Linux实验报告
大二上学期的linux的实验报告
一、CentOS Linux的安装
准备CentOS镜像文件,以及虚拟机软件VMware Workkstation。
1、打开VMware新建虚拟机。
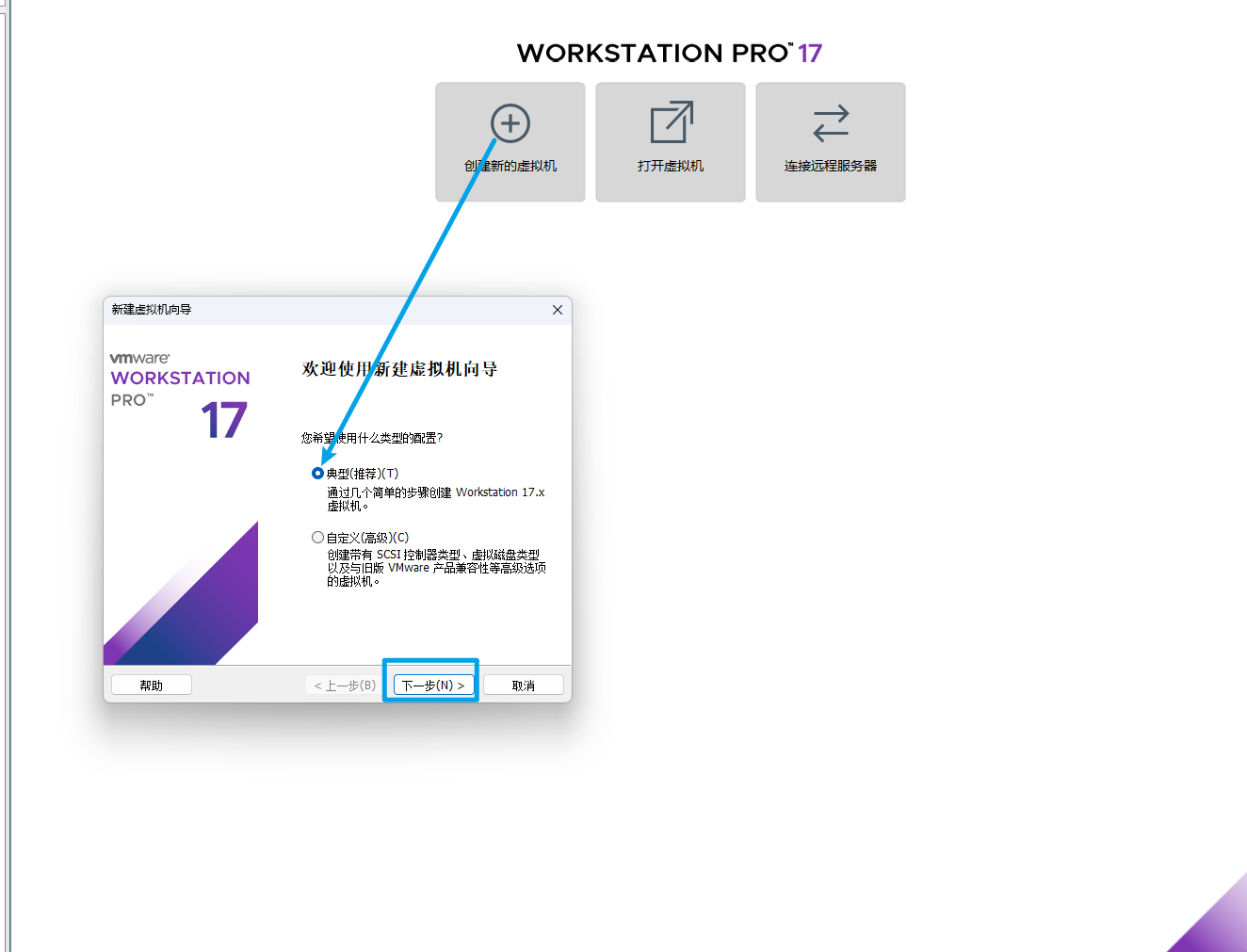
选择稍后安装操作系统
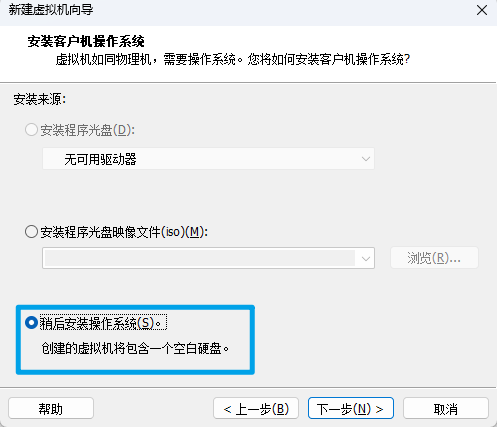
选择与镜像文件对应的操作系统级版本
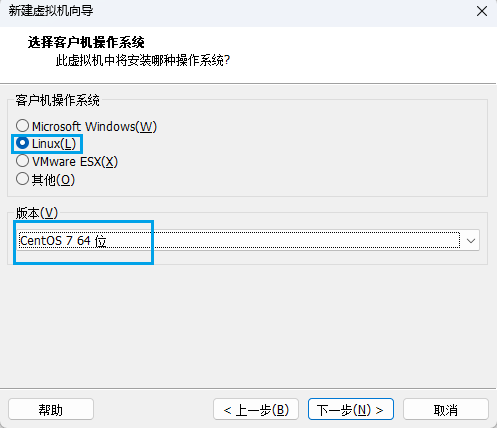
设置虚拟机名称以及虚拟机安装路径
设置虚拟机最大磁盘容量,这里的容量并不会一次性占用,而是随着使用逐渐增加,以后也可以随时进行更改。建议选择将虚拟磁盘存储为单个文件。
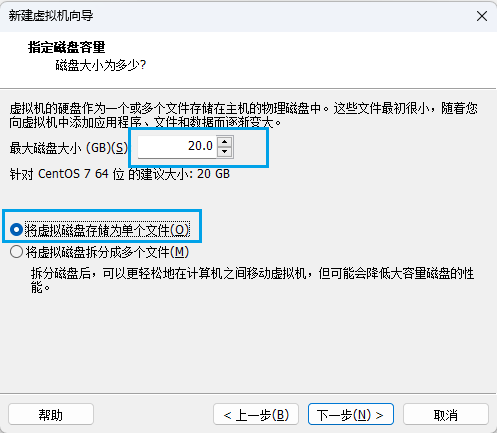
选择自定义硬件
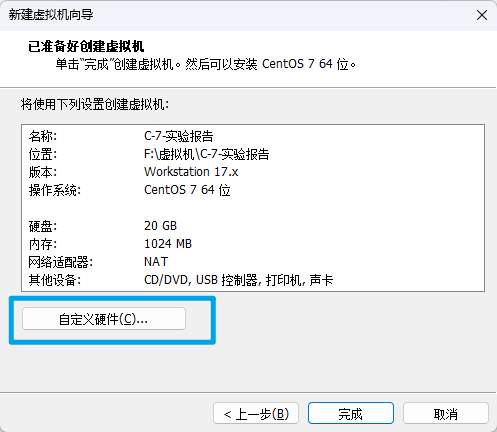
根据需要配置内存和处理器的配置,DVD设备中选择使用ISO镜像文件,并点击浏览,选择准备好的镜像。
网络模式选择NAT模式。其他不需要的设备(比如打印机和声卡)可以移除。
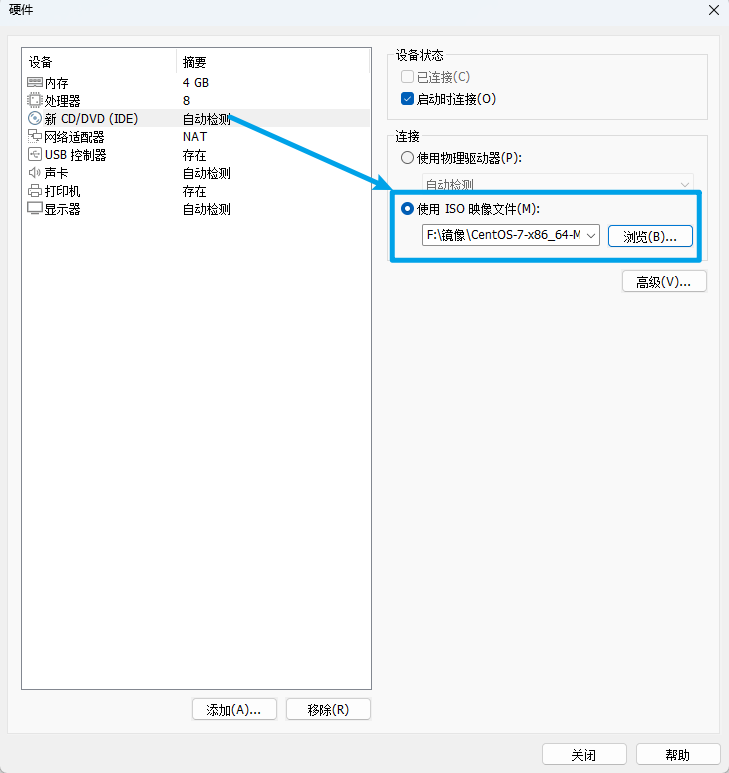
最后,点击关闭,再点击完成,虚拟机就创建好了。接下来就是进行CentOS系统的安装。
2、安装Linux操作系统
找到刚才新建的虚拟机,并打开
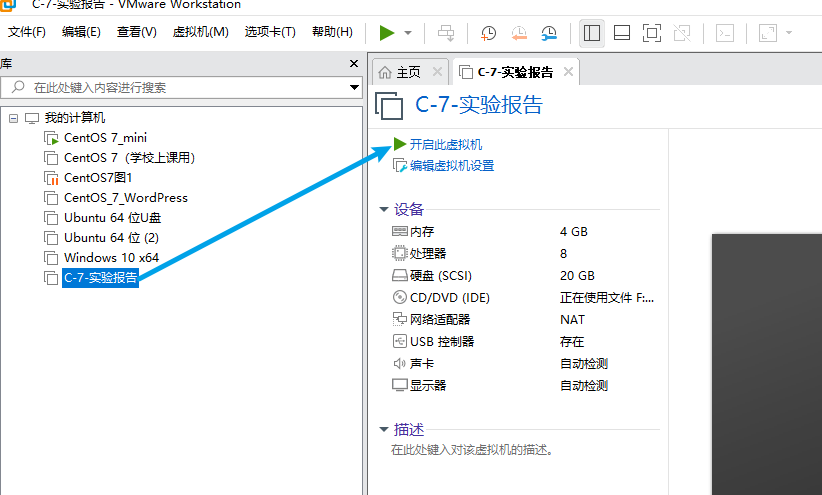
出现如下界面时,点击鼠标进入虚拟机,并通过键盘上下键选择第一个选项,回车。(同时按Ctrl和Alt可以将鼠标释放出来)
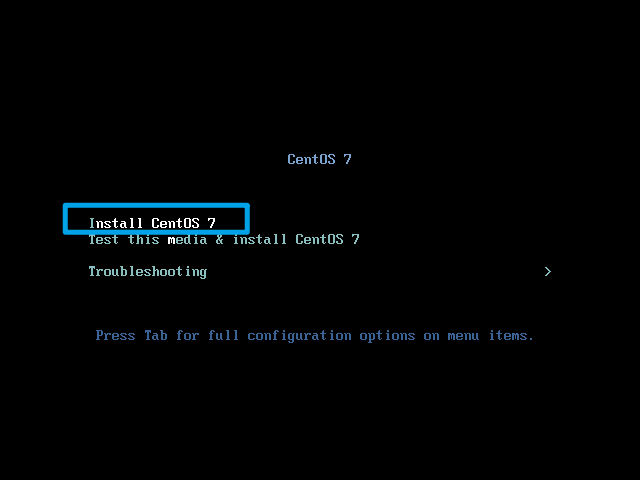
耐心等待一段时间,设备初始化完成后,出现如下界面。选择语言(这里选择英文)
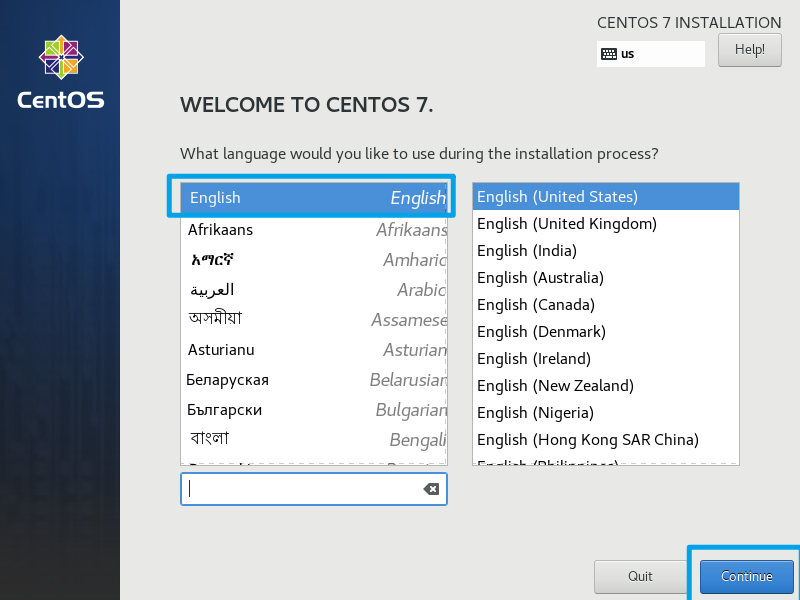
点击并选择安装选项

由于使用的是mini进项,只能选择最小化安装,如果是DVD进行,可以选择一下基础的工具包。选择完成后点击左上角的Done。
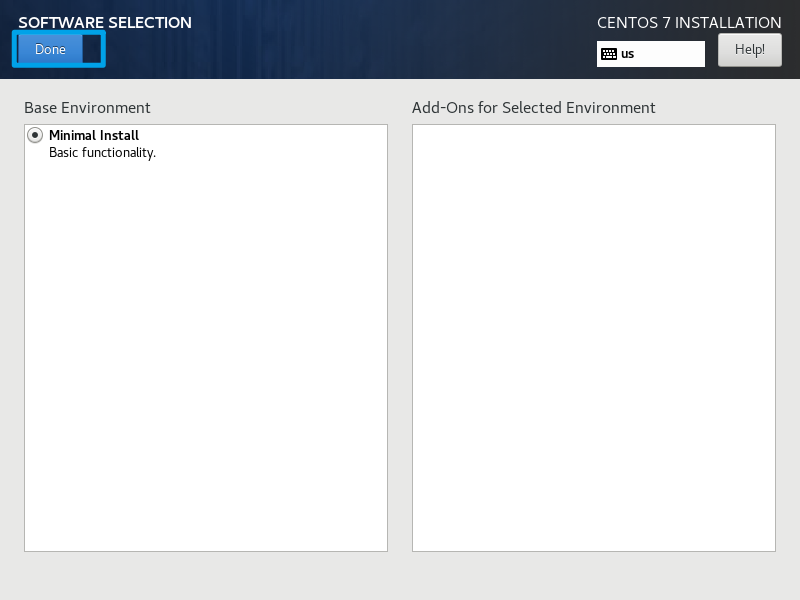
点击,进行磁盘分区

保持默认,直接点击左上角的Done
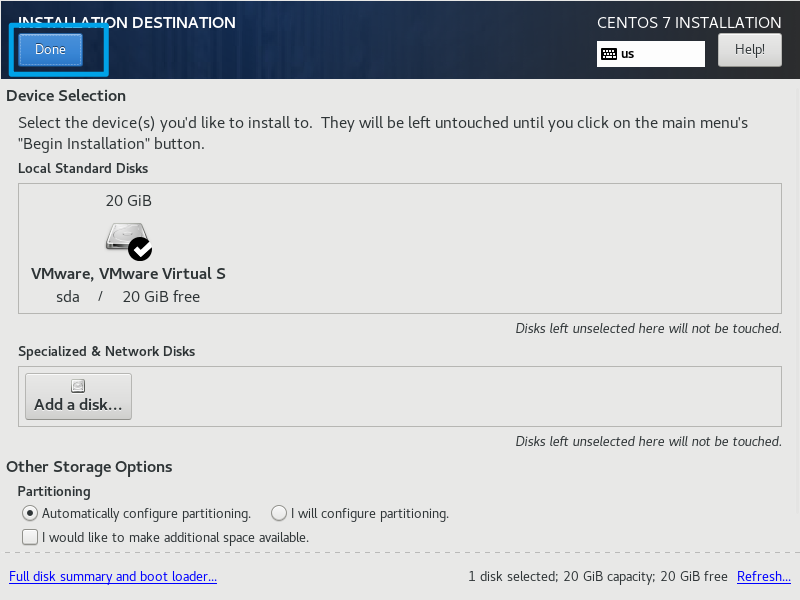
网络先不配置,点击Begin Installation开始安装

设置root用户及密码
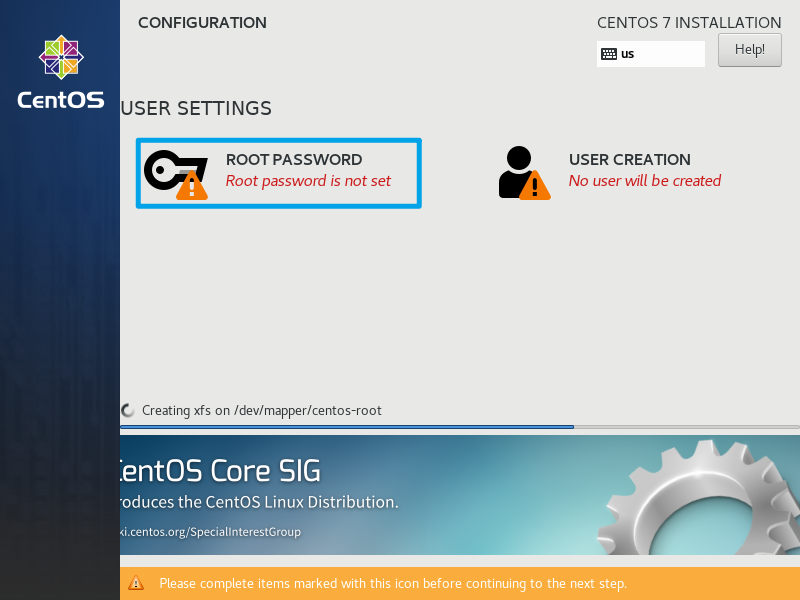
输入两次密码,点击左上角的done完成设置。如果密码强度过低,需要连续点击两次。
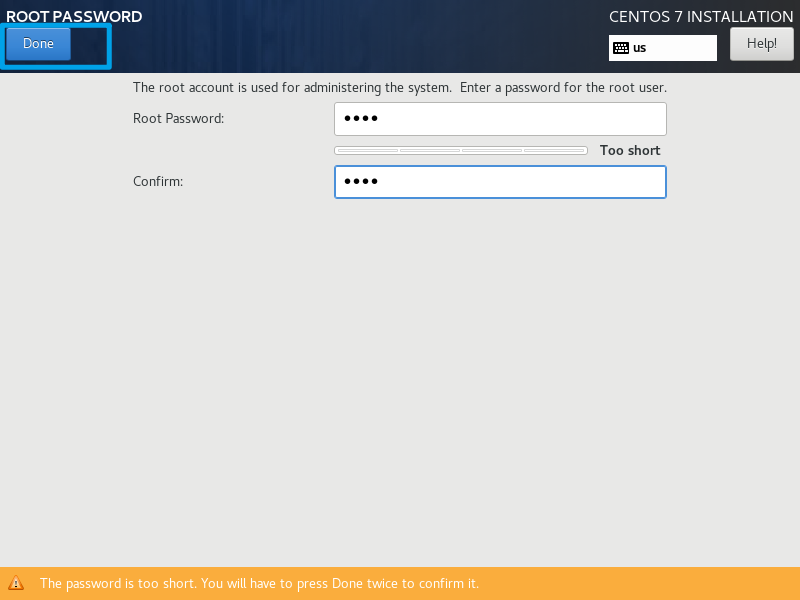
root密码设置好后,等待安装完成即可。当然,也可以设置普通用户的账号和密码。
安装完成后点击右下角的Reboot重启
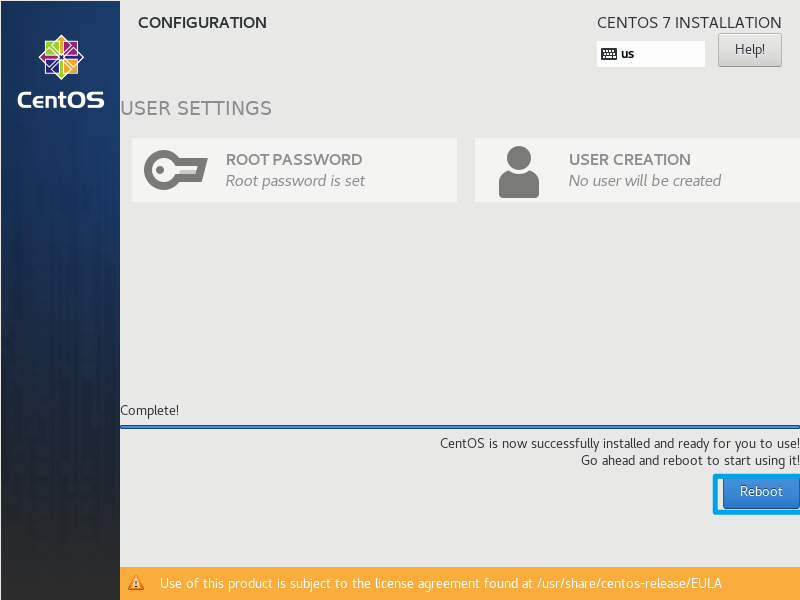
重启之后,出现这个界面就说明安装成功了。
输入账号和密码进行登录。(输入密码时是看不到输入的内容的)
二、VMware的三个网络
仅主机模式:只能虚拟机与虚拟机之间、虚拟机与物理机之间进行通信
桥接模式:虚拟机和物理机一样也拥有自己的IP,虚拟机IP与物理机IP处于同一网段。(如果虚拟机过多,或子网可用IP过少,可能会造成IP冲突,不建议使用)
NAT模式:利用虚拟的NAT设备以及虚拟DHCP服务器来使虚拟机连接外网,虚拟机可以自由配置IP地址,且不会造成IP冲突。(推荐使用)
下面演示配置虚拟机网络的过程。(NAT模式)
1、首先是虚拟网络编辑
右键VMware快捷方式,以管理员身份运行,
在VMware上依次点击,编辑>虚拟网络编辑器
在弹出的界面按照下图进行如下配置:
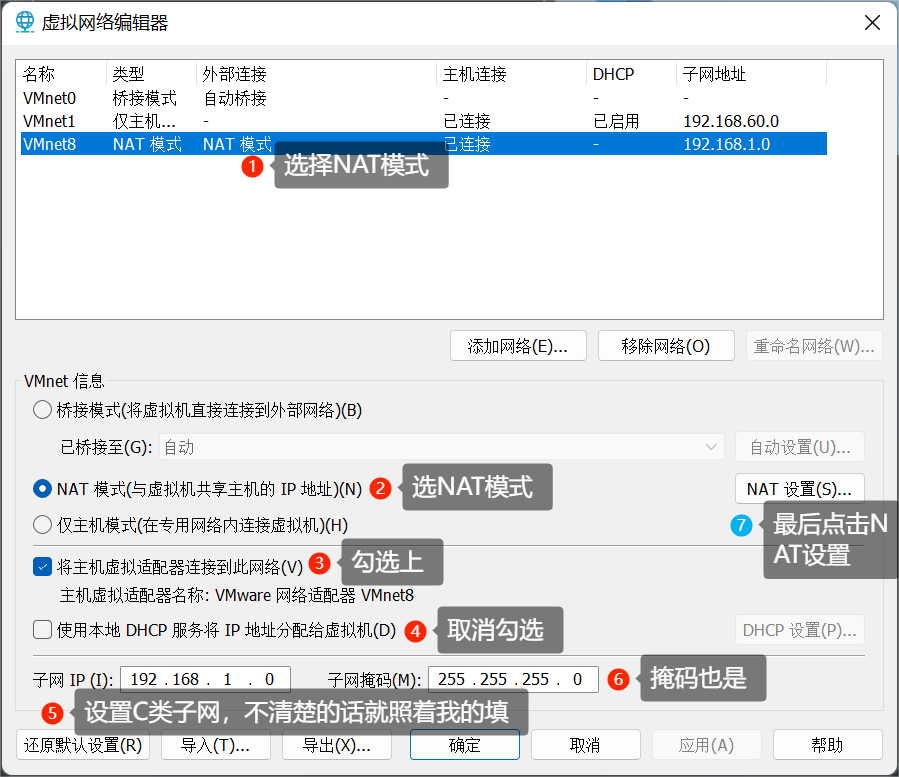
设置网关为:192.168.1.254,然后点击确定,回到上图后再次点击确定。
最后配置如下:子网:192.168.1.0 掩码:255.255.255.0 网关:192.168.1.254
2、在虚拟机中设置网络(命令行界面)
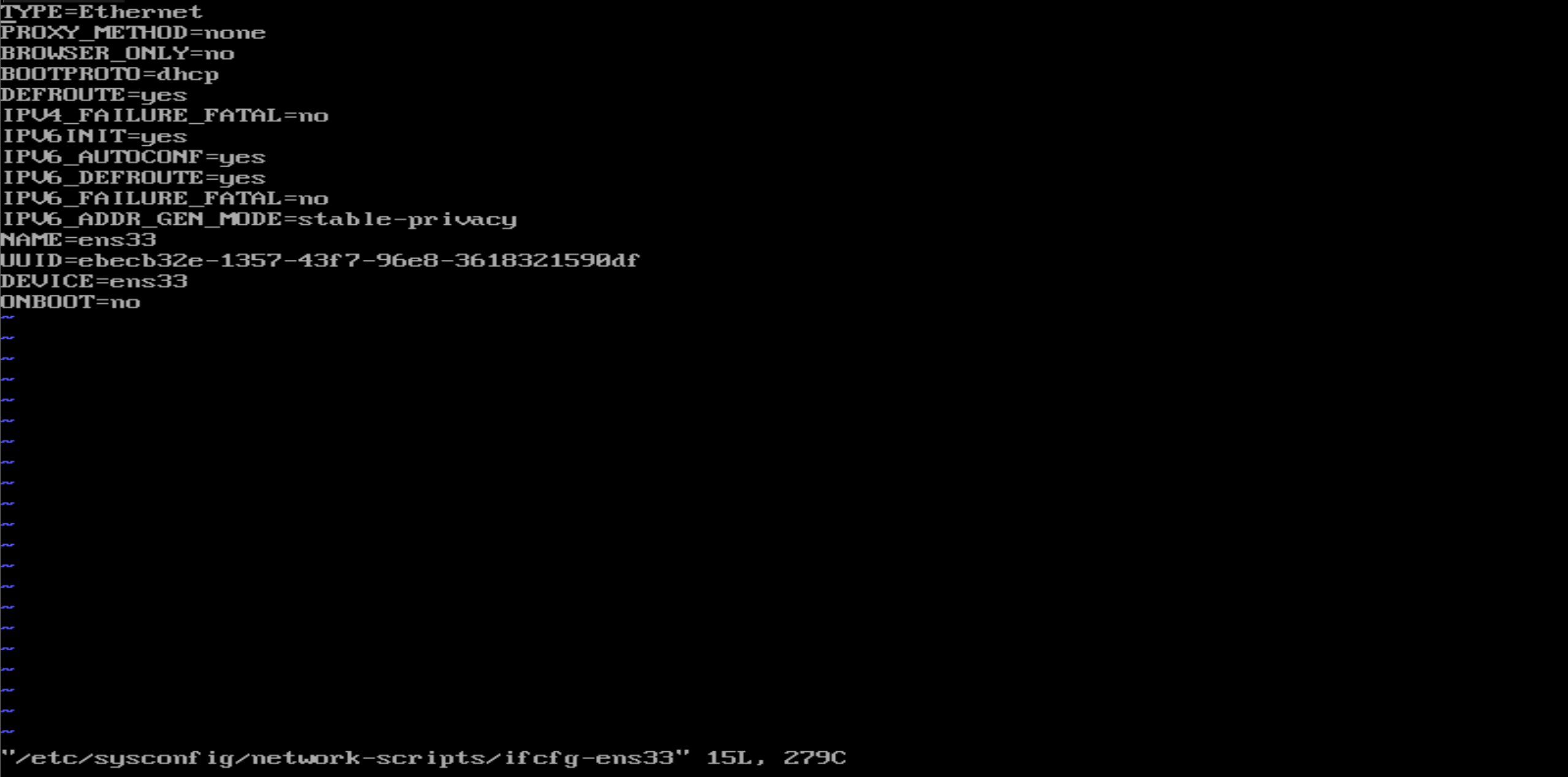
使用以下命令打开ens33配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33 # 用vim编辑器打开 命令1
vi /etc/sysconfig/network-scripts/ifcfg-ens33 # 如果没有vim编辑器的话,就用这条命令 命令2
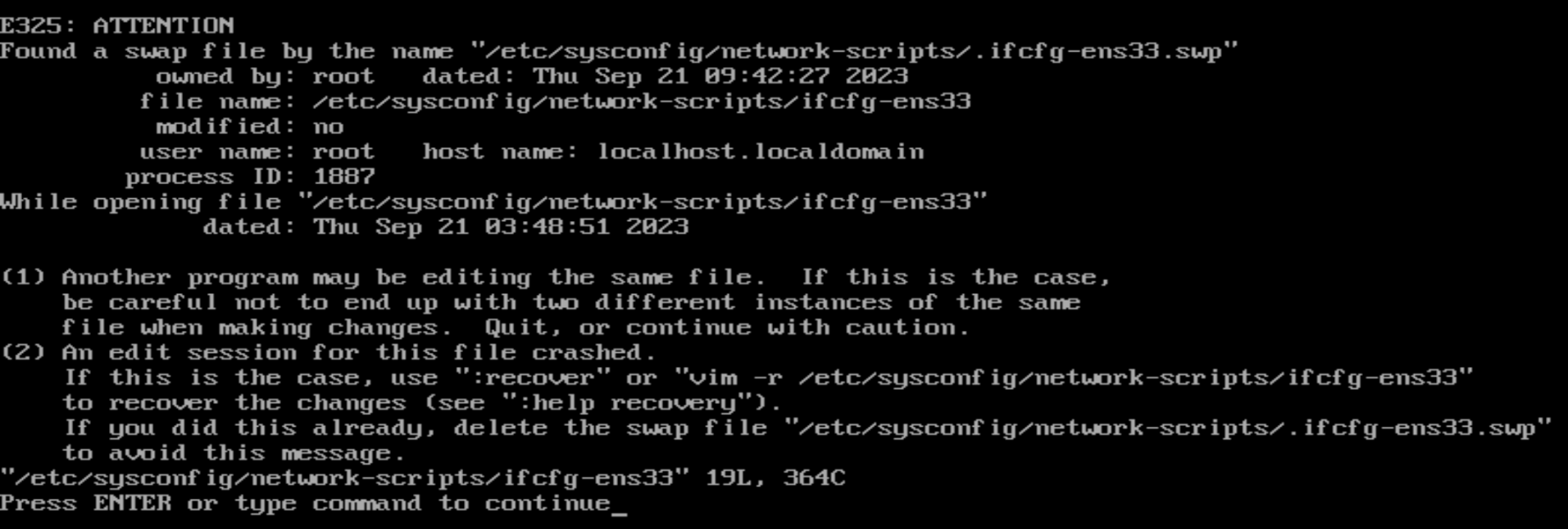
如果出现下面这种情况,提示没有找到vim,就用命令2

打开ens33配置文件后,可以看到类似下面这样的界面
如果你已经配置过ens33的网络,那么打开配置文件时可能会出现下面这种情况,这是有其他程序正在占用这这个配置文件,一般情况下直接回车即可,如果不行的话就只能根据它给的提示进行操作了。
按i进入编辑模式(左下角有INSERT的字样就说明当前处于编辑模式)
在编辑模式下,按键盘的上下左右键可以操控光标移动,退格键删除光标前的字符,回车键换行。

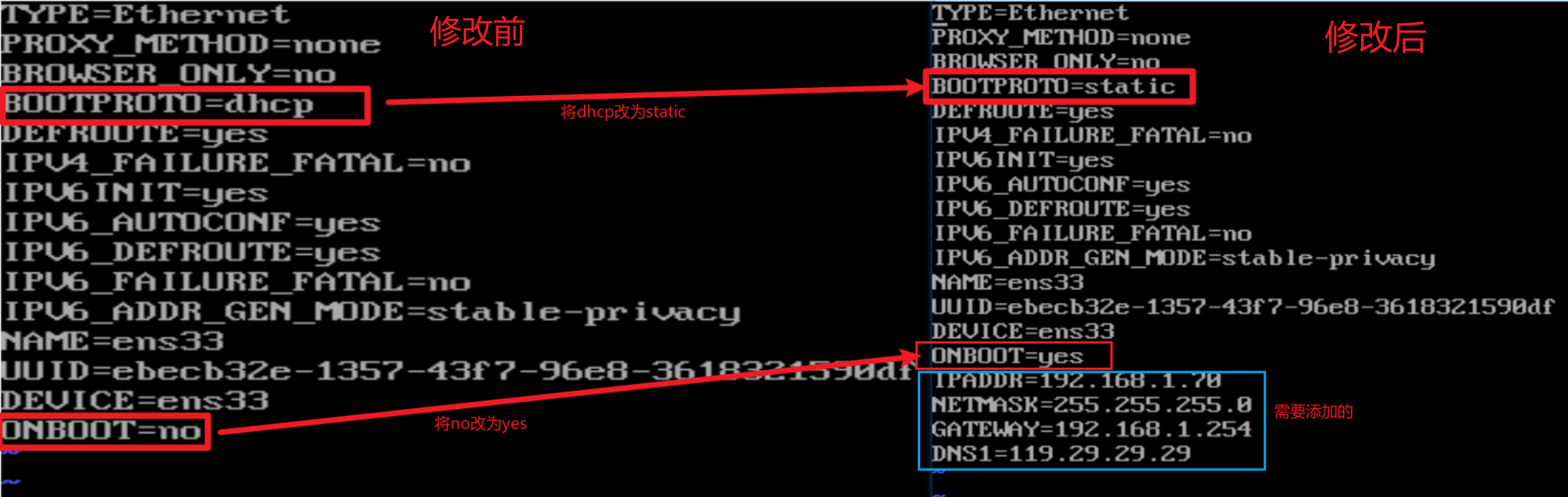
打开配置文件后,我们需要修改两个属性:
ONBOOT=yes # (开机时启动网卡)
BOOTPROTO=static # (设置为静态IP)
还需要添加几个属性:
IPADDR=IP地址
NETMASK=子网掩码
GATEWAY=网关
DNS1=DNS服务器的IP地址 # DNS后面的1是数字1
这里的IP地址、网关、子网掩码、服务器的IP地址需要根据你自己在第一步中虚拟网络编辑器中的配置来设置
下面是我的配置:
IPADDR=192.168.1.70
NETMASK=255.255.255.0
GATEWAY=192.168.1.254
DNS1=119.29.29.29
注意:
(1)这里的网关、子网掩码要和第1、步虚拟网络编辑器中的网关、子网掩码保持一致;
(2)IP地址要属于前面虚拟网络编辑器的子网网段中,比如,我的子网网段是192.168.1.0,子网掩码为255.255.255.0,(很明显这是个C类子网),那么我的IP地址的前24位(也就是192.168.1)要和子网的保持一致,那么我的IP地址只能设置为192.168.1.1到192.168.1.254之间的数,但由于192.168.1.1一般是VMnet网络适配器的IP,所以不能用,而我的网关是192.168.1.254,所以这个IP也不能用(当然如果你的网关是其他的地址,那也不能将I虚拟机P地址设置为网关的地址),所以我的虚拟机IP地址只能在192.168.1.2到192.168.1.253之间选择。
(3)这里的DNS可以设置为你的网关,也可以设置为真实的DNS服务器,比如119.29.29.29就是腾讯的DNS服务器
配置文件修改完成后,按键盘上的Esc键,然后你会发现左下角的INSERT不见了,这时候就可以输入:wq然后回车,将编辑的内容写入,并退出了。

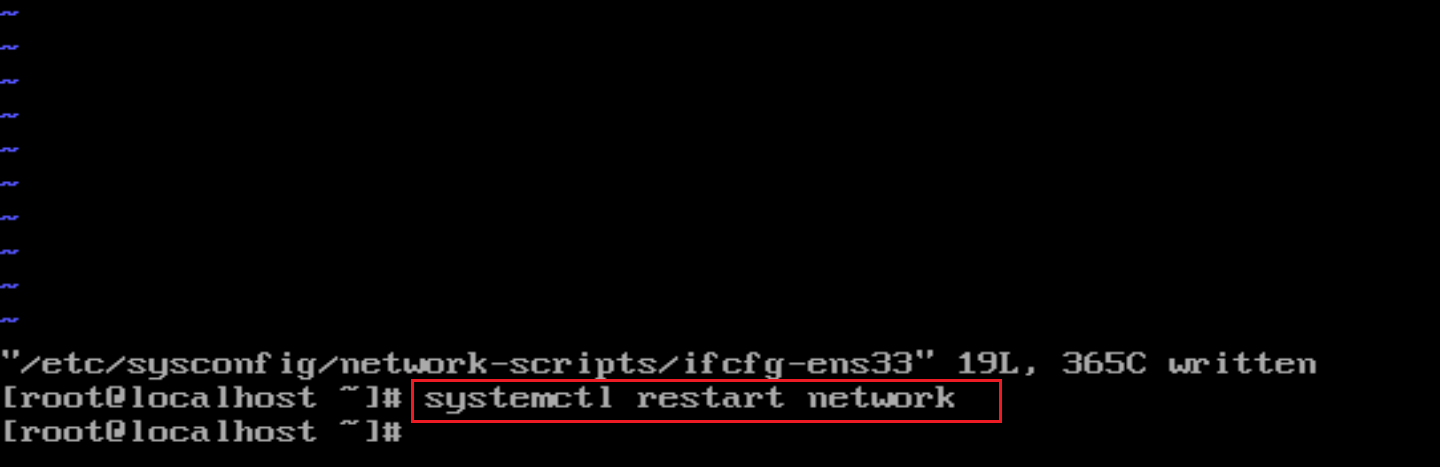
编辑之后输入下面这条命令重启网络服务
systemctl restart network # 重启网络服务
可以使用ping命令查看一下虚拟机是否能够连通外网,当然,前提是你的物理机能够上网。
ping baidu.com # ping百度的官网
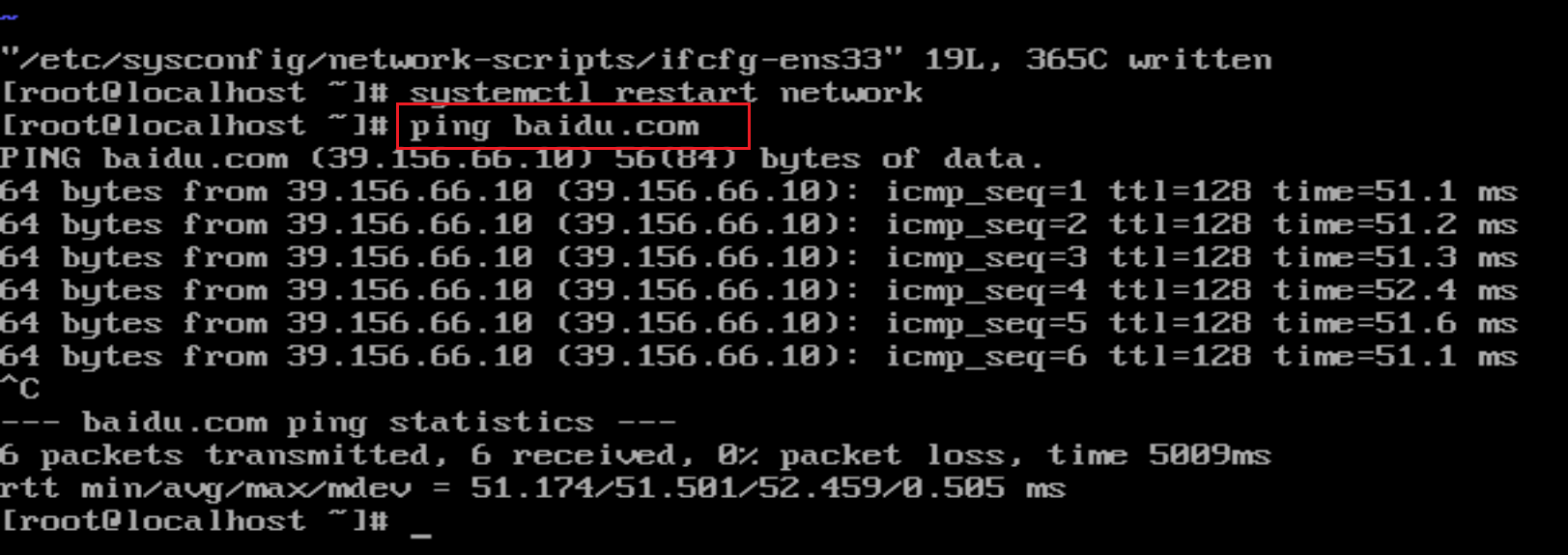
按Ctrl+C可以结束命令。如果,能够访问外网的话,就说明网络配置成功了。
三、使用put、get命令实现文件上传,下载
用xftp直接图形化界面。
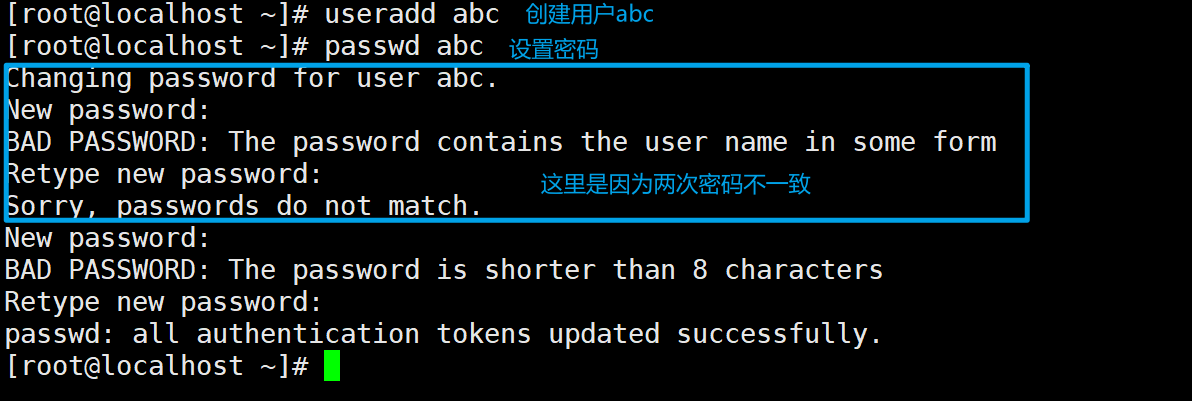
四、用户的添加
useradd添加用户,passwd设置用户密码
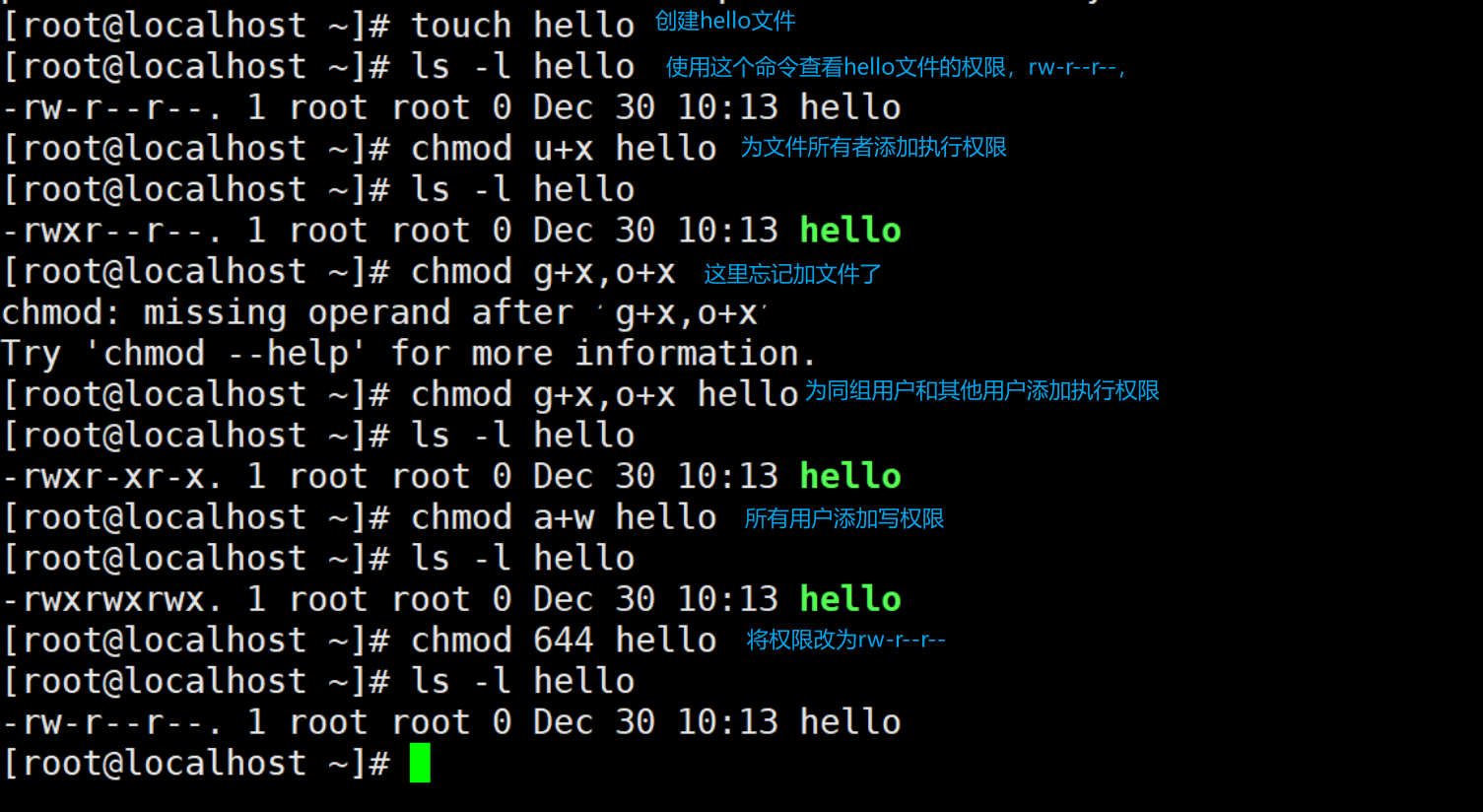
五、权限管理
六、打包tar、解包
打包

解包

七、MBR分区
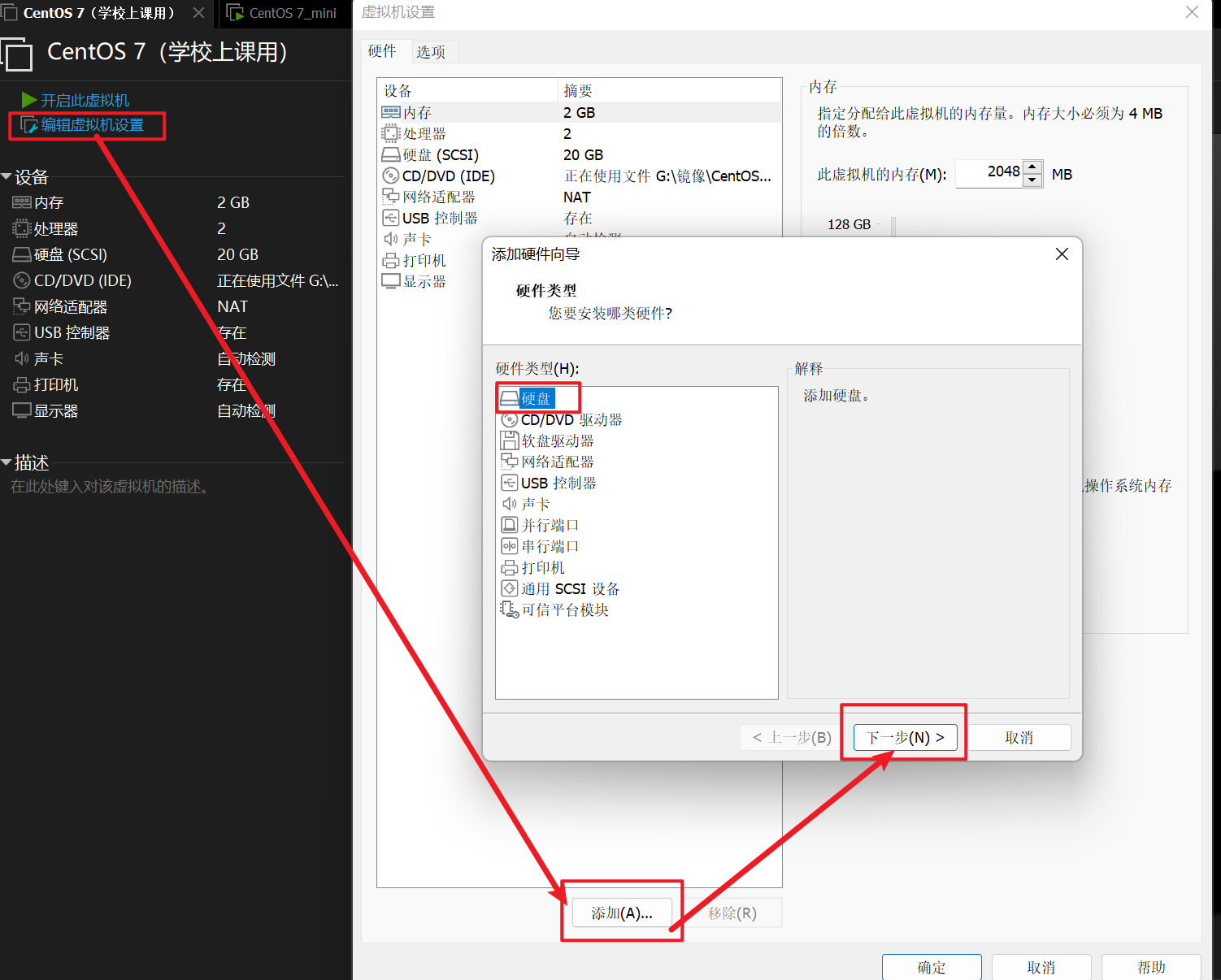
1、在VMware软件中为虚拟机添加硬盘
如下图,点击下一步后,除硬盘大小之外,所有选项都保持默认即可。添加完成后,需重启虚拟机,新添加的硬盘才会生效。
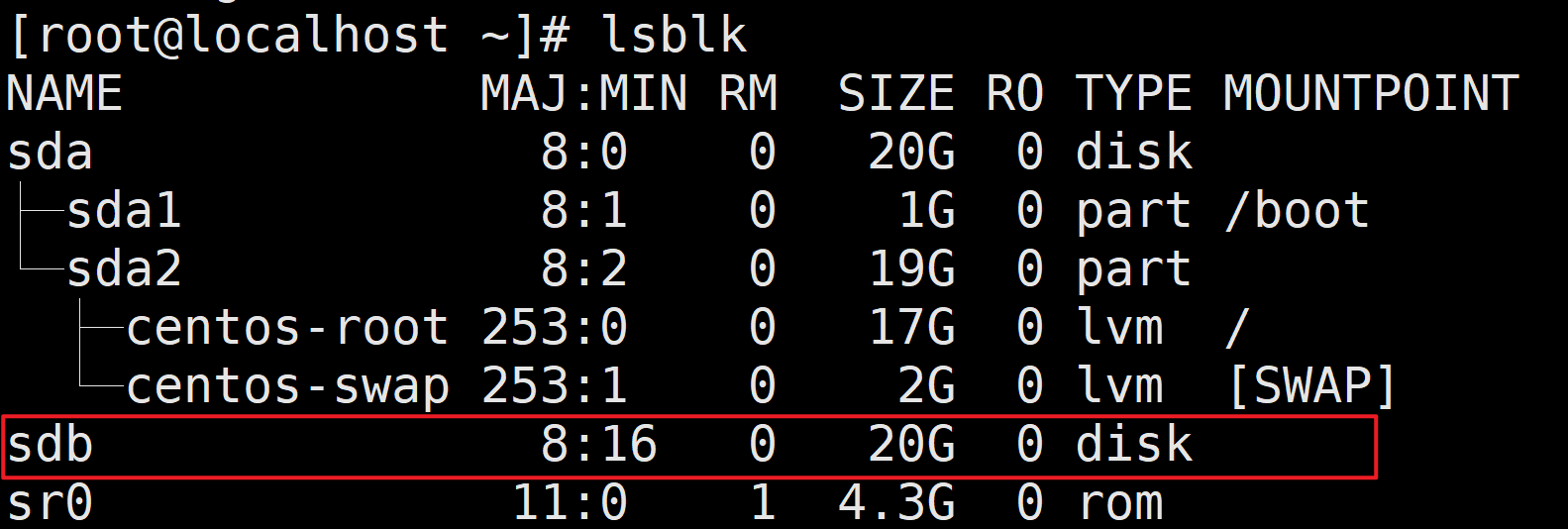
2、在虚拟机中使用lsblk命令查看磁盘分区情况,
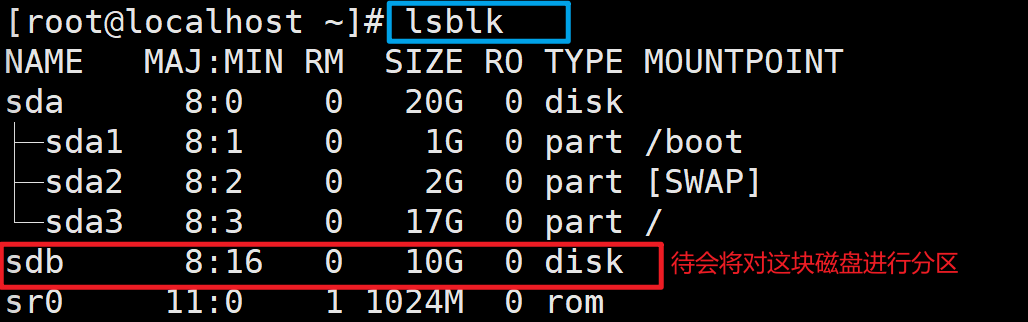
可以看到,新加的硬盘为sdb,大小20G。
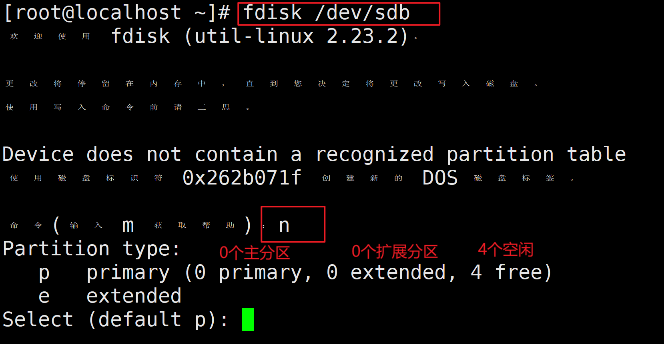
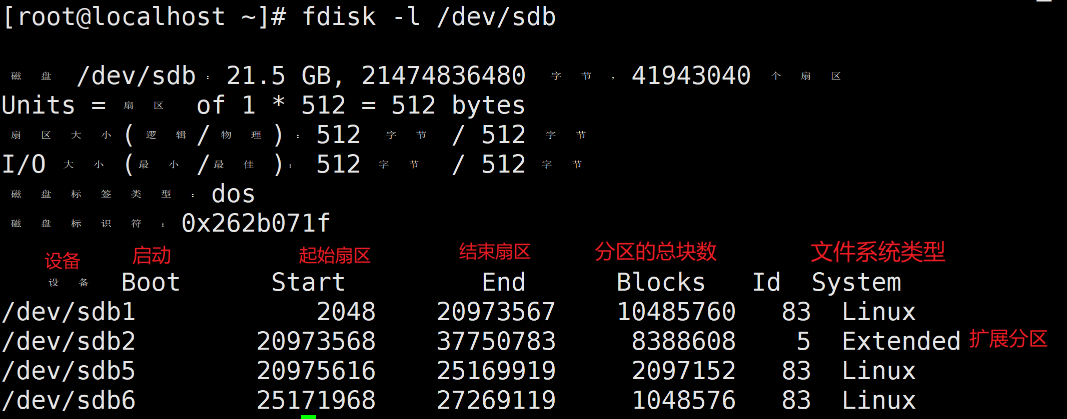
3、使用fdisk命令给新加的硬盘分区
fdisk /dev/sdb # 进入交互界面
(1)添加主分区
输入n添加分区,选项p为添加主分区,e为添加扩展分区。
输入p添加主分区,分区号设置为1,起始扇区直接回车,使用默认的2048,Last扇区可以使用+size{K,M,G}的方式,设置分区的大小,这里将分区1大小设置为10G。

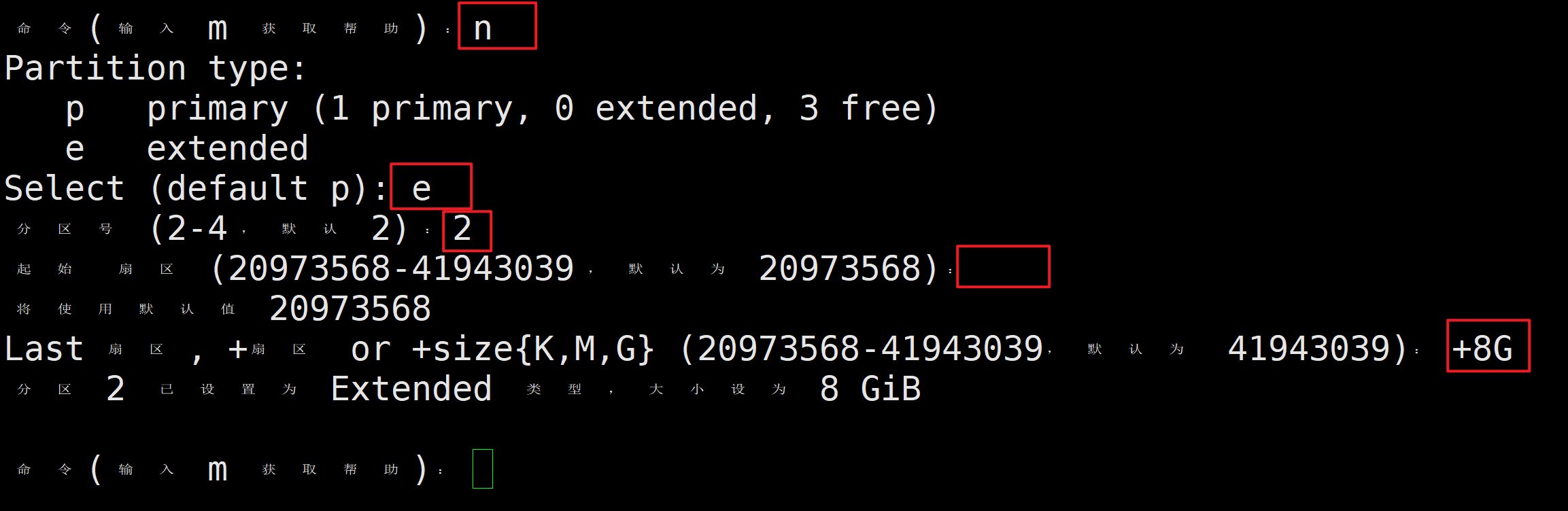
(2)添加扩展分区
再次输入n添加分区,e添加扩展分区,分区号位2,起始扇区默认,Last扇区+8G。
此时添加了8G的扩展分区。
输入p可以打印分区表,
可以看到刚才创建的主分区sdb1和扩展分区sdb2
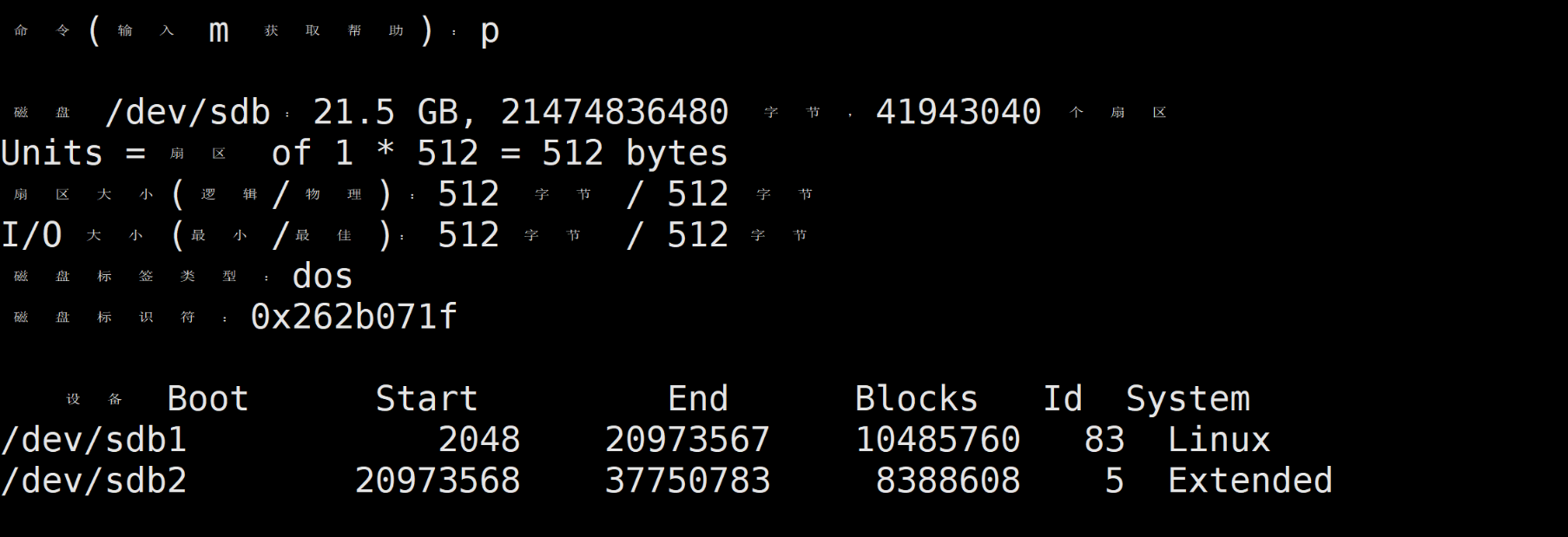
(3)添加逻辑分区
输入n后,输入l添加逻辑分区,逻辑分区的编号从5开始。
添加一个2G的逻辑分区
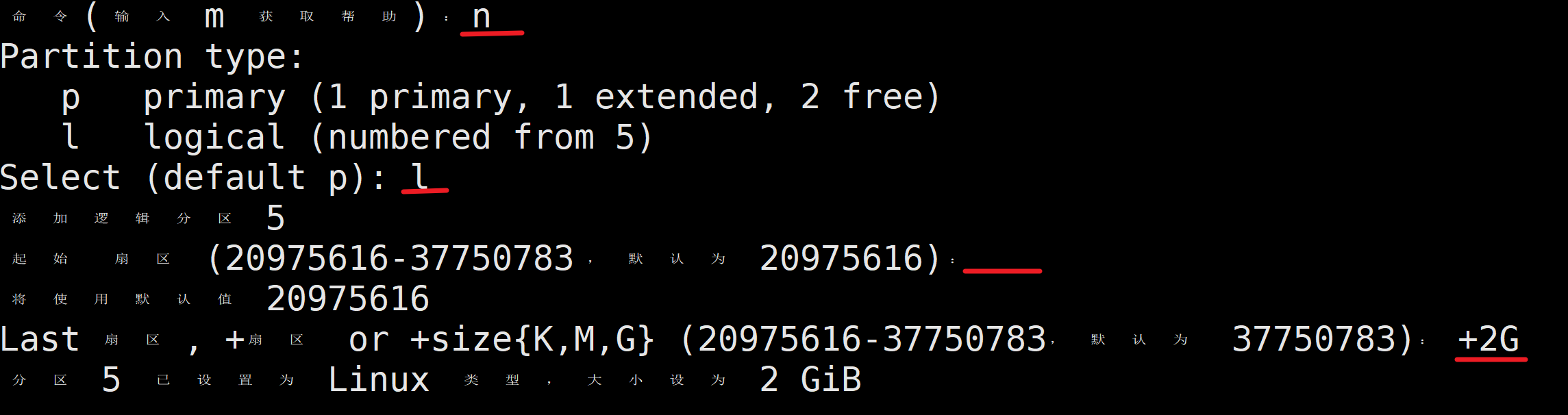
再添加一个1G的逻辑分区
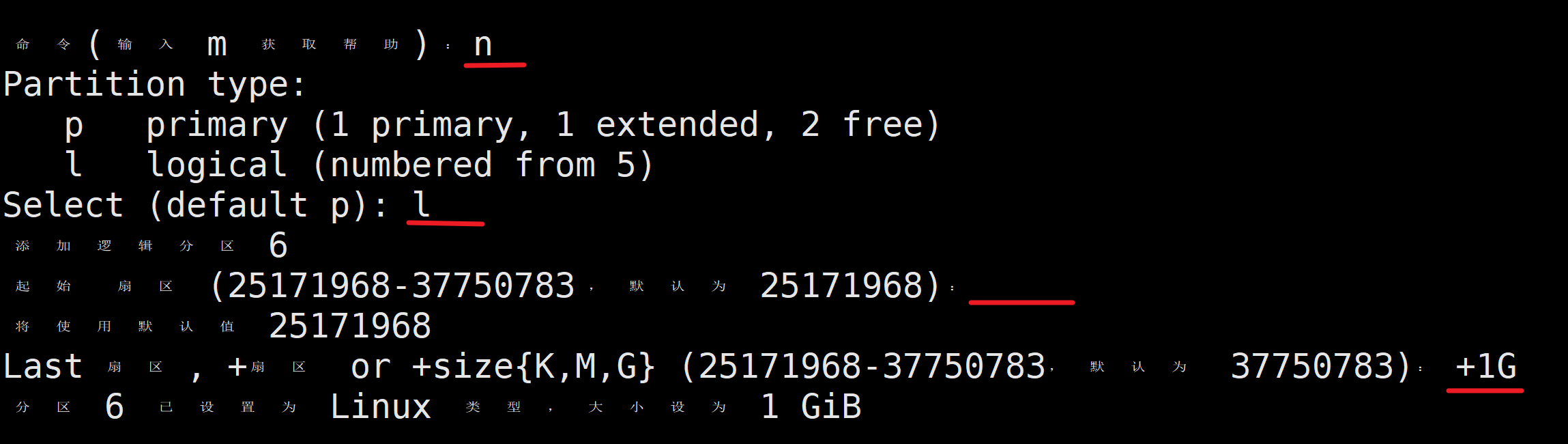
输入p打印分区表
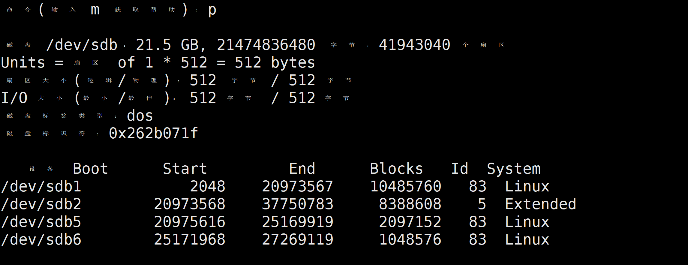
(4)保存退出并查看分区情况
输入w保存并退出,只退出不保存可以输入q,不保存的话刚才的配置不会生效。
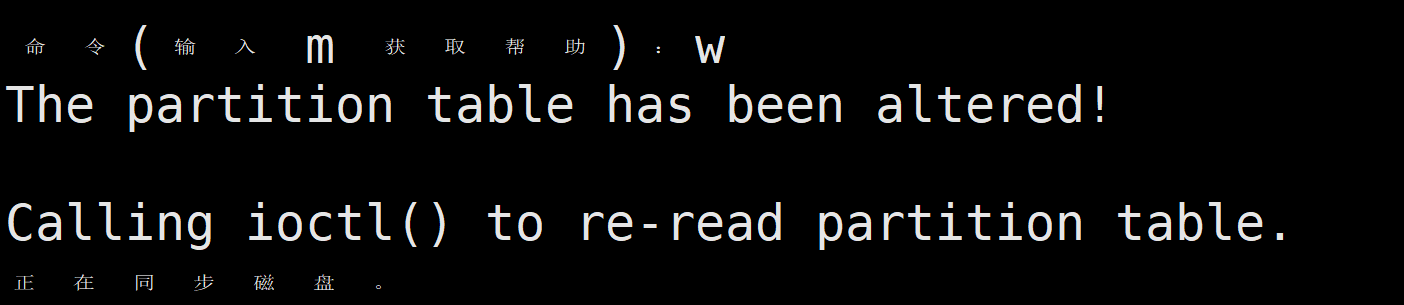
使用fidesk -l /dev/sdb查看磁盘/dev/sdb的分区:
八、GPT分区
使用lsblk命令查看所有磁盘及其分区情况
第一种,使用非交互时parted分区命令
1、创建GPT分区表
使用下面的命令修改磁盘分区表格式
parted /dev/sdb mklabel gpt
# sdb是要分区的磁盘
# mklabel是分区命令
# gpt是分区表格式

2、查看分区表信息
这个命令在后面会多次用到
parted /dev/sdb print
# print也可以简写为p

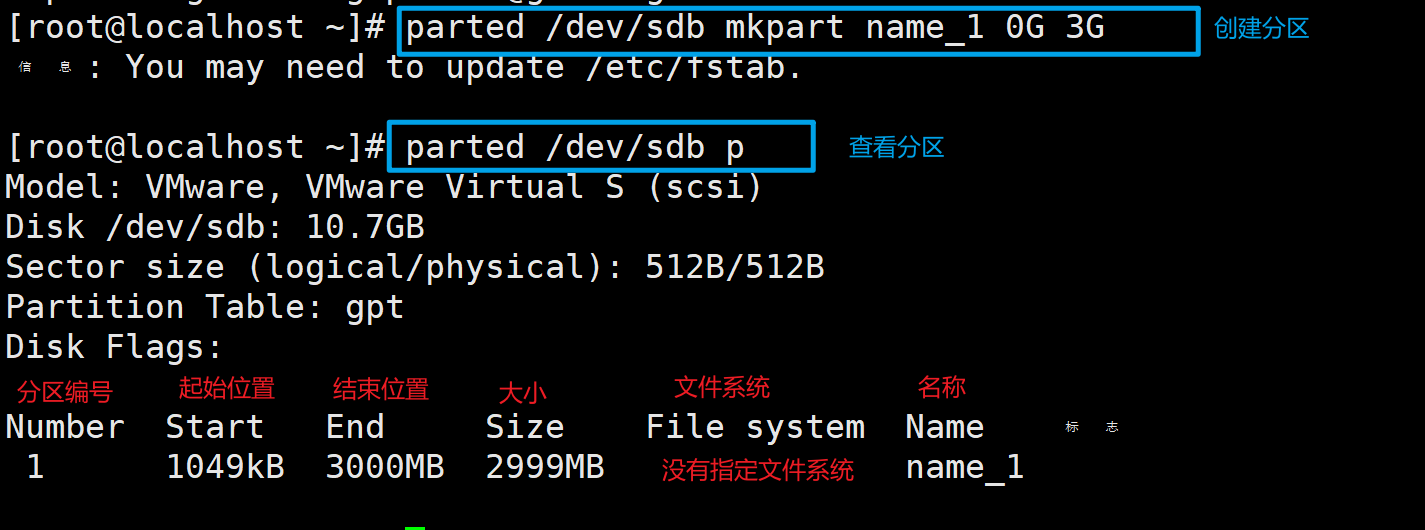
3、创建分区
创建一个名称为name_1,大小为3G的分区
parted /dev/sdb mkpart name_1 0G 3G
# mkpart是创建分区的命令
# name_1是分区名字
# 0G和3G分别是起始位置和结束位置,可根据需要自行选择。
再创建两个分区
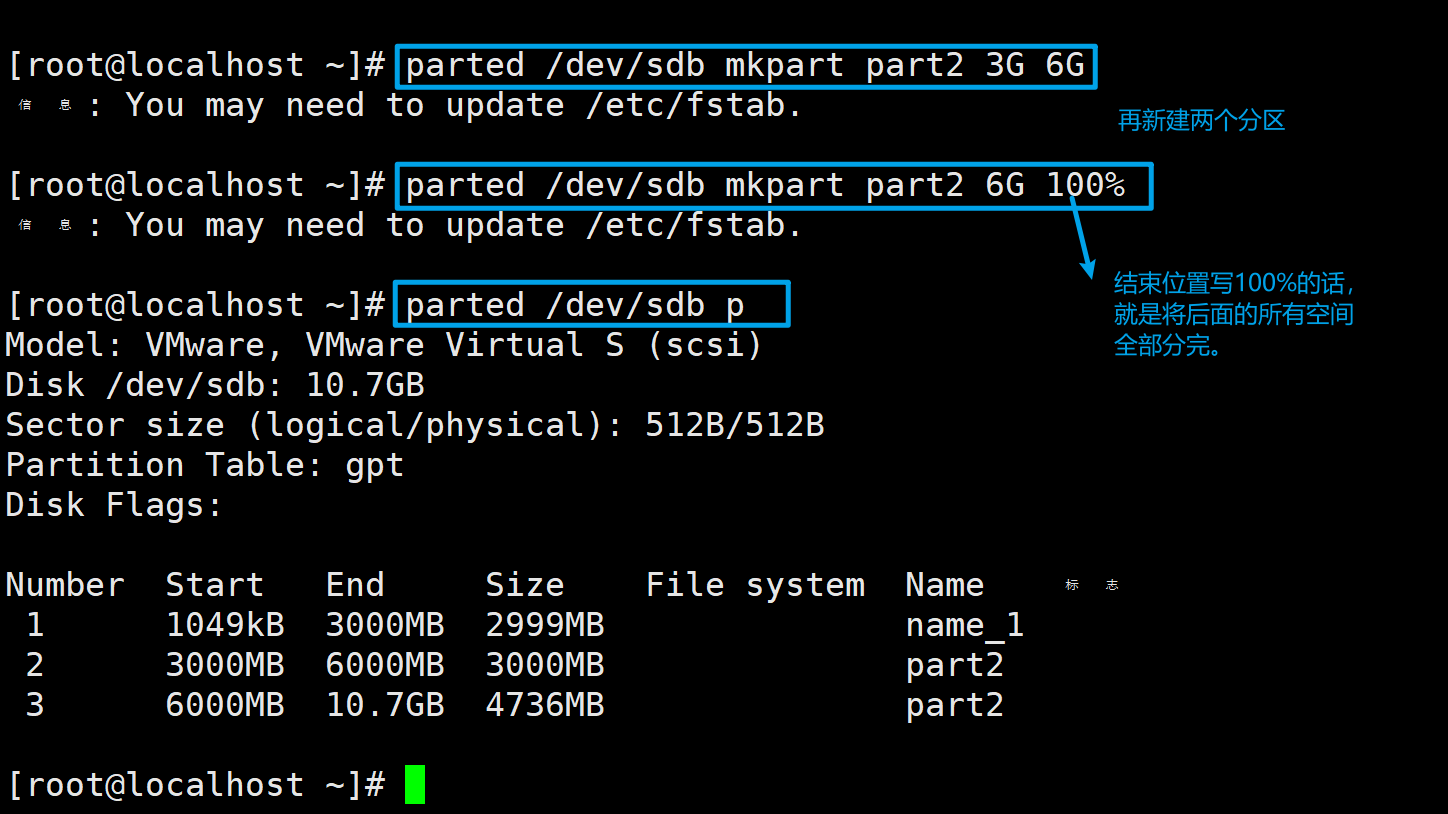
4、修改分区名称
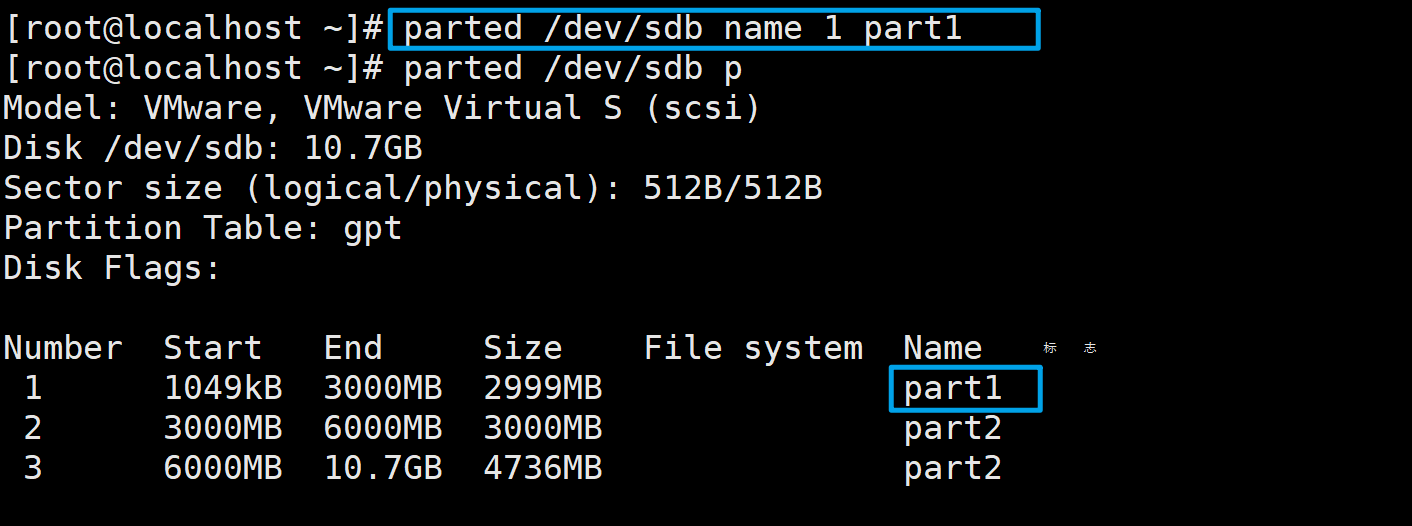
parted /dev/sdb name 1 part1
# name为修改分区名称的命令
# 1为需要修改的分区的编号
# part1是修改后的名字
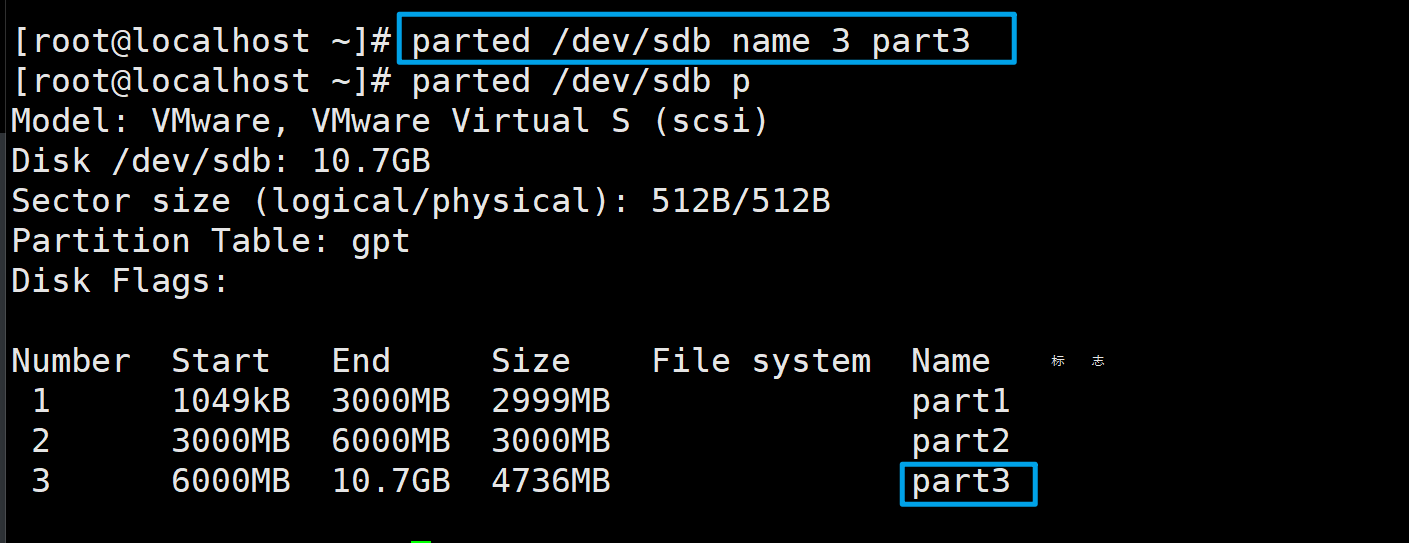
再把第三个分区的名称改为part3
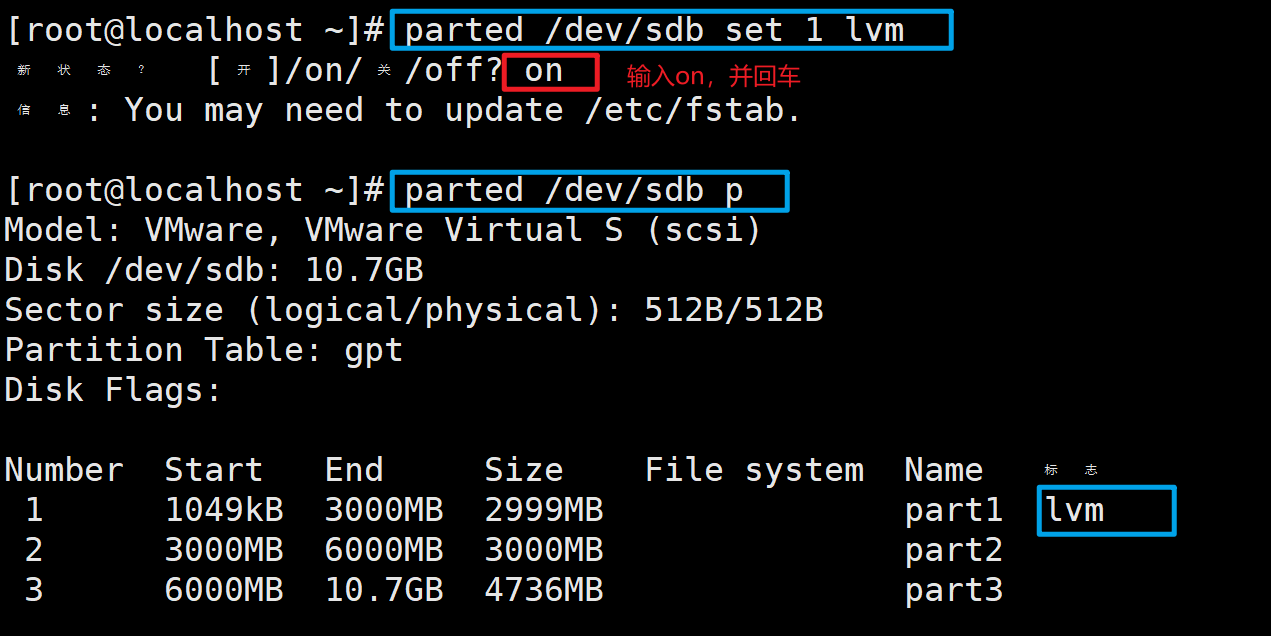
4、配置分区的标记
parted /dev/sdb set 1 lvm
# set为配置分区标记的命令
# 2为需要配置的分区的编号
# lvm为分区标记
取消分区标记
取消标记的命令与配置的命令一样,只不过取消时,需要输入的是off。
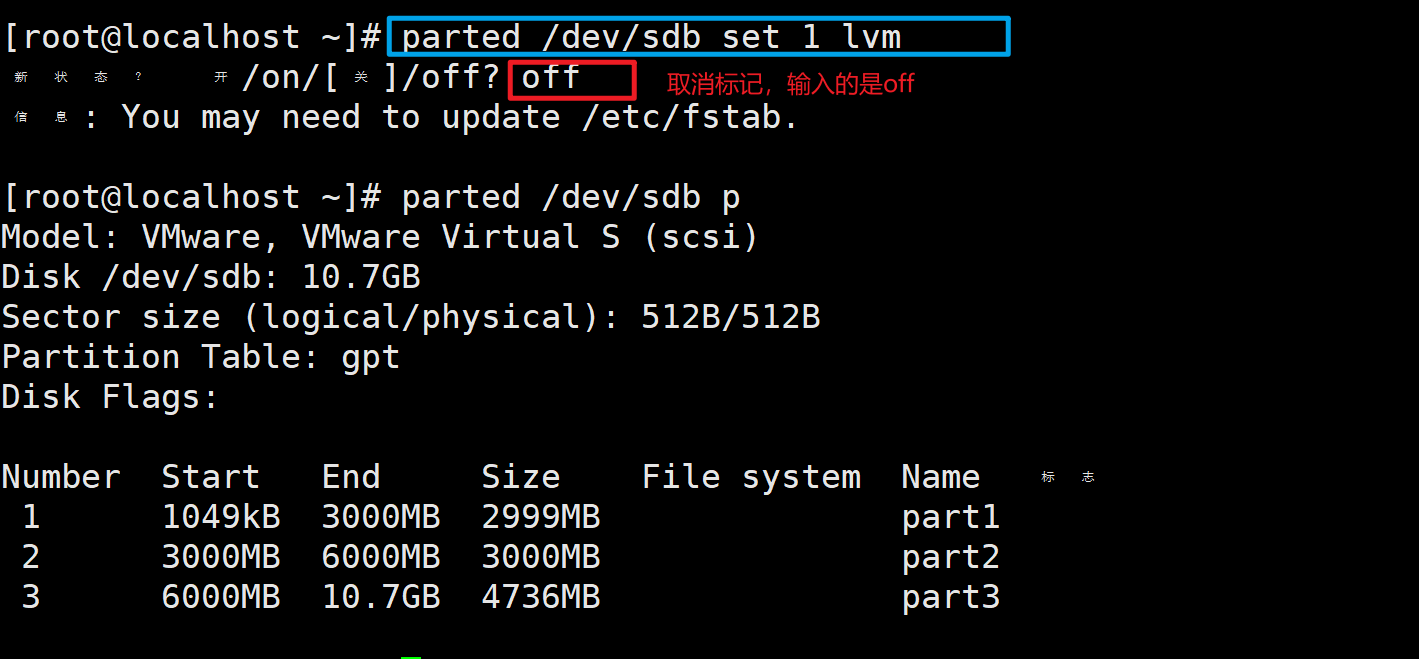
5、删除分区
parted /dev/sdb rm 1
# rm是删除分区的命令
# 1是要删除的分区的编号
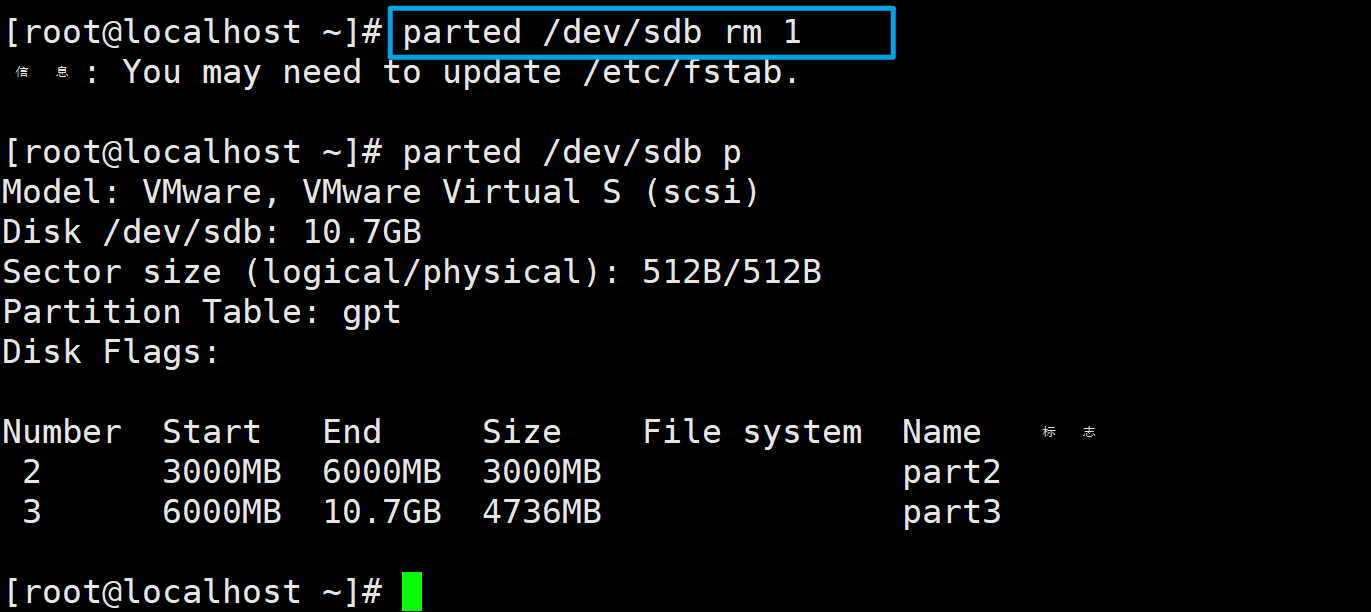
6、更改默认显示单位
这个更改只是一时的,就是说使用parted /dev/sdb unit GB print命令查看时是以GB为单位来显示,但当直接使用parted /dev/sdb print命令查看时还是按照原来的默认显示。
parted /dev/sdb unit GB print
# unit是更改显示单位的命令
# GB是更改后以GB为单位显示(可以是GB、MB、KB等,不区分大小写)
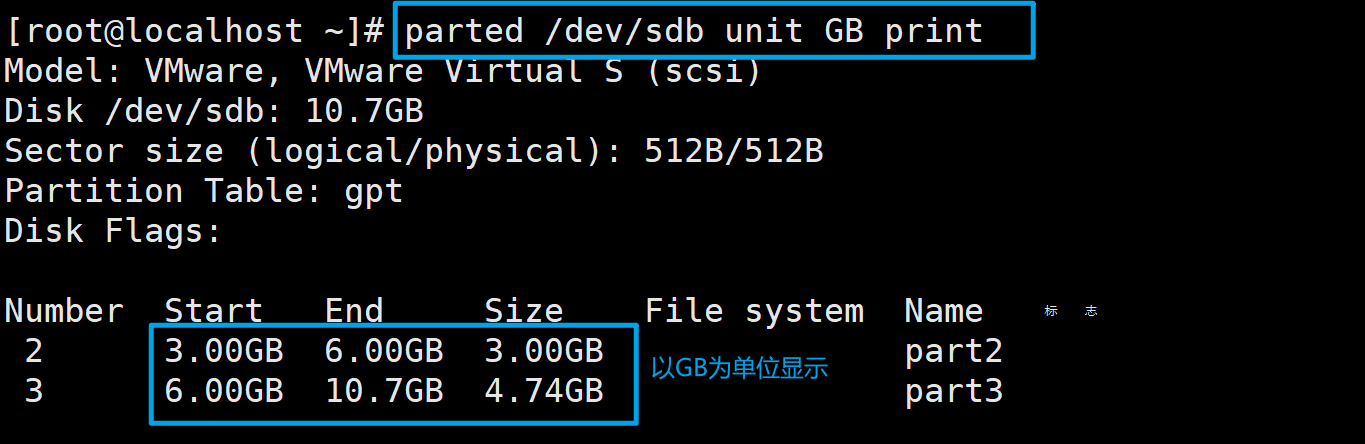
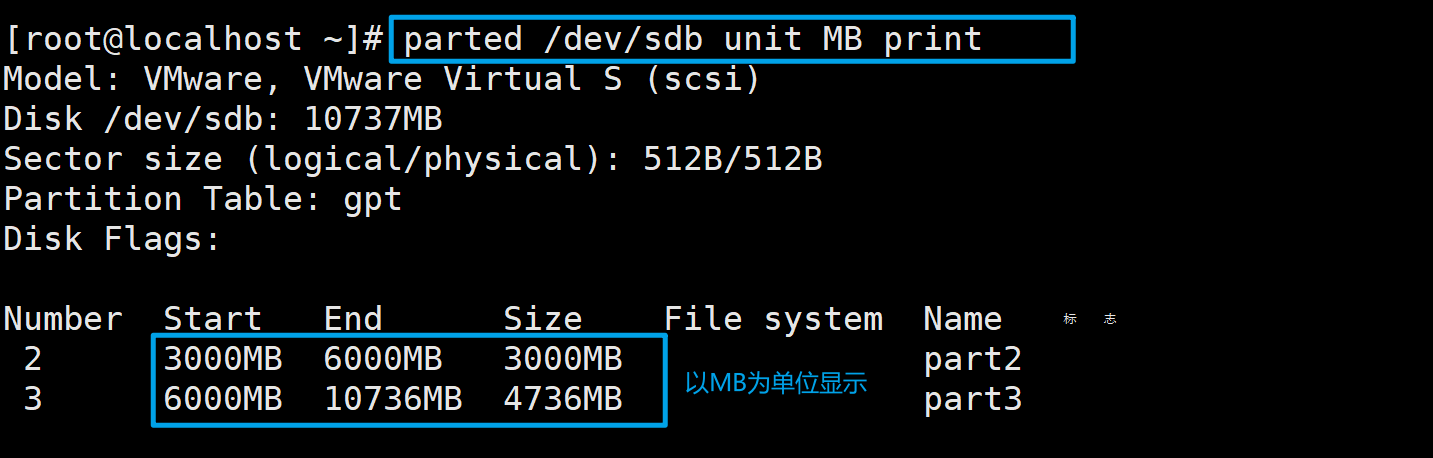
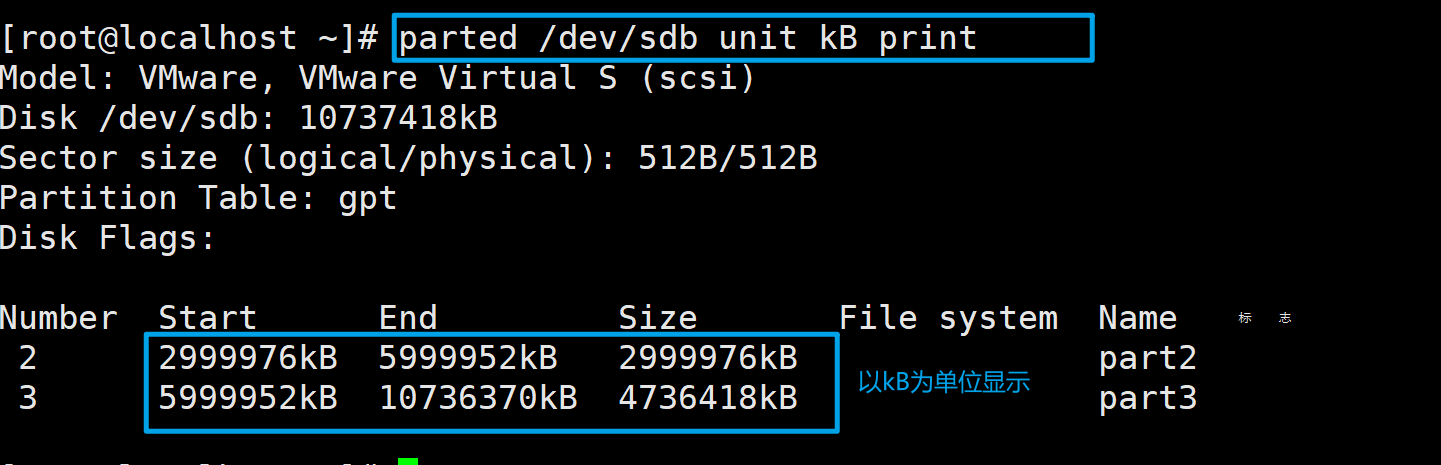
7、怎么计算磁盘剩余容量
使用下面的命令查看磁盘分区情况
parted /dev/sdb print
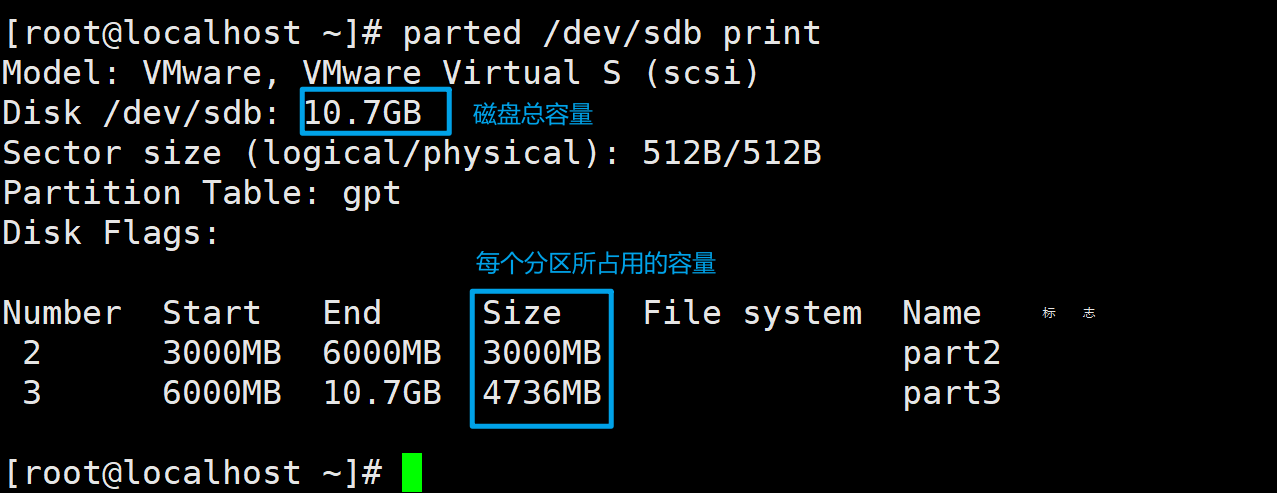
以上图为例,分区2和3占用了大概7.7G左右的空间,磁盘总容量为10.7G,所以磁盘剩余容量为10.7-7.7=3G。
但是,实际能够利用的空间可能没有3GB。在我这个例子中,3000MB到10.7GB的位置是被分区2和3所占有的,剩余的空间是在1048kB到2999MB之间,这段空间是连续的,所以我能够全部利用。
但如果分区2和3之间不是连续的,比如它们之间相隔着1GB的空间没有被分区,在分区2之前也有1GB的空间没有被分区,分区3之后也有1GB的空间没有被分区。空闲容量同样是3GB,但是这3GB我只能将它们分成3个分区使用,每一个分区只能使用1GB。因为一个分区中的空间必须是连续的(除非使用LVM)。
第二种,使用交互模式来进行分区管理
在命令行中输入下面的命令进入到交互模式
parted /dev/sdb
# sdb是需要配置的磁盘
在交互模式中,可以输入help来查看帮助信息,或输入help 指令来查看某条指令的帮助信息。可以使用tab键来补全命令,也可以连按两次tab命令来显示可用指令。

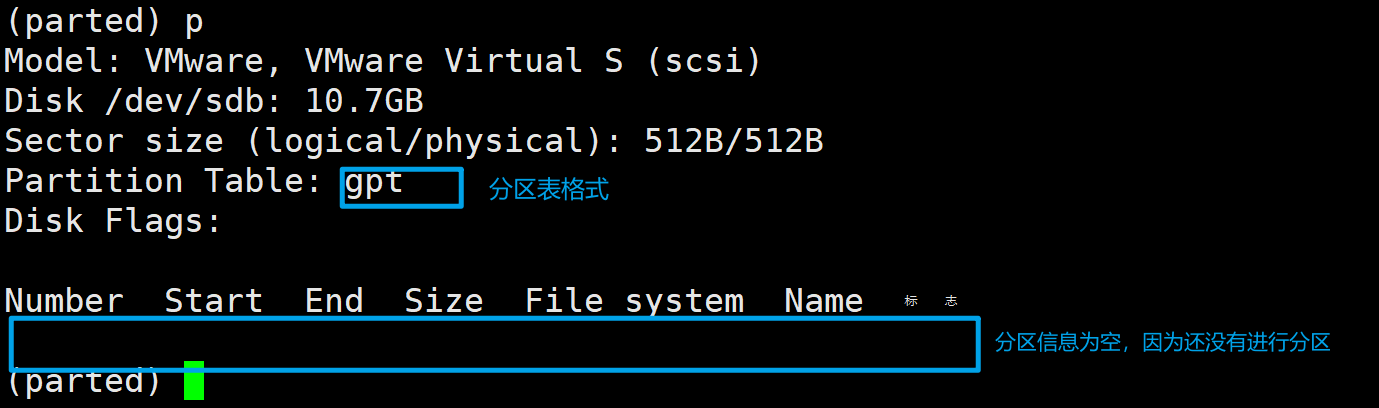
1、新建分区
mklabel gpt
# 创建GPT分区表

输入print或p查看分区包信息
输入mkpart回车,然后按照提示依次输入分区名称、文件系统类型、去世位置,结束位置。
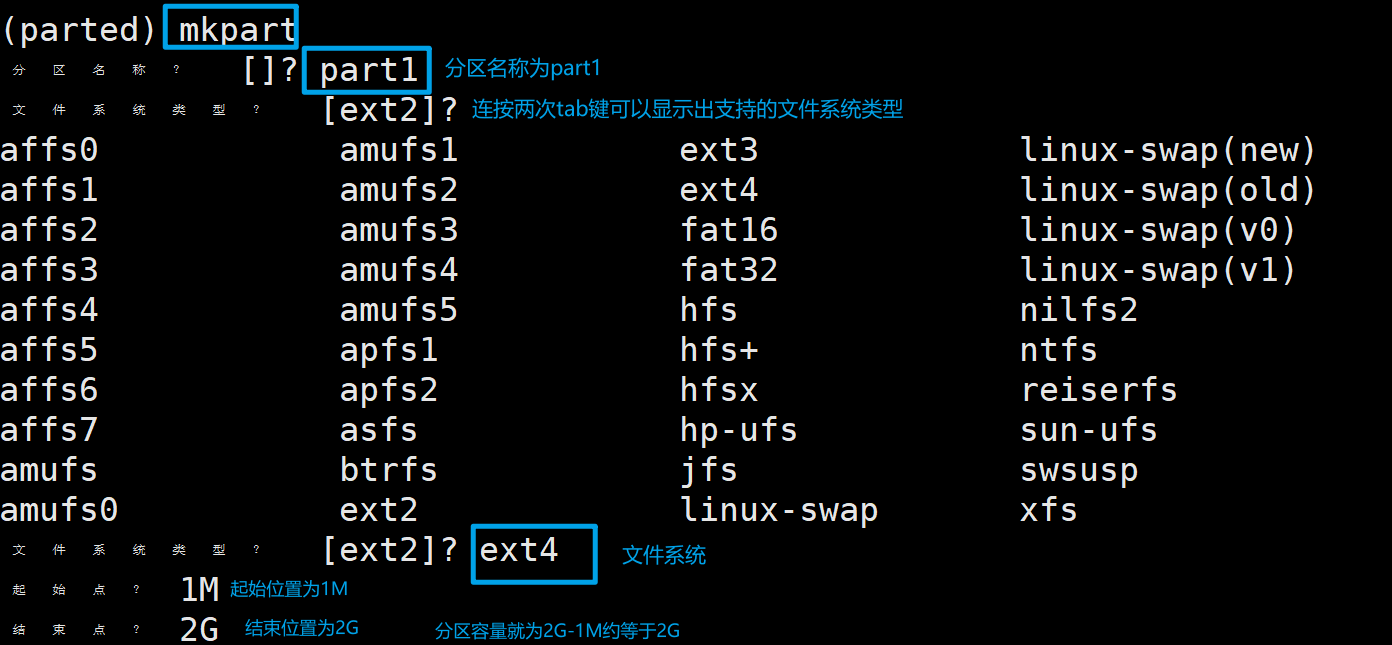
也可以一次性设置好
mkpart part2 ext2 2G 5G
# 分区名称为part2
# 文件系统为ext2
# 起始位置和结束位置分别为2G、5G,所以分区容量为3G
输入p查看一下分区情况
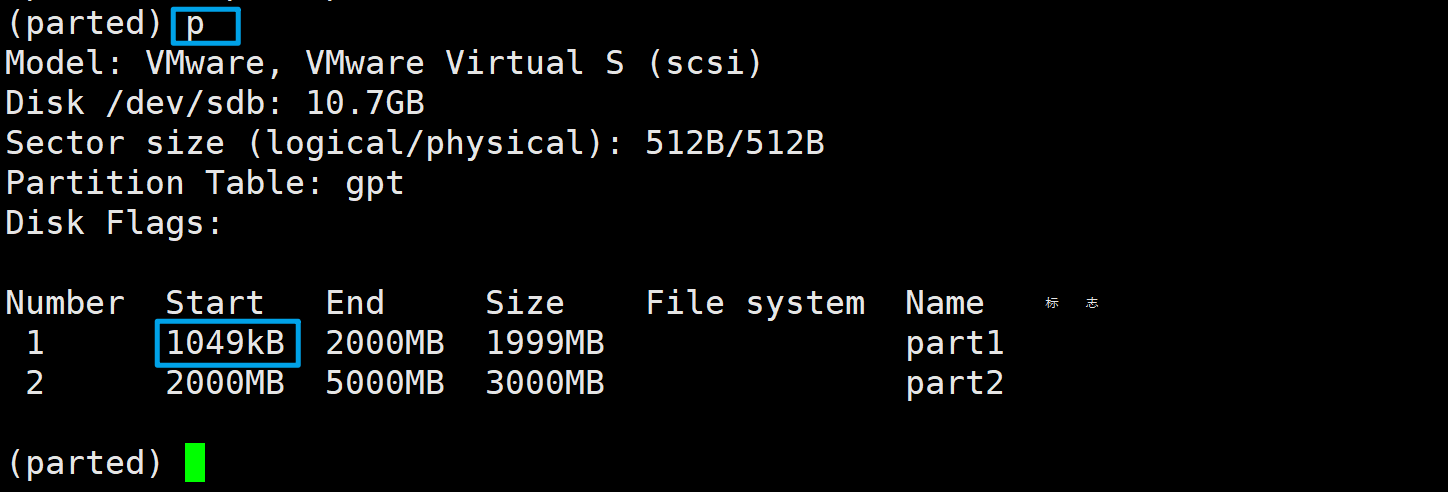
分区1的起始位置为1049kB,1MB==1024KB,。。。(不知道为啥,不纠结,过!)
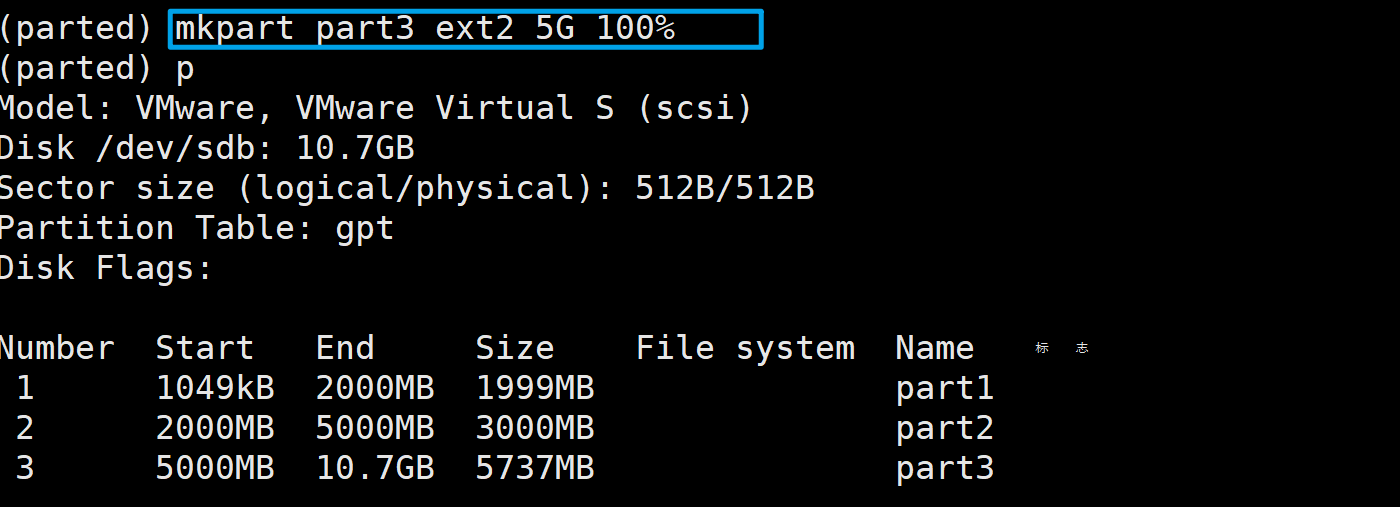
分区的起始位置和结束位置也可以通过百分比的方式来指定。比如:
mkpart part3 ext2 5G 100%
# 将5G之后的空间全部分给分区3
2、设置默认单位
输入unit,回车,根据提示输入要更改的单位。
unit %
# 也可以写在一行
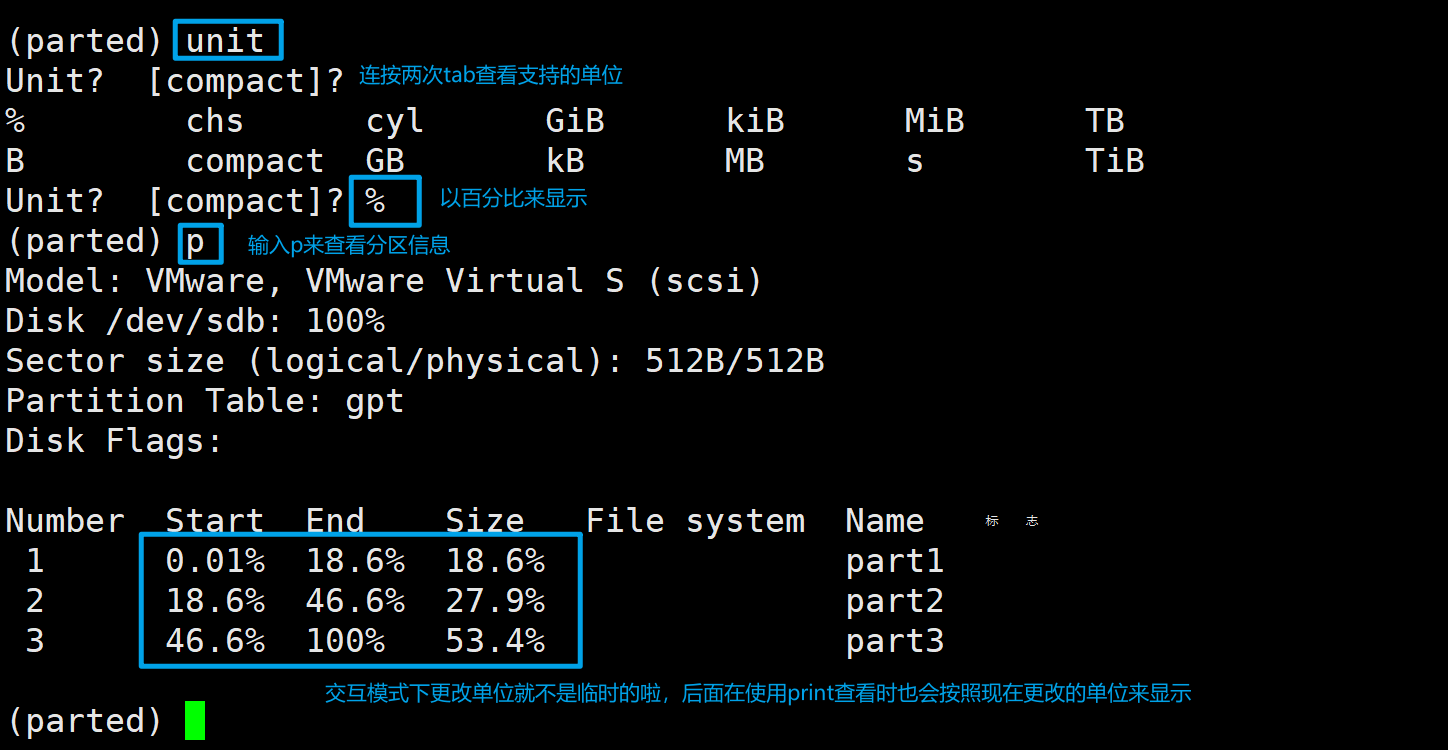
交互模式下更改单位就不是临时的啦,后面在使用print查看时也会按照现在更改的单位来显示。
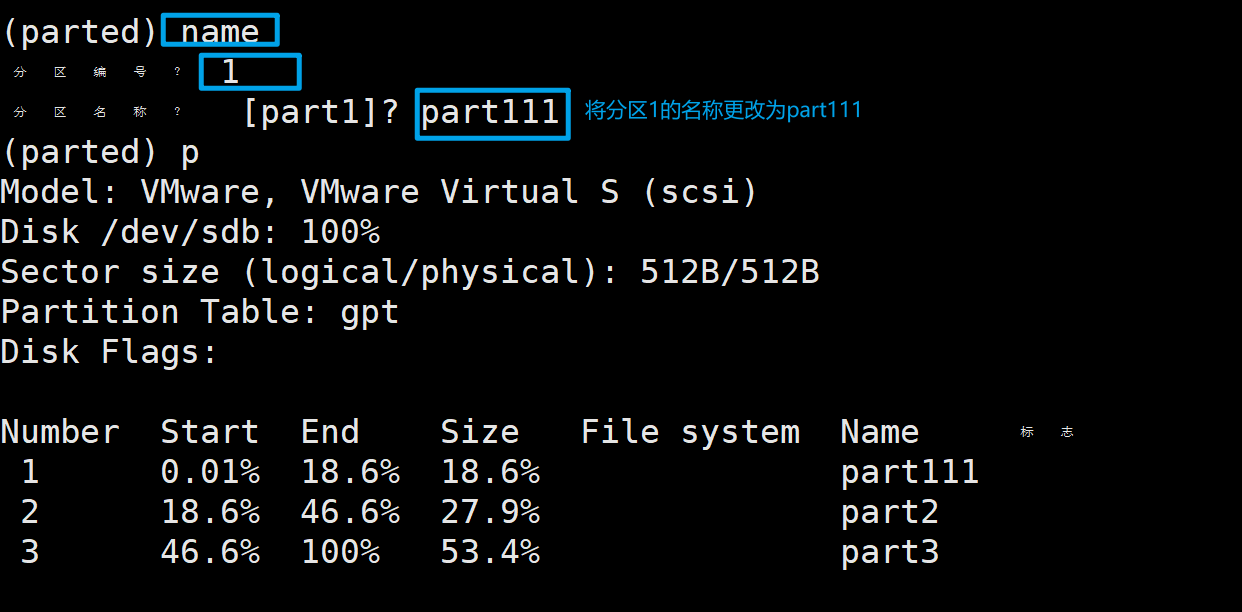
3、更改分区名称
输入name回车,然后根据提示输入分区编号,新名称。
name 1 part111
# 也可以写在一行
4、配置分区标记
输入set,然后根据提示依次输入分区编号、标记类型、on或off(打开或关闭)。同样的在输入标记类型时也可以连按两次tab键来查看支持的类型。
set 1 diag on
# 也可以写在一行中
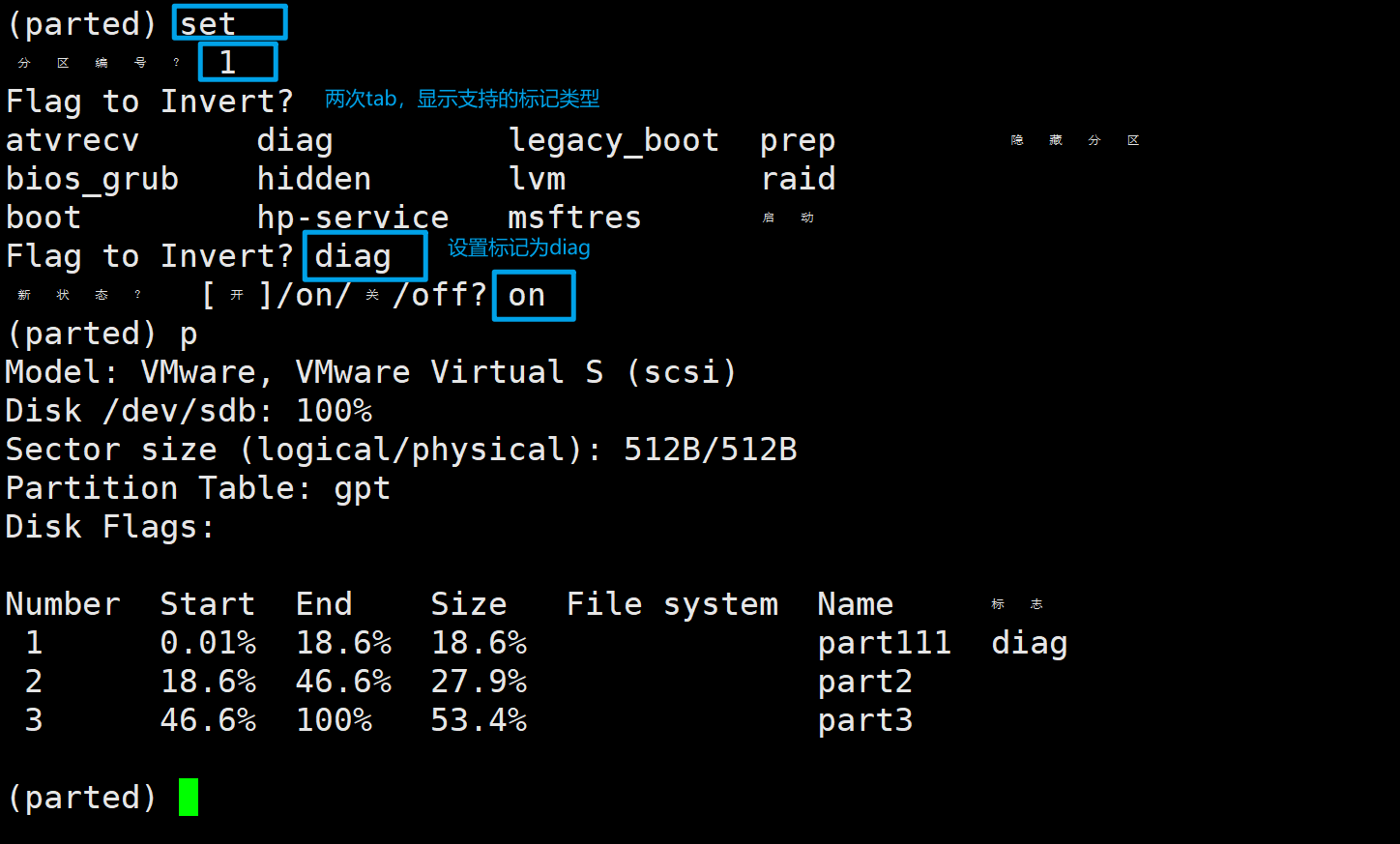
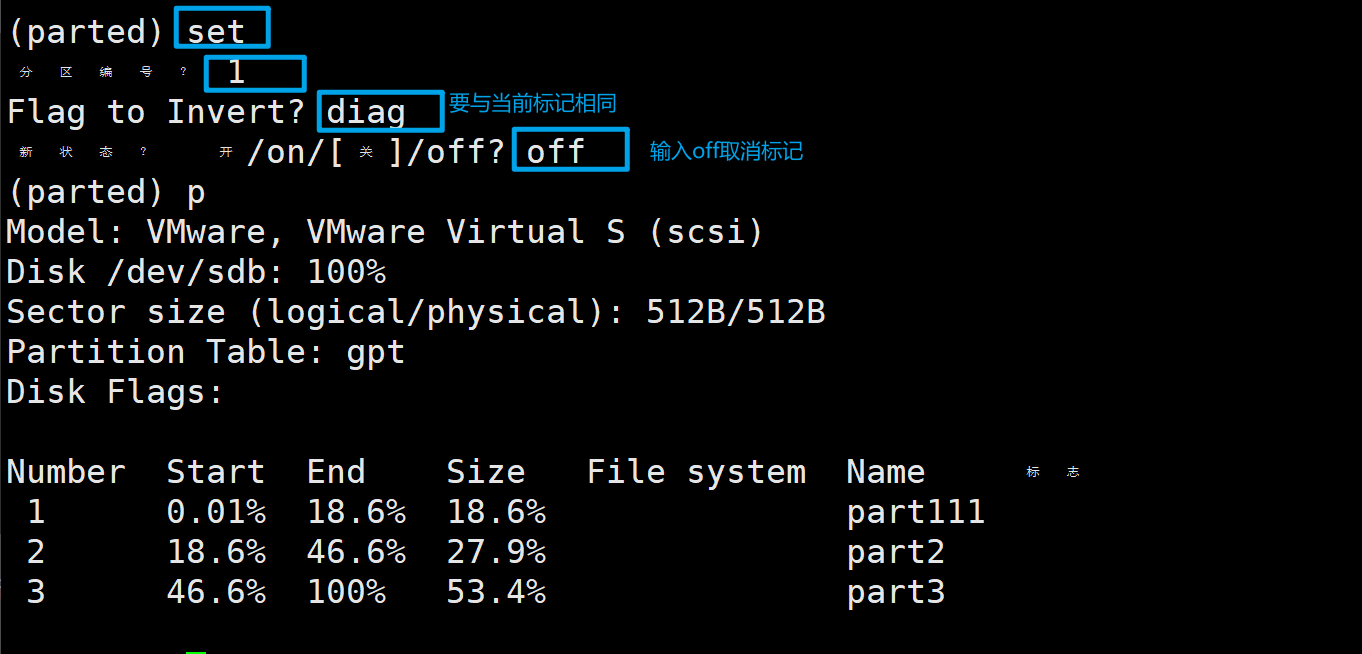
取消标记的操作域配置时类似,在新状态的提示中输入off表示取消标记。
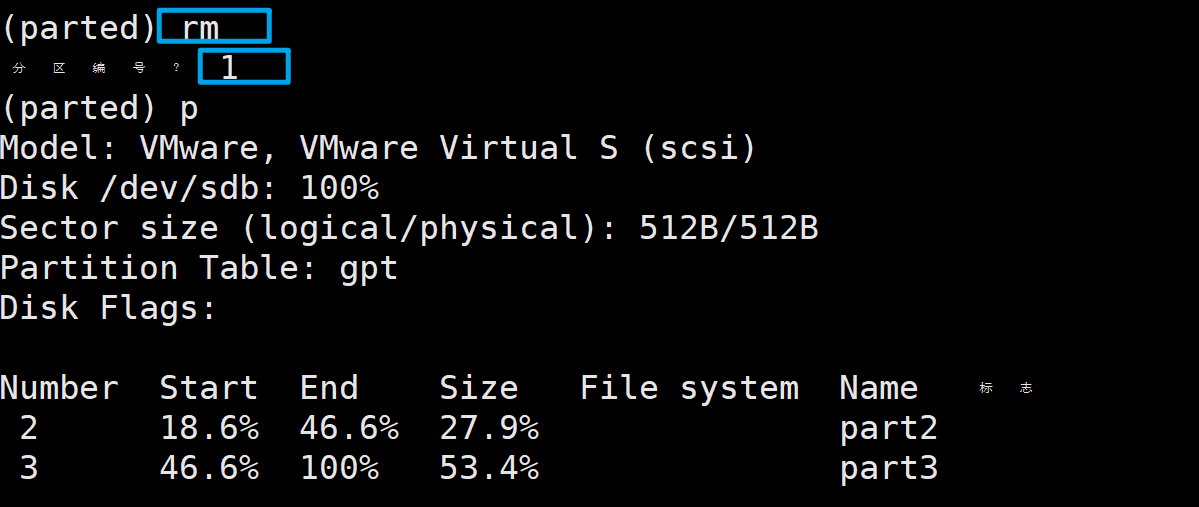
5、删除分区
输入rm回车,然后根据提示输入要删除的分区编号。
rm 1
# 也可以写在一行,直接执行
九、RAID磁盘阵列(待补充)
先使用分区命令 fdisk在系统中创建两个空闲分区/dev/sda5 和/dev/sda6,之后使用这两个分区创建一个名 为/dev/md0 的 RAIDO 级别磁盘阵列,具体命令如下:
mdadm -C /dev/md0 -l 0 -n 2 /dev/sda4 /dev/sda5
# -C工作模式,创建一个新阵列
# /dev/md0 RAID磁盘阵列的名称(路径)
# -l 0 指定RAID级别为0
# -n 2 指定设备数量为2个
# /dev/sda4 /dev/sda5 用于创建RAID的设备
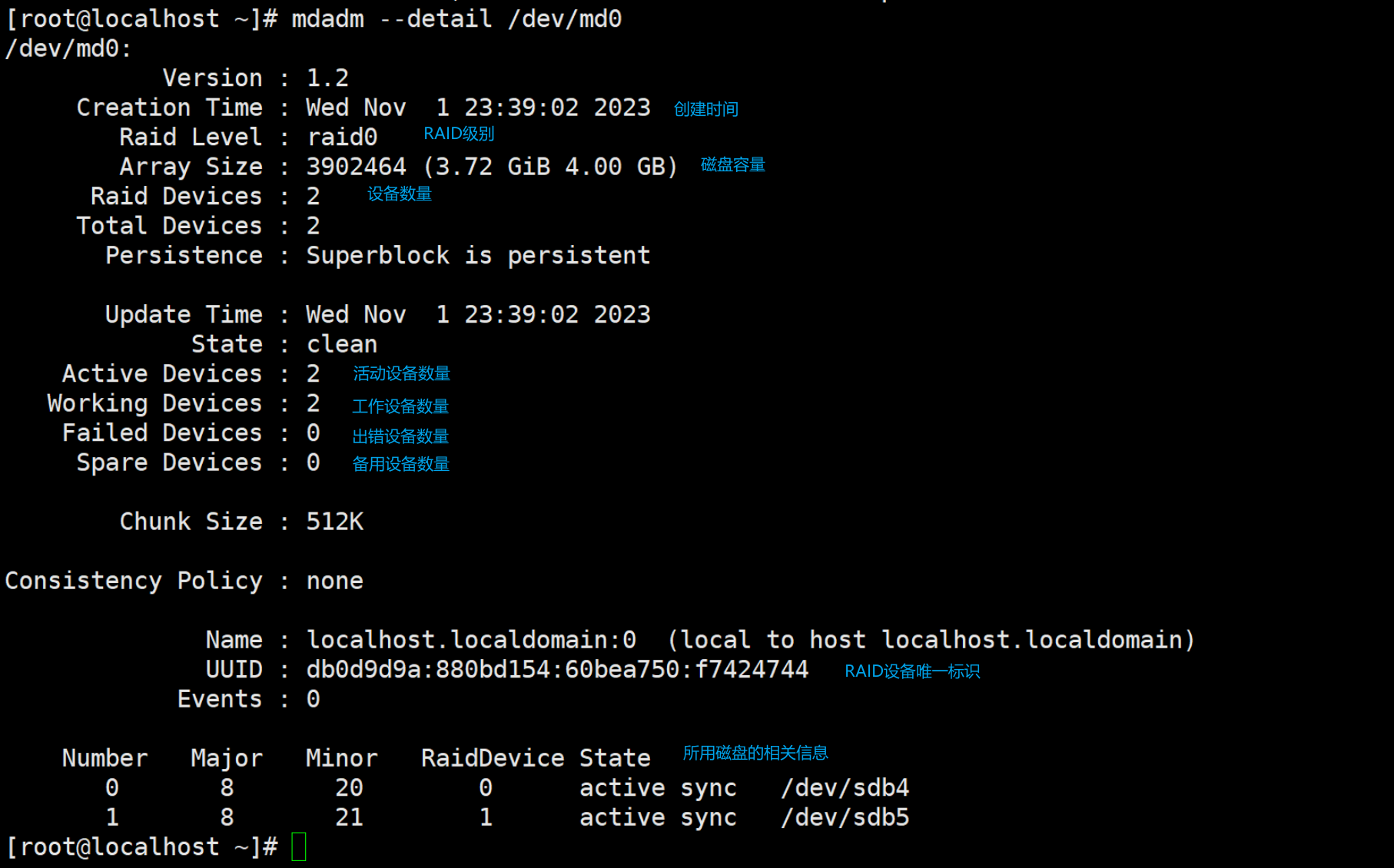
查看RAID磁盘相关信息:
mdadm --detail /dev/md0
十、vi编辑器的使用
1、vi 和 vim 常用的三种模式
-
正常模式
以 vim 打开一个档案就直接进入一般模式了(这是默认的模式) 。在这个模式中, 你可以使用『上下左右』按键来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容, 也可以使用『复制、粘贴』来处理你的文件数据。
-
插入模式
按下 i, I, o, O, a, A, r, R 等任何一个字母之后才会进入编辑模式, 一般来说按 i 即可. -
命令行模式
按 Esc 再输入:在这个模式当中, 可以提供你相关指令,完成读取、存盘、替换、离开 vim 、显示行号等的动作则是在此模式中达成的!
2、各种模式的相互切换
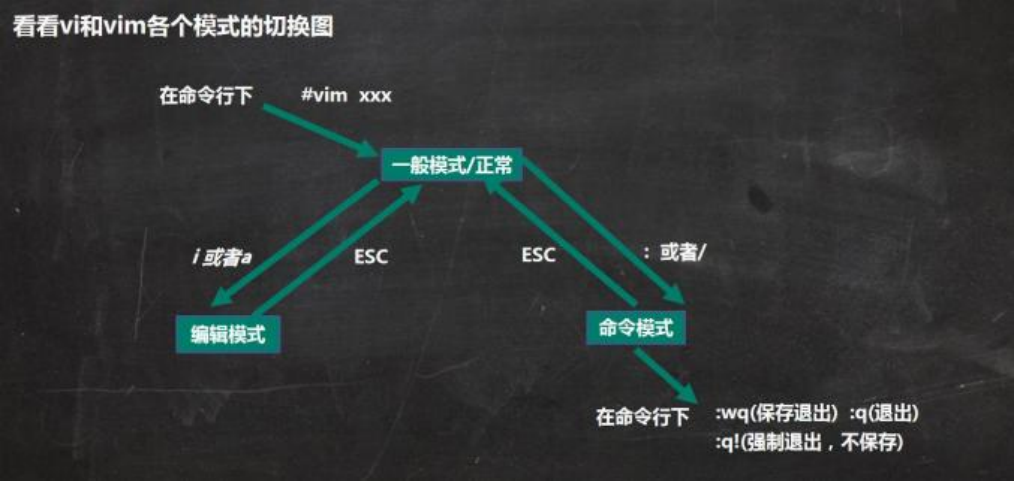
(1)命令模式与插入模式间的切换。
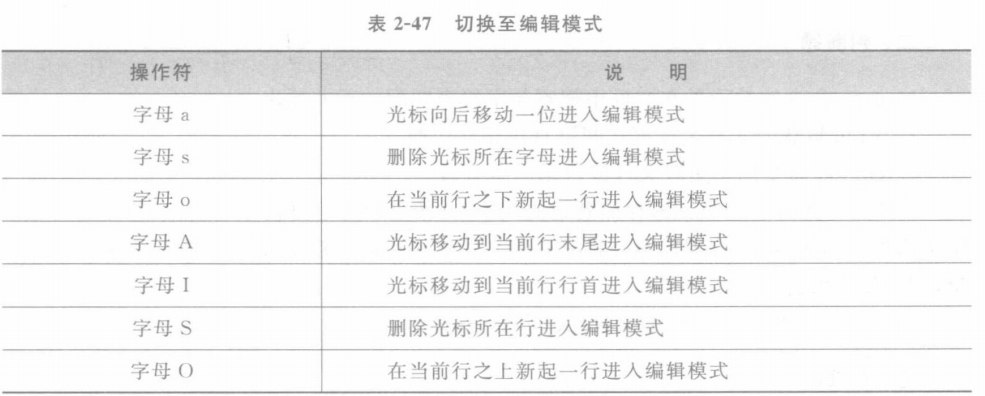
一般情况下,用户可以使用按键 i,直接进入编辑模式,此时内容与光标的位置和命令模 式相同。另外还有其余多种按键,可以不同的形式切换到编辑模式。下面通过表2-47 对其余按键逐一进行讲解。
另使用Esc 键可从插入模式返回命令模式。
(2)命令模式与底行模式间的切换。
在命令模式下使用输入“:”或"/"按键,可进入底行模式。若想从底行模式返回到命令模式,可以使用Esc 键。若底行不为空,可以连按两次 Esc 键,清空底行,并返回命令模式。
3、vi 和 vim 快捷键
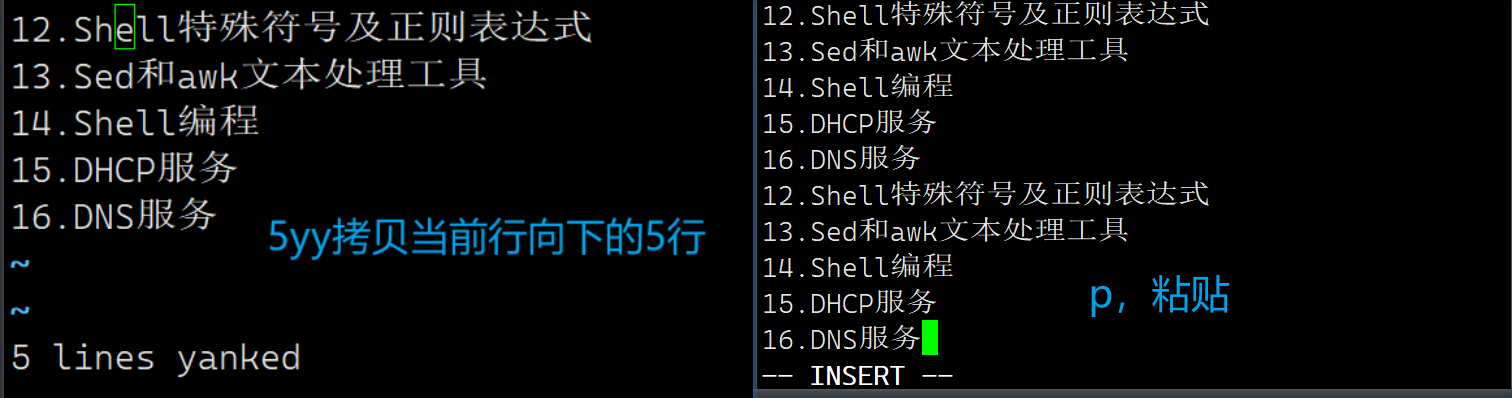
1、拷贝当前行 yy , 拷贝当前行向下的 5 行 5yy ,并粘贴(输入 p)。
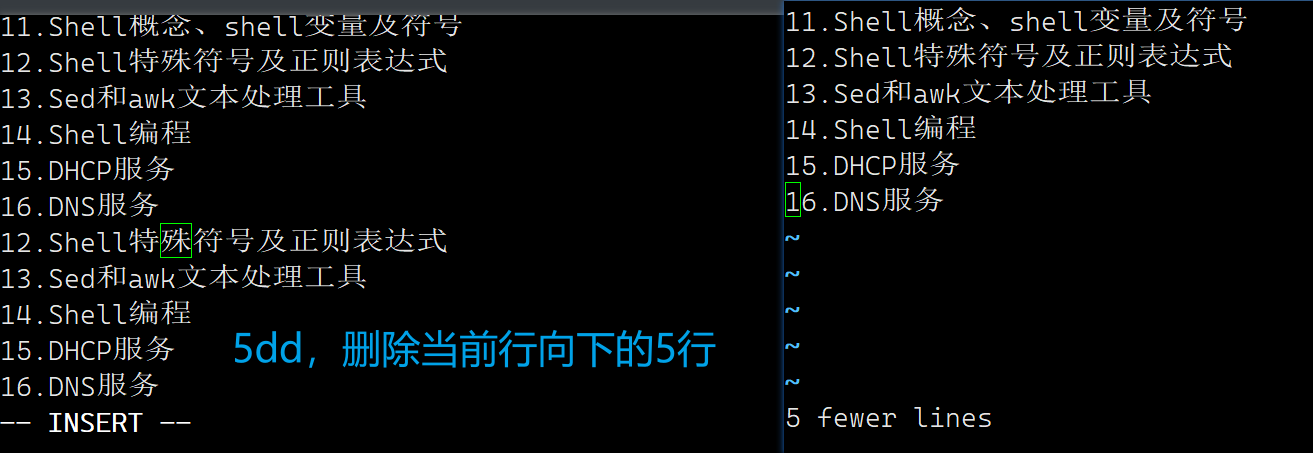
2、删除当前行 dd , 删除当前行向下的 5 行 5dd
3、在文件中查找某个单词 [命令行下输入 /关键字 , 回车查找 , 再输入 n 就是查找下一个 ,N为查找下一个]
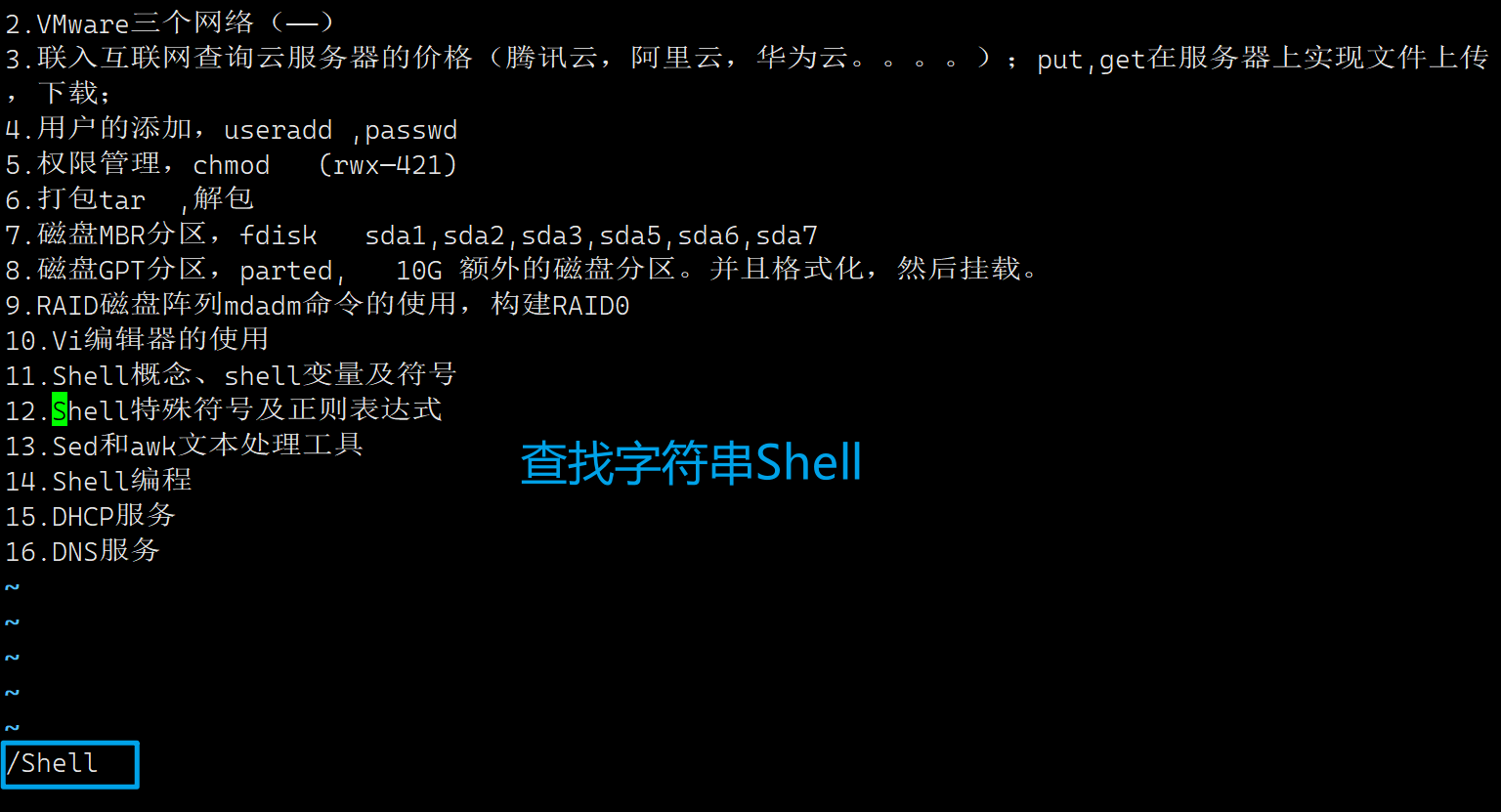
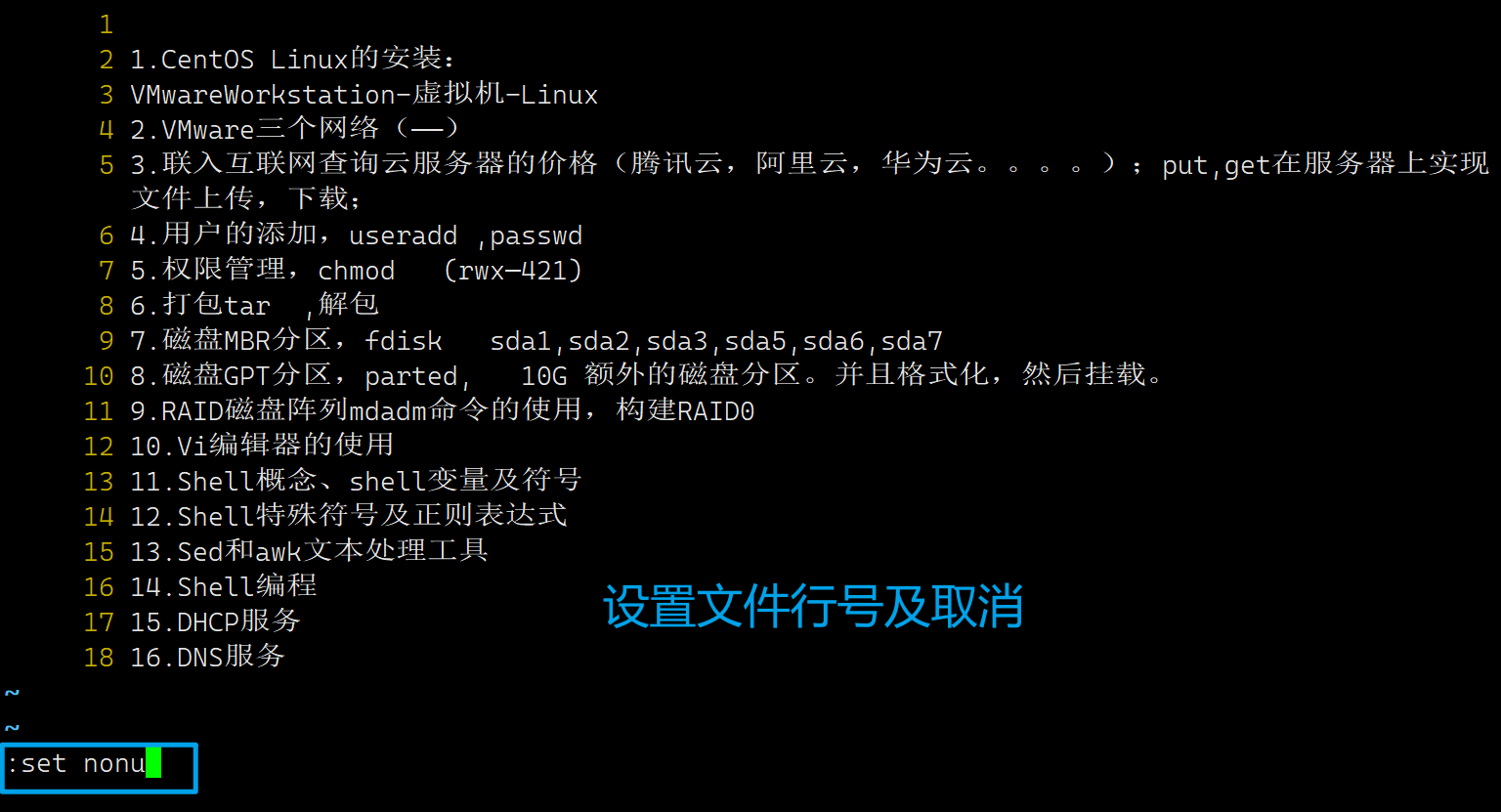
4、设置文件的行号,取消文件的行号.[命令模式下 : set nu 和 :set nonu]
5、定位首行和尾行,在一般模式下, 使用快捷键到该文档的最末行 G 和最首行 gg
6、撤销动作,在一般模式下, 撤销动作为 u
7、定位某行,在一般模式下, 输入 20,再输入 G,则光标移动到20行首
十一、Shell概念、shell变量及符号
二、Shell中的变量
Shell中常用的 变量有4种:本地变量、环境变量、位置变量和特殊变量。
1、本地变量
本地变量相当于C 语言中的局部变量,它只在本 Shell中有效,如果 Shell退出,本地变量将被销毁。
本地变量的定义格式如下所示:
NAME=value
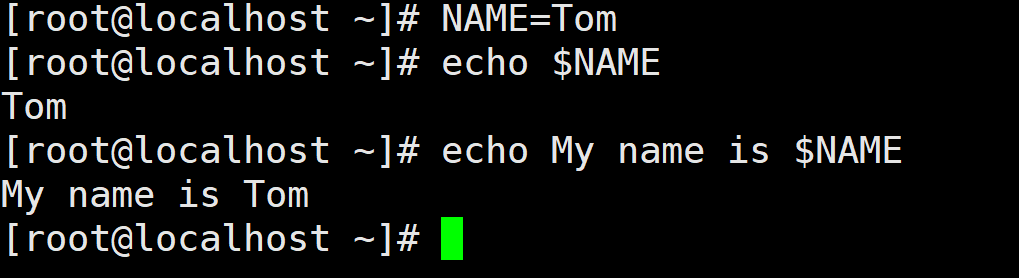
NAME 是变量名,value是赋给变量的值。如果 value 没有指定,变量将被赋值为空字符串。在使用变量时,要在变量前面加“\(”符号。例如,定义一个变量 NAME, 其值为 Tom, 在输出时,要以\)NAME 的形式输出。
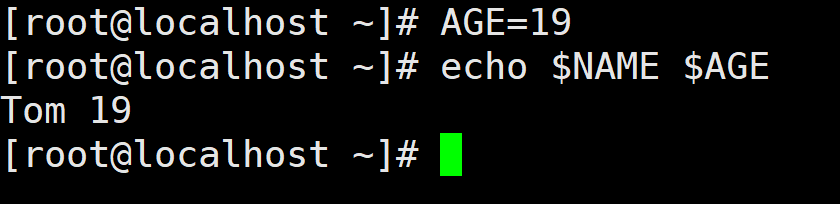
Shell支持连续输出多个变量的值,例如,再定义一个变量 AGE, 其值为19,然后同时输出变量NAME与AGE。
在定义本地变量时,还可以使用read命令从标准输入中读取变量值,其中 read 的-p 选项可以设置输入提示信息。

删除所定义的变量,可以使用unset命令。

调用 unset 命令删除 AGE 变量后,再输出该变量时值不再显示,仅输出一个空白行,表明这个变量已被删除(输出一个不存在的变量时也是输出一个空白行)。
总结:
# 定义,使用赋值号
NAME=value # 变量名好像不一定需要是大写
# 使用,在变量名前加$
echo $NAME
# 删除unset
unset NAME
2、环境变量
环境变量是 Shell中非常重要的一个变量,用于初始化 Shell的启动环境。
(1)环境变量的定义与清除
环境变量在 Shell编程和 Linux 系统管理方面都起着非常重要的作用,它一般用来存储路径列表,这些路径可用于搜索可执行文件、库文件等。环境变量定义格式如下所示:
export ENVIRON-VAEIABLE=value
环境变量必须要使用export关键字导出,export关键字的作用是声明此变量为环境变量。例如,定义 APPSPATH 变量并赋值为/usr/local,然后利用 export 将 APPSPATH 声明为环境变量。

在命令行中使用 export定义的环境变量只在当前 Shell与子 Shell中有效,Shell 重启后这些环境变量将丢失,如果需要永久更改,需要修改环境变量的配置文件(后面会讲)。
使用env 命令可以查看所有的环境变量,包括用户自定义的环境变量。
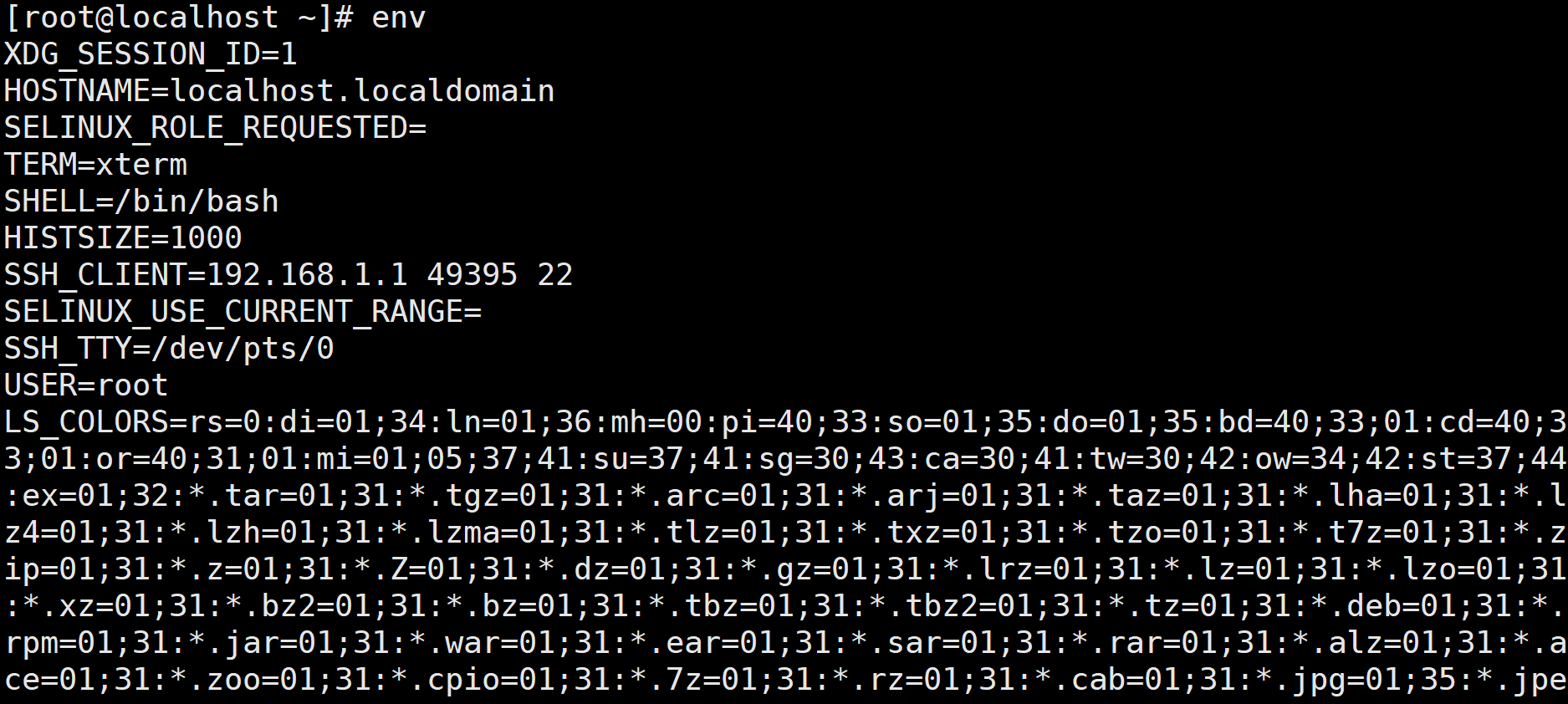
删除环境变量和删除本地变量的方式相同,也是调用unset命令。
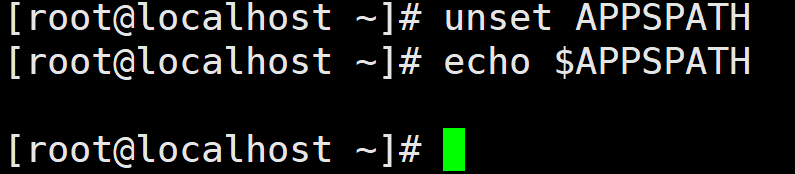
总结:
环境变量的定义、使用和删除与本地变量类似,只是环境变量在定义时需要使用export关键字进行声明。
使用env可以查看所有的环境变量。
(2)几个重要的环境变量
bash 中预设了很多环境变量,其中有几个比较重要的环境变量,Linux 系统及诸多应用 程序的正常运行都依赖它们。
PATH
PATH 是 Linux 中一个极为重要的环境变量,它用于帮助Shell找到用户所输入的命令。用户输入的每个命令都是一个可执行程序,计算机执行这个程序以实现这个命令的功能。可执行程序存在于不同目录下,PATH 变量就记录了这一系列的目录列表。
输出 PATH 变量的值,结果如下所示:

由输出结果可知,PATH 中包含了多个目录,它们之间用冒号分隔,这些目录中保存着命令的可执行程序,例如,输入 ls命令,PATH 就会去这些目录中查找 ls命令的可执行程 序,首先在/usr/local/bin目录查找,找到就执行该命令;没找到就继续查找下一个目录,直 到找到为止。如果PATH 值存储的目录列表中的所有目录都不包含相应文件,则 Shell会 提示"未找到命令……"。
PATH 变量的值可以被修改,但在修改时要注意不可以直接赋新值,否则 PATH 现有 的值将会被覆盖。如果要在 PATH 中添加新目录,可以使用下面的命令格式:
PATH=$PATH:/newdrectory
# 例如将目录/opt目录加到环境变量中
PATH=$PATH:/opt
以上格式中$PATH 表示原来的 PATH 变量,new directory 表示要添加的新路径,中 间用冒号隔开,旧的 PATH 变量加上新增路径之后再赋值给PATH 变量。
PWD 和 OLDPWD
PWD 记录当前的目录路径,当利用cd命令切换到其他目录时,系统自动更新PWD的值,OLDPWD 保存旧的工作目录。输出这两个变量的值,结果如下所示:
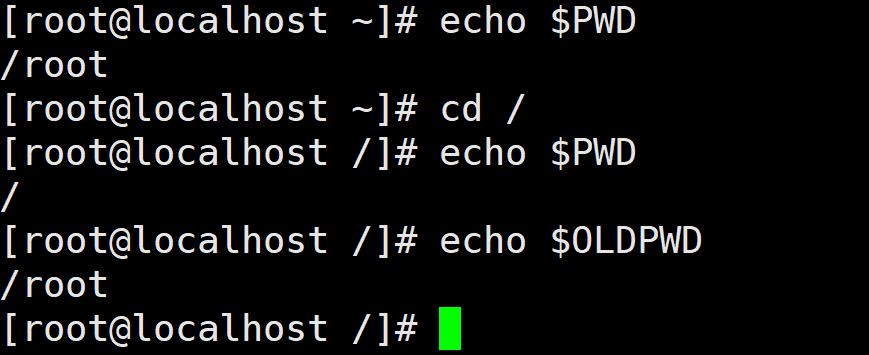
从/root目录切换到根目录后,当前目录为/,之前所在的目录是/root。
HOME
HOME 记录当前用户的家目录,例如,在本机中有两个用户 root、abc,分别用这两 个用户输出$HOME 变量的值,具体如下所示:
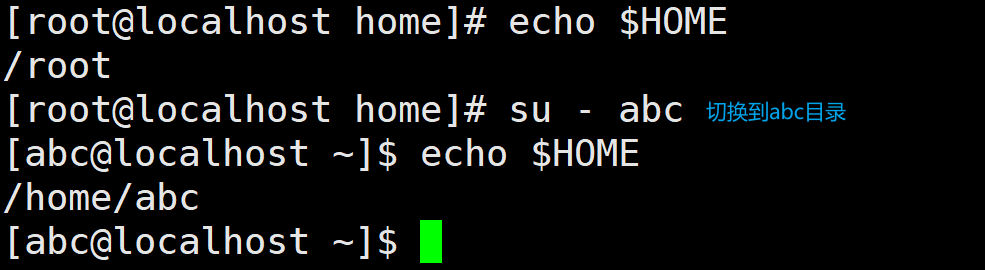
SHELL
SHELL 变量的值是/bin/bash,表示当前的 Shell是 bash。 如果有必要使用其他Shell, 则需要重置 SHELL 变量的值。
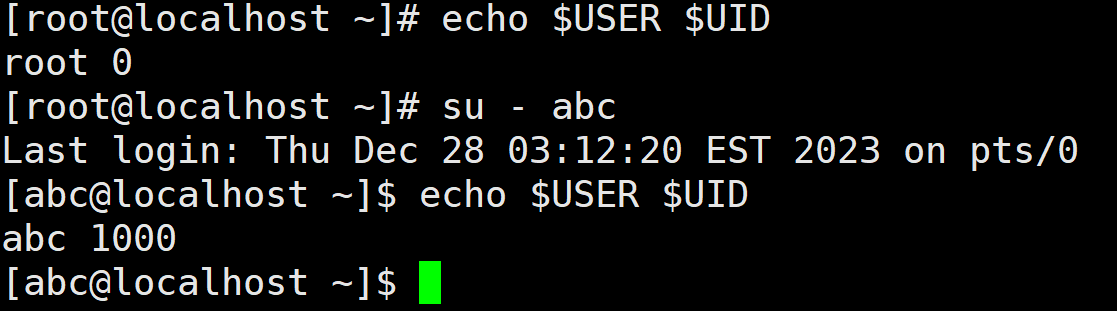
USER 和 UID
USER 和 UID 是用于保存用户信息的环境变量,USER 保存已登录用户的名字,UID 则保存已登录用户的ID。 使用echo 命令打印这两个环境变量,具体如下所示:
PS1 和PS2
PS1 和 PS2 称为提示符变量,用于设置提示符格式。例如,“[itheima@localhost ~]$” 就是 Shell提示符,[]里包含了当前用户名、主机名和当前目录等信息,这些信息并不是固 定不变的,可以通过PS1 和 PS2 的设置而改变。
PS1 用于设置一级 Shell提示符,也称为主提示符。使用 echo命令查看 PS1 的值。

由以上输出结果可知,变量PS1 包含4项内容,这4项内容的含义分别如下:
- \u 表示即当前用户名;
- \h 表示主机名;
- \W 表示当前目录名;
\$是命令提示符,普通用户是$符号,如果是 root用户,命令提示符是#符号。
PS2 用于设置二级 Shell提示符,使用echo 命令查看PS2 的值,其结果如下所示:
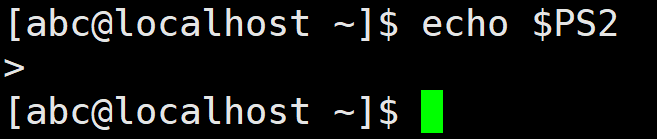
PS2 的值为>符号,当输入命令不完整时,将出现二级提示符。
(3)环境变量的配置文件
Linux 中环境变量包括系统级和用户级,系统级的环境变量对每个用户都有效,而用户级的环境变量只对当前用户有效。环境变量的配置文件也分为系统级和用户级,系统级的文件有很多,例如/etc/profile、/etc/profile.d、/etc/bashrc、/etc/environment 等,在这些文件中定义的环境变量对所有用户都是永久有效的。用户级的环境变量配置文件主要是 .bash profile和 .bashrc两个文件,它们位于用户的家目录下。例如,以abc用户登录, 它们位于/home/abc/目录下,使用cat命令查看两个文件中的内容,具体如下所示:
注意:如果是从其他用户使用su命令切换到abc用户的,那么无法查看这个文件。需要直接使用abc用户登录,才能查看abc家目录下的这个文件。
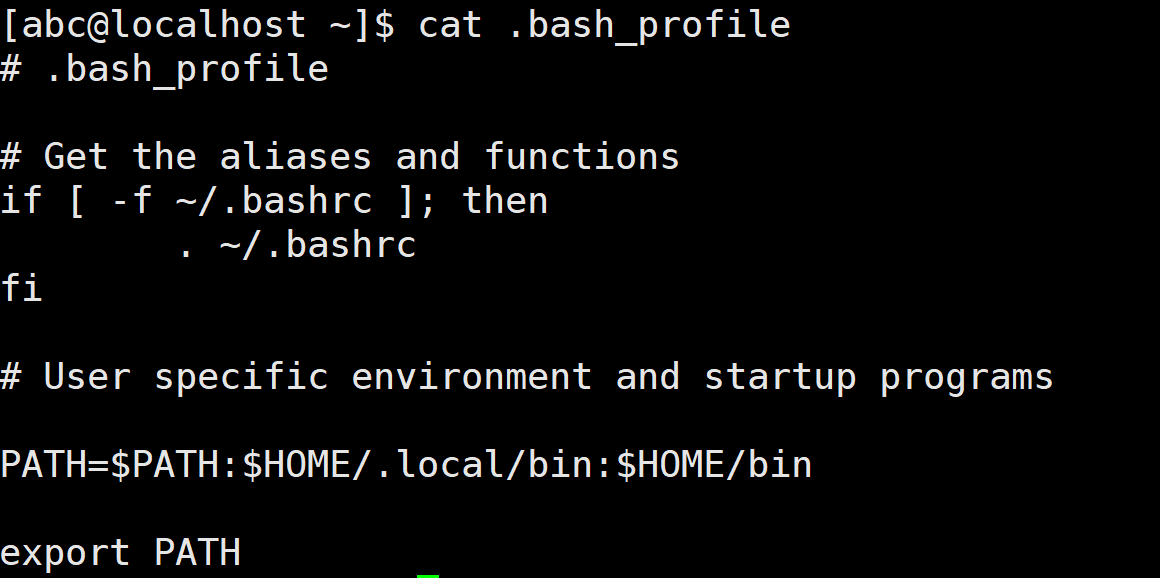
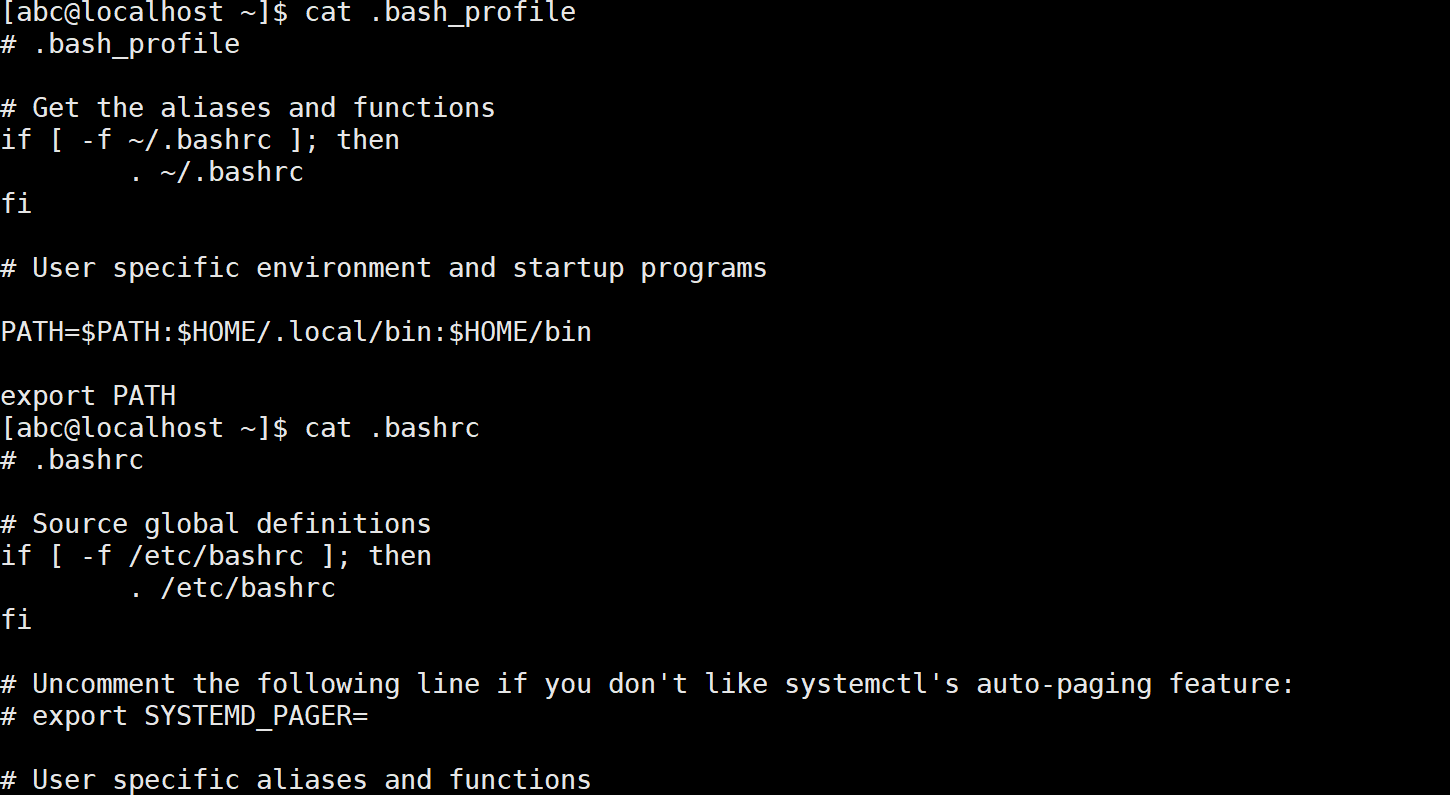
.bash profile文件主要定义当前 Shell 环境变量, .bashrc 文件主要用于定义子 Shell 环境变量。如果当前 Shell创建了一个子 Shell,则 .bashrc 文件使得子 Shell的环境变量与 当前 Shell 的环境变相分离。
用户在上述文件中均可以定义永久有效的环境变量,但要区分开环境变量是对所有用户有效还是对当前用户有效。
3、位置变量
位置变量主要用于接收传入 Shell脚本的参数,因此位置变量也被称为位置参数。位置变量的名称由“$”与整数组成,命名规则如下所示:
$n
$n 用于接收传递给 Shell脚本的第 n 个参数,如变量\(1接收传入脚本的第一个参 数。当位置变量名中的整数**大于9时,需使用{}将其括起来**,如脚本中的第11个位置参数 应表示为\){11}。位置变量是Shell 中唯一全部使用数字命名的变量。需要注意的是,n 是 从1开始的,$0表示脚本自身的名称。
接下来通过一个 Shell脚本来演示位置变量的用法,使用vi编辑器创建并编写test.sh脚本,内容如下:
#!/bin/bash
echo "The script's name is : $0" # 脚本名
echo "Parameter #1: $1" # 第1个位置参数
echo "Parameter #2: $2"
echo "Parameter #3: $3"
echo "Parameter #4: $4"
echo "Parameter #5: $5"
echo "Parameter #6: $6"
echo "Parameter #7: $7"
echo "Parameter #8: $8"
echo "Parameter #9: $9"
echo "Parameter #10: ${10}"
echo "Parameter #11: ${11}"
注:“#”后的字符表示注释,除第一行外的注释都可以不写。
执行test.sh脚本并传入参数,输出结果如下:
bash test.sh a b c d e f g h i j k
# 脚本按照位置接受参数,与编程语言中的函数类似。
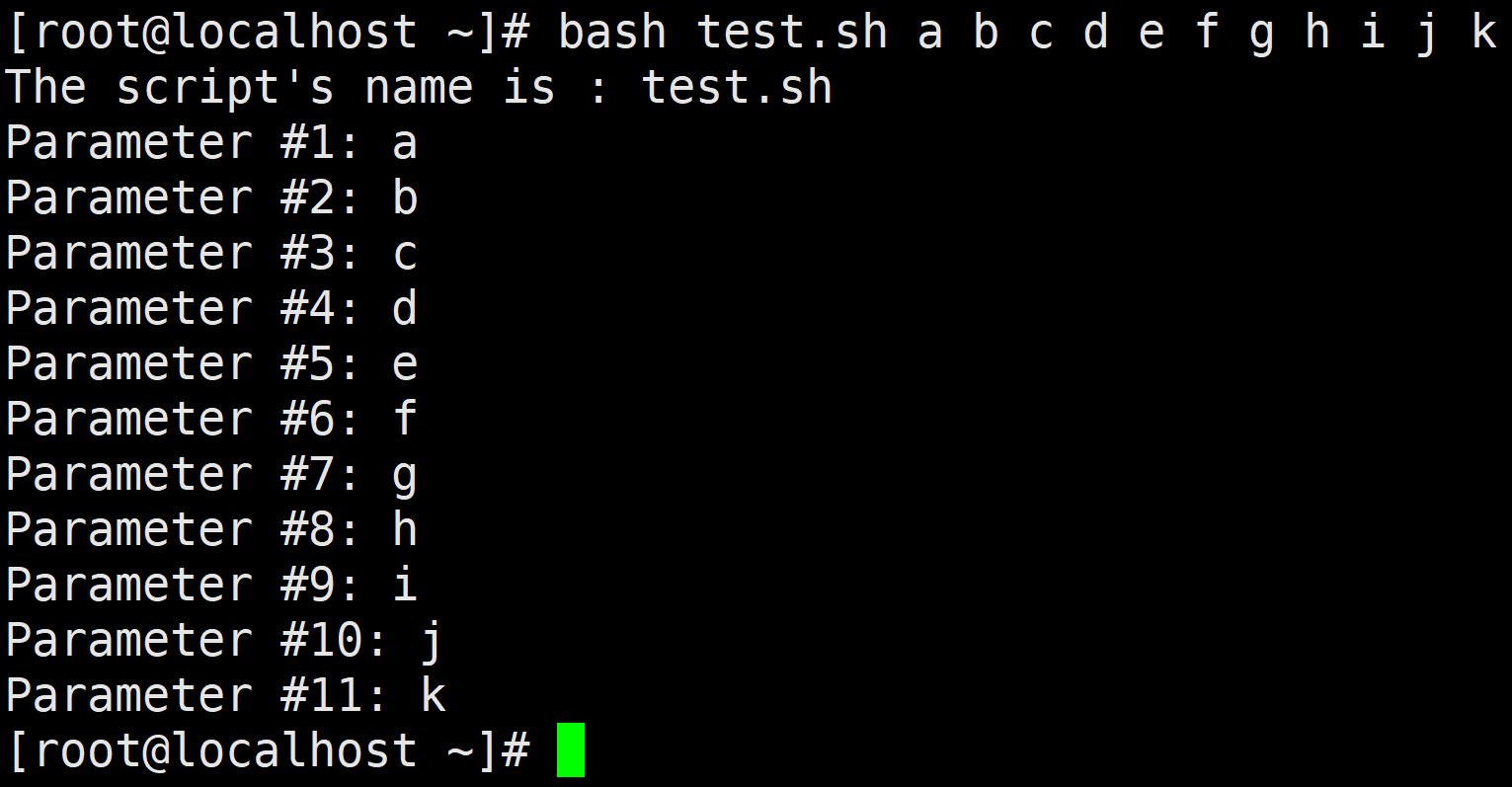
在接受参数时,位置变量只根据位置来接受相应参数,比如修改 test.sh 脚本如下。
#!/bin/bash
echo "The script's name is : $0"
echo "Parameter #8: $8"
echo "Parameter #9: $9"
echo "Parameter #10: ${10}"
再次执行脚本,参数与上一次相同,结果如下:
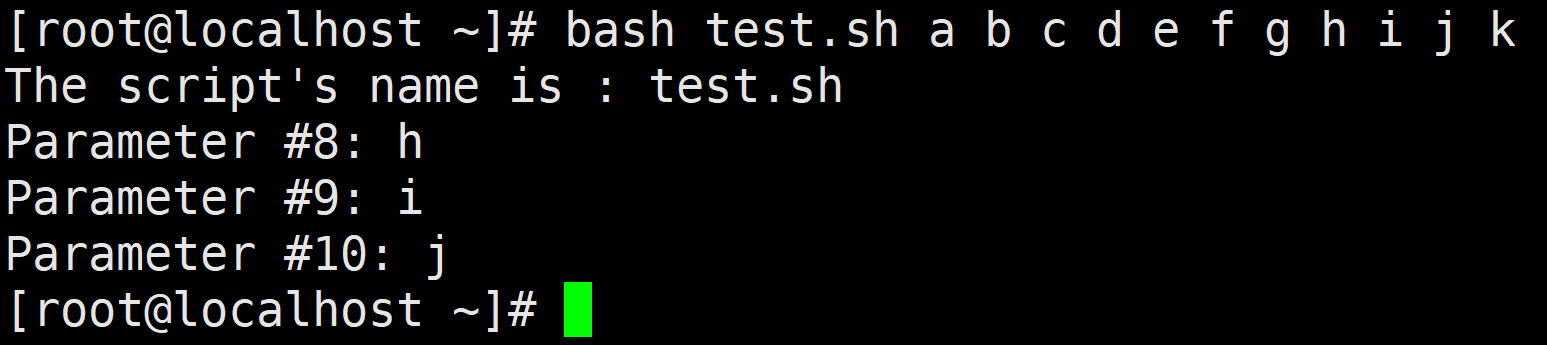
在传入的参数中,第8个位置是h,$8 读取到了相应位置的参数。如果传入的参数不足8个,那么$8值为空。参数传多了也不会报错。
4、特殊变量
除了上述几个变量之外,Shell还定义了一些特殊变量,主要用来查看脚本的运行信息。 Shell中的常用的特殊变量如下所示。
$#:传递到脚本的参数数量。$*和$@:传递到脚本的所有参数。$?:命令退出状态,0表示正常退出,非0表示异常退出。$$:表示进程的PID。
接下来修改 test.sh脚本来演示特殊变量的用法,在脚本中添加一些内容。
#!/bin/bash
echo "The script's name is : $0"
echo "Parameter #8: $8"
echo "Parameter #9: $9"
echo "Parameter #10: ${10}"
# 新增代码
echo "Parameter count: $#" # 传递给脚本的参数的数量
echo "All parameter: $*" # 传递给脚本的所有参数
echo "All parameter: $@" # 传递给脚本的所有参数
echo "PID: $$" # 本程序的进程ID
运行结果如下:
bash test.sh a b c d e f g h i j k
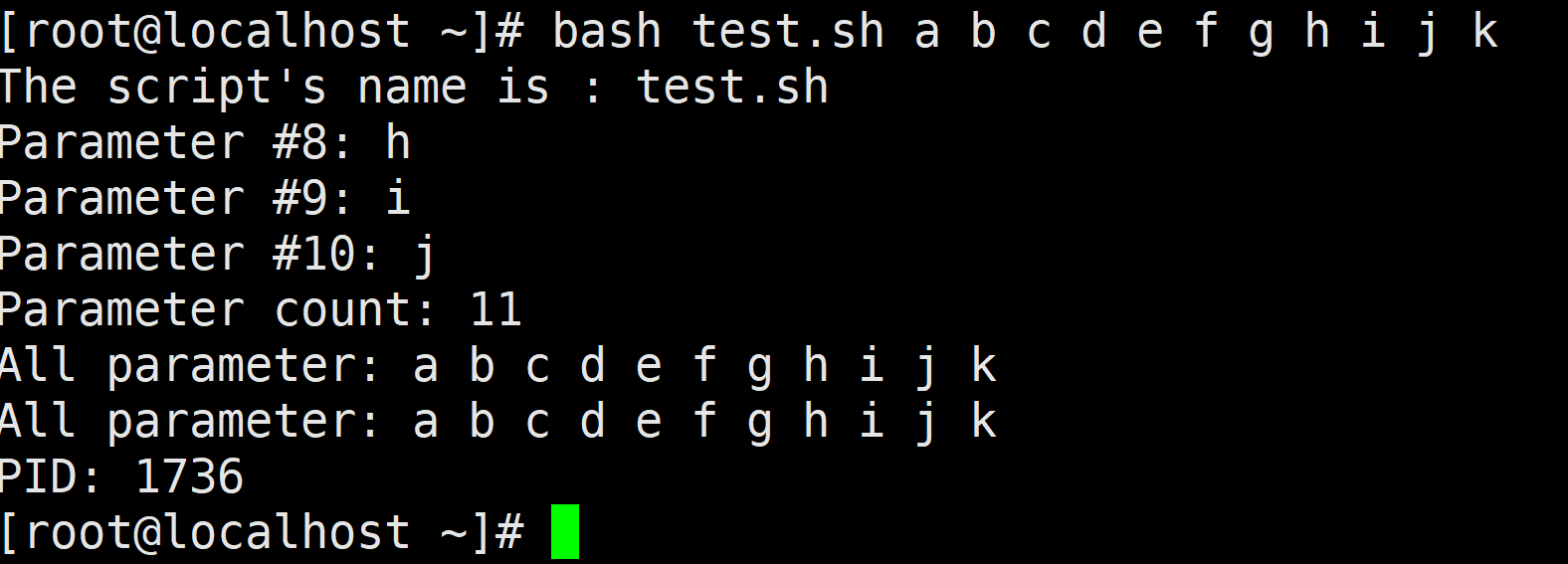
三、Shell中的符号
1、引号
在 Shell中,引号主要用来转换元字符的含义。所谓元字符,是指那些在正则表达式(正则表达式在后面会讲)中具有特殊处理能力的字符,如$、\、>等字符。
Shell 中的引号有3种:单引号(')、双引号("")与反引号()。接下来分别介绍这几种引号。
(1)单引号
单引号可以将它中间的字符还原为字面意义,实现屏蔽 Shell元字符的功能。引号里的字符串就是一个单纯的字符串,没有任何含义。例如,定义变量 NUM=100, 在输出变量时需要添加\(符号,如果这个变量加上单引号输出,则直接将\)符号与变量整体作为一个字 符串输出,命令如下所示:
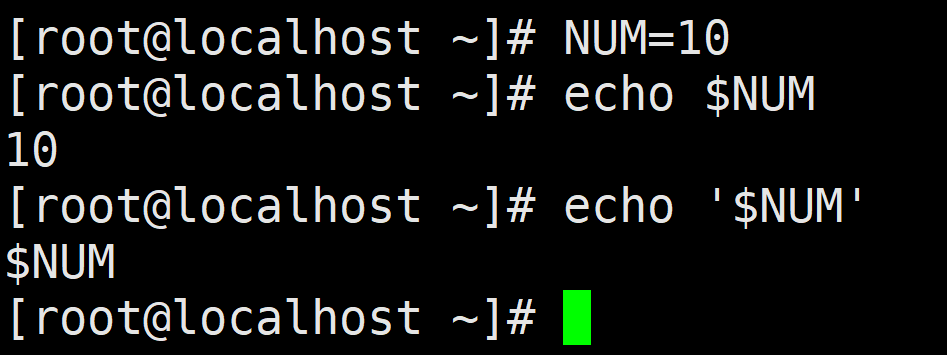
注意:不可以在两个单引号中间单独插入一个单引号,单引号必须要成对出现。
(2)双引号
双引号也具有屏蔽作用,但它不会屏蔽$符号、\符号``符号(反引号)。将刚才定义的变量NUM 加双引号输出,具体如下所示:
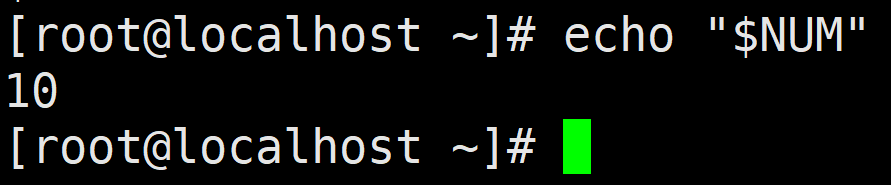
注意:双引号也可以屏蔽单引号的作用,在一对双引号中,单引号不必成对出现。
(3)反引号
反引号可以进行命令替换。反引号与双引号可以结合使用。例如,输出系统的时间,具体操作如下:

以上所示的命令中用到了命令 date,该命令的功能是打印系统当前的时间。
可以把反引号嵌入到双引号中,但是当把反引号嵌入到单引号中时,单引号会屏蔽掉反引号的功能。例如,把date嵌入单引号中,将不会打印出当前的时间。

2、通配符
Shell的通配符一般用于数据处理或文件名匹配,常用的通配符如表所示。
| 符号 | 说 明 | 符号 | 说 明 |
|---|---|---|---|
| * | 与零个或多个字符匹配 | [] | 与 中的任一字符匹配 |
| ? | 与任何单个字符匹配 | [!] | 与[]之外的任一字符匹配 |
(1)通配符“*”
如果用户想要列出/etc目录下以sys开头的所有文件,可以使用如下命令:
ls -d /etc/sys*

在以上命令中,sys* 表示匹配以字符串 sys开头的所有文件。 -d选项表示仅对目标目录本身进行处理,不递归处理目录中的文件。
如果想输出以.conf结尾的所有文件,则可以使用如下命令:
ls /etc/*.conf
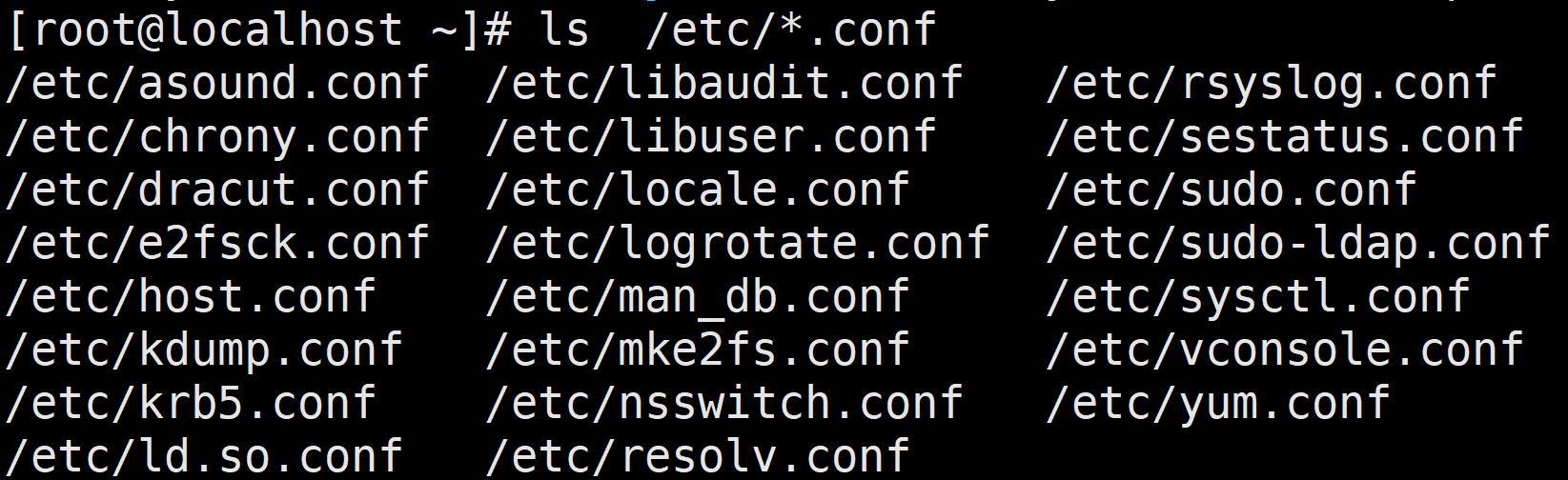
(2)通配符“?”
通配符"?"每次只能匹配一个字符,通常与其他通配符结合使用。如果想查找/etc目录 下文件名是由两个字符组成的文件,可以使用如下命令:
ls -d /etc/??

(3)通配符“[]”
通配符“[]”表示与[]中的任一字符匹配,它通常是一个范围。例如,在/etc 目录,列出 以 f~h范围的字母开头,并以.conf结尾的文件,可以使用如下命令:
ls /etc/[f-h]*.conf

(4)通配符“!”
通配符“[!]”表示除了[]里的字符,与其他任一字符匹配。例如,如果查找以 y 开头且不以.conf 结尾的文件,可以使用如下命令:
ls -d /etc/y*[!.conf]

3、连接符
Shell中提供了一组用于连接命令的符号,包括;``&&以及||,使用这些符号,可以对多条 Shell指令进行连接,使这些指令顺序或根据命令执行结果有选择地执行。下面将对这些符号的功能分别进行介绍。
(1)连接符“;”
使用“;”连接符间隔的命令,会按照先后次序依次执行。假如现在有一系列确定的操作需要执行,且这一系列操作的执行需要耗费一定时间,如安装 gdb 包时,在下载好安装包后,还需要逐个执行以下命令

且在大多数命令开始执行后,都需要一定的时间,等待命令执行完毕。若此时使用";"连接符连接这些命令,具体如下所示:

系统会自动执行这一系列命令。
又或者执行完ls -a命令后再执行ls -al命令:
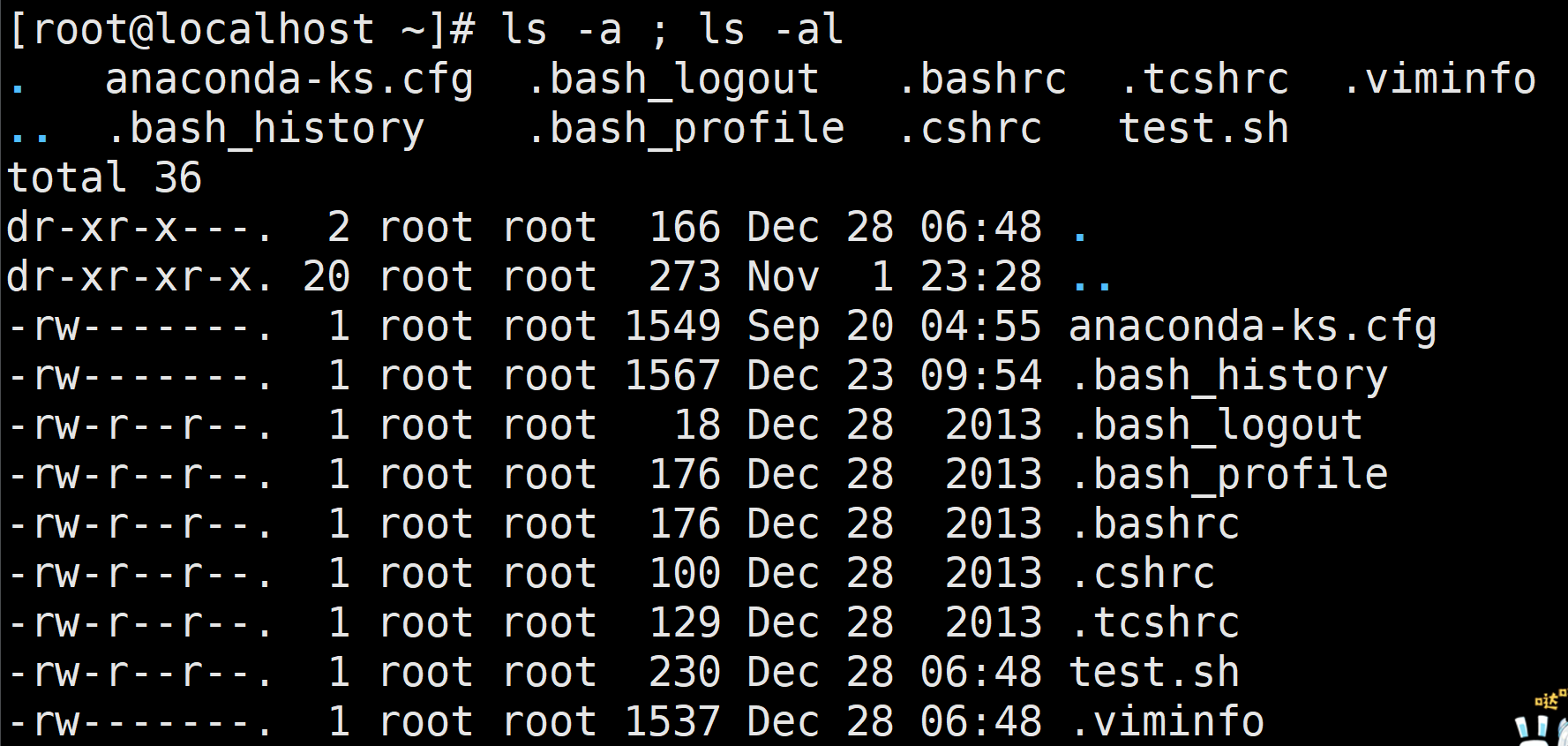
(2)连接符“&&”
使用“&& ”连接符连接的命令,其前后命令的执行遵循逻辑与关系,只有该连接符之前的命令执行成功后,它后面的命令才被执行。
(3)连接符“||”
使用“||”连接符连接的命令,其前后命令的执行遵循逻辑或关系,只有该连接符之前的命令执行失败时,他后面的命令才被执行。
十二、Shell特殊符号及正则表达式
限定符
x* # x出现0次或多次
x+ # x出现1次或多次
x? # x出现0次或1次
x{5} # x出现5次 如:\d{8}表示数字出现8次
x{2,5} # x出现2-5次
x{2,} # x出现2次及以上
或运算符
(x|y) # 匹配x或y
(xy)|(gy) # 匹配xy或gy
字符类
[abc] # 匹配a或b或c
[a-c] # 匹配a或b或c;匹配a到c的任意字符
[a-zA-Z0-9] # 匹配小写字母或者大写字母或者数字
[^0-9] # 匹配非数字字符
[]中的^表示非
元字符
\d # 匹配数字字符
\D # 匹配非数字字符
\w # 匹配单词字符(字母、数字、下划线)
\W # 匹配非单词字符
\s # 匹配空白字符(包括空格、换行符、制表符)
\S # 匹配非空白字符
. # 匹配任意一个字符(换行符除外)
\b # 标注字符的边界 \B也一样 这里的字符指的是字母、数字、下划线和汉字
vvv vv vv# jdf@ @ @ ___ - - _231233 00.
^ # 匹配行首
$ # 匹配行尾
如^abc表示行首为abc的,\d{8}$表示行尾为8个数字的
当需要匹配.^*+?之类的字符时,可用\来转义
贪婪匹配、懒惰匹配
.+ # 贪婪匹配任意字符(换行符除外)
.+? # 懒惰匹配任意字符(换行符除外)
如:<.+>和<.+?>
<啦啦啦啦啦<,
十三、 sed和awk文本处理工具
1、sed
(1)追加文本
在poem 文件中的“For rain"后追加新的文本"add a new line!!!”
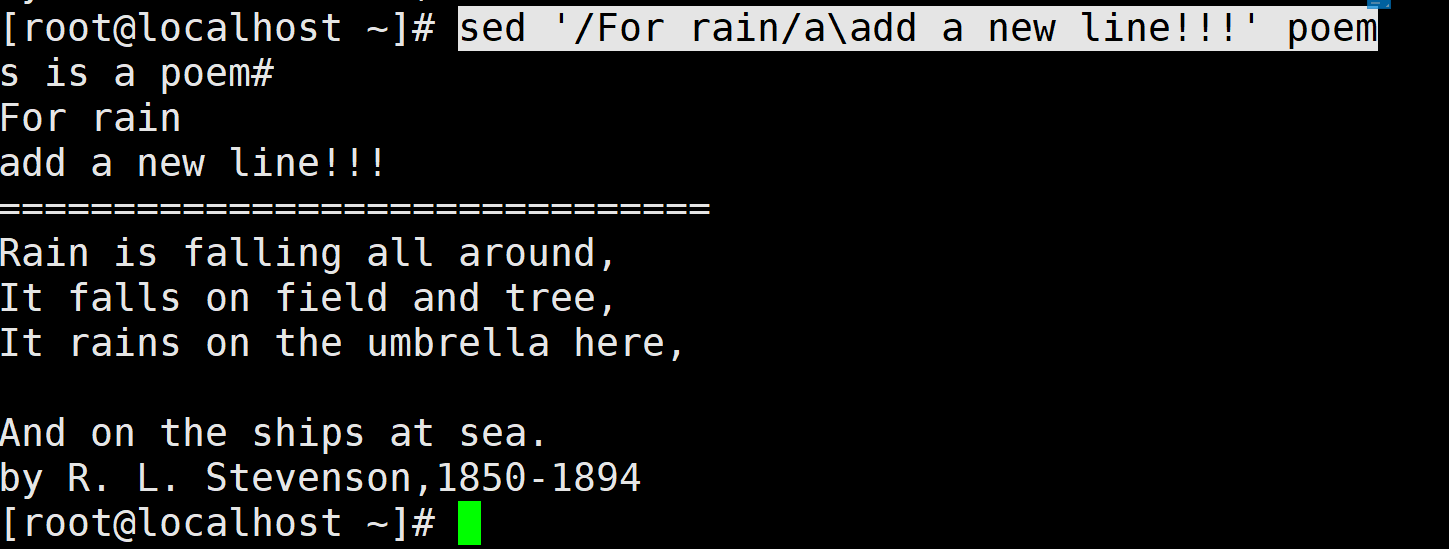
由输出结果可以看出,追加成功。同样,也可以用脚本来实现文本的追加,编写脚本add.sh,内容如下所示:
/For rain/a\
we add a new line!!!
/==/a\
add anothernew line!!!
脚本add.sh 中使用编辑命令 a\实现追加。如果追加的文本有多行,可以使用反斜杠 “\”完成换行。脚本编写完成后,在命令行使用 sed命令调用脚本,方可完成追加。
sed -f add.sh poem
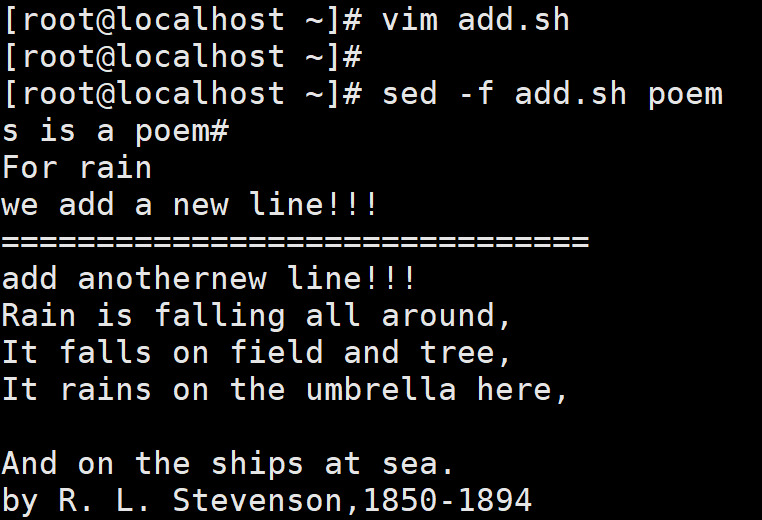
(3)删除文本
使用编辑命令d实现。
sed '/For rain/d' poem
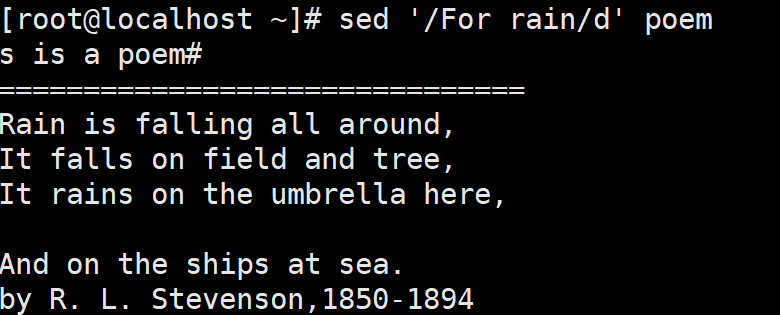
2、awk
例1:用关系表达式作为 awk 命令的匹配模式,筛选出第一科成绩大于80分的同学
awk '$2>80 {print}' scores
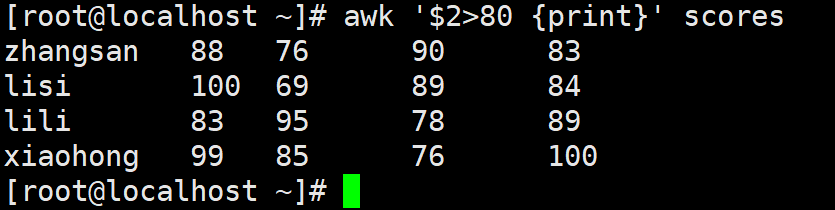
例2:使用正则表达式匹配首字符为 x 的行
awk '/^x/ {print}' scores
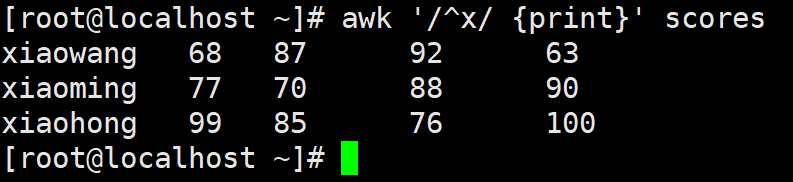
例2.1:匹配以zhang开头或li开头的文本行
awk '/^(zhang|li)/ {print}' scores
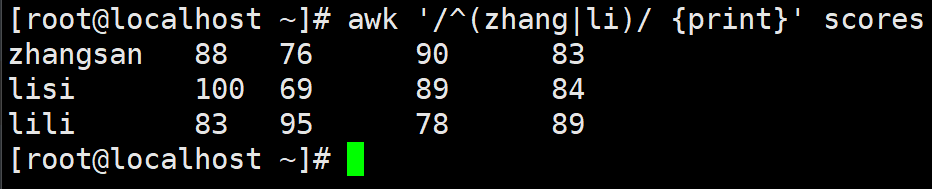
例3:在文件 scores 中查找开头为 li 且第二列的值大于80 的文本行
awk '/^li/ && $2>80 {print}' scores

例4:使用区间模式匹配一段连续的文本行
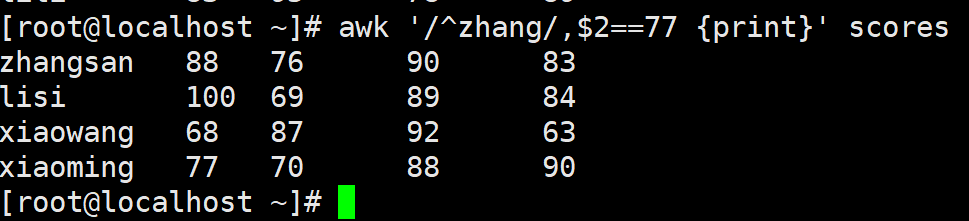
awk '/^zhang/,$2==77 {print}' scores
十四、Shell编程
编写计算1到100的和的脚本程序
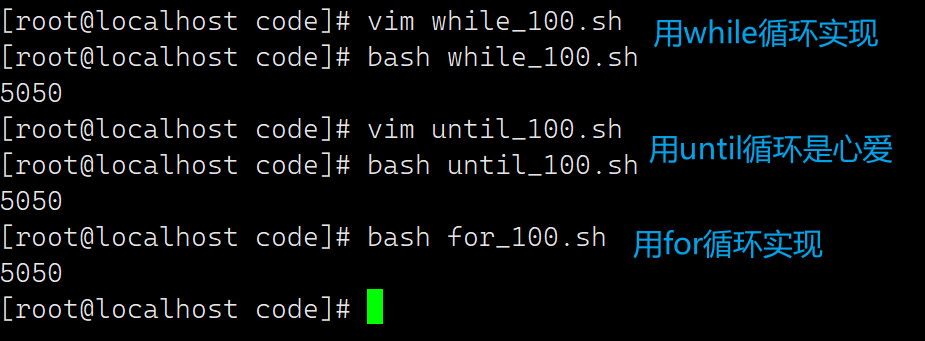
1、使用for循环
#!/bin/bash
sum=0 # 初始化sum
for i in {1..100} # i从1遍历到100
do
let sum=sum+i
done
echo $sum # 输出sum
2、使用while循环
#!/bin/bash
sum=0
i=1
while (($i<=100)) # i>100时结束循环
do
let sum=sum+i
let i++
done
echo $sum
3、使用until循环
#!/bin/bash
sum=0
i=1
until (($i>100)) # i>100时结束循环
do
let sum=sum+i
let i++
done
echo $sum
计算任意数的累加和(从键盘获取)
#!/bin/bash
echo "请输入一个整数:"
read n
sum=0
while (($n>=1)) # n<1时结束循环
do
let sum=sum+n
let n-- # n自减
done
echo $sum
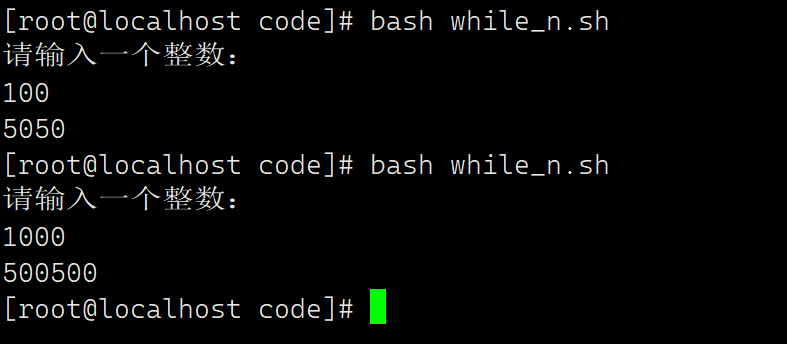
十五、DHCP
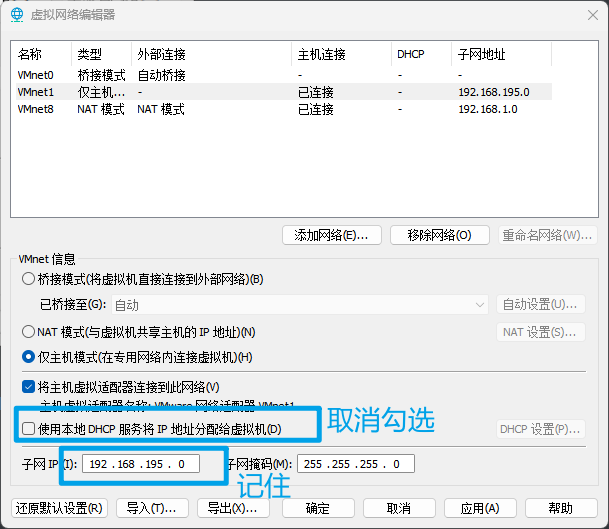
1、在vmware中,编辑->虚拟网络编辑器
选择仅主机模式下,取消勾选DHCP。点击确定。
2、准备两台虚拟机,
一台是Linux作为DHCP服务器,另一台windows或Linux作为客户机去验证DHCP服务器能否正常工作。(这里选择windows作为客户机)
将windows的网络适配器也设置为仅主机模式。
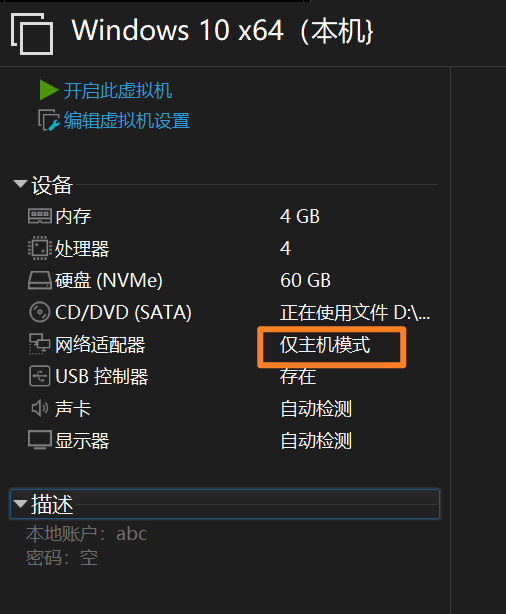
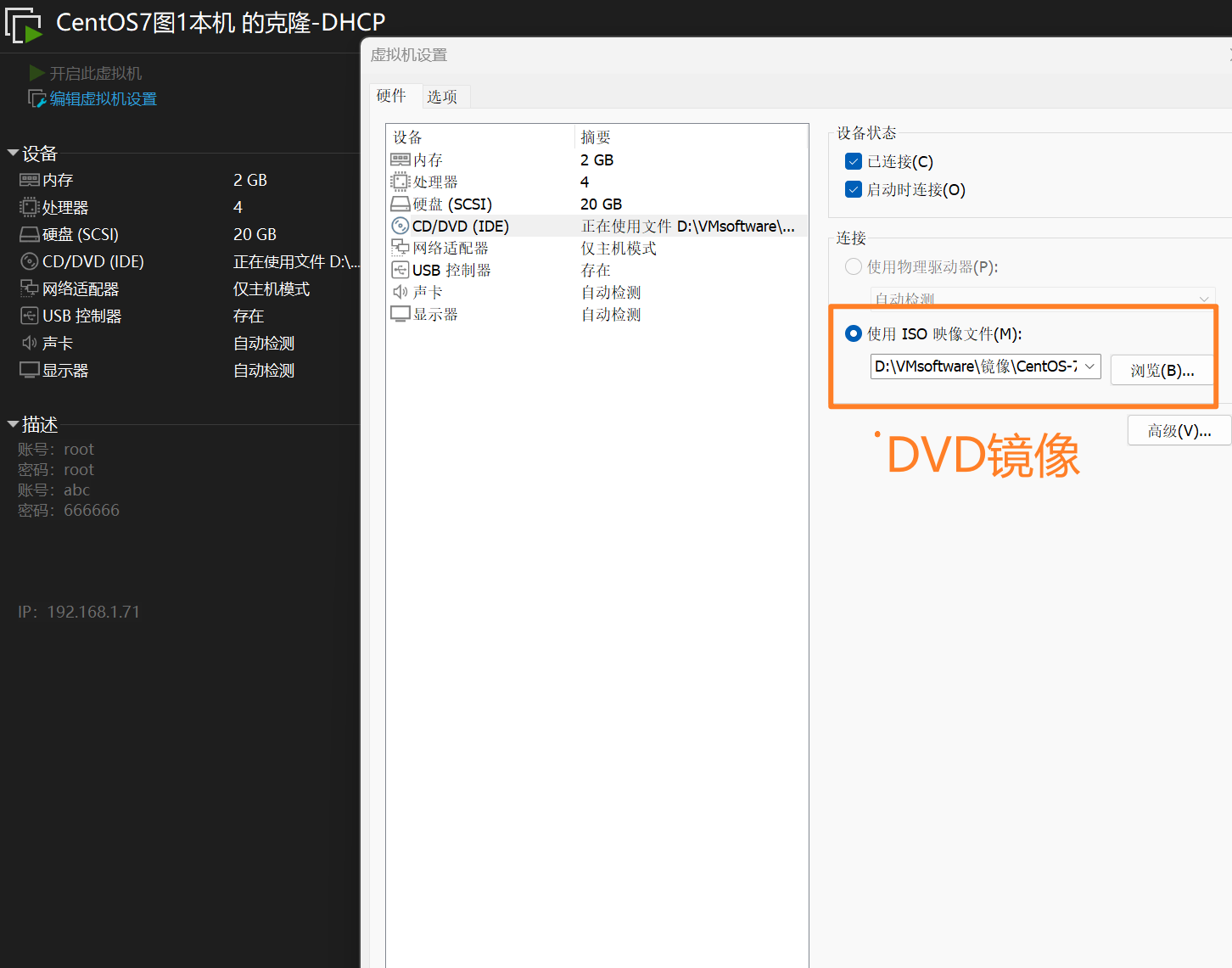
3、将Linux的DVD镜像连接到虚拟机
将作为DHCP服务器的Linux虚拟机网络适配器设置为仅主机模式,并将Linux的DVD镜像连接到虚拟机。
4、在物理机中打开网络适配器
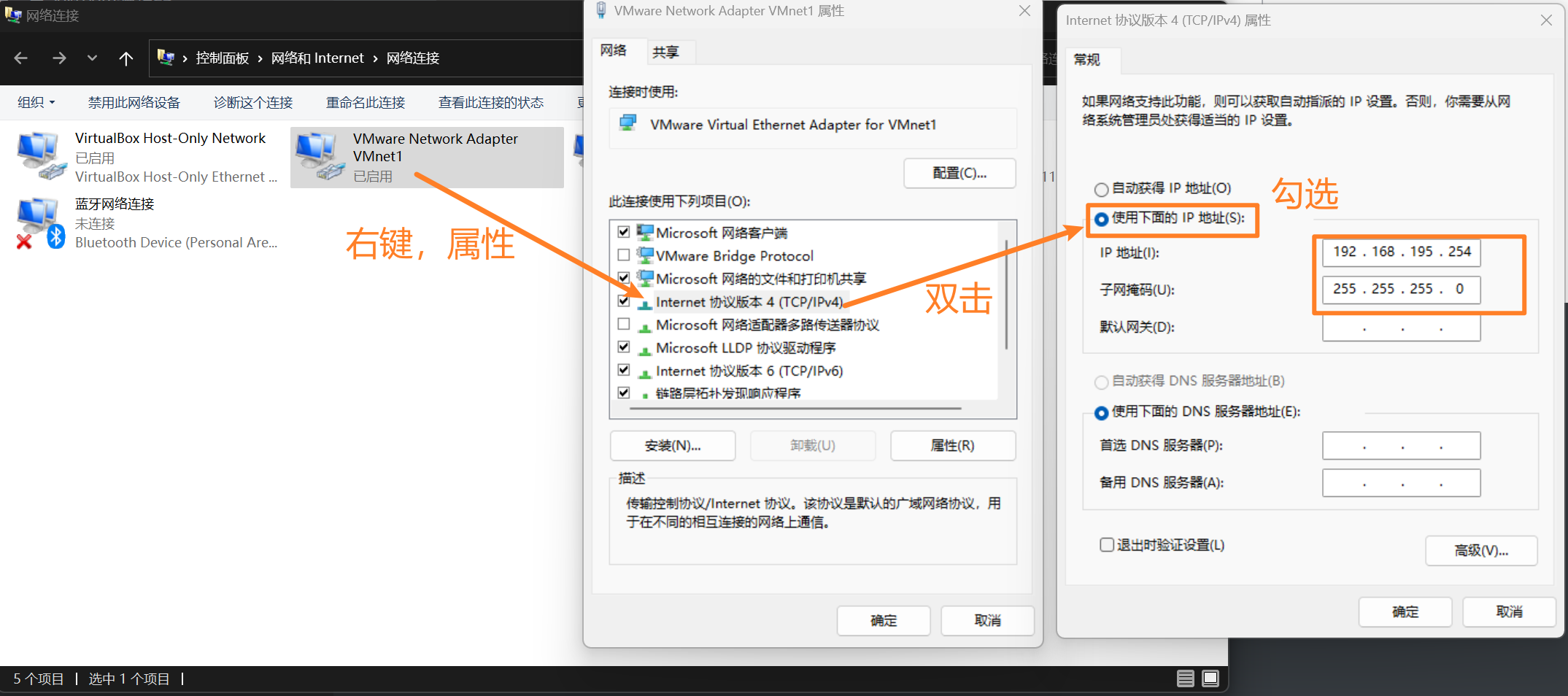
这里的IP地址是作为仅主机模式的虚拟机的网关来使用的(经过实验,其实并不一定是虚拟机的网关。这个IP的作用是,当虚拟机和物理机之间互相通信时,就是通过这个虚拟网卡的这个IP来进行通信的)。
配置完成后点击确定。最好再禁用再启用一下。
5、配置DHCP服务器为静态IP
虚拟机IP地址要在“虚拟网络编辑器”那里的子网的范围中。
查看虚拟机网络编辑器中的仅主机模式的子网
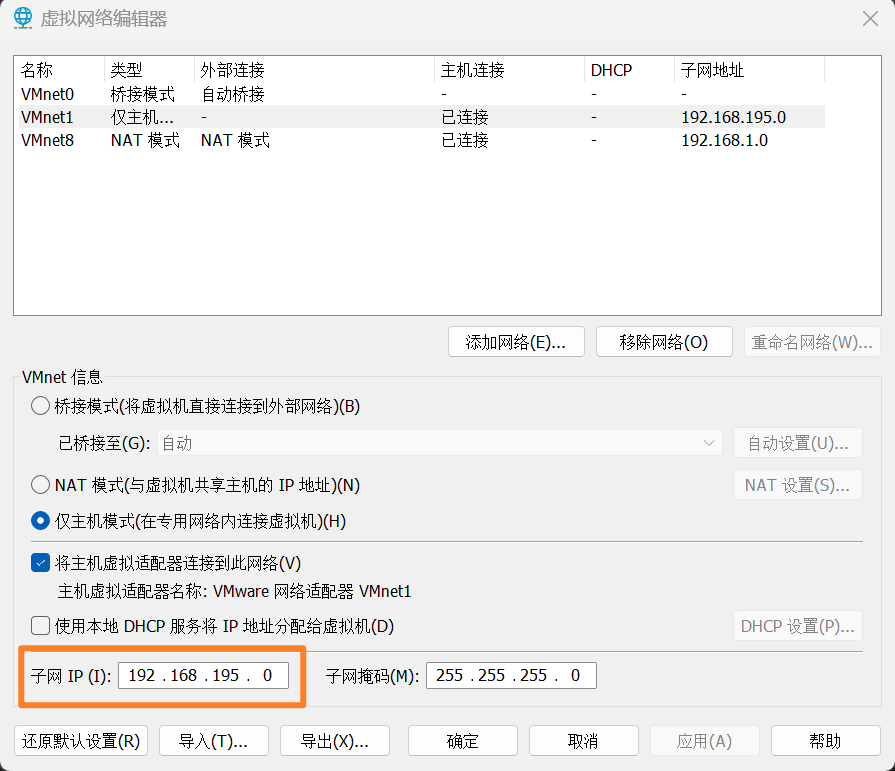
这的子网为192.168.195.0,掩码是255.255.255.0,所以仅主机模式下的虚拟机可以使用的IP地址是192.168.195.1到192.168.195.254。
图形化:
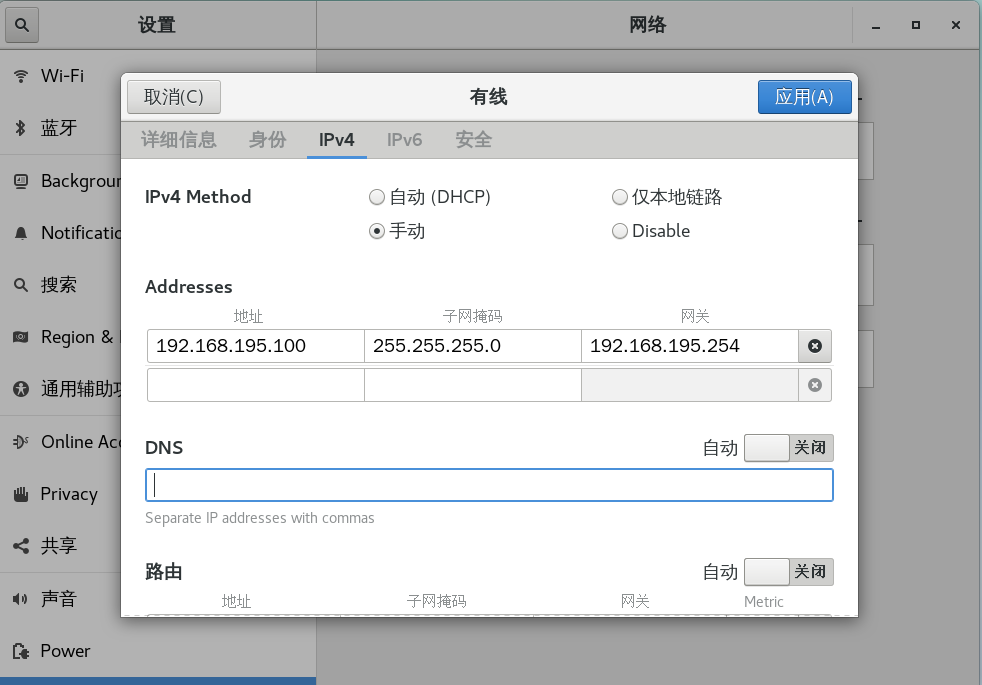
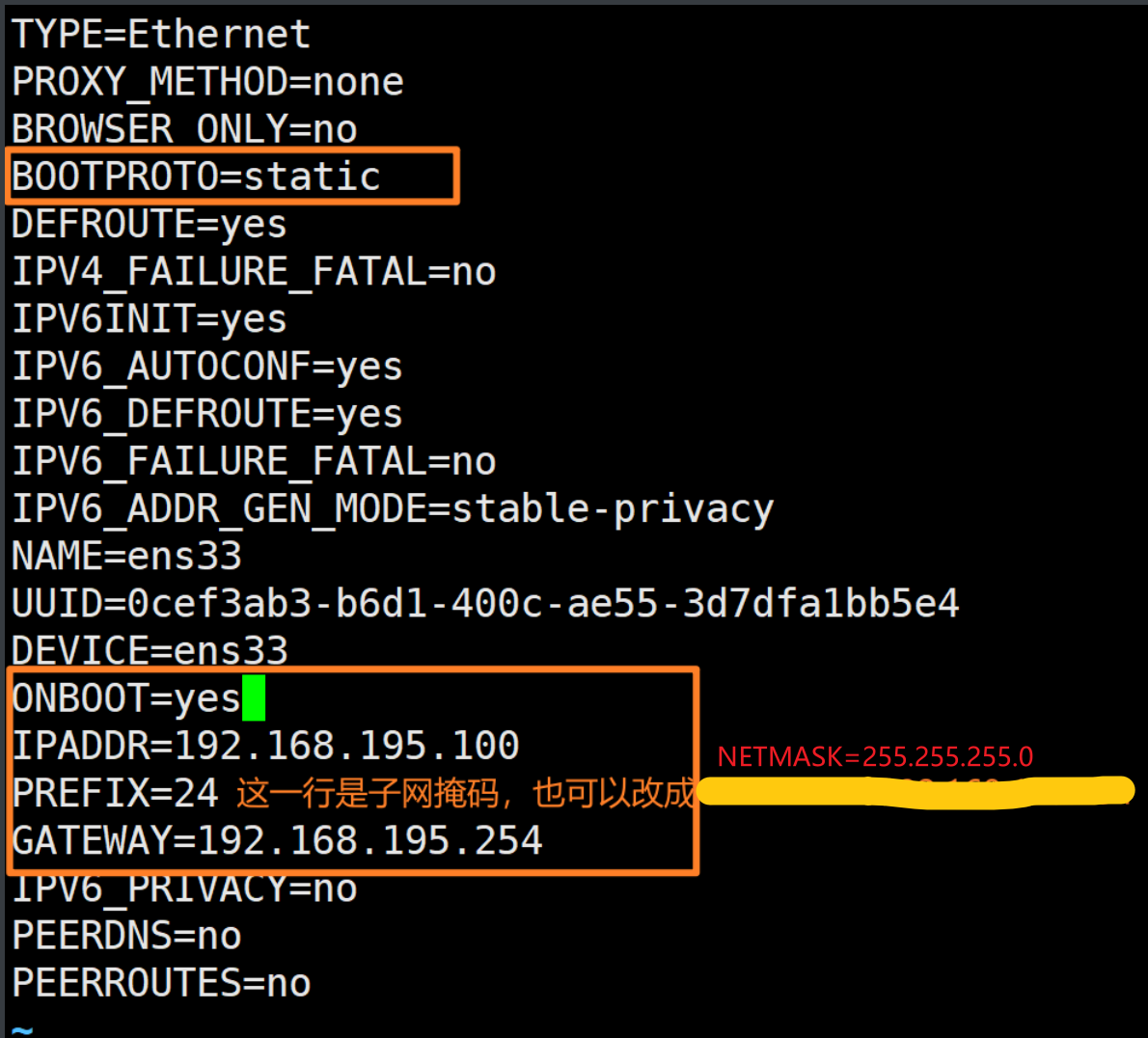
字符界面:
# 修改配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
6、挂载DVD光盘,安装DHCP
在DHCP服务器中,
使用cat查看/etc/yum.repos.d/CentOS-Media.repo文件的内容,
[c7-media]
name=CentOS-$releasever - Media
baseurl=file:///media/CentOS/
file:///media/cdrom/
file:///media/cdrecorder/
选择baseurl后面的三个路径中的一个,将DVD镜像文件挂载到目录上。(这里选择cdrom目录
使用ls命令查看cdrom目录是否存在。ls /media/

不存在,则使用mkdir命令创建目录。mkdir /media/cdrom

使用mount命令将镜像文件挂载。mount /dev/cdrom /media/cdrom/

使用安装命令yum --disablerepo=* --enablerepo=c7-media [command]进行安装dhcp。
yum --disablerepo=\* --enablerepo=c7-media install dhcp
两台虚拟机都安装不了。。。一个是找不到软件包,一个是安装过程中出现问题,用的镜像都是同一个,而且都成功挂载了。
使用在线方式安装,重新该一下网络配置。。。。
7、修改dhcp配置文件
使用cat查看/etc/dhcp/dhcpd.conf配置文件,内容如下:
#
# DHCP Server Configuration file.
# see /usr/share/doc/dhcp*/dhcpd.conf.example
# see dhcpd.conf(5) man page
#
根据配置文件内容的提示,查看示例文件。cat /usr/share/doc/dhcp*/dhcpd.conf.example
随便找一段以subnet开头的内容,复制
subnet 10.254.239.32 netmask 255.255.255.224 {
range dynamic-bootp 10.254.239.40 10.254.239.60;
option broadcast-address 10.254.239.31;
option routers rtr-239-32-1.example.org;
}
打开/etc/dhcp/dhcpd.conf配置文件,将复制的内容粘贴到里面,并进行一些修改。
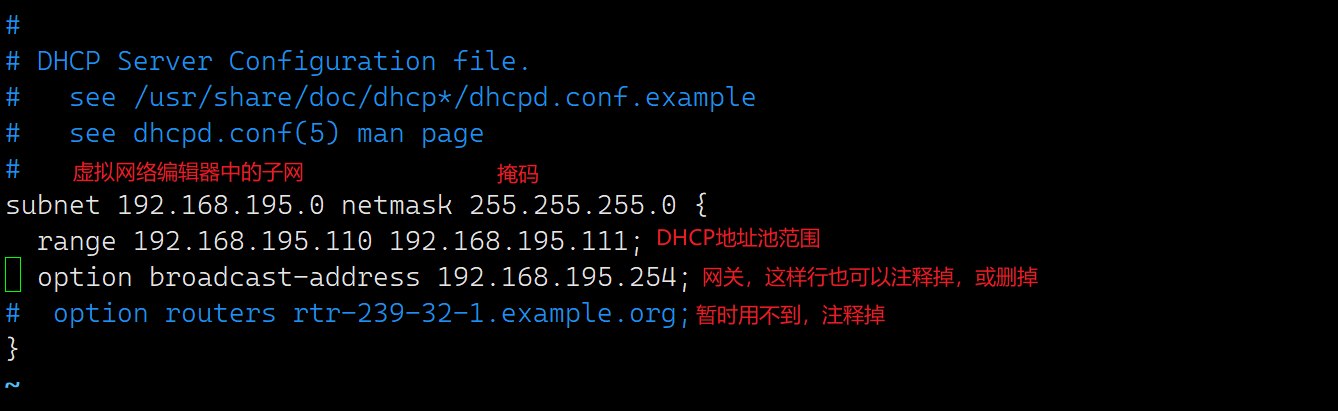
修改完成后重启dhcp服务
systemctl restart dhcpd
8、使用客户机检验dhcp服务器能否正常工作
在windows虚拟机中,打开网络适配器,进行如下配置。
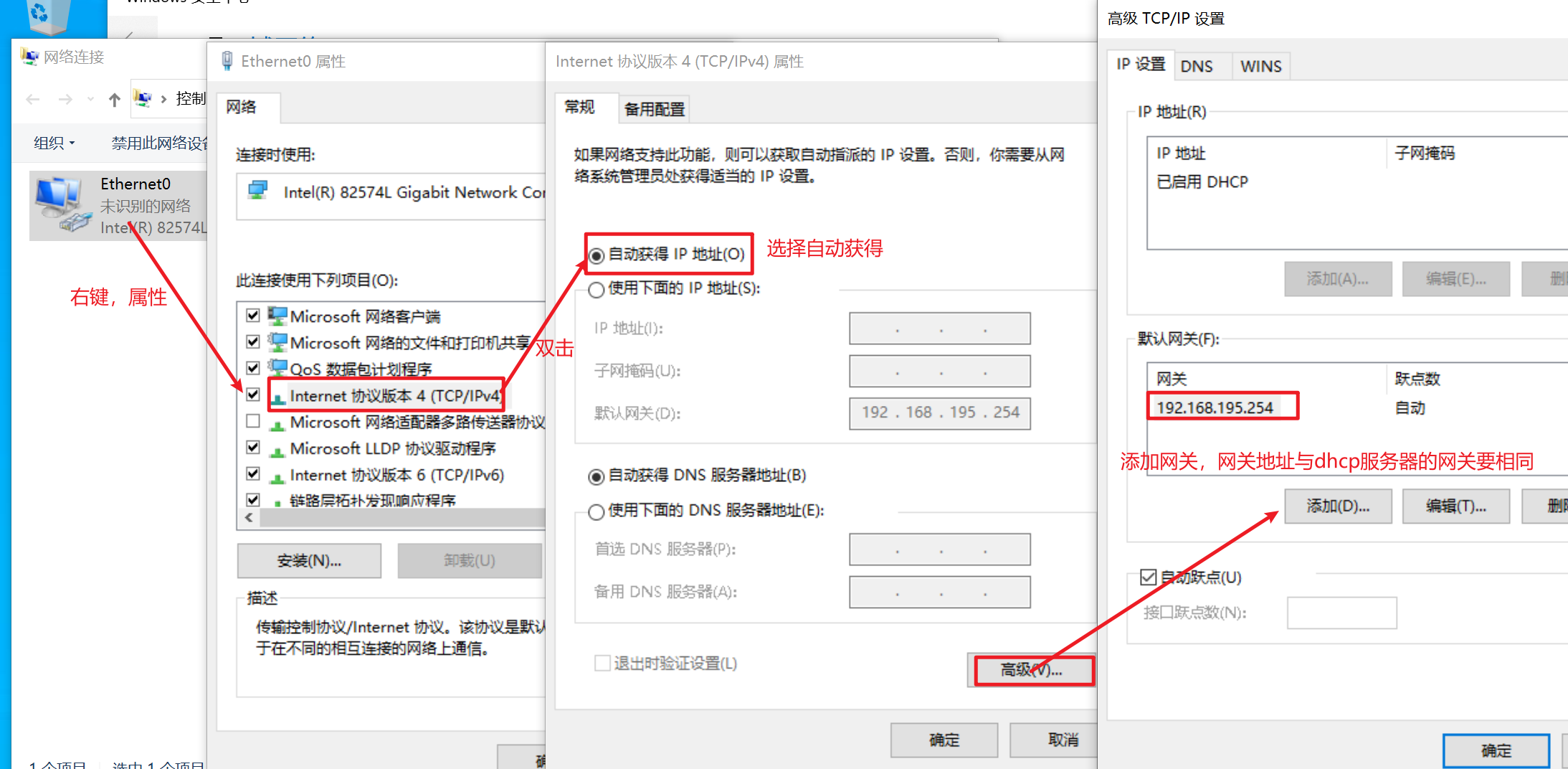
配置完成后,点击确定。然后右键禁用Ethernet0,再右键启用。
虚拟机中打开cmd命令行,使用ipconfig命令查看ip地址,是否自动获取了。
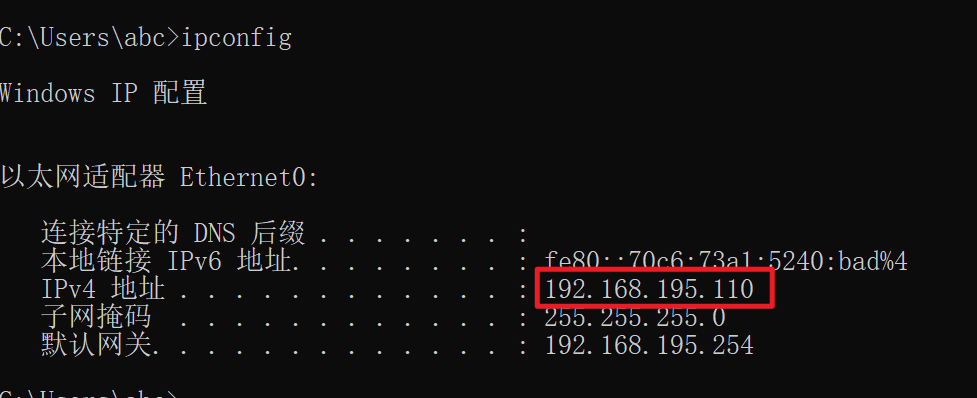
自动获取了IP地址,192.168.195.110,实验成功!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号