[转] Location语法规则
Location规则
语法规则: location [=||*|^~] /uri/ {… }
首先匹配 =,其次匹配^~,其次是按文件中顺序的正则匹配,最后是交给 /通用匹配。当有匹配成功时候,停止匹配,按当前匹配规则处理请求。
| 符号 | 含义 |
|---|---|
| = | = 开头表示精确匹配 |
| ^~ | ^~开头表示uri以某个常规字符串开头,理解为匹配 url路径即可。nginx不对url做编码,因此请求为/static/20%/aa,可以被规则^~ /static/ /aa匹配到(注意是空格) |
| ~ | ~ 开头表示区分大小写的正则匹配 |
| ~* | ~* 开头表示不区分大小写的正则匹配 |
| !~ 和 !~* | !~ 和 !~*分别为区分大小写不匹配及不区分大小写不匹配的正则 |
| / | 用户所使用的代理(一般为浏览器) |
| $http_x_forwarded_for | 可以记录客户端IP,通过代理服务器来记录客户端的ip地址 |
| $http_referer | 可以记录用户是从哪个链接访问过来的 |
匹配规则示例:
location = / {
#规则A
}
location = /login {
#规则B
}
location ^~ /static/ {
#规则C
}
location ~ \.(gif|jpg|png|js|css)$ {
#规则D
}
location ~* \.png$ {
#规则E
}
location !~ \.xhtml$ {
#规则F
}
location !~* \.xhtml$ {
#规则G
}
location / {
#规则H
}
那么产生的效果如下:
- 访问根目录/,比如http://localhost/将匹配规则A
- 访问 http://localhost/login 将匹配规则B,http://localhost/register则匹配规则H
- 访问 http://localhost/static/a.html 将匹配规则C
- 访问 http://localhost/a.gif,http://localhost/b.jpg 将匹配规则D和规则E,但是规则D顺序优先,规则E不起作用,而http://localhost/static/c.png则优先匹配到规则C
- 访问 http://localhost/a.PNG 则匹配规则E,而不会匹配规则D,因为规则E不区分大小写。
- 访问 http://localhost/a.xhtml 不会匹配规则F和规则G,http://localhost/a.XHTML不会匹配规则G,因为不区分大小写。规则F,规则G属于排除法,符合匹配规则但是不会匹配到,所以想想看实际应用中哪里会用到。
- 访问 http://localhost/category/id/1111 则最终匹配到规则H,因为以上规则都不匹配,这个时候应该是nginx转发请求给后端应用服务器,比如FastCGI(PHP),tomcat(jsp),nginx作为方向代理服务器存在。
实际常用规则
直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理。
这里是直接转发给后端应用服务器了,也可以是一个静态首页。
第一个必选规则
location = / {
proxy_passhttp://tomcat:8080/index
}
第二个必选规则是处理静态文件请求,这是nginx作为http服务器的强项
location ^~ /static/ {
# 请求/static/a.txt 将被映射到实际目录文件:/webroot/res/static/a.txt
root /webroot/res/;
}
location ~* \.(gif|jpg|jpeg|png|css|js|ico)${
root /webroot/res/;
}
第三个规则就是通用规则,用来转发动态请求到后端应用服务器
非静态文件请求就默认是动态请求,自己根据实际把握
毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了
location / {
proxy_pass http://tomcat:8080/
}
- 1
- 2
- 3
Location解析过程
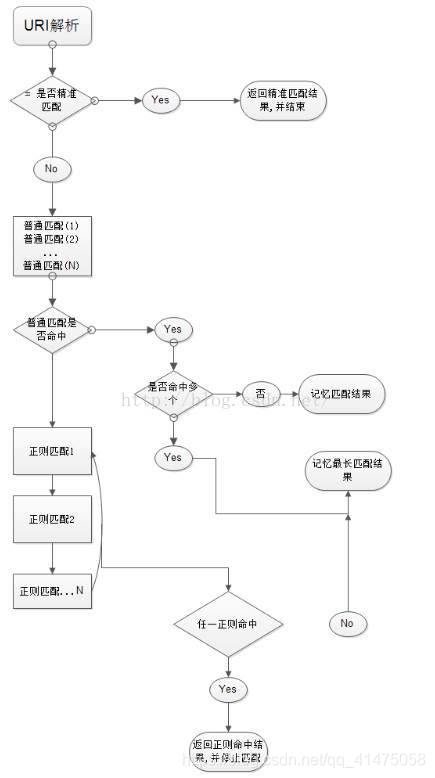
总结:
1、 先判断精准命中,如果命中,立即返回结果并结束解析过程。
2、 判断普通命中,如果有多个命中,“记录”下来“最长”的命中结果(记录但不结束,最长的为准)。
3、 继续判断正则表达式的解析结果,按配置里的正则表达式顺序为准,由上至下开始匹配,一旦匹配成功1个,立即返回结果,并结束解析过程。
4、 普通命中顺序无所谓,是因为按命中的长短来确定。正则命中,顺序有所谓,因为是从前入往后命中的。
5、= 的精确匹配优先级最高,无论放置的顺序如何,它都将优先被匹配并执行。 / 为默认匹配,即如果没有匹配上其他的location,则最后匹配默认匹配的部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}