Spark 3.2.2 集群安装部署
Hadoop 集群部署
基础系统环境准备
在VMware中创建3台centos7.6主机,空间50G:
- 配置/etc/hostname
- 修改/etc/sysconfig/network-scripts/ifcfg-ens33静态ip、网关(192.168.208.1)、DNS(8.8.8.8)
- 配置/etc/hosts , 测试是否相互ping通
| 主机名 | IP | 用户 | 角色 |
|---|---|---|---|
| node-4 | 192.168.208.132 | hp | master |
| node-5 | 192.168.208.133 | hp | worker |
| node-6 | 192.168.208.134 | hp | worker |
解压安装
tar -zxvf spark-3.2.2-bin-hadoop3.2 -C /home/hp/
vi ~/.bashrc
# spark
export SPARK_HOME=/home/hp/spark-3.2.2-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
cd /home/hp/spark-3.2.2-bin-hadoop3.2/conf
# 配置日志级别
cp log4j.properties.template log4j.properties
vi log4j.properties
#修改日志级别
log4j.rootCategory= WARN, console
# 运行
spark-shell
看到运行结果,说明执行成功:
22/09/06 10:28:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node-4:4040
Spark context available as 'sc' (master = local[*], app id = local-1662431339052).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.2
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_311)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
测试:
scala> var r = sc.parallelize(Array(1,2,3,4))
r: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:23
scala> r.map(_*10).collect()
res0: Array[Int] = Array(10, 20, 30, 40)
此时,也可以通过访问http://192.168.208.132:4040访问spark UI
配置Standalone集群
cd /home/hp/spark-3.2.2-bin-hadoop3.2/conf/
cp spark-env.sh.template spark-env.sh
# 增加以下内容
export JAVA_HOME=/home/hp/jdk1.8.0_311
export SPARK_HOME=/home/hp/spark-3.2.2-bin-hadoop3.2
# 修改worker
node-4
node-5
node-6
# 同步spark文件到slave节点
scp -r /home/hp/spark-3.2.2-bin-hadoop3.2 node-5:/home/hp
scp -r /home/hp/spark-3.2.2-bin-hadoop3.2 node-6:/home/hp
scp -r ~/.bashrc node-5:~/
scp -r ~/.bashrc node-6:~/
运行集群
[hp@node-4 conf]$ /home/hp/spark-3.2.2-bin-hadoop3.2/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hp/spark-3.2.2-bin-hadoop3.2/logs/spark-hp-org.apache.spark.deploy.master.Master-1-node-4.out
node-6: starting org.apache.spark.deploy.worker.Worker, logging to /home/hp/spark-3.2.2-bin-hadoop3.2/logs/spark-hp-org.apache.spark.deploy.worker.Worker-1-node-6.out
node-5: starting org.apache.spark.deploy.worker.Worker, logging to /home/hp/spark-3.2.2-bin-hadoop3.2/logs/spark-hp-org.apache.spark.deploy.worker.Worker-1-node-5.out
node-4: starting org.apache.spark.deploy.worker.Worker, logging to /home/hp/spark-3.2.2-bin-hadoop3.2/logs/spark-hp-org.apache.spark.deploy.worker.Worker-1-node-4.out
通过jsp可以查看各个节点的进程分布:
master节点
[hp@node-4 conf]$ jps
22516 Worker
23016 Jps
22445 Master
slave节点1
[hp@node-5 sbin]$ jps
20625 Worker
21707 Jps
slave节点2
[hp@node-6 ~]$ jps
20536 Worker
21082 Jps
登录 http://192.168.208.132:8080/
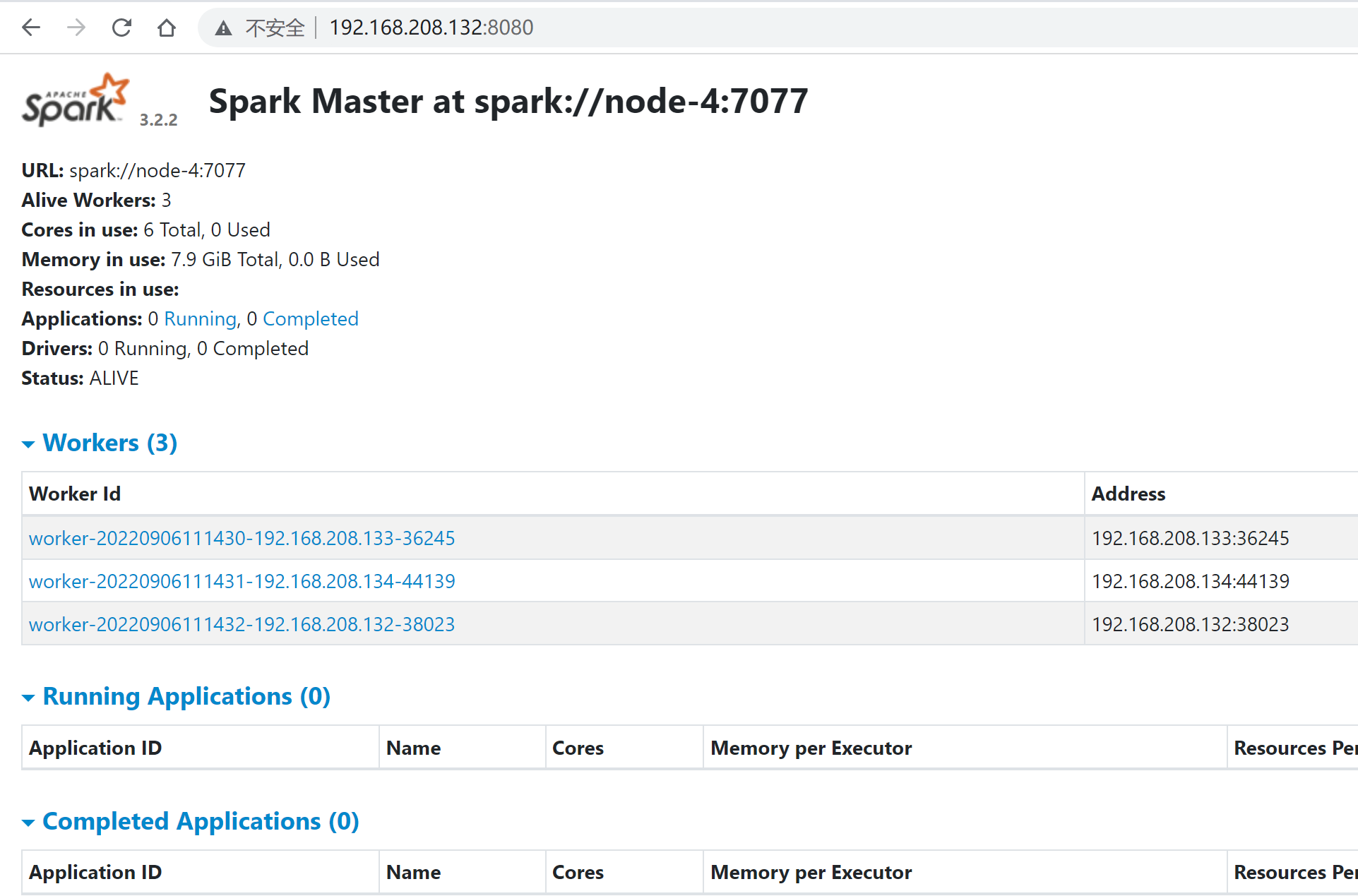
测试集群:
spark-submit --class org.apache.spark.examples.SparkPi --master spark://node-4:7077 --num-executors 1 /home/hp/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar
运行结果:
[hp@node-4 conf]$ spark-submit --class org.apache.spark.examples.SparkPi --master spark://node-4:7077 --num-executors 1 /home/hp/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar
22/09/06 16:57:36 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Pi is roughly 3.145055725278626
此时再查看:http://192.168.208.132:8080/
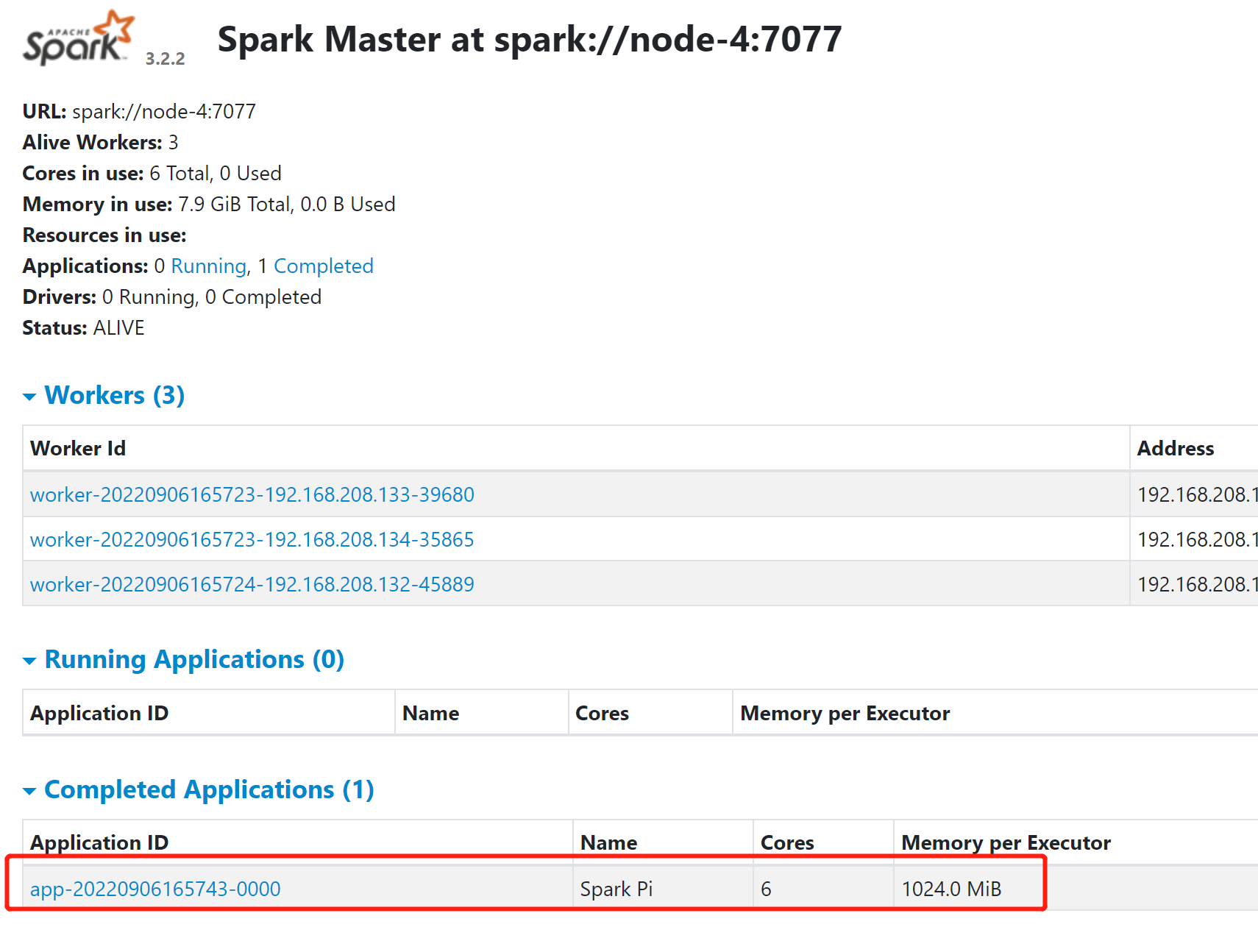
看到Application ID日志记录,说明集群工作正常
关闭集群
/home/hp/spark-3.2.2-bin-hadoop3.2/sbin/stop-all.sh
yarn模式
vi /home/hp/spark-3.2.2-bin-hadoop3.2/conf/spark-env.sh
# 增加hadoop路径,以启用Yarn调度管理spark集群
YARN_CONF_DIR=/home/hp/hadoop-3.2.4/etc/hadoop
# 同步到其他节点
scp ./spark-env.sh node-5:/home/hp/spark-3.2.2-bin-hadoop3.2/conf/
scp ./spark-env.sh node-6:/home/hp/spark-3.2.2-bin-hadoop3.2/conf/
启动Hadoop、spark:
$HADOOP_HOME/sbin/start-all.sh
$SPARK_HOME/sbin/start-all.sh
测试:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1G \
--num-executors 2 \
--executor-memory 1G \
--executor-cores 1 \
/home/hp/spark-3.2.2-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.2.2.jar 100
提示:
22/09/06 17:22:06 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/09/06 17:22:07 WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
需要创建hdfs目录存储:
hdfs dfs -mkdir -p /home/hp/spark_jars
hdfs dfs -ls /home/hp
Found 1 items
drwxr-xr-x - hp supergroup 0 2022-09-06 17:31 /home/hp/spark_jars
cd /home/hp/spark-3.2.2-bin-hadoop3.2/
hdfs dfs -put jars/* /home/hp/spark_jars/
hdfs dfs -ls /home/hp/spark_jars/
# 显示存储的文件
Found 235 items
-rw-r--r-- 3 hp supergroup 136363 2022-09-06 17:32 /home/hp/spark_jars/HikariCP-2.5.1.jar
-rw-r--r-- 3 hp supergroup 232470 2022-09-06 17:32 /home/hp/spark_jars/JLargeArrays-1.5.jar
-rw-r--r-- 3 hp supergroup 1175798 2022-09-06 17:32 /home/hp/spark_jars/JTransforms-3.1.jar
-rw-r--r-- 3 hp supergroup 386529 2022-09-06 17:33 /home/hp/spark_jars/RoaringBitmap-0.9.0.jar
-rw-r--r-- 3 hp supergroup 236660 2022-09-06 17:33 /home/hp/spark_jars/ST4-4.0.4.jar
-rw-r--r-- 3 hp supergroup 69409 2022-09-06 17:32 /home/hp/spark_jars/activation-1.1.1.jar
.....
重新执行测试命令, 注意: --deploy-mode cluster ,运行结果将不显示在控制台,需要通过hadoop UI查看,
访问: http://192.168.208.132:8088/cluster/apps,点击最新一条application id,

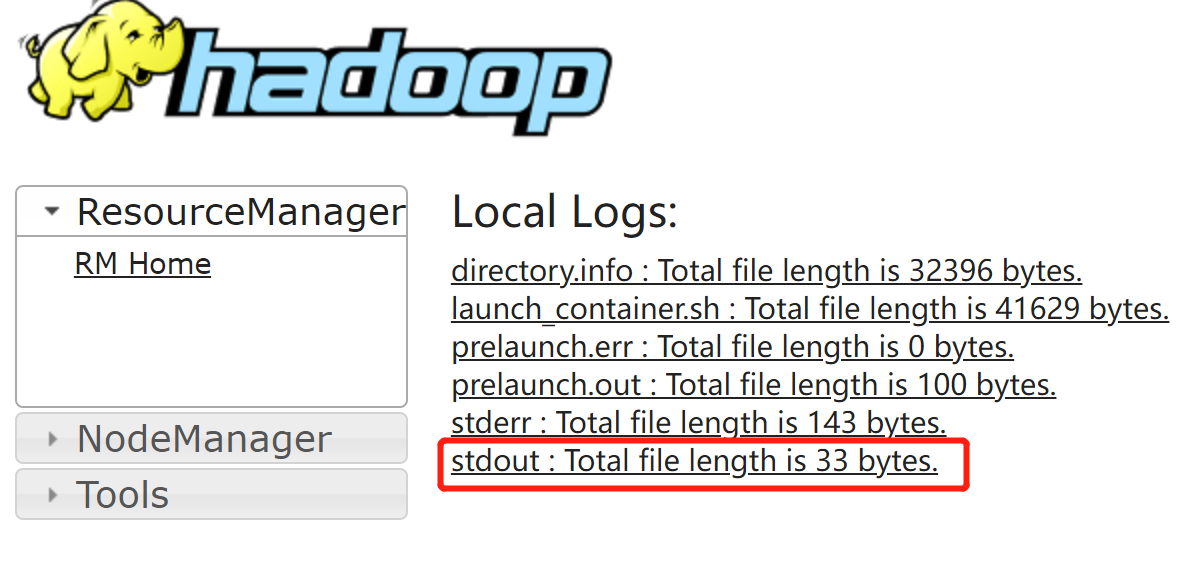
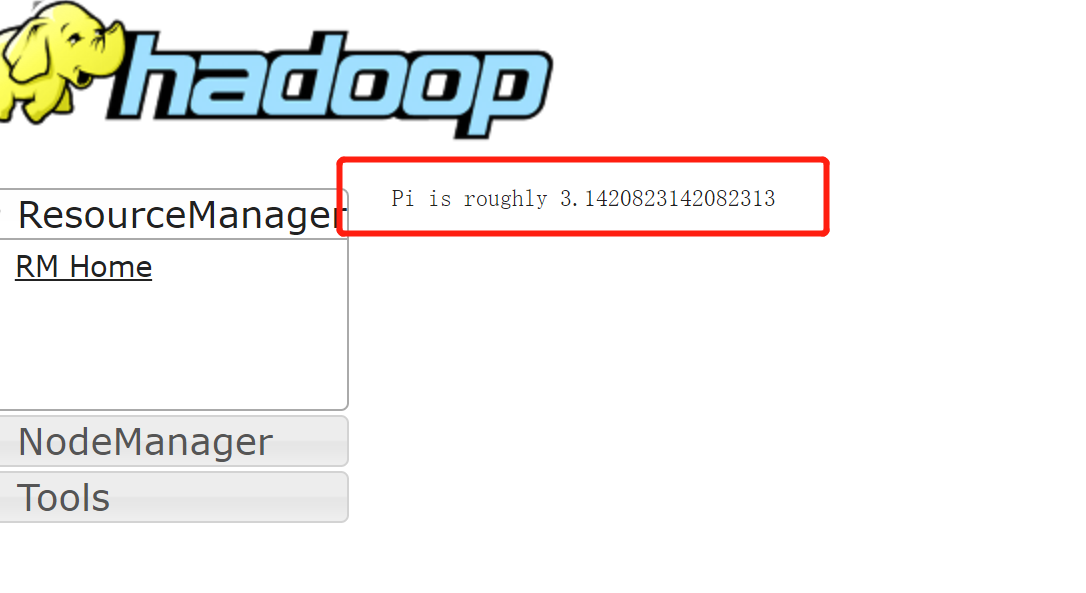
到此,说明yarn模式集群工作正常
参考:
https://blog.csdn.net/xiaoxiongaa0/article/details/90233687
https://blog.csdn.net/qq_41187116/article/details/125814587
https://blog.csdn.net/qq_44226094/article/details/123851080
