

Python教程笔录摘抄——基础
1、在Python交互模式下,只要输入Python代码即可立刻执行并打印结果;在命令行模式运行.py文件,并不会如此, 想要打印内容,需要使用print()。编辑.py脚本可以反复运行。
2、注意:print前面不需要任何空格。Python脚本必须以 .py 结尾,其他的都不行。文件名只能是英文字母、数字和下划线的组合。
3、先用cd进入文件所在目录,然后输入运行脚本的命令:python xx.py 即可运行脚本。在Windows上不能直接运行.py脚本文件,而在Mac和Linux上只需在脚本的第一行加上特殊的注释:#!/usr/bin/env python即可直接运行 脚本文件。在运行文件之前,需要对文件进行授权:chmod a+x xx.py 。用Python开发程序,完全可以一边在文 本编辑器里写代码,一边开一个交互式命令窗口,在写代码的过程中,把部分代码粘到命令行去验证,事半功倍!
4、输出:print()在括号中加上被引号括起来的字符串,即可向屏幕中输出指定的内容;多个字符串用逗号(“,”)隔开,即打印出来的数据就会被空格隔开。
>>> print('The quick brown fox', 'jumps over', 'the lazy dog')
The quick brown fox jumps over the lazy dog
输入:input(),括号中可以输入以引号括起来的字符串,让用户根据字符串提示输入相应的字符串内容。
raw_input()读取控制台的输入,但当输入为数字时,input返回的是数值类型,如int,float;而raw_input返回 的却是字符串类型。记住使用 int() 把 raw_input() 的值转为整数。
任何计算机程序都是为了执行一个特定的任务,有了输入,用户才能告诉计算机程序所需的信息,有了输出, 程序运行后才能告诉用户任务的结果。输入是Input,输出是Output,因此,我们把输入输出统称为 Input/Output,或者简写为IO。
在print 后面加了个逗号(comma) , 这样的话 print 就不会输出新行符而结束这一行跑到下一行去了。
5、Python的语法采用的是缩进方式,按照约定俗成的管理,应该始终坚持使用4个空格的缩进。
以#开头的表示注释;当语句以冒号:结尾时,缩进的语句视为代码块。Python程序对大小写敏感。
6、Python数据类型:
- 整数(任意整数,包括负整数),Python的整数没有大小限制。
- 浮点数,Python的浮点数也没有大小限制,但是超出一定范围就直接表示为
inf(无限大)。 - 字符串(以引号括起来的任意文本,需要用到转义字符 \ ,或者是使用 r' ',单引号内部的字符串默认不转义。输入多行字符串可使用三引号。
多行示例:
>>> print('''line1
... line2
... lin3''')
line1
line2
lin3
>>>
多行字符串'''...'''还可以在前面加上r使用
>>> print (r'''\t
... hsuh\t
... jks\n''')
\t
hsuh\t
jks\n
- 布尔值(True 、False),布尔值可以用
and与运算、or或运算和not非运算,常用在条件判断中。 - 空值None,表示一个特殊的空值。
7、Python 变量
变量名必须是大小写英文、数字和_的组合,且不能用数字开头。定义变量:变量=值。在Python中,等号是 赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。Python解释器中创建变量:先在内存中创建了一个值,然后在内存中创建一个变量,并指向了值。Python支持多种数据类型,在计算机内部,可以把任何数据都看成一个“对象”,而变量就是在程序中用来指向这些数据对象的,对变量赋值就是把数据和变量给关联起来。变量时不会带引号的。
8、Python 常量
在Python中,通常用全部大写的变量名表示常量。所谓常量就是不能变的变量。在Python中,有两种除法,一种除法是 /(除法的结果为浮点数),一种除法是//(结果为整数),称为地板除。
示例: >>> n=123 >>> print(n) 123 >>> f=456.789 >>> print(f) 456.789 >>> s1='Hello, world!' >>> print(s1) Hello, world! >>> s2='Hello,\'Adam\'' >>> print(s2) Hello,'Adam' >>> s3=r'Hello,"Bart"' >>> print(s3) Hello,"Bart" >>> s4=r'''Hello, ... Lisa!''' >>> print(s4) Hello, Lisa! >>>
>>> print(4/2)
2.0
>>> print(6//3)
2
>>> print(9%2)
1
9、字符串和编码
ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。现在计算机系统通用的字符编码工作方式:在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
Python 字符串:对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符,如果知道字符的整数编码,还可以用十六进制进行表示。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
>>> x=b'ABC' >>> print(x) b'ABC' >>> type(x) <class 'bytes'> >>> y='ABC' >>> print(y) ABC >>> type(y) <class 'str'>
以Unicode表示的str通过encode()方法可以编码为指定的bytes;相同的byteske可以使用decode()变为str:
>>> y.encode('ascii')
b'ABC'
>>> x.decode('ascii')
'ABC'
注意:纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。在bytes中,无法显示为ASCII字符的字节,用\x##显示。
在Python中,用len()函数来计算长度:
>>> len(x) #计算字节数 3 >>> len(y) #计算字符数 3
10、格式化(%)
%s --- 字符串替换 、 %d --- 整数替换 、 %f --- 浮点数替换 、 %x --- 十六进制整数 、%% --- 转义%
%r --- repr(),打印时重现它所代表的对象。%r 用来做 debug 比较好,因为它会显示变量的原始数据(raw data),而其它的符号则是用来向用户显示输出的。注:使用%r时转义字符就不起作用了,因为它是用来 debug 的原始格式。%r 打印出来的是你作为程序员写在脚本里的东西,而 %s 打印的是你作为用户应该看到的东西。记住这条:``%r`` 用作 debug,``%s`` 用作显示。
>>> 'Hello,%s!' %'jane'
'Hello,jane!'
>>> 'Hello,%s,you have $%d' %('mike',10)
'Hello,mike,you have $10'
>>>print "I am %s years old." % 22 == >I am 22 years old.
>>>print "I am %r years old." % 22 == >I am 22 years old.
>>>text = "I am %d years old." %22
>>>print "I said: %s." % text ==> I said: I am 22 years old.
>>>print "I said: %r." % text ==> I said: 'I am 22 years old'
>>>import datetime
>>>d = datetime.date.today()
>>> print "%s" % d == > 2017-11-13
>>> print "%r" % d == > datetime.date(2017,11,13)
应该使用 %s 还是 %r?应该使用 %s,只有在想要获取某些东西的 debug 信息时才能用到 %r。 %r 给你的是变量的“程序员原始版本”,又被称作“representation”。
11、list 列表
定义列表:列表名=[],多个元素使用逗号(,)分隔。列表的索引从0开始,使用下标索引来获取列表中对应的值,若 想获取最后一个元素,可使用-1做索引来获取。
使用len()函数可以获取列表的个数;append()可追加元素到列表末尾;insert()可以根据索引号插入元素到列表中;pop()可删除列表末尾的元素,也可以根据索引位置 i 进行删除;del()可删除列表元素。
替换列表中的元素:列表名[索引号]=值
12、转义序列
| 转义符 | 功能 | 转义符 | 功能 |
| \\ |
Backslash ()反斜杠 |
\N{name} |
Unicode 数据库中的字符名,其中 name 就 |
| \' | Single quote(') 单引号 | \r ASCII |
Carriage Return (CR) 回车符 |
| \" | Double quote (") 双引号 | \t ASCII |
Horizontal Tab (TAB) 水平制表符 |
| \a | ASCII Bell (BEL) 响铃符 | \uxxxx |
值为 16 位十六进制值xxxx 的字符 |
| \b | ASCII Backspace (BS)退格符 | \Uxxxxxxxx |
值为 32 位十六进制值xxxx 的字符 |
| \f | ASCII Fornfeed (FF)进纸符 | \v |
ASCII Vertical Tab (VT) 垂直制表符 |
| \n |
ASCII Linefeed (LF) 换行符 |
\ooo |
值为八进制值ooo 的字符 |
| \xhh |
值为十六进制数 hh 的字符 |
13、Pydoc
pydoc是Python自带的模块,主要用于从python模块中自动生成文档,这些文档可以基于文本呈现的、也可以生成WEB 页面的,还可以在服务器上以浏览器的方式呈现!使用pydoc可以很方便的查看类和方法结构,按q退出pydoc。
在Windows环境下,直接运行
python -m pydoc <modulename> #查询模块的用法,-m参数:表示Python以脚本的方法运行模块
在Linux环境下,直接运行
pydoc <modulename> #查询模块的用法
python -m pydoc 参数 :
| 参数 | 功能 |
| -p 端口号(8088) | 在本地机器上,按照给定的端口启动HTTP(查看Python内部模块),按ctrl+c 退出 |
| -k 关键字 | 在所有可用的模块中按关键字搜索 |
| -w name.html | 将指定模块的文本字符串生成HTML格式 |
| -g | 弹出一个查找和服务文档的图形界面 |
| -b(Python3) | 启动浏览器 |
14、argv(from sys import argv)
argv 是所谓的“参数变量(argument variable)”,是一个非常标准的编程术语。这个变量包含了你传递给 Python 的参数。参数是在用户执行脚本命令时就要输入,命令行参数是字符串,若想输入数字则需用int()进行转换。
script,first,second,third = argv #argv “解包(unpack)”,
argv “解包(unpack)”,与其将所有参数放到同一个变量下面,我们将每个参数赋予一个变量名: script, first, second, 以及 third,它的含义很简单:“把 argv 中的东西解包,将所有的参数依次赋予左边的变量名”。
15、file
open(filename,arg),arg——w(写入,直接覆盖文件之前的内容)、r(读取)、a(追加)、w+、r+、a+ 文件将以同时读写的方式打开。open()默认工作方式。
- close() – 关闭文件。跟你编辑器的 文件->保存.. 一个意思。
- read() – 读取文件内容。你可以把结果赋给一个变量。
- readline() – 读取文本文件中的一行,文件 f 会记录每次调用 readline() 后的读取位置,即在下次被调用时读取接下来的一行了。
- truncate() – 清空文件,请小心使用该命令。
- write(stuff) – 将stuff 写入文件。write 需要接收一个字符串作为参数,从而将该字符串写入文件。
- seek()方法用于移动文件读取指针到指定位置。fileObject.seek(offset[, whence]);offset -- 开始的偏移量,也就是代表需要移动偏移的字节数;whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。seek() 函数的处理对象是字节,seek(0)只是转到文件的 0 byte,即第一个byte的位置。
rewind(filename):使文件fp的位置指针指向文件开始.当文件刚打开或创建时,该指针指向文件的开始位置。每当进行一次读写后,该指针自动指向下一次读写的位置。可以用函数ftell()获得当前的位置指针,也可以用rewind()/fseek()函数改变位置指针,使其指向需要读写的位置。
open(filename).read()——无需再运行file.close(),因为read() 一旦运行, 文件就会被读到结尾并且被 close 掉。
判断文件行数:len(f.readlines())
16、exists (from os.path import exists)
exists(filename)这个命令将文件名字符串作为参数,如果文件存在的话,它将返回 True,否则将返回 False。
cat 这个命令将两个文件“连接(con*cat*enate)”到一起,不过实际上它最大的用途是打印文件内容到屏幕上;但它只能在Linux 和 osx 下面使用。
17、len()函数
len() 函数,它会以数字的形式返回你传递的字符串的长度。
18、function 函数
函数可以做三样事情:
1. 它们给代码片段命名,就跟“变量”给字符串和数字命名一样。
2. 它们可以接受参数,就跟你的脚本接受 argv 一样。
3. 通过使用 #1 和 #2,它们可以让你创建“微型脚本”或者“小命令”。
Python创建一个函数,使用def命令,也就是“define”的意思,紧跟着def的函数的名称。函数名称可以以字母、数字及下划线组成,但数字不能开头。例如:def print_two(),函数名后的圆括号中可以进行参数传递,def print_two(*args ):告诉函数需要参数,*args (asterisk args)的功能是告诉 python 让它把函数的所有参数都接受进来,然后放到名字叫 args 的列表中去。参数必须放在圆括号中才能正常工作。多个参数可以使用逗号(,)进行隔开。
def print_two(*args): #使用冒号:结束本行
arg1,arg2 = args #使用缩进进行下一行代码的编写,一般缩进为4个空格
print "arg1: %r , arg2:%r" % (arg1,arg2)
函数注意事项如下:
1) 函数定义是以 def 开始的吗?
2) 函数名称是以字符和下划线 _ 组成的吗?
3) 函数名称是不是紧跟着括号 ( ?
4)括号里是否包含参数?多个参数是否以逗号隔开?
5)参数名称是否有重复?(不能使用重复的参数名)
6)紧跟着参数的是不是括号和冒号 ): ?
7) 紧跟着函数定义的代码是否使用了 4 个空格的缩进 (indent)?
8) 函数结束的位置是否取消了缩进 (“dedent”)?
当你运行(或者说“使用 use”或者“调用 call”)一个函数时,记得检查下面的要点:
1) 调运函数时是否使用了函数的名称?
2) 函数名称是否紧跟着 ( ?
3)括号后有无参数?多个参数是否以逗号隔开?
4) 函数是否以 ) 结尾?
“‘运行函数(run)’、‘调用函数(call)’、和 ‘使用函数(use)’是同一个意思”
函数里边的变量和脚本里边的变量之间是没有连接的。return 可以将变量设置为“一个函数的值”,它将 = 右边的东西作为一个函数的返回值。print 只是屏幕输出而已,你可以让一个函数既 print 又返回值。如果你想要打印到屏幕,那就使用 print ,如果是想返回值,那就是用 return 。
def secret_formula(started):
jelly_beans = started * 500
jars = jelly_beans / 1000
crates = jars / 100
return jelly_beans,jars,crates
start_point = 10000
beans, jars, crates = secret_formula(start_point)
记住函数内部的变量都是临时的。当你的函数返回以后,返回值可以被赋予一个变量。这里是创建了一个新变量,用来存放函数的返回值。
python 可以将 ex.py 文件作为模块一样执行 import,不过在 import 的时候不需要加 .py ,因为Python z 知道文件是以 .py 结尾的,所以只需输入 import ex 即可,或者是 from ex import * 。
19、逻辑术语与布尔表达式
- and 与
- or 或
- not 非
- !=(not equal) 不等于
- ==(equal) 等于
- >=(greater-than-equal) 大于等于
- <=(less-than-equal) 小于等于
- True 真
- False 假
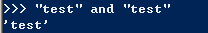
Python 和很多语言一样,都是返回两个被操作对象中的一个,而非它们的布尔表达式True 或 False 。这意味着如果你写了 False and 1 ,你得到的是第一个操作字元(False),而非第二个字元(1)。
真值表
|
NOT |
True? |
|
not False |
True |
|
not True |
False |
|
OR |
True? |
|
True or False |
True |
|
True or True |
True |
|
False or True |
True |
|
False or False |
False |
|
AND |
True? |
|
True and False |
False |
|
True and True |
True |
|
False and True |
False |
|
False and False |
False |
|
NOT OR |
True? |
|
not(True or False) |
False |
|
not(True or True) |
False |
|
not(False or True) |
False |
|
not(False or False) |
True |
|
NOT AND |
True? |
|
not(True and False) |
True |
|
not(True and True) |
False |
|
not(False and True) |
True |
|
not(False and False) |
True |
|
!= |
True? |
|
1!=0 |
True |
|
1!=1 |
False |
|
0!=1 |
True |
|
0!=0 |
False |
|
== |
True? |
|
1==0、0==1 |
Fale |
|
0==0、1==1 |
True |
19、If 、Else
If 语句为代码创建了一个所谓的“分支”,if 语句告诉你的脚本:“如果这个布尔表达式为真,就运行接下来的代码,否则就跳过这一段。”
if 语句的下一行需要 4 个空格的缩进?行尾的冒号的作用是告诉 Python 接下来你要创建一个新的代码区段。这根你创建函数时的冒号是一个道理。
Python 的规则里,只要一行以“冒号(colon)” : 结尾,它接下来的内容就应该有缩进。
if condition:
do something
if condition:
do something1
elif condition:
do something2
else:
do another
如果多个 elif 区块都是 True 是 python 会如何处理?
Python 只会运行它碰到的是 True 的第一个区块,所以只有第一个为 True 的区块会被运行。
if 语句可以进行嵌套,其中的一个分支将引向另一个分支的子分支。想判断一个数字处于某个值域中?可以使用if 来进行判断,例如1<x<10 或者是 x in range(1,10)。
If 语句的规则
1) 每一个“if 语句”必须包含一个 else.
2) 如果这个 else 永远都不应该被执行到,因为它本身没有任何意义,那你必须在 else 语句后面使用一个叫做 die 的函数,让它打印出错误信息并且死给你看,这和上一节的习题类似,这样你可以找到很多的错误。
3) “if 语句”的嵌套不要超过 2 层,最好尽量保持只有 1 层。 这意味着如果你在 if 里边又有了一个 if,那你就需要把第二个 if 移到另一个函数里面。
4) 将“if 语句”当做段落来对待,其中的每一个 if, elif, else 组合就跟一个段落的句子组合一样。在这种组合的最前面和最后面留一个空行以作区分。
5) 你的布尔测试应该很简单,如果它们很复杂的话,你需要将它们的运算事先放到一个变量里,并且为变量取一个好名字。
20、循环和列表
创建列表:haris = ['brown','blond','red'] ,以 [ (左方括号)开头“打开”列表,然后写下你要放入列表的东西,用逗号隔开,就跟函数的参数一样,最后你需要用 ] (右方括号)结束右方括号的定义。
创建空列表:list = [] 即可。
range() 函数可创建一个整数列表,一般用在 for 循环中。左闭右开 [left,right)
range(start, stop[, step])
参数说明:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- end: 计数到 end 结束,但不包括 end。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)。步长为正整数,则最后一个元素小于end;步长取负整数,从-1开始,表示列表中的最后一个,则最后一个元素大于end。必须是非零整数,否则会报错。
list 中的index是从0开始的。
基数:表示数量的意义,即被数的物体有“多少个”,这种用来表示事物数量的数,称为基数。
序数:表示次序的意义,即被数到的物体是序列中的“第几个”,这种用来表示事物次序的数,称为序数。
记住: ordinal == 有序,以 1 开始;cardinal == 随机选取, 以 0 开始。
| Python中对 list 的操作 | 作用 |
| L.append(object) | append object to end |
| L.count(value)---integer | return number of occurrences of value |
| L.extend(iterable) | extend list by appending elements from the iterable |
| L.index(value,[start,[stop]])---integer | return first index of value |
| L.insert(index,object) | insert object before index |
| L.pop([index])---item | remove and return item at index(default last) |
| L.remove(value) | remove first occurrence of value |
| L.reverse() | reverse *IN PLACE* |
| L.sort(cmp=None,key=None,reverse=False) | stable sort *IN PLACE* |
for 循环:
for iterating_var in sequence:
statements(s)
ex:使用内置 enumerate 函数进行遍历
for index, item in enumerate(sequence):
process(index, item)
为什么 for-loop 可以使用未定义的变量?
循环开始时这个变量就被定义了,当然每次循环它都会被重新定义一次。
while 循环:
while 循环,它所作的和 if 语句类似,也是去检查一个布尔表达式的真假,不一样的是它下面的代码片段不是只被执行一次,而是执行完后再调回到 while 所在的位置,如此重复进行,直到 while 表达式为 False 为止。
while 判断条件:
执行语句……
如果判断条件一直 为真,则循环会进入无限循环,可以使用 CTRL+C 来中断循环。
为了避免死循环,你需要遵循下面的规定:
1) 尽量少用 while-loop,大部分时候 for-loop 是更好的选择。
2) 重复检查你的 while 语句,确定你测试的布尔表达式最终会变成 False 。
3) 如果不确定,就在 while-loop 的结尾打印出你要测试的值。看看它的变化。
循环的规则
1. 只有在循环永不停止时使用“while 循环”,这意味着你可能永远都用不到。这条只有 Python中成立,其他的语言另当别论。
2. 其他类型的循环都使用“for 循环”,尤其是在循环的对象数量固定或者有限的情况下。
21、Python 各种符号
| Keywords(关键字) | 作用 |
| and | 逻辑“与” |
| del | 用于list列表操作,删除一个或者连续几个元素 |
| from | 导入相应的模块,用import或者from...import |
| not | 逻辑“非” |
| while | while循环,允许重复执行一块语句,一般无限循环的情况下用它。 |
| as | as单独没有意思,with....as用来代替传统的try...finally语法的 |
| elif | 和 if 配合使用的,if 语句中的一个分支用 elif 表示。 |
| global | 定义全局变量 |
| or | 逻辑“或” |
| with | 和as一起用,with....as |
| assert | 表示断言(断言一个条件就是真的,如果断言出错则抛出异常)用于声明某个条件为真,如果该条件不是真的,则抛出异常:AssertionError |
| else | 和 if 配合使用,if 语句中的另一分支 |
| if | if 语句用于选择分支,依据条件选择执行那个语句块。 |
| pass | pass的意思就是什么都不做。常用来占位 |
| yield | 用起来和return很像,但它返回的是一个生成器。 |
| break | 作用是终止循环,程序走到break的地方就是循环结束的时候。注意:如果从for或while循环中终止(break)之后 ,else语句不执行。 |
| except | 和try一起使用,用来捕获异常。 |
| import | 用来导入模块,有时这样用from....import |
| 输出 | |
| class | 定义类 |
| exec |
exec语句用来执行储存在字符串或者文件中的python语句。可以生成一个包含python代码的字符串,然后使用exec语句执行这些语句。 >>>exec "print 'Hello world!' " —— Hello world |
| in | 查找列表中是否包含某个元素,或者字符串a是否包含字符串b。需要注意的是:不可以查看list1是否包含list2。 |
| raise | raise可以显示地引发异常。一旦执行raise语句,后面的代码就不执行了 |
| continue | 跳过continue后面循环块中的语句,继续进行下一轮循环。 |
| finally | 看到finally语句,必然执行finally语句的代码块。 |
| is |
Python中的对象包含三要素:id、type、value,其中id用来唯一标识一个对象,type标识对象的类型,value是对象的值;is判断的是a对象是否就是b对象,是通过id来判断的;==判断的是a对象的值是否和b对象的值相等,是通过value来判断的 |
| return | 用于跳出函数,也可以在跳出的同时返回一个值。 |
| def | 用于定义方法 |
| for | for....in 一起使用:它在一序列的对象上递归,就是遍历队列中的每个项目 |
| lambda | 即匿名函数,不用想给函数起什么名字。提升了代码的简洁程度。 |
| try | 出现在异常处理中,使用格式为:try...except,try中放想要执行的语句,except捕获异常 |
try: block except [exception,[data…]]: block try: block except [exception,[data...]]: block else: block
该种 Python异常处理语法的规则是:
◆执行try下的语句,如果引发异常,则执行过程会跳到第一个except语句。
◆如果第一个except中定义的异常与引发的异常匹配,则执行该except中的语句。
◆如果引发的异常不匹配第一个except,则会搜索第二个 except,允许编写的except数量没有限制。
◆如果所有的except都不匹配,则异常会传递到下一个调用本代码的最高层try代码中。
◆ 如果没有发生异常,则执行else块代码。
| Python 数据类型 | 作用 |
| True | 布尔类型 真 |
| False | 布尔类型 假 |
| None | 空对象、空值 |
| strings | 字符串类型 |
| numbers | 数字类型 |
| floats | 浮点数类型 |
| lists | 列表类型 |
| 字符串转义序列 | 作用 |
| \\ | 反斜杠 |
| \' | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 横向制表符 |
| \v | 纵向制表符 |
| 字符串格式化 | 作用 |
| %d | 转成有符号十进制 |
| %i | 转成有符号十进制 |
| %o | 转成无符号八进制数 |
| %u | 转成无符号十进制数 |
| %x | 转成无符号十六进制数(x / X 代表转换后的十六进制字符的大小写) |
| %X | |
| %e | 转成科学计数法(e / E控制输出e / E) |
| %E | |
| %f | 转成浮点数(小数部分自然截断) |
| %F | |
| %g | %e和%f / %E和%F 的简写 |
| %G | |
| %c | 整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <=1114111(py27则只支持0-255);字符:将字符添加到指定位置 |
| %r | 获取传入对象的__repr__方法的返回值,并将其格式化到指定位置 |
| %s | 获取传入对象的__str__方法的返回值,并将其格式化到指定位置 |
| %% | 输出% (格式化字符串里面包括百分号,那么必须使用%%) |
| 操作符号 | 作用 |
| + | 加 |
| - | 减 |
| * | 乘 |
| ** | 幂 |
| / | 除 |
| // | 取整除 - 返回商的整数部分 |
| % | 取余 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| == | 等于 |
| != | 不等于 |
| <> | 不等于,同!= 运算符 |
| () | 空元组 |
| [] | 空列表 |
| {} | 空字典 |
| @ | 用作函数修饰符,修饰符必须出现在函数定义前一行,不允许和函数定义在同一行。只可以在模块或类定义层内对函数进行修饰,不允许修修饰一个类。一个修饰符就是一个函数,它将被修饰的函数做为参数,并返回修饰后的同名函数或其它可调用的东西。 |
| , | 逗号 |
| : | 冒号 |
| . | 点 |
| = | 简单赋值运算符 |
| ; | |
| += | 加法赋值运算符 |
| -= | 减法赋值运算符 |
| *= | 乘法赋值运算符 |
| /= | 除法赋值运算符 |
| //= | 取整除赋值运算符 |
| %= | 取模赋值运算符 |
| **= | 幂赋值运算符符 |
22、字典(dictionary)
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
字典返回是无序的。
两个重要的点需要记住:
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住。
2)键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行。
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys(seq[, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | popitem() 随机返回并删除字典中的一对键和值。 |
对于字典来说,key 是一个字符串,获得值的语法是 [key] 。对于模块来说,key是函数或者变量的名称,而语法是 .key 。
23、类
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 实例变量:定义在方法中的变量,只作用于当前实例的类。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 方法:类中定义的函数。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类:
class ClassName: '类的帮助信息' #类文档字符串 class_suite #类体,class_suite 由类成员,方法,数据属性组成。
示例:
class MyClass():
def __init__(self):
self.data = []
__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法。self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self 。
实现实例化的方法,就是像调用函数一样地调用一个类: thing = MyStuff() thing.apple() print thing.tangerine
针对上面的代码详细解释一下:
1. Python 看到了 MyStuff() 并且知道了它是你定义过的一个类。
2. Python 创建了一个空的对象,里边包含了你在类中用 def 创建的所有函数。
3. 然后 Python 回去检查你是不是在里边创建了一个 __init__ 魔法函数,如果你有创建,它就会调用这个函数,从而对你的空对象实现了初始化。
4. 在 MyStuff 中的 __init__ 函数里,我们有一个多余的函数叫做 self ,这就是 Python 为我们创建的空对象,而我可以对它进行类似模块、字典等的操作,为它设置一些变量进去。
5. 在这里,我把 self.tangerine 设成了一段歌词,这样我就初始化了该对象。
6. 最后 Python 将这个新建的对象赋给一个叫 thing 的变量,以供后面使用。
# dict style mystuff['apples'] # module style mystuff.apples() print mystuff.tangerine # class style thing = MyStuff() thing.apples() print thing.tangerine
三种读代码的方法,它们适用于几乎所有的编程语言:1) 从前向后;2) 从后向前;3) 逆时针方向。
24、继承 vs 合成
继承的用处,就是用来指明一个类的大部分或全部功能,都是从一个父类中获得的。父类和子类有三种交互方式:
1. 子类上的动作完全等同于父类上的动作
2. 子类上的动作完全改写了父类上的动作
3. 子类上的动作部分变更了父类上的动作
隐式继承:
class Parent(object):
def implicit(self):
print "PARENT implicit()"
class Child(Parent):
pass
dad = Parent()
son = Child()
dad.implicit()
son.implicit()
显式覆写:
class Parent(object):
def override(self):
print "PARENT override()"
class Child(Parent):
def override(self):
print "CHILD override()"
dad = Parent()
son = Child()
dad.override()
son.override()
Python 的内置函数 super() 来调用父类 Parent 里的版本。最常见的 super() 的用法是在基类的 __init__ 函数中使用。
class Child(Parent):
def __init__(self, stuff):
self.stuff = stuff
super(Child, self).__init__() #初始化 Parent
多重继承: 多重继承是指你定义的类继承了多个类,就像这样:
class SuperFun(Child, BadStuff):
pass
合成:利用模块和别的类中的函数调用实现了相同的目的。
如果两种方案都能解决重用的问题,那什么时候该用哪个呢?
1. 不惜一切代价地避免多重继承,它带来的麻烦比能解决的问题都多。如果你非要用,那你得准备好专研类的层次结构,以及花时间去找各种东西的来龙去脉吧。
2. 如果你有一些代码会在不同位置和场合应用到,那就用合成来把它们做成模块。
3. 只有在代码之间有清楚的关联,可以通过一个单独的共性联系起来的时候使用继承,或者你受现有代码或者别的不可抗拒因素所限非用不可的话,那也用吧。
25、元组
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。如下实例:
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5 );
tup3 = "a", "b", "c", "d"; #任意无符号的对象,以逗号隔开,默认为元组
创建空元组:
tup1 = ();
元组中只包含一个元素时,需要在元素后面添加逗号:
tup1 = (50,);
元组与字符串类似,下标索引从0开始,可以进行截取,组合等。元组可以使用下标索引来访问元组中的值。元组中的元素值是不允许修改的,但我们可以对元组进行连接组合。元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组。
#!/usr/bin/python
tup1 = ('physics', 'chemistry', 1997, 2000);
tup2 = (1, 2, 3, 4, 5, 6, 7 );
print "tup1[0]: ", tup1[0]
print "tup2[1:5]: ", tup2[1:5]
# 以下修改元组元素操作是非法的。
# tup1[0] = 100;
# 创建一个新的元组
tup3 = tup1 + tup2;
print tup3;
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
/***************************************************************************************************************************************
因为是转载文章 在此标明出处,如有冒犯请联系本人,或删除,或标明出处。
因为好的文章,以前只想收藏,但连接有时候会失效,所以现在碰到好的直接转到自己这里。
文章原始出处:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
***************************************************************************************************************************************/
