数据采集与融合技术实践第三次作业
作业1
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
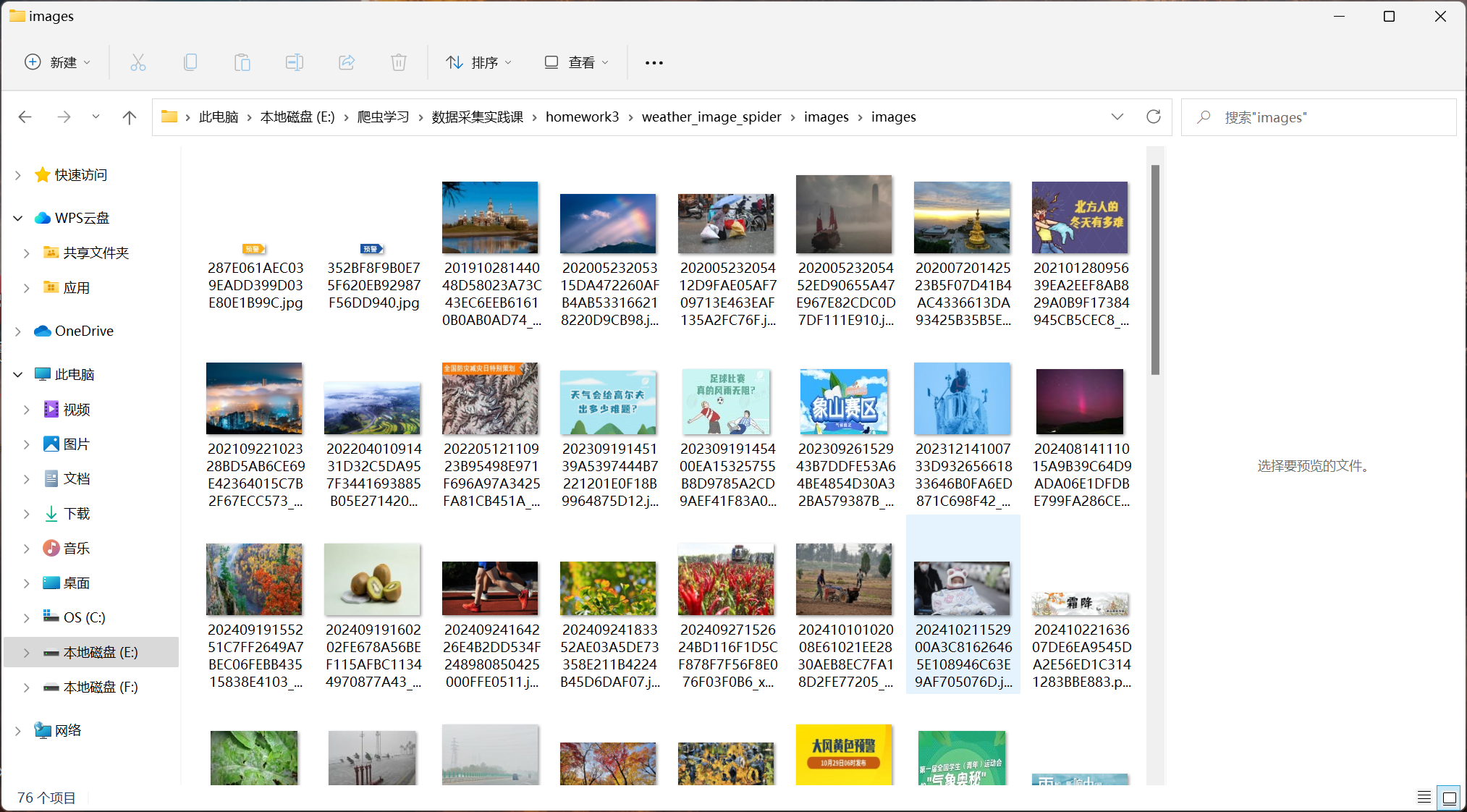
代码:
weather_images.py
import scrapy
import re
import os
from scrapy.http import Request
from weather_image_spider.items import WeatherImageSpiderItem
class WeatherImagesSpider(scrapy.Spider):
name = "weather_images"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn/"]
# 设置图片数量和页面限制
total_images = 125
total_pages = 25 # 按学号尾数设置总页数
images_downloaded = 0
pages_visited = 0
def parse(self, response):
# 获取页面中的链接
url_list = re.findall(r'<a href="(.*?)"', response.text, re.S)
for url in url_list:
if self.pages_visited >= self.total_pages:
break
self.pages_visited += 1
yield Request(url, callback=self.parse_images)
def parse_images(self, response):
img_list = re.findall(r'<img.*?src="(.*?)"', response.text, re.S)
for img_url in img_list:
if self.images_downloaded >= self.total_images:
break
self.images_downloaded += 1
print(f"正在保存第{self.images_downloaded}张图片 路径: {img_url}")
yield WeatherImageSpiderItem(image_urls=[img_url])
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
import os
class WeatherImagePipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None):
image_name = request.url.split('/')[-1]
return f'images/{image_name}'
settings.py
# Scrapy settings for weather_image_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = "weather_image_spider"
SPIDER_MODULES = ["weather_image_spider.spiders"]
NEWSPIDER_MODULE = "weather_image_spider.spiders"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "weather_image_spider (+http://www.yourdomain.com)"
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "weather_image_spider.middlewares.WeatherImageSpiderSpiderMiddleware": 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "weather_image_spider.middlewares.WeatherImageSpiderDownloaderMiddleware": 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "weather_image_spider.pipelines.WeatherImageSpiderPipeline": 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# 限制单线程
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 0.25 # 可以根据需要调整
# 激活图片管道
ITEM_PIPELINES = {
'weather_image_spider.pipelines.WeatherImagePipeline': 1,
}
IMAGES_STORE = './images'
心得体会:对于单线程爬取和多线程爬取的区别还不是很懂,我认为似乎就是在pipelines.py中CONCURRENT_REQUESTS是否被赋值
作业2
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
代码:
eastmoney.py
import scrapy
import json
from ..items import StockItem
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["eastmoney.com"]
def start_requests(self):
base_url1 = 'http://95.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404577990037157569_1696660645140'
base_url2 = '&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696660645141'
total_pages = 4 #爬取前4页
for page_number in range(1, total_pages + 1):
page_url = f"{base_url1}&pn={page_number}{base_url2}"
yield scrapy.Request(page_url, callback=self.parse)
def parse(self, response):
data = response.text
json_data = json.loads(data[data.find('{'):data.rfind('}') + 1])
stock_list = json_data['data']['diff']
for stock in stock_list:
item = StockItem()
item['code'] = stock['f12']
item['name'] = stock['f14']
item['latest_price'] = stock['f2']
item['change_percent'] = stock['f3']
item['change_amount'] = stock['f4']
item['volume'] = stock['f5']
item['turnover'] = stock['f6']
item['amplitude'] = stock['f7']
item['highest'] = stock['f15']
item['lowest'] = stock['f16']
item['open_price'] = stock['f17']
item['close_price'] = stock['f18']
yield item
items.py
import scrapy
class StockItem(scrapy.Item):
code = scrapy.Field()
name = scrapy.Field()
latest_price = scrapy.Field()
change_percent = scrapy.Field()
change_amount = scrapy.Field()
volume = scrapy.Field()
turnover = scrapy.Field()
amplitude = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
open_price = scrapy.Field()
close_price = scrapy.Field()
pipelines.py
import sqlite3
import MySQLdb # 引入 MySQLdb
class StockPipeline:
def __init__(self):
self.create_database()
def create_database(self):
self.conn = sqlite3.connect('stock.db')
self.cursor = self.conn.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
latest_price REAL,
change_percent REAL,
change_amount REAL,
volume INTEGER,
turnover REAL,
amplitude REAL,
highest REAL,
lowest REAL,
open_price REAL,
close_price REAL
)
''')
self.conn.commit()
def process_item(self, item, spider):
self.save_stock_data_to_database(item)
return item
def save_stock_data_to_database(self, item):
self.cursor.execute('''
INSERT INTO stocks (
code, name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, highest, lowest, open_price, close_price
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item['code'], item['name'], item['latest_price'], item['change_percent'],
item['change_amount'], item['volume'], item['turnover'], item['amplitude'],
item['highest'], item['lowest'], item['open_price'], item['close_price']
))
self.conn.commit()
def close_spider(self, spider):
self.conn.close()
class TerminalOutputPipeline(object):
def process_item(self, item, spider):
# 在终端输出数据
print(f"股票代码: {item['code']}")
print(f"股票名称: {item['name']}")
print(f"最新报价: {item['latest_price']}")
print(f"涨跌幅: {item['change_percent']}")
print(f"跌涨额: {item['change_amount']}")
print(f"成交量: {item['volume']}")
print(f"成交额: {item['turnover']}")
print(f"振幅: {item['amplitude']}")
print(f"最高: {item['highest']}")
print(f"最低: {item['lowest']}")
print(f"今开: {item['open_price']}")
print(f"昨收: {item['close_price']}")
return item
class MySQLPipeline:
def open_spider(self, spider):
# 初始化数据库连接
self.connection = MySQLdb.connect(
host='localhost', # 数据库主机名
user='root', # 数据库用户名
password='123456', # 数据库密码
db='stocks_db', # 数据库名称
charset='utf8mb4',
use_unicode=True
)
self.cursor = self.connection.cursor()
def close_spider(self, spider):
# 关闭数据库连接
self.connection.commit()
self.cursor.close()
self.connection.close()
def process_item(self, item, spider):
# 处理 item,并将其存入数据库
self.save_stock_data_to_database(item)
return item
def save_stock_data_to_database(self, item):
sql = '''INSERT INTO stocks (code, name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, highest, lowest, open_price, close_price)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'''
self.cursor.execute(sql, (
item['code'],
item['name'],
item['latest_price'],
item['change_percent'],
item['change_amount'],
item['volume'],
item['turnover'],
item['amplitude'],
item['highest'],
item['lowest'],
item['open_price'],
item['close_price']
))
settings.py
BOT_NAME = "stock_scraper"
SPIDER_MODULES = ["stock_scraper.spiders"]
NEWSPIDER_MODULE = "stock_scraper.spiders"
ITEM_PIPELINES = {
'stock_scraper.pipelines.MySQLPipeline': 2,
'stock_scraper.pipelines.StockPipeline': 1,
'stock_scraper.pipelines.TerminalOutputPipeline': 3,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
ROBOTSTXT_OBEY = False
输出信息:
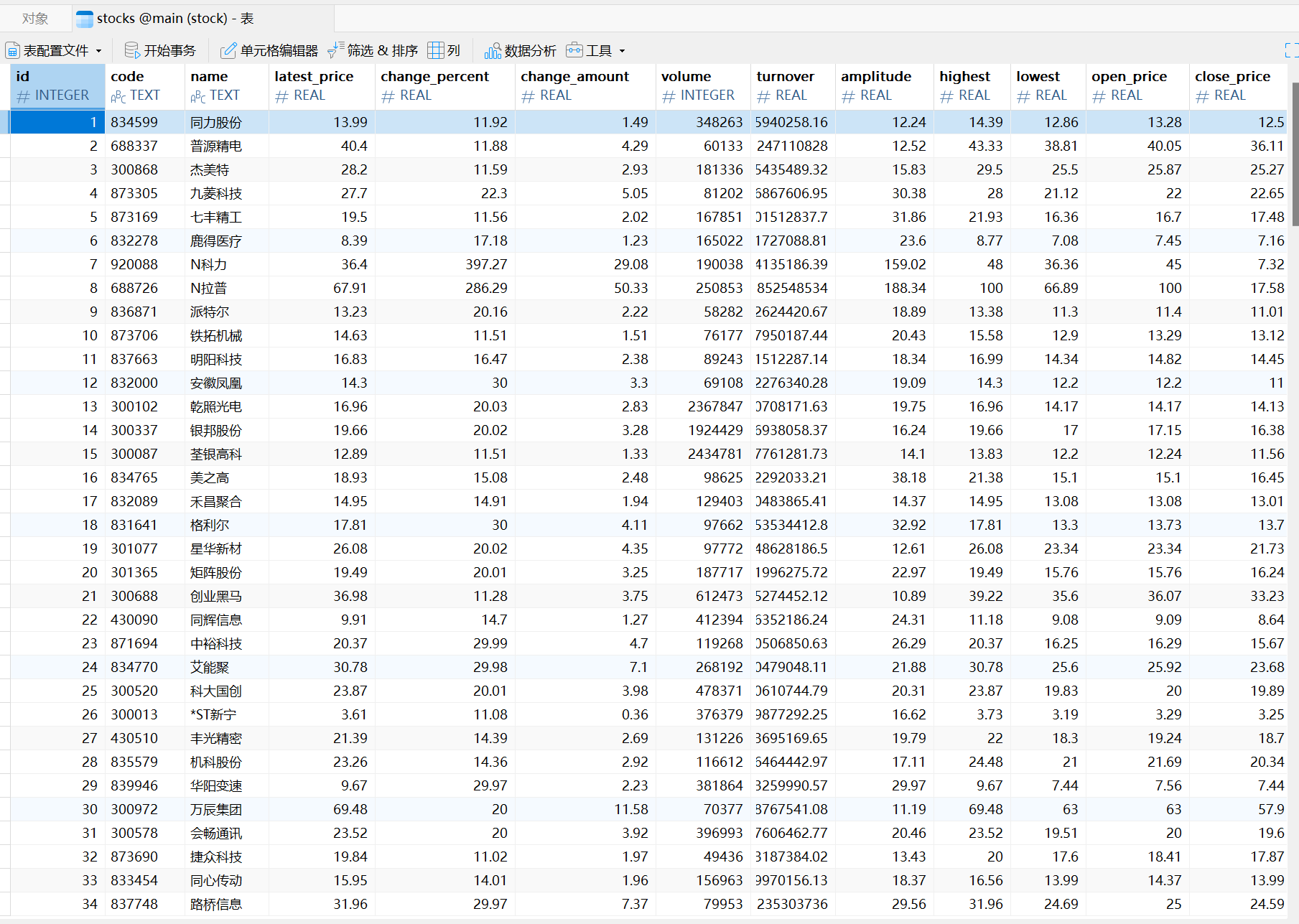
心得体会:这一题用时比较长,因为股票网页是动态的,开始的时候想的比较简单。后来用了F12抓包获取对应的XPATH后才取得了成功。至于对于上课时候讲的通过Selenium框架如何结合着操作,还未实践,听的也不是很懂。
作业3
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码:
bank.py
import scrapy
from bank.items import BankItem
class BankSpider(scrapy.Spider):
name = 'bank'
start_urls = ['https://www.boc.cn/sourcedb/whpj/index.html']
def start_requests(self):
num_pages = int(getattr(self, 'pages', 4))
for page in range(1, num_pages + 1):
if page == 1:
start_url = f'https://www.boc.cn/sourcedb/whpj/index.html'
else:
start_url = f'https://www.boc.cn/sourcedb/whpj/index_{page-1}.html'
yield scrapy.Request(start_url, callback=self.parse)
def parse(self, response):
bank_list = response.xpath('//tr[position()>1]')
for bank in bank_list:
item = BankItem()
item['Currency'] = bank.xpath('.//td[1]/text()').get()
item['TBP'] = bank.xpath('.//td[2]/text()').get()
item['CBP'] = bank.xpath('.//td[3]/text()').get()
item['TSP'] = bank.xpath('.//td[4]/text()').get()
item['CSP'] = bank.xpath('.//td[5]/text()').get()
item['Time'] = bank.xpath('.//td[8]/text()').get()
yield item
items.py
import scrapy
class BankItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
pipelines.py
from itemadapter import ItemAdapter
import sqlite3
class BankPipeline:
def open_spider(self, spider):
self.conn = sqlite3.connect('bank.db')
self.cursor = self.conn.cursor()
self.create_database()
def create_database(self):
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS banks (
Currency TEXT ,
TBP REAL,
CBP REAL,
TSP REAL,
CSP REAL,
Time TEXT
)
''')
self.conn.commit()
def process_item(self, item, spider):
self.cursor.execute('''
INSERT INTO banks (
Currency,
TBP,
CBP,
TSP,
CSP,
Time
) VALUES (?, ?, ?, ?, ?, ?)
''', (item['Currency'],item['TBP'],item['CBP'],item['TSP'],item['CSP'],item['Time'] ))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
settings.py
BOT_NAME = "bank"
SPIDER_MODULES = ["bank.spiders"]
NEWSPIDER_MODULE = "bank.spiders"
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 1
ITEM_PIPELINES = {
'bank.pipelines.BankPipeline': 300,
}
输出信息:
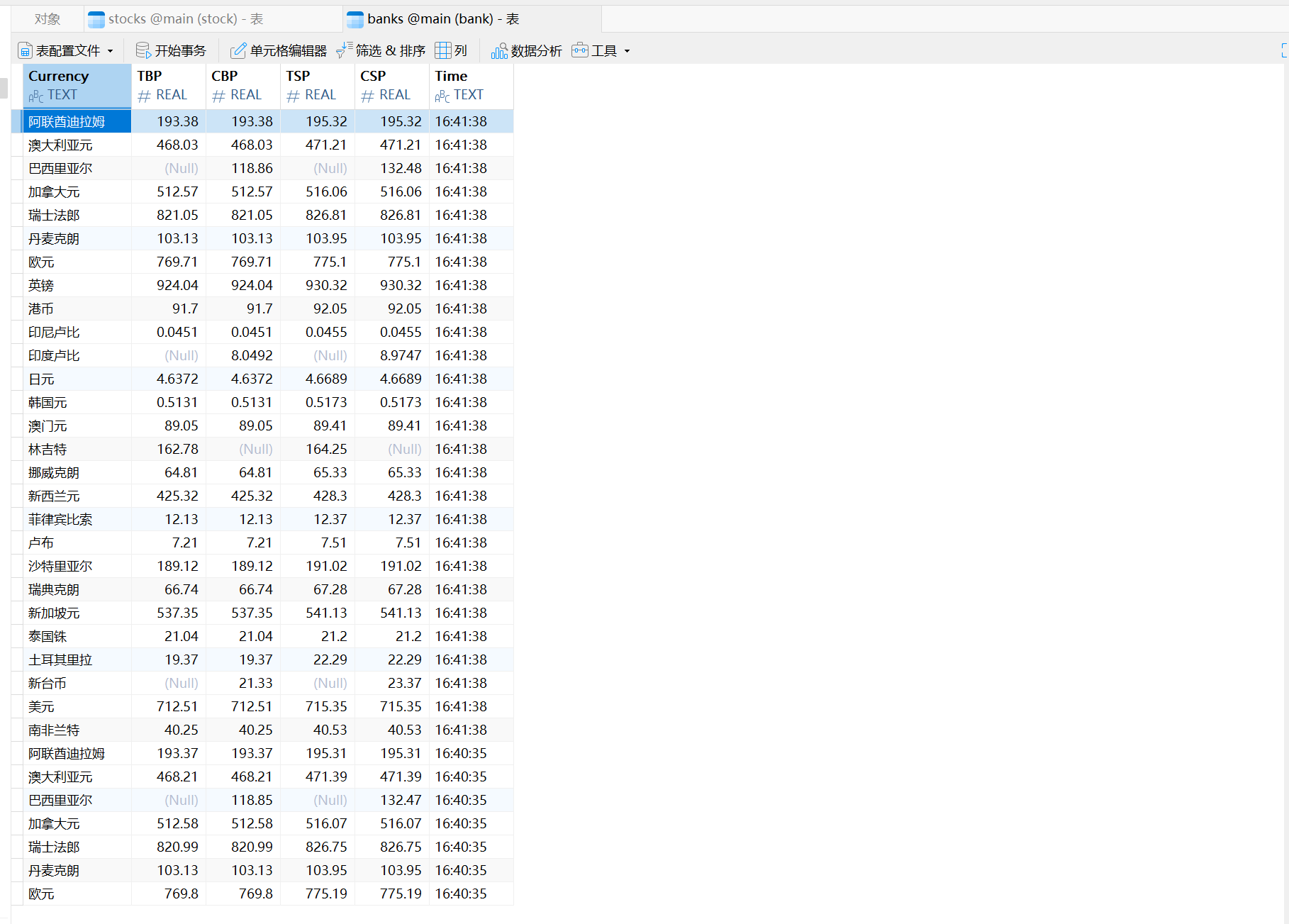
心得体会:做完第二题再来做第三题就会轻松许多了,主要加强了我对Scrapy框架和MySQL数据库(Sqlite3)操作的综合运用能力,最后我是在Navicat Prenium中进行了数据库中表的可视化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号