


Python 核心编程(第二版)——文件和输入输出
1.文件对象
文件对象不仅可以用来访问普通的磁盘文件, 而且也可以访问任何其它类型抽象层面上的"文件". 一旦设置了合适的"钩子", 你就可以访问具有文件类型接口的其它对象, 就好像访问的是普通文件一样。文件只是连续的字节序列. 数据的传输经常会用到字节流, 无论字节流是由单个字节还是大块数据组成。
2.文件内建函数【open()和 file()】
作为打开文件之门的"钥匙", 内建函数 open() [以及 file() ]提供了初始化输入/输出(I/O)操作的通用接口。
open() 内建函数成功打开文件后时候会返回一个文件对象, 否则引发一个错误。当操作失败, Python 会产生一个 IOError 异常。内建函数 open() 的基本语法是:
file_object = open(file_name, access_mode='r', buffering=-1)
file_name 是包含要打开的文件名字的字符串, 它可以是相对路径或者绝对路径. 可选变量access_mode 也是一个字符串, 代表文件打开的模式. 通常, 文件使用模式 'r', 'w', 或是 'a'模式来打开, 分别代表读取, 写入和追加. 还有个 'U' 模式, 代表通用换行符支持。使用 'r' 或 'U' 模式打开的文件必须是已经存在的. 使用 'w' 模式打开的文件若存在则首先清空, 然后(重新)创建. 以 'a' 模式打开的文件是为追加数据作准备的, 所有写入的数据都将追加到文件的末尾. 即使你 seek 到了其它的地方. 如果文件不存在, 将被自动创建, 类似以 'w'模式打开文件.
如果没有给定 access_mode , 它将自动采用默认值 'r' 。另外一个可选参数 buffering 用于指示访问文件所采用的缓冲方式. 其中 0 表示不缓冲, 1表示只缓冲一行数据, 任何其它大于 1 的值代表使用给定值作为缓冲区大小. 不提供该参数或者给定负值代表使用系统默认缓冲机制, 既对任何类电报机( tty )设备使用行缓冲, 其它设备使用正常缓冲. 一般情况下使用系统默认方式即可.
| 文件对象的访问模式 | |
| 文件模式 | 操作 |
| r | 以读方式打开 |
| rU 或 Ua | 以读方式打开, 同时提供通用换行符支持 (PEP 278) |
| w | 以写方式打开 (必要时清空) |
| a | 以追加模式打开 (从 EOF 开始, 必要时创建新文件) |
| r+ | 以读写模式打开 |
| w+ | 以读写模式打开 (参见 w ) |
| a+ | 以读写模式打开 (参见 a ) |
| rb | 以二进制读模式打开 |
| wb | 以二进制写模式打开 (参见 w ) |
| ab | 以二进制追加模式打开 (参见 a ) |
| rb+ | 以二进制读写模式打开 (参见 r+ ) |
| wb+ | 以二进制读写模式打开 (参见 w+ ) |
| ab+ | 以二进制读写模式打开 (参见 a+ ) |
| a | Python 2.3 中新增 |
open() 和 file() 函数具有相同的功能, 可以任意替换。一般说来, 我们建议使用 open() 来读写文件。
通用换行符支持(UNS):当你使用 'U' 标志打开文件的时候, 所有的行分割符(或行结束符, 无论它原来是什么)通过 Python 的输入方法(例如 read*() )返回时都会被替换为换行符NEWLINE(\n). ('rU' 模式也支持 'rb' 选项) . 这个特性还支持包含不同类型行结束符的文件. 文件对象的newlines 属性会记录它曾“看到的”文件的行结束符。
注意 UNS 只用于读取文本文件, 没有对应的处理文件输出的方法。
在编译 Python 的时候,UNS 默认是打开的. 如果你不需要这个特性, 在运行configure 脚本时,你可以使用 --without-universal-newlines 开关关闭它。
3.文件内建方法
open() 成功执行并返回一个文件对象之后, 所有对该文件的后续操作都将通过这个"句柄"进行. 文件方法可以分为四类: 输入, 输出, 文件内移动, 以及杂项操作.
1)输入
read() 方法用来直接读取字节到字符串中, 最多读取给定数目个字节. 如果没有给定 size参数(默认值为 -1)或者 size 值为负, 文件将被读取直至末尾.
readline() 方法读取打开文件的一行(读取下个行结束符之前的所有字节). 然后整行,包括行结束符,作为字符串返回.它也有一个可选的 size 参数, 默认为 -1, 代表读至行结束符. 如果提供了该参数, 那么在超过size 个字节后会返回不完整的行.
readlines() 方法并不像其它两个输入方法一样返回一个字符串. 它会读取所有(剩余的)行然后把它们作为一个字符串列表返回. 它的可选参数 sizhint 代表返回的最大字节大小. 如果它大于 0 , 那么返回的所有行应该大约有 sizhint 字节(可能稍微大于这个数字, 因为需要凑齐缓冲区大小).
2)输出
write() 内建方法把含有文本数据或二进制数据块的字符串写入到文件中去。
writelines() 方法是针对列表的操作, 它接受一个字符串列表作为参数, 将它们写入文件. 行结束符并不会被自动加入, 所以如果需要的话, 你必须在调用writelines()前给每行结尾加上行结束符.
核心笔记:保留行分隔符。当使用输入方法如 read() 或者 readlines() 从文件中读取行时, Python 并不会删除行结束符. 这个操作被留给了程序员.输出方法 write() 或 writelines() 也不会自动加入行结束符. 你应该在向文件写入数据前自己完成。
3)文件内移动
seek() 方法可以在文件中移动文件指针到不同的位置。offset字节代表相对于某个位置偏移量. 位置的默认值为 0 , 代表从文件开头算起(即绝对偏移量), 1 代表从当前位置算起, 2 代表从文件末尾算起.
text() 方法是对 seek() 的补充; 它告诉你当前文件指针在文件中的位置 - 从文件起始算起,单位为字节.
4)文件迭代
在 Python 2.2 中引进了迭代器和文件迭代,文件对象成为了它们自己的迭代器,可以使用迭代器的 next 方法, file.next() 可以用来读取文件的下一行,文件迭代更为高效, 而且写(和读)这样的 Python 代码更容易.
5)其他
close() 通过关闭文件来结束对它的访问. Python 垃圾收集机制也会在文件对象的引用计数降至零的时候自动关闭文件.
fileno() 方法返回打开文件的描述符. 这是一个整数, 可以用在如 os 模块( os.read() )的一些底层操作上.
调用 flush() 方法会直接把内部缓冲区中的数据立刻写入文件, 而不是被动地等待输出缓冲区被写入.
isatty() 是一个布尔内建函数, 当文件是一个类 tty 设备时返回 True , 否则返回False .
truncate() 方法将文件截取到当前文件指针位置或者到给定 size , 以字节为单位.
6)文件方法杂项
核心笔记: 行分隔符和其它文件系统的差异。
操作系统间的差异之一是它们所支持的行分隔符不同.在 POSIX (Unix 系列或 Mac OS X)系统上, 行分隔符是 换行符 NEWLINE ( \n ) 字符. 在旧的 MacOS 下是 RETURN ( \r ) , 而 DOS 和Wind32 系统下结合使用了两者 ( \r\n ).
另个不同是路径分隔符(POSIX 使用 "/", DOS 和 Windows 使用 "\", 旧版本的 MacOS 使用":"), 它用来分隔文件路径名, 标记当前目录和父目录.
Python 的 os 模块设计者已经帮我们想到了这些问题. os 模块有五个很有用的属性.
| 有助于跨平台开发的OS模块属性 | |
| os 模块属性 | 描述 |
|
linesep |
用于在文件中分隔行的字符串 |
| sep | 用来分隔文件路径名的字符串 |
| pathsep | 用于分隔文件路径的字符串 |
| curdir | 当前工作目录的字符串名称 |
| pardir | (当前工作目录的)父目录字符串名称 |
不管你使用的是什么平台, 只要你导入了 os 模块, 这些变量自动会被设置为正确的值, 减少了你的麻烦.
print 语句默认在输出内容末尾后加一个换行符, 而在语句后加一个逗号就可以避免这个行为.readline() 和 readlines() 函数不对行里的空白字符做任何处理,所以你有必要加上逗号. 如果你省略逗号, 那么显示出的文本每行后会有两个换行符, 其中一个是输入是附带的, 另个是 print 语句自动添加的.
文件对象还有一个 truncate() 方法, 它接受一个可选的 size 作为参数. 如果给定, 那么文件将被截取到最多 size 字节处. 如果没有传递 size 参数, 那么默认将截取到文件的当前位置.如, 你刚打开了一个文件, 然后立即调用 truncate() 方法, 那么你的文件(内容)实际上被删除,这时候你是其实是从 0 字节开始截取的( tell() 将会返回这个数值 ).


1 filename = input('Enter file name: ') 2 fobj = open(filename, 'w') 3 while True: 4 aLine = input("Enter a line ('.' to quit): ") 5 if aLine != ".": 6 fobj.write('%s%s' % (aLine, os.linesep) 7 else: 8 break 9 fobj.close()
1 >>> f = open('/tmp/x', 'w+') 2 >>> f.tell() 3 0 4 >>> f.write('test line 1\n') # 加入一个长为12 的字符串 [0-11] 5 >>> f.tell() 6 12 7 >>> f.write('test line 2\n') # 加入一个长为12 的字符串 [12-23] 8 >>> f.tell() # 告诉我们当前的位置 9 24 10 >>> f.seek(-12, 1) # 向后移12 个字节 11 >>> f.tell() # 到了第二行的开头 12 12 13 >>> f.readline() 14 'test line 2\012' 15 >>> f.seek(0, 0) # 回到最开始 16 >>> f.readline() 17 'test line 1\012' 18 >>> f.tell() # 又回到了第二行 19 12 20 >>> f.readline() 21 'test line 2\012' 22 >>> f.tell() # 又到了结尾 23 24 24 >>> f.close() # 关闭文件
file.seek(off, whence=0):从文件中移动off个操作标记(文件指针),正往结束方向移动,负往开始方向移动。如果设定了whence参数,就以whence设定的起始位为准,0代表从头开始,1代表当前位置,2代表文件最末尾位置。[注:文件需以b模式打开才可以进行文件尾计算]
| 文件对象的内建方法列表 | |
| 文件对象的方法 | 操作 |
| file.close() | 关闭文件 |
| file.fileno() | 返回文件的描述符(file descriptor ,FD, 整数值) |
| file.flush() | 刷新文件的内部缓冲区 |
| file.isatty() | 判断 file 是否是一个类 tty 设备 |
| file.next() |
返回文件的下一行(类似于file.readline() ), 或在没有其它行时引发 StopIteration 异常 |
| file.read(size=-1) |
从文件读取 size 个字节, 当未给定 size 或给定负值的时候, 读取剩余的所有字节, 然后作为字符串返回 |
| file.readinto(buf,size) |
从文件读取 size 个字节到 buf 缓冲器(已不支持) |
| file.readline(size=-1) | 从文件中读取并返回一行(包括行结束符), 或返回最大 size个字符 |
| file.readlines(sizhint=0) | 读取文件的所有行并作为一个列表返回(包含所有的行结束符); 如果给定 sizhint 且大于 0 , 那么将返回总和大约为sizhint 字节的行(大小由缓冲器容量的下一个值决定)( 比如说缓冲器的大小只能为4K 的倍数,如果sizhint 为15k,则最后返回的可能是16k———译者按) |
| file.xreadlines() | 用于迭代, 可以替换 readlines() 的一个更高效的方法 |
| file.seek(off,whence=0) | 在文件中移动文件指针, 从 whence ( 0 代表文件其始, 1 代表当前位置, 2 代表文件末尾)偏移 off 字节 |
| file.tell() | 返回当前在文件中的位置 |
| file.truncate(size=file.tell()) | 截取文件到最大 size 字节, 默认为当前文件位置 |
| file.write(str) | 向文件写入字符串 |
| file.writelines(seq) | 向文件写入字符串序列 seq ; seq 应该是一个返回字符串的可迭代对象; 在 2.2 前, 它只是字符串的列表 |
4.文件内建属性
| 文件对象的属性 | |
| 文件对象的属性 | 描述 |
| file.closed | True 表示文件已经被关闭, 否则为 False |
| file.encoding | 文件所使用的编码 - 当 Unicode 字符串被写入数据时, 它们将自动使用 file.encoding 转换为字节字符串; 若file.encoding 为 None 时使用系统默认编码 |
| file.mode | 文件打开时使用的访问模式 |
| file.name | 文件名 |
| file.newlines | 未读取到行分隔符时为 None , 只有一种行分隔符时为一个字符串, 当文件有多种类型的行结束符时,则为一个包含所有当前所遇到的行结束符的列表 |
| file.softspace | 为0 表示在输出一数据后,要加上一个空格符,1 表示不加。这个属性一般程序员用不着,由程序内部使用。 |
5.标准文件
一般说来, 只要你的程序一执行, 那么你就可以访问三个标准文件. 它们分别是标准输入(一般是键盘), 标准输出(到显示器的缓冲输出)和标准错误(到屏幕的非缓冲输出).(这里所说的"缓冲"和"非缓冲"是指 open() 函数的第三个参数.)这些文件沿用的是 C 语言中的命名, 分别为stdin , stdout 和 stderr .
Python 中可以通过 sys 模块来访问这些文件的句柄. 导入 sys 模块以后, 就可以使用sys.stdin , sys.stdout 和 sys.stderr 访问. print 语句通常是输出到 sys.stdout ; 而内建raw_input() 则通常从 sys.stdin 接受输入.
记得 sys.* 是文件, 所以你必须自己处理好换行符. 而 print 语句会自动在要输出的字符串后加上换行符。
6.命令行参数
sys 模块通过 sys.argv 属性提供了对命令行参数的访问。 命令行参数是调用某个程序时除程序名以外的其它参数.
argc 和 argv 分别代表参数个数(argumentcount)和参数向量(argument vector). argv 变量代表一个从命令行上输入的各个参数组成的字符串数组; argc 变量代表输入的参数个数. 在 Python 中, argc 其实就是 sys.argv 列表的长度,而该列表的第一项 sys.argv[0] 永远是程序的名称.总结如下:
sys.argv 是命令行参数的列表
len(sys.argv) 是命令行参数的个数(也就是 argc)
Python 2.3 引入的 optparse 模块辅助处理命令行参数,它是面向对象的。
7.文件系统
对文件系统的访问大多通过 Python 的 os 模块实现. 该模块是Python 访问操作系统功能的主要接口. os 模块实际上只是真正加载的模块的前端, 而真正的那个"模块"明显要依赖与具体的操作系统. 这个"真正"的模块可能是以下几种之一: posix (适用于 Unix 操作系统), nt (Win32),mac(旧版本的 MacOS), dos (DOS), os2 (OS/2), 等. 你不需要直接导入这些模块. 只要导入 os 模块, Python 会为你选择正确的模块, 你不需要考虑底层的工作.
| 模块的文件、目录访问函数 | |
| 函数 | 描述 |
| 文件处理 | |
| mkfifo()/mknod() | 创建命名管道/创建文件系统节点 |
| remove()/unlink() | Delete file 删除文件 |
| rename()/renames() | 重命名文件 |
| *stat() | 返回文件信息 |
| symlink() | 创建符号链接 |
| utime() | 更新时间戳 |
| tmpfile() | 创建并打开('w+b')一个新的临时文件 |
| walk() | 生成一个目录树下的所有文件名 |
| 目录/文件夹 | |
| chdir()/fchdir() | 改变当前工作目录/通过一个文件描述符改变当前工作目录 |
| chroot() | 改变当前进程的根目录 |
| listdir() | 列出指定目录的文件 |
| getcwd()/getcwdu() | 返回当前工作目录/功能相同, 但返回一个 Unicode 对象 |
| mkdir()/makedirs() | 创建目录/创建多层目录 |
| rmdir()/removedirs() | 删除目录/删除多层目录 |
| 访问/权限 | |
| access() | 检验权限模式 |
| chmod() | 改变权限模式 |
| chown()/lchown() | 改变 owner 和 group ID/功能相同, 但不会跟踪链接 |
| umask() | 设置默认权限模式 |
| 文件描述符操作 | |
| open() | 底层的操作系统 open (对于文件, 使用标准的内建 open() 函数) |
| read()/write() | 根据文件描述符读取/写入数据 |
| dup()/dup2() | 复制文件描述符号/功能相同, 但是是复制到另一个文件描述符 |
| 设备号 | |
| makedev() | 从 major 和 minor 设备号创建一个原始设备号 |
| major() /minor() | 从原始设备号获得 major/minor 设备号 |
模块 os.path 可以完成一些针对路径名的操作. 它提供的函数可以完成管理和操作文件路径名中的各个部分, 获取文件或子目录信息, 文件路径查询等操作.
| os.path 模块中的路径名访问函数 | |
| 函数 | 描述 |
| 分隔 | |
| basename() | 去掉目录路径, 返回文件名 |
| dirname() | 去掉文件名, 返回目录路径 |
| join() | 将分离的各部分组合成一个路径名 |
| split() | 返回 (dirname(), basename()) 元组 |
| splitdrive() | 返回 (drivename, pathname) 元组 |
| splitext() | 返回 (filename, extension) 元组 |
| 信息 | |
| getatime() | 返回最近访问时间 |
| getctime() | 返回文件创建时间 |
| getmtime() | 返回最近文件修改时间 |
| getsize() | 返回文件大小(以字节为单位) |
| 查询 | |
| exists() | 指定路径(文件或目录)是否存在 |
| isabs() | 指定路径是否为绝对路径 |
| isdir() | 指定路径是否存在且为一个目录 |
| isfile() | 指定路径是否存在且为一个文件 |
| islink() | 指定路径是否存在且为一个符号链接 |
| ismount() | 指定路径是否存在且为一个挂载点 |
| samefile() | 两个路径名是否指向同个文件 |
核心模块:os (和 os.path )。os 和 os.path 模块提供了访问计算机文件系统的不同方法.
8.永久存储模块
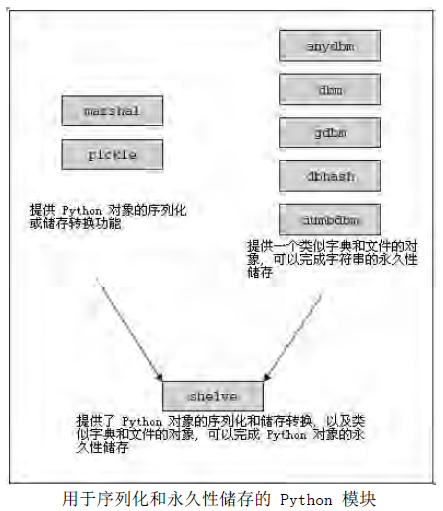
Python 提供了许多可以实现最小化永久性储存的模块. 其中的一组( marshal 和 pickle )可以用来转换并储存 Python 对象. 该过程将比基本类型复杂的对象转换为一个二进制数据集合,这样就可以把数据集合保存起来或通过网络发送, 然后再重新把数据集合恢复原来的对象格式.这个过程也被称为数据的扁平化, 数据的序列化, 或者数据的顺序化. 另外一些模块(dbhash/bsddb, dbm, gdbm, dumbdbm 等)以及它们的"管理器"( anydbm )只提供了 Python 字符串的永久性储存. 而最后一个模块( shelve ) 则两种功能都具备.
marshal 和 pickle 模块都可以对 Python 对象进行储存转换. 这些模块本身并没有提供"永久性储存"的功能, 因为它们没有为对象提供名称空间, 也没有提供对永久性储存对象的并发写入访问( concurrent write access ). 它们只能储存转换 Python 对象, 为保存和传输提供方便. 数据储存是有次序的(对象的储存和传输是一个接一个进行的). marshal 和 pickle 模块的区别在于 marshal 只能处理简单的 Python 对象(数字, 序列, 映射, 以及代码对象), 而pickle 还可以处理递归对象, 被不同地方多次引用的对象, 以及用户定义的类和实例. pickle 模块还有一个增强的版本叫 cPickle , 使用 C 实现了相关的功能.
*db* 系列的模块使用传统的 DBM 格式写入数据, Python 提供了 DBM 的多种实现:dbhash/bsddb, dbm, gdbm, 以及 dumbdbm 等.如果你不确定的话, 那么最好使用 anydbm 模块, 它会自动检测系统上已安装的 DBM 兼容模块, 并选择"最好"Edit By VheavensEdit By Vheavens的一个. dumbdbm 模块是功能最少的一个, 在没有其它模块可用时, anydbm 才会选择它.
shelve 模块使用 anydbm 模块寻找合适的 DBM 模块, 然后使用 cPickle 来完成对储存转换过程. shelve 模块允许对数据库文件进行并发的读访问, 但不允许共享读/写访问.
核心模块: pickle 和 cPickle
可以使用 pickle 模块把 Python 对象直接保存到文件里, 而不需要把它们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里. pickle 模块会创建一个 Python 语言专用的二进制格式, 你不需要考虑任何文件细节, 它会帮你干净利索地完成读写对象操作, 唯一需要的只是一个合法的文件句柄.
pickle 模块中的两个主要函数是 dump() 和 load() . dump() 函数接受一个文件句柄和一个数据对象作为参数, 把数据对象以特定格式保存到给定文件里. 当我们使用 load() 函数从文件中取出已保存的对象时, pickle 知道如何恢复这些对象到它们本来的格式. 我们建议你看一看pickle 和更"聪明"的 shelve 模块, 后者提供了字典式的文件对象访问功能, 进一步减少了程序员的工作.
9.相关模块
| 文件相关模块 | |
| 模块 | 内容 |
| base64 | 提供二进制字符串和文本字符串间的编码/解码操作 |
| binascii | 提供二进制和ASCII 编码的二进制字符串间的编码/解码操作 |
| bz2 | 访问 BZ2 格式的压缩文件 |
| csv | 访问 csv 文件(逗号分隔文件) |
| filecmp | 用于比较目录和文件 |
| fileinput | 提供多个文本文件的行迭代器 |
| getopt/optparse | 提供了命令行参数的解析/处理 |
| glob/fnmatch | 提供 Unix 样式的通配符匹配的功能 |
| gzip/zlib | 读写 GNU zip( gzip) 文件(压缩需要 zlib 模块) |
| shutil | 提供高级文件访问功能 |
| c/StringIO | 对字符串对象提供类文件接口 |
| tarfile | 读写 TAR 归档文件, 支持压缩文件 |
| tempfile | 创建一个临时文件(名) |
| uu | 格式的编码和解码 |
| zipfile | 用于读取 ZIP 归档文件的工具 |
fileinput 模块遍历一组输入文件, 每次读取它们内容的一行, 类似 Perl 语言中的不带参数的 "<>" 操作符. 如果没有明确给定文件名, 则默认从命令行读取文件名.glob 和 fnmatch 模块提供了老式 Unix shell 样式文件名的模式匹配, 例如使用星号( * )通配符代表任意字符串, 用问号( ? )匹配任意单个字符.
核心提示:使用os.path.expanduser() 的波浪号 ( ~ ) 进行扩展
虽然 glob 和 fnmatch 提供了 Unix 样式的模式匹配, 但它们没有提供对波浪号(用户目录)字符, ~ 的支持. 你可以使用 os.path.expanduser() 函数来完成这个功能, 传递一个带波浪号的目录, 然后它会返回对应的绝对路径.Unix 家族系统还支持 "~user" 这样的用法, 表示指定用户的目录. 还有, 注意 Win32版本函数没有使用反斜杠来分隔目录路径.
gzip 和 zlib 模块提供了对 zlib 压缩库直接访问的接口. gzip 模块是在 zlib 模块上编写的, 不但实现了标准的文件访问, 还提供了自动的 gzip 压缩/解压缩. bz2 类似于 gzip , 用于操作 bzip 压缩的文件.

