
Python核心编程(2)—— 对象
1.Python 对象
Python 使用对象模型来存储数据。构造任何类型的值都是一个对象。所有的Python 对像都拥有三个特性:身份,类型和值。
身份:每一个对象都有一个唯一的身份标识自己,任何对象的身份可以使用内建函数id()来得到。这个值可 以被认为是该对象的内存地址。您极少会用到这个值,也不用太关心它究竟是什么。
类型:对象的类型决定了该对象可以保存什么类型的值,可以进行什么样的操作,以及遵循什么样的规 则。可以用内建函数type()查看Python 对象的类型。
值:对象表示的数据项。
以上三个特性在对象创建的时候就被赋值,除了值之外,其它两个特性都是只读的。如果对象支持更新操作,那么它的值就可以改变,否则它的值也是只读的。对象的值是否可以更改被称为对象的可改变性(mutability)。Python 用点(.)标记法来访问属性。
2.标准类型(基本类型)
数字、整型、布尔型、长整型、浮点型、复数型、字符串、列表、元组、字典
3.其他内建类型
类型、Null对象(None)、文件、集合/固定集合、函数/方法、模块、类
通过调用type()函数你能够得到特定对象的类型信息。所有类型对象的类型都是type,它也是所有Python 类型的根和所有Python 标准类的默认元类(metaclass)。类就是类型,实例是对应类型的对象。
Python 有一个特殊的类型,被称作 Null 对象或者 NoneType,它只有一个值,那就是 None。它不支持任何运算也没有任何内建方法。None 没有什么有用的属性,它的布尔值总是False。
核心笔记:布尔值。所有标准对象均可用于布尔测试,同类型的对象之间可以比较大小。每个对象天生具有布尔 True 或 False 值。空对象、值为零的任何数字或者Null 对象 None 的布尔值都是False。以下对象的布尔值是False:None、 False (布尔类型)、所有的值为零的数【0 (整型)、 (浮点型)、0L (长整型)、 0.0+0.0j (复数)】、"" (空字符串)、 [] (空列表)、 () (空元组)、{} (空字典)。
值不是上面列出来的任何值的对象的布尔值都是 True。
4.内部类型
a.代码对象
代码对象是编译过的Python 源代码片段,它是可执行对象。通过调用内建函数compile()可以得到代码对象。代码对象可以被 exec 命令或 eval()内建函数来执行。代码对象本身不包含任何执行环境信息, 它是用户自定义函数的核心, 在被执行时动态获得上下文。(事实上代码对象是函数的一个属性)一个函数除了有代码对象属性以外,还有一些其它函数必须的属性,包括函数名,文档字符串,默认参数,及全局命名空间等等。
b.帧对象
帧对象表示 Python 的执行栈帧。帧对象包含Python 解释器在运行时所需要知道的所有信息。它的属性包括指向上一帧的链接,正在被执行的代码对象(参见上文),本地及全局名字空间字典以及当前指令等。每次函数调用产生一个新的帧,每一个帧对象都会相应创建一个C 栈帧。用到帧对象的一个地方是跟踪记录对象。
c.跟踪记录对象
当你的代码出错时, Python 就会引发一个异常。如果异常未被捕获和处理, 解释器就会退出脚本运行,显示类似下面的诊断信息:
Traceback (innermost last):
File "<stdin>", line N?, in ???
ErrorName: error reason
当异常发生时,一个包含针对异常的栈跟踪信息的跟踪记录对象被创建。如果一个异常有自己的处理程序,处理程序就可以访问这个跟踪记录对象。
d.切片对象
当使用Python 扩展的切片语法时,就会创建切片对象。扩展的切片语法允许对不同的索引切片操作,包括步进切片, 多维切片,及省略切片。切片对象也可以由内建函数 slice()来生成。
多维切片语法是 sequence[start1 : end1,start2 : end2], 或使用省略号,sequence[...,start1 : end1 ]。
步进切片允许利用第三个切片元素进行步进切片,它的语法为sequence[起始索引 : 结束索引 : 步进值]。
e.省略对象
省略对象用于扩展切片语法中,起记号作用。 这个对象在切片语法中表示省略号。类似Null 对象 None, 省略对象有一个唯一的名字 Ellipsis, 它的布尔值始终为 True。
f.Xrange对象
调用内建函数 xrange() 会生成一个Xrange 对象,xrange()是内建函数 range()的兄弟版本, 用于需要节省内存使用或 range()无法完成的超大数据集场合。
5.标准类型运算符
a.对象值的比较(==)
比较运算符用来判断同类型对象是否相等,所有的内建类型均支持比较运算,比较运算返回布尔值 True 或 False。多个比较操作可以在同一行上进行,求值顺序为从左到右。比较操作是针对对象的值进行的,也就是说比较的是对象的数值而不是对象本身。
注:实际进行的比较运算因类型而异。换言之,数字类型根据数值的大小和符号比较,字符串按照字符序列值进行比较,等等。
b.对象身份比较(is)
| 标准类型对象身份比较运算符 | |
| 运算符 | 功能 |
| obj1 is obj2 | obj1 和obj2 是同一个对象 |
| obj1 is not obj2 | obj1 和obj2 不是同一个对象 |
注:整数对象和字符串对象是不可变对象,所以Python会高效的缓存它们。
布尔逻辑运算符 and, or 和 not 都是Python 关键字,not 运算符拥有最高优先级,只比所有比较运算符低一级。 and 和 or 运算符则相应的再低一级。
| 标准类型布尔运算符 | |
| 运算符 | 功能 |
| not expr | expr 的逻辑非 (否) |
| expr1 and expr2 | expr1 和 expr2 的逻辑与 |
| expr1 or expr2 | expr1 和 expr2 的逻辑或 |
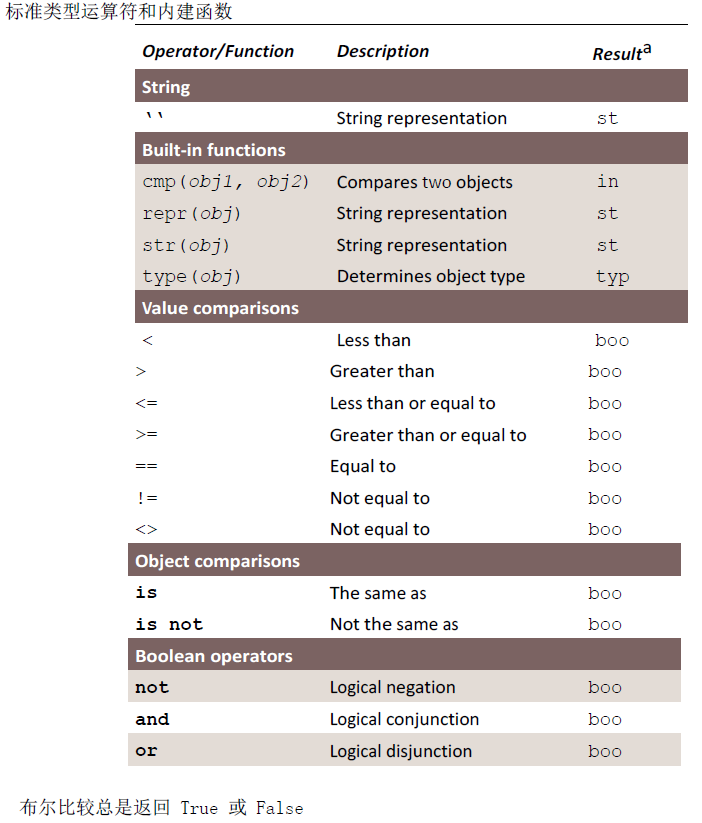
6.标准类型内建函数
Python 提供了一些内建函数用于这些基本对象类型:cmp(), repr(), str(), type(), 和等同于repr()函数的单反引号(``) 运算符。
| 标准类型内建函数 | |
| 函数 | 功能 |
| cmp(obj1, obj2) |
比较 obj1 和 obj2, 根据比较结果返回整数 i: |
| repr(obj) 或 `obj` | 返回一个对象的字符串表示 |
| str(obj) | 返回对象适合可读性好的字符串表示 |
| type(obj) | 得到一个对象的类型,并返回相应的type 对象 |
type() 的用法如下:type(object)。type() 接受一个对象做为参数,并返回它的类型。它的返回值是一个类型对象。对那些不容易显示的对象来说, Python 会以一个相对标准的格式表示这个对象,格式通常是这种形式<object_something_or_another>, 以这种形式显示的对象通常会提供对象类别,对象id 或位置, 或者其它合适的信息。
内建函数cmp()用于比较两个对象obj1 和obj2, 如果obj1 小于obj2, 则返回一个负整数,如果obj1 大于obj2 则返回一个正整数, 如果obj1 等于obj2, 则返回0。比较是在对象之间进行的,不管是标准类型对象还是用户自定义对象。如果是用户自定义对象, cmp()会调用该类的特殊方法__cmp__()。
内建函数 str() 和 repr() 或反引号运算符(``) 可以方便的以字符串的方式获取对象的内容、类型、数值属性等信息。str()函数得到的字符串可读性好, 而repr()函数得到的字符串通常可以用来重新获得该对象, 通常情况下 obj == eval(repr(obj)) 这个等式是成立的。这两个函数接受一个对象做为其参数, 返回适当的字符串。事实上 repr() 和 `` 做的是完全一样的事情,它们返回的是一个对象的“官方”字符串表示, 即绝大多数情况下可以通过求值运算(使用eval()内建函数)重新得到该对象,但str()则有所不同。str() 致力于生成一个对象的可读性好的字符串表示,它的返回结果通常无法用于eval()求值, 但很适合用于 print 语句输出。需要再次提醒一下的是, 并不是所有repr()返回的字符串都能够用eval()内建函数得到原来的对象:
>>> eval(`type(type))`)
File "<stdin>", line 1
eval(`type(type))`)
^
SyntaxError: invalid syntax
核心笔记:为什么我们有了repr()还需要``?在Python 学习过程中,你偶尔会遇到某个运算符和某个函数是做同样一件事情。之所以如此是因为某些场合函数会比运算符更适合使用。举个例子, 当处理类似函数这样的可执行对象或根据不同的数据项调用不同的函数处理时,函数就比运算符用起来方便。另一个例子就是双星号(**)乘方运算和pow()内建函数,x ** y 和 pow(x,y) 执行的都是x 的y 次方。
Python 提供了一个内建函数type()。 type()返回任意Python 对象对象的类型,而不局限于标准类型。除了内建函数type(), 还有一个有用的内建函数叫 isinstance(),isinstance()接受一个类型对象的元组做为参数。函数displayNumType() 接受一个数值参数,它使用内建函数type()来确认数值的类型(或不是一个数值类型)。
7.类型工厂函数
Python 2.2 统一了类型和类, 所有的内建类型现在也都是类, 在这基础之上, 原来的所谓内建转换函数象int(), type(), list() 等等, 现在都成了工厂函数。下面这些大家熟悉的工厂函数在老的Python 版里被称为内建函数:
int(), long(), float(), complex()
str(), unicode(), basestring()
list(), tuple()
type()
新添加的工厂函数:
dict()
bool()
set(), frozenset()
object()
classmethod()
staticmethod()
super()
property()
file()
8.标准类型的分类
“基本”,是指这些类型都是Python 提供的标准或核心类型。
“内建”,是由于这些类型是Python 默认就提供的
“数据”,因为他们用于一般数据存储
“对象”,因为对象是数据和功能的默认抽象
“原始”,因为这些类型提供的是最底层的粒度数据存储
“类型”,因为他们就是数据类型
a.存储模型
对类型进行分类的第一种方式, 就是看看这种类型的对象能保存多少个对象。Python的类型, 就象绝大多数其它语言一样,能容纳一个或多个值。一个能保存单个字面对象的类型我们称它为原子或标量存储,那些可容纳多个对象的类型,我们称之为容器存储。所有的Python 容器对象都能够容纳不同类型的对象。
| 以存储模型为标准的类型分类 | |
| 存储模型 | |
| 分类 | Python类型 |
| 标量/原子类型 | 数值(所有的数值类型),字符串(全部是文字) |
| 容器类型 | 列表、元组、字典 |
b.更新模型
另一种对标准类型进行分类的方式就是, 针对每一个类型问一个问题:“对象创建成功之后,它的值可以进行更新吗?”可变对象允许他们的值被更新,而不可变对象则不允许他们的值被更改。
| 以更新模型为标准的类型分类 | |
| 更新模型 | |
| 分类 | Python类型 |
| 可变类型 | 列表、字典 |
| 不可变类型 | 数字、字符串、元组 |
注:列表的值不论怎么变,列表的ID始终保持不变。
c.访问模型
是区分数据类型的首要模型是使用访问模型。根据访问我们存储的数据的方式对数据类型进行分类。在访问模型中共有三种访问方式:直接存取,顺序,和映射。对非容器类型可以直接访问。所有的数值类型都归到这一类序
列类型是指容器内的元素按从0 开始的索引顺序访问。一次可以访问一个元素或多个元素, 也就是大家所了解的切片(slice)。字符串, 列表和元组都归到这一类。
映射类型类似序列的索引属性,不过它的索引并不使用顺序的数字偏移量取值, 它的元素无序存放, 通过一个唯一的key 来访问, 这就是映射类型, 它容纳的是哈希键-值对的集合。
| 以访问模型为标准的类型分类 | |
| 访问模型 | |
| 分类 | Python类型 |
| 直接访问 | 数字 |
| 顺序访问 | 字符串、列表、元组 |
| 映射访问 | 字典 |
| 标准类型分类 | |||
| 数据类型 | 存储模型 | 更新模型 | 访问模型 |
| 数字 | Scalar | 不可更改 | 直接访问 |
| 字符串 | Scalar | 不可更改 | 顺序访问 |
| 列表 | Container | 可更改 | 顺序访问 |
| 元组 | Container | 不可更改 | 顺序访问 |
| 字典 | Container | 可更改 | 映射访问 |
9.不支持的类型
Python 目前还不支持的数据类型:
char 或 byte:Python无 char 或 byte 类型来保存单一字符或8 比特整数。可使用长度为1 的字符串表示字符或8 比特整数。
指针:Python 替你管理内存,因此没有必要访问指针。在Python 中你可以使用id()函数得到一个对象的身份号, 这是最接近于指针的地址。其实在Python 中, 一切都是指针。
int vs short vs long:由于Python 的整型与长整型密切融合, 用户几乎不需要担心什么。 你仅需要使用一种类型, 就是Python 的整型。即便数值超出整型的表达范围, 比如两个很大的数相乘, Python 会自动的返回一个长整数给你而不会报错。
float VS double:Python 的浮点类型实际上是C 语言的双精度浮点类型。Python 还有一种十进制浮点数类型 Decimal, 不过你必须导入decimal 模块才可以使用它。浮点数总是不精确的。Decimals 则拥有任意的精度。在处理金钱这类确定的值时,Decimal 类型就很有用。 在处理重量,长度或其它度量单位的场合, float 足够用了。
