数据采集技术第六次作业
作业①
1)要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
代码部分
from bs4 import BeautifulSoup
import threading
import re
import requests
import urllib.request
import pymysql
def get_html(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = res.text
prase(html)
def prase(html):
urls = []
soup = BeautifulSoup(html, "html.parser")
movies = soup.find('ol')
movies = movies.find_all('li')
for i in movies:
try:
# 将mNo转换成string类型
id = i.em.string
# 电影名
name = i.find('span').text
# 导演、主演、上映年份、国家、类型等信息存在于同一子节点中
info = i.find('p').text
director = re.findall(r'导演: (.*?) ', info)
main = re.findall(r'主演: (.*?) ', info)
array = re.findall(r'\d+.+', info)[0].split('/')
ontime = array[0].strip()
country = array[1].strip()
filmtype = array[2].strip()
grade = i.find('span', attrs={"class": "rating_num"}).text
person_count = i.find('span', attrs={"class": "rating_num"}).next_sibling.next_sibling.next_sibling.next_sibling.text
# 引用
quote = i.find('span', attrs={"class": "inq"}).text
# 文件路径
path = str(name) + ".jpg"
cursor.execute("insert into douban(id,name,director,main,ontime,country,filmtype,grade,person_count,quote,path)"
"values( %s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(id,name,director,main,ontime,country,filmtype,grade,person_count,quote,path))
except Exception:
pass
# 查找页面内所有图片信息
images = soup.select("img")
for image in images:
try:
# 找出图片对应网址
url = image['src']
# 找出对应电影名
mName = image['alt']
if url not in urls:
T = threading.Thread(target=download, args=(mName, url))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
def download(pic_name, img):
req = urllib.request.Request(img)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/pc_6.2/" + str(pic_name) + ".jpg", "wb")
fobj.write(data)
fobj.close()
url = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36'}
# 连接数据库
con = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='********', db='mydb', charset='utf8')
cursor = con.cursor(pymysql.cursors.DictCursor)
#cursor.execute("delete from movie")
threads = []
for i in range(10):
get_html('https://movie.douban.com/top250'+'?start='+str(25*i))
for t in threads:
t.join()
# 关闭连接
con.commit()
con.close()
结果展示
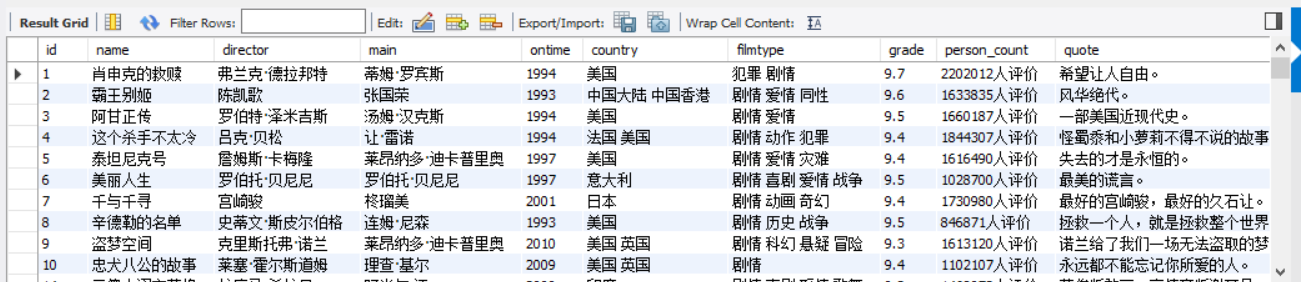
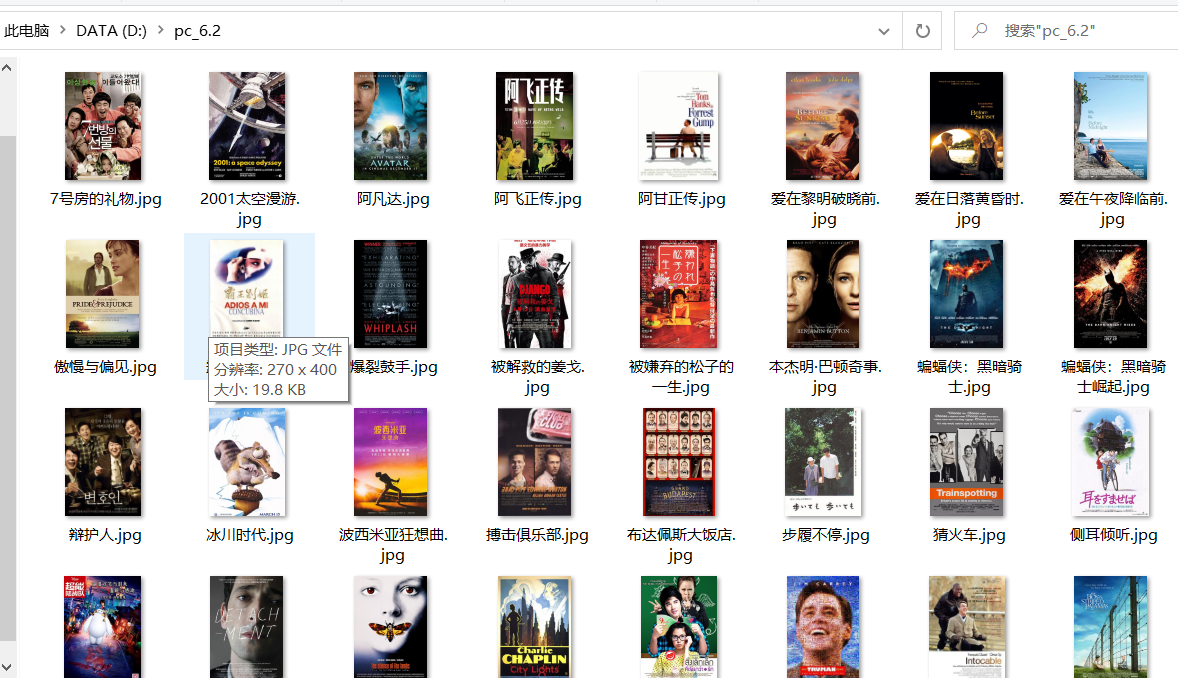
2)心得体会
本次实验用到了许久未见的Beautifulsoup和re,用惯了xpath,突然用这两个方法属实不习惯,经过本次实验我大致复习了一下之前的知识点,看来爬虫这门课还是需要反复的实践,不然马上就会手生.
作业②
1)要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
代码部分
university.py
from re import template
from bs4 import dammit
from pymysql import NULL
import scrapy
import requests
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
from ..items import UniversityItem
import os
class UniversitySpider(scrapy.Spider):
name = 'university'
# allowed_domains = ['www.baidu.com']
start_urls = ['https://www.shanghairanking.cn/rankings/bcur/2020']
def start(self):
url = self.start_urls[0]
yield scrapy.Request(url = url,callback = self.parse)
def parse(self, response):
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text = data)
tr_list = selector.xpath('//table[@class="rk-table"]/tbody/tr')
# print(len(tr_list))
for tr in tr_list:
sNo = tr.xpath('./td[1]/text()').extract_first().strip()
name = tr.xpath('./td[2]/a/text()').extract_first().strip()
city = tr.xpath('./td[3]/text()').extract_first().strip()
url = tr.xpath('./td[2]/a/@href').extract_first()
url = 'https://www.shanghairanking.cn' + url
# 剩下的属性要进入详情页来进行爬取
response = requests.get(url= url)
response.encoding = response.apparent_encoding
page_text = response.text
selector = scrapy.Selector(text = page_text)
# 接下来爬取详情页的数据
surl = selector.xpath('//div[@class="info-container"]//div[@class="univ-website"]/a/text()').extract_first()
info = selector.xpath('//div[@class="univ-introduce"]/p/text()').extract_first()
mFile = str(sNo) + '.jpg'
#print(sNo,name,city,surl,info,mFile)
img_url = selector.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
img_data = requests.get(url= img_url).content
#存储图片到文件夹中
fp = open('D:/pc6.2/'+str(sNo) + '.jpg',"wb")
fp.write(img_data)
fp.close()
item = UniversityItem()
item["sNo"] = sNo
item["name"] = name
item["city"] = city
item["surl"] = surl
item["info"] = info
item["mFile"] = mFile
yield item
items.py
class UniversityItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
sNo = scrapy.Field()
name = scrapy.Field()
city = scrapy.Field()
surl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
settings.py
BOT_NAME = 'University'
SPIDER_MODULES = ['University.spiders']
NEWSPIDER_MODULE = 'University.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'University (+http://www.yourdomain.com)'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre' #UA伪装
ITEM_PIPELINES = {
'University.pipelines.UniversityPipeline': 300,
}
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class UniversityPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="********",db="mydb",charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("detele from books")
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def process_item(self, item, spider):
try:
print(item['sNo'])
print(item['name'])
print(item['city'])
print(item['surl'])
print(item['info'])
print(item['mFile'])
if self.opened:
self.cursor.execute(
"insert into university (sNo,name,city,surl,info,mFile) values(%s,%s,%s,%s,%s,%s)",
(item['sNo'], item['name'], item['city'], item['surl'], item['info'], item['mFile']))
self.count+=1
except Exception as err:
print('err')
return item
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取",self.count-1,"条记录")
结果展示

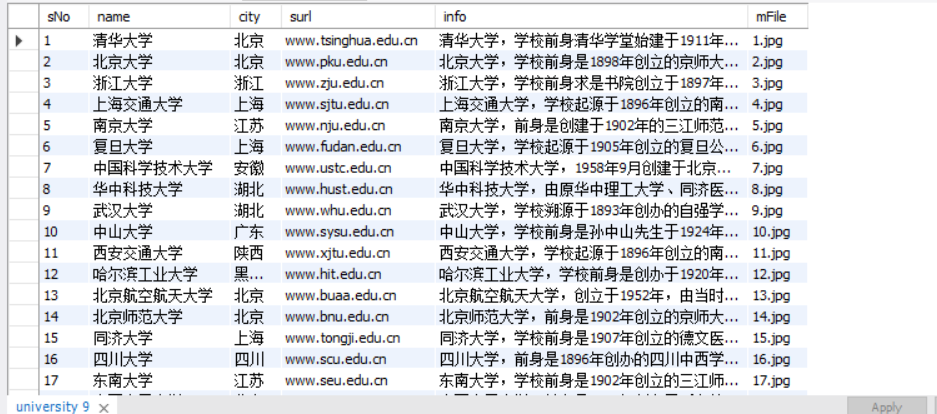

2)心得体会
本次实验再次使用了scrapy框架,太久没用了,感觉步骤很繁琐,操作起来有点不习惯。然后自己也踩到了坑,好像在settings.py中没有添加UA伪装的话就无法爬取到想要的信息,但是所需要的图片又爬取到了,这个有点疑惑。。。加了UA之后,是可以爬取到自己想要的信息,因为部分学校是没有简介信息的,所以在爬取过程中检索不到该属性就抛出了异常,数据库中的数据就没有原本该有的量。这点应该可以再爬取中加一些判断、异常处理来解决。(在浩大将军的指点下才恍然大悟,不得不感慨和浩大将军相比,我还是太弱了)
作业③,
1)要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
代码部分
from time import daylight, sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import datetime
import time
from selenium.webdriver.common.keys import Keys
from lxml import etree
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
count = 1
def startUp(self,url):
# # Initializing Chrome browser
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host = "127.0.0.1",port = 3306,user = "root",passwd = "chu836083241",db = "mydb",charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("delete from stock") #如果表已经存在就删掉
self.opened = True
self.page_num = 1
except Exception as err:
print("连接数据库失败")
self.opened = False
self.driver.get(url)
#这里的search框用id属性显示定位不到
#1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)
#2.找到它老爸后,再找下个层级就能定位到了
#3.要是它老爸的属性也不是很明显
#4.就再往上定位
time.sleep(2)
accession = self.driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
# print(accession)
# time.sleep(3)
accession.click()
time.sleep(3)
#其它登入方式
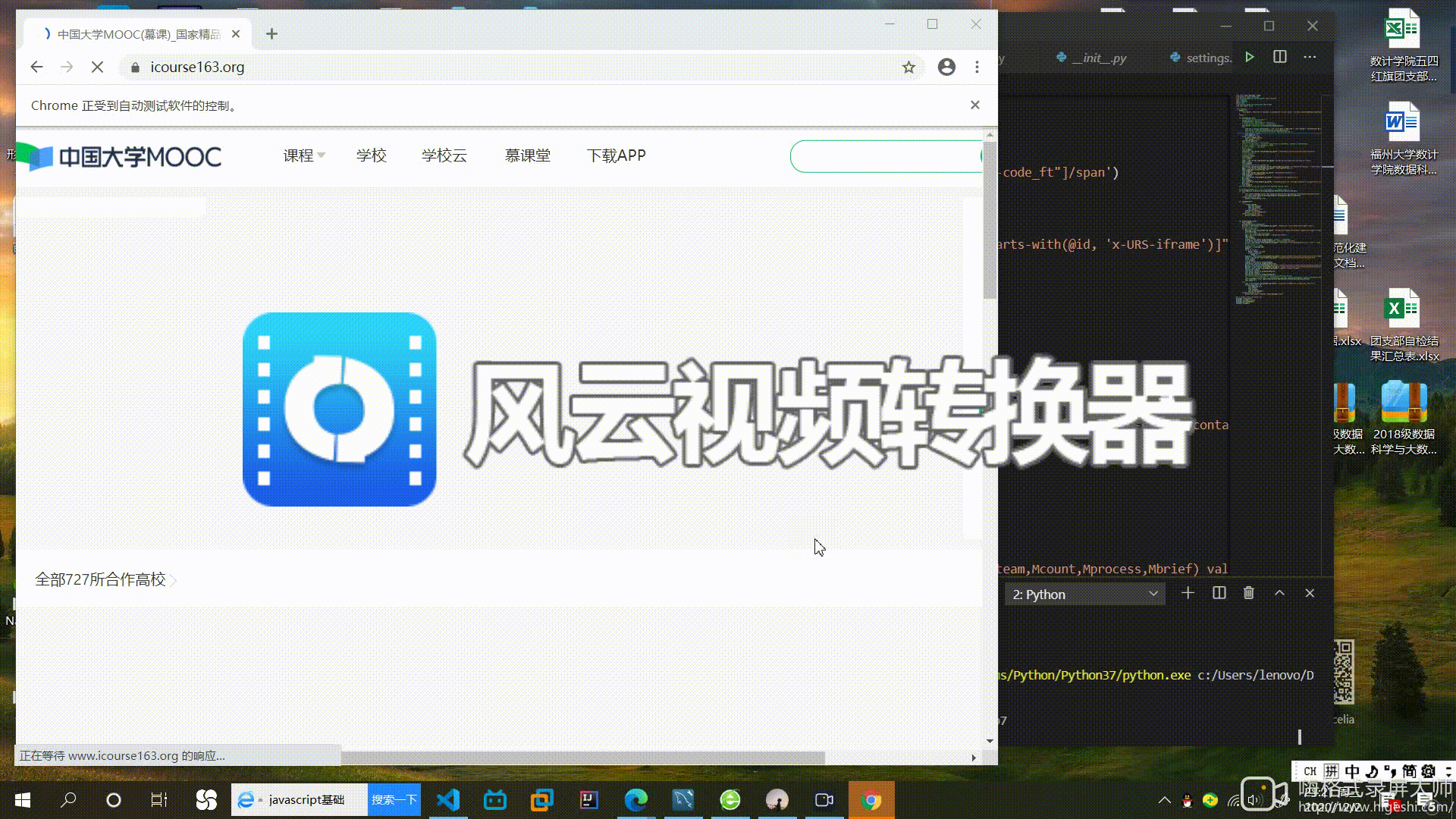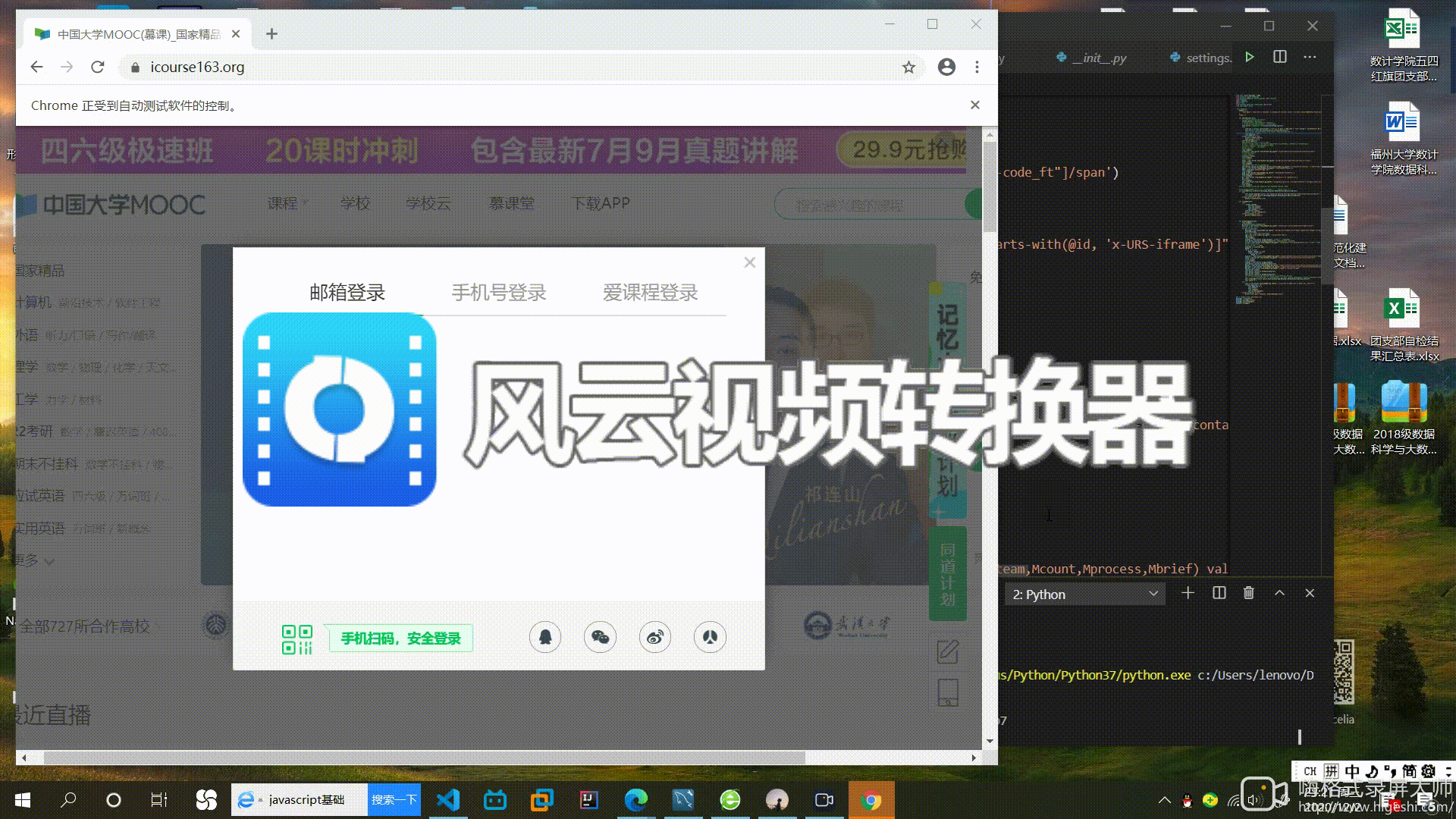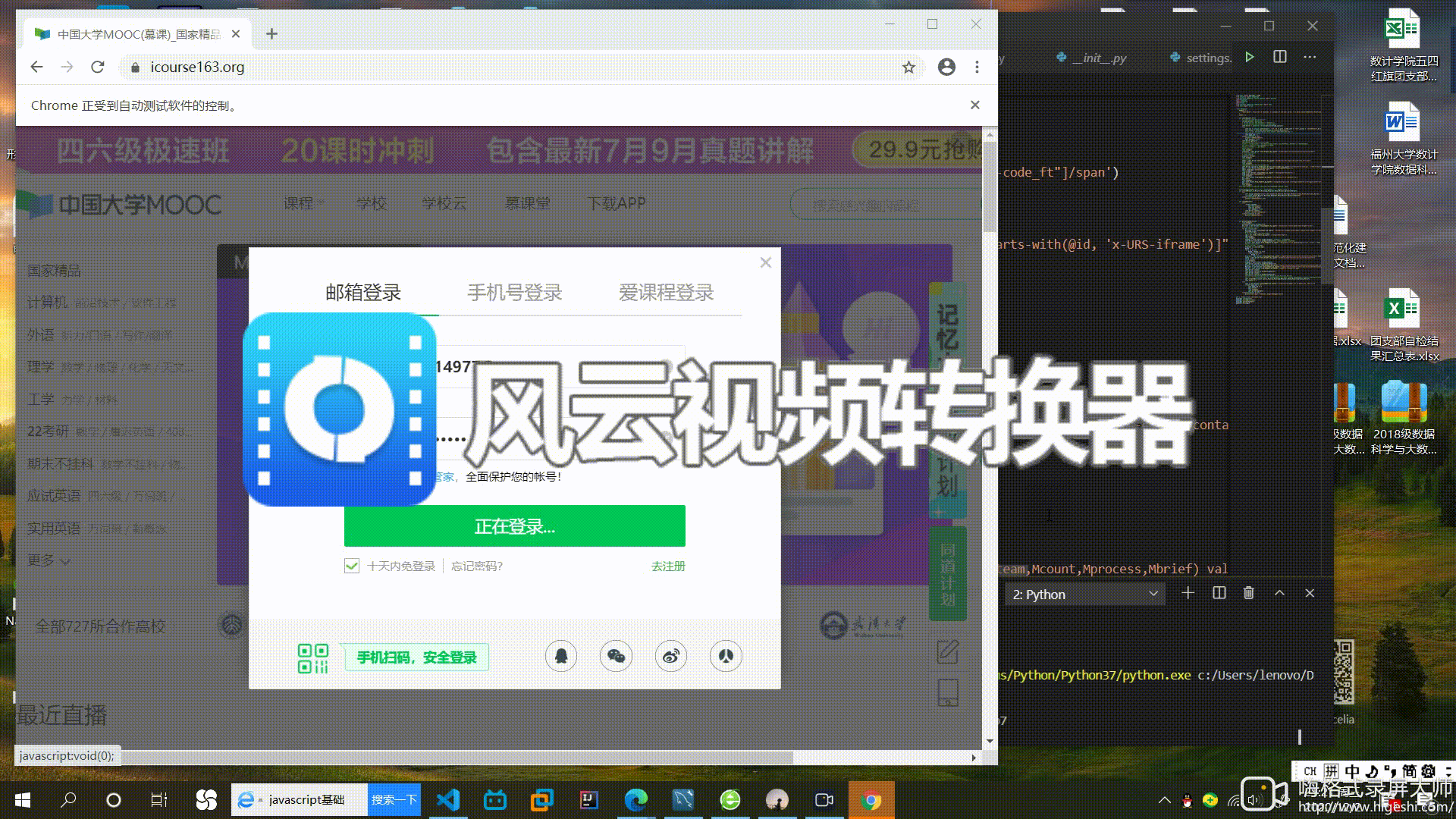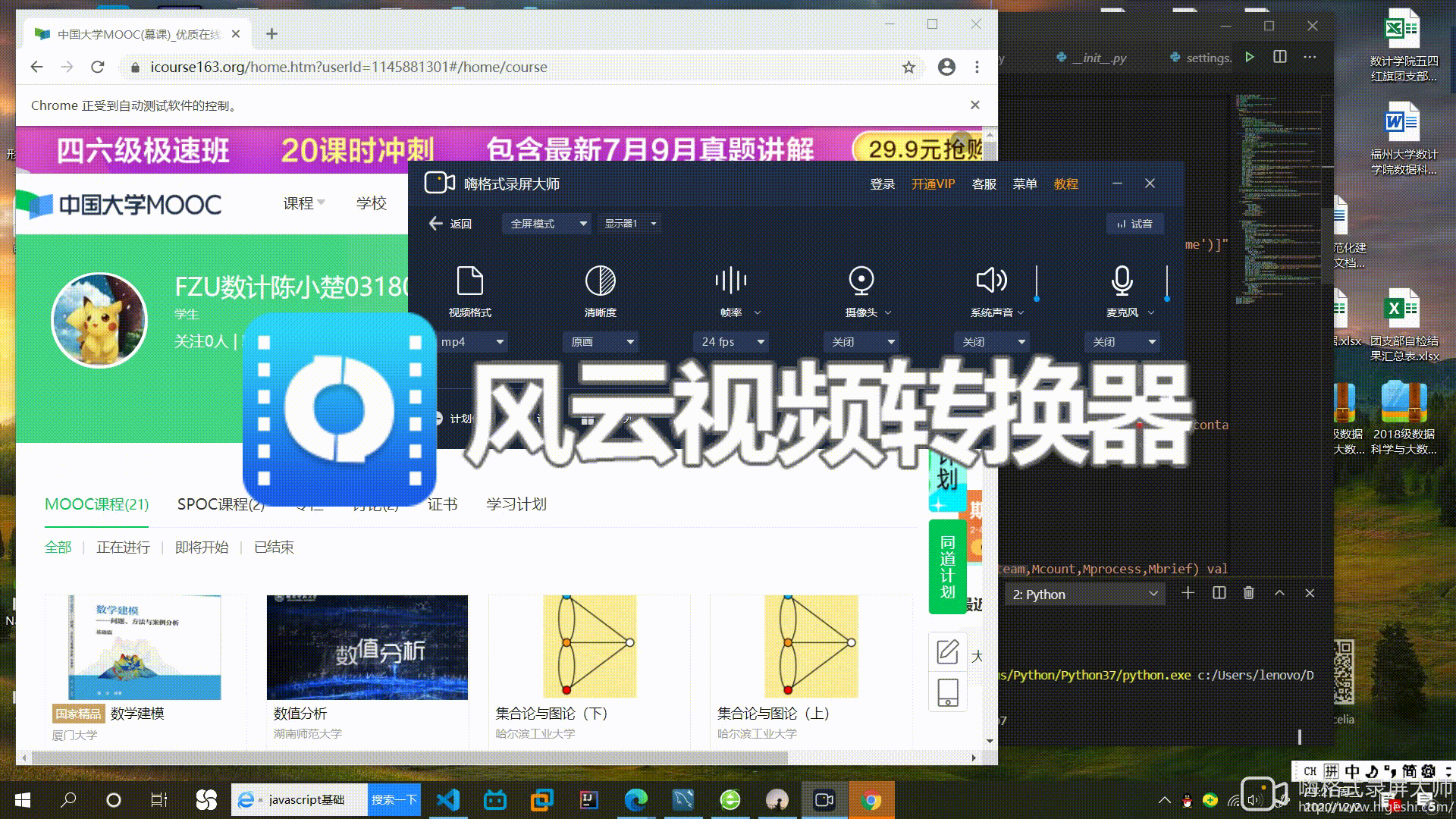
other = self.driver.find_element_by_xpath('//div[@class="ux-login-set-scan-code_ft"]/span')
other.click()
time.sleep(5)
#先切换到iframe,这里我选择邮箱登入
self.driver.switch_to.frame(self.driver.find_element_by_xpath("//iframe[starts-with(@id, 'x-URS-iframe')]"))
email = self.driver.find_element_by_xpath('//input[@name="email"]')
email.send_keys('2105114977@qq.com')
time.sleep(2)
pswd = self.driver.find_element_by_xpath('//input[@name="password"]')
pswd.send_keys('chu836083241')
time.sleep(2)
go = self.driver.find_element_by_xpath('//div[@class="f-cb loginbox"]/a')
go.click()
time.sleep(5)
me = self.driver.find_element_by_xpath('//div[@class="ga-click u-navLogin-myCourse u-navLogin-center-container"]/a/span')
me.click()
time.sleep(3)
#startUp函数已经包括了登入进入到个人中心,接下来就是数据的爬取了
#插入函数没有把数量值+1,所以执行完该函数要再执行一句self.count += 1
def insertDB(self,id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief):
try:
self.cursor.execute("insert into mymooc(id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief) values (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief))
except Exception as err:
print("插入数据失败!",err)
def closeUp(self):
try:
if(self.opened):
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("爬取完毕,关闭数据库")
except Exception as err:
print("关闭数据库失败")
def processSpider(self):
time.sleep(2)
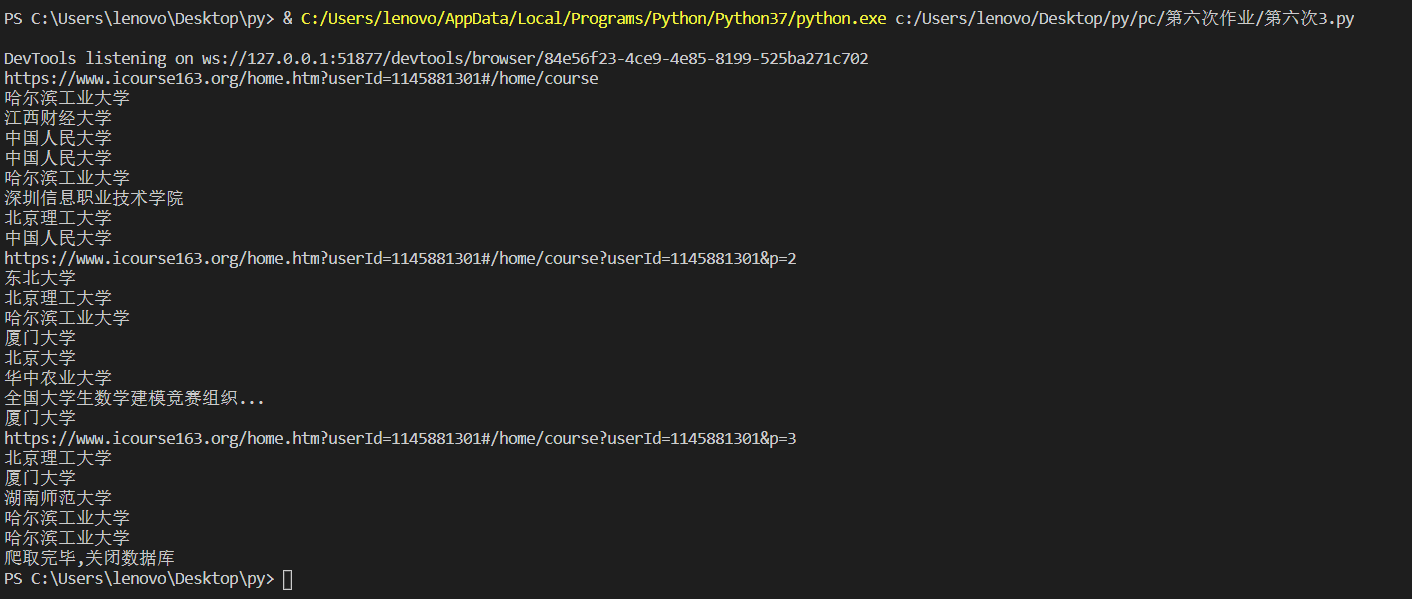
print(self.driver.current_url)
div_list = self.driver.find_elements_by_xpath('//div[@class="course-panel-body-wrapper"]/div')
# print(len(div_list))
for div in div_list:
Mcollege = div.find_element_by_xpath('.//div[@class="common-info-wrapper common-info-wrapper-fix-height"]//div[@class="school"]/a').text
print(Mcollege)
# 通过点击图片来实现进入到详情页
img = div.find_element_by_xpath('.//div[@class="img"]')
img.click()
time.sleep(2)
windows = self.driver.window_handles #获取当前所有页面句柄
self.driver.switch_to.window(windows[1]) #切换到刚刚点击的新页面
a_list = self.driver.find_elements_by_xpath('//h5[@class="f-fc6 padding-top-5"]/a') #获取a标签列表
#print(len(a_list))
#爬取主讲老师和授课团队
Mteacher = a_list[0].text
Mteam = ""
for a in a_list:
Mteam = Mteam + a.text
if(a!=a_list[-1]):
Mteam += " "
Mcourse = self.driver.find_element_by_xpath('//*[@id="g-body"]/div[3]/div/div[1]/div/a[1]/h4').text
title = self.driver.find_element_by_xpath('//*[@id="g-body"]/div[3]/div/div[1]/div/a[1]/h4')
title.click()
time.sleep(2)
windows = self.driver.window_handles
self.driver.switch_to.window(windows[-1])
Mcount = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[2]/div[1]/span').text.strip().replace(' ',"")
Mprocess = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]/span[2]').text
Mbrief = self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
self.driver.close()
self.driver.switch_to.window(windows[1])
self.driver.close()
self.driver.switch_to.window(windows[0])
#print(Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
#通过观察浏览器以及控制台输出,一整页的内容我们确实可以爬取到了 接下来处理好翻页然后保存到数据库即可
self.insertDB(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
self.count += 1
try:
next = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]/a')
if(self.page_num < 3):
self.page_num += 1
next.click()
time.sleep(5)
self.processSpider()
except Exception as err:
print("已经是最后一页或已经爬取了设置的最大值3页")
url = "https://www.icourse163.org"
myspider = MySpider()
myspider.startUp(url=url)
myspider.processSpider()
myspider.closeUp()
结果展示

登入动态图
2)心得体会
这次的作业和上周的作业差不多,所以没遇到太大的困难,不同点就是登入详情页要2次点击,注意窗口的切换即可。
总结
我们的爬虫课程就此告一段落,通过这段时间的学习,自己掌握了一些爬虫的常用方法,虽然一开始感觉写博客比较麻烦,但是现在发现,通过观看班上同学的博客,总可以学习到很多新的东西,有时也让自己少走了很多弯路。这门课程虽然暂时结束了,但是我们的学习还会继续,希望回首之时,看着自己的一步步成长,也能为自己感到骄傲。

