域名伪造检测
dnstwist
介绍
https://github.com/elceef/dnstwist
- 帮助了解用户在尝试键入您的域名时遇到的问题
- 找到类似的域
- 检测域名仿冒者,网络钓鱼攻击,欺诈和企业间谍活动。
- dnstwist作为目标威胁情报的另一个来源非常有用:将域名作为种子,生成潜在网络钓鱼域名列表,然后检查它们是否已注册。
- 测试来自MX记录的邮件服务器用于拦截企业电子邮件
- 可以生成网页的模糊哈希,查看它们是否是网络钓鱼站点
随着域的长度,算法生成的变体数量显着增加,因此验证它们所需的DNS查询数量也会增加。例如,要检查google.com的所有变体,您必须发送超过300k的查询。猜测要花费更多时间。对于较长的域,检查所有内容根本不可能。因此,此工具生成并检查非常接近原始域的域。
根据输入的域名生成一堆相似的域名,然后挨个检查这些相似的域名是否是有效且恶意的
特征
- 高效域模糊算法
dnstwist使用模糊散列(上下文触发的分段散列)。模糊散列是一种概念,它比较两个输入(在这种情况下是HTML代码)并确定基本相似度的能力。对于每个生成的域,dnstwist将从响应的HTTP服务器获取内容(遵循重定向)并将其模糊散列与原始(初始)域的模糊散列进行比较。相似程度将表示为百分比。
提供完整或部分URL地址,dnstwist将解析并申请每个生成的域名变体。
dnstwist.py --ssdeep https://example.com/owa/
dnstwist.py --ssdeep example.com/crm/login
- 使用模糊哈希评估网页相似性以查找实时网络钓鱼站点
- Unicode域名(IDN)
- 多线程作业分发
- 支持查询A,AAAA,NS和MX记录
- 测试MX主机(邮件服务器)是否可用于拦截误导的电子邮件
攻击者会设置电子邮件蜜罐,等待错误的电子邮件。攻击者会将其服务器配置为
清空发往该域的所有电子邮件,无论用户是向哪个用户发送的。dnstwist功能允许在每个邮件服务器上执行一个简单的测试(通过DNS MX记录公布),可疑服务器将标有SPYING-MX。有些邮件服务器只是假装接受错误地址的电子邮件,随后丢弃,用于防止目录收集攻击。
dnstwist.py --mxcheck example.com
- 使用字典文件的其他域变体
要生成更多域名变体,请向dnstwist提供字典文件,字典样本中包含目标网络钓鱼活动中使用的最常用单词列表。
dnstwist.py --dictionary dictionaries / english.dict example.com
- GeoIP位置信息(IP地理位置数据库,根据IP获得地理位置信息)
使用--geoip参数显示每个IPv4地址的地理位置(国家/地区名称)
- 抓取HTTP和SMTP服务banner
- WHOIS查找创建和修改日期
- 以CSV和JSON格式输出
输出案例
相似项目
Phishing Catcher:攻击者通过网络钓鱼手段,诱骗疏于防范的受害者泄露敏感信息。这是一种常见的攻击,这些黑客将他们伪造的网站、电子邮件和文本信息冒充为合法内容。反钓鱼威胁搜索工具Phishing Catcher可以近乎实时地将使用恶意传输层安全(TLS)证书的域名标注出来,它使用了一种标记语言(YAML)配置文件,为TLS证书域名中的字符串分配数字。传送门:https://github.com/x0rz/phishing_catcher
dnstwist源码分析
域名生成
insertion插入一个字符
_insertion把一个域名中的每个字母前后插入一个相邻的键盘字母,并返回一个集合。
点击查看代码
def _insertion(self):
result = set()
for i in range(1, len(self.domain)-1):
prefix, orig_c, suffix = self.domain[:i], self.domain[i], self.domain[i+1:]
for c in (c for keys in self.keyboards for c in keys.get(orig_c, [])):
result.update({
prefix + c + orig_c + suffix,
prefix + orig_c + c + suffix
})
return result
qwerty = {
'1': '2q', '2': '3wq1', '3': '4ew2', '4': '5re3', '5': '6tr4', '6': '7yt5', '7': '8uy6', '8': '9iu7', '9': '0oi8', '0': 'po9',
'q': '12wa', 'w': '3esaq2', 'e': '4rdsw3', 'r': '5tfde4', 't': '6ygfr5', 'y': '7uhgt6', 'u': '8ijhy7', 'i': '9okju8', 'o': '0plki9', 'p': 'lo0',
'a': 'qwsz', 's': 'edxzaw', 'd': 'rfcxse', 'f': 'tgvcdr', 'g': 'yhbvft', 'h': 'ujnbgy', 'j': 'ikmnhu', 'k': 'olmji', 'l': 'kop',
'z': 'asx', 'x': 'zsdc', 'c': 'xdfv', 'v': 'cfgb', 'b': 'vghn', 'n': 'bhjm', 'm': 'njk'
}
qwertz = {
'1': '2q', '2': '3wq1', '3': '4ew2', '4': '5re3', '5': '6tr4', '6': '7zt5', '7': '8uz6', '8': '9iu7', '9': '0oi8', '0': 'po9',
'q': '12wa', 'w': '3esaq2', 'e': '4rdsw3', 'r': '5tfde4', 't': '6zgfr5', 'z': '7uhgt6', 'u': '8ijhz7', 'i': '9okju8', 'o': '0plki9', 'p': 'lo0',
'a': 'qwsy', 's': 'edxyaw', 'd': 'rfcxse', 'f': 'tgvcdr', 'g': 'zhbvft', 'h': 'ujnbgz', 'j': 'ikmnhu', 'k': 'olmji', 'l': 'kop',
'y': 'asx', 'x': 'ysdc', 'c': 'xdfv', 'v': 'cfgb', 'b': 'vghn', 'n': 'bhjm', 'm': 'njk'
}
azerty = {
'1': '2a', '2': '3za1', '3': '4ez2', '4': '5re3', '5': '6tr4', '6': '7yt5', '7': '8uy6', '8': '9iu7', '9': '0oi8', '0': 'po9',
'a': '2zq1', 'z': '3esqa2', 'e': '4rdsz3', 'r': '5tfde4', 't': '6ygfr5', 'y': '7uhgt6', 'u': '8ijhy7', 'i': '9okju8', 'o': '0plki9', 'p': 'lo0m',
'q': 'zswa', 's': 'edxwqz', 'd': 'rfcxse', 'f': 'tgvcdr', 'g': 'yhbvft', 'h': 'ujnbgy', 'j': 'iknhu', 'k': 'olji', 'l': 'kopm', 'm': 'lp',
'w': 'sxq', 'x': 'wsdc', 'c': 'xdfv', 'v': 'cfgb', 'b': 'vghn', 'n': 'bhj'
}
keyboards = [qwerty, qwertz, azerty]
qwerty, qwertz, azerty是三种键盘布局

replacement更换部分词
_replacement把一个域名中的每个字母替换成相邻的键盘字母,并生成一个新的域名。这个函数使用了yield关键字,表示它是一个生成器函数,可以返回多个值。
点击查看代码
def _replacement(self):
for i, c in enumerate(self.domain):
pre = self.domain[:i]
suf = self.domain[i+1:]
for layout in self.keyboards:
for r in layout.get(c, ''):
yield pre + r + suf
bitsquatting替换一个单词
_bitsquatting生成一些域名,域名只有一个比特位和原始域名不同。这是一种利用DNS请求中可能发生的比特翻转错误的网络攻击手段,称为bitsquatting。例如,如果原始域名是bing.com,那么这个函数会生成如下的bitsquat域名:bing.com -> bing.con
点击查看代码
def _bitsquatting(self):
masks = [1, 2, 4, 8, 16, 32, 64, 128]
chars = set('abcdefghijklmnopqrstuvwxyz0123456789-')
for i, c in enumerate(self.domain):
for mask in masks:
b = chr(ord(c) ^ mask)
if b in chars:
yield self.domain[:i] + b + self.domain[i+1:]
homograph同形异义字
_cyrillic把一个域名中的拉丁字母替换成相似的西里尔字母。这是一种利用用户难以区分不同字母表的网络攻击手段,称为homograph attack。
点击查看代码
def _cyrillic(self):
cdomain = self.domain
for l, c in self.latin_to_cyrillic.items():
cdomain = cdomain.replace(l, c)
for c, l in zip(cdomain, self.domain):
if c == l:
return []
return [cdomain]
latin_to_cyrillic = {
'a': 'а', 'b': 'ь', 'c': 'с', 'd': 'ԁ', 'e': 'е', 'g': 'ԍ', 'h': 'һ',
'i': 'і', 'j': 'ј', 'k': 'к', 'l': 'ӏ', 'm': 'м', 'o': 'о', 'p': 'р',
'q': 'ԛ', 's': 'ѕ', 't': 'т', 'v': 'ѵ', 'w': 'ԝ', 'x': 'х', 'y': 'у',
}
_homoglyph把一个域名中的某些字母替换成外观相似的其他字母。这也是一种利用用户难以区分不同字母表的网络攻击手段,称为homoglyph attack。
点击查看代码
def _homoglyph(self):
md = lambda a, b: {k: set(a.get(k, [])) | set(b.get(k, [])) for k in set(a.keys()) | set(b.keys())}
glyphs = md(self.glyphs_ascii, self.glyphs_idn_by_tld.get(self.tld, self.glyphs_unicode))
def mix(domain):
for w in range(1, len(domain)):
for i in range(len(domain)-w+1):
pre = domain[:i]
win = domain[i:i+w]
suf = domain[i+w:]
for c in (set(win) | {win[:2]}):
for g in glyphs.get(c, []):
yield pre + win.replace(c, g) + suf
result1 = set(mix(self.domain))
result2 = set()
for r in result1:
result2.update(set(mix(r)))
return result1 | result2
def domain_tld(domain):
try:
from tld import parse_tld
except ImportError:
ctld = ['org', 'com', 'net', 'gov', 'edu', 'co', 'mil', 'nom', 'ac', 'info', 'biz']
d = domain.rsplit('.', 3)
if len(d) < 2:
return '', d[0], ''
if len(d) == 2:
return '', d[0], d[1]
if len(d) > 2:
if d[-2] in ctld:
return '.'.join(d[:-3]), d[-3], '.'.join(d[-2:])
else:
return '.'.join(d[:-2]), d[-2], d[-1]
else:
d = parse_tld(domain, fix_protocol=True)[::-1]
if d[1:] == d[:-1] and None in d:
d = tuple(domain.rsplit('.', 2))
d = ('',) * (3-len(d)) + d
return d
glyphs_ascii = {
'0': ('o',),
'1': ('l', 'i'),
'3': ('8',),
'6': ('9',),
'8': ('3',),
'9': ('6',),
'b': ('d', 'lb'),
'c': ('e',),
'd': ('b', 'cl', 'dl'),
'e': ('c',),
'g': ('q',),
'h': ('lh'),
'i': ('1', 'l'),
'k': ('lc'),
'l': ('1', 'i'),
'm': ('n', 'nn', 'rn', 'rr'),
'n': ('m', 'r'),
'o': ('0',),
'q': ('g',),
'w': ('vv',),
}
glyphs_unicode = {
'2': ('ƻ',),
'3': ('ʒ',),
'5': ('ƽ',),
'a': ('ạ', 'ă', 'ȧ', 'ɑ', 'å', 'ą', 'â', 'ǎ', 'á', 'ə', 'ä', 'ã', 'ā', 'à'),
'b': ('ḃ', 'ḅ', 'ƅ', 'ʙ', 'ḇ', 'ɓ'),
'c': ('č', 'ᴄ', 'ċ', 'ç', 'ć', 'ĉ', 'ƈ'),
'd': ('ď', 'ḍ', 'ḋ', 'ɖ', 'ḏ', 'ɗ', 'ḓ', 'ḑ', 'đ'),
'e': ('ê', 'ẹ', 'ę', 'è', 'ḛ', 'ě', 'ɇ', 'ė', 'ĕ', 'é', 'ë', 'ē', 'ȩ'),
'f': ('ḟ', 'ƒ'),
'g': ('ǧ', 'ġ', 'ǵ', 'ğ', 'ɡ', 'ǥ', 'ĝ', 'ģ', 'ɢ'),
'h': ('ȟ', 'ḫ', 'ḩ', 'ḣ', 'ɦ', 'ḥ', 'ḧ', 'ħ', 'ẖ', 'ⱨ', 'ĥ'),
'i': ('ɩ', 'ǐ', 'í', 'ɪ', 'ỉ', 'ȋ', 'ɨ', 'ï', 'ī', 'ĩ', 'ị', 'î', 'ı', 'ĭ', 'į', 'ì'),
'j': ('ǰ', 'ĵ', 'ʝ', 'ɉ'),
'k': ('ĸ', 'ǩ', 'ⱪ', 'ḵ', 'ķ', 'ᴋ', 'ḳ'),
'l': ('ĺ', 'ł', 'ɫ', 'ļ', 'ľ'),
'm': ('ᴍ', 'ṁ', 'ḿ', 'ṃ', 'ɱ'),
'n': ('ņ', 'ǹ', 'ń', 'ň', 'ṅ', 'ṉ', 'ṇ', 'ꞑ', 'ñ', 'ŋ'),
'o': ('ö', 'ó', 'ȯ', 'ỏ', 'ô', 'ᴏ', 'ō', 'ò', 'ŏ', 'ơ', 'ő', 'õ', 'ọ', 'ø'),
'p': ('ṗ', 'ƿ', 'ƥ', 'ṕ'),
'q': ('ʠ',),
'r': ('ʀ', 'ȓ', 'ɍ', 'ɾ', 'ř', 'ṛ', 'ɽ', 'ȑ', 'ṙ', 'ŗ', 'ŕ', 'ɼ', 'ṟ'),
's': ('ṡ', 'ș', 'ŝ', 'ꜱ', 'ʂ', 'š', 'ś', 'ṣ', 'ş'),
't': ('ť', 'ƫ', 'ţ', 'ṭ', 'ṫ', 'ț', 'ŧ'),
'u': ('ᴜ', 'ų', 'ŭ', 'ū', 'ű', 'ǔ', 'ȕ', 'ư', 'ù', 'ů', 'ʉ', 'ú', 'ȗ', 'ü', 'û', 'ũ', 'ụ'),
'v': ('ᶌ', 'ṿ', 'ᴠ', 'ⱴ', 'ⱱ', 'ṽ'),
'w': ('ᴡ', 'ẇ', 'ẅ', 'ẃ', 'ẘ', 'ẉ', 'ⱳ', 'ŵ', 'ẁ'),
'x': ('ẋ', 'ẍ'),
'y': ('ŷ', 'ÿ', 'ʏ', 'ẏ', 'ɏ', 'ƴ', 'ȳ', 'ý', 'ỿ', 'ỵ'),
'z': ('ž', 'ƶ', 'ẓ', 'ẕ', 'ⱬ', 'ᴢ', 'ż', 'ź', 'ʐ'),
'ae': ('æ',),
'oe': ('œ',),
}
hyphenation连接符断字
_hyphenation把一个域名中的任意一个位置插入一个连字符,并返回一个集合。
点击查看代码
def _hyphenation(self):
return {self.domain[:i] + '-' + self.domain[i:] for i in range(1, len(self.domain))}
omission删除部分词:www.btu.edu.cn
_omission把一个域名中的每个字母删除,并返回一个集合。
点击查看代码
def _omission(self):
return {self.domain[:i] + self.domain[i+1:] for i in range(len(self.domain))}
tld-swapTLD域名交换
transposition部分词换位
_transposition把一个域名中的每两个相邻的字母交换位置,并返回一个集合。
点击查看代码
def _transposition(self):
return {self.domain[:i] + self.domain[i+1] + self.domain[i] + self.domain[i+2:] for i in range(len(self.domain)-1)}
vowel-swap元音交换
subdomain子域名
_subdomain函数把一个域名中的每个字母前面插入一个点号,并生成一个新的域名。这个函数有一个条件,就是插入点号的位置不能是域名的开头或结尾,也不能是已经有点号或连字符的位置。
点击查看代码
def _subdomain(self):
for i in range(1, len(self.domain)-1):
if self.domain[i] not in ['-', '.'] and self.domain[i-1] not in ['-', '.']:
yield self.domain[:i] + '.' + self.domain[i:]
various删除次级域名:bjtuedu.cn

点击查看代码
glyphs_idn_by_tld = {
**dict.fromkeys(['cz', 'sk', 'uk', 'co.uk', 'nl', 'edu'], {
# IDN not suported by the corresponding registry
}),
**dict.fromkeys(['br'], {
'a': ('à', 'á', 'â', 'ã'),
'c': ('ç',),
'e': ('é', 'ê'),
'i': ('í',),
'o': ('ó', 'ô', 'õ'),
'u': ('ú', 'ü'),
'y': ('ý', 'ÿ'),
}),
**dict.fromkeys(['dk'], {
'a': ('ä', 'å'),
'e': ('é',),
'o': ('ö', 'ø'),
'u': ('ü',),
'ae': ('æ',),
}),
**dict.fromkeys(['eu', 'de', 'pl'], {
'a': ('á', 'à', 'ă', 'â', 'å', 'ä', 'ã', 'ą', 'ā'),
'c': ('ć', 'ĉ', 'č', 'ċ', 'ç'),
'd': ('ď', 'đ'),
'e': ('é', 'è', 'ĕ', 'ê', 'ě', 'ë', 'ė', 'ę', 'ē'),
'g': ('ğ', 'ĝ', 'ġ', 'ģ'),
'h': ('ĥ', 'ħ'),
'i': ('í', 'ì', 'ĭ', 'î', 'ï', 'ĩ', 'į', 'ī'),
'j': ('ĵ',),
'k': ('ķ', 'ĸ'),
'l': ('ĺ', 'ľ', 'ļ', 'ł'),
'n': ('ń', 'ň', 'ñ', 'ņ'),
'o': ('ó', 'ò', 'ŏ', 'ô', 'ö', 'ő', 'õ', 'ø', 'ō'),
'r': ('ŕ', 'ř', 'ŗ'),
's': ('ś', 'ŝ', 'š', 'ş'),
't': ('ť', 'ţ', 'ŧ'),
'u': ('ú', 'ù', 'ŭ', 'û', 'ů', 'ü', 'ű', 'ũ', 'ų', 'ū'),
'w': ('ŵ',),
'y': ('ý', 'ŷ', 'ÿ'),
'z': ('ź', 'ž', 'ż'),
'ae': ('æ',),
'oe': ('œ',),
}),
**dict.fromkeys(['fi'], {
'3': ('ʒ',),
'a': ('á', 'ä', 'å', 'â'),
'c': ('č',),
'd': ('đ',),
'g': ('ǧ', 'ǥ'),
'k': ('ǩ',),
'n': ('ŋ',),
'o': ('õ', 'ö'),
's': ('š',),
't': ('ŧ',),
'z': ('ž',),
}),
**dict.fromkeys(['no'], {
'a': ('á', 'à', 'ä', 'å'),
'c': ('č', 'ç'),
'e': ('é', 'è', 'ê'),
'i': ('ï',),
'n': ('ŋ', 'ń', 'ñ'),
'o': ('ó', 'ò', 'ô', 'ö', 'ø'),
's': ('š',),
't': ('ŧ',),
'u': ('ü',),
'z': ('ž',),
'ae': ('æ',),
}),
**dict.fromkeys(['be', 'fr', 're', 'yt', 'pm', 'wf', 'tf', 'ch', 'li'], {
'a': ('à', 'á', 'â', 'ã', 'ä', 'å'),
'c': ('ç',),
'e': ('è', 'é', 'ê', 'ë'),
'i': ('ì', 'í', 'î', 'ï'),
'n': ('ñ',),
'o': ('ò', 'ó', 'ô', 'õ', 'ö'),
'u': ('ù', 'ú', 'û', 'ü'),
'y': ('ý', 'ÿ'),
'ae': ('æ',),
'oe': ('œ',),
}),
**dict.fromkeys(['ca'], {
'a': ('à', 'â'),
'c': ('ç',),
'e': ('è', 'é', 'ê', 'ë'),
'i': ('î', 'ï'),
'o': ('ô',),
'u': ('ù', 'û', 'ü'),
'y': ('ÿ',),
'ae': ('æ',),
'oe': ('œ',),
}),
}
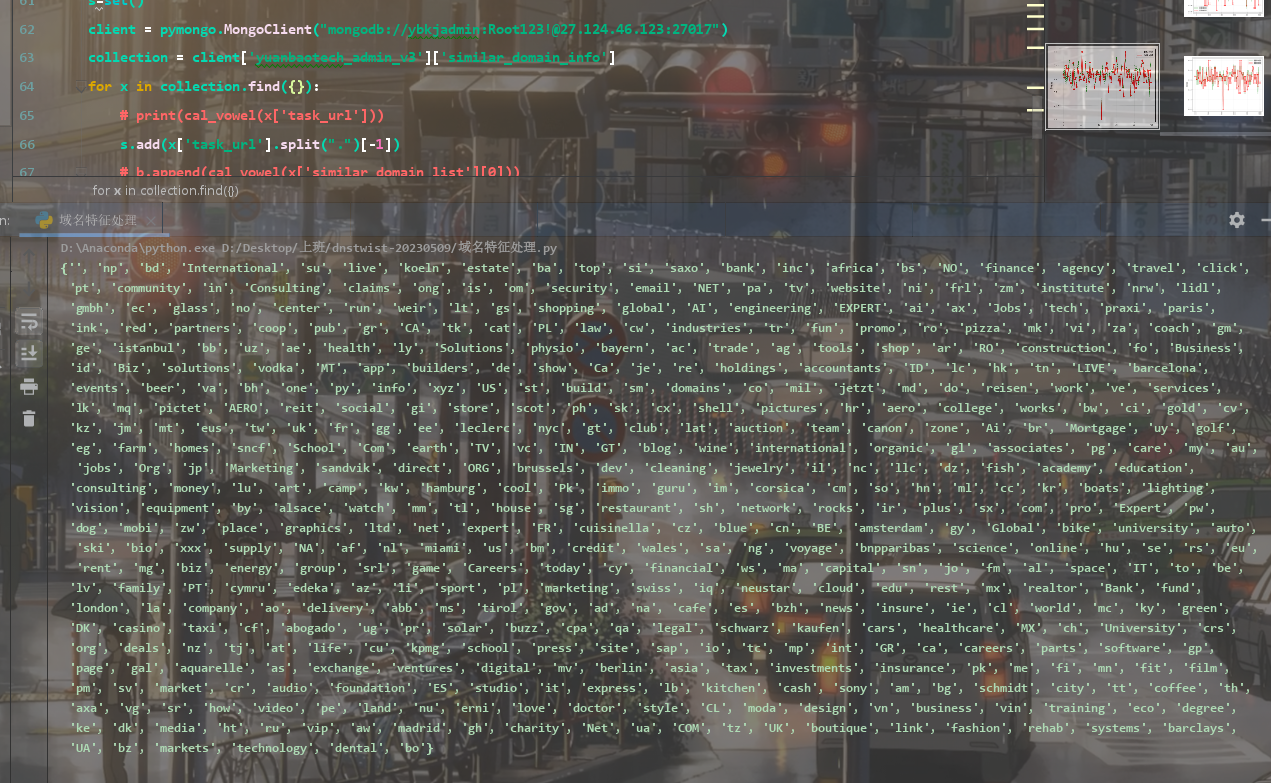
--ssdeep功能分析
对输入参数进行解析,lsh代表使用LSH算法进行模糊查找,默认选择的算法是ssdeep
https://www.jianshu.com/p/b70ff7ba6822 局部敏感哈希(Locality Sensitive Hashing,LSH)算法,是近似最近邻搜索算法中最流行的一种,它有坚实的理论依据并且在高维数据空间中表现优异。它的主要作用就是从海量的数据中挖掘出相似的数据,可以具体应用到文本相似度检测、网页搜索等领域。

这个工具里面只选择了ssdeep和tlsh这两种敏感哈希算法
https://www.freebuf.com/sectool/321011.html ssdeep的计算结果是[0,100]之间的相似值,0表示完全不相关,100表示基本完全一致。tlsh的计算结果是[0,X]之间的距离值,0表示基本完全一致,X的上限暂时不清楚,但距离越大,表示文件差异越大。

这里的lsh_url如果加了会做一次全域名解析

开始扫描,发送一次url请求

UrlOpener函数,根据输入的url进行一次请求,并处理一下返回结果
class UrlOpener():
def __init__(self, url, timeout=REQUEST_TIMEOUT_HTTP, headers={}, verify=True):
http_headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9',
'accept-encoding': 'gzip,identity',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8'}
for h, v in headers.items(): # do not override accepted encoding - only gzip,identity is supported
if h.lower() != 'accept-encoding':
http_headers[h.lower()] = v
if verify: # 处理https,verify决定是否验证 SSL 证书
ctx = urllib.request.ssl.create_default_context()
else:
ctx = urllib.request.ssl._create_unverified_context()
request = urllib.request.Request(url, headers=http_headers)
# urllib.request.urlopen用于打开一个远程的url连接,并且向这个连接发出请求,获取响应结果。
# 返回的结果是一个http响应对象,这个响应对象中记录了本次http访问的响应头和响应体
with urllib.request.urlopen(request, timeout=timeout, context=ctx) as r:
self.headers = r.headers
self.code = r.code
self.reason = r.reason
self.url = r.url
self.content = r.read()
if self.content[:3] == b'\x1f\x8b\x08':
self.content = gzip.decompress(self.content) # [0x1f, 0x8b, 0x08] 是 gzip 文件的 header
if 64 < len(self.content) < 1024:
try:
# 用于从 HTML 的 meta 标签中提取 url。
# 第一个参数用于匹配类似于 <meta name="xxx" content="xxx" url="xxx" ...> 这样的字符串。
# 第二个参数是要查找的字符串。self.content.decode(),将 bytes 类型的内容转换为 str 类型。
# 第三个参数是 re.IGNORECASE,表示忽略大小写。
# 如果查找到了匹配的内容,则返回一个 Match 对象,否则返回 None。Match 对象有很多方法和属性,可以用于获取匹配到的内容、位置等信息。
meta_url = re.search(r'<meta[^>]*?url=(https?://[\w.,?!:;/*#@$&+=[\]()%~-]*?)"', self.content.decode(), re.IGNORECASE)
except Exception:
pass
else:
if meta_url:
# 提取出meta_url中匹配到的第一个url
self.__init__(meta_url.group(1), timeout=timeout, headers=http_headers, verify=verify)
self.normalized_content = self._normalize()
def _normalize(self):
# 第一个键值对:key匹配的action=“xxx”、src=“xxx”、href=“xxx”这样的字符串。 value 用于替换字符串中匹配到的内容,接受一个参数m,表示匹配到的内容,首先使用 split() 方法将匹配到的内容按照等号分割成两部分,将第一部分加上等号和两个双引号,最后返回这个字符串。因此其做的是将action=“xxx”、src=“xxx”、href=“xxx”的值清空
# 第二个键值对: key匹配字符串中类似于 url(xxx) 的字符串,value用于将 url(xxx) 替换为 url()。
content = b' '.join(self.content.split()) # 将content中的多个空格替换为一个空格
mapping = dict({
b'(action|src|href)="[^"]+"': lambda m: m.group(0).split(b'=')[0] + b'=""',
b'url\([^)]+\)': b'url()',
})
for pattern, repl in mapping.items():
content = re.sub(pattern, repl, content, flags=re.IGNORECASE)
return content
ssdeep用的是专门的库,tlsh也是专门的库,将上一步处理好的页面直接丢进去,算模糊哈希值。
丢到worker里面上多线程

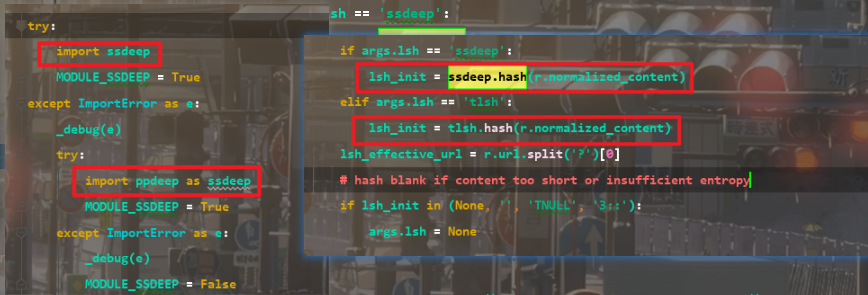
如果dns_a或dns_aaaa为真,进行了DNS解析,则执行try语句块中的代码。使用UrlOpener类打开一个domain的URL,如果URL成功,则执行else部分,比较两个URL是否相同,如果不同,则执行一些操作。其中,self.lsh_effective_url和r.url.split('?')[0]分别表示两个URL。如果这两个URL不同,则根据self.option_lsh的值来决定使用哪种算法计算r.normalized_content的哈希值,并将哈希比较的结果存储在task字典中。下面的tlsh:tlsh.diff计算原始url和变形后的url页面之间的哈希值差异,返回一个整数,表示相似性的分数。用min(..,300)/3把分数的范围缩小到0到100之间。int(100-(min(..)/3))把分数从浮点数转换成整数,100减是为了把分数反转,使得分数越高,表示越相似。
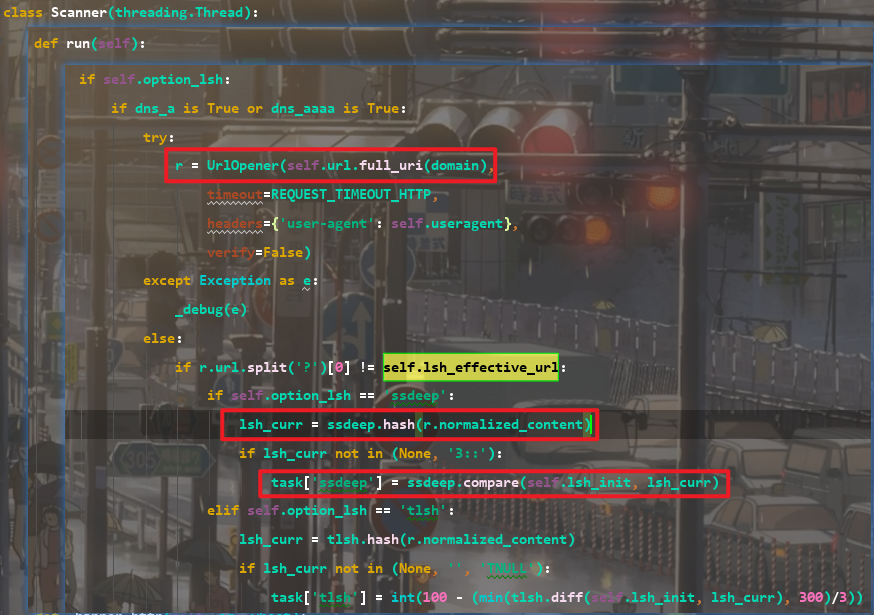
domain参数的来源:根据输入进的url调用Fuzzer进行fuzzer,生成一堆的url变形体(code:1301),然后把每一个原始url的变形体放到对列中(code:1365)
Fuzzer的字典是自己的造的感觉可以优化一下:

--phash功能分析
主要涉及两个参数-p和--phash-url,加url不太重要

根据phash_url是否存在,选择要请求的网页的地址,赋值给request_url变量。打印出正在渲染的网页地址,并创建一个浏览器对象browser。try块中,用browser.get(request_url)方法来访问网页,并用browser.screenshot()方法来截取网页的图片,保存到screenshot变量中。如果没有发生异常,则用pHash(BytesIO(screenshot))方法来计算图片的pHash值,并赋值给phash变量。然后用browser.stop()方法来停止浏览器对象。

pHash类计算图片的感知哈希值和相似度:__init__初始化一个pHash对象。用PIL库来打开图片,转换为灰度图,并缩放为8x8的正方形。接着,把图片的像素值存储到一个列表中,计算平均值。最后,用一个字符串来表示哈希值,遍历像素列表,如果像素值大于平均值,就用'1'表示,否则用'0'表示。__sub__计算两个pHash对象之间的相似度。它接受另一个pHash对象作为参数。然后,计算两个哈希值的长度和汉明距离。接着,它用一个公式来计算相似度的百分比,其中e是自然常数。最后,它返回相似度的整数值,如果小于0,就返回0。__repr__返回一个pHash对象的字符串表示,把哈希值从二进制转换为十六进制,并返回。__int__返回一个pHash对象的整数表示,把哈希值从二进制转换为十进制,并返回。

--mxcheck功能分析
直接跳到关键部分,Scanner类中的_mxcheck方法:用来检查一个邮件服务器(mx)是否可以接收来自某个域名(from_domain)的邮件,并发送到另一个域名(to_domain)的邮件:首先,定义两个随机的邮件地址,分别用from_domain和to_domain作为后缀。用smtplib库来创建一个SMTP对象,连接到mx服务器,端口为25,超时时间为REQUEST_TIMEOUT_SMTP。然后,用smtp.sendmail方法来发送一封内容为'And that's how the cookie crumbles'的邮件,从from_addr到to_addr。
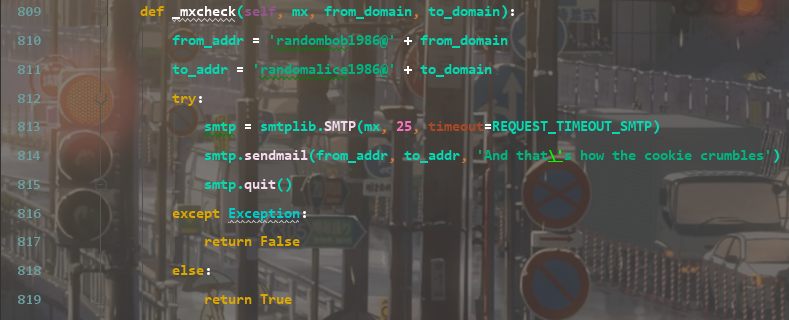
这一部分比较疑惑,都没注册过就能发邮件吗?
--geoip功能分析
首先判断是否可以导入geoip2或GeoIP模块,并定义一个geoip类,用来根据IP地址获取国家名称的:尝试导入geoip2.database模块,并创建一个Reader对象,使用GEOLITE2_MMDB作为数据库文件。如果发生异常,尝试导入GeoIP模块,并创建一个GeoIP对象,使用内存缓存模式。如果再次发生异常,把MODULE_GEOIP变量设置为False,表示没有可用的geoip模块。如果没有发生异常,就把MODULE_GEOIP变量设置为True,表示有可用的geoip模块,并定义一个geoip类,使用GeoIP模块的方法来实现根据IP地址获取国家名称的功能。

--banner功能分析
banner部分涉及dns_a和dns_mx两个开关器。
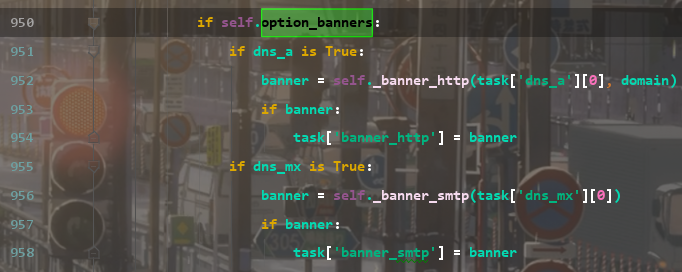
_banner_http用来获取一个IP地址和一个虚拟主机名对应的HTTP服务器的类型:创建一个socket对象,并设置超时时间为1秒,然后连接到IP地址的80端口,表示HTTP协议。就用http.send方法发送一个HEAD请求,用来获取HTTP服务器的响应头,其中包含了服务器的类型。请求中使用vhost作为主机名,self.useragent作为用户代理。http.recv方法接收服务器的响应,并解码为字符串。接着,把响应字符串按换行符分割成列表,遍历每一行,如果以'server: '开头(不区分大小写),就返回它后面的部分,表示服务器的类型。

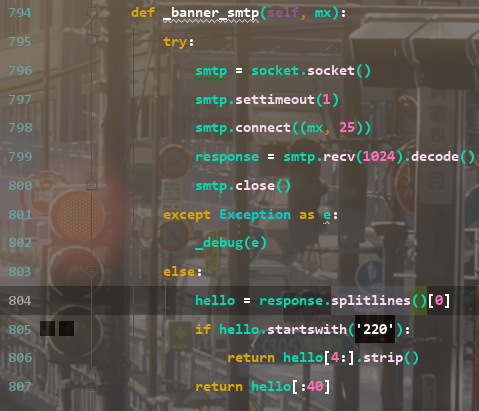
_banner_smtp方法,用来获取一个邮件服务器(mx)的欢迎信息:创建一个socket对象,并设置超时时间为1秒,然后连接到mx服务器的25端口,表示SMTP协议。用smtp.recv方法接收服务器的响应,并解码为字符串。用smtp.close方法关闭连接。然后,把响应字符串按换行符分割成列表,并取第一行,赋值给hello变量。如果hello以'220'开头,表示服务器正常响应,就返回它后面的部分,并去掉两边的空格,表示服务器的欢迎信息。如果hello不以'220'开头,表示服务器异常或不支持SMTP协议,就返回它前面的40个字符,表示服务器的响应。
开源项目
GitHub - Chauncy-lab/Deep-learning-of-DGA: 基于深度学习对dga恶意域名检测研究
GitHub - Silent-voice/DGA-Domain-Predict: 使用LSTM模型检测DGA域名
GitHub - Wenzhao299/Malicious-domain-detection-system: 恶意域名检测系统
GitHub - skydownacai/DGA-Domain-Detection: 基于LSTM的恶意域名检测实例
GitHub - Rhy0ThoM/MaliciousDomainDetection: 恶意域名检测 SVM
GitHub - pengchenghu428/dga_detection: 域名检测算法方案汇总
GitHub - section9-lab/DGA: DGA域名检测
GitHub - pipipig1998/-svm-svm-malicious_web-: SVM恶意域名检测
GitHub - AnchoretY/DGA_Detection: 使用深度学习的方式进行DGA域名检测
GitHub - CharileBrown/lstm_dga: lstm进行dga域名检测
GitHub - badboyqiqi/Malicious-domains-detection: 恶意域名检测工具(Malicious domains detection)
GitHub - fengupupup/storm: 暴露面检测系统 - 输入您的公司名称或者资产域名,一键查找公司在互联网暴露的已知、未知信息资产,检测存在的安全风险。(暴露面扫描、暴露面收敛)
GitHub - mayixiaobai248/idshwk5: 网络入侵检测与数字取证_DGA域名检测
GitHub - Wenzhao299/Malicious-domain-detection-system: 恶意域名检测系统
论文
一种基于集成学习的DGA僵尸网络检测新模型 |IEEE会议出版物 |IEEE Xplore
DGA域名检测
DGA介绍
DGA域名是指使用DGA算法生成的域名。DGA(Domain Generation Algorithm)是一种域名生成算法,它可以生成大量随机的域名来供恶意软件连接C&C控制服务器。这种域名通常硬编码在恶意软件中,用于逃避域名黑名单检测技术。
https://mp.weixin.qq.com/s/GlWqTWQzBfoXt8J8uJAPRQ
DGA技术的复杂性各不相同,有简单的统一生成的域名,也有试图在真实域中模拟分布的域名。总的来说可分为以下4种类型的DGA域名生成算法。
1)基于算术的DGA:根据时间或者随机种子,初始化出一系列可以根据ASCII码直接表示成域名的值, 或者使用这些值作为偏移量,指向DGA硬编码的字符表中的一个字符。
2)基于哈希的DGA:使用十六进制表示的哈希值生成DGA域名,通常有SHA256和MD5两种哈希值。
3)基于单词表的DGA: 从一个或者多个单词表中随机选择单词,并将其拼接成一个域名。
4)基于置换的DGA:对正常域名进行置换操作,生成多个新域名,例如:恶意 DGA 生成算法合集
信息熵区分
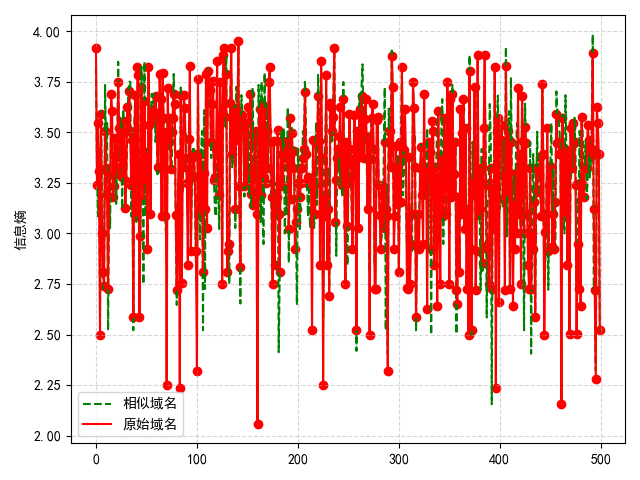
import pymongo
import numpy as np
def cal_entropy(data):
import math
if not data:
return 0
valid_chars = set(data)
entropy = 0
for x in valid_chars:
p_x = float(data.count(x)) / len(data)
if p_x > 0:
entropy += - p_x * math.log(p_x, 2)
return entropy
def print_fg(x,a,b):
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
plt.plot(x,b, c='green', linestyle='--', label="相似域名")
plt.plot(x,a , c='red', label="原始域名")
plt.scatter(x, a, c='red')
plt.legend(loc='best')
plt.ylabel("信息熵")
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
x = np.arange(1,11)
a = []
b = []
client = pymongo.MongoClient("mongodb://ybkjadmin:Root123!@27.124.46.123:27017")
collection = client['yuanbaotech_admin_v3']['similar_domain_info']
for x in collection.find({}).limit(500):
a.append(cal_entropy(x['task_url']))
b.append(cal_entropy(x['similar_domain_list'][0]))
# for i in x['similar_domain_list']:
# a.append(cal_entropy(x['task_url']))
# b.append(cal_entropy(i))
print_fg(np.arange(0,len(b)),a,b)
元音字母比重分析
def cal_vowel(data):
vowel=['a','e','i','o','u']
valid_chars = set(data)
cnt = 0
if not data:
return 0
for char in data.lower():
if char in vowel:
cnt += 1
return float(cnt/len(data))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号