结对编程作业
博客链接:
自己:https://www.cnblogs.com/chu-3/p/13840671.html
队友:https://www.cnblogs.com/fzucsx/p/13842779.html
自己的全部原型部分代码
队友的全部AI部分代码
分工情况:
| 姓名 | 分工 |
|---|---|
| 陈晟新 | AI,算法部分的实现,测试接口,大比拼,算法部分博客 |
| 陈小楚 | 原型设计,游戏的实现,测试代码,大比拼,原型部分博客 |
1、原型设计
1.1设计说明
本次游戏的设计是用html,css,JavaScript实现。
该网页也仅仅实现了比较简单的一些功能,用户通过点击开始按钮/暂停按钮来控制时间是否走动;可以查看历史记录以及最佳成绩。
一些原型图,因为只有一个界面,所以这个比较简单。

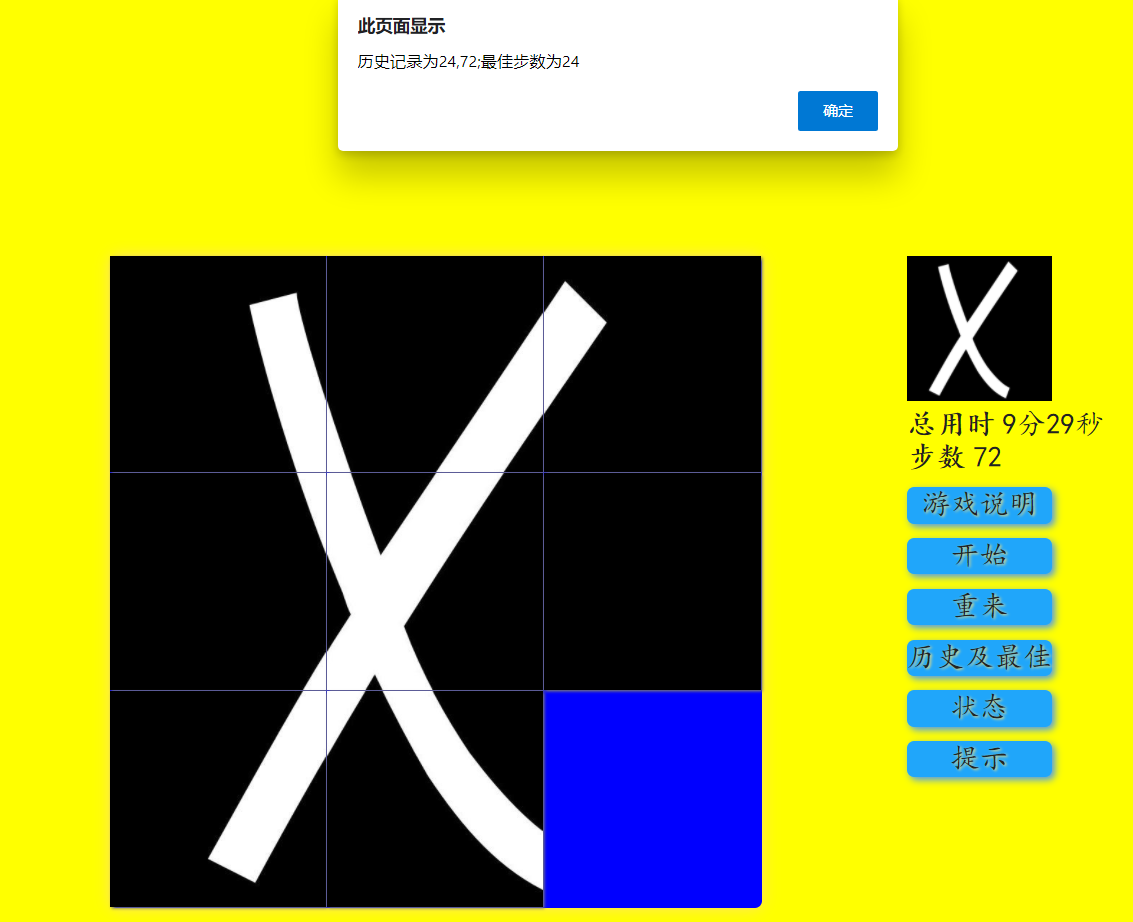

这是游戏初始的界面。

游戏完成时仅仅只是在界面上方加了一行游戏成功的提示。

1.2所采用的原型开发工具
此次我采用的是Axure Rp8,因为自己代码实力不够,只能实现简单的单一网页的界面。
Axure Rp8可以用于制作快速原型,也可以绘制中保真原型草图。
1.3结对过程

1.4遇到的困难及解决方法
1、困难:在刚刚使用原型设计工具的时候发现不太会,做了很多尝试才慢慢熟练。最后想在网页上实现一下AI内嵌让它自动求解,一开始的方向是依赖队友已经写好的答案文件,不过后来尝试读取文件一直出问题,后来想自己用js通过bfs求解,不过由于时间比较仓促,最终未能实现。
2、收获:通过本次实验,自己对网页的设计算是有了一些了解,不过还是要花更多的时间进行深入学习,感觉自己拖了队友的后腿。
2、AI与原型设计实现
2.1、代码实现思路
- 网络接口的使用
(1)获取题目
import json
def access_problem(url):
'''输入为赛题url,返回showdoc中对应格式的数据'''
teaminfo = {
"teamid": 52,
"token": "3585feb4-f430-4e99-b80d-99f952c41798"
}
req = requests.post(url, json=teaminfo)
datas = json.loads(req.text)
return datas
(2)提交答案
import json
def submit_answer(operations,free_swap):
'''
根据解出的移动序列(字符串)以及自由交换序列(列表)想指定网络接口提交答案
'''
url = "http://47.102.118.1:8089/api/challenge/submit"
postdatas = {
"uuid": uuid,
"teamid": 52,
"token": "3585feb4-f430-4e99-b80d-99f952c41798",
"answer": {
"operations": operations,
"swap": free_swap
}
}
req = requests.post(url, json=postdatas)
print(req.text)
(3)发布题目
import requests
import json
def issue_topic():
'''
利用相应网络接口发布题目
填写字段:letter,exclude,challenge,step,swap
'''
url = "http://47.102.118.1:8089/api/challenge/create"
title = {
"teamid":52 ,
"data": {
"letter": "M",
"exclude": 9,
"challenge": [
[1, 7, 3],
[0, 6, 8],
[5, 4, 2]
],
"step": 15,
"swap": [2,7]
},
"token": "3585feb4-f430-4e99-b80d-99f952c41798"
}
r = requests.post(url,json=title)
print(r.text)
- 代码组织与内部实现设计
图像识别


算法准备

算法应用

- 算法的关键及主要步骤流程图
主要步骤流程图
图像识别
图像识别采用分割图像逐一比对的方法,首先读取图像为numpy矩阵,然后利用行列索引将其均匀切割为9块图像矩阵,再用tolist方法将矩阵类型转换为列表类型。进行图像识别时,将分割后的题给图像与分割后的本地答案图像进行一一比对,由于空格必然无法比对成功,因此若两张图像有8块图像比对成功,则可判定题给图像就是该答案图像的乱序形式,将空格记为0,其他图像利用列表的index方法用其在原图中的位置进行数字编码。
算法准备
算法搭建在从答案状态逆向推出的状态-路径映射文件的基础之上,具体做法是先将图片华容道问题抽象为数字华容道问题,数字1-9表示有序状态对应的位置,0代表空格。因此,由于空格出现的位置随机,所以答案有九种可能。例如其中一种可能的答案为123456780(空格出现在第九个位置,程序中用列表来存储),我们的做法是以答案的状态也就是123456780为起点,将该状态移动一步获得123456708、123450786两种状态,这两种状态花费1步的代价就可以回到答案,我们记为第一层,然后再以第一层的每个状态为起点,推出第二层(花费2步的代价可以回到答案),其中每个层中的状态不能与之前层中的状态重复,否则要去重。于是我们可以获得由浅至深各个层的各个状态(作为字典的键key),并在由上一层退出下一层的过程中,记录当前移动位置以便使用时转化为路径序列(作为字典的值value),这样就成功构建出了答案字典对象,最后利用pickle库的序列化对象操作存储字典对象到pkl文件也就是我们的答案文件。循环1-9选取空格位置并重复以上操作,我们就成功存储了记录了所有3X3棋盘布局的走法方案的字典对象(9个pkl文件)作为后续测试以及AI大比拼的基础。
算法应用
在AI大比拼中,我们将所有题目分为三种情形讨论。
第一种情况是原图有解且可以在强制交换之前走完。根据之前的算法准备所存储的答案文件,原图有解当且仅当题给状态在答案字典的key中,且我们已经存好了状态对应的路径序列,这样就成功解决了第一种情况。
第二种情况是原图无解或者有解但是在强制交换之前无法走完,针对这种情况,我们采用类似广搜的想法,从当前状态出发走step步,得出所有走step步之后的可能状态以及对应的路径序列,然后再对每一个状态进行指定位置的强制交换,然后对有解的状态计算代价(几步可以走回答案),对无解的状态去答案字典中由低代价层向高代价层匹配,即只要该无解状态和答案字典中的有解状态有且仅有2个位置数值不一样就认为匹配,因为可以通过自由交换使其变为一样。这样可以获取走完step步所有状态的最小代价并选取其对应的状态作为我们强制交换后的出发点,这也就是我们保证算法一定能解出最短步数的关键所在。
至于第三种情况其实只是一个特判,就是step=0的情况,也就是一开始就进行强制交换,如果强制交换后有解,则查字典可以获取最短路径序列,否则跟第二种情况中的思想类似,对无解的状态去答案字典中由低代价层向高代价层匹配,用匹配到的最低代价对应的状态作为出发状态,同样查字典可得最短路径序列。
- 重要的代码片段
图像识别
def split_image(img): # 输入为图像矩阵np
'''分割图像'''
imgs = []
for i in range(0,900,300):
for j in range(0,900,300):
imgs.append(img[i:i+300,j:j+300].tolist())
return (imgs) # 返回值是九块图像矩阵的列表
上述代码是用来利用矩阵的行列索引来分割图像为九块的代码,返回值是多层的嵌套列表,之所以使用tolist方法是因为后续判断相等的时候列表类型比矩阵类型更方便操作
def encode_image(title_image,store_image):
'''图像编码为数字'''
current_table = [] # 图像对应的表数字编码
ans_type = list(range(1,10)) # 答案类型
for ls_title in title_image:
try:
pos_code = store_image.index(ls_title)+1
current_table.append(pos_code)
ans_type.remove(pos_code)
except:
current_table.append(0) # IndexError:空格匹配不到
return current_table,ans_type[0] # 返回表编码和答案类型
上述代码是在识别出图像之后将每一块分割后的图编码成数字的程序,ans_type代表答案类型,也就是空格挖去的位置,一共有1-9种答案类型,remove方法意思是排除当前有编码的数字,最后没有进行编码的1-9中的那个数字就是最后的答案类型了,至于每块图像的编码在程序中就是使用index方法了。
算法准备
def move(layer): #传入为9个数值元素编码的列表
state, way = [], []
try:
layer_type = type(layer[0])
except:
print('layer maybe empty')
return state,way
if(layer_type==type(1)): #该层只有一个状态
# print("the k {}".format(k))
table = layer[:]
ways = []
orgin_table = table[:]
index = orgin_table.index(0)
# up,down,left,right = index-3,index+3,index-1,index+1
if index % 3 == 0:
direction = [index - 3, index + 3, index + 1]
elif index % 3 == 2:
direction = [index - 3, index + 3, index-1]
else:
direction = [index - 3, index + 3, index - 1, index + 1]
for go in direction: # 上下左右
if (judge_limit(go)): # 可移动的位置下标
table = orgin_table[:] # 原始表交换!,若没有[:]只是复制引用
table[index], table[go] = table[go], table[index] # 交换
state.append(table)
way_method = dic[str(orgin_table)][:]
way_method.append(go + 1)
ways.append(way_method)
else: # 该层有多个状态,是列表的列表
ways = []
for table in layer: # table是其中一个状态,类型为列表
orgin_table = table[:]
index = orgin_table.index(0)
#up,down,left,right = index-3,index+3,index-1,index+1
if index % 3 == 0:
direction = [index - 3, index + 3, index + 1]
elif index % 3 == 2:
direction = [index - 3, index + 3, index - 1]
else:
direction = [index - 3, index + 3, index - 1, index + 1]
for go in direction: #上下左右
if(judge_limit(go)):#可移动的位置下标
table = orgin_table[:] # 原始表交换!,若没有[:]只是复制引用
table[index],table[go] = table[go],table[index] #交换
if table not in state:
state.append(table)
way_method = dic[str(orgin_table)][:]
way_method.append(go + 1)
ways.append(way_method)
return state,ways
上述代码是实现由上一层状态推出下一层状态的方法,direction表示当前空格位置可能可以走的位置,judge_limit是调用了程序中的另一个方法,用来判断位置是否越界,ways用来存储当前对应移动的位置,将来用来逆序还原路径序列
if __name__ == "__main__":
for i in range(9): # 最终答案空格可能出现位置
layer0 = [1, 2, 3, 4, 5, 6, 7, 8, 9] # answer状态对应0层
layer0[i] = 0 #空格所在位置
layers = [layer0]
exist_table = [layer0]
k = 0 # 层数
# way_method = [9]
dic = {str(layer0):[i+1]}
while True:
state,ways = move(layers[k])
k += 1 # 移动完层数+1
layer,ways = remove_same(state, ways,exist_table)
store_exist(layer)
bulid_dic(layer, ways)
if len(layer) == 0:
print('The deepest layer is layer {}'.format(k-1))
save_name = 'dic'+str(i+1)+'.pkl'
pkl_file = open(save_name, 'wb')
pickle.dump(dic, pkl_file)
pkl_file.close()
print("dic has already saved in default path")
break
layers.append(layer)
print(k)
print('len {}'.format(len(layer)))
上述代码是算法准备的主程序代码,循环进行每一种可能答案类型的初始化、移动、去重、存取、建立字典...最终写入文件操作
算法应用
def find_solvable_optimal(swaped_tables): # 输入为二维列表,每个元素是列表
cost = 35 # max_cost == 32
optimal_table = []
unsolvable_tables = []
for table in swaped_tables:
if str(table) in dic: # 有解
if len(dic[str(table)])<cost: # 更优
cost = len(dic[str(table)])
optimal_table = table
if cost == 1: # 答案
return optimal_table,cost,unsolvable_tables
else: # 无解
unsolvable_tables.append(table)
return optimal_table, cost, unsolvable_tables
上述代码实现的功能是寻找广搜后所有状态中有解的最小代价及其对应的状态,并存储无解的状态为列表,传入下述代码中进行处理。
def find_whole_optimal(cost, unsolvable_tables):
target_table = [] # 自由交换之后的表状态
free_swap = [] # 自由交换方法
orgin_table = [] # 原强制交换表
for table in unsolvable_tables: # 遍历无解情况
arr_table = np.array(table)
for key in dic.keys():
if len(dic[key]) >= cost: # 不必往更深遍历
break
arr_target = np.array(eval(key))
if len(arr_table[arr_table != arr_target]) == 2: # 交换完之后可以一样
cost = len(dic[key]) # 维护最小cost
(d_index,) = np.where(arr_table != arr_target)
d_index = (d_index + 1) # 下标从0开始,位置从1开始
orgin_table = table[:]
target_table = eval(key)
free_swap = list(d_index)
break # 不必往更深遍历
return orgin_table,target_table,free_swap
上述代码实现的功能是寻找广搜后所有无解状态最小代价并记录自由交换的策略,为优化代码效率,当按代价由小到大到答案字典中遍历进行匹配时,只要遍历到代价大于等于当前记录的最小代价而还未匹配,则不需要继续遍历下去
if __name__ == "__main__":
url = "http://47.102.118.1:8089/api/challenge/start/e9d5727c-57fa-4182-a1fd-24b43fd392ce" # 获取赛题的接口
datas = access_problem(url)
data = datas['data']
json_image = data['img']
chanceleft = datas['chanceleft']
step = data['step']
swap = data['swap']
uuid = datas['uuid']
current_table, anstype = image_recognition.main(json_image) # 调用图像识别模块,返回数字华容道数字序列和答案int类型
## 读取对应答案类型的答案文件
target_file = 'dic' + str(anstype) + '.pkl'
pkl_file = open(target_file, 'rb') # 图像识别挖去的是第几块
dic = pickle.load(pkl_file)
pkl_file.close()
# 变量初始化
dic_path = {}
# 提交变量初始化
operations = ''
free_swap = []
table = current_table[:]
## 特判
if step == 0:
table[swap[0]-1],table[swap[1]-1] = table[swap[1]-1],table[swap[0]-1]
if str(table) in dic: # 有解
operations = get_stepmethod(table)
else: # 无解
target_table, free_swap = special_free_swap(table)
operations = get_stepmethod(target_table)
else:
## 第一种情况
if str(table) in dic and len(dic[str(table)])-1 <= step: # 有解且可以在强制交换之前走完
operations = get_stepmethod(table)
## 第二种情况
else: # 无解或者有解但在强制交换前走不完
bfs_tables = bfs_execute([table], stepnum=step)
swaped_tables = force_swap(swap, bfs_tables) # 所有进行强制交换
optimal_table, cost, unsolvable_tables = find_solvable_optimal(swaped_tables) # 有解中的最优
orgin_table, target_table, free_swap = find_whole_optimal(cost, unsolvable_tables) # 无解中的更优(全局最优“)
if len(free_swap) == 0: # 无解中没有更优
orgin_table = optimal_table[:] # 为了接下来获取强制交换之前的原始表路径
orgin_table[swap[0]-1],orgin_table[swap[1]-1] = orgin_table[swap[1]-1],orgin_table[swap[0]-1]
operations = dic_path[str(orgin_table)] + get_stepmethod(optimal_table)
else: # 无解中有更优
orgin_table[swap[0] - 1], orgin_table[swap[1] - 1] = orgin_table[swap[1] - 1], orgin_table[swap[0] - 1]
operations = dic_path[str(orgin_table)] + get_stepmethod(target_table)
if len(free_swap) == 2:
free_swap = [int(free_swap[0]),int(free_swap[1])] # 处理中numpy转为int64,json上传不接受
submit_answer(operations, free_swap)
上述代码是AI大比拼中使用的主程序代码,实现细节可看注释
- 性能分析与改进
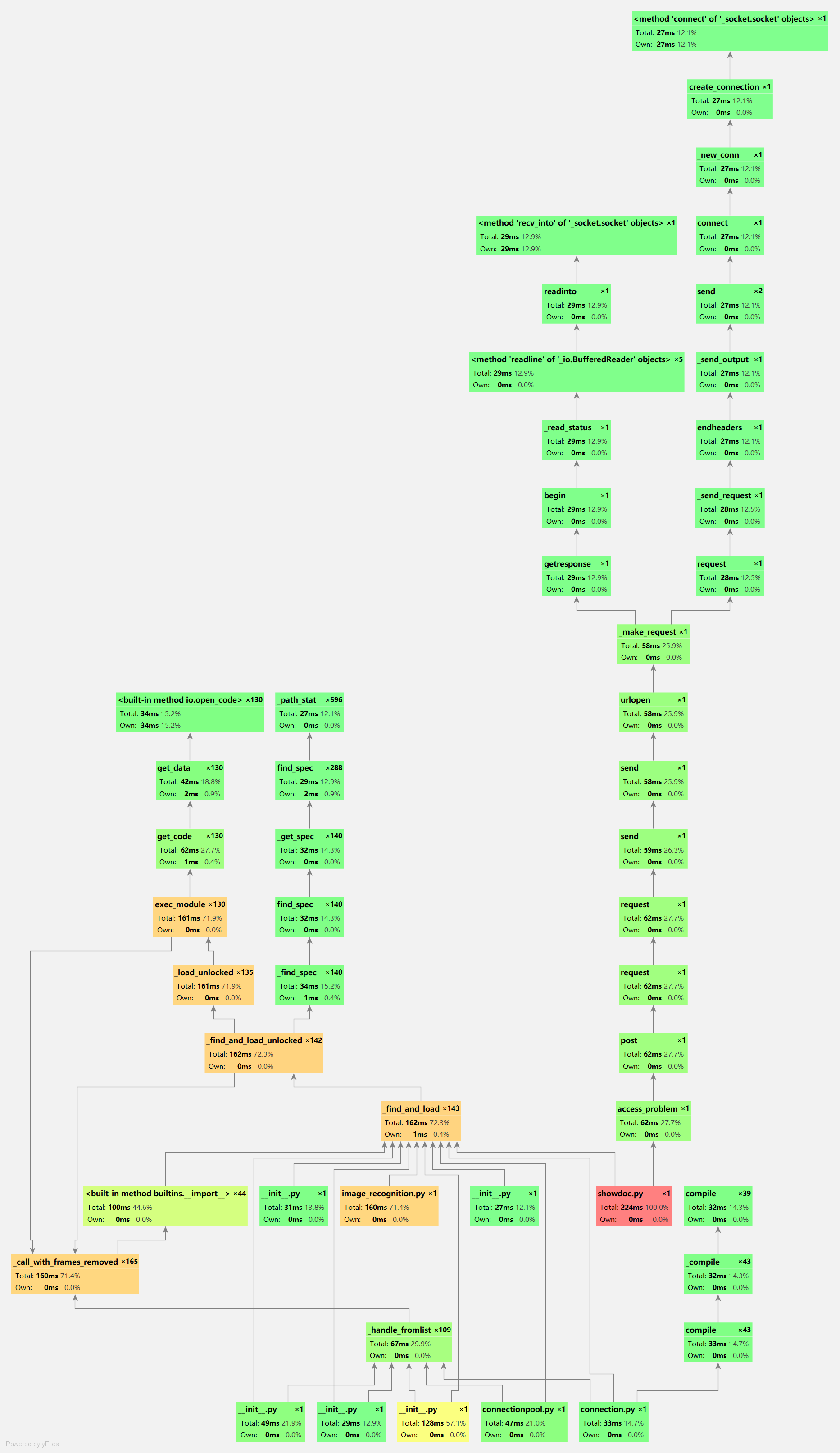
在AI大比拼中,我们可以每一题保证步数的最优,但是时间总是在20-30秒左右,主要瓶颈在于图像识别部分占了很大一部分的时间,核心算法部分也就是解决数字华容道的部分效率还是挺满意的,基本上运行时间能控制在5秒以内,随问题复杂度的提升耗时不会增加太多。但最终受时间所限,图像识别并没有进行改动和优化。讲一下结对过程中优化的核心算法部分。
性能方面,算法应用中有许多值得分析和改进的地方,例如实现广搜的bfs_execute函数,以及在广搜step步后寻找最小代价的策略上,bfs的过程中很影响性能的一点就是是否及时进行去重操作,以为bfs中的每一步就像细胞分裂过程一样,属于指数级别的复杂度增长,若不能根据需要进行去重,会大大拉低算法的性能。至于广搜step步寻找最小策略这方面,也是算法的核心部分,其中有解部分由于有答案字典的支持所以求解最小代价非常快,而无解部分则需要对答案字典由低层向深层遍历(其中状态数的增加速度是非常快的),是这一步决定效率好坏的关键所在,改进方法详见改进思路。
-
改进的思路
既然如何求解无解部分最小代价是决定算法核心部分效率的关键,所以就要设计一个策略来优化其求解来达到优化整体算法性能的目的。思路就是既然有解部分求解比较容易,那么就可以先求出有解部分的最小步数来维护一个cost变量,其中遍历到无解部分的时候先将其存入一个列表后续设置一个函数统一处理。将cost变量传入求解无解部分最小代价的函数中,顺序遍历字典(按代价从小到大)进行匹配,当遍历到的字典状态代价已经大于等于当前记录的最小代价cost时,就停止其继续往深层遍历(因为此时及时匹配成功也不是最优解),而若在代价小于cost就匹配成功时,则将cost更新为当前更小的代价,优化后续匹配过程,这种策略在实际操作中可以基本上让无解部分只在字典浅层的少数几个表中进行尝试匹配,而不必让无解部分的每一状态遍历到最深层去逐一尝试匹配近20万个表。 -
展示性能分析图和程序中消耗最大的函数
-
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
import AI
import unittest
from BeautifulReport import BeautifulReport
class MyTest(unittest.TestCase):
'''
有针对性地测试四种情况
'''
def test1(self):
'''step=0'''
exclude = 5
challenge = [1, 7, 3, 0, 6, 8, 9, 4, 2] # 一维列表
step = 0
swap = [2, 9]
print(AI.main(exclude,challenge,step,swap))
def test2(self):
'''原图有解且可以在强制交换之前走完'''
exclude = 2
challenge = [1, 7, 3, 0, 6, 8, 4, 5, 9] # 一维列表
step = 20
swap = [3, 6]
print(AI.main(exclude, challenge, step, swap))
def test3(self):
'''原图有解但无法在强制交换之前走完'''
exclude = 2
challenge = [1, 7, 3, 0, 6, 8, 4, 5, 9] # 一维列表
step = 10
swap = [3, 6]
print(AI.main(exclude, challenge, step, swap))
def test4(self):
'''原图无解'''
exclude = 9
challenge = [1, 7, 3, 0, 6, 8, 5, 4, 2] # 一维列表
step = 15
swap = [2, 7]
print(AI.main(exclude, challenge, step, swap))
if __name__ == "__main__":
ts = unittest.TestSuite()
for i in range(1,5):
testname = 'test'+str(i)
ts.addTest(MyTest(testname))
result = BeautifulReport(ts)
result.report(
filename='TestReport.html', # 测试报告名称, 如果不指定默认文件名为report.html
description='测试', # 测试报告用例名称展示
report_dir='report', # 报告文件写入路径
theme='theme_default'
)
测试的函数是github链接中的AI部分代码,也就是实现数字华容道的核心算法部分,构造测试数据思路就是要包含各种情况:step=0、原图有解且可以在强制交换之前走完、原图有解但无法在强制交换之前走完、原图无解。至于每一个测试样例如何构造的一方面是靠尝试,一方面是构造相应的测试代码,其实自己还有一份“老代码”可以很方便的进行这方面的测试。
2.2、贴出Github的代码签入记录,合理记录commit信息
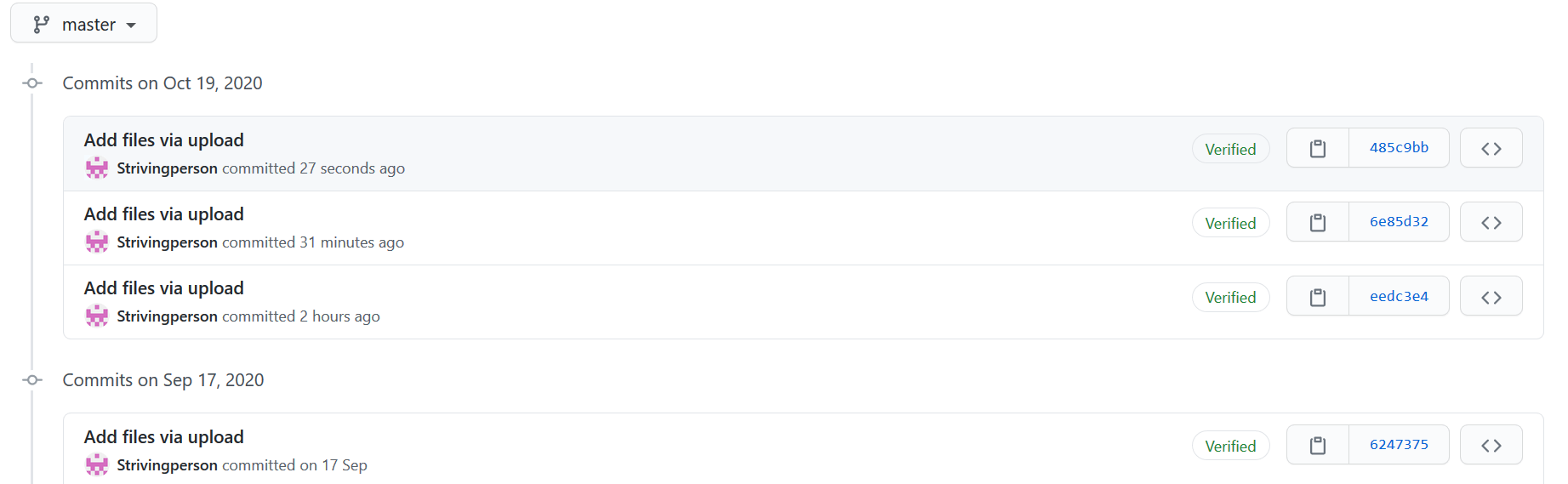
(争取下次做更好一点)
2.3、遇到的代码模块异常或结对困难及解决方法
- 问题描述
(1) AI大比拼前的测试代码性能不好,不仅效率低而且解出的往往不是最优解
(2) 在算法实现的过程中碰到了很多次感觉很费解的bug - 解决尝试
(1) 对已经没有潜力的解法进行更新,用更好的算法去实现一个更优的代码性能
(2) 编写多个测试样例让程序运行,人工检验正确与否,以及在程序中加入多个print语句打印中间结果来发现过程中的异常 - 是否解决
上述问题均已得到解决,新的算法及时得到实现并且在AI大比拼中取得了比测试期间更好的成绩 - 有何收获
出现问题和队友沟通是第一步,AI大比拼的前一个晚上发现了代码性能不好的情况下就和队友去操场散步认真讨论了一下,最终商讨出了新的解决方案及时实现并运用到大比拼中,有问题先思考解决问题的方法,这是这次结对编程带给我们的收获
2.4、评价你的队友
- 值得学习的地方
逻辑能力很强,能够很快地发现算法的问题所在,并提出相应的修改意见,值得多多学习,没有什么不足之处。 - 需要改进的地方
希望下次能够更多地一起交流进展,互相给一些建议,也可以分享自己的一些学习心得。
2.5、此次结对作业的PSP和学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(h) | 累计学习耗时(h) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 10 | 10 | 了解前端的基本特性 |
| 2 | 120 | 120 | 14 | 24 | 学习并练习html,js,css语句 |
| 3 | 150 | 270 | 16 | 40 | 继续学习html,js,css的写法,练习Axure的使用 |
| 4 | 100 | 370 | 20 | 60 | 将js和css嵌入html当中(实现Axure) |
| 5 | 100 | 470 | 20 | 80 | 最终实现游戏的页面 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(h) | 累计学习耗时(h) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 10 | 10 | 查阅相关资料,制定算法 |
| 2 | 250 | 250 | 14 | 24 | 实现bfs代码 |
| 3 | 150 | 400 | 16 | 40 | 完成图像识别,并且看看代码是否存在bug |
| 4 | 200 | 600 | 20 | 60 | 学习使用接口 |
| 5 | 300 | 900 | 20 | 80 | 发现算法不足,完善代码 |
3、原型设计实现
//随机打乱方块函数,我的思路是用空格不断和周围的交换,这样保证一定有解
function random_d(){
var change=Math.floor(Math.random()*200)+10;
for(var i=0;i<change;i++){
for(var j=1;j<=9;j++){
if(d[j]==0){
break;
}
}
var blank_ = j;
var move_list = d_direct[j]
var to_index = Math.floor(Math.random()*move_list.length); //获取要移动的相邻块组成列表的索引
var to = move_list[to_index];
document.getElementById("d"+d[to]).style.left=d_posXY[blank_][0]+"px";
document.getElementById("d"+d[to]).style.top=d_posXY[blank_][1]+"px";
var tem = d[blank_];
d[blank_] = d[to];
d[to] = tem;
}
}
//记录历史以及最佳
function history(){
var min = history_list[0];
if(num==0){
alert("无记录");
}
else{
for(var i =0;i<num;i++){
if(min>history_list[i]){
min = history_list[i];
}
}
alert("历史记录为"+history_list+";最佳步数为"+min);
}
}
//实现拼图的移动函数
function move(id){
//移动函数,前面我们已将讲了
var i=1;
for(i=1; i<10; ++i){
if( d[i] == id )
break;
}
//这个for循环是找出小DIV在大DIV中的位置,找出我们要移动的图片目前所在的位置
var target_d=0;
//保存小DIV可以去的编号,0表示不能移动
target_d=whereCanTo(i);
//用来找出小DIV可以去的位置,如果返回0,表示不能移动,如果可以移动,则返回可以去的位置编号
if( target_d != 0){
d[i]=0;
//把当前的大DIV编号设置为0,因为当前小DIV已经移走了,所以当前大DIV就没有装小DIV了
d[target_d]=id;
//把目标大DIV设置为被点击的小DIV的编号
document.getElementById("d"+id).style.left=d_posXY[target_d][0]+"px";
document.getElementById("d"+id).style.top=d_posXY[target_d][1]+"px";
count+=1;
document.getElementById("count").innerHTML=count;
//最后设置被点击的小DIV的位置,把它移到目标大DIV的位置
}
var finish_flag=true;
for(var k=1; k<9; ++k){
if( d[k] != k){
finish_flag=false;
document.getElementById("win").innerHTML="";
break;
}
}
if(finish_flag==true){
if(!pause)
start();
document.getElementById("win").innerHTML="successed,congratulations!!";
history_list[num] = count;
num = num+1;
}
//如果为true,则表示游戏完成,如果当前没有暂停,则调用暂停韩式,并且弹出提示框,完成游戏。
//start()这个函数是开始,暂停一起的函数,如果暂停,调用后会开始,如果开始,则调用后会暂停
}

