

数据采集第二次作业
码云仓库链接:https://gitee.com/fjpt-chen-siyu/crawl_project/tree/master/homework2
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
点击查看代码
import requests
import sqlite3
from bs4 import BeautifulSoup
# 定义要爬取的城市列表
cities = ['北京', '上海', '广州', '深圳', '杭州'] # 可以根据需要修改
# 创建SQLite数据库和表
conn = sqlite3.connect('weather.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS Weather (
city TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
''')
# 爬取每个城市的天气信息
for city in cities:
# 构造请求的URL
url = f'http://www.weather.com.cn/weather/{city}.shtml'
# 发起请求
response = requests.get(url)
if response.status_code == 200:
# 解析HTML页面
soup = BeautifulSoup(response.text, 'html.parser')
weather_data = soup.find_all('div', class_='t clearfix') # 根据实际页面结构调整
for day in weather_data:
date = day.find('h1').text # 日期
weather = day.find('p', class_='wea').text # 天气情况
temperature = day.find('p', class_='tem').text.strip() # 温度
# 保存数据到数据库
cursor.execute('''
INSERT INTO Weather (city, date, weather, temperature)
VALUES (?, ?, ?, ?)
''', (city, date, weather, temperature))
# 提交事务
conn.commit()
else:
print(f"请求失败,城市: {city}, 状态码: {response.status_code}")
# 关闭数据库连接
conn.close()
print("数据爬取完成,已保存至数据库。")
输出信息:
gitee文件链接:https://gitee.com/fjpt-chen-siyu/crawl_project/blob/master/homework2/weather.db
心得:
在该次代码中,引用了sqlite3库用于数据库操作,SQLite 是轻量级的嵌入式数据库,非常适合用于这种小型项目,数据量不大时无需部署复杂的数据库系统。创建本地 SQLite 数据库,并建立一个用于存储天气数据的表格。循环遍历每个城市,构造请求 URL,抓取对应城市的天气数据。最后解析天气数据并将其插入数据库。
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
点击查看代码
'''
数据来源:东方财富网-行情中心
https://quote.eastmoney.com/center
'''
import requests
import json
import os
import logging
from typing import List, Dict
import pandas as pd
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from tqdm import tqdm
# 设置日志配置
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("stock_fetch.log"),
logging.StreamHandler()
]
)
class StockFetcher:
def __init__(self, save_dir: str = "StockData", page_size: int = 20, retries: int = 5, delay_factor: float = 0.3):
self.api_url = "https://48.push2.eastmoney.com/api/qt/clist/get"
self.session = requests.Session()
retry_strategy = Retry(
total=retries,
backoff_factor=delay_factor,
status_forcelist=[500, 502, 503, 504],
allowed_methods=["GET"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount('http://', adapter)
self.session.mount('https://', adapter)
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/90.0.4430.93 Safari/537.36"
}
self.save_dir = save_dir
self.page_size = page_size
self.market_cmds = {
"A股市场": "m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"上证市场": "m:1+t:2,m:1+t:23",
"深证市场": "m:0+t:6,m:0+t:80",
}
self.fields = "f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
self.common_params = {
"cb": "callback",
"pn": 1,
"pz": self.page_size,
"po": 1,
"np": 1,
"ut": "bd1d9ddb04089700cf9c27f6f7426281",
"fltt": 2,
"invt": 2,
"dect": 1,
"wbp2u": "|0|0|0|web",
"fid": "f3",
"fields": self.fields,
"_": 0
}
# 创建保存目录
if not os.path.exists(self.save_dir):
os.makedirs(self.save_dir)
logging.info(f"创建目录: {self.save_dir}")
def fetch_data(self, market: str, page: int) -> Dict:
params = self.common_params.copy()
params.update({
"pn": page,
"fs": market,
"_": int(pd.Timestamp.now().timestamp() * 1000)
})
try:
response = self.session.get(self.api_url, headers=self.headers, params=params, timeout=10)
response.raise_for_status()
jsonp_text = response.text
json_text = jsonp_text[jsonp_text.find('(')+1 : jsonp_text.rfind(')')]
data = json.loads(json_text)
return data
except requests.RequestException as e:
logging.error(f"请求失败: {e}")
return {}
except json.JSONDecodeError as e:
logging.error(f"解析JSON失败: {e}")
return {}
def fetch_stocks(self, market: str, page: int) -> List[List[str]]:
data = self.fetch_data(market, page)
if not data or 'data' not in data or 'diff' not in data['data']:
logging.warning(f"无数据,市场: {market}, 页码: {page}")
return []
stock_list = []
for item in data['data']['diff']:
stock_info = [
item.get("f1", ""), # 序号
item.get("f2", ""), # 股票代码
item.get("f3", ""), # 股票名称
item.get("f4", ""), # 最新价格
item.get("f5", ""), # 涨跌额
item.get("f6", ""), # 涨跌幅
item.get("f7", ""), # 成交量
item.get("f8", ""), # 成交金额
item.get("f9", ""), # 振幅
item.get("f10", ""), # 最高价
item.get("f11", ""), # 最低价
item.get("f12", ""), # 今开
item.get("f13", ""), # 昨收
item.get("f14", ""), # 量比
item.get("f15", ""), # 换手率
item.get("f16", ""), # 市盈率
item.get("f17", ""), # 市净率
item.get("f18", ""), # 总市值
item.get("f20", ""), # 流通市值
item.get("f21", ""), # 涨停价
item.get("f22", ""), # 跌停价
item.get("f23", ""), # 涨速
item.get("f24", ""), # 52周最高价
item.get("f25", ""), # 52周最低价
item.get("f62", ""), # 每股收益
item.get("f128", ""), # 每股净资产
item.get("f136", ""), # 股东数
item.get("f115", ""), # 市销率
item.get("f152", "") # 数据时间
]
stock_list.append(stock_info)
return stock_list
def process_market(self, market_name: str, market_cmd: str):
logging.info(f"开始抓取市场: {market_name}")
page = 1
stock_data = []
progress_bar = tqdm(desc=f"抓取 {market_name}", unit="页")
while page <= 10: # 限制抓取页数为10
stocks = self.fetch_stocks(market_cmd, page)
if not stocks:
logging.info(f"市场 {market_name} 页码 {page} 无更多数据。")
break
stock_data.extend(stocks)
progress_bar.update(1)
if len(stocks) < self.page_size:
logging.info(f"市场 {market_name} 抓取到第 {page} 页,数据抓取完成。")
break
page += 1
progress_bar.close()
if stock_data:
df = pd.DataFrame(stock_data, columns=[
"序号", "代码", "名称", "最新价格", "涨跌额", "涨跌幅", "成交量", "成交额",
"振幅", "最高价", "最低价", "今开", "昨收", "量比", "换手率", "市盈率",
"市净率", "总市值", "流通市值", "涨停价", "跌停价", "涨速",
"52周最高价", "52周最低价", "每股收益", "每股净资产", "股东数",
"市销率", "数据时间"
])
df.dropna(subset=["代码"], inplace=True)
safe_market_name = "".join(c for c in market_name if c not in r'\/:*?"<>|')
file_path = os.path.join(self.save_dir, f"{safe_market_name}.xlsx")
try:
df.to_excel(file_path, index=False)
logging.info(f"保存文件 {file_path},共抓取 {len(stock_data)} 条记录。")
except Exception as e:
logging.error(f"文件保存失败: {e}")
else:
logging.warning(f"市场 {market_name} 无任何抓取数据。")
def run(self):
for market, market_cmd in self.market_cmds.items():
self.process_market(market, market_cmd)
logging.info("所有市场数据抓取完毕。")
def main():
fetcher = StockFetcher()
fetcher.run()
if __name__ == "__main__":
main()
输出信息:
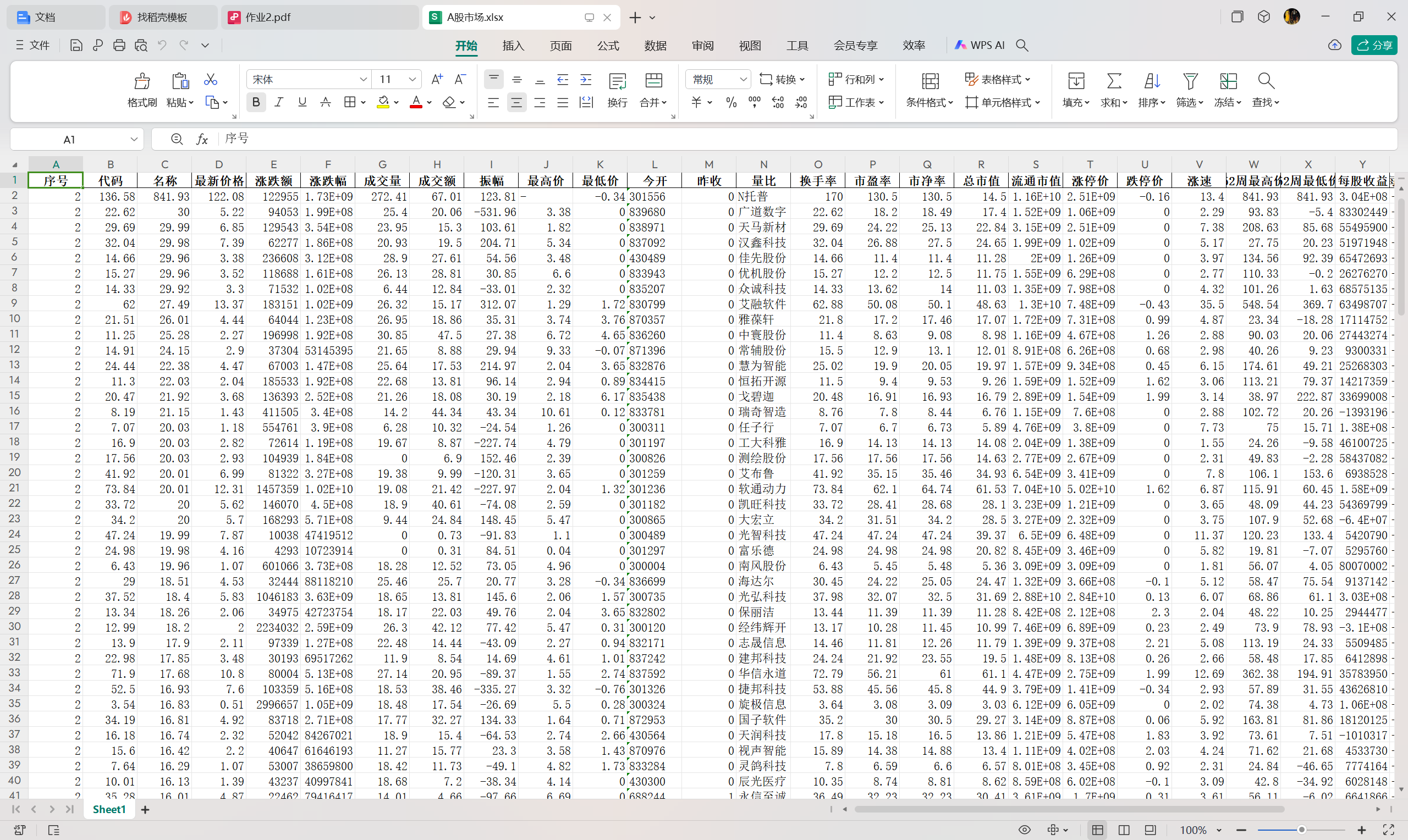
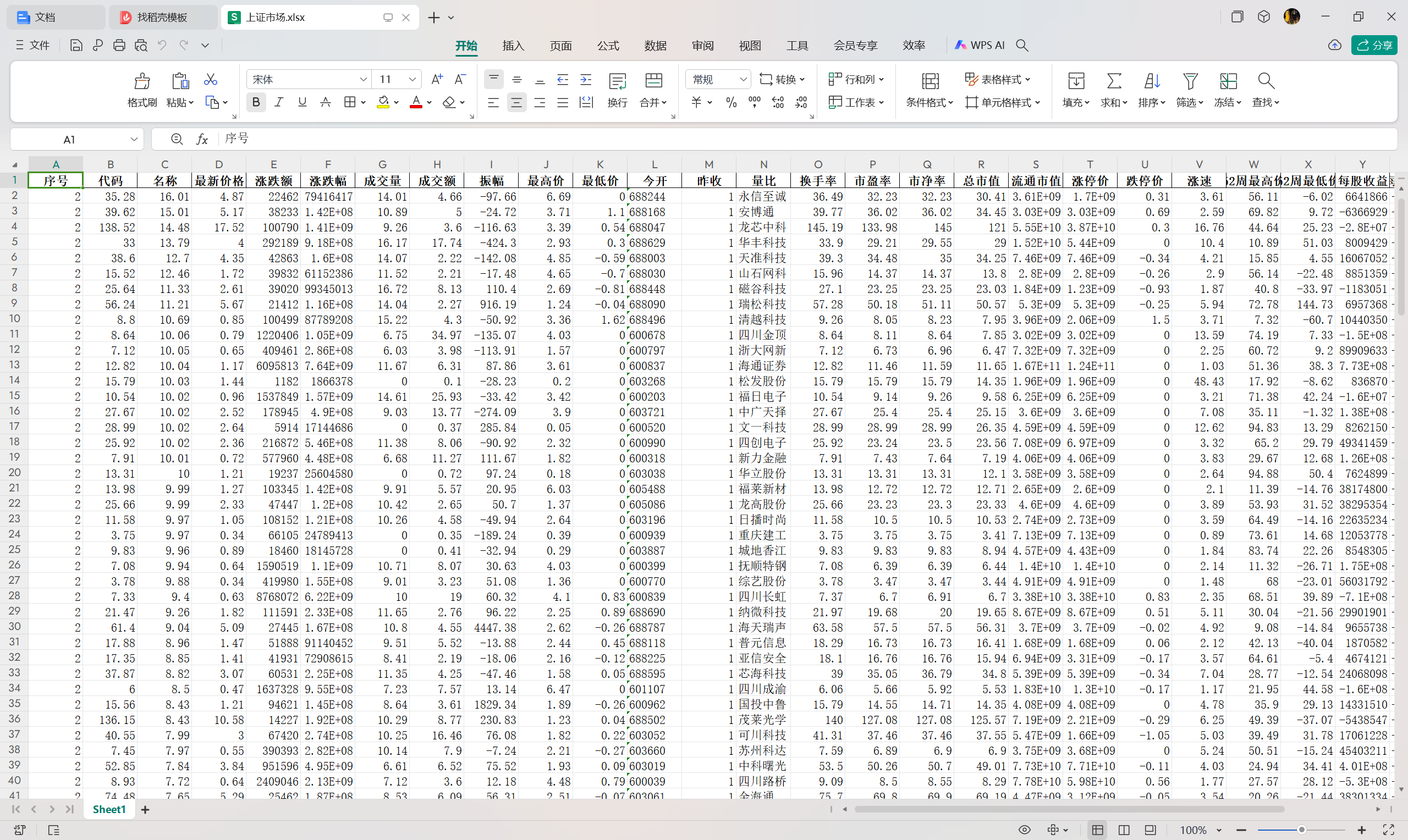
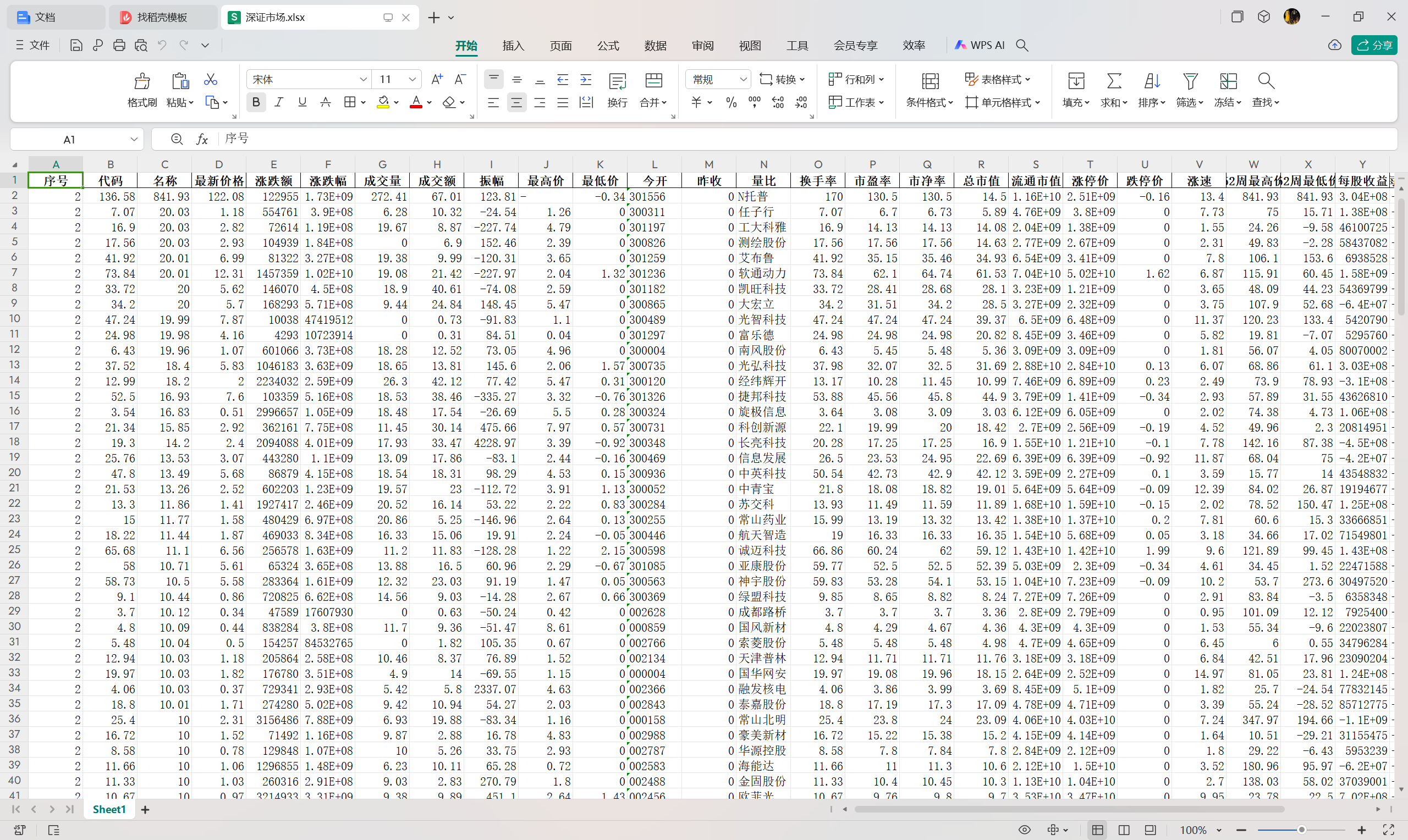
心得:
在这一部分中,最重要的就是通过网页F12的功能提取url并且进行分析,发现其中的pn为翻页信息,ts也是一个变化的项,所以针对这两个部分,需要着重进行变量设置。
作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
点击查看代码
import requests
import re
import sqlite3
class UniversityDatabase:
def __init__(self):
self.connection = sqlite3.connect("universities.db")
self.db_cursor = self.connection.cursor()
self.initialize_table()
def initialize_table(self):
self.db_cursor.execute("""
CREATE TABLE IF NOT EXISTS university_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER,
name TEXT,
province TEXT,
category TEXT,
score REAL
)
""")
self.connection.commit()
def close_connection(self):
self.connection.commit()
self.connection.close()
def bulk_insert(self, university_list):
self.db_cursor.executemany("""
INSERT INTO university_data (rank, name, province, category, score)
VALUES (?, ?, ?, ?, ?)
""", university_list)
self.connection.commit()
def display_data(self):
self.db_cursor.execute("SELECT * FROM university_data")
results = self.db_cursor.fetchall()
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format("Rank", "University", "Province", "Category", "Score"))
for record in results:
print("{:<10} {:<20} {:<15} {:<15} {:<10}".format(record[1], record[2], record[3], record[4], record[5]))
class UniversityRankings:
def __init__(self):
self.database = UniversityDatabase()
def get_web_content(self, url):
response = requests.get(url)
response.raise_for_status()
return response.text
def find_pattern(self, pattern, text):
return re.findall(pattern, text)
def extract_university_data(self, text_content):
university_names = self.find_pattern(r',univNameCn:"(.*?)",', text_content)
scores = self.find_pattern(r',score:(.*?),', text_content)
categories = self.find_pattern(r',univCategory:(.*?),', text_content)
provinces = self.find_pattern(r',province:(.*?),', text_content)
code_block = self.find_pattern(r'function(.*?){', text_content)[0]
code_items = code_block[code_block.find('a'):code_block.find('pE')].split(',')
mutation_block = self.find_pattern(r'mutations:(.*?);', text_content)[0]
mutation_values = mutation_block[mutation_block.find('(')+1:mutation_block.find(')')].split(",")
university_data = [
(i + 1, university_names[i], mutation_values[code_items.index(provinces[i])][1:-1],
mutation_values[code_items.index(categories[i])][1:-1], scores[i])
for i in range(len(university_names))
]
return university_data
def process_rankings(self, url):
try:
webpage_text = self.get_web_content(url)
university_data = self.extract_university_data(webpage_text)
self.database.bulk_insert(university_data)
except Exception as error:
print(f"Error processing data: {error}")
def display_university_data(self):
print("\nDisplaying university data from the database:\n")
self.database.display_data()
def close_database(self):
self.database.close_connection()
# Example usage
if __name__ == "__main__":
rankings = UniversityRankings()
target_url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
rankings.process_rankings(target_url)
rankings.display_university_data()
rankings.close_database()
print("Process completed")
print("Database output completed")
输出信息:
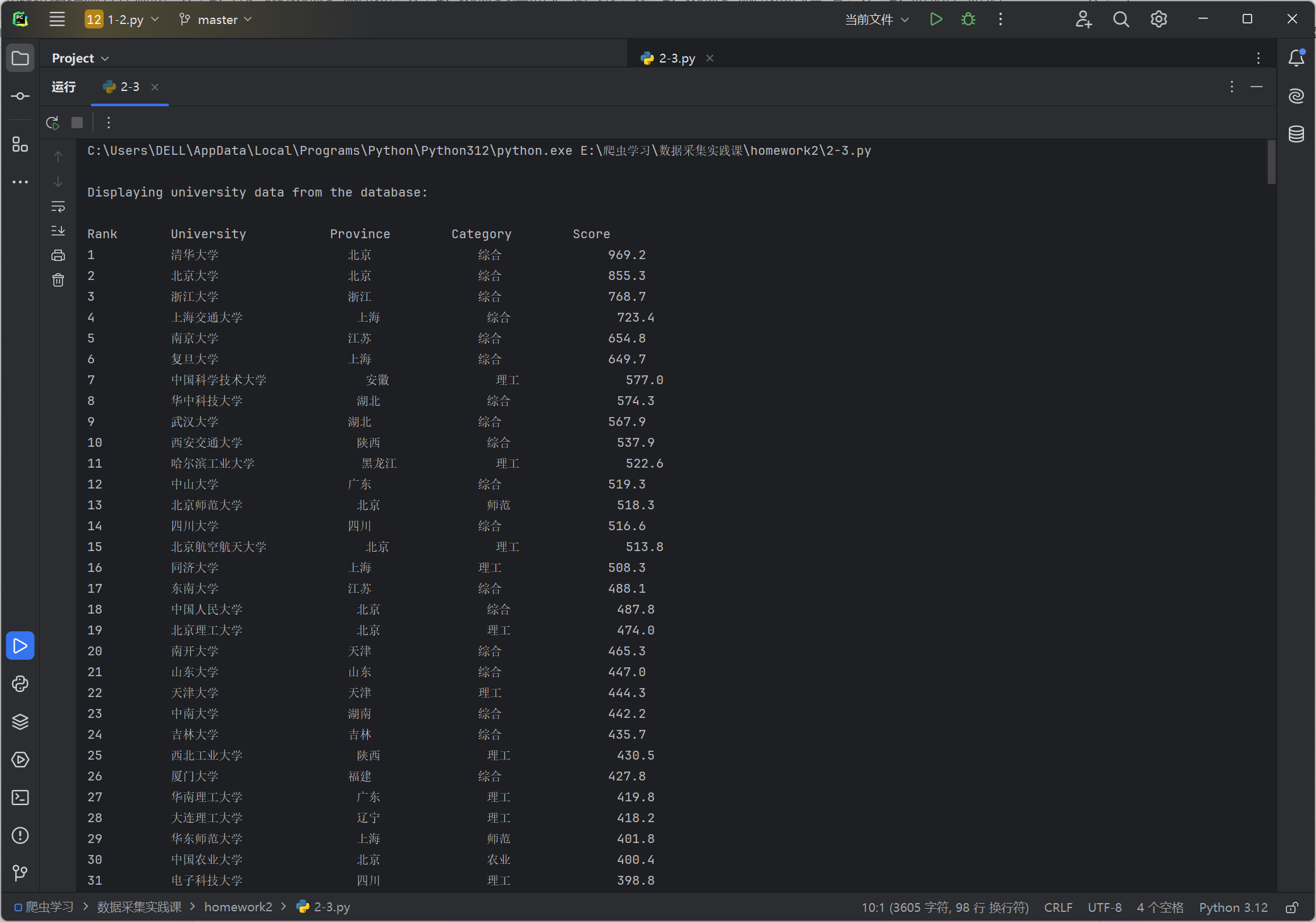

心得:
在这一部分的作业当中,我学会了如何分析网站的API,并且更加熟悉了F12开发者工具的使用
