爬虫之URLLIB模块(一)
URLLIB模块
第一章 URLLIB访问
其实趋向URLLIB模块,我更想用Requests模块
当然更多也是为了系统学习爬虫
认识下urllib模块:
> urllib.request 打开和读取 URL
> urllib.error 包含 urllib.request 抛出的异常
> urllib.parse 用于解析 URL
> urllib.robotparser 用于解析 robots.txt 文件
今天着重学习一下 urllib.request 与 urllib.parse
我们先看urllib.request模块
官方定义:
urllib.request 模块定义了适用于在各种复杂情况下打开 URL(主要为 HTTP)的函数和类 — 例如基本认证、摘要认证、重定向、cookies 及其它。
简单介绍一下今日需要的urllib.request模块下的一些使用函数或类
1、urllib.request.urlopen
看看参数介绍:
urllib.request.urlopen(url, data=None, [timeout, ]*,
cafile=None, capath=None, cadefault=False, context=None)
我们可以看到,首当其中的就是比较关键的参数:
url:打开统一资源定位地址 url,可以是一个字符串或一个 Request 对象
data:必须是一个指定要发送到服务器的其他数据的对象,或如果不需要这些数据为None
timeout:是一个可选参数,以秒为单位指定用于阻止连接尝试之类的操作的超时(如果未指定,将使用全局默认超时设置)。这实际上仅适用于HTTP,HTTPS和FTP连接。
cafile:cafile应该指向包含一堆 CA证书的单个文件
capath:capath应该指向哈希证书文件的目录
cadefault:此函数始终返回可以用作上下文管理器的对象
context:如果指定了context,则它必须是ssl.SSLContext描述各种SSL选项的实例
其实在3.6版本后不推荐使用cafile,capath和cadefault,而推荐使用context或者让 ssl.create_default_context()您为您选择系统的受信任CA证书
这里CA证书我就不扫盲了
这里用到的参数只有几个不多,
可以看一小段范例:
'导包'
import urllib.request
'引入url,就以爱思助手里面的资源为例,这个链接是隐藏链接'
ring_url = 'https://www.i4.cn/ring_1_0_1.html'
'我们在使用方法来获取资源,这里会返回一个HTTPResponse对象,可以看到我们只用了一个url参数'
resp = urllib.request.urlopen(ring_url)
'打印看一下结果是一个响应对象'
print(resp)
'打印结果如下,当然这里的 0x000001E4B8695108,每次打印都会不同,因为是一段控件地址值'
<http.client.HTTPResponse object at 0x000001E4B8695108>
现在介绍 另一个方法,是urllib.request下的一个Request类
如果上方的对象看不懂没关系,等下来介绍一些操作
我们先看一下Request类的一些参数
urllib.request.Request(url,data = None,headers = {},origin_req_host = None,unverifiable = False,method = None )
url:是一个含有一个有效 URL 的字符串。
data:必须是一个指定要发送到服务器的其他数据的对象,或者None如果不需要这些数据 但是别以为,就是这么简单,
官方详解:
当前,HTTP请求是唯一使用数据的请求。支持的对象类型包括字节,类似文件的对象以及类似字节的对象的可迭代对象。如果未提供Content-Lengthnor
Transfer-Encoding标头字段,HTTPHandler则将根据data的类型设置这些标头。
Content-Length将用于发送字节对象, 对于HTTP POST请求方法,数据应为标准application /
x-www-form-urlencoded格式的缓冲区。该
urllib.parse.urlencode()函数采用二元组的映射或序列,并以这种格式返回ASCII字符串。在用作数据参数之前,应将其编码为字节
headers:是一个字典,并且将被视为如同 add_header()以每个键和值作为参数调用时一样。这通常用于“欺骗”User-Agent标头值,该标头值由浏览器用来标识自己-一些HTTP服务器仅允许来自普通浏览器的请求而不是脚本,也就是模拟浏览器访问
Content-Type如果存在data 参数,则应包含适当的标头。如果未提供此标头并且数据 不是None,则将默认添加。Content-Type: application/x-www-form-urlencoded
origin_req_host:是原始事务的请求主机,默认为http.cookiejar.request_host(self)。这是用户发起的原始请求的主机名或IP地址。例如,如果请求是针对HTML文档中的图像,则该请求应该是包含该图像的页面的请求的请求主机,其实指请求方的 host 名称或者 IP 地址
unverifiable:指出请求是否不可验证, 默认为False。unverifiable的请求是用户无法选择URL的请求。例如,如果请求是针对HTML文档中的图像,并且用户没有选择权限自动获取图像,则应为true
method:是指使用的HTTP请求方法的字符串(例如’HEAD’)。如果提供,则其值存储在 method属性中,使用get_method()。默认值是’GET’如果数据是None或’POST’以其他方式。子类可以通过method在类本身中设置属性来指示不同的默认方法 ,意思就是请求方法是GET还是POST或是PUT等等其他请求方法
我们再举个🌰
'导包'
import urllib.request
'继续引入url,爱思助手里面的资源铃声,这个链接是隐藏链接'
ring_url = 'https://www.i4.cn/ring_1_0_1.html'
'这次不同我们需要加入头部信息,这个头部信息,是浏览器的标识'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
'我们在使用方法来获取资源,这里会返回一个Response对象,可以看到我们用了一个url参数和一个headers信息'
resp = urllib.request.Request(url = ring_url, headers = head)
'打印看一下是Response对象'
<class 'urllib.request.Request'>
上方请求的方法都是GET请求,
那什么又是POST请求
我们继续看一段代码
'导包'
import urllib.request
'这次我们换一个连接'
ring_url = 'http://httpbin.org/post'
'我们需要加入头部信息,这个头部信息,是浏览器的标识,还可以加入其他的一些信息,例如Host'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
'Host':'httpbin.org/post'
}
'这里加上我们的data数据'
url_from = {
'name': 'Go China, go HuaWei'
}
'注意data是字节流编码格式的内容,即 bytes 类型,这里urlencode接下就要讲到.'
data = bytes(urllib.parse.urlencode({'name': 'Go China, go HuaWei'}), encoding='utf8')
'''
我们在使用方法来获取资源,这里会返回一个Response对象,
可以看到我们用了
一个url参数
一个data参数
一个headers信息
一个method请求方式
'''
resp_url = urllib.request.Request(url=ring_url, data=data, headers=head, method='POST')
'其实我们发现我们构造好的是一个Request请求对象,那现在就需要请求,请求还是用到urlopen方法'
resp = urllib.request.urlopen(resp_url)
'最终返回的还是一个HTTPResponse对象'
<http.client.HTTPResponse object at 0x000001CB2A7BB348>
我们有三个问题出现了,
第一个urllib.parse.urlencode和urllib.parse
第二个HTTPResponse这个对象是什么
第三个如何使用这个对象拿到我们想要的资源
跟着节奏来,我们了解到
urllib.parse.urlencode:将自定义的字典的数据转成字节流,使用 bytes() 方法,
第一个参数需要是str(字符串)类型, 用到了 urllib.parse 模块里的 urlencode() 方法来将参数字典转化为字符串。
第二个参数指定编码格式,在这里指定为 utf8
2、urllib.parse
我们只要这个模块是用于解析 URL
下方官方定义翻译了一下:
该模块定义了一个标准接口,用于分解组件中的统一资源定位符(URL)字符串(寻址方案,网络位置,路径等),将组件组合回URL字符串,并将“相对URL”转换为给出“基本URL”的绝对URL
支持协议的方案有很多:
file,ftp, gopher,hdl,http,https,imap,mailto,mms,news,nntp,prospero,rsync,rtsp,rtspu,sftp, shttp,sip,sips,snews,svn,svn+ssh,telnet, wais,ws,wss
功能分为两大类:URL解析和URL引用
URL解析:
解析的话,我比较说一下基于解析ASCII编码字节,如果想了解更多,有兴趣可以看看官方的解析
URL解析函数最初设计为仅对字符串进行操作。
在实践中,能够将url正确地引用并编码为ASCII字节序列是很有用的。相应地,该模块中的URL解析函数除了操作str对象外,还都操作bytes和bytearray对象
如果传入str数据,结果也将只包含str数据。如果传入字节或bytearray数据,结果将只包含字节数据。
试图在单个函数调用中混合str数据和字节或bytearray将导致类型错误,而试图传入非ascii字节值将触发UnicodeDecodeError。
为了更容易地在str和字节之间转换结果对象,URL解析函数的所有返回值都提供了encode()方法(当结果包含str数据时)或decode()方法(当结果包含字节数据时)。
这些方法的签名 与对应的str和bytes方法的签名相匹配 (除了默认编码是’ascii’而不是’utf8’)。
每个函数都会生成一个对应类型的值,该值包含bytes数据(对于encode()方法)或str数据
(对于decode()方法)。需要对可能包含非ascii数据的引用不当的URL进行操作的应用程序,在调用URL解析方法之前,需要自己进行从字节到字符的解码。
URL引用
URL引用函数主要用于获取程序数据,并通过引用特殊字符和对非ascii文本进行适当编码来确保其作为URL组件使用时的安全性。如果上面的URL解析函数没有涉及到该任务,它们还支持反向这些操作,以便从URL组件的内容重新创建原始数据
例如刚才使用的urllib.parse.urlencode方法
如果用作urlopen()函数进行POST操作的数据,那么需要将其编码为字节,否则将导致类型错误
这里还需要引入一个概念百分号编码以及url的一些信息解释
我们随意拿到一个链接,例如我们从百度随意搜索信息,获取一条链接
https://www.baidu.com/s?ie=UTF-8&wd=%E5%AE%8C%E7%BE%8E%E4%B8%96%E7%95%8C
'''
我们看到除了除了固定的网址后方在?号的后面出现了一些类似字典形式或者是赋值变量形式的参数
例如
我们分解一下看看
域名
https://www.baidu.com/s 这里是百度资源服务器访问的搜索重定向界面,如果去除s既是百度搜索首页,当然也存在Ajax异步请求局部刷新
?号:这个问号有两个作用最主要的就是连接作用,后面连接一些参数
ie=UTF-8和wd=%E5%AE%8C%E7%BE%8E%E4%B8%96%E7%95%8C这两个参数使用了&进行连接
我们看到
wd后面是一连串的%E5%AE%8C%E7%BE%8E%E4%B8%96%E7%95%8C类似一定格式的编码,这就是百分号编码
实际上这种编码,也是对url的一中特殊处理
实际wd就是对应的参数时完美世界,也就是我需要搜索的参数
而且这段链接并没有完全编码
'''
所以这里我们入第二个方法解编码
urllib.parse.quote
urllib.parse.quote(string, safe='/', encoding=None, errors=None)
'''
按照标准,URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,此时就要进行编码。因为在构造URL的过程中要使用到中文
'''
'如此就构造一个百度搜索的代码'
'导包'
import urllib.request, urllib.parse
'先手动输入搜索内容'
search = input("请输入您需要搜搜的内容:")
'接着转一下编码,其实也可以直接搜索不用转,但是为了安全,可以先转一下'
qu_search = urllib.parse.quote(search)
'这次上百度链接,wd后面的参数单独择出来,他不是一个百分号编码么,那就给他转一转'
bd_url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd='+ qu_search
'这里我们打印看看url的链接'
print(bd_url)
'我们需要加入头部信息,这个头部信息,是浏览器的标识,还可以加入其他的一些信息,例如Host'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
'存储请求信息'
resp_url = urllib.request.Request(url=bd_url, headers=head, method='GET')
'请求url'
resp = urllib.request.urlopen(resp_url)
'这次我们不返回什么对象了,我们要数据,使用read读取数据,并将字节流数据转码utr8,拿到的是一个网页源码。'
print(resp.read().decode('utf8'))
看一下结果
这里拿到的数据是我们没办法看懂的一个HTTPResponse对象,实际就是我们请求url,服务器返回给我们的一个响应,存在需要的数据
那我们需要使用这个对象拿到数据,就需要一些操作方法登场了,
HTTPResponse.read([amt])
读取并返回响应体,amt可选字节数,读取指定字节数
这也是常用的读取数据方法,当然限定在urllib模块下的请求获取到的,HTTPResponse对象,当然获取到的是字节流,需要进行解码转成可读编码,就是用到上方说明的deocde方法
HTTPResponse.getheader(name[, default])
获得指定头信息
HTTPResponse.getheaders()
获得(header, value)元组的列表
HTTPResponse.fileno()
获得底层socket文件描述符
HTTPResponse.msg
获得头内容
HTTPResponse.version
获得头http版本
HTTPResponse.status
获得返回状态码
HTTPResponse.reason
获得返回说明
以上可以测试操作,
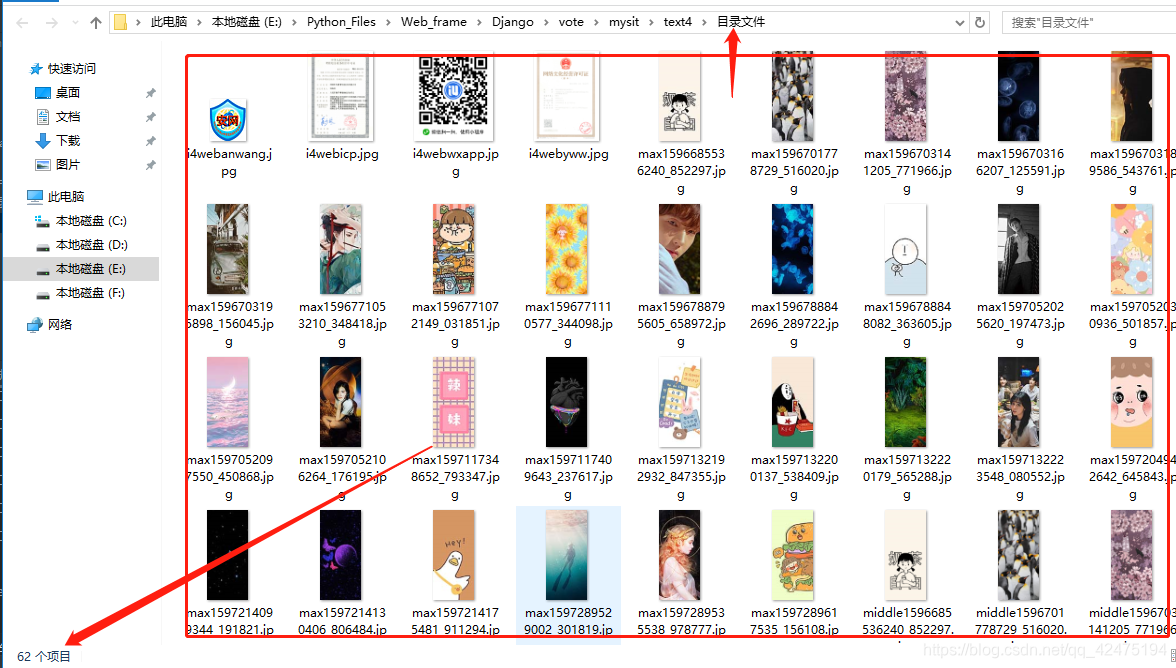
那接下来我们就上来一个爬取案例,我们爬取爱思助手图片,并保存到本地的案例
'''
思路是:
我们先找到爱思助手图片的链接地址:
bd_pict_url = 'https://www.i4.cn/wper_1_0_0_1.html'
通过uillib.request 模块里面的 Request方法构建
我们使用urlopen函数获取地址的网页源数据
拿到数据后,通过re模块,正则表达式筛选,当然这里只是测试,不懂得同学可以使用在线正则网站匹配规则,筛选后拿到的是列表,
将列表的url再次通过urlopen方法请求数据,拿到数据写入文件
'''
'首先先导入包'
import urllib.request, urllib.parse
import re
import os
'url连接'
bd_pict_url = 'https://www.i4.cn/wper_1_0_0_1.html'
'头部信息'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
'构建好信息'
pict_url = urllib.request.Request(url=bd_pict_url, headers=head, method='GET')
'请求源码文件'
resp = urllib.request.urlopen(pict_url).read().decode('utf8')
'正则定义晒筛选方法,将http图片格式的 url,筛选方法定义'
re_url = re.compile(r'[a-zA-z]+://[^\s]*.jpg')
'完后源码筛选'
url_list = re_url.findall(resp)
'这里是为了防止目录不存在先创建'
if not os.path.exists('图片目录'):
os.mkdir('图片目录')
'遍历列表里面的url,然后进项请求,'
for i in url_list:
'这里使用的文件名是一个组成字符串操作'
file = (i[8:].split('/'))[1] + (i[8:].split('/'))[-1]
'这里是相对路径,读写文件数据,二进制'
with open(f'图片目录/{file}', 'wb+') as f:
data = urllib.request.urlopen(i).read()
f.write(data)
print(f'写入文件:{file},成功')
print('写入完成')
以上完成了简单的图片爬取,我们看一下文件图片
好的今天介绍到这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号