1返回出去。w1执行完毕。 - 返回调用w1的地方,也就是w2的
res2 = func2(*args, **kwargs),将f2(也就是w1)的返回值赋值给res2,然后执行下一行打印print('wrapper2退出'),最后将返回值res2返回出去,w2执行完毕。 - 返回调用w2的地方,也就是w1的
res3 = func3(*args, **kwargs),将f3(也就是w2)的返回值赋值给res3,然后执行下一行打印print('wrapper3退出'),最后将返回值res3返回出去,w3执行完毕。 - 返回调用w3的地方,也就是全局的
res = prt(),将返回值赋值给res。下一行print(res),将原本的prt的返回值打印出来,至此完毕。
运行结果如下:与我们分析的结果相同
wrapper3打开
wrapper2打开
wrapper1打开
鸡蛋鸭蛋荷包蛋
wrapper1退出
wrapper2退出
wrapper3退出
搞快点!搞快点!
5.7 迭代器、可迭代对象
5.7.1 可迭代对象
可迭代对象:内置有__iter__()方法的对象,也可以说,可以转换成迭代器的对象就称之为可迭代对象。
例如字符串、列表、字典、元组、集合、文件对象。
s = 'love' # 字符串
s.__iter__()
l = [1, 2, 3] # 列表
l.__iter__()
dic = {1: 'one', 2: 'two', 3: 'three'} # 字典
dic.__iter__()
tup = (1, 2, 3) # 元组
tup.__iter__()
aggre = {1, 2, 3} # 集合
aggre.__iter__()
with open(r'date\read.txt',mode='rt',encoding='utf-8')as f:
f.__iter__() # 文件对象
f.__next__() # 文件对象既是可迭代对象,又是迭代器对象
print(list(f))
print(f.__iter__().__next__())
print(f.__next__())
5.7.2 迭代器
迭代器(iterator):内置有__iter__()方法,并且还内置__next__方法的对象(所以迭代器对象也是可迭代对象)
- 迭代器调用
__next__方法,就会得到迭代器的下一个值 - 迭代器调用
__iter__()方法,得到的仍然是迭代器本身(和没调一样)【证明如下】 - 迭代器不依赖于索引迭代取值
# 迭代器调用`__iter__()`方法,得到的仍然是迭代器本身(这样做的目的是为了让统一for循环的工作原理,后面一部分会讲)
abc = {1, 2, 3}
res = abc.__iter__() # 生成一个迭代器res
print(res is res.__iter__()) # True
5.7.3 __iter__()方法和__next__()方法
补充:
s = 'abc'
s.__len__()等价于len(s)
同样,s.__iter__()和s.__next__()也可写成iter(s)和next(s)
用法案例:
# __iter__()将可迭代对象生成一个迭代器对象,并返回
dic = {1: 'one', 2: 'two', 3: 'three'} # 以字典为例
res = dic.__iter__() # res是一个有dic生成的一个迭代器对象
print(res) # <dict_keyiterator object at 0x00000276B48D58A0> # 字典的key的迭代器
# 通过迭代器的__next()方法,可以对迭代器进行迭代取值
print(res.__next__()) # 取出res的第一个值
1 # 字典比较特殊,直接使用__iter__()方法生成的迭代器是由字典的key构成的
print(res.__next__()) # 取出res下一个值,(也就是第二个值)
2
print(res.__next__())
3 # 字典总共有三个key,所以res也只有三个“值”,现在已经取出三个来了,
print(res.__next__())
# 迭代器的值取完之后,再使用__next__()方法就会抛出异常:StopIteration (意思为“停止迭代”)
# 若还需要对迭代器进行取值,那么只能重新再生成一个迭代器
res.__iter__()
使用while循环来对迭代器进行迭代取值
dic = {1: 'one', 2: 'two', 3: 'three'}
res = dic.__iter__()
while True:
try:
print(res.__next__()) # 使用__next__()方法对迭代器取值
except StopIteration: # 捕捉到StopIteration异常后执行下面缩进的代码
print('停止迭代StopIteration')
break
# 输出:
1
2
3
停止迭代StopIteration
5.7.4 for循环原理
执行步骤:
- 调用对象的
__iter__()方法,得到他的一个迭代器版本 - 调用该迭代器的
__next__()方法,拿到下一个返回值并赋值给i - 循环执行步骤2,直到抛出异常,就捕获异常,并结束循环
由于迭代器使用__iter__()得到的仍然是她本身,所以,在第一步中就不需要进行特殊处理,无论是可迭代对象还是迭代器,最终使用__iter__()方法得到的都是一个迭代器。
for i in 可迭代对象.__iter__():
for i in 迭代器对象.__iter__():
abc = {1, 2, 3}
for i in abc:
print(i)
list(),type()等方法的原理也与for循环原理类似
先对传入的参数(可迭代对象)使用__iter__()方法生成一个迭代器,然后使用__next__()方法对迭代器迭代取值,将取出的值放入到列表或元组中。
print(list('abc'))
print(tuple('abc'))
# ['a', 'b', 'c']
# ('a', 'b', 'c')
5.7.5 生成器
生成器(generator)其实也是一个迭代器,只不过生成器是有我们自定义的迭代器。
包含yield语句的函数可以用来创建生成器对象,这样的函数也称生成器函数。
yield语句与return语句的作用相似,都是用来从函数中返回值。与return语句不同的是,return语句一旦执行会立刻结束函数的运行,而每次执行到yield语句并返回一个值之后会暂停或挂起后面代码的执行,下次通过生成器对象的__next__()方法、内置函数next()、for循环遍历生成器对象元素或其他方式显式“索要”数据时恢复执行。
生成器具有惰性求值的特点,占用内存少,适合大数据处理。
下面是自定义生成器的例子:
# 自定义生成器
def func():
print('第一次执行')
yield 1 # yield返回一个值后,函数并不会停止,而是会暂停,下次进行执行后面的代码
print('第二次执行')
yield 2
print('第三次执行')
yield 3
print('验证后面没有yield时,代码还会不会执行')
res = func() # 此时函数func并不会执行 res是一个迭代器对象
print(res) # <generator object func at 0x00000243DF0C0E40>
print(next(res))
print(next(res))
print(next(res))
# print(next(res)) # 迭代器没有值了,停止迭代,同样是抛出StopIteration异常
输出:
第一次执行
1
第二次执行
2
第三次执行
3
验证后面没有yield时,代码还会不会执行 # 看来还是会执行的,当函数执行完毕,仍然没有遇到yield时,才会抛异常
StopIteration
注:不是说函数内部写了yield关键字,那个函数就是生成器。实际上,我们调用内部有yield关键字的函数时,函数字代码并不会正常执行,而是会返回一个生成器对象,这个对象才是生成器,比如上面的例子中的res。
现在说一下生成器的执行过程(以上面的例子为例):
- 首先执行res = func(),函数并不会执行,而是返回一个生成器对象。接下来使用next()方法来对生成器res迭代取值。
- 第一次执行next(res)时,函数从头开始执行,打印
print('第一次执行'),当遇到yield关键字时,函数暂停执行,并将yield关键字后的返回值返回。 - 第二次执行next(res)时,打印
print('第二次执行'),当遇到yield关键字时,函数暂停执行,并将yield关键字后的返回值返回。 - 同理,每次执行next(res)时,函数都会从上一次暂停时的yield关键字的地方开始执行,当遇到yield时,又将函数暂停,并返回yield后的返回值。
- 当迭代器取到最后一个值,也就是函数暂停在最后一个yield关键字的位置时,再执行一次next(res),函数仍然会继续向后执行,当函数执行完毕后,仍然没有遇到yield关键字,那么就会抛StopIteration异常,并停止执行。

例题:编写并使用能够生成斐波那契数列的生成器函数。
>>> def f():
a, b = 1, 1 # 序列解包,同时为多个元素赋值
while True:
yield a # 暂停执行,需要时再产生一个新元素
a, b = b, a+b # 序列解包,继续生成新元素
>>> a = f() # 创建生成器对象
>>> for i in range(10): # 斐波那契数列中前10个元素
print(next(a), end=' ') # 这里的next(a)相当于next(f())
1 1 2 3 5 8 13 21 34 55
>>> for i in f(): # 斐波那契数列中第一个大于100的元素
if i > 100:
print(i, end=' ')
break
144
>>> a = f() # 创建生成器对象
>>> next(a) # 使用内置函数next()获取生成器对象中的元素
1
>>> next(a) # 每次索取新元素时,由yield语句生成
1
>>> a.__next__() # 也可以调用生成器对象的__next__()方法
2
>>> a.__next__()
3
5.7.6 yield表达式(暂不需要掌握)
yield表达式在并发编程中用到。
# 给yield传参
def func(x):
print('func开始执行')
while True:
# 将yield的值赋值给y
y = yield None # yield后面不写返回值,默认返回的就是None
# 这里可以看成两部分,赋值y=yield和返回yield None
print(x,y)
g = func(123) # 又yield表达式的函数和普通函数一样,也需要传参。
g.send(None) # 迭代器刚开始时,给yield传的参只能是None
# g.send(None)和g.__next__()是一样的
g.send(1)
g.send(2)
g.send(3)
自己写一个程序,使用yield表达式控制函数的执行,同时还可以再两个函数之间切换。
比如:一个函数用来生成1、2、3、4这四个数的全排列,每生成一个全排列,就这个数传给另一个函数,另一个函数判断这个数是否为素数。(写着写着才发现,不仅没有达到要求,这样做反而还多此一举。。。略过略过。。。。)
def su_shu():
while True:
n = yield # 使用yield来收参数
for i in range(2, int(n ** 0.5)):
if n % i == 0:
break
else:
print(f'{n}是素数')
def qpl(l, level):
if level == len(l):
num = int(''.join(l)) # 将全排列结果转换为数字
# 调用判断素数的函数
g_su_shu.send(num)
for i in range(level, len(l)):
l[i], l[level] = l[level], l[i]
qpl(l, level + 1)
l[i], l[level] = l[level], l[i]
l = ['1', '2', '3', '4']
g_su_shu = su_shu()
g_su_shu.send(None) # 开始的第一个yield值必须为None
qpl(l, 0)
输出:
1423是素数
2143是素数
2341是素数
4231是素数
5.8 函数参数的类型提示
使用类型提示可以让函数的使用者更容易知道函数参数及返回值的类型。类型提示并不会对函数起到任何影响,只是起一个提示的作用。在python3.5以后才有。
函数参数的类型提示
- 在参数的后面加一个冒号
:,冒号后可以写类型提示,提示内容可以随意写。 - 当使用类型提示时,定义的默认值参数的等号需要写在提示内容后面。
- 在函数括号和冒号之间,使用
->可以进行返回值提示
# 函数参数的类型提示(3.5以后才有)
def func(a: int, b: '你是大傻蛋', c: str = 123) -> '返回值类型': # 给默认参数赋值式不能写在:前
print(a, b, c)
func(1, 2) # 类型提示只起到一个提示的作用,并不会影响函数的执行
print(func.__annotations__) # 查看函数提示信息
第七章、字符串
7.1 字符串简介
在Python中,字符串属于不可变有序序列,使用单引号、双引号、三单引号或三双引号作为定界符,并且不同的定界符之间可以互相嵌套。
除了支持序列通用方法(包括双向索引、比较大小、计算长度、切片、成员测试等操作)以外,字符串类型还支持一些特有的操作方法,例如字符串格式化、查找、替换、排版等等。
字符串属于不可变序列,不能直接对字符串对象进行元素增加、修改与删除等操作,切片操作也只能访问其中的元素而无法使用切片来修改字符串中的字符。
最早的字符串编码是美国标准信息交换码ASCII,仅对10个数字、26个大写英文字母、26个小写英文字母及一些其他符号进行了编码。ASCII码采用1个字节来对字符进行编码,最多只能表示256个符号。
7.2 字符串编码
- 最早的字符串编码是美国标准信息交换码ASCII,仅对10个数字、26个大写英文字母、26个小写英文字母及一些其他符号进行了编码。ASCII码采用1个字节来对字符进行编码,最多只能表示256个符号。
- GB2312是我国制定的中文编码,使用1个字节表示英语,2个字节表示中文;GBK是GB2312的扩充,而CP936是微软在GBK基础上开发的编码方式。GB2312、GBK和CP936都是使用2个字节表示中文。
- UTF-8对全世界所有国家需要用到的字符进行了编码,以1个字节表示英语字符(兼容ASCII),以3个字节表示常见中文字符,还有些语言的符号使用2个字节(例如俄语和希腊语符号)或4个字节。
不同编码格式之间相差很大,采用不同的编码格式意味着不同的表示和存储形式,把同一字符存入文件时,写入的内容可能会不同,在试图理解其内容时必须了解编码规则并进行正确的解码。如果解码方法不正确就无法还原信息,从这个角度来讲,字符串编码也具有加密的效果。
Python 3.x完全支持中文字符,默认使用UTF8编码格式,无论是一个数字、英文字母,还是一个汉字,在统计字符串长度时都按一个字符对待和处理。
>>> s = '中国山东烟台'
>>> len(s) # 字符串长度,或者包含的字符个数
6
>>> s = '中国山东烟台ABCDE' # 中文与英文字符同样对待,都算一个字符
>>> len(s)
11
>>> 姓名 = '张三' # 使用中文作为变量名
>>> print(姓名) # 输出变量的值
张三
7.3 转义字符
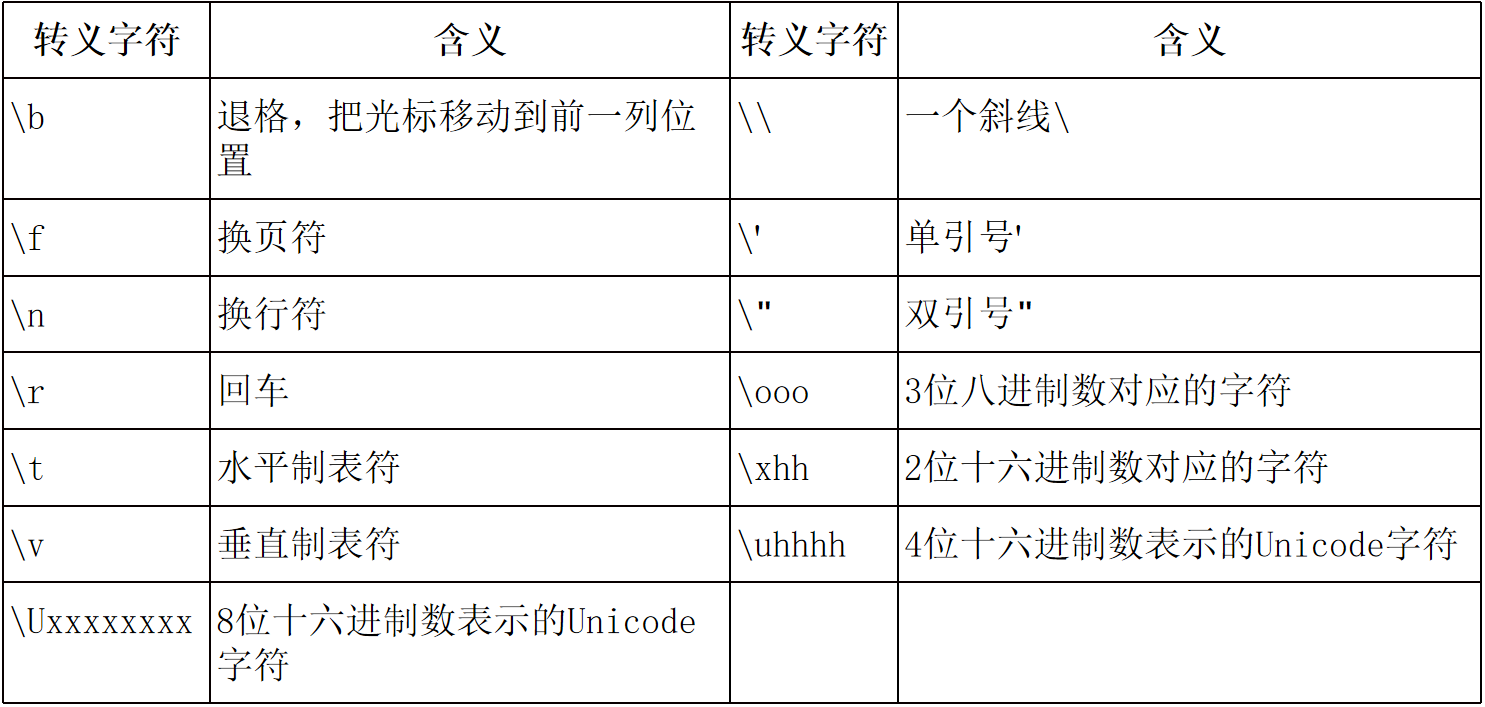
转义字符常见用法:
>>> print('Hello\nWorld') # 包含转义字符的字符串
Hello
World
>>> print('\101') # 三位八进制数对应的字符,\后面跟的数字默认是8进制
A
>>> print('\x41') # 两位十六进制数对应的字符,\x后面是16进制,\b二进制
A
>>> print('我是\u8463\u4ed8\u56fd') # 四位十六进制数表示Unicode字符
我是董付国
为了避免对字符串中的转义字符进行转义,可以使用原始字符串,在字符串前面加上字母r或R表示原始字符串,其中的所有字符都表示原始的含义而不会进行任何转义。
>>> path = 'C:\Windows\notepad.exe'
>>> print(path) # 字符\n被转义为换行符
C:\Windows
otepad.exe
>>> path = r'C:\Windows\notepad.exe' # 原始字符串,任何字符都不转义
>>> print(path)
C:\Windows\notepad.exe
7.4 字符串格式化
7.4.1 使用%运算符进行格式化
name = 'chuang'
age = 19
l = [1,2,3,4,5,6]
print('我的名字是%s'%name) # 单个变量
print('我的名字是%s,我的年龄是%d'%(name,age)) # 多个变量时,需要放到元组中,按照先后位置对应
print('保留两位小数:%.2f'%3.1415926)
print('这是一个列表:%s'%l) # 右边的变量也可以是容器类型
# 输出结果:
我的名字是chuang
我的名字是chuang,我的年龄是19
保留两位小数:3.14
这是一个列表:[1, 2, 3, 4, 5, 6]
# 猜测:左边字符串中%后面跟着的格式化字符(如s,d,f),并不会限制右边的类型,而是表示以什么样的方式来处理右边的变量。
# 可能%d就是调用int()方法,将右边的变量作为参数,处理之后得到一个结果,再将这个结果以字符串的形式加入到字符串中。
7.4.2 使用format()方法格式化字符串
format的三种传值方式:
1、按照位置传
左边括号{}中的参数为空,这时的传值方式是,将右边format()中的参数按照从左到右的顺序依次传入左边的空括号{}中。
2、按照括号中对应的参数位置传
左边括号{}中写数字0、1、2、、、n,这时,左边的括号中的数字n表示的是右边format()中的第n个参数,类似与列表的索引。这时传值可以不需要按照顺序。而且同一个参数可以在不同地方多次引用。
3、按照关键字参数传
左边括号{}中写关键字参数名称,右边的format()函数传值方式按照关键字参数的方式来串。这时,左边{}中的参数名就表示右边对应实参的值。
name = 'chuang'
age = 19
l = [1,2,3,4,5,6]
print('我的名字是{}'.format(name)) # 单个变量
print('我的名字是{},我的年龄是{}'.format(name,age)) # 按照对应位置传
print('我的名字是{0},我的年龄是{1}'.format(name,age)) # 也可以在{}中使用数字,数字n代表format()中的第n个参数
print('我的名字是{1},我的年龄是{0}'.format(age,name)) # 按照数字来传时可以不按顺序
print('我的名字是{name},我的年龄是{age}'.format(name=name,age=age)) # 按照关键字参数的方式来传,{}中的变量名就是关键字参数的变量名
print('我的名字是{aaa},我的年龄是{abc},我来自{zhongguo}'.format(abc=age,aaa=name,zhongguo='中国')) # 也可以不按顺序
print('这是一个列表:{0:}'.format(l))
输出结果:
我的名字是chuang
我的名字是chuang,我的年龄是19
我的名字是chuang,我的年龄是19
我的名字是chuang,我的年龄是19
我的名字是chuang,我的年龄是19
我的名字是chuang,我的年龄是19,我来自中国
这是一个列表:[1, 2, 3, 4, 5, 6]
使用format进行字符串填充
格式为:{变量 : 填充字符 >或^或< 字符串长度}
- 冒号左边的“变量”与前面的只有一个括号{}时的传递方式一样。
- 变量长度比设定的"字符串长度"短时,使用"填充字符"填充。
>表示做填充,^两边填充,<右填充
print('{0:-^9}'.format('娃哈哈')) # 字符串长度不足9,则在两边填充符号-
print('{0:-<9}'.format('娃哈哈')) # 字符串长度不足9,则在右边填充符号-
print('{:-<9}123456{:a<10}'.format('娃哈哈','爽歪歪')) # 冒号左边空着,按照对应位置传值
输出结果:
---娃哈哈---
娃哈哈------
娃哈哈------123456爽歪歪aaaaaaa
使用format控制精度
控制精度的格式和c语言差不多
print('{:.3f}'.format(3.1415926))
print('{0:.3f}, {1:.2f}'.format(3.1415926,123.456))
print('{num:.10f}'.format(num=3.1415926))
输出结果:
3.142
3.142, 123.46
3.1415926000
其他
- 逗号
,表示对数字进行千位分隔,例如10000格式化为10,000 #b,#o,#x分别表示将数字格式化为二进制、八进制、十六进制输出
print('普通输出{0:}---千位分隔{0:,}'.format(123456789))
print('二进制{0:#b},八进制{0:#o},十六进制{0:#x}'.format(16))
输出结果:
普通输出123456789---千位分隔123,456,789
二进制0b10000,八进制0o20,十六进制0x10
7.4.3 使用f格式化字符串
f与format一样,只不过比format更加方便。在使用f格式化字符串时,字符串括号{}中的变量需要填写已经存在的变量。
name = 'chuang'
age = 19
print(f'我的名字是{name},我的年龄是{age}') # 在字符串的''前加上f,可以在字符串中的{}内写变量
print(f'我的名字是{name},我的年龄是{age},我来自{"中国"}') # 也可以在括号中直接写字符串,但是字符串的引号要与外层引号不同。
print(f'我的名字是{name},我的年龄是{age},我来自{name,age}') # 传多个变量时打包为元组形式的字符串
输出结果:
我的名字是chuang,我的年龄是19
我的名字是chuang,我的年龄是19,我来自中国
我的名字是chuang,我的年龄是19,我来自('chuang', 19)
7.5 字符串常用方法
7.5.1 查找
1、find(),rfind()
find()的作用类似与数据结构中的模式匹配,也就是找子串。
三个参数,sub,start,end。其中sub是待匹配的子串,start和end是在字符串s中的查找范围,其端点取值与字符串切片一样,也是顾头不顾尾。
返回的结果是第一个匹配的子串的第一个字符,在字符串s中的索引。
rfind()与find()类似,只不过find()是从左向右,返回第一个匹配到的子串,而rfind()是从右向左。
s = 'hello world'
print(s.find('llo')) # 返回的结果是第一个匹配的子串的第一个字符,在字符串s中的索引
print(s.find('llo',3,6)) # 在字符串s[3,6]中寻找子串'llo',找不到返回-1
print(s.find('l')) # 从左边开始第一个匹配的'l'
print(s.rfind('l')) # 从右边开始第一个匹配的'l'
输出结果:
2
-1
2
9
2、index(),rindex()
index()与find()一样,区别是index找不到会报错。
rindex()是从右向左找。
s = 'hello world'
print(s.index('llo'))
# print(s.index('llo',5,100)) # 找不到报错,substring not found
print(s.index('l'))
print(s.rindex('l'))
输出结果:
2
2
9
3、count()
返回指定范围中子串出现的次数。也是三个参数sub,start,end;sub是要统计的子串,start和end用来指定查找的范围,顾头不顾尾,与range、字符串切片一样。
s = 'hello world'
print(s.count('l'))
print(s.count('a'))
输出结果:
3
0
7.5.2 拆分
split()、rsplit()
split有三个参数sep、maxsplit。
- sep表示拆分的分隔符,默认为None,表示拆分所有空白字符(包括 \n \r \t \f 和空格)。
- maxsplit表示最拆分次数,默认值为-1,表示没有限制。
# split()、rsplit()
s1 = 'apple--banana-potato'
print(s1.split('-')) # 以'-'作为分隔符进行拆分,两个连续的-之间拆分出一个空字符
print(s1.split('--',maxsplit=1)) # 指定最大拆分次数,达到最大拆分次数时,后面的字符将不再进行拆分
输出结果:
['apple', '', 'banana', 'potato']
['apple', 'banana-potato']
s2 = ' \n\n abc \t de \t\t fgh\n '
print(s2.split()) # 默认以空白字符作为分隔符
# 注:分隔符为默认时,多个连续的空白字符将作为一个分隔符进行拆分
print(s2.split('\n')) # 但当指定以某个空白字符来进行拆分时,将不会合并
print(s1.rsplit('-',maxsplit=1)) # 从右往左进行拆分
输出结果:
['abc', 'de', 'fgh']
[' ', '', ' abc \t de \t\t fgh', ' ']
['apple--banana', 'potato']
7.5.3 连接 join()
将调用join方法的字符串作为连接符,将join的参数的元素进行连接,并返回一个新的连接后的字符串。
join的参数需要是一个可迭代对象(iterable),且可迭代对象的每个元素都必须是str类型。
l = ['apple','banana','potato']
tup = ('apple','banana','potato')
s1 = '连接符'.join(l)
s2 = '-'.join(tup)
print(s1)
print(s2)
输出结果:
apple连接符banana连接符potato
apple-banana-potato
s3 = '***'.join('大家好') # 也可以直接将字符串进行拼接
print(s3)
# 大***家***好
7.5.4 大小写转换
lower()、upper()、capitalize()、title()、swapcase()
s = 'I am a student.This is 2023 years'
print(s.lower()) # 返回全小写的字符串
print(s.upper()) # 返回全大写的字符串
print(s.capitalize()) # 返回的字符串,第一个字母大写,其他全部小写
print(s.title()) # 每个单词首字母大写
print(s.swapcase()) # 大小写互换
输出结果:
i am a student.this is 2023 years
I AM A STUDENT.THIS IS 2023 YEARS
I am a student.this is 2023 years
I Am A Student.This Is 2023 Years
i AM A STUDENT.tHIS IS 2023 YEARS
7.5.5 替换
1、replace()
- 三个位置参数,old,new,count。
- 返回一个新字符串,其中所有出现的子字符串 old 都替换为 new。
- count指定替换次数,默认为-1,表示全部替换。
s = '你好,你好,你好'
print(s.replace('你好','hello')) # 替换所有字符
print(s.replace('你好','hello',1)) # 替换一个
2、maketrans()
- maketrans()用来生成字符映射表,通常与translate()组合使用。
- 生成的映射表是一个字典,键和值分别是maketrans的第一个参数和第二个参数的ASCII码值(实际上是Unicode码值)。
- 两个参数的长度必须相同
table = ''.maketrans('abcde','ABCDE') # 通常用空字符串''来调用功能就可以啦
table = str.maketrans('abcde','ABCDE')
# maketrans是str类下面的一个方法,调用时可以通过对象(比如空字符串'')来调用,也可以使用类来调用(str)
print(table,type(table))
{97: 65, 98: 66, 99: 67, 100: 68, 101: 69} <class 'dict'>
3、translate()
根据映射表中定义的对应关系,转换字符串,并替换其中的字符。
s = 'abc123aaaccc'
s1 = s.translate({97: 65, 98: 66, 99: 67, 100: 68, 101: 69})
print(s1) # ABC123AAACCC
# 转换字符时并不是按照顺序来的,而是将字符串中符合映射条件的所有字符全部都替换掉。
# 比如映射表中有一个'a'到'A'的映射(97::65)那么字符串中所有的a都会被替换为A
table = ''.maketrans('abc123','xyz789') # 创建'abc123'到'xyz789'的映射表
s2 = s.translate(table) # 使用创建的映射表进行转换
print(s2) # xyz789xxxzzz
# 将s中的所有a替换为x,b替换为y,c替换为z。。。。。。
例题:将英文字母向后偏移n位。例如偏移3位时,a变为d,b变为e,c变为f。。。x变为a,y变为b,z变为c。大写字母也是一样,A变为D。。。
import string
s_low = string.ascii_lowercase # 小写字母
s_up = string.ascii_uppercase # 大写字母
s_low_up = string.ascii_letters # 小写+大写
n = 3
# 创建映射
table = ''.maketrans(s_low_up,s_low[n:]+s_low[:n]+s_up[n:]+s_up[:n])
s = 'abc,ABC,hello,xyz'
s2 = s.translate(table) # 使用映射进行转换
print(s2) # def,DEF,khoor,abc
7.5.6 删除
strip()、rstrip()、lstrip()
默认删除两边的空白字符
# strip()、rstrip()、lstrip()
s = '\n \t\t \n 你好 \t \t 啦啦啦 \n\t \t \n\n \t'
print(s.strip()) # 默认删除空白字符
# 你好 啦啦啦
删除指定字符
注意:删除字符时,是一层一层的往里扒,如果遇到一个字符是指定的要删除的字符,则删除,如果不是,就停止。
print('aabaa hello aaa你好aaa'.strip('a')) # 删除两端的字符a
# baa hello aaa你好 # 左边遇到'b'时停止,右边遇到“好”时停止
也可以删除多个字符
print('aabaa hello aaa你好ababab'.strip('ab'))
# ' hello aaa你好 ' # hello前面的空格没有被删除
# ab并不是作为一个整体来进行匹配的,而是分开的。例如遇到一个字符,判断它是a或是b,如果是其中一个,就删除,都不是,就停止
从左边或右边删除
print('aabaa hello aaa你好ababab'.rstrip('ab')) # 从右边删除
# 'aabaa hello aaa你好'
print('aabaa hello aaa你好ababab'.lstrip('ab')) # 从左边删除
# ' hello aaa你好ababab'
7.5.7 判断开始和结束
startswith()、endswith()
检测字符串是否以指定字符字符串开始或结束,是则返回True,否False。
start参数和end参数用来指定检测的范围,顾头不顾尾,与字符串切片一样。
s = 'Hello world'
print(s.startswith('H')) # 检测整个字符串是否以H开头
print(s.startswith('H',5)) # 指定检测范围的起始位置
print(s.endswith('l',5,-1)) # 检测范围为s[5:-1],也就是' worl'顾头不顾尾
# 输出:
# True
# False
# True
7.5.8 判断字符组成
isalnum()、isalpha()、isdigit()、isspace()、isupper()、islower(),
用来测试字符串是否为数字或字母、是否为字母、是否为数字字符、是否为空白字符、是否为大写字母以及是否为小写字母。
print('1234abcd'.isalnum()) # 是否为数字或字母
# True
print('1234abcd'.isalpha()) # 全部为英文字母时返回True
# False
print('1234abcd'.isdigit()) # 全部为数字时返回True
# False
print(' \t \n '.isspace()) # 是否为空白字符
# True
print('ABC'.isupper()) # 是否为大写字母
# True
print('ABc'.islower()) # 是否为小写字母
# False
7.5.9 填充
center()、ljust()、rjust()
- 返回指定宽度的新字符串,原字符串居中、左对齐或右对齐出现在新字符串中,
- 如果指定宽度大于字符串长度,则使用指定的字符(默认为空格)进行填充。小于则不填充。
- 填充字符的长度必须为1,也就是只能使用一种字符进行填充。
s = 'hello world'
print(s.center(20))
# ' hello world '
print(s.ljust(20,'+')) # 居左填充
# 'hello world+++++++++'
print(s.rjust(20,'`')) # 居右填充
# '`````````hello world'
第八章、文件
5.1 文件介绍
5.1.1 I/O问题
为提高程序运行效率,需要尽可能的减少I/O操作。I/O操作就是将内存中的数据写入到硬盘或从硬盘中将数据读取到内存的操作。
# I/O问题
# 平均寻道时间
# 7200/60 = 120
# 1000/120 = 8ms/2 = 4ms
# 平均寻址时间
# 5ms
# I/O延迟 = 平均寻道时间 + 平均寻址时间
5.1.2 编码(待补充)
内存中存储的字符都是Unicode编码格式的,但从内存存入硬盘或从硬盘读取到内存时,字符进行编码或解码的方式有多种多样。
需要补充的:编码和解码的过程。
5.1.3 乱码问题
1、读文件或写文件时的乱码问题
python2解释器默认读文件用的是ASCII码,python3用的是utf-8。当代码使用其他编码保存时可能就会出现乱码问题。
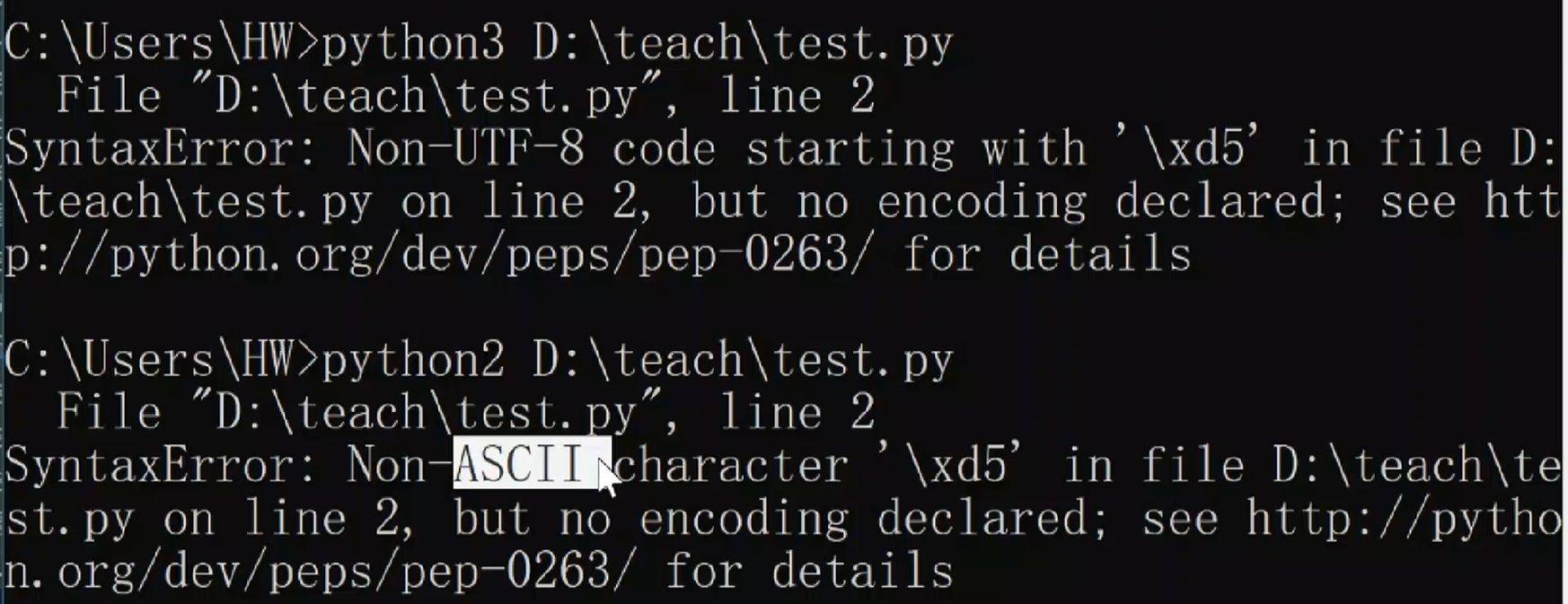
在python代码的首行加入注释coding:编码指定读取该文件是使用的编码。例如在python程序首行中添加如下注释,当pyhton解释器执行这个文件时,就会根据其指定的编码方式来读取。
# coding:utf-8
2、在python2中出现的字符串乱码问题
在字符串的引号前加小写u可以指定python程序将字符串以Unicode编码存入内存。即使文件头中指定的是其他编码。
一般在使用python2时才需要这样做。
a = u'人'
5.2 open()
5.2.1 open()的几种模式
1、控制文件读写操作的模式
| 字母 | 模式即功能 |
|---|---|
| r | 只读模式 |
| w | 只写模式,打开时会将内容清空,若文件不存在则新建空文件 |
| a | 只追加写模式,在文件末尾追加写入,文件不存在时新建空文件 |
| + | r+,w+,a+。在原有功能的基础上添加其没有的的功能。例如r+模式,使只读模式的r增加了写的功能。 |
| x | 文件存在时就报错,文件不存在时可以进行写操作。很少用到。 |
2、控制文件读写内容的的模式
-
t模式:
-
读写都是以字符串(unicode)为单位的
-
指定参数encoding = 'utf-8'
-
只针对文本文件
-
-
b模式:bytes模式/二进制模式
5.2.2 open()的用法
1、打开文件
使用open()可以打开文件,第一个位置参数为文件的路径。
绝对路径:从根目录下开始找文件
相对路径:从当前程序所在的文件夹开始找。
open('D:\\teach\\a.txt') # 在\前再加一个\防止\被转义
open('D:/teach/a.txt') # 将\换成/也可以
open(r'D:\teach\a.txt') # 绝对路径
open('data/a.txt') # 相对路径
2、文件操作(读、写)
open()有两个关键字参数mode和encoding。mode用于指定对文件的操作,encoding用于指定打开文件的编码方式。
- mode默认值是'rt',表示以只读方式打开文件。
- 如果不指定encoding参数,那么编码方式就是操作系统默认的编码方式(例如windows中是cp936,也就是GBK编码)。
注:mode参数中,r、w、a三个字符有且只能有一个,t或b也是有且只能有一个,+可以没有。没有顺序要求,例如'rt+'和'r+t'和'+rt'都是等价的。
f = open('data/a.txt', mode='rt', encoding='utf-8') # open()返回一个文件对象
res = f.read() # 读取文件内容并返回
print(res) # 由于是以t模式读取的,所以返回的值是一个字符串
3、关闭文件
open()打开文件后占用两部分资源,操作系统打开文件的资源,和文件对象f占用的资源。
- 文件对象f所占用的资源可以通过Python的垃圾回收机制回收,例如使用del f后,f对应的值引用计数为0,就会这个值就会被回收。
- 而操作系统打开文件所占用的内存空间Python的回收机制无法回收,需要使用colse()来关闭。
f.close() # 关闭文件
当文件关闭后,f所占用的资源仍然是存在的,我们仍然可以访问到f,但是此时的f已经么有任何意义,不能够再对f进行操作了。
例如使用f.read()对文件进行读操作,就会提示“I/O操作实在一个已经关闭的文件上”。
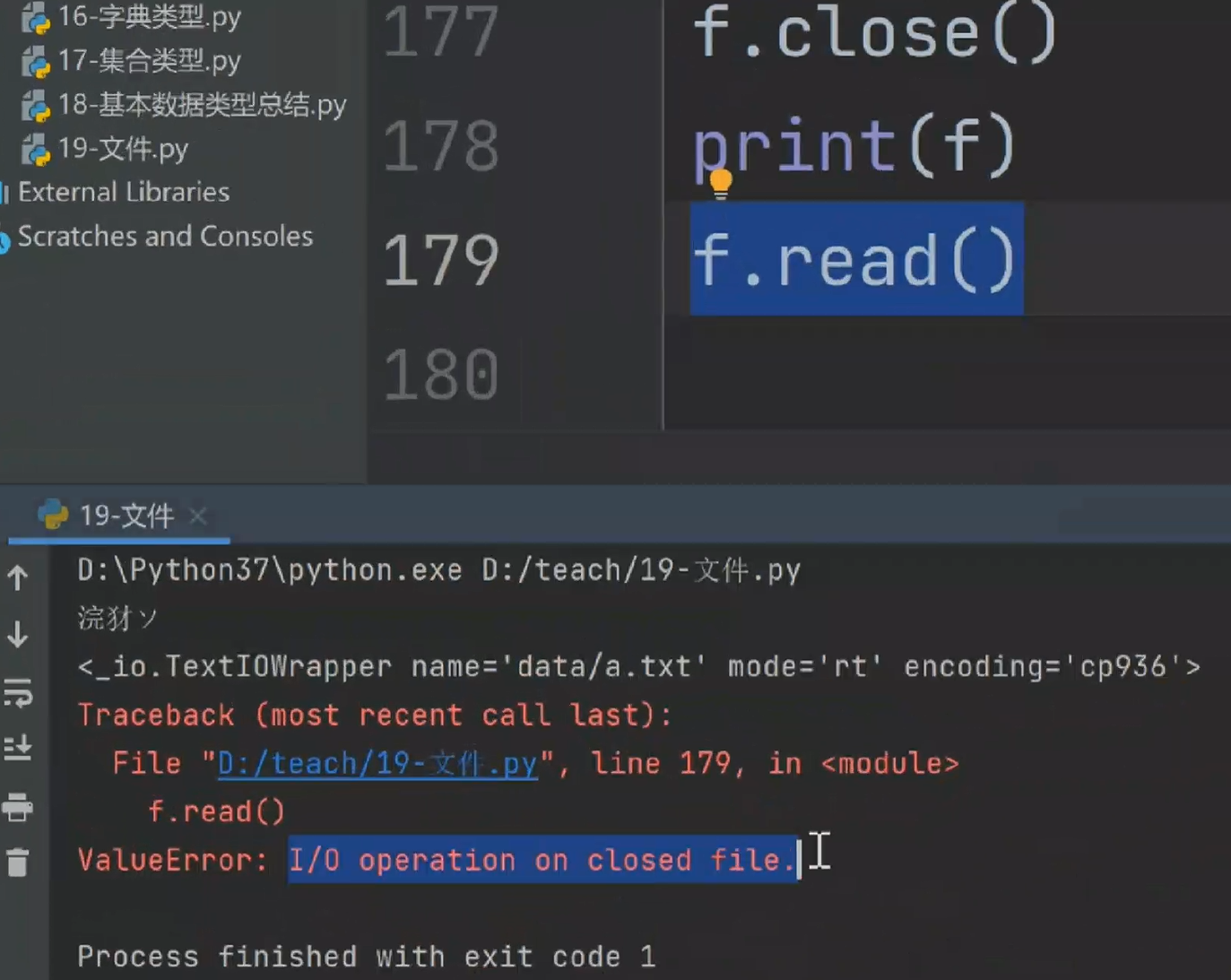
with语法(上下文管理器)
with语法可以在语句块执行完毕后自动关闭文件,同时,with语法还可以同时打开多个文件,每个open()之间用逗号分开。
当一行的内容过长时,可以添加一个反斜杠进行续行
with open('data/a.txt', mode='rt', encoding='utf-8')as f,\ # 反斜杠\用于续行
open('data/b.txt', mode='rt', encoding='utf-8')as f2:
res = f.read()
print(res)
res2 = f2.read()
print(res2)
5.3 open()各种模式的使用
5.3.1 r、w、a三种模式的使用
文件指针:python中的文件指针和c语言中的指针不同,可以理解为文本编辑器中的光标。
1、rt模式
只读模式,只能读取。r模式下,打开文件时,文件指针处于文件开头的位置。
with open('data/a.txt', mode='rt', encoding='utf-8')as f:
print('第1次读'.center(80, '-')) # center()填充字符
res1 = f.read() # r模式下使用read()读取文件,指针会从开头读到结尾,一次性的将文件内容全部读取出来。
print(res1)
print('第2次读'.center(80, '-'))
res2 = f.read() # 第二次读取时,文件指针已经处于文件末尾,后面已经没有内容了,什么也读不到
print(res2) # res2
案例:用户登录
将用户名和密码存入文件中,然后读取出来,与用户输入的用户名和密码比较,判断用户输入的账号密码是否正确。
(1)文件中只有一个用户名和密码的情况
假设文内容如下:
u1---121
代码:
username = 'd1303544500'
password = '123456'
input_username = input('请输入账号>>>').strip()
input_password = input('请输入密码>>>').strip()
with open('data/user.txt', mode='rt', encoding='utf-8')as f:
res = f.read()
username, password = res.split('---') # 解压赋值
# print(res)
if input_username == username and input_password == password:
print('登录成功')
else:
print('账号或密码错误')
(2)文件中有多个用户名和密码的情况
假设文件内容如下:
u1---121
u2---122
u3---123
# 这里有个空行(这是有第三行末尾的换行符产生的),由于后面没有内容了,所以这一行就是个空字符,末尾没有换行符的
可以使用for循环来读取每一行的内容
with open('data/user.txt', mode='rt', encoding='utf-8')as f:
for line in f:
print(line)
输出结果:
u1---121 # 这里有一个换行符,是文件内容本身的就有的换行符
# 这一行也有一个换行符,这是print添加的
u2---122
u3---123
# 这是文件中的第四行内容为空
进程已结束,退出代码为 0
可以看到,在输出结果中国每行内容都隔着一行,这是因为,print默认在输出的默认之后加入了一个换行符。而原来的文件内容中每一行后面也有一个换行符,只是看不见而已。
如果直接用split()对每一行的内容进行拆分的话就会出现下面这种情况
with open('data/user.txt', mode='rt', encoding='utf-8')as f:
for line in f:
输出结果:
['u1', '121\n']
['u2', '122\n']
['u3', '123\n']
进程已结束,退出代码为 0
每一行末尾的换行符仍然还存在,所以在进行拆分时需要先将末尾的换行符去除
line = line.strip() # strip()去除两端的空白字符,包括换行符
所以,当文件中有多个用户名和密码时,可以使用下面的代码实现功能:
input_username = input('请输入账号>>>').strip()
input_password = input('请输入密码>>>').strip()
with open('data/user.txt', mode='rt', encoding='utf-8')as f:
for line in f:
username, password = line.strip().split('---') # 去除换行符后拆分,再解压赋值
if input_username == username and input_password == password:
print('登录成功')
break # 找到匹配的账号密码后即可退出循环
else: # else要放到for循环后面
print('账号或密码错误') # 文件中没有匹配的用户名和密码,打印错误
2、wt模式
只写模式,只能写。w模式下,若文件不存在,则会创建一个空文件,若文件存在,则会将文件清空。
注:文件不存在时会新建,但目录不存在时会报错。例如a/b/c/abc.txt,若路径a/b/c/存在,abc.txt不存在,则会创建这个文件。若路径不存在,直接报错FileNotFoundError: [Errno 2] No such file or directory: "a/b/c/abc.txt"
w模式只有在打开文件时才会将文件清空,文件打开后可以进行多次写操作,不会清空文件。
with open('data/c.txt', mode='w', encoding='utf-8')as f:
f.write('晓看天色暮看云\n') # 若这里没有换行符,则下面那一句是紧跟在“云”字后面的
f.write('行也思君做也思君') # 字符串中没有换行符的话,是不会自动换行的。
3、at模式
只追加写模式。文件不存在时新建,文件存在时打开后指针移动到文件末尾,可在文件末尾添加内容。
案例:用户注册
username = input('请输入账号>>>')
password = input('请输入密码>>>')
with open('data/user_data.txt', mode='a', encoding='utf-8')as f:
f.write(f'{username}----{password}\n') # 格式化字符,并写入
案例:拷贝功能
old_path = input('请输入原文件路径>>>').strip()
new_path = input('请输入新文件路径>>>').strip()
with open(fr'{old_path}', mode='rt', encoding='utf-8')as f1,\
open(fr'{new_path}', mode='wt', encoding='utf-8')as f2: # 由于是使用t模式打开的文件,所以只能拷贝文本文件
res = f1.read()
f2.write(res)
fr'{old_path}'的解释:r是防止引号中的字符串被转义,f是格式化字符串,可以子在字符串中的{}之间填写变量名,并格式化为字符串。
5.3.2 +模式和b模式
1、r+模式
给r增加写的功能,r+模式以r模式为准,文件不存在时报错,初始时文件指针在文件开头。
mode='r+t'可以写成‘rt+'或'+rt'都可以,只要包含有对应功能的字母即可。这里的t也可以省略,因为mode默认读取内容的模式是t模式。
with open('data/d.txt', mode='r+t', encoding='utf-8')as f:
f.write('abc') # 此时文件指针在文件开头,写入的内容会覆盖原来位置上的内容
print(f.read()) # 此时的文件指针在第三个字符后面,read返回的是文件指针后的内容
r+写文件时,写入的内容会将原来的内容覆盖,例如文件中的内容是123456789,执行上述代码后文件内容变为abc456789,print输出的结果为456789
注:使用r+写入时可能会出现乱码,比如说在utf-8编码是,中文和字母编码所用的字节不相同,中文一个字符占3字节,英文一个字符占1字节,当在中文"你好呀"写入字母a时,a只占一个字节,"你"站三个字节,两者不匹配,就会出现乱码。
with open('data/d.txt', mode='r+t', encoding='utf-8') as f:
f.write('a')
你好呀 变成 a��好呀
2、w+模式
给w增加读的功能。w+模式也是以w模式为准,文件不存在时创建,文件存在时清空,初始时文件指针在文件开头。
with open('data/d.txt', mode='w+t', encoding='utf-8')as f:
f.write('abc\n') # 写入
f.write('def\n')
res = f.read() # 此时文件指针在文件的末尾,read()读取的内容为空
print(res)
3、a+模式
a+模式也是以a模式为准,在a的只追加写的功能项添加了读的功能,但由于a模式打开文件时文件指针在文件末尾,所以如果需要读取文件的话,需要通过移动指针的方法来实现。
补充:
各个平台的换行符:
- windows:\r\n
- linux:\n
- mac os 9:\r
- mac os 9之后:\n
b模式
b模式是以二进制模式进行读取文件的,所以对任意类型的文件都适用。但不能指定encoding参数。
with open('data/图片.jpg', mode='rb')as f:
res = f.read()
print(res)
print(type(res)) # python将二进制数据进行了优化,使用bytes类型来表示。
如果的是文本文件,那显示的就是utf-8格式的二进制。有些英文字符会直接显示成为英文,而不是16进制的值。
这里只需要明白,b模式读取出的是存储在硬盘中的文件的1010101的二进制即可。至于print打印出来是什么结果(英文字母或十六进制形式的二进制),无需纠结。
with open('data/h.txt', mode='wb')as f:
f.write('天下没有白吃的午餐'.encode('utf-8')) # 写如的内容页需要是bytes类型的
f.write('天下没有白吃的午餐'.encode('gbk')) # 最好使用同一种编码方式写入,不然读取时会乱码
案例:拷贝功能
b模式下读取的bytes类型的数据也是有换行的,至于为什么,先不考虑,以后再探究。
with open('data/图片.jpg', mode='rb')as f:
for line in f:
print(line)
使用for循环来读取文件时,可能会出现某一行特别的长,很占内存空间,所以可以给resd()传参数,每次读取一定长度的内容。
with open('data/img.png', mode='rb')as f:
while True:
res = f.read(1024)
if not res : # 当res为空时,退出循环
break
print(res)
print(len(res))
每次读取1024字节的内容。
拷贝功能的代码:
old_path = input('请输入原文件路径>>>').strip()
new_path = input('请输入新文件路径>>>').strip()
with open(fr'{old_path}', mode='rb')as f1,\ # 打开原文件
open(fr'{new_path}', mode='wb')as f2: # 创建并打开新文件
# for line in f1: # for循环可以会出现一行内容太多的情况
# f2.write(line)
while 1:
res = f1.read(1024) # 每次读取1024字节
if not res: # 内容为空时退出循环
break
f2.write(res)
5.4 文件对象的常用功能
5.4.1 readline、readlines
realline()每次读取一行,realines()一次性读取所有内容用列表返回,列表中每个元素对应一行的内容。
t模式和b模式下都是类似的。
with open('data/user.txt', mode='rt', encoding='utf-8') as f:
res = f.readline()
print(res) # u1---121
res = f.readlines()
print(res) # ['u2---122\n', 'u3---123\n']
5.4.2 writelines
t模式下
# 注意:只能向文件内写入str和bytes类型的数据
# writelines 类似利用for循环遍历列表,将列表中的元素写入
with open(r'data\2.txt', mode='wt', encoding='utf-8') as f:
f.writelines(['dsaf\n', 'kfdls\n', '123456']) # 需手动加换行符,不加换行的话就是连着写的
b模式下
# writelines 需要编码成bytes类型才可写入
with open(r'data\2.txt', mode='wb') as f:
l = [
b'dsa@#f\n', # 字符串中只有英文和数字时,在前面加上b转换为bytes类型
b'kfdls\n', # 其实就是,字符串前带有符号b,就表示这是个bytes类型的数据
b'123456',
bytes('我i呀\n', encoding='utf-8'), # 用bytes()编码
b'hjsdakl23',
'君不见,黄河之水天上来'.encode('utf-8') # 用encode编码
]
f.writelines(l)
print(l)
5.4.3 其他功能
# 其他功能
# f.flush 将数据立马存入硬盘(一般不用)
# f.readable() 判断文件是否可读
# f.writable() 判断文件是否可写
# f.closed 判断文件是否关闭
# f.encoding 获取文件编码方式,若文件打开模式为b,则没有该属性
# f.name 获取当前文件名
5.5 控制文件指针移动
with open(r'date\read.txt', mode='rt', encoding='utf-8') as f:
res = f.read(5) # 只有t模式下read()的n才代表字符个数,其他要移动文件指针的地方都是字节
print(res) # 输出:abc一二
注意:只有t模式下read()的n才代表字符个数,其他情况下,移动文件指针的时的单位都是字节。
5.5.1 seek()方法
假设文件内容abc一二三,共12字节,每个汉字占3字节,字母占1字节。
f.seek(偏移量n,参照位置)
文件指针移动以字节为单位。seek有三中类型的参照位置,也可以理解为是有三种模式。
模式0
以文件开头作为参照位置 ,来进行偏移,t,b两种模式都可以
f.seek(3,0) 0--->3 # 以第0个字节为参照,向后偏移3个字节,指针停在第3个字节的位置
f.seek(5,0) 0--->5 # 以第0个字节为参照,向后偏移5个字节,指针停在第5个字节的位置
模式1
以指针当前的位置作为参照,来进行偏移,不可在t模式下用
假设当前指针停在第三个字节处
f.seek(2,1) 3--->5 # 以当前位置第三个字节为参照,向后偏移2个字节,指针停留在第5个字节的位置
f.seek(3,1) 5--->8
模式2
以文件末尾作为参照,不可在t模式下用
因为文件是12个字节,所以文件末尾也就是第12个字节的位置。
f.seek(-3,2) 12--->9 # 以末尾作为参照,向前偏移3个字节
f.seek(-5,2) 12--->7
注意:
模式1和2不能在t模式下使用:因为‘t’模式只允许从文件头开始计算相对位置,从文件尾计算时就会引发异常但是,在t模式下用了好像也没问题,但只有偏移量n为0时才可以。
seek的练习:
with open(r'date\read.txt', mode='rb') as f:
f.seek(3, 0)
print(f.tell()) # 获取文件指针当前位置
res = f.read().decode('utf-8')
print(res)
f.seek(5, 0) # 文件指针卡在字符里,不能解码,会报错
with open(r'date\write.txt', mode='wb') as f:
f.write(bytes('君不见黄河之水天上来\n', encoding='utf-8'))
f.write('奔流到海不复回'.encode('utf-8'))
f.seek(0, 0)
f.write('将进酒'.encode('utf-8'))
f.seek(9, 0)
f.write('李白'.encode('utf-8')) # 跳转到前面输入会覆盖前面的内容
print(f.tell())
# 覆盖时会出现乱码,原因未知,待解决(已解决,原因就是下面所述的)
# 可能是不同类型的字符,一个字符所占的字节不同,覆盖时才会出现乱码。验证过,使用相同字符时,覆盖不会乱码
注:使用a模式进行写操作时,即使使用seek移动了文件的指针,写入时也会从文件末尾开始写。
5.5.2 案例:监控日志
监控日志的程序:
import time
with open(r'date\user.log', mode='rb') as f:
f.seek(0 ,2) # 参照末尾,移动0个字节。也就是将指针移动到末尾
while True:
res = f.readline().decode('utf-8') # 读取每一行的内容,并使用utf-8解码
if res:
print(res, end='') # 内容不为空则输出
time.sleep(0.2) # 使程序延时0.2秒,防止一直执行死循环占用资源
写入日志的程序:
while True:
res = input('输入日志:')
with open(r'date\user.log', mode='at', encoding='utf-8') as f:
f.write(f'2023/02/03>>>{res}\n') # 这里的日期可以使用time模块获取并写入
先执行监控日志程序,然后再写入日志,就可以看到如下效果:
5.2.3 修改文件
例如文件内容为“我喜欢你”,要改为“我不喜欢你”
第一种(文本编辑器修改文件的方法)
将所有内容读取到内存,然后再重新写入到硬盘,覆盖原来的数据。
缺点是一次性把文件读入到内存,对内存占用大。优点是容都在内存,用户能够快速访问。
with open(r'date\3.txt',mode='rt',encoding='utf-8')as f: # 读取文件
res = f.read() # 读取内容,res是字符串'我不喜欢你'
l = list(res) # 转换为列表
l.insert(1,'不') # 在列表中插入值
new_res = ''.join(l) # 对列表进行拼接,重新变回字符串
# 这里的w模式写文件不能写在上面的with语句里,如果写在上面的话,w模式打开文件时会将文件清空,在执行with语句块中的内容之前文件就已经被清空了。
with open(r'date\3.txt',mode='wt',encoding='utf-8')as f: # w模式会将文件清空
f.write(new_res) # 将修改后的文件写入
第二种
优点是对内存占用小,不会消耗过多的计算机资源。
import os
with open(r'date\3.txt',mode='rt',encoding='utf-8')as f,\
open(r'date\3(替换).txt',mode='wt',encoding='utf-8')as f1: # 创建一个副本文件
for line in f: # 文本文件一般不会出现一行有很多内容的情况,所以用for循环没什么问题
# l = list(line) # 将没一行的内容转换为列表
# l.insert(1, '不') # 插入
# res=''.join(l) # 拼接
# 也可以直接使用replace方法替换
line.replace('喜欢','不喜欢') # 字符串的替换
f1.write(res) # 写入副本
os.remove(r'date\3.txt') # os模块提供的方法,删除文件
os.rename(r'date\3(替换).txt',r'date\3.txt') # 更改文件名
总结
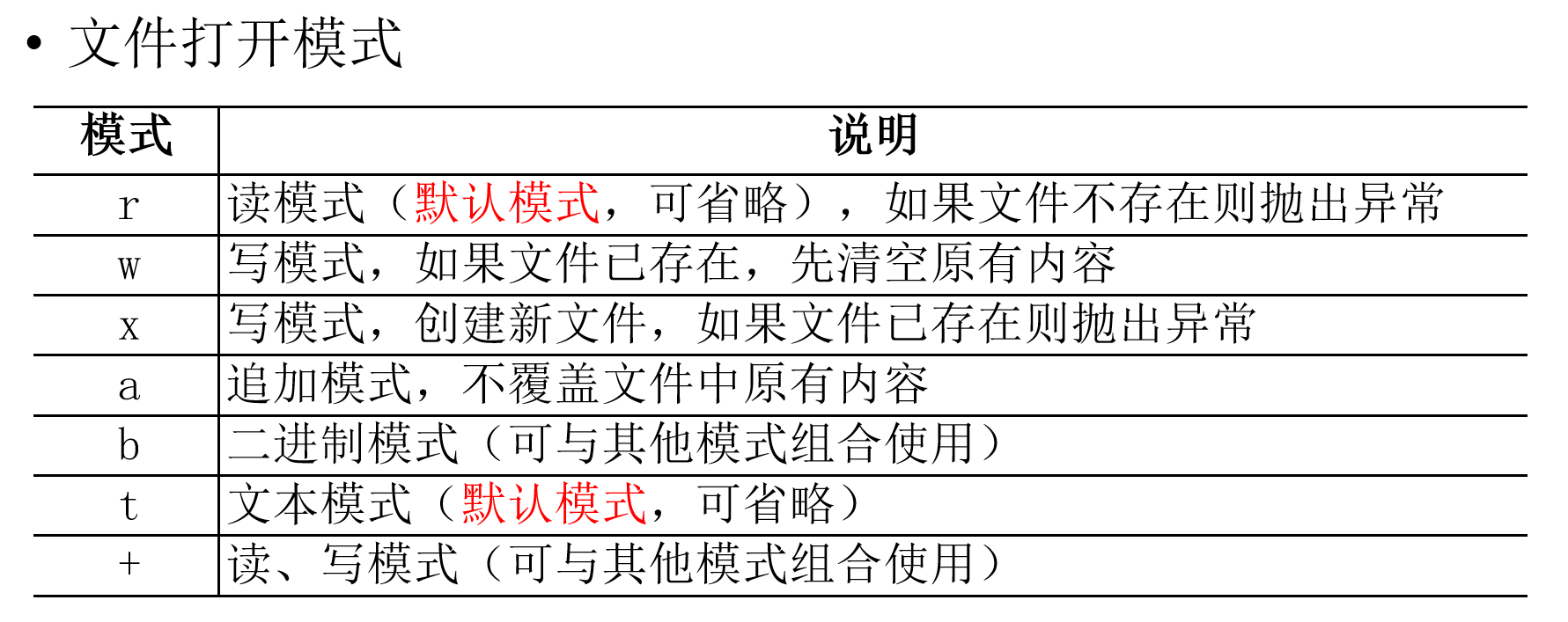

本文作者:最爱喝开水
本文链接:https://www.cnblogs.com/chuangblog/p/17942781
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步