mysql存储引擎
一、Mysql体系结构

Mysql服务层实现了所有与存储引擎无关的特性。
select语句:不管对于哪种存储引擎而言,我都要是要查出想要的数据,select语句的功能就是在mysql服务层实现的。至于如何从文件中获取到我们所要查询的数据,这个具体的实现方式则是由下一层的存储引擎层来实现的。
存储引擎层时mysql与其它数据库差异最大的地方。mysql定义了一系列存储引擎的接口,只要符合存储引擎接口的要求就可以为mysql开发出一款完全符合自己需要的存储引擎。
这种插件式存储引擎最大的特点就是灵活。可以根据不同的应用特点选择不同的存储引擎。
注意:存储引擎是针对于表的而不是针对于库的,也就是说一个库中的不同表可以使用不同的存储引擎。
二、MyISAM存储引擎
mysql5.5之前版本默认的存储引擎。
1、MyISAM会把数据和索引存储情况:
数据-> MYD为拓展名的文件中。
索引-> MYI为拓展名的文件中。
2、特性
并发性与锁级别(表级锁,读写互斥),因此MyISAM对读写混合操作的并发性支持并不会很好。
表损害修复,Myisam支持因任何意外关闭而损害的myisam表进行检查和修复操作。修复中也可能造成数据的丢失。
check table tableName 进行检查,
repair table tableName进行修复。
myisamchk --help 这个工具也可以用来修复。(需要将mysql服务停止,如果是运行中执行该命令,可能会对表造成更大得损坏)
3、myisam表支持的索引类型。
- 全文索引,mysql5.6之前唯一支持全文索引的官方存储引擎。
- 对text和blog值类型支持前500个字符的前缀索引。
myisam表支持数据压缩(对表中的数据不需要修改),且是单行压缩的,如果只需要读取表中某些行的数据是不需要对整个表进行解压的。
压缩命令:myisampack
4、示例:
现在我们在test库中建立一张myisam为存储引擎的myIsam表。
create table myIsam(id int,c1 varchar(10))engine=myisam;
进入mysql的安装目录,然后进入test目录(每个库都有一个目录)。
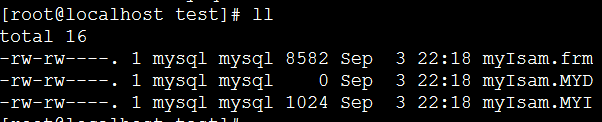
.frm为后缀的文件是很多存储引擎都会有的文件,用来存放表结构。
.MYD和.MYI是myisam存储引擎特有的文件。
检查myIsam表。
check table myIsam;
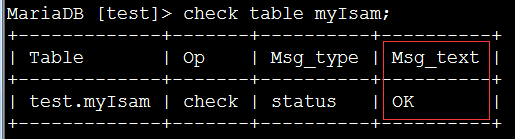
如果Msg_text=ok,表示我们的表示正常的。
修复myIsam表(虽然不需要)
repair table myIsam;
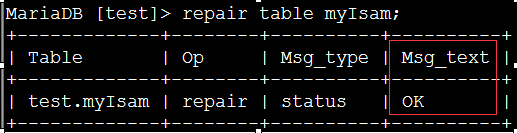
如果有损坏的myisam表时,就可以用 repair来进行修复。
对myIsam表进行压缩
//–backup,-b 使用table_name.OLD名备份表数据文件
myisampack -b -f myIsam.MYI

这里是因为我的表中数据为空,我又采用了 -f 进行强制压缩,所有压缩后的文件比压缩前的文件还大。
如果myisam表已经压缩了,在对myisam表进行写入操作,会提示 read only.的表,所有压缩后的表是个只读表,是不能进行写入操作的。

5、限制
- version < 5.0 时,单表默认大小最大为 4G。如果需要在单表中存储超过4G的数据时,则需要在建表是指定 MAX_Rows 和 AVG_ROW_LENGTH 来实现。二者相乘的大小即为表最大的大小。
- version > 5.0时,默认支持 256TB。
6、适用场景
- 非事务型应用。
- 只读类应用(可进行数据压缩,且共享锁不影响读)。
- 空间类应用(mysql5.7之前,MyIsam是唯一支持空间函数的存储引擎)。
三、InnoDB存储引擎
mysql5.58版本之后InnoDB称为默认存储引擎。
InnoDB使用表空间进行数据存储,具体存储在什么样的表空间呢,由参数 innodb_file_per_table 来进行定义。
innodb_file_per_table=ON :独立表空间,户存储在 tableName.idb 中。
innodb_file_per_table=OFF : 系统共享表空间, 存储在ibdataX中,X是一个数字。
show variables like 'innodb_file_per_table';

1、共享表空间
create table myinnodb(id int,c1 varchar(10))engine='innodb';

frm后缀的文件用来记录表结构。
实际数据存储在安装目录下的 ibdata*的共享表空间中的。

2、独立表空间
SET GLOBAL innodb_file_per_table=ON;
create table myinnodb_on(id int c1 varchar(10))engine='innodb';

frm后缀的文件用来记录表结构。
idb文件就是innodb表数据实际存储的地方。
3、系统表空间和独立表空间要如何选择
比较
- 系统表空间无法简单的收缩文件大小,独立表空间可以通过optimize table 命令收缩系统文件。
- 系统表空间会产生IO瓶颈,独立表空间可以同时向多个文件刷新数据。
建议:对InnoDB使用独立表空间。mysql5.6后,独立表空间为默认配置。
4、表转移的步骤
把原来存在于系统表空间中的表转移到独立表空间的方法。
- 使用mysqldump导出所有数据库表数据。
- 停止mysql服务,修改参数,并删除InnoDB相关文件。
- 重启mysql服务,重建Innodb系统表空间。
- 重新导入数据。
5、InnoDB存储引擎的特性。
- InnoDB数据字典存放的都是InnoDB存储引擎相关的一些数据字典,如事务,Undo回滚段。frm后缀是mysql数据库服务器层的数据字典,对mysql所有存储引擎都是一样的。
- Innodb是一种事务型存储引擎。完全支持输入的ACID特性。
- Innodb之所以有事务ACID特性,主要依赖于重做日志Redo Log 和 回滚日志Undo Log。
- Innodb支持行级锁,行级锁可以最大程度的支持并发,行级锁是由存储引擎层实现的。
6、Redo Log
Redo Log 主要用于实现事务的持久性,它存储的是已提交的事务,由内存中的重做日志缓冲区(由innodb_file_buffer_size参数来决定其大小,单位字节)和重做日志文件(ib_logfile开头的一些文件)两部分组成。
show variables like 'innodb_log_buffer_size';

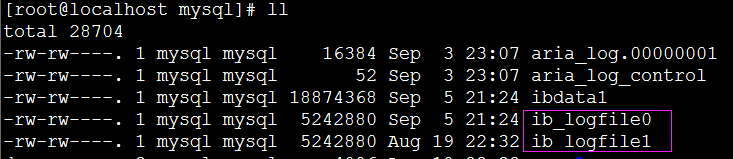
ib_logfile*文件的个数有 innodb_log_files_in_group 参数来决定。
show variables like 'innodb_log_files_in_group';

7、Undo Log
Undo Log主要是帮助未提交事务进行回滚。它存储的是未提交的事务。
Undo Log会发生大量的随机读写,不像redo Log那样几乎都是顺序读写。
mysql5.6之后,支持UndoLog独立于表空间存在,这样就可以将UndoLog存储在固态磁盘上,以获得更好的随机读写性能。
8、什么是锁
锁的主要作用是管理共享资源的并发访问。
锁用于实现事务的隔离性。
9、锁的粒度。
表级锁
虽然我们的innodb是行级锁,但是我们也可以给它加上表级锁。
lock table myinnodb write;

此时我们在另一个连接中查询被锁住的这张表,就会发现已经阻塞住了。

直到我们执行解锁操作时,我们的第二个连接才能查出该表的数据。
unlock tables;
行级锁
行级锁能最大程度支持并发,但是锁的开销也会大一些,行级锁只在存储引擎中实现, mysql服务器层并没有实现。
10、阻塞与死锁
什么是阻塞?
一个连接要等待另一个连接所占用的资源释放,才能正常执行。
什么是死锁?
两个或两个以上的事务在等待过程中相互占用了对方的资源而产生的一种异常。
11、InnoDB提供了一个独特的性能监控工具。
包含了一些平均值统计信息,这些平均值是上次结果输出后生成的统计数。如果要使用该命令,要确保两次输出间至少间隔30s左右的时间。
show engine innodb status\G;
//统计的是过去41秒内数据的一个平均值。 ===================================== 190906 22:53:46 INNODB MONITOR OUTPUT ===================================== Per second averages calculated from the last 41 seconds ----------------- //线程相关信息 ----------------- BACKGROUND THREAD ----------------- //信号相关信息 ---------- SEMAPHORES ---------- //文件IO相关信息(读写进程,默认有4读4写进程) -------- FILE I/O -------- //缓存和自适应hash索引的一些信息 ------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- //log信息 --- LOG --- //缓存池和内存的信息,总的内存分配和附加缓冲池的一些信息 ---------------------- BUFFER POOL AND MEMORY ---------------------- //行的操作信息 -------------- ROW OPERATIONS -------------- //事务相关信息 ------------ TRANSACTIONS ------------
12、Innodb存储的适用场景
Innodb适合于大多数OLTP应用(在V5.6之后,InnoDB也支持全文索引和空间函数)。
四、Memory
1、了解memory存储引擎
也称为HEAP存储引擎,所有数据保存在内存中。
一旦数据库重启,memcache存储引擎中所有的表数据都会丢失,但是表结构会保存下来。因为表结构是保存在.frm后缀的文件中的,而数据是保存在内存中的。
memory存储引擎的效率要比myisam的效率高很多。因为myisam虽然索引是保存在内存中,但是数据是由操作系统来缓存的。memory存储引擎的数据和索引都是保存在内存中的。
2、Memory支持的索引类型。
- HASH索引
- BTree索引
HASH索引
如果建立索引时没有指定类型的话,默认建立的是hash索引。
特点
在做等值查询的时候非常快,但是如果做范围查询的话,就无法使用hash索引了。
BTree索引
如果大部分查找都是范围查找的话,我们需要建立BTree索引
不正确的索引类型会对性能造成很大的影响。
3、所有字段存储都是固定长度
就算我们定义表时使用了varchar(10)也会被转为char(10).
4、不支持BLOG和TEXT等大字段。
5、Memory存储引擎使用表级锁。
尽管memcache所有的数据和索引都在内存中,但是在一个繁忙的系统中,其性能也不见得会比InnoDB好,因为InnoDB也会把所需要的数据和索引缓存在内存中,如果我们访问的是热数据的话,也是从内存中进行读取的,且Innodb支持行级锁,能最大程度的支持并发。
6、memory的大小
memory最大大小由 max_heap_table_size 参数决定。默认值为16M,注意修改这个参数对已存在的memory表是无效的。如果想让已存在的表生效,就需要对已存在的表进行重建。
7、示例
如果我们建立text类型,会报错。
CREATE TABLE mymemory(id int,c1 varchar(10),c2 char(10),c3 text)engine=memory;

创建一个正常的表
CREATE TABLE mymemory(id int,c1 varchar(10),c2 char(10))engine=memory;
查看表的文件存储方式

说明memory的表数据是不存在于数据文件中的,只有一个存储表结构的,frm文件。
创建一个默认的索引
create index idx_c1 on mymemory(c1);
创建一个btree索引
create index idx_c2 using btree on mymemory(c2);
查看索引情况
show index from mymemory\G

查看表的状态信息
show table status like 'mymemory'\G;

说明就算我们定义了varchar的类型,也会被转成固定长度的类型。
8、容易混淆的概念
Memory存储引擎表和临时表
临时表
分为查询优化器所使用的内部零时表和create temporary table创建的零时表

9、使用场景
- 用于查找或者是映射表,例如邮编和地区的对应表。
- 用于保存数据分析中产生的中间表。
- 用于缓存周期性聚合数据的结果表。
10、注意:
Memory数据易失,所以要求数据可再生。
容易犯的错误:如果我们想在主从复制的主db中使用memory存储引擎的表,而在从db中使用innodb或myisam存储引擎的表,想以这样的方式来保证当主db重启是,从db中还有一份可用的数据,可是实际上主db在重启时会重建memory存储引擎的表,所以从db上相同的表也会被重建,故数据还是会丢失。
五、如何选择存储引擎
参考条件
- 事务 (目前只有Innodb能完美的支持事务)
- 备份 (只有Innodb有免费的在线热备方案,mysqldump不算在线热备的方案,它需要对数据加锁)
- 崩溃恢复(myisam表由于系统崩溃导致数据损坏的概率比Innodb高跟很多,而且恢复速度也没有innodb快)
- 存储引擎特有的特性(如需要聚簇索引,那就需要选择innodb存储引擎,有的需要使用地理空间搜索,那 )
总的来说如果没有什么非常非常特殊的需求,我们一般就选择innodb存储引擎,切记不要在同一个库中同时使用多个不同的存储引擎。
本文为袋鼠学习中的总结,如有转载请注明出处:https://www.cnblogs.com/chrdai/protected/p/11456322.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号