CTF | bugku | 速度要快
- 检查源码时发现有
<!-- OK ,now you have to post the margin what you find -->
- 检查响应头发现有
flag: 6LeR55qE6L+Y5LiN6ZSZ77yM57uZ5L2gZmxhZ+WQpzogTWpZNE9USTU=
- 然后写代码爬网页
''' @Modify Time @Author ------------ ------- http://123.206.87.240:8002/web6/ 2019/9/7 16:40 laoalo ''' import requests import base64 url='http://123.206.87.240:8002/web6/' response = requests.session() head = response.get(url=url).headers str1 = base64.b64decode(head['flag']) flag = base64.b64decode(repr(str1).split(':')[1]) # flag = base64.b64decode(head['flag']).decode('utf-8').split(':')[1] # print(flag) data = {'margin':flag} key = response.post(url=url,data=data).text print(key)
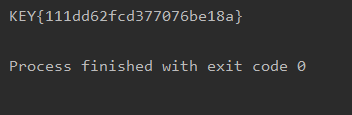
记一次错误的写法:
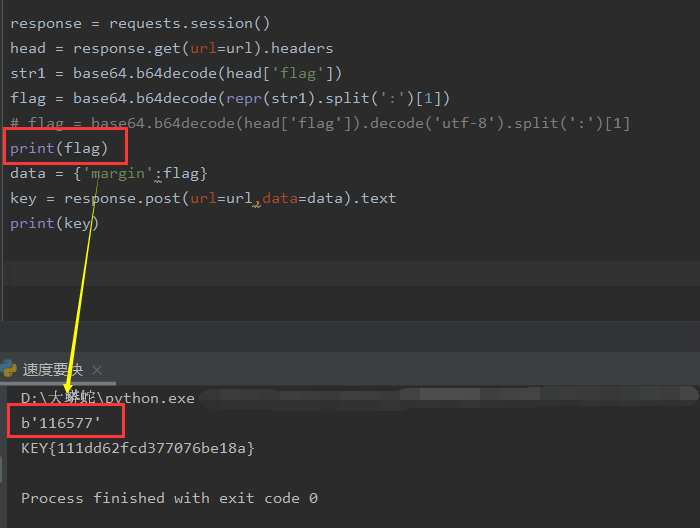
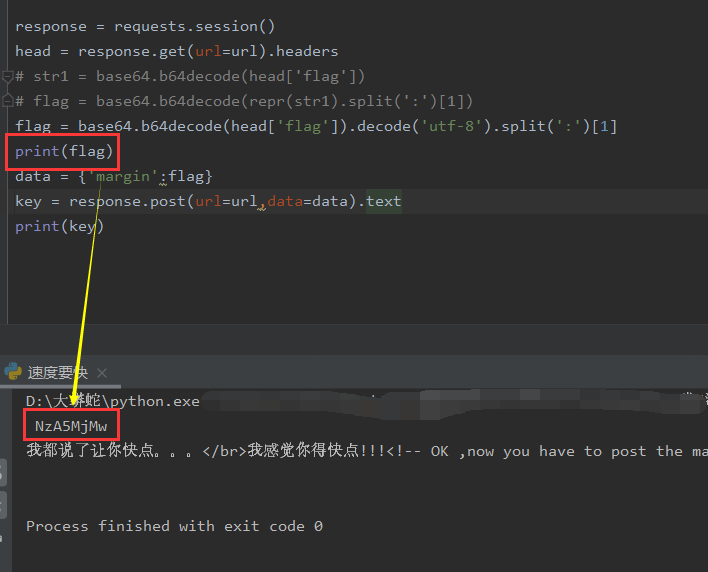
- 原因
flags = base64.b64decode(head['flag']).decode('utf-8').split(':')[1] # 将flag从respond解析出来,结果是str. flag = base64.b64decode(flags) # 在post的时候也需要编码,原来的码缺这一步
- repr() 函数将对象转化为供解释器读取的形式。返回值:string 参数:object
-
 修改后
修改后''' @Modify Time @Author ------------ ------- http://123.206.87.240:8002/web6/ 2019/9/7 16:40 laoalo ''' import requests import base64 url='http://123.206.87.240:8002/web6/' response = requests.session() head = response.get(url=url).headers # str1 = base64.b64decode(head['flag']) # # print("答案的:",repr(str1).split(':')[1],type(repr(str1).split(':')[1])) # print("我的:",base64.b64decode(head['flag']).decode('utf-8').split(':')[1]) # # flag = base64.b64decode(repr(str1).split(':')[1]) # print(flag) flags = base64.b64decode(head['flag']).decode('utf-8').split(':')[1] # 将flag从respond解析出来,结果是str. flag = base64.b64decode(flags) # 在post的时候也需要上传 print(flag) data = {'margin':flag} key = response.post(url=url,data=data).text print(key)


