


Python 核心编程(第二版)——函数和函数式编程
1. 什么是函数?
函数是对程序逻辑进行结构化或过程化的一种编程方法。能将整块代码巧妙地隔离成易于管理的小块,把重复代码放到函数中而不是进行大量的拷贝--这样既能节省空间,也有助于保持一致性。
元组语法上不需要一定带上圆括号。元组既可以被分解成为单独的变量,也可以直接用单一变量对其进行引用。
| 返回值及其类型 | |
| Stated Number of Objects to Return | Type of Object That Python Returns |
| 0 | None |
| 1 | object |
| >1 | tuple |
2. 调用函数
使用一对圆括号调用函数,任何输入的参数都必须放置在括号中。作为函数声明的一部分,括号也会用来定义那些参数。
关键字参数:是让调用者通过函数调用中的参数名字来区分参数。这样规范允许参数缺失或者不按顺序,因为解释器能通过给出的关键字来匹配参数的值。


1 def foo(x): 2 foo_suite # presumably does some processing with 'x' 3 标准调用 foo():foo(42) foo('bar') foo(y) 4 关键字调用foo():foo(x=42) foo(x='bar') foo(x=y)
默认参数就是声明了默认值的参数。因为给参数赋予了默认值,所以, 在函数调用时,不向该参数传入值也是允许的。
参数组:func(*tuple_grp_nonkw_args, **dict_grp_kw_args)
其中的tuple_grp_nonkw_args 是以元组形式体现的非关键字参数组, dict_grp_kw_args 是装有关键字参数的字典。这种特性允许你把变量放在元组和/或者字典里,并在没有显式地对参数进行逐个声明的情况下,调用函数。实际上,你也可以给出形参!这些参数包括标准的位置参数和关键字参数,所以在python 中允许的函数调用的完整语法为:
func(positional_args, keyword_args,*tuple_grp_nonkw_args, **dict_grp_kw_args)
该语法中的所有的参数都是可选的---从参数传递到函数的过程来看,在单独的函数调用时,每个参数都是独立的。
3. 创建函数
函数是用def 语句来创建的,语法如下:
def function_name(arguments):
"function_documentation_string"
function_body_suite
标题行由def 关键字,函数的名字,以及参数的集合(如果有的话)组成。def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档字串,和必需的函数体。
在声明和定义有区别的语言中,往往是因为函数的定义可能和其声明放在不同的文件中。python将这两者视为一体,函数的子句由声明的标题行以及随后的定义体组成的。
函数属性:函数属性是python 另外一个使用了句点属性标识并拥有名字空间的领域。
内部/内嵌函数:在函数体内创建另外一个函数(对象)。最明显的创造内部函数的方法是在外部函数的定义体内定义函数(用def 关键字)。内部函数一个有趣的方面在于整个函数体都在外部函数的作用域之内。另外一个函数体内创建函数对象的方式是使用lambda 语句。如果内部函数的定义包含了在外部函数里定义的对象的引用(这个对象甚至可以是在外部函数之外),内部函数会变成被称为闭包(closure)的特别之物。
* 函数(与方法)装饰器:装饰器背后的主要动机源自python 面向对象编程。装饰器是在函数调用之上的修饰。这些修饰仅是当声明一个函数或者方法的时候,才会应用的额外调用。
装饰器的语法以@开头,接着是装饰器函数的名字和可选的参数。紧跟着装饰器声明的是被修饰的函数,和装饰函数的可选参数。装饰器看起来会是这样:
@decorator(dec_opt_args)
def func2Bdecorated(func_opt_args):
:
有参数和无参数的装饰器:
没有参数的情况,一个装饰器如:
@deco
def foo():
pass
……
###foo = deco(foo)
带参数的装饰器decomaker():
@decomaker(deco_args)
def foo():
pass
……
###func = decomaker(deco_args)(foo)
那么什么是装饰器?
装饰器实际就是函数,当你看见一个装饰器函数的时候,很可能在里面找到这样一些代码,它定义了某个函数并在定义内的某处嵌入了对目标函数的调用或者至少一些引用。可以考虑在装饰器中置入通用功能的代码来降低程序复杂度。例如,可以用装饰器来:
引入日志
增加计时逻辑来检测性能
给函数加入事务的能力
4. 传递函数
函数有一个独一无二的特征使它同其他对象区分开来,那就是函数是可调用的。可以用其他的变量来做作为函数的别名,因为所有的对象都是通过引用来传递的,函数也不例外。当对一个变量赋值时,实际是将相同对象的引用赋值给这个变量。如果对象是函数的话,这个对象所有的别名都是可调用的。
>>> def foo(): ... print 'in foo()' ... >>> bar = foo >>> bar() in foo()
甚至可以把函数作为参数传入其他函数来进行调用。
1 >>> def bar(argfunc): 2 ... argfunc() 3 ... 4 >>> bar(foo) 5 in foo()
注意到函数对象foo 被传入到bar()中。bar()调用了foo()(用局部变量argfunc 来作为其别名就如同在前面的例子中我们把foo 赋给bar 一样)。
5. 形式参数
python 函数的形参集合由在调用时要传入函数的所有参数组成,这参数与函数声明中的参数列表精确的配对。这些参数包括了所有必要参数(以正确的定位顺序来传入函数的),关键字参数(以顺序或者不按顺序传入,但是带有参数列表中曾定义过的关键字),以及所有含有默认值,函数调用时不必要指定的参数。(声明函数时创建的)局部命名空间为各个参数值,创建了一个名字。一旦函数开始执行,即能访问这个名字。
位置参数:位置参数必须以在被调用函数中定义的准确顺序来传递。另外,没有任何默认参数(见下一个部分)的话,传入函数(调用)的参数的精确的数目必须和声明的数字一致。
作为一个普遍的规则,无论何时调用函数,都必须提供函数的所有位置参数。可以不按位置地将关键字参数传入函数,给出关键字来匹配其在参数列表中的合适的位置是被准予的。
python 中用默认值声明变量的语法是所有的位置参数必须出现在任何一个默认参数之前。每个默认参数都紧跟着一个用默认值的赋值语句。如果在函数调用时没有给出值,那么这个赋值就会实现。
1 def func(posargs, defarg1=dval1, defarg2=dval2,...): 2 "function_documentation_string" 3 function_body_suite
所有必需的参数都要在默认参数之前。为什么?简单说来就是因为它们是强制性的,但默认参数不是。从句法构成上看,对于解释器来说,如果允许混合模式,确定什么值来匹配什么参数是不可能的。如果没有按正确的顺序给出参数,就会产生一个语法错误。
6. 可变长度的参数
常规参数都是在函数声明中命名的。由于函数调用提供了关键字以及非关键字两种参数类型,python 用两种方法来支持变长参数,在函数调用中使用*和**符号来指定元组和字典的元素作为非关键字以及关键字参数的方法。在这个部分中,我们将再次使用相同的符号,但是这次在函数的声明中,表示在函数调用时接收这样的参数。这语法允许函数接收在函数声明中定义的形参之外的参数。
可变长的参数元组必须在位置和默认参数之后,带元组(或者非关键字可变长参数)的函数普遍的语法如下:
def function_name([formal_args,] *vargs_tuple):
"function_documentation_string"
function_body_suite
星号操作符之后的形参将作为元组传递给函数,元组保存了所有传递给函数的"额外"的参数(匹配了所有位置和具名参数后剩余的)。如果没有给出额外的参数,元组为空。
由于和位置参数必须放在关键字参数之前一样的原因,所有的形式参数必须先于非正式的参数之前出现。
关键字变量参数:在我们有不定数目的或者额外集合的关键字的情况中, 参数被放入一个字典中,字典中键为参数名,值为相应的参数值。为什么一定要是字典呢?因为为每个参数-参数的名字和参数值--都是成对给出---用字典来保存这些参数自然就最适合不过了。使用了变量参数字典来应对额外关键字参数的函数定义的语法:
def function_name([formal_args,][*vargst,] **vargsd):
function_documentation_string function_body_suite
为了区分关键字参数和非关键字非正式参数,使用了双星号(**)。 **是被重载了的以便不与幂运算发生混淆。关键字变量参数应该为函数定义的最后一个参数,带**。
7. 函数式编程
python 允许用lambda 关键字创造匿名函数。匿名是因为不需要以标准的方式来声明,比如说,使用def 语句一个完整的lambda“语句”代表了一个表达式,这个表达式的定义体必须和声明放在同一行。
lambda [arg1[, arg2, ... argN]]: expression
参数是可选的,如果使用的参数话,参数通常也是表达式的一部分。
核心笔记:lambda 表达式返回可调用的函数对象。用合适的表达式调用一个lambda 生成一个可以像其他函数一样使用的函数对象。它们可被传入给其他函数,用额外的引用别名化,作为容器对象以及作为可调用的对象被调用(如果需要的话,可以带参数)。当被调用的时候,如过给定相同的参数的话,这些对象会生成一个和相同表达式等价的结果。它们和那些返回等价表达式计算值相同的函数是不能区分的。
可以把lambda 表达式赋值给一个如列表和元组的数据结构,其中,基于一些输入标准,我们可以选择哪些函数可以执行,以及参数应该是什么。lambda 表达式运作起来就像一个函数,当被调用时,创建一个框架对象。
| 函数式编程的内建函数 | |
| 内建函数 | 描述 |
| apply(func[, nkw][, kw]) |
用可选的参数来调用func,nkw 为非关键字参数,kw 关键字参数;返回值是函数调用的返回值。 |
| filter(func, seq) |
调用一个布尔函数func 来迭代遍历每个seq 中的元素; 返回一个使func 返回值为ture 的元素的序列。 |
| map(func, seq1[,seq2...]) |
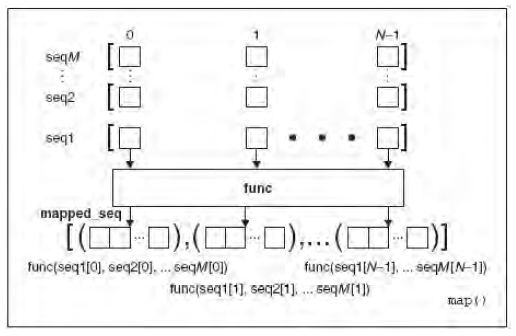
将函数func 作用于给定序列(s)的每个元素,并用一个列表来提供返回值;如果func 为None, func 表现为一个身份函数,返回一个含有每个序列中元素集合的n 个元组的列表。 |
| reduce(func, seq[, init]) |
将二元函数作用于seq 序列的元素,每次携带一对(先前的结果以及下一个序列元素),连续的将现有的结果和下雨给值作用在获得的随后的结果上,最后减少我们的序列为一个单一的返回值;如果初始值init 给定,第一个比较会是init 和第一个序列元素而不是序列的头两个元素。 |
filter 函数为已知的序列的每个元素调用给定布尔函数。每个filter 返回的非零(true)值元素添加到一个列表中。返回的对象是一个从原始队列中“过滤后”的队列。一种更好地理解filter()的方法就是形象化其行为。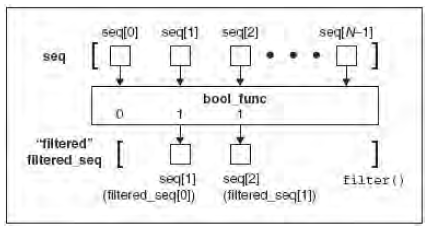
map()将函数调用“映射”到每个序列的元素上,并返回一个含有所有返回值的列表。在最简单的形式中,map()带一个函数和队列, 将函数作用在序列的每个元素上, 然后创建由每次函数应用组成的返回值列表。map()运作如图:
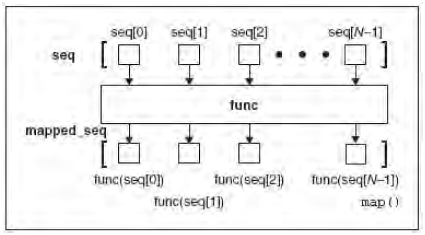
上图是一个map()如何和单一的序列一起运行。若用带有每个序列有N 个对象的M 个序列来的map(),则运行如下图:
reduce 使用了一个二元函数(一个接收带带两个值作为输入,进行了一些计算然后返回一个值作为输出),一个序列,和一个可选的初始化器,卓有成效地将那个列表的内容“减少”为一个单一的值,如同它的名字一样。它通过取出序列的头两个元素,将他们传入二元函数来获得一个单一的值来实现。然后又用这个值和序列的下一个元素来获得又一个值,然后继续直到整个序列的内容都遍历完毕以及最后的值会被计算出来为止。
关键字参数总是出现在形参之后。
8. 变量作用域
标识符的作用域是定义为其声明在程序里的可应用范围, 或者即是我们所说的变量可见性。
核心笔记:搜索标识符(aka 变量,名字,等等)
当搜索一个标识符的时候,python 先从局部作用域开始搜索。如果在局部作用域内没有找到那个名字,那么就一定会在全局域找到这个变量否则就会被抛出NameError 异常。局部名字空间是首先被搜索的,存在于其局部作用域。如果找到一个名字,搜索就不会继续去寻找一个全局域的变量,所以在全局或者内建的名字空间内,可以覆盖任何匹配的名字。
global 的语法如下:
global var1[, var2[, ... varN]]]
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是closure。定义在外部函数内的但由内部函数引用或者使用的变量被称为自由变量。
闭包将内部函数自己的代码和作用域以及外部函数的作用结合起来。闭包的词法变量不属于全局名字空间域或者局部的--而属于其他的名字空间,带着“流浪"的作用域。(注意这不同于对象因为那些变量是存活在一个对象的名字空间但是闭包变量存活在一个函数的名字空间和作用域)
python 的lambda 匿名函数遵循和标准函数一样的作用域规则。一个lambda 表达式定义了新的作用域,就像函数定义,所以这个作用域除了局部lambda/函数,对于程序其他部分,该作用域都是不能对进行访问的。那些声明为函数局部变量的lambda 表达式在这个函数体内是可以访问的;然而,在lambda 语句中的表达式有和函数相同的作用域。你也可以认为函数和一个lambda 表达式是同胞。
9. 递归
如果函数包含了对其自身的调用,该函数就是递归的。如果一个新的调用能在相同过程中较早的调用结束之前开始,那么该过程就是递归的。递归广泛地应用于语言识别和使用递归函数的数学应用中。
10. 生成器
什么是python 式的生成器?从句法上讲,生成器是一个带yield 语句的函数。一个函数或者子程序只返回一次,但一个生成器能暂停执行并返回一个中间的结果----那就是yield 语句的功能, 返回一个值给调用者并暂停执行。当生成器的next()方法被调用的时候,它会准确地从离开地方继续(当它返回[一个值以及]控制给调用者时)当在2.2 生成器被加入的时候,因为它引入了一个新的关键字,yield,为了向下兼容,你需要从_future_模块中导入generators 来使用生成器。从2.3 开始,当生成器成为标准的时候,这就不再是必需的了。
与迭代器相似,生成器以另外的方式来运作:当到达一个真正的返回或者函数结束没有更多的值返回(当调用next()),一个StopIteration 异常就会抛出。
使用生成器最好的地方就是当你正迭代穿越一个巨大的数据集合,而重复迭代这个数据集合是一个很麻烦的事,比如一个巨大的磁盘文件,或者一个复杂的数据库查询。对于每行的数据,你希望执行非元素的操作以及处理,但当正指向和迭代过它的时候,你“不想失去你的地盘“。
在python2.5 中,一些加强特性加入到生成器中,所以除了next()来获得下个生成的值,用户可以将值回送给生成器[send()],在生成器中抛出异常,以及要求生成器退出[close()]。

