
数据采集第一次作业
作业1:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
# 目标URL
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 发送请求获取网页内容
response = urllib.request.urlopen(url)
html_content = response.read()
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(html_content, 'html.parser')
# 找到排名信息所在的表格
# 从网页中找到合适的class标记,这里假设表格的class为'rankings'
table = soup.find('table', class_='rk-table')
# 提取表格内容
# 先找到表格的每一行
rows = table.find_all('tr')
# 打印标题
print(f"{'排名':<8}{'学校名称':<20}{'省市':<10}{'学校类型':<10}{'总分':<10}")
# 遍历表格的每一行,提取数据
for row in rows[1:]: # 跳过标题行
columns = row.find_all('td')
# 提取每一列的数据
rank = columns[0].get_text(strip=True) # 排名
name = columns[1].get_text(strip=True) # 学校名称
province = columns[2].get_text(strip=True) # 省市
school_type = columns[3].get_text(strip=True) # 学校类型
score = columns[4].get_text(strip=True) # 总分
# 打印排名信息
print(f"{rank:<8}{name:<20}{province:<10}{school_type:<10}{score:<10}")
完成图片:
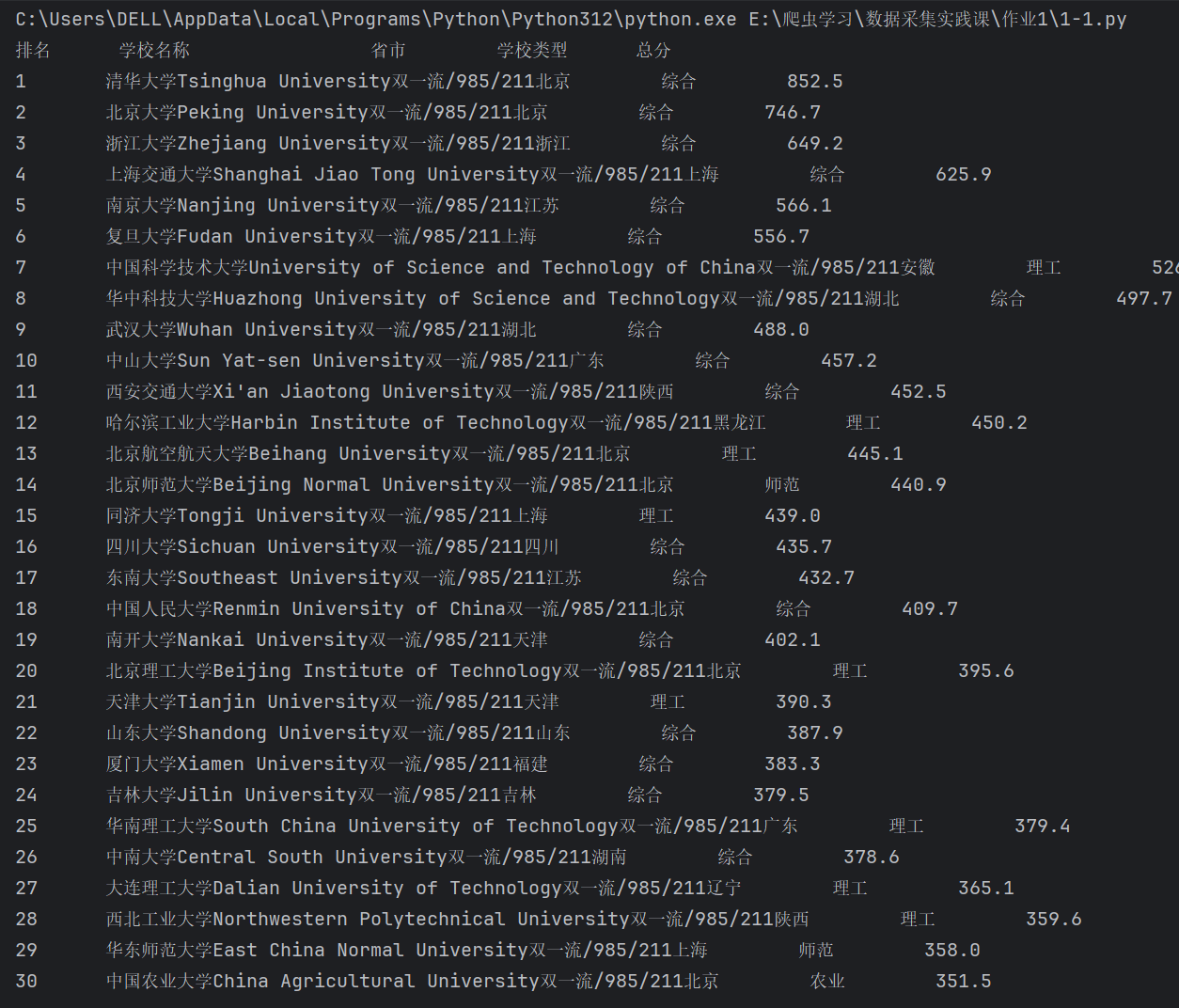
心得:使用 BeautifulSoup 解析 HTML 结构,提取表格中的排名信息。这种技术叫做 Web Scraping,可以用来自动化提取网站上的数据。接着通过 find 和 find_all 方法锁定需要提取的数据,最后清晰地打印出排名、学校名称、所在地、类型和分数等信息
作业2:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
点击查看代码
import urllib.request
import re
def fetchHTML(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
try:
request = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(request) as resp:
html_content = resp.read().decode()
return html_content
except Exception as error:
print(f"Failed to retrieve data from {url}: {error}")
return ""
def extractData(info_list, content):
prices = re.findall(r'"sku_price":"([\d.]+)"', content)
titles = re.findall(r'"ad_title_text":"(.*?)"', content)
limit = min(len(prices), len(titles))
for idx in range(limit):
price = prices[idx].replace('"', '')
name = titles[idx].strip('"')
info_list.append([len(info_list) + 1, price, name])
return info_list
def displayItems(info_list):
template = "{0:^5}\t{1:^10}\t{2:^20}"
print(template.format("Index", "Price", "Product Name"))
for item in info_list:
print(template.format(item[0], item[1], item[2]))
def main():
search_url = 'https://re.jd.com/search?keyword=%E4%B9%A6%E5%8C%85&enc=utf-8&page='
product_info = []
# Scraping pages 3 and 4
for page in range(3, 5):
url = f"{search_url}{page}"
content = fetchHTML(url)
if content:
extractData(product_info, content)
displayItems(product_info)
if __name__ == "__main__":
main()
完成图片:
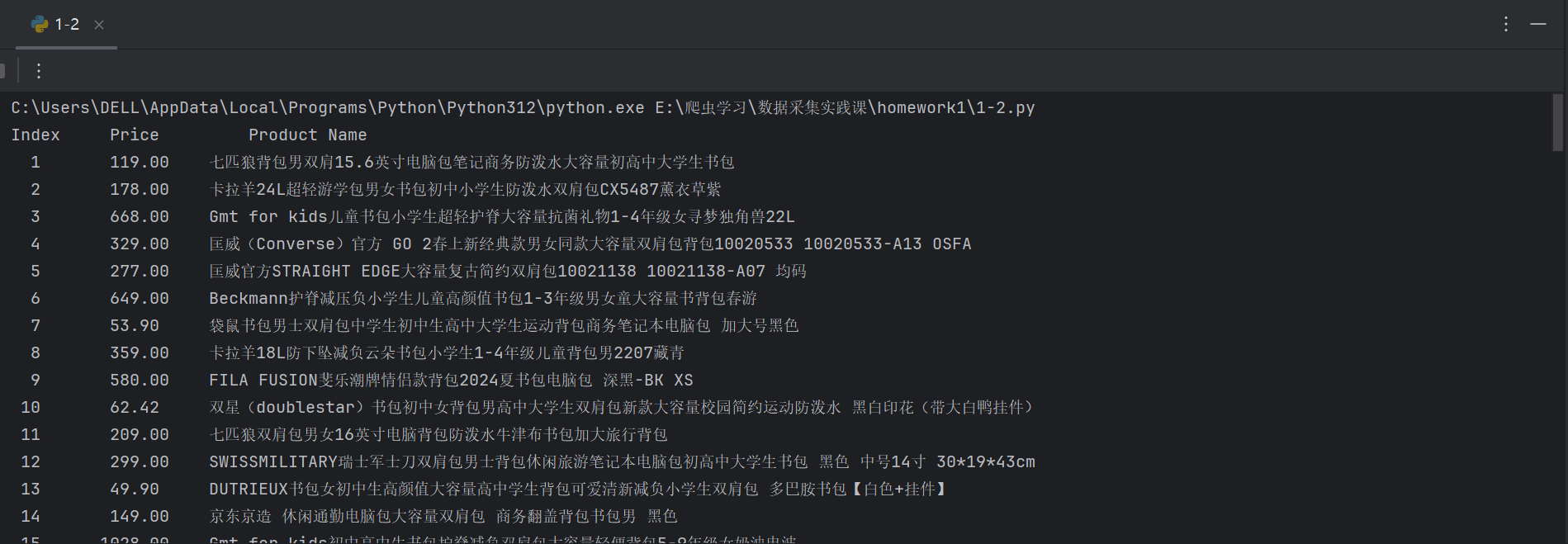
心得:在这当中,正则表达式匹配部分非常重要,商品的价格和名称需要保证正则表达式准确无误。并且应该遵循这类网站的爬取规则。
作业3:
要求:爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 忽略SSL警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 创建保存图片的文件夹
output_dir = 'downloaded_images'
os.makedirs(output_dir, exist_ok=True)
# 目标网页
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 发起请求并解析页面
response = requests.get(url, verify=False) # 禁用SSL证书验证
if response.status_code == 200:
# 解析页面
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有JPEG和JPG格式的图片链接
img_tags = soup.find_all('img')
image_urls = []
for img in img_tags:
img_src = img.get('src')
if img_src:
# 构造完整的URL
full_url = urljoin(url, img_src)
if full_url.lower().endswith(('.jpeg', '.jpg')):
image_urls.append(full_url)
# 下载图片
for img_url in image_urls:
try:
img_data = requests.get(img_url, verify=False).content # 禁用SSL证书验证
# 获取图片名称
img_name = os.path.basename(img_url)
# 保存图片
with open(os.path.join(output_dir, img_name), 'wb') as f:
f.write(img_data)
print(f'下载成功: {img_name}')
except Exception as e:
print(f'下载失败: {img_url} | 错误信息: {e}')
else:
print('请求失败,状态码:', response.status_code)
完成图片:

心得:这段代码是 Web Scraping 技术的进阶应用,它不仅抓取网页中的文本数据,还进一步抓取了网页上的图片资源。使用 BeautifulSoup 解析 HTML,找到所有图片的 标签,并提取它们的 src 属性。

