
综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/ |
|---|---|
| 组名、项目简介 | 组名:都给爷爬 项目目标:为心理疾病患者进行个性化的音乐疗愈 项目需求:市面上大多数音乐软件都需要会员而且存在打榜等现象,不能完全个性化推荐,我们希望我们的个性化音乐系统能为心理疾病患者带来音乐疗愈,因此选择了该公益项目 项目开展技术路线:python(django,pytorch,tensorflow)、爬虫技术、MySQL |
| 团队成员学号 | 102202135 102202146 102202127 102202125 102202139 102202109 102202128 |
| 这个项目的目标 | 我们希望免费的公益的为有心理疾病的患者提供音乐疗愈的软件,我们可以根据患者、医生希望的音乐进行推荐,给患者相对舒服的音乐疗愈。 |
| 其他参考文献 | 【1】https://github.com/marl/openl3 【2】https://eva.fing.edu.uy/pluginfile.php/524749/mod_folder/content/0/BERT Pre-training of Deep Bidirectional Transformers for Language Understanding.pdf 【3】https://link.springer.com/chapter/10.1007/978-1-4842-6168-2_6 【4】https://blog.csdn.net/weixin_42645636/article/details/135777479 |
项目整体介绍
码云链接
该项目是基于智能推荐算法,为心理障碍人群提供免费公益的音乐播放平台。我们采用爬虫从音乐平台上爬取歌曲、歌单丰富我们的平台,为用户提供丰富的、多类的曲目进行选择。使用OpenGL->librosa对音频进行特征提取、Bert提取文本特征、resnet50提取图像特征,同时我们接入大模型,让大模型对用户现状进行分析,给出适合的音乐类型推荐,再将用户的行为特征一起考虑,构成我们的协同过滤推荐算法,实现音乐个性化的推荐,满足用户需求。
系统概述:
1. 前端
前端部分负责与用户交互,展示推荐结果和用户行为数据。在此项目中,前端将展示歌曲的推荐结果、用户偏好以及推荐算法反馈的数据。用户通过网页或移动端应用提交行为数据(如评分、评论、播放历史等),并接收根据多模态数据推荐的歌曲。前端与后端通过API进行数据交互,确保用户体验的流畅性和响应速度。
2. 后端
后端主要负责处理用户请求、管理数据存储、执行推荐算法及特征提取和融合等逻辑。具体实现包括以下几个模块:
特征提取模块:负责从文本(BERT)、图像(ResNet50)、音频(梅尔频谱图、MFCC等)中提取多模态特征。通过并行处理提升性能。
推荐算法模块:结合内容推荐与协同过滤算法,通过加权融合提升推荐的多样性和精准性。
用户偏好建模模块:根据用户的多维度行为(收藏、评分、评论、播放历史)建立偏好模型。
特征融合模块:通过多头注意力机制和线性投影融合音频、图像、文本特征,输出统一的特征向量。
特征存储模块:利用Django ORM进行数据库操作,通过事务确保数据一致性,缓存机制提高特征读取效率。
3. 数据库
数据库存储用户行为数据、歌曲信息以及提取的多模态特征。具体包括:
歌曲信息表:存储每首歌曲的基本信息(如歌名、歌手、专辑等)和相关的多模态特征(音频、文本、图像特征)。
用户行为数据表:存储用户的收藏、评分、评论及播放历史。
特征缓存表:存储提取的音频、文本、图像及融合后的特征,使用序列化存储以支持高效的读取和管理。
4. AI接口
AI接口主要包含两个部分:
特征提取接口:提供音频、文本和图像特征的提取服务,分别利用预训练的BERT、ResNet50和自定义音频处理模型进行处理。接口通过异步或并行处理提高特征提取的效率。
推荐接口:基于用户行为数据和歌曲特征,提供基于内容推荐和协同过滤推荐的服务。通过加权融合推荐算法,生成最终的推荐列表,返回给前端展示。
5. 爬虫
通过爬取千千音乐(https://music.91q.com),解析请求获取API,获取歌曲和歌单相应的信息并存到数据库中。
6. 部署平台
使用华为云平台部署系统,保证系统的高可用和稳定性。
项目展示


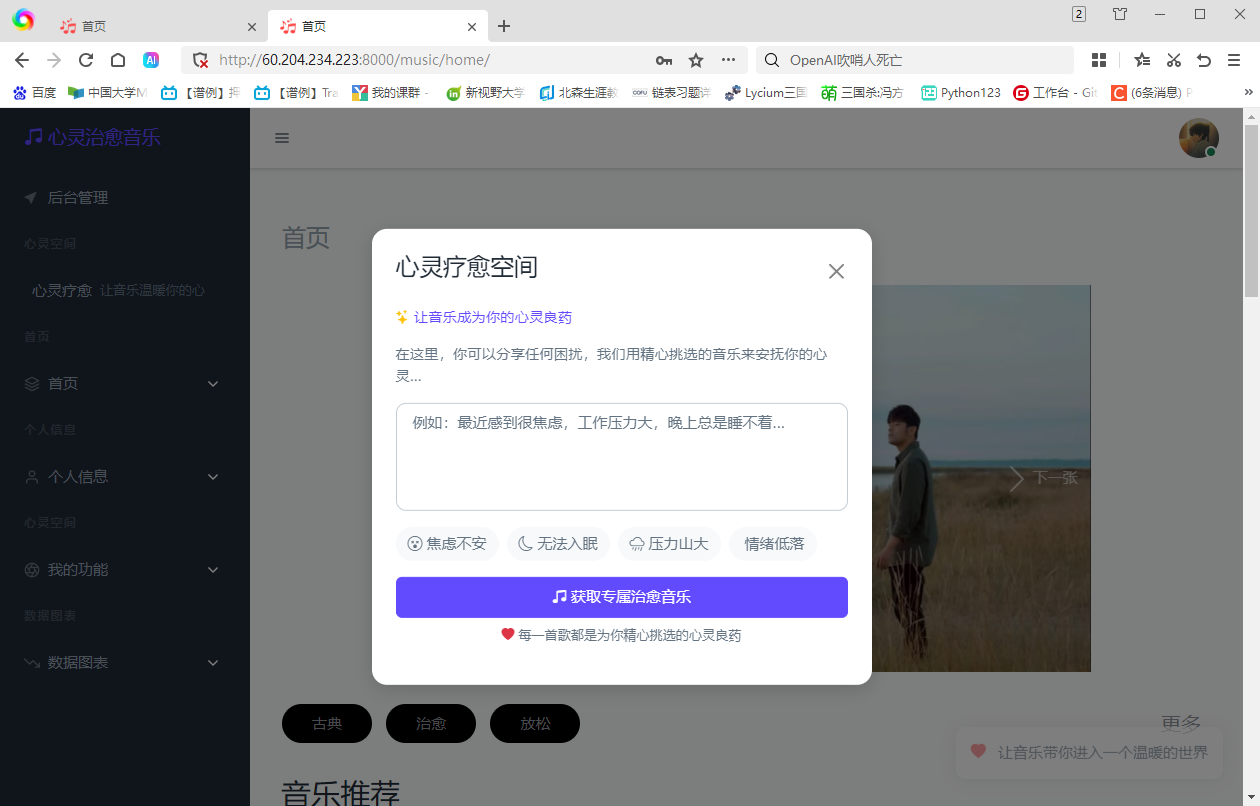



个人任务
爬虫程序分析及编写
爬虫这一部分一共有三个程序,实现的是通过爬取千千音乐(http://music.91q.com)获得我们所需的音乐的详细信息并且存到数据库中,同时通过额外的API获取音乐文件的URL,下载音乐文件。
spiderPublic.py
import requests
import time
import hashlib
import os
import csv
import json
class PublicUtilsFn:
def __init__(self):
self.sheetUrl = "https://music.91q.com/v1/tracklist/list"
self.songUrl = "https://music.91q.com/v1/tracklist/info"
self.musicInfoUrl = "https://music.91q.com/v1/song/tracklink"
self.secret = "0b50b02fd0d73a9c4c8c3a781c30845f"
self.appid = 16073360
def init_songSheet(self):
if not os.path.exists('./songSheet.csv'):
with open('./songSheet.csv', 'w', encoding='utf-8', newline='') as csvFile:
write = csv.writer(csvFile)
write.writerow([
'id',
'title',
'desc',
'tagList',
'img',
'type',
'musicNum',
'createTime'
])
def init_song(self):
if not os.path.exists('./song.csv'):
with open('./song.csv', 'w', encoding='utf-8', newline='') as csvFile:
write = csv.writer(csvFile)
write.writerow([
'assetId',
'songSheetId',
'title',
'singer',
'type',
'albumTitle',
'duration',
'lyric',
'img',
'songUrl',
'createTime'
])
def save_to_songSheetCsv(self, row):
with open('songSheet.csv', 'a', encoding='utf8', newline='') as csvfile:
write = csv.writer(csvfile)
write.writerow(row)
def save_to_songCsv(self, row):
with open('song.csv', 'a', encoding='utf8', newline='') as csvfile:
write = csv.writer(csvfile)
write.writerow(row)
def md5Encode(self, str):
md5 = hashlib.md5()
md5.update(str.encode('utf-8')) # 使用MD5算法对字符串进行编码
return md5.hexdigest() # 返回编码后的16进制字符串
def getTimeStamp(self):
return int(time.time()) # 获取当前时间的时间戳,返回整数类型
# 获取音乐详情
def getMusicInfo(self, TSID):
timestamp = self.getTimeStamp()
args = {
"sign": "",
"appid": self.appid,
"TSID": TSID,
"timestamp": timestamp
}
signParam = "TSID={0}&appid={1}×tamp={2}{3}".format(TSID, self.appid, timestamp, self.secret)
args["sign"] = self.md5Encode(signParam)
# 构建最终的URL
final_url = self.musicInfoUrl + '?' + '&'.join(['{}={}'.format(key, value) for key, value in args.items()])
print(final_url)
res = requests.get(url=self.musicInfoUrl, params=args)
return res.json()
主要功能:初始化时定义了几个常用的url,用于获取歌单列表,获取单个歌单的歌曲详情,获取歌曲的播放链接。利用MD5码将输入的字符串进行加密,生成API请求参数。然后将歌单信息和歌曲信息各自存到对应的CSV文件里。
spiderSong.py
import csv
import time
from spider.spiderPublic import PublicUtilsFn
import requests
import os
import django
import random
import pandas as pd
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'python个性化音乐推荐系统.settings')
django.setup()
from music.models import SongType, SongSheet, Song
def get_json(id):
# 获取时间戳
timestamp = publicObj.getTimeStamp()
# 创建参数字典
args = {
"sign": "",
"id": id,
"pageSize": 50,
"appid": publicObj.appid,
"timestamp": timestamp,
}
# 创建签名参数字符串
signParam = "appid={0}&id={1}&pageSize={2}×tamp={3}{4}".format(
publicObj.appid,
args['id'],
args["pageSize"],
timestamp,
publicObj.secret # 确保 secret 是在参数列表中的最后一个,并且与 signParam 字符串中的占位符对应
)
# 添加签名到参数字典
args["sign"] = publicObj.md5Encode(signParam)
# 构建最终的URL
final_url = publicObj.songUrl + '?' + '&'.join(['{}={}'.format(key, value) for key, value in args.items()])
print(final_url)
# 发送HTTP GET请求
res = requests.get(url=publicObj.songUrl, params=args)
# 打印响应结果
print(res.json())
return res.json()
def parse_json(response, songSheetId):
dataList = response['data']['trackList']
for song in dataList:
try:
id = song['assetId']
songSheetId = songSheetId
title = song['title']
singer = song['artist'][0]['name']
type = song['genre']
albumTitle = song['albumTitle']
duration = song['duration']
lyric = song['lyric']
img = song['pic']
# 初始化重试次数
max_retries = 2
retry_count = 0
# 初始化songUrl为空字符串
songUrl = ''
# 当重试次数小于最大重试次数时,进行尝试
while retry_count < max_retries:
try:
# 尝试获取歌曲的URL地址
songUrl1 = publicObj.getMusicInfo(id).get("data", {}).get("path")
songUrl2 = publicObj.getMusicInfo(id).get("data", {}).get("trail_audio_info", {}).get("path")
# 如果songUrl1存在,则赋值给songUrl
if songUrl1:
songUrl = songUrl1
# 否则,如果songUrl2存在,则赋值给songUrl
elif songUrl2:
songUrl = songUrl2
# 如果成功获取到URL,则退出循环
break
except:
# 如果发生异常,增加重试次数
retry_count += 1
# 如果达到最大重试次数仍未成功,则设置songUrl为空字符串
if retry_count == max_retries:
songUrl = ''
print(songUrl)
# 获取歌曲的发布时间,只取前10个字符(可能是年月日时分秒)
createTime = song['releaseDate'][:10]
# 生成一个随机的整数作为文件名的部分
randomFilename = str(random.randint(1, 10000000)) + '.mp3'
try:
download_audio(songUrl, '../media/music', randomFilename)
print(randomFilename)
except:
randomFilename = '' # 重置文件名为空字符串
resultData = [
id, songSheetId, title, singer, type, albumTitle, duration,
lyric, img, f'music/{randomFilename}', createTime
]
publicObj.save_to_songCsv(resultData)
print('%s - 歌曲爬取完毕' % song['title'])
except:
continue
def download_audio(url, local_folder, filename):
# 检查本地文件夹是否存在
if not os.path.exists(local_folder):
# 如果不存在,则创建该文件夹
os.makedirs(local_folder)
# 构建文件在本地系统中的完整路径
local_path = os.path.join(local_folder, filename)
# 使用requests库获取远程URL的内容
response = requests.get(url)
# 以写入模式打开目标文件
with open(local_path, 'wb') as file:
# 将响应内容写入到文件中
file.write(response.content)
def clearData(output_file='./cleaned_songs.csv'):
# 读取 CSV 文件
df = pd.read_csv('./song.csv')
print("总条数为%d" % df.shape[0])
# 筛选 songUrl 不等于 'music/',并创建副本
matching_rows = df[df['songUrl'] != 'music/'].copy()
if not matching_rows.empty:
print("正在去除没有音乐文件的歌曲...")
# 将 title 列转换为小写以区分大小写
matching_rows['title_lower'] = matching_rows['title'].str.lower()
# 去除重复的 title,保持原始大小写
unique_rows = matching_rows.drop_duplicates(subset='title_lower', keep='first')
# 删除临时的 'title_lower' 列
unique_rows = unique_rows.drop(columns=['title_lower'])
if not unique_rows.empty:
print("去除重复歌曲后条数为%d" % unique_rows.shape[0])
# 保存去重后的数据到新的 CSV 文件
unique_rows.to_csv(output_file, index=False)
print(f"去重后的数据已保存到 {output_file}")
return unique_rows.values
else:
print("没有找到有效的歌曲文件。")
return None
else:
print("没有找到任何歌曲文件。")
return None
def save_to_sql():
data = clearData()
allSheetList = SongSheet.objects.all()
for song in data:
try:
for sheet in allSheetList:
if song[1] == sheet.sheetId:
Song.objects.create(song_Sheet=sheet, title=song[2], singer=song[3],
type=song[4],
albumTitle=song[5],
duration=song[6],
lyric=song[7],
img=song[8],
songUrl=song[9],
createTime=song[10])
except:
pass
print('歌曲存入成功')
def main(startSheet, endSheet):
songSheetList = []
with open('./songSheet.csv', 'r', encoding='utf-8') as reader:
readerCsv = csv.reader(reader)
next(readerCsv) # 跳过表头
for songSheet in readerCsv:
songSheetList.append(songSheet)
# print(songSheetList)
for songSheet in songSheetList[startSheet:endSheet]:
print('歌单名称为:' + songSheet[1])
resJson = get_json(songSheet[0])
parse_json(resJson, songSheet[0])
if __name__ == '__main__':
publicObj = PublicUtilsFn()
publicObj.init_song()
main(1, 480)
save_to_sql()
主要功能:从指定的API获取包含歌曲的歌单信息,构建请求并获取响应。对于每个歌单中的歌曲,提取相关信息,并通过额外的API获取音乐文件的URL,下载音乐文件。将获取到的歌曲音频文件下载到本地指定目录,并保存到CSV文件中。从CSV文件中筛选有效数据,去除无效或重复的歌曲。将去重后的数据通过Django ORM保存到数据库中,包括歌单、歌曲等信息。主函数中,main(1, 480) 使得程序从 songSheet.csv 文件中获取第二行到第480行的数据(总共处理480个歌单)
spiderSheet.py
from spider.spiderPublic import PublicUtilsFn
import requests
import json
import os
import django
import pandas as pd
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'python个性化音乐推荐系统.settings')
django.setup()
from music.models import SongType, SongSheet
typeList = [
{
'subCateId': 2385,
'name': '古典'
},
{
'subCateId': 2411,
'name': '治愈'
},
{
'subCateId': 2412,
'name': '放松'
},
]
def get_json(type, page):
timestamp = publicObj.getTimeStamp()
args = {
"sign": "",
"appid": publicObj.appid,
"subCateId": type['subCateId'],
"pageNo": page,
"timestamp": timestamp,
"pageSize": 50
}
signParam = "appid={0}&pageNo={1}&pageSize={2}&subCateId={3}×tamp={4}{5}".format(
publicObj.appid,
args['pageNo'],
args['pageSize'],
args['subCateId'],
timestamp,
publicObj.secret # 确保 secret 是在参数列表中的最后一个,并且与 signParam 字符串中的占位符对应
)
args["sign"] = publicObj.md5Encode(signParam)
# print(args)
# 构建最终的URL
final_url = publicObj.sheetUrl + '?' + '&'.join(['{}={}'.format(key, value) for key, value in args.items()])
print(final_url)
res = requests.get(url=publicObj.sheetUrl, params=args)
# print(res.json())
# print()
return res.json()
def parse_json(response, type):
dataList = response['data']['result']
for sheet in dataList:
id = sheet['id']
title = sheet['title']
desc = sheet['desc']
tagList = json.dumps(sheet['tagList'])
img = sheet['pic']
typeOf = type['name']
musicNum = sheet['trackCount']
createTime = sheet['addDate'][:10]
resultData = [id, title, desc, tagList, img, typeOf, musicNum, createTime]
publicObj.save_to_songSheetCsv(resultData)
print('%s歌单爬取完毕' % type['name'])
def main(pageStart, pageEnd):
for page in range(pageStart, pageEnd + 1):
for type in typeList:
resJson = get_json(type, page)
parse_json(resJson, type)
def clearData():
df = pd.read_csv('./songSheet.csv')
print("歌单总条数为%d" % df.shape[0])
return df.values
def save_to_sql():
data = clearData()
for sheet in data:
try:
# 添加不同类型的歌主题 title字段已经设置唯一性
SongType.objects.create(title=sheet[5], desc=sheet[2], tagList=sheet[3])
except:
pass
allTypeList = SongType.objects.all()
for sheet in data:
try:
for type in allTypeList:
if sheet[5] == type.title:
SongSheet.objects.create(song_type=type, title=sheet[1], sheetId=sheet[0], img=sheet[4],
createTime=sheet[7], musicNum=sheet[6])
except:
pass
print('类型、歌单存入成功')
if __name__ == '__main__':
publicObj = PublicUtilsFn()
publicObj.init_songSheet()
main(1, 3)
save_to_sql()
主要功能:从外部API爬取不同类型的歌单信息,如古典、治愈、放松,用于我们治疗具有心理疾病的病人的需求。解析数据并将歌单及其相关类型信息存储到数据库中。主函数的main(1, 3) 通过调用 get_json 函数获取指定类型(古典、治愈、放松)歌单的分页数据(从第1页到第3页),并将解析得到的歌单信息保存到CSV文件中。
爬取内容示例结果展示截图:

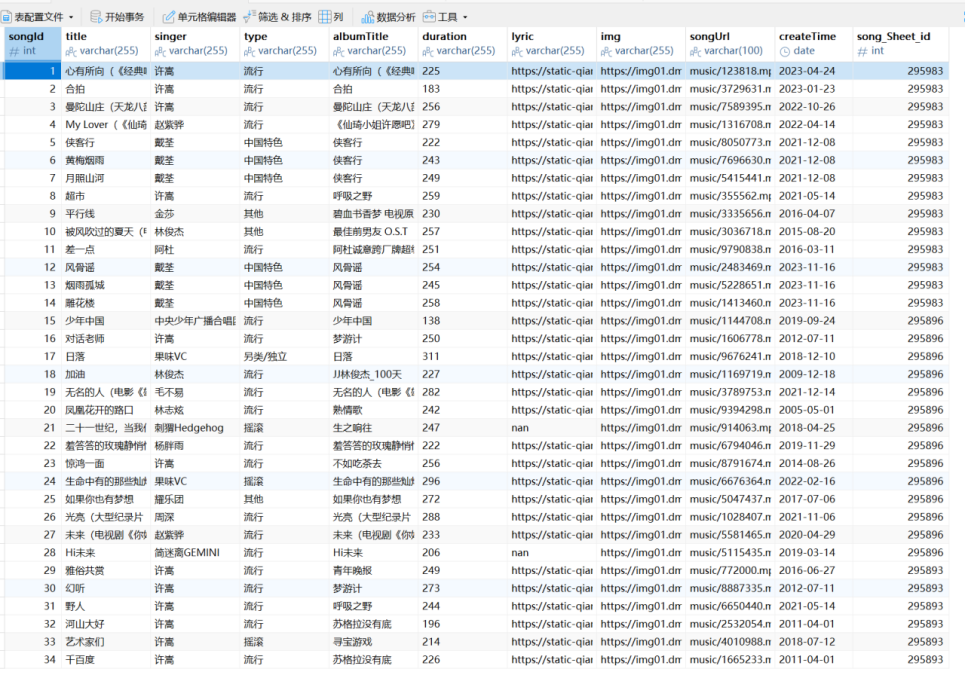
心得体会:
在这次项目的任务中,我负责的是编写爬虫程序爬取所需音乐的任务。我体会到了爬虫的数据获取、解析、存储环节。首先,我需要从指定的 API 获取数据。通过构建请求参数、生成签名并发送 HTTP 请求,成功地获取了返回的 JSON 格式数据。为了便于后续处理,我将数据解析为适合存储和分析的格式。通过对 JSON 数据的遍历和提取,成功提取了每个歌单的关键字段,如 id, title, desc, tagList 等信息。此外,我还学习到如何通过异常处理机制避免数据插入时发生错误。例如,在插入 SongType 和 SongSheet 时,我通过 try-except 语句捕捉并忽略了重复插入的情况,这确保了程序的稳定性和高效性。
在开发过程中,也遇到了一些问题和挑战:
1.部分接口可能会有请求频率限制,导致爬虫频繁报错。为了避免被封禁,我在开发中模拟了合理的请求间隔,并采取了错误重试机制。
2.不同歌单的数据格式可能略有差异,尤其是 tagList 这种复杂的数据结构,需要确保在解析时统一格式,避免出错。
3.在任务的初期,我试图想办法爬取VIP音乐,但经过多次的尝试,发现能力有限
