Spark 3.2使用体验
👀 单机安装部署
基于官网:spark-3.2.2-bin-hadoop3.2.tgz包
测试机器:hyper-v test001
路径: /home/soft/spark-3.2.2-bin-hadoop3.2
修改spark-defaults.conf
# Example:
# spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir s3a://bigdatas/sparklogs
spark.hadoop.fs.s3a.access.key minio
spark.hadoop.fs.s3a.secret.key minio123
spark.hadoop.fs.s3a.impl org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3a.endpoint http://minio.local:32000
spark.hadoop.fs.s3a.connection.ssl.enabled false
spark.hadoop.fs.s3a.path.style.access true
spark.hadoop.fs.s3a.aws.credentials.provider org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider
spark.yarn.historyServer.address=spark.master.local:18080
spark.history.ui.port=18080
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
修改spark-env.sh
export SPARK_MASTER_WEBUI_PORT=8083
修改workers
localhost
修改log4j.properties
cp log4j.properties.template log4j.properties
./jars目录添加一些jar包
https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.2/hadoop-aws-3.2.2.jar
https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-bundle/1.11.563/aws-java-sdk-bundle-1.11.563.jar
配置~/.bashrc
export JAVA_HOME=/home/soft/jdk1.8.0_212
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export SPARK_HOME=/home/soft/spark-3.2.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
Spark-Submit
local模式
即单机模式,命令执行之后当前机器默认就是master节点
spark-submit --class org.apace.spark.examples.SparkPi --num-executors 1 /home/soft/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar
日志:
[root@test001 spark-3.2.2-bin-hadoop3.2]# spark-submit --class org.apache.spark.examples.SparkPi --num-executors 1 /home/soft/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar
23/07/10 17:02:39 WARN Utils: Your hostname, test001 resolves to a loopback address: 127.0.0.1; using 192.168.137.100 instead (on interface eth0)
23/07/10 17:02:39 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
23/07/10 17:02:39 INFO SparkContext: Running Spark version 3.2.2
23/07/10 17:02:39 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
23/07/10 17:02:39 INFO ResourceUtils: ==============================================================
23/07/10 17:02:39 INFO ResourceUtils: No custom resources configured for spark.driver.
23/07/10 17:02:39 INFO ResourceUtils: ==============================================================
23/07/10 17:02:39 INFO SparkContext: Submitted application: Spark Pi
23/07/10 17:02:39 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
23/07/10 17:02:39 INFO ResourceProfile: Limiting resource is cpu
23/07/10 17:02:39 INFO ResourceProfileManager: Added ResourceProfile id: 0
23/07/10 17:02:39 INFO SecurityManager: Changing view acls to: root
23/07/10 17:02:39 INFO SecurityManager: Changing modify acls to: root
23/07/10 17:02:39 INFO SecurityManager: Changing view acls groups to:
23/07/10 17:02:39 INFO SecurityManager: Changing modify acls groups to:
23/07/10 17:02:39 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/07/10 17:02:39 INFO Utils: Successfully started service 'sparkDriver' on port 34175.
23/07/10 17:02:40 INFO SparkEnv: Registering MapOutputTracker
23/07/10 17:02:40 INFO SparkEnv: Registering BlockManagerMaster
23/07/10 17:02:40 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
23/07/10 17:02:40 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
23/07/10 17:02:40 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
23/07/10 17:02:40 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-e7753769-7e74-4784-98b2-6e3291041837
23/07/10 17:02:40 INFO MemoryStore: MemoryStore started with capacity 366.3 MiB
23/07/10 17:02:40 INFO SparkEnv: Registering OutputCommitCoordinator
23/07/10 17:02:40 INFO Utils: Successfully started service 'SparkUI' on port 4040.
23/07/10 17:02:40 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://minio.local:4040
23/07/10 17:02:40 INFO SparkContext: Added JAR file:/home/soft/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar at spark://minio.local:34175/jars/spark-examples_2.12-3.2.2.jar with timestamp 1688979759604
23/07/10 17:02:40 INFO Executor: Starting executor ID driver on host minio.local
23/07/10 17:02:40 INFO Executor: Fetching spark://minio.local:34175/jars/spark-examples_2.12-3.2.2.jar with timestamp 1688979759604
23/07/10 17:02:40 INFO TransportClientFactory: Successfully created connection to minio.local/192.168.137.100:34175 after 21 ms (0 ms spent in bootstraps)
23/07/10 17:02:40 INFO Utils: Fetching spark://minio.local:34175/jars/spark-examples_2.12-3.2.2.jar to /tmp/spark-444257f5-6b8d-4ca9-9caa-b70acebe1fd4/userFiles-2aa5801f-5102-4ec0-9ec5-c756fad2384f/fetchFileTemp2244229015190384862.tmp
23/07/10 17:02:40 INFO Executor: Adding file:/tmp/spark-444257f5-6b8d-4ca9-9caa-b70acebe1fd4/userFiles-2aa5801f-5102-4ec0-9ec5-c756fad2384f/spark-examples_2.12-3.2.2.jar to class loader
23/07/10 17:02:40 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39429.
23/07/10 17:02:40 INFO NettyBlockTransferService: Server created on minio.local:39429
23/07/10 17:02:40 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
23/07/10 17:02:40 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, minio.local, 39429, None)
23/07/10 17:02:40 INFO BlockManagerMasterEndpoint: Registering block manager minio.local:39429 with 366.3 MiB RAM, BlockManagerId(driver, minio.local, 39429, None)
23/07/10 17:02:40 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, minio.local, 39429, None)
23/07/10 17:02:40 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, minio.local, 39429, None)
23/07/10 17:02:40 WARN MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties
23/07/10 17:02:40 INFO MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
23/07/10 17:02:40 INFO MetricsSystemImpl: s3a-file-system metrics system started
23/07/10 17:02:41 INFO SingleEventLogFileWriter: Logging events to s3a://bigdatas/sparklogs/local-1688979760382.inprogress
23/07/10 17:02:41 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
23/07/10 17:02:41 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
23/07/10 17:02:41 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
23/07/10 17:02:41 INFO DAGScheduler: Parents of final stage: List()
23/07/10 17:02:41 INFO DAGScheduler: Missing parents: List()
23/07/10 17:02:41 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
23/07/10 17:02:41 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 4.0 KiB, free 366.3 MiB)
23/07/10 17:02:41 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 2.3 KiB, free 366.3 MiB)
23/07/10 17:02:41 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on minio.local:39429 (size: 2.3 KiB, free: 366.3 MiB)
23/07/10 17:02:41 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1478
23/07/10 17:02:41 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
23/07/10 17:02:41 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks resource profile 0
23/07/10 17:02:42 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (minio.local, executor driver, partition 0, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
23/07/10 17:02:42 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1) (minio.local, executor driver, partition 1, PROCESS_LOCAL, 4578 bytes) taskResourceAssignments Map()
23/07/10 17:02:42 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
23/07/10 17:02:42 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
23/07/10 17:02:42 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 957 bytes result sent to driver
23/07/10 17:02:42 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 957 bytes result sent to driver
23/07/10 17:02:42 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 226 ms on minio.local (executor driver) (1/2)
23/07/10 17:02:42 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 211 ms on minio.local (executor driver) (2/2)
23/07/10 17:02:42 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
23/07/10 17:02:42 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.363 s
23/07/10 17:02:42 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
23/07/10 17:02:42 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
23/07/10 17:02:42 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 0.403940 s
Pi is roughly 3.1417557087785437
23/07/10 17:02:42 INFO SparkUI: Stopped Spark web UI at http://minio.local:4040
23/07/10 17:02:42 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/07/10 17:02:42 INFO MemoryStore: MemoryStore cleared
23/07/10 17:02:42 INFO BlockManager: BlockManager stopped
23/07/10 17:02:42 INFO BlockManagerMaster: BlockManagerMaster stopped
23/07/10 17:02:42 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/07/10 17:02:42 INFO SparkContext: Successfully stopped SparkContext
23/07/10 17:02:42 INFO ShutdownHookManager: Shutdown hook called
23/07/10 17:02:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-444257f5-6b8d-4ca9-9caa-b70acebe1fd4
23/07/10 17:02:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-b2fb7ba0-e103-4186-9bb4-375565dfd757
23/07/10 17:02:42 INFO MetricsSystemImpl: Stopping s3a-file-system metrics system...
23/07/10 17:02:42 INFO MetricsSystemImpl: s3a-file-system metrics system stopped.
23/07/10 17:02:42 INFO MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
Standalone模式(多台机器组集群的情况)
一般是多机器,有master节点、slave节点,master配置了workers文件,并提前启动了$SPARK_HOME/sbin/start-all.sh ,并可以通过jps命令在各节点查看spark启动进程情况
spark-submit --master spark://master-node:7077 --class org.apache.spark.examples.SparkPi --num-executors 1 /home/soft/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar
相比local模式,主要是启动命令需要添加master参数, 如果是$SPARK_HOME/conf/spark-defaults.conf已配置master参数,启动命令则可以省略该参数
# 去除spark.master的注释
# /etc/hosts 配置: ip master-node
spark.master spark://master-node:7077
💭 Spark-shell
输入spark-shell,进入scala控制台
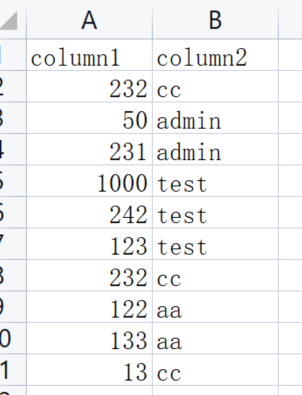
创建一个csv文件(如下图),上传到MinIO中:
输入scale代码测试:
// 导入 SparkSession
import org.apache.spark.sql.SparkSession
// 创建 SparkSession
val spark = SparkSession.builder().appName("ScalaSparkTest").getOrCreate()
// 读取示例数据(例如 CSV 文件)
val df = spark.read.option("header", true).option("inferSchema", true).csv("s3a://bigdatas/test-files/test001.csv")
// 执行一些数据操作和转换
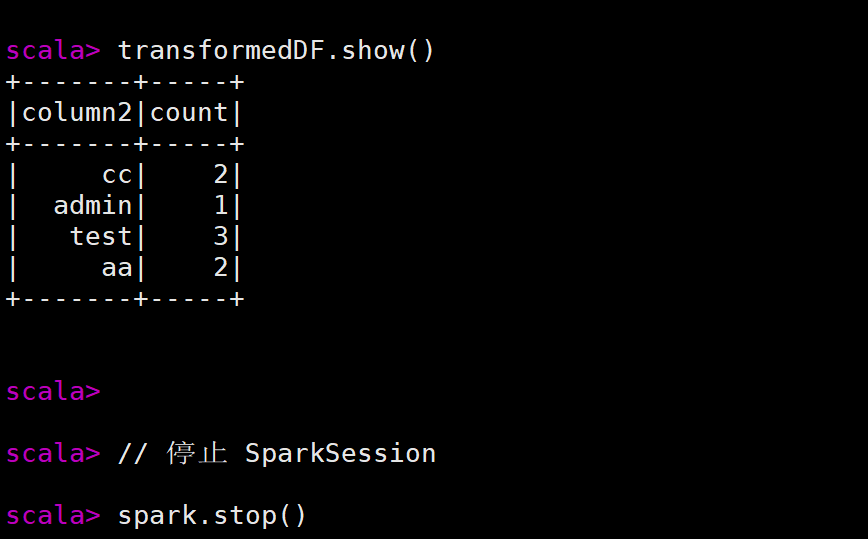
val transformedDF = df.select("column1", "column2").filter("column1 > 100").groupBy("column2").count()
// 展示结果
transformedDF.show()
// 停止 SparkSession
spark.stop()
执行过成中,看到以下内容说明spark-shell基于spark的读取功能正常: