数据采集与融合实践第四次作业
• 作业①:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
o 候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
o 输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号
id,股票代码:bStockNo……,由同学们自行定义设计表头:
• Gitee 文件夹链接:https://gitee.com/fjpt-chen-siyu/crawl_project/tree/master/homework4/4-1.py
4-1.py
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import datetime
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"}
imagePath = "download"
def startUp(self, url,key):
# 初始化Chrome浏览器
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置无头模式,不弹出浏览器窗口
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.get(url)
# 初始化变量
self.bankuai = ["nav_hs_a_board", "nav_sh_a_board", "nav_sz_a_board"]
self.bankuai_id = 0 # 当前板块
# 初始化数据库
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="shares",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
# 如果有表就删除
self.cursor.execute("drop table stocks2")
# 建立新的表
sql = "create table stocks2(序号 varchar(128),代码 varchar(128),名称 varchar(128),最新价格 varchar(128),涨跌额 varchar(128),涨跌幅 " \
"varchar(128),成交量 varchar(128),成交额 varchar(128),振幅 varchar(128)," \
"最高 varchar(128),最低 varchar(128),今开 varchar(128),昨收 varchar(128));"
self.cursor.execute(sql)
except Exception as err:
print(err)
# 关闭浏览器和数据库连接
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
# 数据库插入操作
def insertDB(self,number,code, name, latest_price, price_limit, price_range, turnover, volume_transaction,
amplitude, highest, lowest, today_open, yesterday_close):
try:
sql = "insert into stocks2(序号,代码,名称,最新价格,涨跌额,涨跌幅,成交量,成交额,振幅,最高,最低,今开,昨收)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cursor.execute(sql,(number,code, name, latest_price, price_limit, price_range, turnover, volume_transaction,
amplitude, highest, lowest, today_open, yesterday_close))
except Exception as err:
print(err)
# 爬虫主程序
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
trs = self.driver.find_elements(By.XPATH,"//table[@class='table_wrapper-table']/tbody/tr")
# 遍历表格行,提取数据并插入数据库
for tr in trs:
number = tr.find_elements(By.XPATH,"./td")[0].text
code = tr.find_elements(By.XPATH,"./td")[1].text
name = tr.find_elements(By.XPATH,"./td")[2].text
latest_price = tr.find_elements(By.XPATH,"./td")[4].text
price_limit = tr.find_elements(By.XPATH,"./td")[5].text
price_range = tr.find_elements(By.XPATH,"./td")[6].text
turnover = tr.find_elements(By.XPATH,"./td")[7].text
volume_transaction = tr.find_elements(By.XPATH,"./td")[8].text
amplitude = tr.find_elements(By.XPATH,"./td")[9].text
highest = tr.find_elements(By.XPATH,"./td")[10].text
lowest = tr.find_elements(By.XPATH,"./td")[11].text
today_open = tr.find_elements(By.XPATH,"./td")[12].text
yesterday_close = tr.find_elements(By.XPATH,"./td")[13].text
try:
self.insertDB(number,code, name, latest_price, price_limit, price_range, turnover, volume_transaction,
amplitude, highest, lowest, today_open, yesterday_close)
except Exception as err:
print(err)
print("插入失败")
# 切换到下一个板块
self.bankuai_id += 1
next = self.driver.find_element(By.XPATH,"//li[@id='"+self.bankuai[self.bankuai_id]+"']/a")
self.driver.execute_script("arguments[0].click();", next)
time.sleep(100) # 等待页面加载完成
self.processSpider()
except Exception as err:
print(err)
# 执行爬虫程序
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
# 输出程序结束信息和运行时间
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
# 主程序部分
url ="http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = MySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executeSpider(url,"key")
elif s == "2":
break
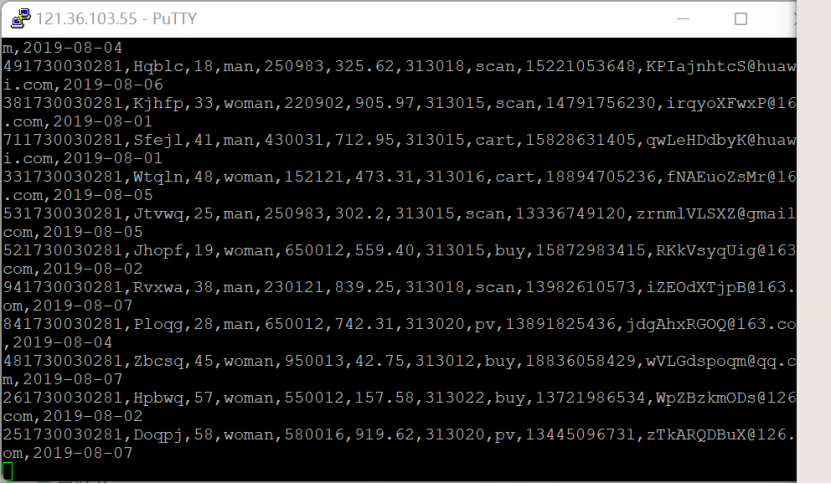
运行结果截图:

心得体会:
跟以前爬取相比,将数据保存到MySQL这都是一样的,只不过这次要爬取三个板块的股票,所以就涉及到切换板块,那这就需要点击操作,所以就使用selenium。通过开发者工具可以知道所有板块都是li标签下的a标签对象,而每个li标签都各自有自己的id,所以我们只需self.bankuai_id变量的初始值为0,代表第一个板块(沪深A股)。这样通过控制self.bankuai_id变量的值,配合查找HTML元素和模拟点击(执行click())方法等操作,就可以实现板块切换功能了。
总之,对selenium查找HTML元素更熟练了,找的更准确了,还有使用MySQL数据库连接数据库、建立表格、插入数据等操作也更加熟练。
• 作业②:
o 要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
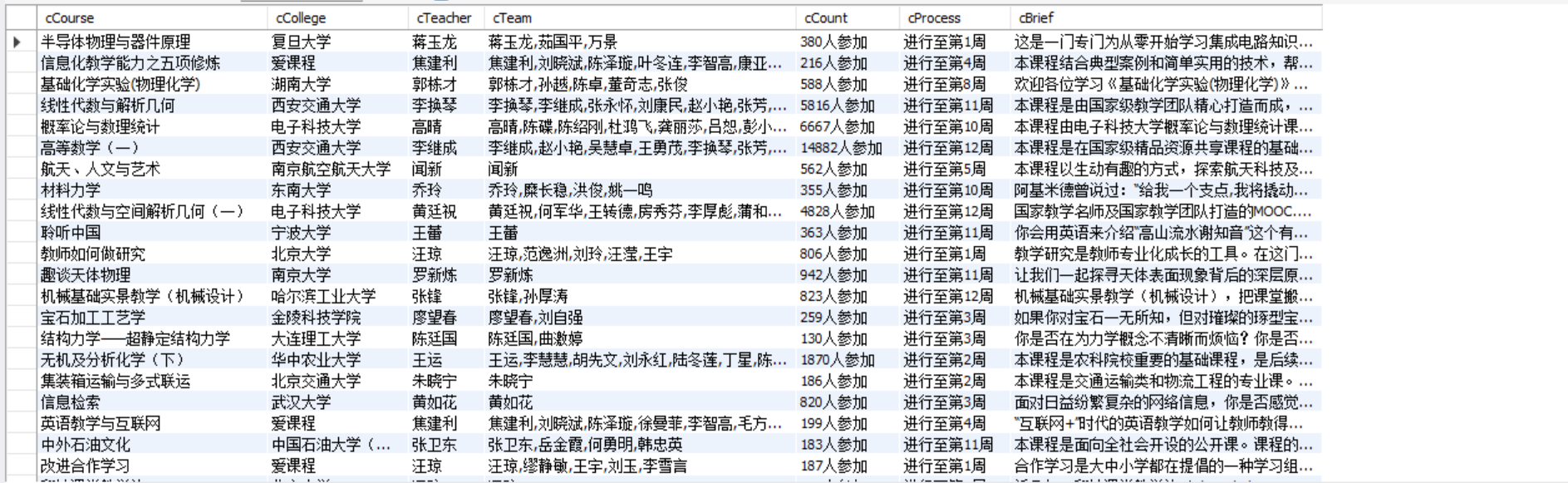
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
o 候选网站:中国 mooc 网:https://www.icourse163.org
o 输出信息:MYSQL 数据库存储和输出格式
• Gitee 文件夹链接:https://gitee.com/fjpt-chen-siyu/crawl_project/blob/master/homework4/4-2.py
4-2.py
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeService
from selenium.webdriver import ChromeOptions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pymysql
chrome_options = ChromeOptions()
chrome_options.add_argument('--disable-gpu')
chrome_options.binary_location = r"C:\Users\DELL\AppData\Local\Google\Chrome\Application\chrome.exe"
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
# chrome_options.add_argument('--headless') # 无头模式
service = ChromeService(executable_path=r"C:\Users\DELL\Downloads\chromedriver-win64\chromedriver-win64\chromedriver.exe")
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.maximize_window() # 使浏览器窗口最大化
# 连接MySql
try:
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3306, database='shares')
cursor = db.cursor()
cursor.execute('DROP TABLE IF EXISTS courseMessage')
sql = '''CREATE TABLE courseMessage(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),
cProcess varchar(32),cBrief varchar(2048))'''
cursor.execute(sql)
except Exception as e:
print(e)
# 爬取一个页面的数据
def spiderOnePage():
time.sleep(3) # 等待页面加载完成
courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
current_window_handle = driver.current_window_handle
for course in courses:
cCourse = course.find_element(By.XPATH, './/h3').text # 课程名
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 大学名称
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 主讲老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 参与该课程的人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 课程进展
course.click() # 点击进入课程详情页,在新标签页中打开
Handles = driver.window_handles # 获取当前浏览器的所有页面的句柄
driver.switch_to.window(Handles[1]) # 跳转到新标签页
time.sleep(3) # 等待页面加载完成
# 爬取课程详情数据
# cBrief = WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'j-rectxt2'))).text
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')
cBrief = ""
for c in cBriefs:
cBrief += c.text
# 将文本中的引号进行转义处理,防止插入表格时报错
cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")
cBrief = cBrief.strip()
# 爬取老师团队信息
nameList = []
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
# 如果有下一页的标签,就点击它,然后继续爬取
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
while len(nextButton)!= 0:
nextButton[0].click()
time.sleep(3)
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
cTeam = ','.join(nameList)
driver.close() # 关闭新标签页
driver.switch_to.window(current_window_handle) # 跳转回原始页面
try:
cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
except Exception as e:
print(e)
# 访问中国大学慕课
driver.get('https://www.icourse163.org/')
# 访问国家精品课程
driver.get(WebDriverWait(driver, 10, 0.48).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a'))).get_attribute(
'href'))
spiderOnePage() # 爬取第一页的内容
count = 1
'''翻页操作'''
# 下一页的按钮
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
# 如果还有下一页,那么该标签的class属性为_3YiUU
while next_page.get_attribute('class') == '_3YiUU ':
if count == 3:
break
count += 1
next_page.click() # 点击按钮实现翻页
spiderOnePage() # 爬取一页的内容
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
try:
cursor.close()
db.close()
except:
pass
time.sleep(3)
driver.quit()
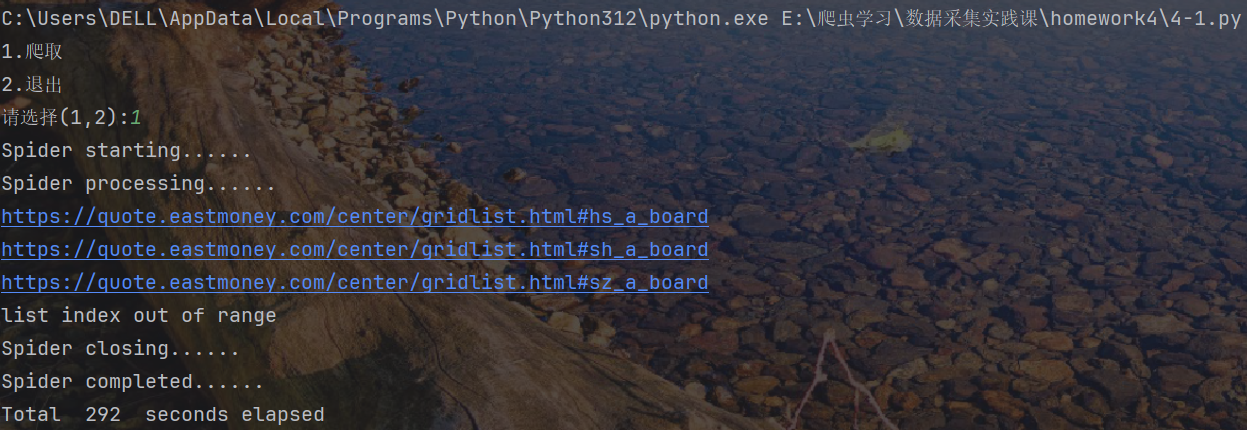
运行结果截图:
心得体会:这一题用时比较长,首先要确认登录页面是否已经切换到了正确的 iframe 中,根据提供的switch_to.frame() 方法进行切换,一定要切换到 iframe 元素的正确ID。然后最开始的思路是登陆以后,通过搜索栏输入关键词进行对应信息的爬取。结果是通过F12抓包分析检查对应的XPATH元素以后还是无法实现自动输入搜索的功能,所以退而求其次,使用了点击click()方法进入一个新的页面进行爬取
• 作业③:
o 要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
• 环境搭建:
·任务一:开通 MapReduce 服务
• 实时分析开发实战:
·任务一:Python 脚本生成测试数据
·任务二:配置 Kafka
·任务三: 安装 Flume 客户端
·任务四:配置 Flume 采集数据
输出:实验关键步骤或结果截图。
开通 MapReduce 服务
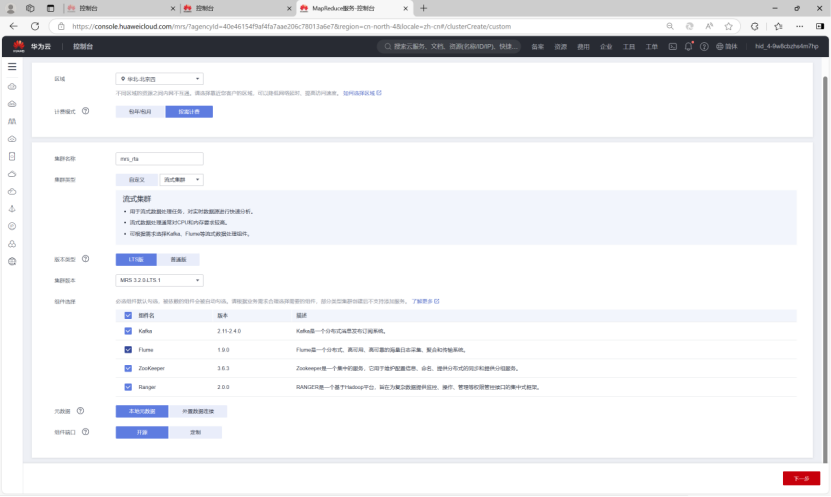
集群配置:硬件配置
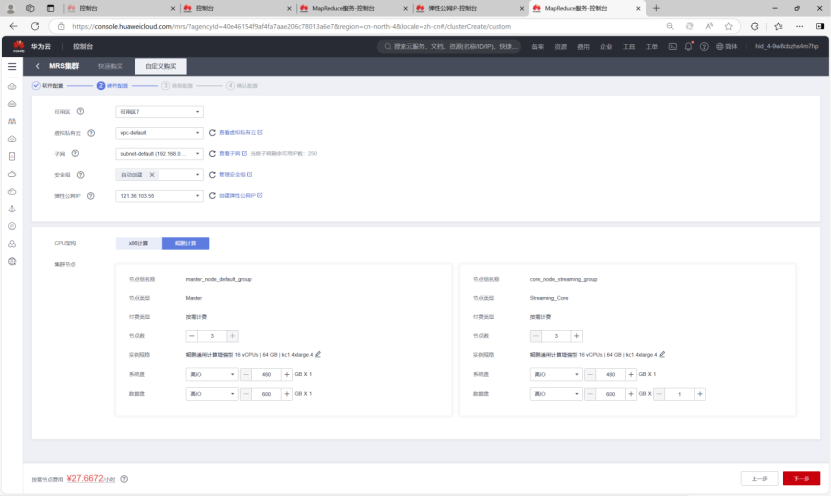
集群配置:高级配置
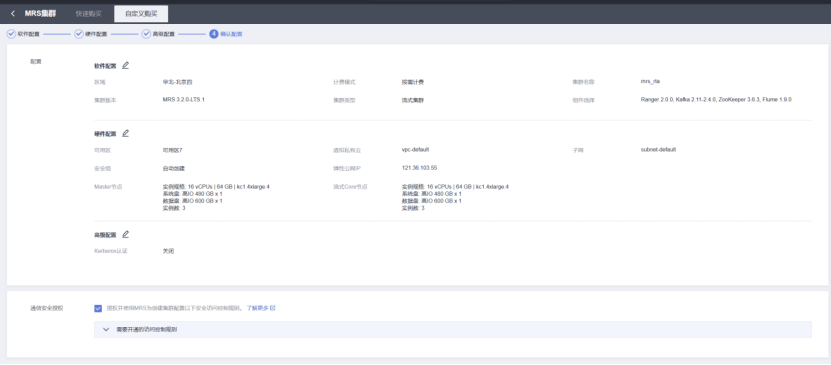
查看购买的集群

给集群的master节点绑定弹性IP

Python 脚本生成测试数据

下载安装并配置Kafka

校验下载的客户端文件包
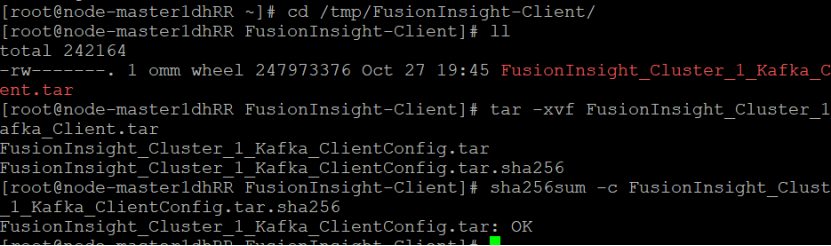
安装Kafka运行环境
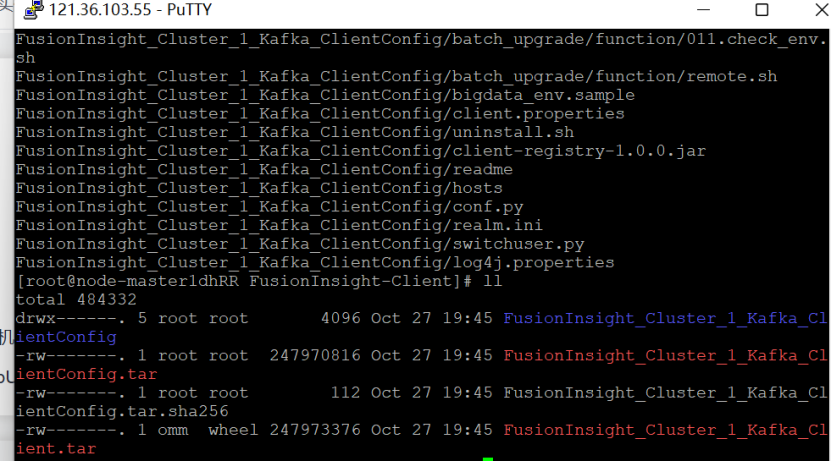
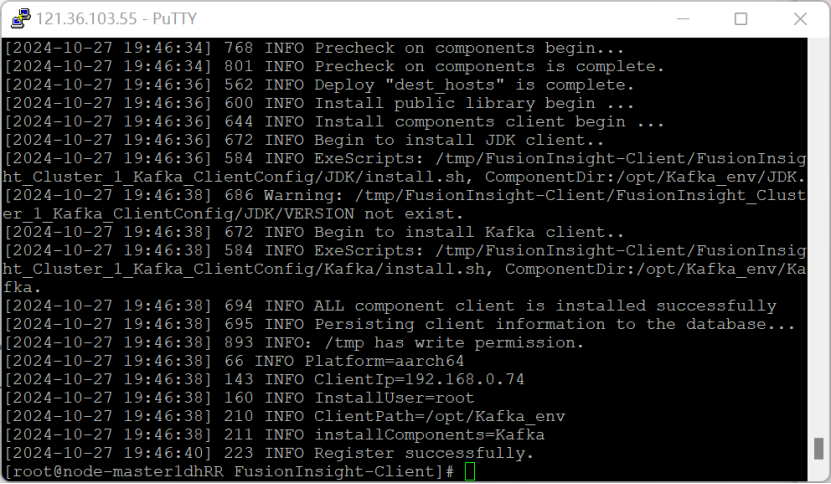
安装Kafka客户端

在kafka中创建topic


查看topic信息

安装 Flume 客户端
下载Flume客户端
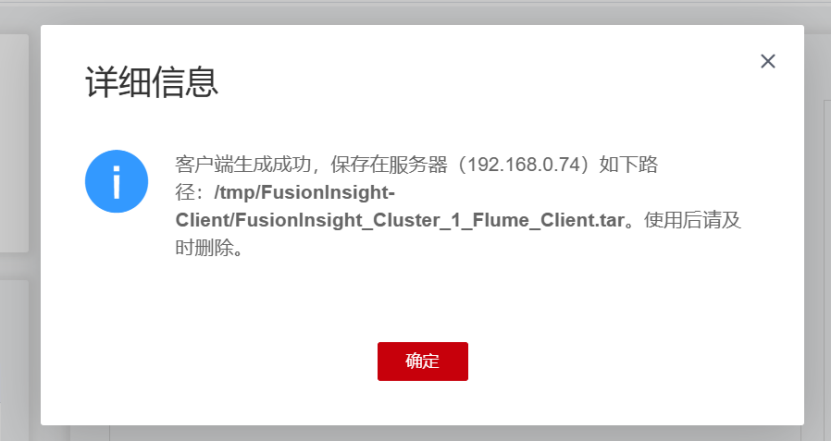
校验下载的客户端文件包

安装Flume运行环境
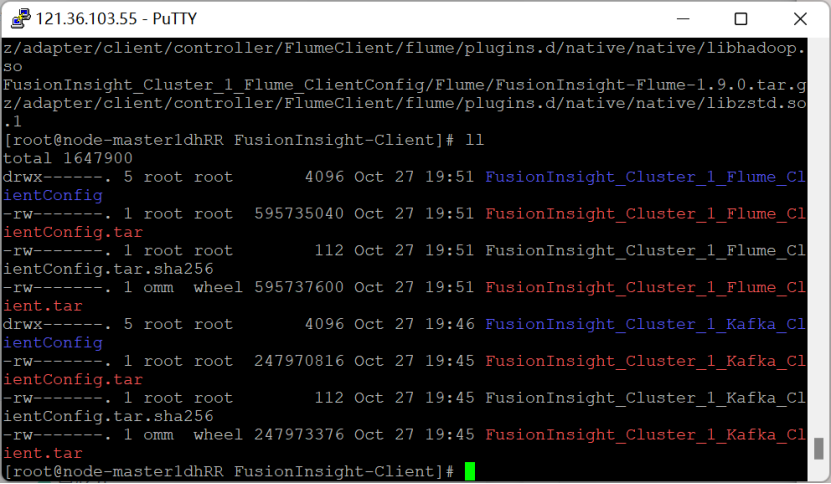

安装Flume客户端
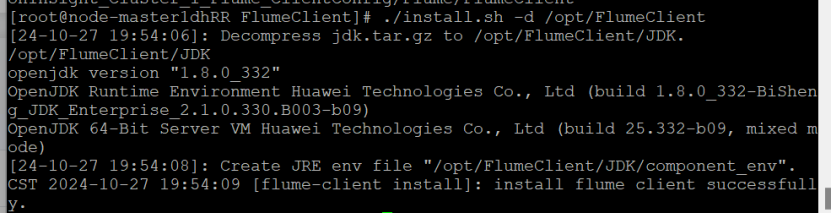
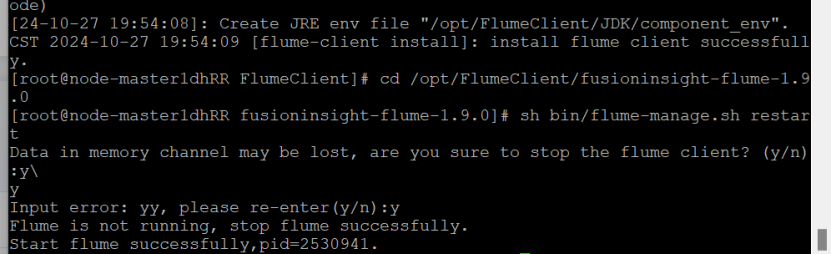
重启Flume服务
配置Flume采集数据